Auxiliary sbt commands for building individual
stdlib packages.
The commands check if the engine distribution was built at least once,
and only copy the necessary package files if necessary.
So far added:
- `buildStdLibBase`
- `buildStdLibDatabase`
- `buildStdLibTable`
- `buildStdLibImage`
- `buildStdLibGoogle_Api`
Related to [#182014385](https://www.pivotaltracker.com/story/show/182014385)
Implement a command that launches the application, runs a series of steps (a "workflow"), writes a profile to a file, and exits.
See: [#181775808](https://www.pivotaltracker.com/story/show/181775808)
# Important Notes
- The command to capture run and profile is used like: `./run profile --workflow=new_project --save-profile=out.json`. Defining some more workflows (collapse nodes, create node and edit value) comes next; they are implemented with the same infrastructure as the integration-tests.
- The `--save-profile` option can also be used when profiling interactively; when the option is provided, capturing a profile with the hotkey will write a file instead of dumping the data to the devtools console.
- If the IDE panics, the error message is now printed to the console that invoked the process, as well as the devtools console. (If a batch workflow fails, this allows us to see why.)
- New functionality (writing profile files, quitting on command, logging to console) relies on Electron APIs. These APIs are implemented in `index.js`, bridged to the render process in `preload.js`, and wrapped for use in Rust in a `debug_api` crate.
In order to analyse why the `runner.jar` is slow to start, let's _"self sample"_ it using the [sampler library](https://bits.netbeans.org/dev/javadoc/org-netbeans-modules-sampler/org/netbeans/modules/sampler/Sampler.html). As soon as the `Main.main` is launched, the sampling starts and once the server is up, it writes its data into `/tmp/language-server.npss`.
Open the `/tmp/language-server.npss` with [VisualVM](https://visualvm.github.io) - you should have one copy in your
GraalVM `bin/jvisualvm` directory and there has to be a GraalVM to run Enso.
#### Changelog
- add: the `MethodsSampler` that gathers information in `.npss` format
- add: `--profiling` flag that enables the sampler
- add: language server processes the updates in batches
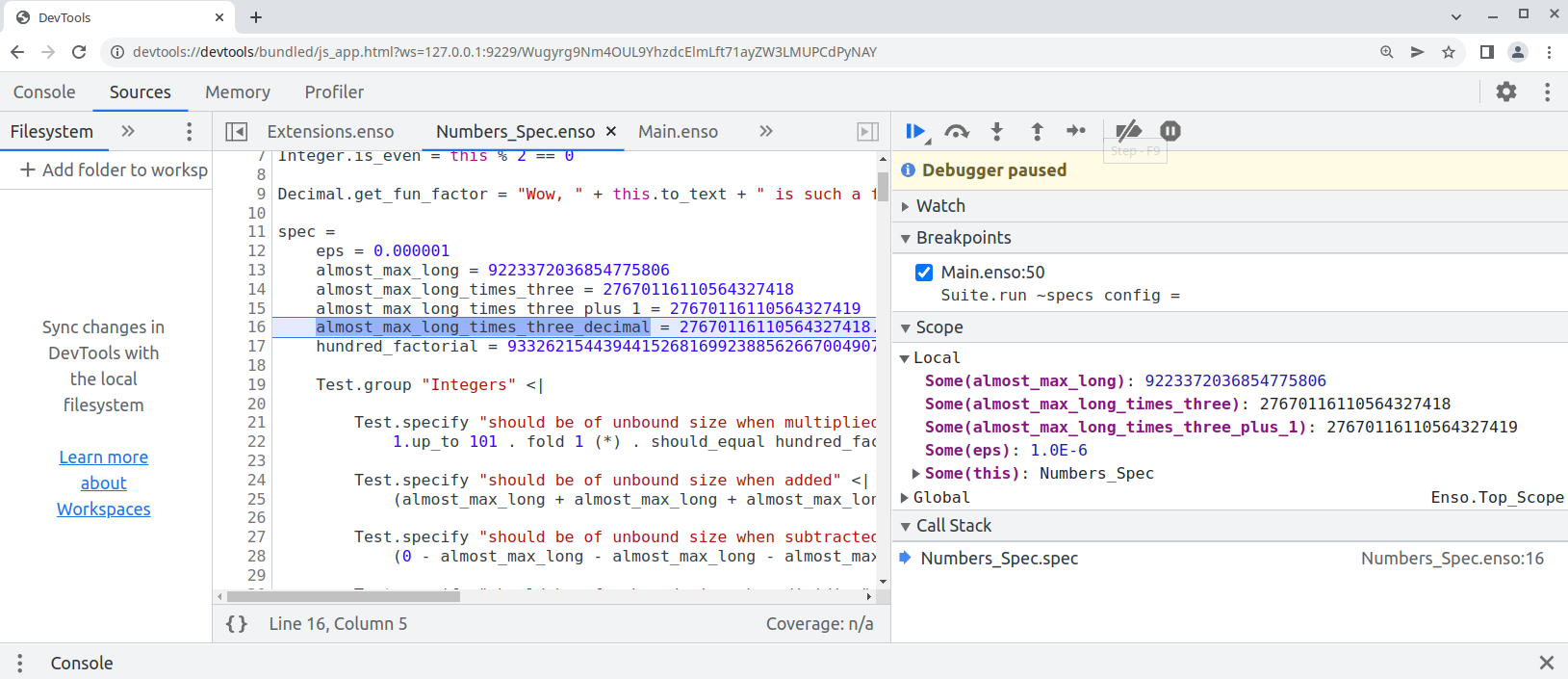
Finally this pull request proposes `--inspect` option to allow [debugging of `.enso`](e948f2535f/docs/debugger/README.md) in Chrome Developer Tools:
```bash
enso$ ./built-distribution/enso-engine-0.0.0-dev-linux-amd64/enso-0.0.0-dev/bin/enso --inspect --run ./test/Tests/src/Data/Numbers_Spec.enso
Debugger listening on ws://127.0.0.1:9229/Wugyrg9Nm4OUL9YhzdcElmLft71ayZW3LMUPCdPyNAY
For help, see: https://www.graalvm.org/tools/chrome-debugger
E.g. in Chrome open: devtools://devtools/bundled/js_app.html?ws=127.0.0.1:9229/Wugyrg9Nm4OUL9YhzdcElmLft71ayZW3LMUPCdPyNAY
```
copy the printed URL into chrome browser and you should see:
One can also debug the `.enso` files in NetBeans or [VS Code with Apache Language Server extension](https://cwiki.apache.org/confluence/display/NETBEANS/Apache+NetBeans+Extension+for+Visual+Studio+Code) just pass in special JVM arguments:
```bash
enso$ JAVA_OPTS=-agentlib:jdwp=transport=dt_socket,server=y,address=8000 ./built-distribution/enso-engine-0.0.0-dev-linux-amd64/enso-0.0.0-dev/bin/enso --run ./test/Tests/src/Data/Numbers_Spec.enso
Listening for transport dt_socket at address: 8000
```
and then _Debug/Attach Debugger_. Once connected choose the _Toggle Pause in GraalVM Script_ button in the toolbar (the "G" button):
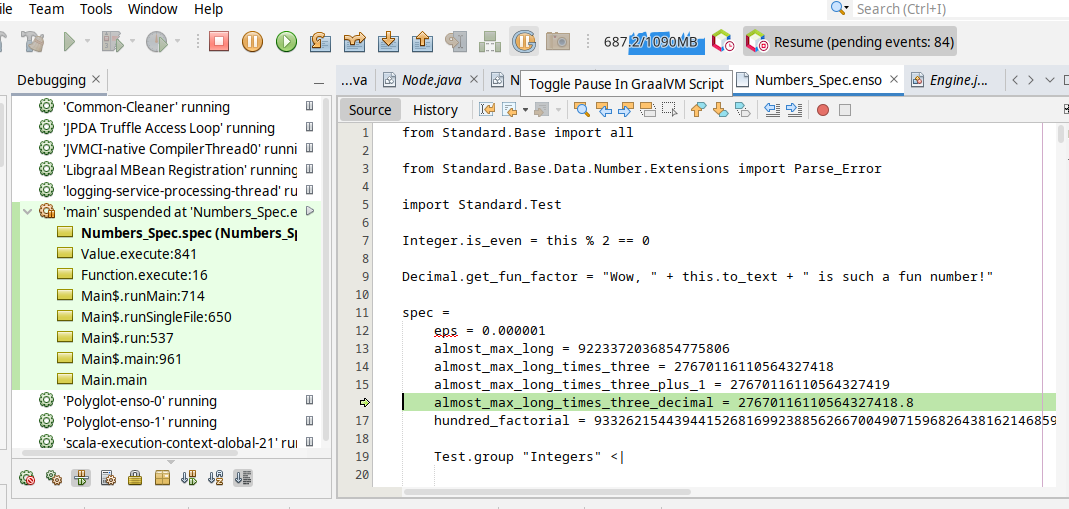
and your execution shall stop on the next `.enso` line of code. This mode allows to debug both - the Enso code as well as Java code.
Originally started as an attempt to write test in Java:
* test written in Java
* support for JUnit in `build.sbt`
* compile Java with `-g` - so it can be debugged
* Implementation of `StatementNode` - only gets created when `materialize` request gets to `BlockNode`
Debug is not imported by default (let me know if it should be?)
# Important Notes
When Debug was part of Builtins.enso everything was imported. Let me know if the new setup is not as expected.
- Read in Excel files following the specification.
- Support for XLSX and XLS formats.
- Ability to select ranges and sheets.
- Skip Rows and Row Limits.
# Important Notes
- Minor fix to DelimitedReader for Windows
This PR replaces hard-coded `@Builtin_Method` and `@Builtin_Type` nodes in Builtins with an automated solution
that a) collects metadata from such annotations b) generates `BuiltinTypes` c) registers builtin methods with corresponding
constructors.
The main differences are:
1) The owner of the builtin method does not necessarily have to be a builtin type
2) You can now mix regular methods and builtin ones in stdlib
3) No need to keep track of builtin methods and types in various places and register them by hand (a source of many typos or omissions as it found during the process of this PR)
Related to #181497846
Benchmarks also execute within the margin of error.
### Important Notes
The PR got a bit large over time as I was moving various builtin types and finding various corner cases.
Most of the changes however are rather simple c&p from Builtins.enso to the corresponding stdlib module.
Here is the list of the most crucial updates:
- `engine/runtime/src/main/java/org/enso/interpreter/runtime/builtin/Builtins.java` - the core of the changes. We no longer register individual builtin constructors and their methods by hand. Instead, the information about those is read from 2 metadata files generated by annotation processors. When the builtin method is encountered in stdlib, we do not ignore the method. Instead we lookup it up in the list of registered functions (see `getBuiltinFunction` and `IrToTruffle`)
- `engine/runtime/src/main/java/org/enso/interpreter/runtime/callable/atom/AtomConstructor.java` has now information whether it corresponds to the builtin type or not.
- `engine/runtime/src/main/scala/org/enso/compiler/codegen/RuntimeStubsGenerator.scala` - when runtime stubs generator encounters a builtin type, based on the @Builtin_Type annotation, it looks up an existing constructor for it and registers it in the provided scope, rather than creating a new one. The scope of the constructor is also changed to the one coming from stdlib, while ensuring that synthetic methods (for fields) also get assigned correctly
- `engine/runtime/src/main/scala/org/enso/compiler/codegen/IrToTruffle.scala` - when a builtin method is encountered in stdlib we don't generate a new function node for it, instead we look it up in the list of registered builtin methods. Note that Integer and Number present a bit of a challenge because they list a whole bunch of methods that don't have a corresponding method (instead delegating to small/big integer implementations).
During the translation new atom constructors get initialized but we don't want to do it for builtins which have gone through the process earlier, hence the exception
- `lib/scala/interpreter-dsl/src/main/java/org/enso/interpreter/dsl/MethodProcessor.java` - @Builtin_Method processor not only generates the actual code fpr nodes but also collects and writes the info about them (name, class, params) to a metadata file that is read during builtins initialization
- `lib/scala/interpreter-dsl/src/main/java/org/enso/interpreter/dsl/MethodProcessor.java` - @Builtin_Method processor no longer generates only (root) nodes but also collects and writes the info about them (name, class, params) to a metadata file that is read during builtins initialization
- `lib/scala/interpreter-dsl/src/main/java/org/enso/interpreter/dsl/TypeProcessor.java` - Similar to MethodProcessor but handles @Builtin_Type annotations. It doesn't, **yet**, generate any builtin objects. It also collects the names, as present in stdlib, if any, so that we can generate the names automatically (see generated `types/ConstantsGen.java`)
- `engine/runtime/src/main/java/org/enso/interpreter/node/expression/builtin` - various classes annotated with @BuiltinType to ensure that the atom constructor is always properly registered for the builitn. Note that in order to support types fields in those, annotation takes optional `params` parameter (comma separated).
- `engine/runtime/src/bench/scala/org/enso/interpreter/bench/fixtures/semantic/AtomFixtures.scala` - drop manual creation of test list which seemed to be a relict of the old design
A draft of simple changes to the compiler to expose sum type information. Doesn't break the stdlib & at the same time allows for dropdowns. This is still broken, for example it doesn't handle exporting/importing types, only ones defined in the same module as the signature. Still, seems like a step in the right direction – please provide feedback.
# Important Notes
I've decided to make the variant info part of the type, not the argument – it is a property of the type logically.
Also, I've pushed it as far as I'm comfortable – i.e. to the `SuggestionHandler` – I have no idea if this is enough to show in IDE? cc @4e6
Most of the functions in the standard library aren't gonna be invoked during particular program execution. It makes no sense to build their Truffle AST for the functions that are not executing. Let's delay the construction of the tree until a function is first executed.
* Initial integration with Frgaal in sbt
Half-working since it chokes on generated classes from annotation
processor.
* Replace AutoService with ServiceProvider
For reasons unknown AutoService would fail to initialize and fail to
generate required builtin method classes.
Hidden error message is not particularly revealing on the reason for
that:
```
[error] error: Bad service configuration file, or exception thrown while constructing Processor object: javax.annotation.processing.Processor: Provider com.google.auto.service.processor.AutoServiceProcessor could not be instantiated
```
The sample records is only to demonstrate that we can now use newer Java
features.
* Cleanup + fix benchmark compilation
Bench requires jmh classes which are not available because we obviously
had to limit `java.base` modules to get Frgaal to work nicely.
For now, we default to good ol' javac for Benchmarks.
Limiting Frgaal to runtime for now, if it plays nicely, we can expand it
to other projects.
* Update CHANGELOG
* Remove dummy record class
* Update licenses
* New line
* PR review
* Update legal review
Co-authored-by: Radosław Waśko <radoslaw.wasko@enso.org>
* New JSON profile format.
* Use string-table optimization for labels in JSON format.
* Use TimeOffset header to render beanpoles
* Log RPC messages sent to the backend.
* Display RPC requests on graph
* Simplify metadata-logging interface.
Implements a visualization that is integrated with our GUI profiling visualization for the multiprocess data implemented in #3395https://user-images.githubusercontent.com/1428930/165915395-c850c7b2-1cc5-4eb0-8f21-37565d113b1e.mp4
The visualization shows a horizontal line for Engine, Language Server and GUI and renders arrows for each message passed between them. Information about the message is revealed on hover.
# Important Notes
* this PR refactors the tooltip mechanism. Note that this has not been in active use anywhere else, as tooltips for node received a custom implementation and the tooltip that was previously implemented was used nowhere else yet.
[ci no changelog needed]
* The List View component was refactored: it allows for hiding the internal selection widget, and exposes information where the widget should be placed. This allows us to create selection widget in component list panel, so it can be animated between component groups and sections.
* Fixed some warnings when checking WASM code.
* Adjusted the style of Component Group View a little, so it better reflects the design doc. Still not ideal, because the list_view has some weird design regarding padding, but I don't want to stuck in some bigger refactoring.
I will add a video in a few minutes.
# Important Notes
https://user-images.githubusercontent.com/3919101/165507826-60329f9e-7de3-4eb2-9271-292e45568cb2.mov
[ci no changelog needed]
This is fixed copy of already reviewed #3384
[Task link](https://www.pivotaltracker.com/story/show/181413200)
This PR implements content clipping for the ScrollArea component.
List of changes:
- Implemented `InstanceWithAttachedLayer` abstraction that allows creating additional sublayers for our components. In the future, this abstraction can be used for text rendering as well (right now text rendering requires additional hardcoded layers).
- Fixed `complex-shape-system` demo scene by removing `node_searcher_mask` layer.
- Fixed `SublayersModel::remove` - it was not clearing the `layer_placement` hashmap.
- Implemented disabling the wheel scrolling in `Navigator`, and refactored it to reduce the number of functions arguments by introducing a `NavigatorSettings` struct.
Video (`scroll_area` demo):
https://user-images.githubusercontent.com/6566674/164506455-e177a7a7-9f1c-4f50-888f-112423cebbe4.mp4
# Important Notes
- `InstanceWithAttachedLayer` is implemented in such a way that it allows an extension in the future - namely to use it to simplify text rendering. The implementation might be simplified though.
[ci no changelog needed]
[Task link](https://www.pivotaltracker.com/story/show/181413200)
This PR implements content clipping for the ScrollArea component.
List of changes:
- Implemented `InstanceWithAttachedLayer` abstraction that allows creating additional sublayers for our components. In the future, this abstraction can be used for text rendering as well (right now text rendering requires additional hardcoded layers).
- Fixed `complex-shape-system` demo scene by fixing `node_searcher_mask` layer.
- Fixed `SublayersModel::remove` - it was not clearing the `layer_placement` hashmap.
- Implemented disabling the wheel scrolling in `Navigator`, and refactored it to reduce the number of functions arguments by introducing a `NavigatorSettings` struct.
Video (`scroll_area` demo):
https://user-images.githubusercontent.com/6566674/164506455-e177a7a7-9f1c-4f50-888f-112423cebbe4.mp4
# Important Notes
- `InstanceWithAttachedLayer` is implemented in such a way that it allows an extension in the future - namely to use it to simplify text rendering. The implementation might be simplified though.
Implements https://www.pivotaltracker.com/story/show/181266184
### Important Notes
Changed example image download to only proceed if the file did not exist before - thus cutting on the build time (the build used to download it _every_ time - which completely failed the build if network is down). A redownload can be forced by performing a fresh repository checkout.
Changelog:
- fix: `search/completion` request with the position parameter.
- fix: `refactoring/renameProject` request. Previously it did not take into account the library namespace (e.g. `local.`)
See: [#181837344](https://www.pivotaltracker.com/story/show/181837344).
I've separated this PR from some deeper changes I'm making to the profile format, because the changeset was getting too complex. The new APIs and tools in this PR are fully-implemented, except the profile format is too simplistic--it doesn't currently support headers that are needed to determine the relative timings of events from different processes.
- Adds basic support for profile files containing data collected by multiple processes.
- Implements `api_events_to_profile`, a tool for converting backend message logs (#3392) to the `profiler` format so they can be merged with frontend profiles (currently they can be merged with `cat`, but the next PR will introduce a merge tool).
- Introduces `message_beanpoles`, a simple tool that diagrams timing relationships between frontend and backend messages.
### Important Notes
- All TODOs introduced here will be addressed in the next PR that defines the new format.
- Introduced a new crate, `enso_profiler_enso_data`, to be used by profile consumers that need to refer to Enso application datatypes to interpret metadata.
- Introduced a `ProfileBuilder` abstraction for writing the JSON profile format; partially decouples the runtime event log structures from the format definition.
- Introducing the conversion performed for `ProfilerBuilder` uncovered that the `.._with_same_start!` low-level `profiler` APIs don't currently work; they return `Started<_>` profilers, but that is inconsistent with the stricter data model that I introduced when I implemented `profiler_data`; they need to return profilers in a created, unstarted state. Low-level async profilers have not been a priority, but once #3382 merges we'll have a way to render their data, which will be really useful because async profilers capture *why* we're doing things. I'll bring up scheduling this in the next performance meeting.
[ci no changelog needed]
# Important Notes
The REPL used to use some builtin Java text representation leading to outputs like this:
```
> [1,2,3]
>>> Vector [1, 2, 3]
> 'a,b,c'.split ','
>>> Vector JavaObject[[Ljava.lang.String;@131c0b6f (java.lang.String[])]
```
This PR makes it use `to_text` (if available, otherwise falling back to regular `toString`). This way we get outputs like this:
```
> [1,2,3]
>>> [1, 2, 3]
> 'a,b,c'.split ','
>>> ['a', 'b', 'c']
```
Add logging of EnsoGL performance stats to the profiling framework. Also extends the visualization in the debug scene to show an overview of the performance stats. We now render a timeline of blocks that indicate by their colour the rough FPS range we are in:
https://user-images.githubusercontent.com/1428930/162433094-57fbb61a-b502-43bb-8815-b7fc992d3862.mp4
# Important Notes
[ci no changelog needed]
Needs to be merged after https://github.com/enso-org/enso/pull/3382 as it requires some changes about metadata logging from there. That is why this PR is currently still in draft mode and based on that branch.
- Added Encoding type
- Added `Text.bytes`, `Text.from_bytes` with Encoding support
- Renamed `File.read` to `File.read_text`
- Renamed `File.write` to `File.write_text`
- Added Encoding support to `File.read_text` and `File.write_text`
- Added warnings to invalid encodings
Result of automatic formatting with `scalafmtAll` and `javafmtAll`.
Prerequisite for https://github.com/enso-org/enso/pull/3394
### Important Notes
This touches a lot of files and might conflict with existing PRs that are in progress. If that's the case, just run
`scalafmtAll` and `javafmtAll` after merge and everything should be in order since formatters should be deterministic.
Changelog:
- add: component groups to package descriptions
- add: `executionContext/getComponentGroups` method that returns component groups of libraries that are currently loaded
- doc: cleanup unimplemented undo/redo commands
- refactor: internal component groups datatype
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}