This change modifies the current language by requiring explicit `self` parameter declaration
for methods. Methods without `self` parameter in the first position should be treated as statics
although that is not yet part of this PR. We add an implicit self to all methods
This obviously required updating the whole stdlib and its components, tests etc but the change
is pretty straightforward in the diff.
Notice that this change **does not** change method dispatch, which was removed in the last changes.
This was done on purpose to simplify the implementation for now. We will likely still remove all
those implicit selfs to bring true statics.
Minor caveat - since `main` doesn't actually need self, already removed that which simplified
a lot of code.
Adds least squares regression APIs. Covers the basic 4 trend line types from Excel (doesn't cover Polynomial or Moving Average).
Removes the old `Model` from the `Standard.Table`.
Significantly improves the polyglot Date support (as introduced by #3374). It enhances the `Date_Spec` to run it in four flavors:
- with Enso Date (as of now)
- with JavaScript Date
- with JavaScript Date wrapped in (JavaScript) array
- with Java LocalDate allocated directly
The code is then improved by necessary modifications to make the `Date_Spec` pass.
# Important Notes
James has requested in [#181755990](https://www.pivotaltracker.com/n/projects/2539304/stories/181755990) - e.g. _Review and improve InMemory Table support for Dates, Times, DateTimes, BigIntegers_ the following program to work:
```
foreign js dateArr = """
return [1, new Date(), 7]
main =
IO.println <| (dateArr.at 1).week_of_year
```
the program works with here in provided changes and prints `27` as of today.
@jdunkerley has provided tests for proper behavior of date in `Table` and `Column`. Those tests are working as of [f16d07e](f16d07e640). One just needs to accept `List<Value>` and then query `Value` for `isDate()` when needed.
Last round of changes is related to **exception handling**. 8b686b12bd makes sure `makePolyglotError` accepts only polyglot values. Then it wraps plain Java exceptions into `WrapPlainException` with `has_type` method - 60da5e70ed - the remaining changes in the PR are only trying to get all tests working in the new setup.
The support for `Time` isn't part of this PR yet.
**Note**: This PR also contains content of previous Grid View PR. We decided to discard the previous, because this one did some refactoring of old one, and it's not a big addition.
Added a scrollable::GridView component, which just embeds the GridView in ScrollArea. Also, re-worked the idea of text layers.
https://user-images.githubusercontent.com/3919101/179020359-512ee127-c333-4f86-bff5-f1cb4154e03c.mp4
This PR contains all work for finishing integration of first Component List Panel in the IDE:
* It adds a stub for the whole Component Browser View. The documentation panel is re-used from the old searcher.
* It has the presenter implementation, integrating the view with Hierarchical Component List from the controller.
* It extends the View API, so the integration is possible, making use of Component Group Set wrapper.
* The selection integration was also merged into this PR, because it depended on the API extension mentioned above. However, we should avoid such practice in the future.
https://user-images.githubusercontent.com/3919101/177816427-8c4285b4-8941-4048-a400-52f4acf77a9f.mp4
# Important Notes
There are some known issues, to-be-fixed in the future.
* The performance is bad. It should be improved with new text::Area, and the decent one shall come with [GridView inside component browser](https://www.pivotaltracker.com/story/show/182561072)
* There is no keyboard navigation. It should also be delivered with [GridView](https://www.pivotaltracker.com/story/show/182561072).
* The Favorites section is not [filtered out by node source type](https://www.pivotaltracker.com/story/show/182661634).
Updates `write_bytes` API to be part of `Vector` and to conform to `write` APIs.
# Important Notes
Ensures doesn't touch the file if an invalid byte array.
More and more often I need a way to only recover a specific type of a dataflow error (in a similar manner as with panics). So the API for `Error.catch` has been amended to more closely resemble `Panic.catch`, allowing to handle only specific types of dataflow errors, passing others through unchanged. The default is `Any`, meaning all errors are caught by default, and the behaviour of `x.catch` remains unchanged.
Modified UppercaseNames to now resolve methods without an explicit `here` to point to the current module.
`here` was also often used instead of `self` which was allowed by the compiler.
Therefore UppercaseNames pass is now GlobalNames and does some extra work -
it translated method calls without an explicit target into proper applications.
# Important Notes
There was a long-standing bug in scopes usage when compiling standalone expressions.
This resulted in AliasAnalysis generating incorrect graphs and manifested itself only in unit tests
and when running `eval`, thus being a bit hard to locate.
See `runExpression` for details.
Additionally, method name resolution is now case-sensitive.
Obsolete passes like UndefinedVariables and ModuleThisToHere were removed. All tests have been adapted.
Adds support for appending to an existing Excel table.
# Important Notes
- Renamed `Column_Mapping` to `Column_Name_Mapping`
- Changed new type name to `Map_Column`
- Added last modified time and creation time to `File`.
If a node created by the user gets placed off-screen, the screen's camera is panned to make the node visible.
https://www.pivotaltracker.com/story/show/181188687
#### Visuals
A screencast showing a number of node creation scenarios when the camera is panned to the newly created node, including when zoomed out.
https://user-images.githubusercontent.com/273837/177169716-50a12b0a-c742-4b01-9766-56206e7938b9.mov
# Important Notes
- Camera is panned also if the node is only partially visible, or if there's not enough free space visible around the node. The specific amount of free space that needs to be visible around a newly created node is configured in the theme.
- If the screen area is so small that the node cannot be fully fit in it (either horizontally or vertically), showing the left and top boundaries of the node's area takes priority over showing the corresponding opposite edges.
Initial work restructuring the `Database.connect` API
- New SQLite API with support for InMemory.
- Updated PostgreSQL API with SSL and Client Certificate Support.
- Updated Redshift API.
# Important Notes
Follow up tasks:
- PostgreSQL SSL additional testing.
- Driver version updating.
- `.pgpass` support.
This PR adds sources for Enso language support in IGV (and NetBeans). The support is based on TextMate grammar shown in the editor and registration of the Enso language so IGV can find it. Then this PR adds new GitHub Actions workflow file to build the project using Maven.
- Remove `from_xls` and `from_xlsx`.
- Add `headers` support to `File_Format.Excel`.
- Altered default read for Excel to be the first sheet.
- Altered behavior so that single cells grow down and right when reading sheet.
- Altered `Excel_Range` so knows if single cell or 1x1 range address.
# Important Notes
- Renamed `Range` to `Cell_Range` to avoid name clash.
A semi-manual s/this/self appied to the whole standard library.
Related to https://www.pivotaltracker.com/story/show/182328601
In the compiler promoted to use constants instead of hardcoded
`this`/`self` whenever possible.
# Important Notes
The PR **does not** require explicit `self` parameter declaration for methods as this part
of the design is still under consideration.
This introduces a tiny alternative to our stdlib, that can be used for testing the interpreter. There are 2 main advantages of such a solution:
1. Performance: on my machine, `runtime-with-intstruments/test` drops from 146s to 65s, while `runtime/test` drops from 165s to 51s. >6 mins total becoming <2 mins total is awesome. This alone means I'll drink less coffee in these breaks and will be healthier.
2. Better separation of concepts – currently working on a feature that breaks _all_ enso code. The dependency of interpreter tests on the stdlib means I have no means of incremental testing – ALL of stdlib must compile. This is horrible, rendered my work impossible, and resulted in this PR.
- Removed `select` method.
- Removed `group` method.
- Removed `Aggregate_Table` type.
- Removed `Order_Rule` type.
- Removed `sort` method from Table.
- Expanded comments on `order_by`.
- Update comment on `aggregate` on Database.
- Update Visualisation to use new APIs.
- Updated Data Science examples to use new APIs.
- Moved Examples test out of Tests to own test.
# Important Notes
Need to get Examples_Tests added to CI.
Auto-generate all builtin methods for builtin `File` type from method signatures.
Similarly, for `ManagedResource` and `Warning`.
Additionally, support for specializations for overloaded and non-overloaded methods is added.
Coverage can be tracked by the number of hard-coded builtin classes that are now deleted.
## Important notes
Notice how `type File` now lacks `prim_file` field and we were able to get rid off all of those
propagating method calls without writing a single builtin node class.
Similarly `ManagedResource` and `Warning` are now builtins and `Prim_Warnings` stub is now gone.
Implemented the `order_by` function with support for all modes of operation.
Added support for case insensitive natural order.
# Important Notes
- Improved MultiValueIndex/Key to not create loads of arrays.
- Adjusted HashCode for MultiValueKey to have a simple algorithm.
- Added Text_Utils.compare_normalized_ignoring_case to allow for case insensitive comparisons.
- Fixed issues with ObjectComparator and added some unit tests for it.
Drop `Core` implementation (replacement for IR) as it (sadly) looks increasingly
unlikely this effort will be continued. Also, it heavily relies
on implicits which increases some compilation time (~1sec from `clean`)
Related to https://www.pivotaltracker.com/story/show/182359029
- Added new `Statistic`s: Covariance, Pearson, Spearman, R Squared
- Added `covariance_matrix` function
- Added `pearson_correlation` function to compute correlation matrix
- Added `rank_data` and Rank_Method type to create rankings of a Vector
- Added `spearman_correlation` function to compute Spearman Rank correlation matrix
# Important Notes
- Added `Panic.throw_wrapped_if_error` and `Panic.handle_wrapped_dataflow_error` to help with errors within a loop.
- Removed `Array.set_at` use from `Table.Vector_Builder`
There are two dirty flags in layers: depth_order_dirty and element_depth_order_dirty - one marking changed in Layer, second marking change in one of sublayers. The depth_order_dirty has a proper callback for setting element_depth_order_dirty of its parent. However, the latter did not propagate up.
I fixed it by adding callback for element_depth_order_dirty which sets the depth_order_dirty of the parent.
# Important Notes
* The question to @wdanilo : is it possible, that I can propagate dirty directly to element_depth_order_dirty, without setting depth_order_dirty? As far as I understand the code, it would also work (and we would omit some unnecessary updates).
* I tried to leave some logs, but I don't feel how to do that: the tooling I used was very specific, only the concrete ids of symbols and layers were logged, and I don't know how to generalize it.
This is the 2nd part of DSL improvements that allow us to generate a lot of
builtins-related boilerplate code.
- [x] generate multiple method nodes for methods/constructors with varargs
- [x] expanded processing to allow for @Builtin to be added to classes and
and generate @BuiltinType classes
- [x] generate code that wraps exceptions to panic via `wrapException`
annotation element (see @Builtin.WrapException`
Also rewrote @Builtin annotations to be more structured and introduced some nesting, such as
@Builtin.Method or @Builtin.WrapException.
This is part of incremental work and a follow up on https://github.com/enso-org/enso/pull/3444.
# Important Notes
Notice the number of boilerplate classes removed to see the impact.
For now only applied to `Array` but should be applicable to other types.
Promoted `with`, `take`, `finalize` to be methods of Managed_Resource
rather than static methods always taking `resource`, for consistency
reasons.
This required function dispatch boilerplate, similarly to `Ref`.
In future iterations we will address this boilerplate code.
Related to https://www.pivotaltracker.com/story/show/182212217
The change promotes static methods of `Ref`, `get` and `put`, to be
methods of `Ref` type.
The change also removes `Ref` module from the default namespace.
Had to mostly c&p functional dispatch for now, in order for the methods
to be found. Will auto-generate that code as part of builtins system.
Related to https://www.pivotaltracker.com/story/show/182138899
A low-hanging fruit where we can automate the generation of many
@BuiltinMethod nodes simply from the runtime's methods signatures.
This change introduces another annotation, @Builtin, to distinguish from
@BuiltinType and @BuiltinMethod processing. @Builtin processing will
always be the first stage of processing and its output will be fed to
the latter.
Note that the return type of Array.length() is changed from `int` to
`long` because we probably don't want to add a ton of specializations
for the former (see comparator nodes for details) and it is fine to cast
it in a small number of places.
Progress is visible in the number of deleted hardcoded classes.
This is an incremental step towards #181499077.
# Important Notes
This process does not attempt to cover all cases. Not yet, at least.
We only handle simple methods and constructors (see removed `Array` boilerplate methods).
- Implements various statistics on Vector
# Important Notes
Some minor codebase improvements:
- Some tweaks to Any/Nothing to improve performance
- Fixed bug in ObjectComparator
- Added if_nothing
- Removed Group_By_Key
Finally this pull request proposes `--inspect` option to allow [debugging of `.enso`](e948f2535f/docs/debugger/README.md) in Chrome Developer Tools:
```bash
enso$ ./built-distribution/enso-engine-0.0.0-dev-linux-amd64/enso-0.0.0-dev/bin/enso --inspect --run ./test/Tests/src/Data/Numbers_Spec.enso
Debugger listening on ws://127.0.0.1:9229/Wugyrg9Nm4OUL9YhzdcElmLft71ayZW3LMUPCdPyNAY
For help, see: https://www.graalvm.org/tools/chrome-debugger
E.g. in Chrome open: devtools://devtools/bundled/js_app.html?ws=127.0.0.1:9229/Wugyrg9Nm4OUL9YhzdcElmLft71ayZW3LMUPCdPyNAY
```
copy the printed URL into chrome browser and you should see:
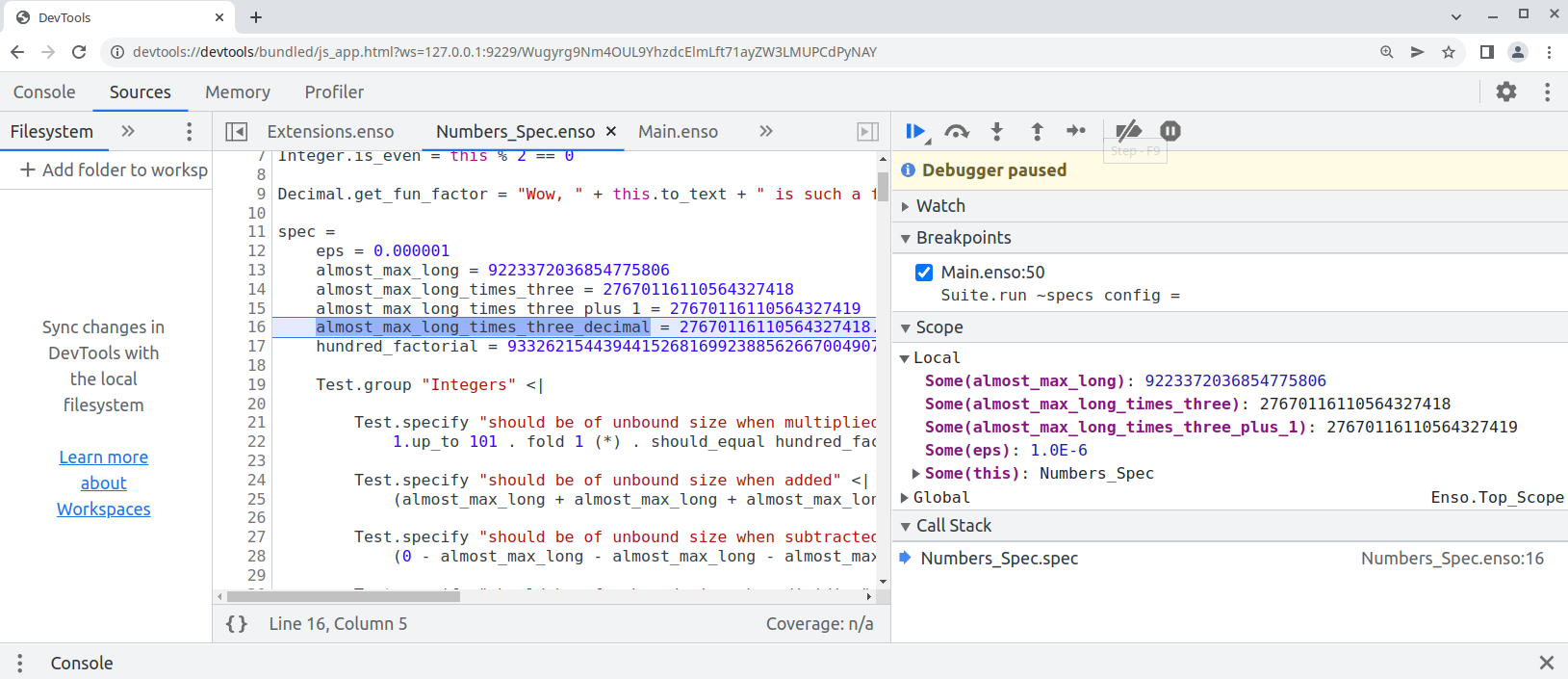
One can also debug the `.enso` files in NetBeans or [VS Code with Apache Language Server extension](https://cwiki.apache.org/confluence/display/NETBEANS/Apache+NetBeans+Extension+for+Visual+Studio+Code) just pass in special JVM arguments:
```bash
enso$ JAVA_OPTS=-agentlib:jdwp=transport=dt_socket,server=y,address=8000 ./built-distribution/enso-engine-0.0.0-dev-linux-amd64/enso-0.0.0-dev/bin/enso --run ./test/Tests/src/Data/Numbers_Spec.enso
Listening for transport dt_socket at address: 8000
```
and then _Debug/Attach Debugger_. Once connected choose the _Toggle Pause in GraalVM Script_ button in the toolbar (the "G" button):
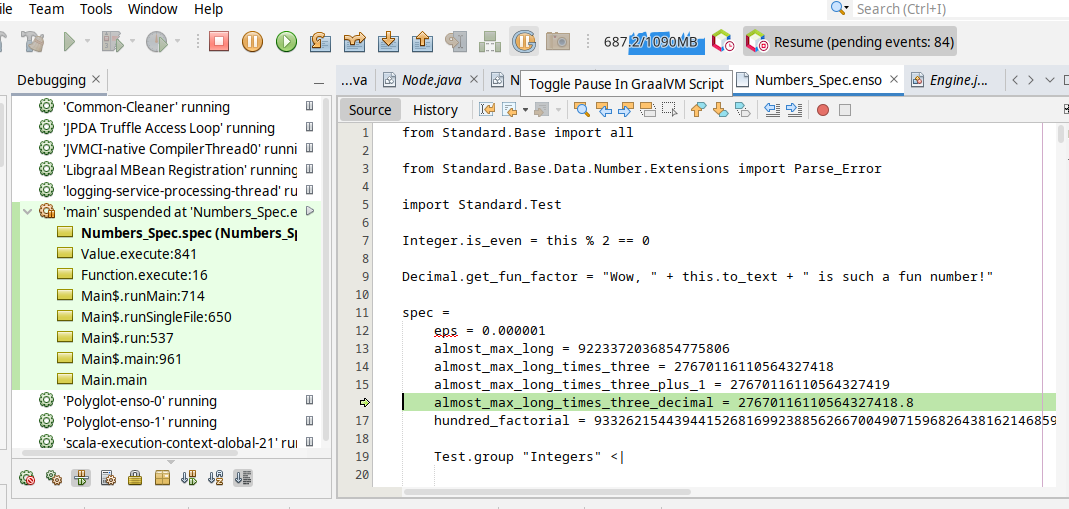
and your execution shall stop on the next `.enso` line of code. This mode allows to debug both - the Enso code as well as Java code.
Originally started as an attempt to write test in Java:
* test written in Java
* support for JUnit in `build.sbt`
* compile Java with `-g` - so it can be debugged
* Implementation of `StatementNode` - only gets created when `materialize` request gets to `BlockNode`
- Read in Excel files following the specification.
- Support for XLSX and XLS formats.
- Ability to select ranges and sheets.
- Skip Rows and Row Limits.
# Important Notes
- Minor fix to DelimitedReader for Windows
This PR replaces hard-coded `@Builtin_Method` and `@Builtin_Type` nodes in Builtins with an automated solution
that a) collects metadata from such annotations b) generates `BuiltinTypes` c) registers builtin methods with corresponding
constructors.
The main differences are:
1) The owner of the builtin method does not necessarily have to be a builtin type
2) You can now mix regular methods and builtin ones in stdlib
3) No need to keep track of builtin methods and types in various places and register them by hand (a source of many typos or omissions as it found during the process of this PR)
Related to #181497846
Benchmarks also execute within the margin of error.
### Important Notes
The PR got a bit large over time as I was moving various builtin types and finding various corner cases.
Most of the changes however are rather simple c&p from Builtins.enso to the corresponding stdlib module.
Here is the list of the most crucial updates:
- `engine/runtime/src/main/java/org/enso/interpreter/runtime/builtin/Builtins.java` - the core of the changes. We no longer register individual builtin constructors and their methods by hand. Instead, the information about those is read from 2 metadata files generated by annotation processors. When the builtin method is encountered in stdlib, we do not ignore the method. Instead we lookup it up in the list of registered functions (see `getBuiltinFunction` and `IrToTruffle`)
- `engine/runtime/src/main/java/org/enso/interpreter/runtime/callable/atom/AtomConstructor.java` has now information whether it corresponds to the builtin type or not.
- `engine/runtime/src/main/scala/org/enso/compiler/codegen/RuntimeStubsGenerator.scala` - when runtime stubs generator encounters a builtin type, based on the @Builtin_Type annotation, it looks up an existing constructor for it and registers it in the provided scope, rather than creating a new one. The scope of the constructor is also changed to the one coming from stdlib, while ensuring that synthetic methods (for fields) also get assigned correctly
- `engine/runtime/src/main/scala/org/enso/compiler/codegen/IrToTruffle.scala` - when a builtin method is encountered in stdlib we don't generate a new function node for it, instead we look it up in the list of registered builtin methods. Note that Integer and Number present a bit of a challenge because they list a whole bunch of methods that don't have a corresponding method (instead delegating to small/big integer implementations).
During the translation new atom constructors get initialized but we don't want to do it for builtins which have gone through the process earlier, hence the exception
- `lib/scala/interpreter-dsl/src/main/java/org/enso/interpreter/dsl/MethodProcessor.java` - @Builtin_Method processor not only generates the actual code fpr nodes but also collects and writes the info about them (name, class, params) to a metadata file that is read during builtins initialization
- `lib/scala/interpreter-dsl/src/main/java/org/enso/interpreter/dsl/MethodProcessor.java` - @Builtin_Method processor no longer generates only (root) nodes but also collects and writes the info about them (name, class, params) to a metadata file that is read during builtins initialization
- `lib/scala/interpreter-dsl/src/main/java/org/enso/interpreter/dsl/TypeProcessor.java` - Similar to MethodProcessor but handles @Builtin_Type annotations. It doesn't, **yet**, generate any builtin objects. It also collects the names, as present in stdlib, if any, so that we can generate the names automatically (see generated `types/ConstantsGen.java`)
- `engine/runtime/src/main/java/org/enso/interpreter/node/expression/builtin` - various classes annotated with @BuiltinType to ensure that the atom constructor is always properly registered for the builitn. Note that in order to support types fields in those, annotation takes optional `params` parameter (comma separated).
- `engine/runtime/src/bench/scala/org/enso/interpreter/bench/fixtures/semantic/AtomFixtures.scala` - drop manual creation of test list which seemed to be a relict of the old design
A draft of simple changes to the compiler to expose sum type information. Doesn't break the stdlib & at the same time allows for dropdowns. This is still broken, for example it doesn't handle exporting/importing types, only ones defined in the same module as the signature. Still, seems like a step in the right direction – please provide feedback.
# Important Notes
I've decided to make the variant info part of the type, not the argument – it is a property of the type logically.
Also, I've pushed it as far as I'm comfortable – i.e. to the `SuggestionHandler` – I have no idea if this is enough to show in IDE? cc @4e6
Most of the functions in the standard library aren't gonna be invoked during particular program execution. It makes no sense to build their Truffle AST for the functions that are not executing. Let's delay the construction of the tree until a function is first executed.
* Initial integration with Frgaal in sbt
Half-working since it chokes on generated classes from annotation
processor.
* Replace AutoService with ServiceProvider
For reasons unknown AutoService would fail to initialize and fail to
generate required builtin method classes.
Hidden error message is not particularly revealing on the reason for
that:
```
[error] error: Bad service configuration file, or exception thrown while constructing Processor object: javax.annotation.processing.Processor: Provider com.google.auto.service.processor.AutoServiceProcessor could not be instantiated
```
The sample records is only to demonstrate that we can now use newer Java
features.
* Cleanup + fix benchmark compilation
Bench requires jmh classes which are not available because we obviously
had to limit `java.base` modules to get Frgaal to work nicely.
For now, we default to good ol' javac for Benchmarks.
Limiting Frgaal to runtime for now, if it plays nicely, we can expand it
to other projects.
* Update CHANGELOG
* Remove dummy record class
* Update licenses
* New line
* PR review
* Update legal review
Co-authored-by: Radosław Waśko <radoslaw.wasko@enso.org>
Implements https://www.pivotaltracker.com/story/show/181266184
### Important Notes
Changed example image download to only proceed if the file did not exist before - thus cutting on the build time (the build used to download it _every_ time - which completely failed the build if network is down). A redownload can be forced by performing a fresh repository checkout.
Changelog:
- fix: `search/completion` request with the position parameter.
- fix: `refactoring/renameProject` request. Previously it did not take into account the library namespace (e.g. `local.`)
- Added Encoding type
- Added `Text.bytes`, `Text.from_bytes` with Encoding support
- Renamed `File.read` to `File.read_text`
- Renamed `File.write` to `File.write_text`
- Added Encoding support to `File.read_text` and `File.write_text`
- Added warnings to invalid encodings
Changelog:
- add: component groups to package descriptions
- add: `executionContext/getComponentGroups` method that returns component groups of libraries that are currently loaded
- doc: cleanup unimplemented undo/redo commands
- refactor: internal component groups datatype
PR adds a monitor that handles messages between the language server and the runtime and dumps them as a CSV file `/tmp/enso-api-events-*********.csv`
```
UTC timestamp,Direction,Request Id,Message class
```
# Important Notes
⚠️ Monitor is enabled when the log level is set to trace. You should pass `-vv` (very verbose) option to the backend when starting IDE
```
enso -- -vv
```
Implements https://www.pivotaltracker.com/story/show/181805693 and finishes the basic set of features of the Aggregate component.
Still not all aggregations are supported everywhere, because for example SQLite has quite limited support for aggregations. Currently the workaround is to bring the table into memory (if possible) and perform the computation locally. Later on, we may add more complex generator features to emulate the missing aggregations with complex sub-queries.
This commit implements `Text.reverse` as an extension on `Text`.
`Text.reverse` reverses strings. For example: `"Hello World!".reverse`
results in `"!dlroW olleH"`.
Strings are reversed by their Extended Grapheme Clusters not by their
characters. This has some performance implications because we need to
find these grapheme cluster boundaries when iterating. To do so,
`BreakIterator.getCharacterInstance` is used.
Implements: https://www.pivotaltracker.com/n/projects/2539304/stories/181265419
When a new node is created with the <kbd>TAB</kbd> key or by clicking the `(+)` on-screen button while multiple nodes are selected, place the new node below all the selected nodes. (Previously, the new node was placed below the node that was selected earliest.)
Additionally, when placing a new node below an existing non-error node with a visualization enabled, place the new node below the visualization. (Previously, the new node was placed to the left of the visualization.)
https://www.pivotaltracker.com/story/show/180887079
#### Visuals
The following screencast demonstrates the feature on various arrangements of selected nodes, with visualization enabled and disabled.
https://user-images.githubusercontent.com/273837/159971452-148aa4d7-c0f3-4b48-871a-a2783989f403.mov
The following screencast demonstrates that new nodes created by double-clicking an output port of a node with visualization enabled are now placed below the visualization:
https://user-images.githubusercontent.com/273837/160107733-e3f7d0f9-0161-49d1-8cbd-06e18c843a20.mov
# Important Notes
- Some refactorings that were needed for this PR were ported from the #3301 PR:
- the code responsible for calculating the positions of new nodes was moved to a separate module (`new_node_position`);
- the `free_place_finder` module was made a submodule of the `new_node_position` module, due to the latter being its only user.
Use a new algorithm for placement of new nodes in cases when:
- a) there is no selected node, and the `TAB` key is pressed while the mouse pointer is near an existing node (especially in an area below an existing node);
- b) a connection is dragged out from an existing node and dropped near the node (especially in an area below the node).
In both cases mentioned above, the new node will now be placed in a location suggested by an internal algorithm, aligned to existing nodes. Specifically, the placement algorithm used is similar to when pressing `TAB` with a node selected.
For more details, see: https://www.pivotaltracker.com/story/show/181076066
# Important Notes
- Visible visualizations enabled with the "eye icon" button are treated as part of a node. (In case of nodes with errors, visualizations are not visible, and are not treated as part of a node.)
- Make it easier to understand the computations.
- Fix issue with First.
- Improve quote handling in Concatenate
- Added validation and warnings to input
Double-clicking a node's output port or clicking the port with a right mouse button (RMB) creates a new node aligned to the clicked node.
#### Visuals
The screencast below demonstrates the following features:
- double-clicking the left mouse button on a node's output port;
- clicking the right mouse button on a node's output port;
- alignment of the nodes created as a result of the actions described above;
- corner case: double-clicking (and RMB-clicking) on output ports of a "collapsed" ("enterable") node;
- double-clicking on a "collapsed" ("enterable") node still allows entering the node when done over an area of the node that is not the node's output port;
- basic support for nodes with multiple output ports (shown on the `interface` demo scene).
https://user-images.githubusercontent.com/273837/158991856-e0faa5f0-9d2f-44bd-bddd-ba314977db6e.mov
The supplementary screencast below demonstrates that double-clicking or RMB-clicking a node's output port cancels the action of dragging a new connection from a node.
https://user-images.githubusercontent.com/273837/158998097-100aed42-37ff-4467-939f-2b755ef0d3dc.movhttps://www.pivotaltracker.com/story/show/181076145
# Important Notes
- The "double-clicking a node" shortcut was previously used to allow entering a "collapsed" node (for example, a node created by pressing the `cmd+g` keyboard shortcut after selecting a group of nodes). This PR keeps that functionality when the user double-clicks on a node, as long as the mouse is not positioned over the node's output ports.
- The support for nodes with multiple output ports is currently very basic. The information about a port (`Crumb`) is passed into the `create_node` function, but it is not passed further to `NodeSource`. The Node Searcher currently does not support passing port information through `NodeSource`.
The mechanism follows a similar approach to what is being in functions
with default arguments.
Additionally since InstantiateAtomNode wasn't a subtype of EnsoRootNode it
couldn't be used in the application, which was the primary reason for
issue #181449213.
Alternatively InstantiateAtomNode could have been enhanced to extend
EnsoRootNode rather than RootNode to carry scope info but the former
seemed simpler.
See test cases for previously crashing and invalid cases.
In this PR two things are implemented:
1. Node Searcher zoom factor (and therefore its size) is fixed no matter how you move the main camera. The node searcher is also positioned directly below currently edited node at all times.
2. Node growth/shrink animation when you start/finish node editing. After animation end the edited node zoom factor is also fixed and matches the zoom factor of the node searcher.
See attached video with different ways of editing/creating nodes:
https://user-images.githubusercontent.com/6566674/157348758-2880aa2b-494d-46e6-8eee-a22be84081ed.mp4
#### Technical details
1. Added several additional scene layers for separate rendering: `node_searcher`, `node_searcher_text`, `edited_node`, `edited_node_text`. Searcher is always rendered by `node_searcher` camera, edited node moves between its usual layers and `edited_node` layer. Because text rendering uses different API, all node components were modified to support change of the layer.
2. Also added `node_searcher` DOM layer, because documentation is implemented as a DOM object.
3. Added two FRP endpoints for `ensogl::Animation`: `on_end` and `set_value`. These endpoints are useful while implementing growth/shrink animation.
4. Added FRP endpoints for the `Camera2d`: `position` and `zoom` outputs. This allows to synchronize cameras easily using FRP networks.
5. Growth/shrink animation implemented in GraphEditor by blending two animations, similar to Node Snapping implementation. However, shrinking animation is a bit tricky to implement correctly, as we must always return node back to the `main` scene layer after editing is done.
* Creating a new node with the (+) button (#3278)
[The Task](https://www.pivotaltracker.com/story/show/180887253)
A new (+) button on the left-bottom corner appeared. It may be clicked to open searcher in the middle of the scene, as an alternative to tab key.
https://user-images.githubusercontent.com/3919101/154514279-7972ed6a-0203-47cb-9a09-82dba948cf2f.mp4
* The window_control_buttons::common was extracted to separate crate `ensogl-component-button` almost without change.
* This includes a severe refactoring of adding nodes in general in the Graph Editor. The whole responsibility of adding new nodes (and starting their editing) was moved to Graph Editor - the Project View only reacts for GE events to show searcher properly.
* The status bar was moved from the bottom-left corner to the middle-top of the scene. It does not collide with (+) button, and plays "notification" role anyway.
* The `interface` debug scene was buggy. The problem was with one expression's span-tree. When I replaced it, the scene works.
* I've removed "new searcher" API, as it is completely outdated.
* I've changed code owners of integration tests to GUI team, as it is the team writing mostly the integration tests (int rust)
* Fix regression #181528359
* Add docs & remove unused function
* Fix & enable native Rust tests
* Fix formatting
Co-authored-by: Adam Obuchowicz <adam.obuchowicz@enso.org>
Co-authored-by: mergify[bot] <37929162+mergify[bot]@users.noreply.github.com>
PR fixes the issue when the user is unable to sign in with Google.
In the end, my assumption about the `User-Agent` header was correct and Google sign-in works with the recent Electron out of the box.
[ci no changelog needed]
This PR reverts commit [0836ce741d](0836ce741d) because of the spotted regression:
To reproduce:
1. Open a default project.
2. Without doing anything else, cmd + click on any node to edit it.
3. Abort editing by pressing escape.
4. Top-most node disappears (it is actually removed from scene)
If you start editing the bottom node - you will also see a visible regression in node searcher's position.
See thread https://discord.com/channels/401396655599124480/950730235719065620/950731247909478410 for details.
- Added Minimum, Maximum, Longest. Shortest, Mode, Percentile
- Added first and last to Map
- Restructured Faker type more inline with FakerJS
- Created 2,500 row data set
- Tests for group_by
- Performance tests for group_by
Following the Slice and Array.Copy experiment, took just the Array.Copy parts out and built into the Vector class.
This gives big performance wins in common operations:
| Test | Ref | New |
| --- | --- | --- |
| New Vector | 41.5 | 41.4 |
| Append Single | 26.6 | 4.2 |
| Append Large | 26.6 | 4.2 |
| Sum | 230.1 | 99.1 |
| Drop First 20 and Sum | 343.5 | 96.9 |
| Drop Last 20 and Sum | 311.7 | 96.9 |
| Filter | 240.2 | 92.5 |
| Filter With Index | 364.9 | 237.2 |
| Partition | 772.6 | 280.4 |
| Partition With Index | 912.3 | 427.9 |
| Each | 110.2 | 113.3 |
*Benchmarks run on an AWS EC2 r5a.xlarge with 1,000,000 item count, 100 iteration size run 10 times.*
# Important Notes
Have generally tried to push the `@Tail_Call` down from the Vector class and move to calling functions on the range class.
- Expanded benchmarks on Vector
- Added `take` method to Vector
- Added `each_with_index` method to Vector
- Added `filter_with_index` method to Vector
Functioning group_by based of Enso Map.
# Important Notes
This is an initial version which will be used to establish the API.
The grouping map will need to be moved to Java code for performance.
* Move to_upper_case and to_lower_case into to_case
* Add an export, not sure about it
* Implement title case
TODO: some more tests would be good
* Add more tests
* explain title case
* fix todo
* changelog
[The Task](https://www.pivotaltracker.com/story/show/180887253)
A new (+) button on the left-bottom corner appeared. It may be clicked to open searcher in the middle of the scene, as an alternative to tab key.
https://user-images.githubusercontent.com/3919101/154514279-7972ed6a-0203-47cb-9a09-82dba948cf2f.mp4
# Important Notes
* The window_control_buttons::common was extracted to separate crate `ensogl-component-button` almost without change.
* This includes a severe refactoring of adding nodes in general in the Graph Editor. The whole responsibility of adding new nodes (and starting their editing) was moved to Graph Editor - the Project View only reacts for GE events to show searcher properly.
* The status bar was moved from the bottom-left corner to the middle-top of the scene. It does not collide with (+) button, and plays "notification" role anyway.
* The `interface` debug scene was buggy. The problem was with one expression's span-tree. When I replaced it, the scene works.
* I've removed "new searcher" API, as it is completely outdated.
* I've changed code owners of integration tests to GUI team, as it is the team writing mostly the integration tests (int rust)
Implementation of the Text take and drop APIs
- Added `Range.contains` function
- Added `Text_Sub_Range` type
- Added `Text_Utils.index_of` and `Text_Utils.last_index_of` based on ICU StringSearcher
* Add matching mode definitions
* Add stub for new method API and an initial test suite
* Fix tests, implement exact matching
* Implement Regex matching
* changelog
* Add benchmarks
* Wokraround for case insensitive regex locale support
* minor tweaks
* Unify Case_Insensitive
* Update edge cases
* Fix other affected places
* minor style change
* Add a problematic test
* Add a regex test for a similar situation
* Migrate to StringSearch:wq
* Add test cases for scharfes S edge case
* Add problematic Regex Unicode normalization test
* Document the regex accents peculiarity
* Do not apply the normalization in ASCII only mode
* cr
[Task link](#181181203).
This is a reincarnation of PR [3273](https://github.com/enso-org/enso/pull/3273).
The maximum zoom factor of Graph Editor is limited to 1.0x. It is not possible to zoom in from the default camera position.
Debug Mode (activated with `ctrl-shift-d` shortcut) allows to zoom up to 100.0x (the previous behavior of Graph Editor).
If you enable Debug Mode, then zoom in and disable Debug Mode - you won't see the immediate change of zoom factor back to 1.0x. But it will "jump" (with animation) back once you make a zoom in/out event with your controls.
Video:
https://user-images.githubusercontent.com/6566674/154037310-1d166737-353e-4ae6-aca1-f7840571ab16.mp4
# Important Notes
This is a reincarnation of PR [3273](https://github.com/enso-org/enso/pull/3273). There are two changes since that PR:
1. Fixed bug with GeoMap zooming described [here](https://github.com/enso-org/enso/pull/3290). This is done by restricting `ZoomEvent` API so that it will never contain `amount` which is equal to `0.0`.
2. A few refactoring changes from https://github.com/enso-org/enso/pull/3289 to simplify code a bit.
* Integer parse via Longs
* Integer parse via Longs
* Benchmark for Number Parse
* CHANGELOG.md and Natural Order
* Expanded test set
* Number base tests
* Few more negative tests
* Implement Natural_Order and sort_columns
* Starting on Rename
Align Column_Mapping
Add By_Position
Separating off the validation for By_Index so can reuse for rename
By_Position implemented
By_Index implemented
Adjusted behaviour following discussion with Ned, so that renames dominate untouched columns.
Moving to validation style checks for problems
Putting accumulator back
Rename work
* Add Range.find
* More work
* Regex support
Tidy of Unique Name Strategy
* Fix Regex support
* Warning messages
Tests for Unique Naming Strategy
Table rename working
* Database Table rename_columns
Fix for Table
**Must follow up on slice**
* Some tests
* More tests
* Complete test set
(and associated fixes)
* Functional use_first_row_as_names
Tests to go...
* Test for use_first_row_as_names
* Change log
* trailing space
Co-authored-by: Radosław Waśko <radoslaw.wasko@enso.org>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}