* OpenFileCmd sends a reply when finished
Lack of reply and therefore a non-determinism on when OpenFile handler
can finish, led to some sporadic instability. Once caches format got
changed, things were taking such a long time that I wasn't able to start
even a basic project (requests would start to timeout).
The change also removes PushContextCmd from synchronous cmds (as
introduced in #798 to remove initialization problems in tests as well as
in real scenarions); the change did the job but was also a bit
controversial.
The change can also help with randomly failing applies (#8174) as IDE kept
closing and opening the project that might have exploited the
race-condition.
* Adapt tests
* Make tests more resilient to out of order messages
* Drop retries that lead to confusing errors
* less random failures
* s/OpenFileNotification/OpenFileRequest
Using a `TruffleLogger` in `SerializationManager` that is bound to the engine rather than the context prevents reaching an illegal state when using thread pools.
Also cleaned up some tests for consistency.
To verify the fix
```diff
--- a/engine/runtime/src/main/scala/org/enso/compiler/SerializationManager.scala
+++ b/engine/runtime/src/main/scala/org/enso/compiler/SerializationManager.scala
@@ -31,7 +31,7 @@ final class SerializationManager(compiler: Compiler) {
import SerializationManager._
/** The debug logging level. */
- private val debugLogLevel = Level.FINE
+ private val debugLogLevel = Level.INFO
```
and run
`sbt:enso> runtime/test`
Closes#8147.
close#8033
Changelog:
- update: run language server initialization once
- fix: issues with async `getSuggestionDatabase` message handling in new IDE
- update: implement unique background jobs
- refactor: initialization logic to Java
- refactor: `UniqueJob` to a marker interface
- Validate spans during existing lexer and parser unit tests, and in `enso_parser_debug`.
- Fix lost span info causing failures of updated tests.
# Important Notes
- [x] Output of `parse_all_enso_files.sh` is unchanged since before #7881 (modulo libs changes since then).
- When the parser encounters an input with the first line indented, it now creates a sub-block for lines at than indent level, and emits a syntax error (every indented block must have a parent).
- When the parser encounters a number with a base but no digits (e.g. `0x`), it now emits a `Number` with `None` in the digits field rather than a 0-length digits token.
* Reduce extra output in compilation and tests
I couldn't stand the amount of extra output that we got when compiling
a clean project and when executing regular tests. We should strive to
keep output clean and not print anything additional to stdout/stderr.
* Getting rid of explicit setup by service loading
In order for SL4J to use service loading correctly had to upgrade to
latest slf4j. Unfortunately `TestLogProvider` which essentially
delegates to `logback` provider will lead to spurious ambiguous warnings
on multiple providers. In order to dictate which one to use and
therefore eliminate the warnings we can use the `slf4j.provider` env
var, which is only available in slf4j 2.x.
Now, there is no need to explicitly call `LoggerSetup.get().setup()` as
that is being called during service setup.
* legal review
* linter
* Ensure ConsoleHandler uses the default level
ConsoleHandler's constructor uses `Level.INFO` which is unnecessary for
tests.
* report warnings
- Previous GraalVM update: https://github.com/enso-org/enso/pull/6750
Removed warnings:
- Remove deprecated `ConditionProfile.createCountingProfile()`.
- Add `@Shared` to some `@Cached` parameters (Truffle now emits warnings about potential `@Share` usage).
- Specialization method names should not start with execute
- Add limit attribute to some specialization methods
- Add `@NeverDefault` for some cached initializer expressions
- Add `@Idempotent` or `@NonIdempotent` where appropriate
BigInteger and potential Node inlining are tracked in follow-up issues.
# Important Notes
For `SDKMan` users:
```
sdk install java 17.0.7-graalce
sdk use java 17.0.7-graalce
```
For other users - download link can be found at https://github.com/graalvm/graalvm-ce-builds/releases/tag/jdk-17.0.7
Release notes: https://www.graalvm.org/release-notes/JDK_17/
R component was dropped from the release 23.0.0, only `python` is available to install via `gu install python`.
`executionFailed` instead is sent when an evaulation finishes with a a critical failure or a non-critical error.
The PR tries to miniminally modify the change in the messages exchange so as to avoid a major redesign at this point.
Closes#7002.
# Important Notes
Unblocks IDE which will need to modify to this new setup.
Fixes#6955 by:
- using `visualisationModule` to specify the module where the visualization is to be used
- referring to method in `Meta.get_annotation` with `.method_name` - e.g. unresolved symbol notation
- evaluating arguments to `Meta.get_annotation` in the context of the user module (which can access the extension functions)
Request Timeouts started plaguing IDE due to numerous `executionContext/***Visualization` requests. While caused by a bug they revealed a bigger problem in the Language Server when serving large amounts of requests:
1) Long and short lived jobs are fighting for various locks. Lock contention leads to some jobs waiting for a longer than desired leading to unexpected request timeouts. Increasing timeout value is just delaying the problem.
2) Requests coming from IDE are served almost instantly and handled by various commands. Commands can issue further jobs that serve request. We apparently have and always had a single-thread thread pool for serving such jobs, leading to immediate thread starvation.
Both reasons increase the chances of Request Timeouts when dealing with a large number of requests. For 2) I noticed that while we used to set the `enso-runtime-server.jobParallelism` option descriptor key to some machine-dependent value (most likely > 1), the value set would **only** be available for instrumentation. `JobExecutionEngine` where it is actually used would always get the default, i.e. a single-threaded ThreadPool. This means that this option descriptor was simply misused since its introduction. Moved that option to runtime options so that it can be set and retrieved during normal operation.
Adding parallelism intensified problem 1), because now we could execute multiple jobs and they would compete for resources. It also revealed a scenario for a yet another deadlock scenario, due to invalid order of lock acquisition. See `ExecuteJob` vs `UpsertVisualisationJob` order for details.
Still, a number of requests would continue to randomly timeout due to lock contention. It became apparent that
`Attach/Modify/Detach-VisualisationCmd` should not wait until a triggered `UpsertVisualisationJob` sends a response to the client; long and short lived jobs will always compete for resources and we cannot guarantee that they will not timeout that way. That is why the response is sent immediately from the command handler and not from the job executed after it.
This brings another problematic scenario:
1. `AttachVisualisationCmd` is executed, response sent to the client, `UpsertVisualisationJob` scheduled.
2. In the meantime `ModifyVisualisationCmd` comes and fails; command cannot find the visualization that will only be added by `UpsertVisualisationJob`, which might have not yet been scheduled to run.
Remedied that by checking visualisation-related jobs that are still in progress. It also allowed for cancelling jobs which results wouldn't be used anyway (`ModifyVisualisationCmd` sends its own `UpsertVisualisationJob`). This is not a theoretical scenario, it happened frequently on IDE startup.
This change does not fully solve the rather problematic setup of numerous locks, which are requested by short and long lived jobs. A better design should still be investigated. But it significantly reduces the chances of Request Timeouts which IDE had to deal with.
With this change I haven't been able to experience Request Timeouts for relatively modest projects anymore.
I added the possibility of logging wait times for locks to better investigate further problems.
Closes#7005
close#6800
Update the `executionContext/expressionUpdates` notification and send the list of not applied arguments in addition to the method pointer.
# Important Notes
IDE is updated to support the new API.
The change adds an additional field to `ExpressionUpdates` messages sent by `ProgramExecutionSupport` to indicate if the type of value (or its method pointer) has changed and therefore would potentially require a suggestions' update.
Prior to #3729 that check was done during the instrumentation. However we still want to continue to support "pending expression" functionality therefore `SuggestionsHandler` will use the additional information to filter only the required expression updates.
Most of the changes are related to adapting our tests to the new field.
Closes#6706.
# Important Notes
The associated project now loads and navigates smoothly.
Also attaching a screenshot from the project that illustrates that pending functionality continues to work:
[Kazam_screencast_00006.webm](https://github.com/enso-org/enso/assets/292128/35918841-f84f-4e1c-b1b0-40e45d97e111)
Artifically limiting the number of reported warnings to 100. Also added benchmarks with random Ints to investigate perf issues when dealing with warnings (future task).
Ideally we would have a custom set-like collection that allows us internally to specify a maximal number of elements. But `EnsoHashMap` (and potentially `EnsoSet`) are still WIP when it comes to being PE-friendly.
The change also allows for checking if the limit for the number of reported warnings has been reached. It will visualize by adding an additional "Warnings limit reached." to the visualization.
The limit is configurable via `--warnings-limit` parameter to `run`.
Closes#6283.
close#6324
Changelog
- feat: DataflowAnalysis compiler pass preserves the order of dependencies. This way when attaching the visualization to the sub-expression, the engine can find the first cached parent node, and properly invalidate it.
- update: runtime visualization test is updated to reproduce the issue
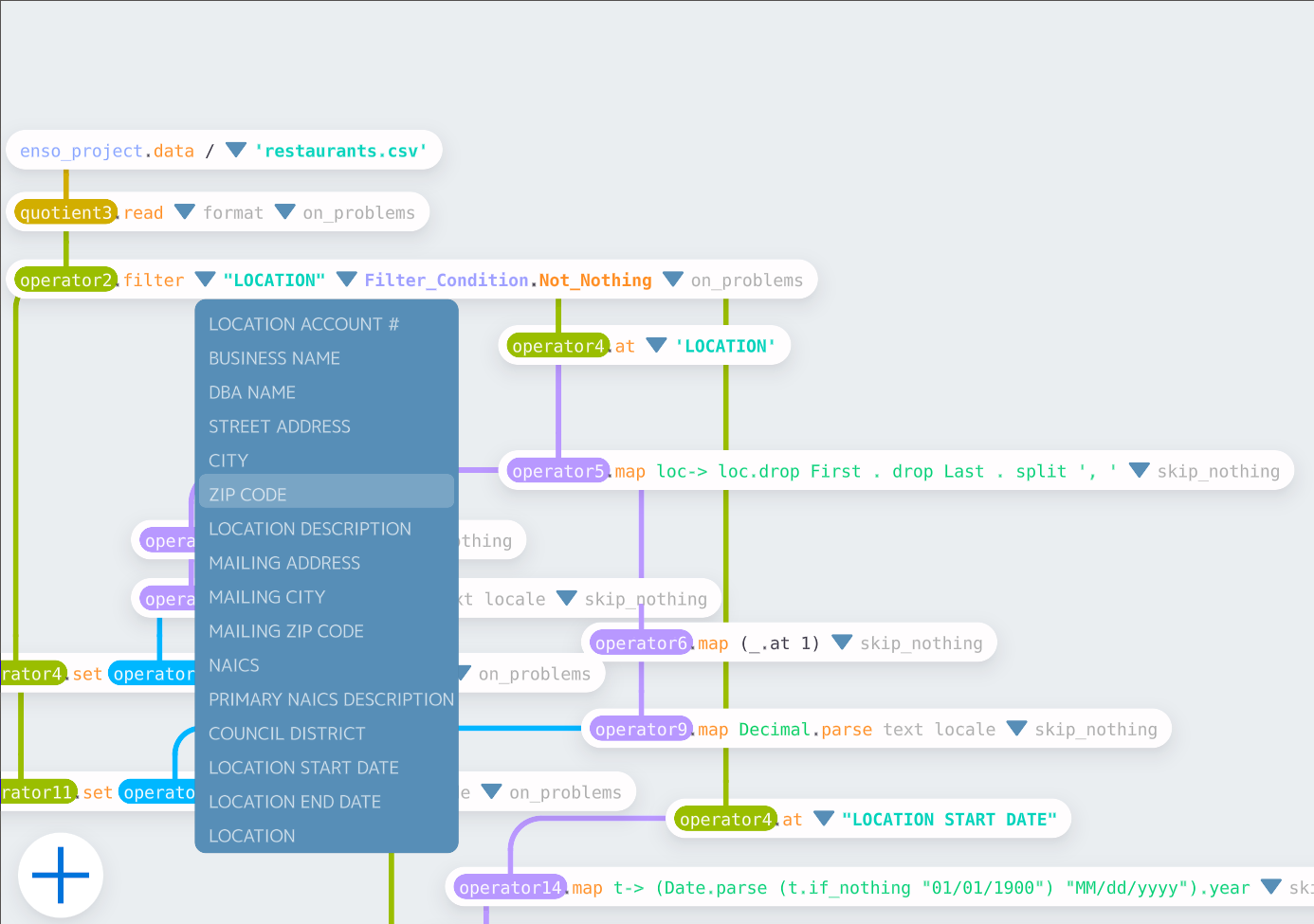
# Important Notes
The dropdown for the column `"LOCATION"` is available right after the Restaurants project startup.
This change modifies method dispatch for methods that override Any's definitions. When an overrided method is invoked statically we call Any's method to stay consistent.
This change primarily addresses the plethora of problems related to `to_text` invocations. It does not attempt to completely modify method dispatch logic.
Closes#6300.
- Missing tests from number parsing.
- Fix type signature on some warning methods.
- Fix warnings on `Standard.Database.Data.Table.parse_values`.
- Added test for `Nothing` and empty string on `use_first_row_as_names`.
- New API for `Number.format` taking a simple format string and `Locale`.
- Add ellipsis to truncated `Text.to_display_text`.
- Adjusted built-in `to_display_text` for numbers to not include type (but also to display BigInteger as value).
- Remove `Noise.Generator` interface type.
- Json: Added `to_display_text` to `JS_Object`.
- Time: Added `to_display_text` for `Date`, `Time_Of_Day`, `Date_Time`, `Duration` and `Period`.
- Text: Added `to_display_text` to `Locale`, `Case_Sensitivity`, `Encoding`, `Text_Sub_Range`, `Span`, `Utf_16_Span`.
- System: Added `to_display_text` to `File`, `File_Permissions`, `Process_Result` and `Exit_Code`.
- Network: Added `to_display_text` to `URI`, `HTTP_Status_Code` and `Header`.
- Added `to_display_text` to `Maybe`, `Regression`, `Pair`, `Range`, `Filter_Condition`.
- Added support for `to_js_object` and `to_display_text` to `Random_Number_Generator`.
- Verified all error types have `to_display_text`.
- Removed `BigInt`, `Date`, `Date_Time` and `Time_Of_Day` JS based rendering as using `to_display_text` now.
- Added support for rendering nested structures in the table viz.
close#5892
Changelog:
add: feature to delay background jobs execution
add: start background jobs when program finishes
add: start background jobs on `search/completion` request
Creating two `findExceptionMessage` methods in `HostEnsoUtils` and in `VisualizationResult`. Why two? Because one of them is using `org.graalvm.polyglot` SDK as it runs in _"normal Java"_ mode. The other one is using Truffle API as it is running inside of partially evaluated instrument.
There is a `FindExceptionMessageTest` to guarantee consistency between the two methods. It simulates some exceptions in Enso code and checks that both methods extract the same _"message"_ from the exception. The tests verifies hosted and well as Enso exceptions - however testing other polyglot languages is only possible in other modules - as such I created `PolyglotFindExceptionMessageTest` - but that one doesn't have access to Truffle API - e.g. it doesn't really check the consistency - just that a reasonable message is extracted from a JavaScript exception.
# Important Notes
This is not full fix of #5260 - something needs to be done on the IDE side, as the IDE seems to ignore the delivered JSON message - even if it contains properly extracted exception message.
Implements the #5643 idea. As soon as `MainModule` creates `Context` for GraalVM execution, it schedules a background task to initialize JavaScript. The initialization finishes sooner than Enso compiler is ready to work, saving time when it is actually needed.
# Important Notes
Only modifies boot sequence of `MainModule` (used in the IDE) and `VerifyJavaScriptIsAvailableTest` (to verify the _"context passing logic"_ works OK between threads). Regular CLI execution remains unchanged for now assuming batch execution may not need JavaScript in all the cases and if it does the initialization speed isn't that critical.
Add `Comparator` type class emulation for all types. Migrate all the types in stdlib to this new `Comparator` API. The main documentation is in `Ordering.enso`.
Fixes these pivotals:
- https://www.pivotaltracker.com/story/show/183945328
- https://www.pivotaltracker.com/story/show/183958734
- https://www.pivotaltracker.com/story/show/184380208
# Important Notes
- The new Comparator API forces users to specify both `equals` and `hash` methods on their custom comparators.
- All the `compare_to` overrides were replaced by definition of a custom _ordered_ comparator.
- All the call sites of `x.compare_to y` method were replaced with `Ordering.compare x y`.
- `Ordering.compare` is essentially a shortcut for `Comparable.from x . compare x y`.
- The default comparator for `Any` is `Default_Unordered_Comparator`, which just forwards to the builtin `EqualsNode` and `HashCodeNode` nodes.
- For `x`, one can get its hash with `Comparable.from x . hash x`.
- This makes `hash` as _hidden_ as possible. There are no other public methods to get a hash code of an object.
- Comparing `x` and `y` can be done either by `Ordering.compare x y` or `Comparable.from x . compare x y` instead of `x.compare_to y`.
Expressions returning polyglot values were not reporting the type of the result because we have to do additional magic that infers the correct Enso type. Since this is exactly what `TypeOfNode` does, I re-used the logic.
Straightforward solution failed in tests because of assertions:
```
[enso] WARNING: Execution of function main failed (Invalid library usage. Cached library must be adopted by a RootNode before it is executed.).
java.lang.AssertionError: Invalid library usage. Cached library must be adopted by a RootNode before it is executed.
```
That is why this PR replaces `ExecutionEventListener` with `ExecutionEventNodeFactory`.
# Important Notes
Usage of `TypeOfNode` for programs that **do not** import stdlib means that we report types that do not involve stdlib e.g.
`Standard.Builtins.Main.Integer` instead of `Standard.Base.Data.Numbers.Integer`. While surprising, this is correct and I would say desirable. While reviewing the code, notice the difference in expectations in our runtime tests.
LS needs to notify runtime that modules' sources need to be reloaded from FS, once its own buffer has been reloaded as well.
# Important Notes
Discovered during integration of https://github.com/enso-org/enso/pull/4050.
The test illustrates the problem if we don't reload module's sources - the sources essentially become stale even though they have changed.
When the function is visualized with the `default_preprocessor` method, it returns a dataflow error that shows up in the logs as
```
Cannot encode class org.enso.interpreter.runtime.error.DataflowError to byte array.
```
PR handles dataflow errors in the preprocessor and fallbacks the `to_display_text` value. As a bonus, we get a function visualization.
Use `InteropLibrary.isString` and `asString` to convert any string value to `byte[]`
# Important Notes
Also contains a support for `Metadata.assertInCode` to help locating the right place in the code snippets.
`runtime-with-instruments` project sets `-Dgraalvm.locatorDisabled=true` that disables the discovery of available polyglot languages (installed with `gu`). On the other hand, enabling locator makes polyglot languages available, but also makes the program classes and the test classes loaded with different classloaders. This way we're unable to use `EnsoContext` in tests to observe internal context state (there is an exception when you try to cast to `EnsoContext`).
The solution is to move tests with enabled polyglot support, but disabled `EnsoContext` introspection to a separate project.
{kind=link}