PR allows to attach metod pointers as a visualization expressions. This way it allows to attach a runtime instrument that enables caching of intermediate expressions.
# Important Notes
ℹ️ API is backward compatible.
To attach the visualization with caching support, the same `executionContext/attachVisualisation` method is used, but `VisualisationConfig` message should contain the message pointer.
While `VisualisationConfiguration` message has changed, the language server accepts both new and old formats to keep visualisations working in IDE.
#### Old format
```json
{
"executionContextId": "UUID",
"visualisationModule": "local.Unnamed.Main",
"expression": "x -> x.to_text"
}
```
#### New format
```json
{
"executionContextId": "UUID",
"expression": {
"module": "local.Unnamed.Main",
"definedOnType": "local.Unnamed.Main",
"name": "encode"
}
}
```
Show custom icons in Component Browser for entries that have a non-empty `Icon` section in their docs with the section's body containing a name of a predefined icon.
https://www.pivotaltracker.com/story/show/182584336
#### Visuals
A screenshot of a couple custom icons in the Component Browser:
<img width="346" alt="Screenshot 2022-07-27 at 15 55 33" src="https://user-images.githubusercontent.com/273837/181265249-d57f861f-8095-4933-9ef6-e62644e11da3.png">
# Important Notes
- The PR assigns icon names to four items in the standard library, but only three of them are shown in the Component Browser because of [a parsing bug in the Engine](https://www.pivotaltracker.com/story/show/182781673).
- Icon names are assigned only to four items in the standard library because only two currently predefined icons match entries in the currently defined Virtual Component Groups. Adjusting the definitions of icons and Virtual Component Groups is covered by [a different task](https://www.pivotaltracker.com/story/show/182584311).
- A bug in the documentation of the Enso protocol message `DocSection` is fixed. A `text` field in the `Tag` interface is renamed to `body` (this is the field name used in Engine).
This change allows for importing modules using a qualified name and deals with any conflicts on the way.
Given a module C defined at `A/B/C.enso` with
```
type C
type C a
```
it is now possible to import it as
```
import project.A
...
val x = A.B.C 10
```
Given a module located at `A/B/C/D.enso`, we will generate
intermediate, synthetic, modules that only import and export the successor module along the path.
For example, the contents of a synthetic module B will look like
```
import <namespace>.<pkg-name>.A.B.C
export <namespace>.<pkg-name>.A.B.C
```
If module B is defined already by the developer, the compiler will _inject_ the above statements to the IR.
Also removed the last elements of some lowercase name resolution that managed to survive recent
changes (`Meta.Enso_Project` would now be ambiguous with `enso_project` method).
Finally, added a pass that detects shadowing of the synthetic module by the type defined along the path.
We print a warning in such a situation.
Related to https://www.pivotaltracker.com/n/projects/2539304
# Important Notes
There was an additional request to fix the annoying problem with `from` imports that would always bring
the module into the scope. The changes in stdlib demonstrate how it is now possible to avoid the workaround of
```
from X.Y.Z as Z_Module import A, B
```
(i.e. `as Z_Module` part is almost always unnecessary).
Modified UppercaseNames to now resolve methods without an explicit `here` to point to the current module.
`here` was also often used instead of `self` which was allowed by the compiler.
Therefore UppercaseNames pass is now GlobalNames and does some extra work -
it translated method calls without an explicit target into proper applications.
# Important Notes
There was a long-standing bug in scopes usage when compiling standalone expressions.
This resulted in AliasAnalysis generating incorrect graphs and manifested itself only in unit tests
and when running `eval`, thus being a bit hard to locate.
See `runExpression` for details.
Additionally, method name resolution is now case-sensitive.
Obsolete passes like UndefinedVariables and ModuleThisToHere were removed. All tests have been adapted.
This PR adds sources for Enso language support in IGV (and NetBeans). The support is based on TextMate grammar shown in the editor and registration of the Enso language so IGV can find it. Then this PR adds new GitHub Actions workflow file to build the project using Maven.
Changelog:
- Describe the `EditKind` optional parameter that allows enabling engine-side optimizations, like value updates
- Describe the `text/openBuffer` message required for the lazy visualizations feature
New plan to [fix the `sbt` build](https://www.pivotaltracker.com/n/projects/2539304/stories/182209126) and its annoying:
```
log.error(
"Truffle Instrumentation is not up to date, " +
"which will lead to runtime errors\n" +
"Fixes have been applied to ensure consistent Instrumentation state, " +
"but compilation has to be triggered again.\n" +
"Please re-run the previous command.\n" +
"(If this for some reason fails, " +
s"please do a clean build of the $projectName project)"
)
```
When it is hard to fix `sbt` incremental compilation, let's restructure our project sources so that each `@TruffleInstrument` and `@TruffleLanguage` registration is in individual compilation unit. Each such unit is either going to be compiled or not going to be compiled as a batch - that will eliminate the `sbt` incremental compilation issues without addressing them in `sbt` itself.
fa2cf6a33ec4a5b2e3370e1b22c2b5f712286a75 is the first step - it introduces `IdExecutionService` and moves all the `IdExecutionInstrument` API up to that interface. The rest of the `runtime` project then depends only on `IdExecutionService`. Such refactoring allows us to move the `IdExecutionInstrument` out of `runtime` project into independent compilation unit.
* The bash entry point was renamed `run.sh` -> `run`. Thanks to that `./run` works both on Linux and Windows with PowerShell (sadly not on CMD).
* Everyone's favorite checks for WASM size and program versions are back. These can be disabled through `--wasm-size-limit=0` and `--skip-version-check` respectively. WASM size limit is stored in `build-config.yaml`.
* Improved diagnostics for case when downloaded CI run artifact archive cannot be extracted.
* Added GH API authentication to the build script calls on CI. This should fix the macOS build failures that were occurring from time to time. (Actually they were due to runner being GitHub-hosted, not really an OS-specific issue by itself.)
* If the GH API Personal Access Token is provided, it will be validated. Later on it is difficult to say, whether fail was caused by wrong PAT or other issue.
* Renamed `clean` to `git-clean` as per suggestion to reduce risk of user accidently deleting unstaged work.
* Whitelisting dependabot from changelog checks, so PRs created by it are mergeable.
* Fixing issue where wasm-pack-action (third party) randomly failed to recognize the latest version of wasm-pack (macOS runners), leading to failed builds.
* Build logs can be filtered using `ENSO_BUILD_LOG` environment variable. See https://docs.rs/tracing-subscriber/0.3.11/tracing_subscriber/struct.EnvFilter.html#directives for the supported syntax.
* Improve help for ci-run source, to make clear that PAT token is required and what scope is expected there.
Also, JS parts were updated with some cleanups and fixes following the changes made when introducing the build script.
Promoted `with`, `take`, `finalize` to be methods of Managed_Resource
rather than static methods always taking `resource`, for consistency
reasons.
This required function dispatch boilerplate, similarly to `Ref`.
In future iterations we will address this boilerplate code.
Related to https://www.pivotaltracker.com/story/show/182212217
Finally this pull request proposes `--inspect` option to allow [debugging of `.enso`](e948f2535f/docs/debugger/README.md) in Chrome Developer Tools:
```bash
enso$ ./built-distribution/enso-engine-0.0.0-dev-linux-amd64/enso-0.0.0-dev/bin/enso --inspect --run ./test/Tests/src/Data/Numbers_Spec.enso
Debugger listening on ws://127.0.0.1:9229/Wugyrg9Nm4OUL9YhzdcElmLft71ayZW3LMUPCdPyNAY
For help, see: https://www.graalvm.org/tools/chrome-debugger
E.g. in Chrome open: devtools://devtools/bundled/js_app.html?ws=127.0.0.1:9229/Wugyrg9Nm4OUL9YhzdcElmLft71ayZW3LMUPCdPyNAY
```
copy the printed URL into chrome browser and you should see:
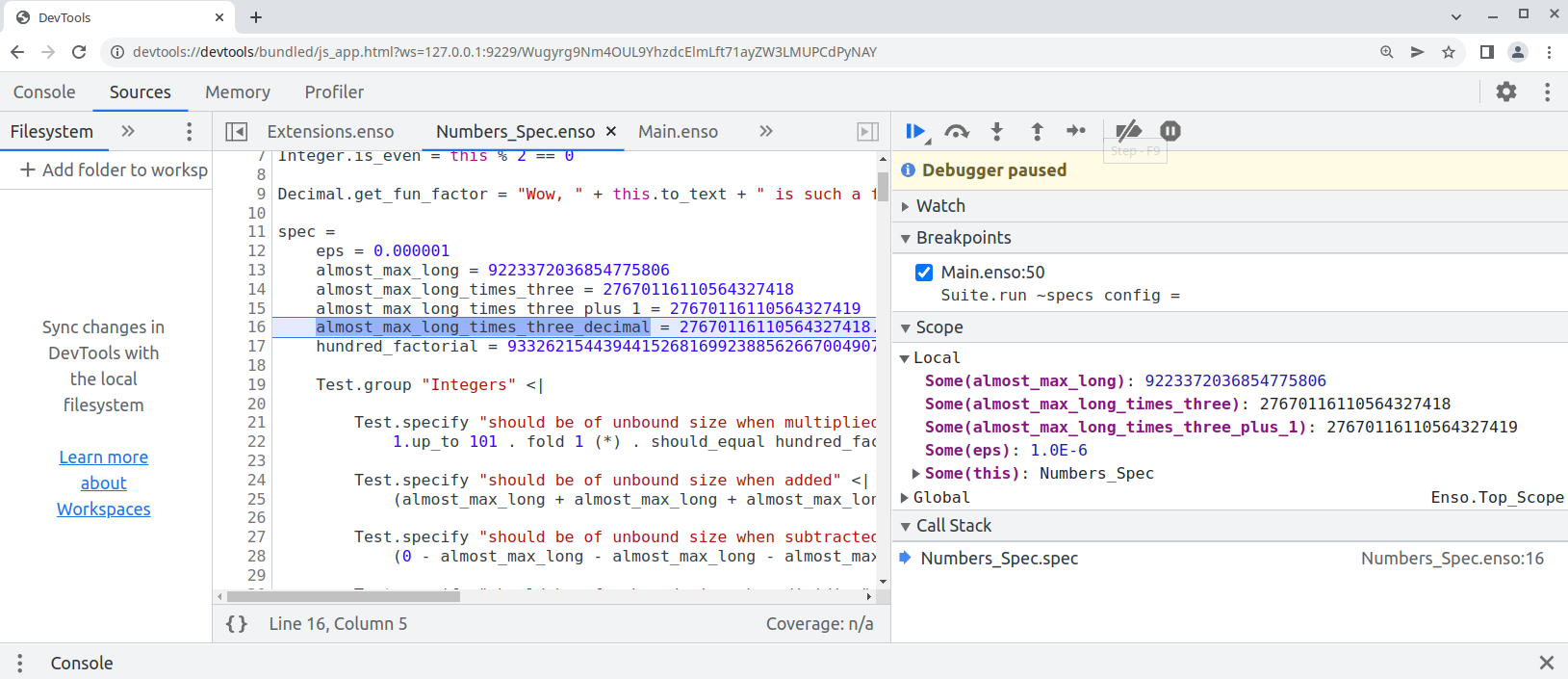
One can also debug the `.enso` files in NetBeans or [VS Code with Apache Language Server extension](https://cwiki.apache.org/confluence/display/NETBEANS/Apache+NetBeans+Extension+for+Visual+Studio+Code) just pass in special JVM arguments:
```bash
enso$ JAVA_OPTS=-agentlib:jdwp=transport=dt_socket,server=y,address=8000 ./built-distribution/enso-engine-0.0.0-dev-linux-amd64/enso-0.0.0-dev/bin/enso --run ./test/Tests/src/Data/Numbers_Spec.enso
Listening for transport dt_socket at address: 8000
```
and then _Debug/Attach Debugger_. Once connected choose the _Toggle Pause in GraalVM Script_ button in the toolbar (the "G" button):
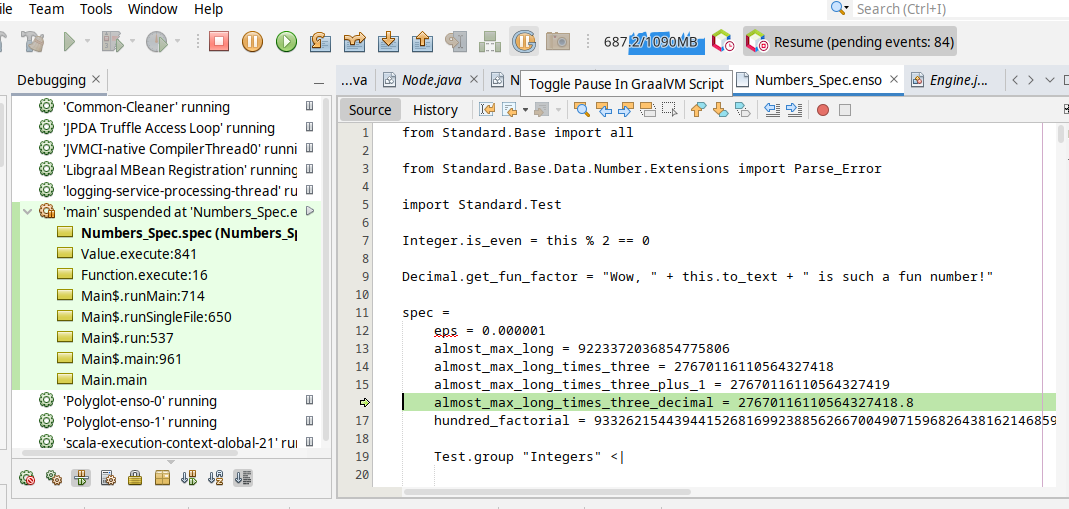
and your execution shall stop on the next `.enso` line of code. This mode allows to debug both - the Enso code as well as Java code.
Originally started as an attempt to write test in Java:
* test written in Java
* support for JUnit in `build.sbt`
* compile Java with `-g` - so it can be debugged
* Implementation of `StatementNode` - only gets created when `materialize` request gets to `BlockNode`
This PR replaces hard-coded `@Builtin_Method` and `@Builtin_Type` nodes in Builtins with an automated solution
that a) collects metadata from such annotations b) generates `BuiltinTypes` c) registers builtin methods with corresponding
constructors.
The main differences are:
1) The owner of the builtin method does not necessarily have to be a builtin type
2) You can now mix regular methods and builtin ones in stdlib
3) No need to keep track of builtin methods and types in various places and register them by hand (a source of many typos or omissions as it found during the process of this PR)
Related to #181497846
Benchmarks also execute within the margin of error.
### Important Notes
The PR got a bit large over time as I was moving various builtin types and finding various corner cases.
Most of the changes however are rather simple c&p from Builtins.enso to the corresponding stdlib module.
Here is the list of the most crucial updates:
- `engine/runtime/src/main/java/org/enso/interpreter/runtime/builtin/Builtins.java` - the core of the changes. We no longer register individual builtin constructors and their methods by hand. Instead, the information about those is read from 2 metadata files generated by annotation processors. When the builtin method is encountered in stdlib, we do not ignore the method. Instead we lookup it up in the list of registered functions (see `getBuiltinFunction` and `IrToTruffle`)
- `engine/runtime/src/main/java/org/enso/interpreter/runtime/callable/atom/AtomConstructor.java` has now information whether it corresponds to the builtin type or not.
- `engine/runtime/src/main/scala/org/enso/compiler/codegen/RuntimeStubsGenerator.scala` - when runtime stubs generator encounters a builtin type, based on the @Builtin_Type annotation, it looks up an existing constructor for it and registers it in the provided scope, rather than creating a new one. The scope of the constructor is also changed to the one coming from stdlib, while ensuring that synthetic methods (for fields) also get assigned correctly
- `engine/runtime/src/main/scala/org/enso/compiler/codegen/IrToTruffle.scala` - when a builtin method is encountered in stdlib we don't generate a new function node for it, instead we look it up in the list of registered builtin methods. Note that Integer and Number present a bit of a challenge because they list a whole bunch of methods that don't have a corresponding method (instead delegating to small/big integer implementations).
During the translation new atom constructors get initialized but we don't want to do it for builtins which have gone through the process earlier, hence the exception
- `lib/scala/interpreter-dsl/src/main/java/org/enso/interpreter/dsl/MethodProcessor.java` - @Builtin_Method processor not only generates the actual code fpr nodes but also collects and writes the info about them (name, class, params) to a metadata file that is read during builtins initialization
- `lib/scala/interpreter-dsl/src/main/java/org/enso/interpreter/dsl/MethodProcessor.java` - @Builtin_Method processor no longer generates only (root) nodes but also collects and writes the info about them (name, class, params) to a metadata file that is read during builtins initialization
- `lib/scala/interpreter-dsl/src/main/java/org/enso/interpreter/dsl/TypeProcessor.java` - Similar to MethodProcessor but handles @Builtin_Type annotations. It doesn't, **yet**, generate any builtin objects. It also collects the names, as present in stdlib, if any, so that we can generate the names automatically (see generated `types/ConstantsGen.java`)
- `engine/runtime/src/main/java/org/enso/interpreter/node/expression/builtin` - various classes annotated with @BuiltinType to ensure that the atom constructor is always properly registered for the builitn. Note that in order to support types fields in those, annotation takes optional `params` parameter (comma separated).
- `engine/runtime/src/bench/scala/org/enso/interpreter/bench/fixtures/semantic/AtomFixtures.scala` - drop manual creation of test list which seemed to be a relict of the old design
Changelog:
- add: component groups to package descriptions
- add: `executionContext/getComponentGroups` method that returns component groups of libraries that are currently loaded
- doc: cleanup unimplemented undo/redo commands
- refactor: internal component groups datatype
Implements infrastructure for new aggregations in the Database. It comes with only some basic aggregations and limited error-handling. More aggregations and problem handling will be added in subsequent PRs.
# Important Notes
This introduces basic aggregations using our existing codegen and sets-up our testing infrastructure to be able to use the same aggregate tests as in-memory backend for the database backends.
Many aggregations are not yet implemented - they will be added in subsequent tasks.
There are some TODOs left - they will be addressed in the next tasks.
Changelog:
- feat: during the boot, prune outdated modules
from the suggestions database
- feat: when renaming the project, send updates
about changed records in the database
- refactor: remove deprecated
executionContext/expressionValuesComputed
notification
PR adds the new executionContext/expressionUpdates
API that replaces executionContext/expressionValueUpdates
notification, and in the future will be extended to support
the dataflow errors.
Related to #1153, implements the first part of the integration, without the
parts that use the runner which will be done next.
Temporarily there are two logger implementations - this will be alleviated with
the next part - when and the direct classpath dependency on the language server
is removed.
A bunch of improvements to the suggestions
system. Suggestions are extracted to the tree data
structure. The tree allows producing better diffs
between the file versions. And better diffs reduce
the number of updates that are sent to the IDE
after a file change, and consequently fix the
issue when the runtime type got overwritten with
the compile-time type.
Add new `executionContext/executionStatus`
notification returning a list of diagnostic
messages containing localized (linked to the
location in the code) information about
compilation errors and warnings, as well as
runtime errors with stack traces.
Names of fields `author` and `maintainer` in the `package.yaml` file
have been changed to `authors` and `maintainers` respectively, and their
format has been modified.
Projects created in older versions may not be compatible.
In the current workflow, at first, the default Unnamed project is
created, and the Suggestions database is populated with entries from the
Unnamed.* modules. When the user changes the name of the project, we
should update all modules in the Suggestion Database with the new
project name.
This PR implements module renaming in the Suggestions database and fixes
the initialization issues.
- add: search/invalidateSuggestionsDatabase JSON-RPC command that resets
the corrupted Suggestions database
- update: SuggestionsHandler to rename the modules in the
SuggestionsDatabase when the project is renamed
- fix: MainModule initialization
ExpressionValueUpdate notification contains information about the
executed object. To have the full information about this object, IDE
needs the id of the corresponding suggestion. PR updates the
notification adding the suggestion id of the executed object.
- update: public API for ExpressionValueUpdate notification
- update: ContextEventsListener groups ExpressionValueUpdates and sends
them in a batch
- update: ContextRegistry listens to the notifications from runtime and
routes them to the corresponding listener.
- test: add ContextEventsListenerSpec
1. Implements the `enso install distribution` command.
2. Implements a DistributionManager which is used for managing installation
layout in the launcher.
PR #1034Resolves#1010
1. This commit ensures that builds outside of repository don't file not being
able to fetch the git metadata for the version string but just report a
warning.
2. It also clarifies documentation on getting Enso artifacts from CI.
PR #1036
1. This commit adds an extensive library for parsing commandline
arguments and formatting output.
2. It implements the expected CLI for the launcher.
3. It turns off parallel execution on the CI in hopes of making it
more stable.
4. It implements plugin support in the launcher.
{kind=link}
{kind=link}
{kind=link}