close#6232
Changelog:
- remove: `SqlVersionsRepo`
- update: `SuggestionsDatabaseModuleUpdateNotification` message removing the version
- update: cleanup versions repo usages in the language server
close#6080
Changelog
- add: implement `SuggestionsRepo.insertAll` as a batch SQL insert
- update: `search/getSuggestionsDatabase` returns empty suggestions. Currently, the method is only used at startup and returns the empty response anyway because the libs are not loaded at that point.
- update: serialize only global (defined in the module scope) suggestions during the distribution building. There's no sense in storing the local library suggestions.
- update: sqlite dependency
- remove: unused methods from `SuggestionsRepo`
- remove: Arguments table
# Important Notes
Speeds up libraries loading by ~1 second.


close#5874
Changelog:
- add: `isStatic` parameter to `search/completion` request to search by the `static` suggestion attribute
- update: search non-static suggestions when opening component browser
# Important Notes
Component browser doesn't show `Table.new` and `Table.from_rows` suggestions when a `Table` node is selected.
Some small improvements relating to rendering:
- Add a debug option: `-debug.pixel-read-period`. This can be used to measure the performance impact of checking the pointer location on different hardware. [On my development box, it makes no difference to performance.] (Closes#5490).
- Unbind pixel pack buffers after each use. This is recommended practice. It has no performance impact on my machine, and allows SpectorJS to run (`-debug.enable-spector`). (Closes#5941).
Also, simplify the profiling CLI: the `profile.load-profile` and `profile.save-profile` options have been renamed to `profile.load`/`profile.save`; `profile.save` now has a default filename, so you can capture a profile at any time in Electron with Ctrl+Alt+P and it will be written to `profile.json`.
Implement new Enso documentation parser; remove old Scala Enso parser.
Performance: Total time parsing documentation is now ~2ms.
# Important Notes
- Doc parsing is now done only in the frontend.
- Some engine tests had never been switched to the new parser. We should investigate tests that don't pass after the switch: #5894.
- The option to run the old searcher has been removed, as it is obsolete and was already broken before this (see #5909).
- Some interfaces used only by the old searcher have been removed.
This change downgrades hashing algorithm used in caching IR and library bindings to SHA-1. It is sufficient and significantly faster for the purpose of simple checksum we use it for.
Additionally, don't calculate the digest for serialized bytes - if we get the expected object type then we are confident about the integrity.
Don't initialize Jackson's ObjectMapper for every metadata serialization/de-serialization. Initialization is very costly.
Avoid unnecessary conversions between Scala and Java. Those back-and-forth `asScala` and `asJava` are pretty expensive.
Finally fix an SBT warning when generating library cache.
Closes https://github.com/enso-org/enso/issues/5763
# Important Notes
The change cuts roughly 0.8-1s from the overall startup.
This change will certainly lead to invalidation of existing caches. It is advised to simply start with a clean slate.
This change adds serialization and deserialization of library bindings.
In order to be functional, one needs to first generate IR and
serialize bindings using `--compiled <path-to-library>` command. The bindings
will be stored under the library with `.bindings` suffix.
Bindings are being generated during `buildEngineDistribution` task, thus not
requiring any extra steps.
When resolving import/exports the compiler will first try to load
module's bindings from cache. If successful, it will not schedule its
imports/exports for immediate compilation, as we always did, but use the
bindings info to infer the dependent modules.
The current change does not make any optimizations when it comes to
compiling the modules, yet. It only delays the actual
compilation/loading IR from cache so that it can be done in bulk.
Further optimizations will come from this opportunity such as parallel
loading of caches or lazily inferring only the necessary modules.
Part of https://github.com/enso-org/enso/issues/5568 work.
Older versions of `Powershell (5.x)` do not support running the `run` command, so you need to replace it with a higher version of `Powershell (7.x)` or use `cmd`
Automating the assembly of the engine and its execution into a single task. If you are modifying standard libraries, engine sources or Enso tests, you can launch `sbt` and then just:
```
sbt:enso> runEngineDistribution --run test/Tests/src/Data/Maybe_Spec.enso
[info] Engine package created at built-distribution/enso-engine-0.0.0-dev-linux-amd64/enso-0.0.0-dev
[info] Executing built-distribution/enso-engine-...-dev/bin/enso --run test/Tests/src/Data/Maybe_Spec.enso
Maybe: [5/5, 30ms]
- should have a None variant [14ms]
- should have a Some variant [5ms]
- should provide the `maybe` function [4ms]
- should provide `is_some` [2ms]
- should provide `is_none` [3ms]
5 tests succeeded.
0 tests failed.unEngineDistribution 4s
0 tests skipped.
```
the [runEngineDistribution](3a581f29ee/docs/CONTRIBUTING.md (running-enso)) `sbt` input task makes sure all your sources are properly compiled and only then executes your enso source. Everything ready at a single press of Enter.
# Important Notes
To debug in chrome dev tools, just add `--inspect`:
```
sbt:enso> runEngineDistribution --inspect --run test/Tests/src/Data/Maybe_Spec.enso
E.g. in Chrome open: devtools://devtools/bundled/js_app.html?ws=127.0.0.1:9229/7JsgjXlntK8
```
everything gets build and one can just attach the Enso debugger.
Closes#5036
Move the logic that looks up method pointers from the language server to IDE. This way we can keep the suggestion updates and expression updates async, otherwise it will hurt the initial startup time of LS.
Fixes the issue when some expression updates does not contain the method pointer.
Start `project-manager` with following options to provide first 20s of the startup sequence:
```
$ project-manager --profiling-events-log-path=start.log --profiling-path=start.npss --profiling-time=20
```
once the `start.log` and `start.npss` files are generated (next to each other), open them in GraalVM's VisualVM:
```
$ graalvm/bin/jvisualvm --openfile start.npss
```
analyze.
VCS restore operation was correctly restoring the state of projects to the requested commit. Unfortunately, after the operation file system was becoming out-of-sync with language server's buffers (and IDE's content versions).
A few important changes are introduced here that complicate the interaction between components:
1) `vcs restore` returns an actual diff between the current state and the
requested commit
2) the response is forwarded to buffer registry first rather than to the client
3) the diff is used to identify appropriate collaborative editors and
notify them about the need to reload buffers from file system
4) all clients of affected open buffers are notified of the change via
`text/didChange` notification. If a file was removed and there were open buffers for it, clients will be notified via `file/event` and editor will be stopped
5) only then the client is notified about a successful restore operation
This PR addresses one of the two problems reported in https://www.pivotaltracker.com/story/show/184097084.
# Important Notes
We need to make sure that IDE correctly responds to `text/didChange` notifications.
`Any.==` is a builtin method. The semantics is the same as it used to be, except that we no longer assume `x == y` iff `Meta.is_same_object x y`, which used to be the case and caused failures in table tests.
# Important Notes
Measurements from `EqualsBenchmarks` shows that the performance of `Any.==` for recursive atoms increased by roughly 20%, and the performance for primitive types stays roughly the same.
Apparently
```
git --git-dir .enso/.vcs log refs/heads/master
fatal: ambiguous argument 'refs/heads/master': unknown revision or path not in the working tree.
```
but
```
git --git-dir .enso/.vcs log HEAD
fatal: ambiguous argument 'refs/heads/master': unknown revision or path not in the working tree.
```
works just fine on Windows.
Added some safeguards to avoid propagating weird errors because of retrieving element from an
empty Option.
Allow arbitrary expression evaluation in the chromeinspector console. Moreover, allow modifications of any variable in any stack frame.
# Important Notes
- Implement inline parsing in `EnsoLanguage.parse(InlineParsingRequest)`.
- Debugging experience is affected by this [bug in Truffle](https://github.com/oracle/graal/issues/5513), which causes NPEs when a host object gets into chromeinspector. I tried to implement a workaround, but it does not work all the time. Nevertheless, it should not matter that much - if there is a NPE in the debugger, you can just ignore it, as it should be concealed in the debugger and should not be propagted outside. See comments in the `docs/debugger`.
Upgrading to GraalVM 22.3.0.
# Important Notes
- Removed all deprecated `FrameSlot`, and replaced them with frame indexes - integers.
- Add more information to `AliasAnalysis` so that it also gathers these indexes.
- Add quick build mode option to `native-image` as default for non-release builds
- `graaljs` and `native-image` should now be downloaded via `gu` automatically, as dependencies.
- Remove `engine-runner-native` project - native image is now build straight from `engine-runner`.
- We used to have `engine-runner-native` without `sqldf` in classpath as a workaround for an internal native image bug.
- Fixed chrome inspector integration, such that it shows values of local variables both for current stack frame and caller stack frames.
- There are still many issues with the debugging in general, for example, when there is a polyglot value among local variables, a `NullPointerException` is thrown and no values are displayed.
- Removed some deprecated `native-image` options
- Remove some deprecated Truffle API method calls.
This change adds support for Version Controlled projects in language server.
Version Control supports operations:
- `init` - initialize VCS for a project
- `save` - commit all changes to the project in VCS
- `restore` - ability to restore project to some past `save`
- `status` - show the status of the project from VCS' perspective
- `list` - show a list of requested saves
# Important Notes
Behind the scenes, Enso's VCS uses git (or rather [jGit](https://www.eclipse.org/jgit/)) but nothing stops us from using a different implementation as long as it conforms to the establish API.
The main culprit of a Vector slowdown (when compared to Array) was the normalization of the index when accessing the elements. Turns out that the Graal was very persistent on **not** inlining that particular fragment and that was degrading the results in benchmarks.
Being unable to force it to do it (looks like a combination of thunk execution and another layer of indirection) we resorted to just moving the normalization to the builtin method. That makes Array and Vector perform roughly the same.
Moved all handling of invalid index into the builtin as well, simplifying the Enso implementation. This also meant that `Vector.unsafe_at` is now obsolete.
Additionally, added support for negative indices in Array, to behave in the same way as for Vector.
# Important Notes
Note that this workaround only addresses this particular perf issue. I'm pretty sure we will have more of such scenarios.
Before the change `averageOverVector` benchmark averaged around `0.033 ms/op` now it does consistently `0.016 ms/op`, similarly to `averageOverArray`.
- Reimplement the `Duration` type to a built-in type.
- `Duration` is an interop type.
- Allow Enso method dispatch on `Duration` interop coming from different languages.
# Important Notes
- The older `Duration` type should now be split into new `Duration` builtin type and a `Period` type.
- This PR does not implement `Period` type, so all the `Period`-related functionality is currently not working, e.g., `Date - Period`.
- This PR removes `Integer.milliseconds`, `Integer.seconds`, ..., `Integer.years` extension methods.
When nodes get invalidated in the cache, they have to be recomputed. Let the IDE know which of the nodes are pending by sending `Api.ExpressionUpdate.Payload.Pending` message.
# Important Notes
This PR introduces new `Api.ExpressionUpdate.Payload.Pending` message. This message is delivered before re-computation of nodes. Later `Api.ExpressionUpdate.Payload.Value` or other is sent to notify the IDE that a value for given node is available.
Trivial implementation of of the `Api.ExpressionUpdate.Payload.Pending` message in the IDE is provided by this PR to (improperly) visualize pending node status - further improvements needed in follow up PRs.
This PR adds a possibility to generate native-image for engine-runner.
Note that due to on-demand loading of stdlib, programs that make use of it are currently not yet supported
(that will be resolved at a later point).
The purpose of this PR is only to make sure that we can generate a bare minimum runner because due to lack TruffleBoundaries or misconfiguration in reflection config, this can get broken very easily.
To generate a native image simply execute:
```
sbt> engine-runner-native/buildNativeImage
... (wait a few minutes)
```
The executable is called `runner` and can be tested via a simple test that is in the resources. To illustrate the benefits
see the timings difference between the non-native and native one:
```
>time built-distribution/enso-engine-0.0.0-dev-linux-amd64/enso-0.0.0-dev/bin/enso --no-ir-caches --in-project test/Tests/ --run engine/runner-native/src/test/resources/Factorial.enso 6
720
real 0m4.503s
user 0m9.248s
sys 0m1.494s
> time ./runner --run engine/runner-native/src/test/resources/Factorial.enso 6
720
real 0m0.176s
user 0m0.042s
sys 0m0.038s
```
# Important Notes
Notice that due to a [bug in GraalVM](https://github.com/oracle/graal/issues/4200), which is already fixed in 22.x, and us still being on 21.x for the time being, I had to add a workaround to our sbt build to build a different fat jar for native image. To workaround it I had to exclude sqlite jar. Hence native image task is on `engine-runner-native` and not on `engine-runner`.
Will need to add the above command to CI.
This PR reenables code signing and notarization on macOS.
[ci no changelog needed]
# Important Notes
* electron-builder has been bumped, mostly to avoid missing Python issue. A workaround for a regression with Windows installer is provided as a patch.
IR cache never really took into account a situation when a binding from the imported module has changed. In other words, it would continue to happily use the serialized metadata without noticing that it changed.
This change forces cache invalidation when any of the imported modules was invalidated (or rather not loaded from cache).
# Important Notes
Added simple test infrastructure that simulates file modifications that would trigger the initial cache invalidation.
If they succeed, cache invalidation is propagated thus causing an error.
[ci no changelog needed]
Python 2 is required for our version of the `electron-builder` when building Enso IDE on modern Mac OS versions. Unfortunately, Apple removed the `/usr/bin/python` executable in the macOS Monterey release, so we are forced to give instructions on reinstalling it. I took the most popular solution from https://stackoverflow.com/questions/60298514/how-to-reinstall-python2-from-homebrew
This change adds Autosave action for open buffers. The action is scheduled
after every edit request and is cancelled by every explicit save file request, if
necessary. Successful autosave also notifies any active clients of the buffer.
Related to https://www.pivotaltracker.com/story/show/182721656
# Important Notes
WIP
PR allows to attach metod pointers as a visualization expressions. This way it allows to attach a runtime instrument that enables caching of intermediate expressions.
# Important Notes
ℹ️ API is backward compatible.
To attach the visualization with caching support, the same `executionContext/attachVisualisation` method is used, but `VisualisationConfig` message should contain the message pointer.
While `VisualisationConfiguration` message has changed, the language server accepts both new and old formats to keep visualisations working in IDE.
#### Old format
```json
{
"executionContextId": "UUID",
"visualisationModule": "local.Unnamed.Main",
"expression": "x -> x.to_text"
}
```
#### New format
```json
{
"executionContextId": "UUID",
"expression": {
"module": "local.Unnamed.Main",
"definedOnType": "local.Unnamed.Main",
"name": "encode"
}
}
```
Show custom icons in Component Browser for entries that have a non-empty `Icon` section in their docs with the section's body containing a name of a predefined icon.
https://www.pivotaltracker.com/story/show/182584336
#### Visuals
A screenshot of a couple custom icons in the Component Browser:
<img width="346" alt="Screenshot 2022-07-27 at 15 55 33" src="https://user-images.githubusercontent.com/273837/181265249-d57f861f-8095-4933-9ef6-e62644e11da3.png">
# Important Notes
- The PR assigns icon names to four items in the standard library, but only three of them are shown in the Component Browser because of [a parsing bug in the Engine](https://www.pivotaltracker.com/story/show/182781673).
- Icon names are assigned only to four items in the standard library because only two currently predefined icons match entries in the currently defined Virtual Component Groups. Adjusting the definitions of icons and Virtual Component Groups is covered by [a different task](https://www.pivotaltracker.com/story/show/182584311).
- A bug in the documentation of the Enso protocol message `DocSection` is fixed. A `text` field in the `Tag` interface is renamed to `body` (this is the field name used in Engine).
This change allows for importing modules using a qualified name and deals with any conflicts on the way.
Given a module C defined at `A/B/C.enso` with
```
type C
type C a
```
it is now possible to import it as
```
import project.A
...
val x = A.B.C 10
```
Given a module located at `A/B/C/D.enso`, we will generate
intermediate, synthetic, modules that only import and export the successor module along the path.
For example, the contents of a synthetic module B will look like
```
import <namespace>.<pkg-name>.A.B.C
export <namespace>.<pkg-name>.A.B.C
```
If module B is defined already by the developer, the compiler will _inject_ the above statements to the IR.
Also removed the last elements of some lowercase name resolution that managed to survive recent
changes (`Meta.Enso_Project` would now be ambiguous with `enso_project` method).
Finally, added a pass that detects shadowing of the synthetic module by the type defined along the path.
We print a warning in such a situation.
Related to https://www.pivotaltracker.com/n/projects/2539304
# Important Notes
There was an additional request to fix the annoying problem with `from` imports that would always bring
the module into the scope. The changes in stdlib demonstrate how it is now possible to avoid the workaround of
```
from X.Y.Z as Z_Module import A, B
```
(i.e. `as Z_Module` part is almost always unnecessary).
Modified UppercaseNames to now resolve methods without an explicit `here` to point to the current module.
`here` was also often used instead of `self` which was allowed by the compiler.
Therefore UppercaseNames pass is now GlobalNames and does some extra work -
it translated method calls without an explicit target into proper applications.
# Important Notes
There was a long-standing bug in scopes usage when compiling standalone expressions.
This resulted in AliasAnalysis generating incorrect graphs and manifested itself only in unit tests
and when running `eval`, thus being a bit hard to locate.
See `runExpression` for details.
Additionally, method name resolution is now case-sensitive.
Obsolete passes like UndefinedVariables and ModuleThisToHere were removed. All tests have been adapted.
This PR adds sources for Enso language support in IGV (and NetBeans). The support is based on TextMate grammar shown in the editor and registration of the Enso language so IGV can find it. Then this PR adds new GitHub Actions workflow file to build the project using Maven.
Changelog:
- Describe the `EditKind` optional parameter that allows enabling engine-side optimizations, like value updates
- Describe the `text/openBuffer` message required for the lazy visualizations feature
New plan to [fix the `sbt` build](https://www.pivotaltracker.com/n/projects/2539304/stories/182209126) and its annoying:
```
log.error(
"Truffle Instrumentation is not up to date, " +
"which will lead to runtime errors\n" +
"Fixes have been applied to ensure consistent Instrumentation state, " +
"but compilation has to be triggered again.\n" +
"Please re-run the previous command.\n" +
"(If this for some reason fails, " +
s"please do a clean build of the $projectName project)"
)
```
When it is hard to fix `sbt` incremental compilation, let's restructure our project sources so that each `@TruffleInstrument` and `@TruffleLanguage` registration is in individual compilation unit. Each such unit is either going to be compiled or not going to be compiled as a batch - that will eliminate the `sbt` incremental compilation issues without addressing them in `sbt` itself.
fa2cf6a33ec4a5b2e3370e1b22c2b5f712286a75 is the first step - it introduces `IdExecutionService` and moves all the `IdExecutionInstrument` API up to that interface. The rest of the `runtime` project then depends only on `IdExecutionService`. Such refactoring allows us to move the `IdExecutionInstrument` out of `runtime` project into independent compilation unit.
* The bash entry point was renamed `run.sh` -> `run`. Thanks to that `./run` works both on Linux and Windows with PowerShell (sadly not on CMD).
* Everyone's favorite checks for WASM size and program versions are back. These can be disabled through `--wasm-size-limit=0` and `--skip-version-check` respectively. WASM size limit is stored in `build-config.yaml`.
* Improved diagnostics for case when downloaded CI run artifact archive cannot be extracted.
* Added GH API authentication to the build script calls on CI. This should fix the macOS build failures that were occurring from time to time. (Actually they were due to runner being GitHub-hosted, not really an OS-specific issue by itself.)
* If the GH API Personal Access Token is provided, it will be validated. Later on it is difficult to say, whether fail was caused by wrong PAT or other issue.
* Renamed `clean` to `git-clean` as per suggestion to reduce risk of user accidently deleting unstaged work.
* Whitelisting dependabot from changelog checks, so PRs created by it are mergeable.
* Fixing issue where wasm-pack-action (third party) randomly failed to recognize the latest version of wasm-pack (macOS runners), leading to failed builds.
* Build logs can be filtered using `ENSO_BUILD_LOG` environment variable. See https://docs.rs/tracing-subscriber/0.3.11/tracing_subscriber/struct.EnvFilter.html#directives for the supported syntax.
* Improve help for ci-run source, to make clear that PAT token is required and what scope is expected there.
Also, JS parts were updated with some cleanups and fixes following the changes made when introducing the build script.
Promoted `with`, `take`, `finalize` to be methods of Managed_Resource
rather than static methods always taking `resource`, for consistency
reasons.
This required function dispatch boilerplate, similarly to `Ref`.
In future iterations we will address this boilerplate code.
Related to https://www.pivotaltracker.com/story/show/182212217
Finally this pull request proposes `--inspect` option to allow [debugging of `.enso`](e948f2535f/docs/debugger/README.md) in Chrome Developer Tools:
```bash
enso$ ./built-distribution/enso-engine-0.0.0-dev-linux-amd64/enso-0.0.0-dev/bin/enso --inspect --run ./test/Tests/src/Data/Numbers_Spec.enso
Debugger listening on ws://127.0.0.1:9229/Wugyrg9Nm4OUL9YhzdcElmLft71ayZW3LMUPCdPyNAY
For help, see: https://www.graalvm.org/tools/chrome-debugger
E.g. in Chrome open: devtools://devtools/bundled/js_app.html?ws=127.0.0.1:9229/Wugyrg9Nm4OUL9YhzdcElmLft71ayZW3LMUPCdPyNAY
```
copy the printed URL into chrome browser and you should see:
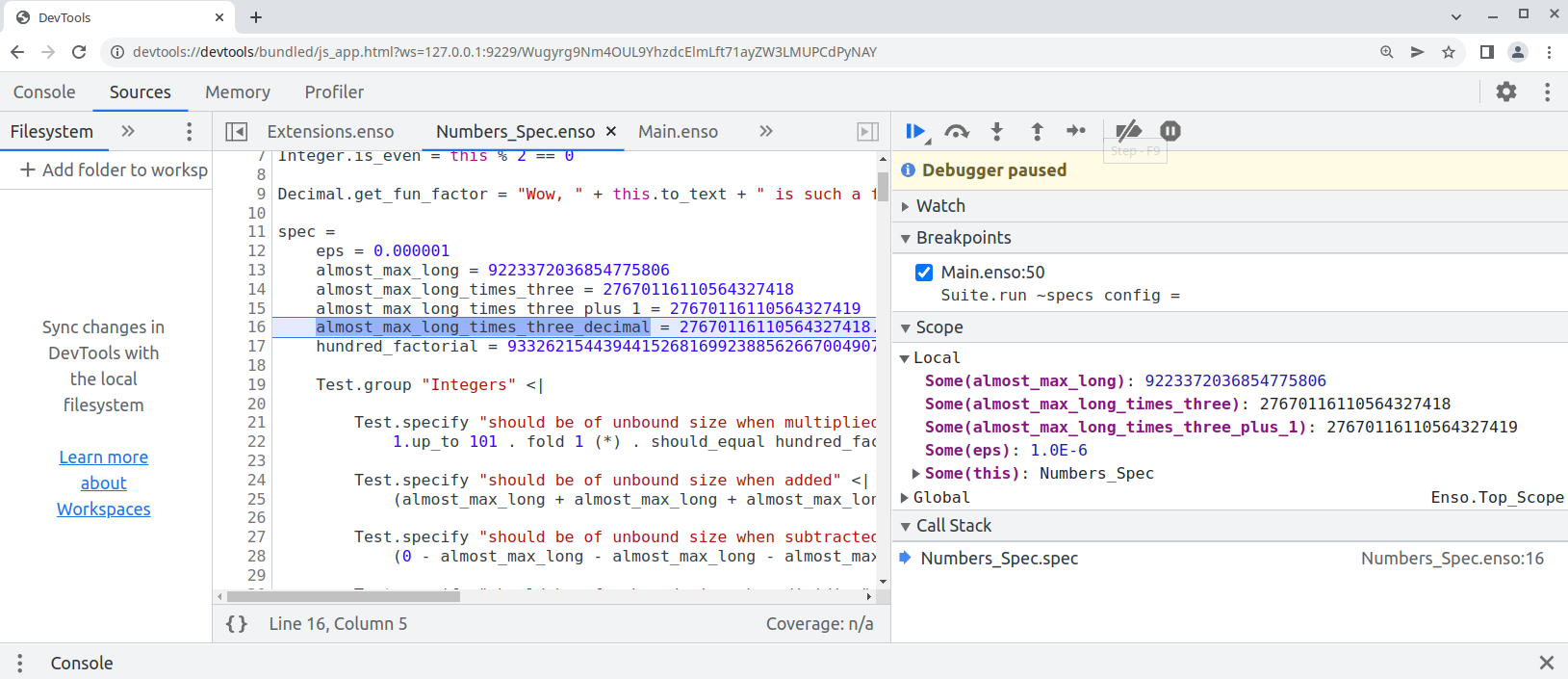
One can also debug the `.enso` files in NetBeans or [VS Code with Apache Language Server extension](https://cwiki.apache.org/confluence/display/NETBEANS/Apache+NetBeans+Extension+for+Visual+Studio+Code) just pass in special JVM arguments:
```bash
enso$ JAVA_OPTS=-agentlib:jdwp=transport=dt_socket,server=y,address=8000 ./built-distribution/enso-engine-0.0.0-dev-linux-amd64/enso-0.0.0-dev/bin/enso --run ./test/Tests/src/Data/Numbers_Spec.enso
Listening for transport dt_socket at address: 8000
```
and then _Debug/Attach Debugger_. Once connected choose the _Toggle Pause in GraalVM Script_ button in the toolbar (the "G" button):
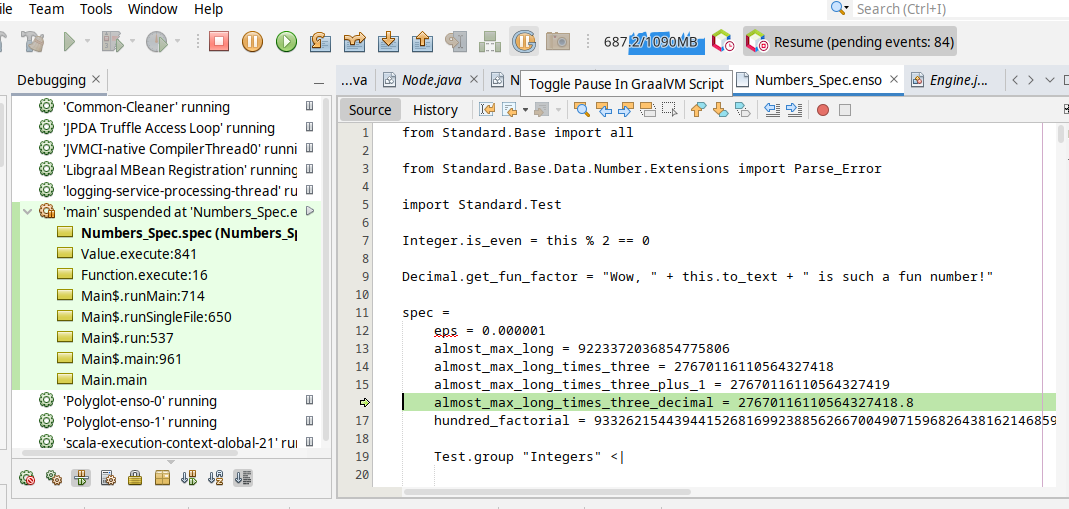
and your execution shall stop on the next `.enso` line of code. This mode allows to debug both - the Enso code as well as Java code.
Originally started as an attempt to write test in Java:
* test written in Java
* support for JUnit in `build.sbt`
* compile Java with `-g` - so it can be debugged
* Implementation of `StatementNode` - only gets created when `materialize` request gets to `BlockNode`
This PR replaces hard-coded `@Builtin_Method` and `@Builtin_Type` nodes in Builtins with an automated solution
that a) collects metadata from such annotations b) generates `BuiltinTypes` c) registers builtin methods with corresponding
constructors.
The main differences are:
1) The owner of the builtin method does not necessarily have to be a builtin type
2) You can now mix regular methods and builtin ones in stdlib
3) No need to keep track of builtin methods and types in various places and register them by hand (a source of many typos or omissions as it found during the process of this PR)
Related to #181497846
Benchmarks also execute within the margin of error.
### Important Notes
The PR got a bit large over time as I was moving various builtin types and finding various corner cases.
Most of the changes however are rather simple c&p from Builtins.enso to the corresponding stdlib module.
Here is the list of the most crucial updates:
- `engine/runtime/src/main/java/org/enso/interpreter/runtime/builtin/Builtins.java` - the core of the changes. We no longer register individual builtin constructors and their methods by hand. Instead, the information about those is read from 2 metadata files generated by annotation processors. When the builtin method is encountered in stdlib, we do not ignore the method. Instead we lookup it up in the list of registered functions (see `getBuiltinFunction` and `IrToTruffle`)
- `engine/runtime/src/main/java/org/enso/interpreter/runtime/callable/atom/AtomConstructor.java` has now information whether it corresponds to the builtin type or not.
- `engine/runtime/src/main/scala/org/enso/compiler/codegen/RuntimeStubsGenerator.scala` - when runtime stubs generator encounters a builtin type, based on the @Builtin_Type annotation, it looks up an existing constructor for it and registers it in the provided scope, rather than creating a new one. The scope of the constructor is also changed to the one coming from stdlib, while ensuring that synthetic methods (for fields) also get assigned correctly
- `engine/runtime/src/main/scala/org/enso/compiler/codegen/IrToTruffle.scala` - when a builtin method is encountered in stdlib we don't generate a new function node for it, instead we look it up in the list of registered builtin methods. Note that Integer and Number present a bit of a challenge because they list a whole bunch of methods that don't have a corresponding method (instead delegating to small/big integer implementations).
During the translation new atom constructors get initialized but we don't want to do it for builtins which have gone through the process earlier, hence the exception
- `lib/scala/interpreter-dsl/src/main/java/org/enso/interpreter/dsl/MethodProcessor.java` - @Builtin_Method processor not only generates the actual code fpr nodes but also collects and writes the info about them (name, class, params) to a metadata file that is read during builtins initialization
- `lib/scala/interpreter-dsl/src/main/java/org/enso/interpreter/dsl/MethodProcessor.java` - @Builtin_Method processor no longer generates only (root) nodes but also collects and writes the info about them (name, class, params) to a metadata file that is read during builtins initialization
- `lib/scala/interpreter-dsl/src/main/java/org/enso/interpreter/dsl/TypeProcessor.java` - Similar to MethodProcessor but handles @Builtin_Type annotations. It doesn't, **yet**, generate any builtin objects. It also collects the names, as present in stdlib, if any, so that we can generate the names automatically (see generated `types/ConstantsGen.java`)
- `engine/runtime/src/main/java/org/enso/interpreter/node/expression/builtin` - various classes annotated with @BuiltinType to ensure that the atom constructor is always properly registered for the builitn. Note that in order to support types fields in those, annotation takes optional `params` parameter (comma separated).
- `engine/runtime/src/bench/scala/org/enso/interpreter/bench/fixtures/semantic/AtomFixtures.scala` - drop manual creation of test list which seemed to be a relict of the old design
Changelog:
- add: component groups to package descriptions
- add: `executionContext/getComponentGroups` method that returns component groups of libraries that are currently loaded
- doc: cleanup unimplemented undo/redo commands
- refactor: internal component groups datatype
Implements infrastructure for new aggregations in the Database. It comes with only some basic aggregations and limited error-handling. More aggregations and problem handling will be added in subsequent PRs.
# Important Notes
This introduces basic aggregations using our existing codegen and sets-up our testing infrastructure to be able to use the same aggregate tests as in-memory backend for the database backends.
Many aggregations are not yet implemented - they will be added in subsequent tasks.
There are some TODOs left - they will be addressed in the next tasks.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}