Every slider min, max and step values as well as its default value is now configurable through the config file. |
||
|---|---|---|
| .github | ||
| .idea | ||
| configs | ||
| data | ||
| frontend | ||
| images | ||
| ldm | ||
| models | ||
| optimizedSD | ||
| scripts | ||
| .dockerignore | ||
| .env_docker.example | ||
| .gitattributes | ||
| .gitignore | ||
| docker-compose.yml | ||
| docker-reset.sh | ||
| Dockerfile | ||
| entrypoint.sh | ||
| environment.yaml | ||
| LICENSE | ||
| README.md | ||
| setup.py | ||
| Stable_Diffusion_v1_Model_Card.md | ||
| webui-streamlit.cmd | ||
| webui.cmd | ||
| webui.sh | ||
Visit sd-webui's Discord Server 
Installation instructions for Windows, Linux
Have an issue?
- If the issue involves a bug in textual-inversion create the issue on sd-webui/stable-diffusion-webui
- If you want to know how to activate or use textual-inversion see hlky/sd-enable-textual-inversion. Activation not working? create the issue on sd-webui/stable-diffusion-webui
Want to contribute?
Gradio version (stable)
Open new Pull Requests on dev branch!
for Gradio check out the docs to contribute
Have an issue or feature request with Gradio? open a issue/feature request on github for support: https://github.com/gradio-app/gradio/issues
Need more support with Gradio? We have a discord channel called gradio-stable-diffusion for Q&A with the gradio authors, to join use this link https://discord.gg/Qs8AsnX7Jd, then go to role-assignment and click gradio to join the gradio channels.
New features can be added to Gradio or Streamlit versions
More documentation about features, troubleshooting, common issues very soon
Want to help with documentation? Documented something? Use Discussions
Important
🔥 NEW! webui.cmd updates with any changes in environment.yaml file so the environment will always be up to date as long as you get the new environment.yaml file 🔥
🔥 no need to remove environment, delete src folder and create again, MUCH simpler! 🔥
Questions about Upscalers?
Questions about Optimized mode?
Questions about Command line options?
Features:
- Gradio GUI: Idiot-proof, fully featured frontend for both txt2img and img2img generation
- No more manually typing parameters, now all you have to do is write your prompt and adjust sliders
- GFPGAN Face Correction 🔥: Download the model Automatically correct distorted faces with a built-in GFPGAN option, fixes them in less than half a second
- RealESRGAN Upscaling 🔥: Download the models Boosts the resolution of images with a built-in RealESRGAN option
- 💻 esrgan/gfpgan on cpu support 💻
- Textual inversion 🔥: info - requires enabling, see here, script works as usual without it enabled
- Advanced img2img editor 🎨 🔥 🎨
- 🔥🔥 Mask and crop 🔥🔥
- Mask painting (NEW) 🖌️: Powerful tool for re-generating only specific parts of an image you want to change
- More k_diffusion samplers 🔥🔥 : Far greater quality outputs than the default sampler, less distortion and more accurate
- txt2img samplers: "DDIM", "PLMS", 'k_dpm_2_a', 'k_dpm_2', 'k_euler_a', 'k_euler', 'k_heun', 'k_lms'
- img2img samplers: "DDIM", 'k_dpm_2_a', 'k_dpm_2', 'k_euler_a', 'k_euler', 'k_heun', 'k_lms'
- Loopback (NEW) ➿: Automatically feed the last generated sample back into img2img
- Prompt Weighting (NEW) 🏋️: Adjust the strength of different terms in your prompt
- 🔥 gpu device selectable with --gpu 🔥
- Memory Monitoring 🔥: Shows Vram usage and generation time after outputting.
- Word Seeds 🔥: Use words instead of seed numbers
- CFG: Classifier free guidance scale, a feature for fine-tuning your output
- Launcher Automatic 👑🔥 shortcut to load the model, no more typing in Conda
- Lighter on Vram: 512x512 img2img & txt2img tested working on 6gb
- and ????
Stable Diffusion web UI
A browser interface based on Gradio library for Stable Diffusion.
Original script with Gradio UI was written by a kind anonymous user. This is a modification.




GFPGAN
If you want to use GFPGAN to improve generated faces, you need to install it separately.
Download GFPGANv1.3.pth and put it
into the /stable-diffusion-webui/src/gfpgan/experiments/pretrained_models directory.
RealESRGAN
Download RealESRGAN_x4plus.pth and RealESRGAN_x4plus_anime_6B.pth.
Put them into the stable-diffusion-webui/src/realesrgan/experiments/pretrained_models directory.
LDSR
- Download LDSR project.yaml and model last.cpkt. Rename last.ckpt to model.ckpt and place both under stable-diffusion-webui/src/latent-diffusion/experiments/pretrained_models/
Web UI
When launching, you may get a very long warning message related to some weights not being used. You may freely ignore it. After a while, you will get a message like this:
Running on local URL: http://127.0.0.1:7860/
Open the URL in browser, and you are good to go.
Features
The script creates a web UI for Stable Diffusion's txt2img and img2img scripts. Following are features added that are not in original script.
GFPGAN
Lets you improve faces in pictures using the GFPGAN model. There is a checkbox in every tab to use GFPGAN at 100%, and also a separate tab that just allows you to use GFPGAN on any picture, with a slider that controls how strong the effect is.

RealESRGAN
Lets you double the resolution of generated images. There is a checkbox in every tab to use RealESRGAN, and you can choose between the regular upscaler and the anime version. There is also a separate tab for using RealESRGAN on any picture.

Sampling method selection
txt2img samplers: "DDIM", "PLMS", 'k_dpm_2_a', 'k_dpm_2', 'k_euler_a', 'k_euler', 'k_heun', 'k_lms' img2img samplers: "DDIM", 'k_dpm_2_a', 'k_dpm_2', 'k_euler_a', 'k_euler', 'k_heun', 'k_lms'

Prompt matrix
Separate multiple prompts using the | character, and the system will produce an image for every combination of them.
For example, if you use a busy city street in a modern city|illustration|cinematic lighting prompt, there are four combinations possible (first part of prompt is always kept):
a busy city street in a modern citya busy city street in a modern city, illustrationa busy city street in a modern city, cinematic lightinga busy city street in a modern city, illustration, cinematic lighting
Four images will be produced, in this order, all with same seed and each with corresponding prompt:
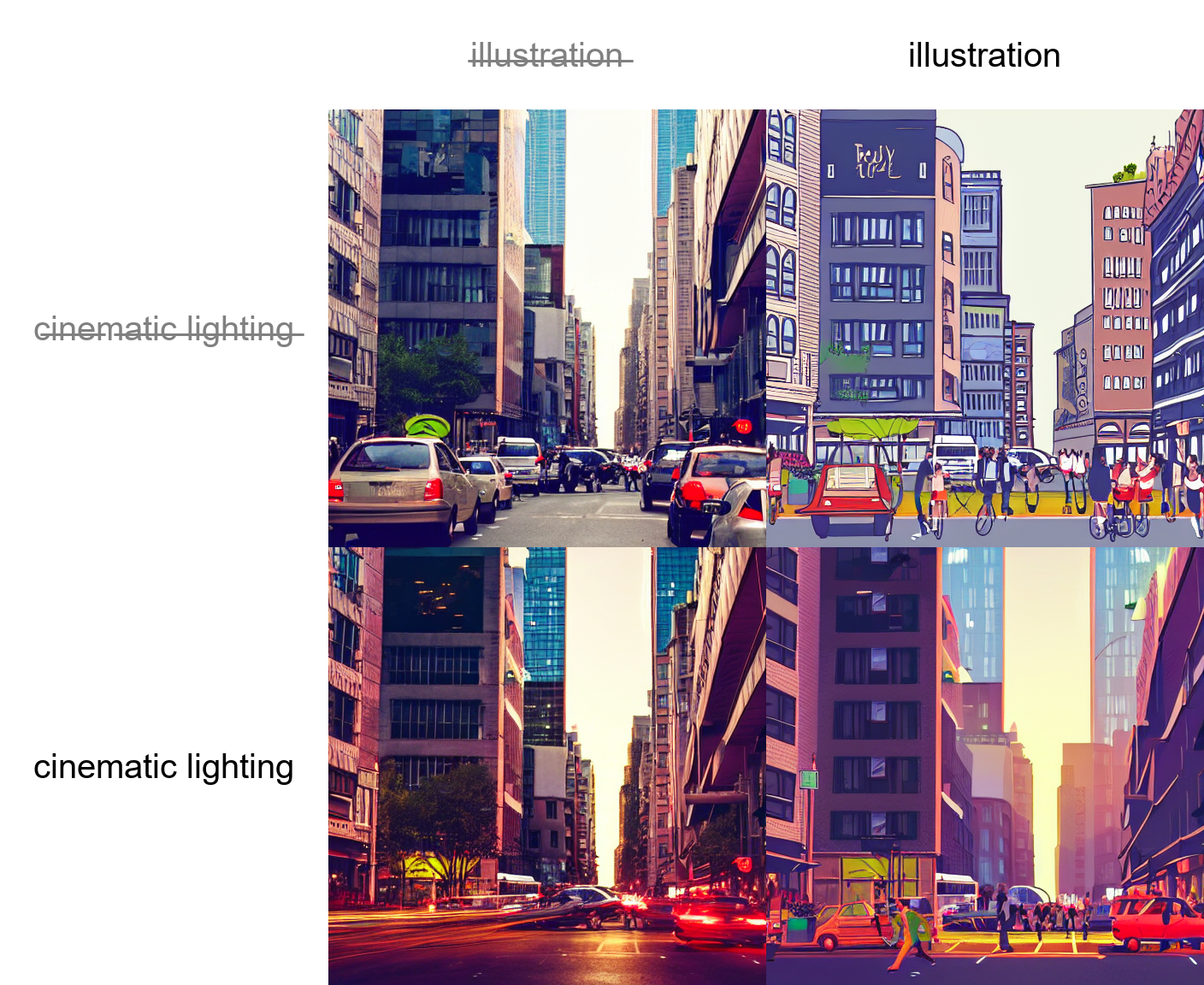
Another example, this time with 5 prompts and 16 variations:

If you use this feature, batch count will be ignored, because the number of pictures to produce depends on your prompts, but batch size will still work (generating multiple pictures at the same time for a small speed boost).
Flagging (Broken after UI changed to gradio.Blocks() see Flag button missing from new UI)
Click the Flag button under the output section, and generated images will be saved to log/images directory, and generation parameters
will be appended to a csv file log/log.csv in the /sd directory.
but every image is saved, why would I need this?
If you're like me, you experiment a lot with prompts and settings, and only few images are worth saving. You can just save them using right click in browser, but then you won't be able to reproduce them later because you will not know what exact prompt created the image. If you use the flag button, generation paramerters will be written to csv file, and you can easily find parameters for an image by searching for its filename.
Copy-paste generation parameters
A text output provides generation parameters in an easy to copy-paste form for easy sharing.
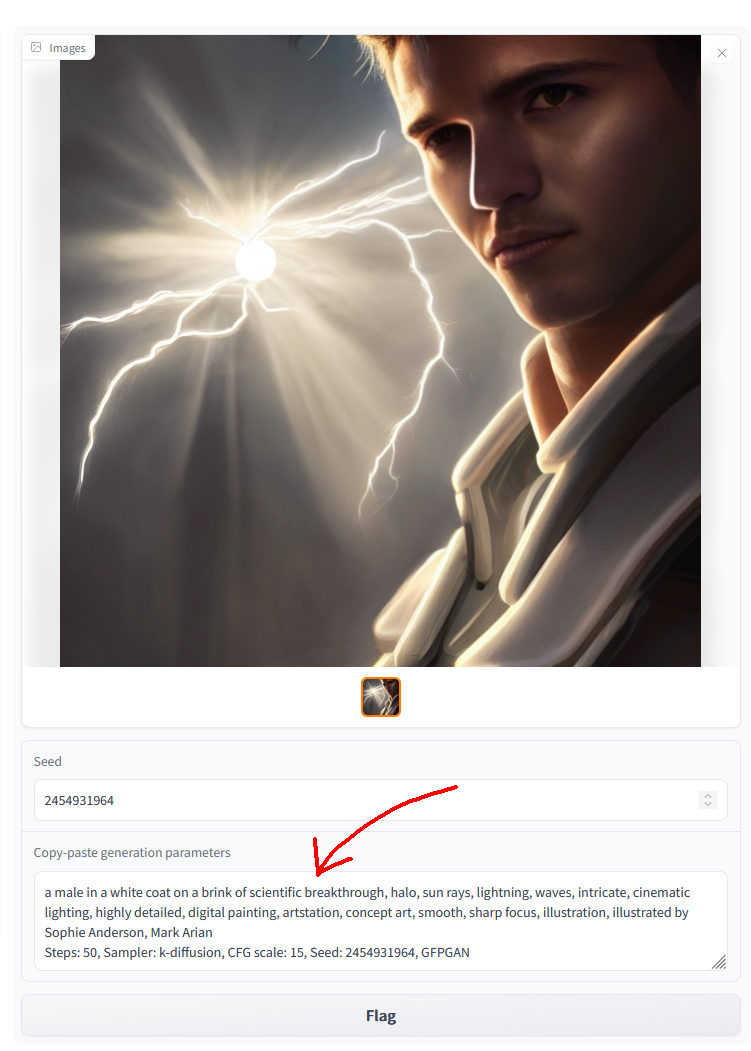
If you generate multiple pictures, the displayed seed will be the seed of the first one.
Correct seeds for batches
If you use a seed of 1000 to generate two batches of two images each, four generated images will have seeds: 1000, 1001, 1002, 1003.
Previous versions of the UI would produce 1000, x, 1001, x, where x is an iamge that can't be generated by any seed.
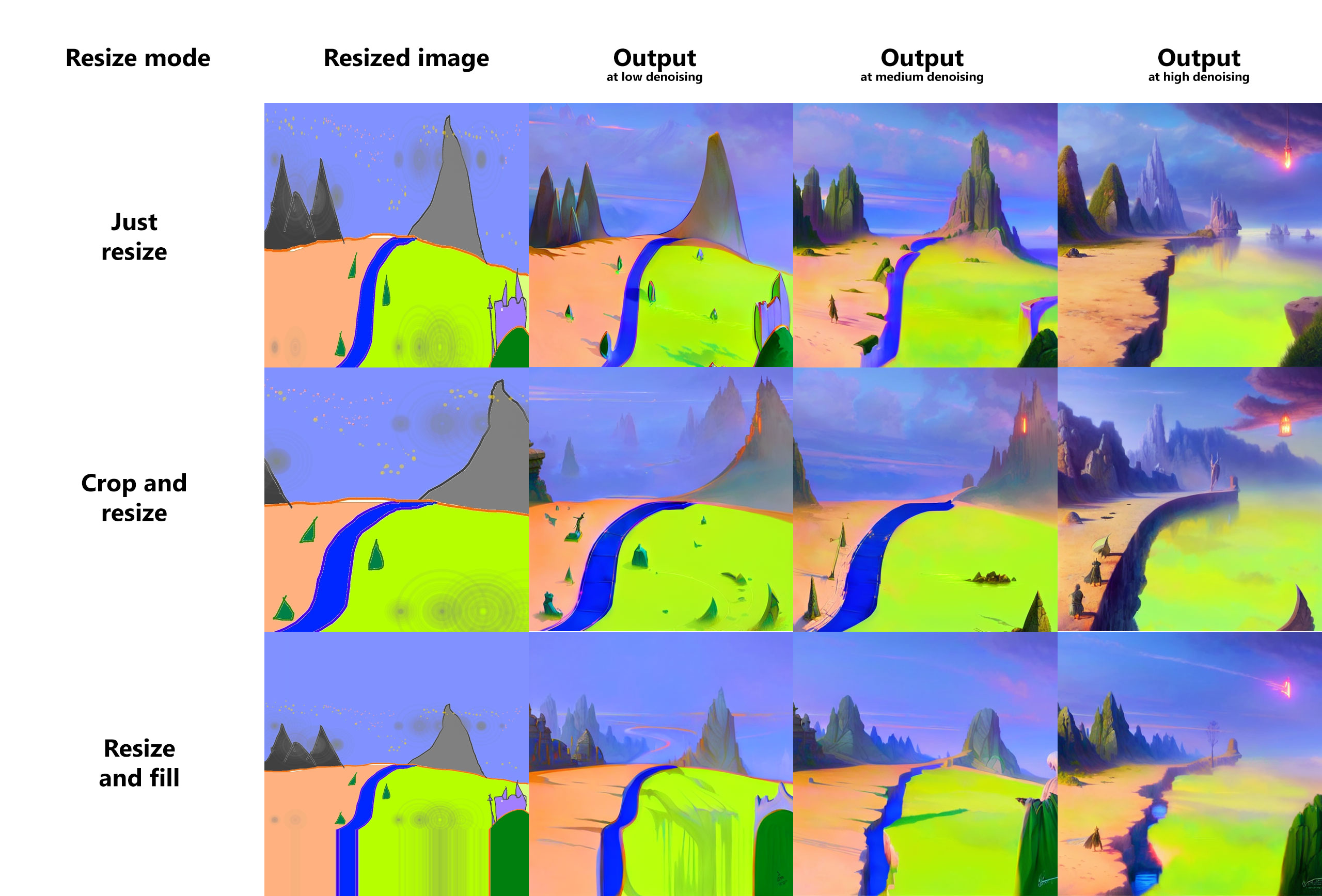
Resizing
There are three options for resizing input images in img2img mode:
- Just resize - simply resizes source image to target resolution, resulting in incorrect aspect ratio
- Crop and resize - resize source image preserving aspect ratio so that entirety of target resolution is occupied by it, and crop parts that stick out
- Resize and fill - resize source image preserving aspect ratio so that it entirely fits target resolution, and fill empty space by rows/columns from source image
Example:
Loading
Gradio's loading graphic has a very negative effect on the processing speed of the neural network. My RTX 3090 makes images about 10% faster when the tab with gradio is not active. By default, the UI now hides loading progress animation and replaces it with static "Loading..." text, which achieves the same effect. Use the --no-progressbar-hiding commandline option to revert this and show loading animations.
Prompt validation
Stable Diffusion has a limit for input text length. If your prompt is too long, you will get a warning in the text output field, showing which parts of your text were truncated and ignored by the model.
Loopback
A checkbox for img2img allowing to automatically feed output image as input for the next batch. Equivalent to saving output image, and replacing input image with it. Batch count setting controls how many iterations of this you get.
Usually, when doing this, you would choose one of many images for the next iteration yourself, so the usefulness of this feature may be questionable, but I've managed to get some very nice outputs with it that I wasn't abble to get otherwise.
Example: (cherrypicked result; original picture by anon)

--help
optional arguments:
-h, --help show this help message and exit
--outdir [OUTDIR] dir to write results to
--outdir_txt2img [OUTDIR_TXT2IMG]
dir to write txt2img results to (overrides --outdir)
--outdir_img2img [OUTDIR_IMG2IMG]
dir to write img2img results to (overrides --outdir)
--save-metadata Whether to embed the generation parameters in the sample images
--skip-grid do not save a grid, only individual samples. Helpful when evaluating lots of samples
--skip-save do not save indiviual samples. For speed measurements.
--n_rows N_ROWS rows in the grid; use -1 for autodetect and 0 for n_rows to be same as batch_size (default:
-1)
--config CONFIG path to config which constructs model
--ckpt CKPT path to checkpoint of model
--precision {full,autocast}
evaluate at this precision
--gfpgan-dir GFPGAN_DIR
GFPGAN directory
--realesrgan-dir REALESRGAN_DIR
RealESRGAN directory
--realesrgan-model REALESRGAN_MODEL
Upscaling model for RealESRGAN
--no-verify-input do not verify input to check if it's too long
--no-half do not switch the model to 16-bit floats
--no-progressbar-hiding
do not hide progressbar in gradio UI (we hide it because it slows down ML if you have hardware
accleration in browser)
--defaults DEFAULTS path to configuration file providing UI defaults, uses same format as cli parameter
--gpu GPU choose which GPU to use if you have multiple
--extra-models-cpu run extra models (GFGPAN/ESRGAN) on cpu
--esrgan-cpu run ESRGAN on cpu
--gfpgan-cpu run GFPGAN on cpu
--cli CLI don't launch web server, take Python function kwargs from this file.
Stable Diffusion
Stable Diffusion was made possible thanks to a collaboration with Stability AI and Runway and builds upon our previous work:
High-Resolution Image Synthesis with Latent Diffusion Models
Robin Rombach*,
Andreas Blattmann*,
Dominik Lorenz,
Patrick Esser,
Björn Ommer
CVPR '22 Oral
which is available on GitHub. PDF at arXiv. Please also visit our Project page.
 Stable Diffusion is a latent text-to-image diffusion
model.
Thanks to a generous compute donation from Stability AI and support from LAION, we were able to train a Latent Diffusion Model on 512x512 images from a subset of the LAION-5B database.
Similar to Google's Imagen,
this model uses a frozen CLIP ViT-L/14 text encoder to condition the model on text prompts.
With its 860M UNet and 123M text encoder, the model is relatively lightweight and runs on a GPU with at least 10GB VRAM.
See this section below and the model card.
Stable Diffusion is a latent text-to-image diffusion
model.
Thanks to a generous compute donation from Stability AI and support from LAION, we were able to train a Latent Diffusion Model on 512x512 images from a subset of the LAION-5B database.
Similar to Google's Imagen,
this model uses a frozen CLIP ViT-L/14 text encoder to condition the model on text prompts.
With its 860M UNet and 123M text encoder, the model is relatively lightweight and runs on a GPU with at least 10GB VRAM.
See this section below and the model card.
Stable Diffusion v1
Stable Diffusion v1 refers to a specific configuration of the model architecture that uses a downsampling-factor 8 autoencoder with an 860M UNet and CLIP ViT-L/14 text encoder for the diffusion model. The model was pretrained on 256x256 images and then finetuned on 512x512 images.
*Note: Stable Diffusion v1 is a general text-to-image diffusion model and therefore mirrors biases and (mis-)conceptions that are present in its training data. Details on the training procedure and data, as well as the intended use of the model can be found in the corresponding model card.
Comments
-
Our codebase for the diffusion models builds heavily on OpenAI's ADM codebase and https://github.com/lucidrains/denoising-diffusion-pytorch. Thanks for open-sourcing!
-
The implementation of the transformer encoder is from x-transformers by lucidrains.
BibTeX
@misc{rombach2021highresolution,
title={High-Resolution Image Synthesis with Latent Diffusion Models},
author={Robin Rombach and Andreas Blattmann and Dominik Lorenz and Patrick Esser and Björn Ommer},
year={2021},
eprint={2112.10752},
archivePrefix={arXiv},
primaryClass={cs.CV}
}