By default all polyglot symbols that have been imported were always exported. This means that importing a module that had some polyglot imports brought them into the scope automatically. This didn't follow our desired semantics.
Fixes task 3 in https://www.pivotaltracker.com/story/show/183833055.
- Export all for `Problem_Behavior` (allowing for Report_Warning, Report_Error and Ignore to be trivially used).
- Renamed `Range.Range_Data` to `Range.Value` moved to using `up_to` wherever possible.
- Reviewed `Function`, `IO`, `Polyglot`, `Random`, `Runtime`, `System`.
- `File` now published as type. Some static methods moved to `Data` others into type. Removed `read_bytes` static.
- New `Data` module for reading input data in one place (e.g. `Data.read_file`) will add `Data.connect` later.
- Added `Random` module to the exports.
- Move static methods into `Warning` type and exporting the type not the module.
# Important Notes
- Sorted a few imports into order (ordering by direct import in project, then by from import in project then polyglot and finally self imports).
Upgrading to GraalVM 22.3.0.
# Important Notes
- Removed all deprecated `FrameSlot`, and replaced them with frame indexes - integers.
- Add more information to `AliasAnalysis` so that it also gathers these indexes.
- Add quick build mode option to `native-image` as default for non-release builds
- `graaljs` and `native-image` should now be downloaded via `gu` automatically, as dependencies.
- Remove `engine-runner-native` project - native image is now build straight from `engine-runner`.
- We used to have `engine-runner-native` without `sqldf` in classpath as a workaround for an internal native image bug.
- Fixed chrome inspector integration, such that it shows values of local variables both for current stack frame and caller stack frames.
- There are still many issues with the debugging in general, for example, when there is a polyglot value among local variables, a `NullPointerException` is thrown and no values are displayed.
- Removed some deprecated `native-image` options
- Remove some deprecated Truffle API method calls.
Previously, when exporting the same module multiple times only the first statement would count and the rest would be discarded by the compiler.
This change allows for multiple exports of the same module e.g.,
```
export project.F1
from project.F1 export foo
```
Multiple exports may however lead to conflicts when combined with hiding names. Added logic in `ImportResolver` to detect such scenarios.
This fixes https://www.pivotaltracker.com/n/projects/2539304/stories/183092447
# Important Notes
Added a bunch of scenarios to simulate pos and neg results.
RuntimeStdlibTest now checks that names in type signatures are qualified (aka poor man's typechecker)
Will be merged after the stdlib tidying by James is complete.
Fixes `NullPointerException` in `TreeToIr` by detecting the case and raising `UnexpectedExpression` syntax error.
# Important Notes
This PR prevents the `NullPointerException`. It doesn't change the meaning of `x.` (followed by space) `length`. It just detects when `Tree.OprApp.getRhs() == null` and treats that as an error.
`LocalDate.now()` returns time in system time zone, and git uses UTC. Sometimes it can cause test to fail
```
INFO ide_ci::program::command: sbtℹ️ [info] - must create a commit with a timestamp *** FAILED ***
INFO ide_ci::program::command: sbtℹ️ [info] "2022-11-18T23:05:01.768499800Z" did not start with substring "2022-11-19" (VcsManagerTest.scala:201)
```
- Moved static methods into `Locale` type. Publishing type not module.
- Stop publishing `Nil` and `Cons` from `List`.
- Tidied up `Json` and merged static in to type. Sorted out various type signatures which used a `Constructor`. Now exporting type and extensions.
- Tidied up `Noise` and merge `Generator` into file. Export type not module.
- Moved static method of `Map` into type. Publishing type not module.
# Important Notes
- Move `Text.compare_to` into `Text`.
- Move `Text.to_json` into `Json`.
* Tidy Bound and Interval.
* Fix Interval tests.
* Fix Interval tests.
* Restructure Index_Sub_Range to new Type/Statics.
* Adjust for Vector exported as a type and static methods on it.
* Tidy Maybe.
* Fix issue with Line_Ending_Style.
* Revert Filter_Condition change.
Fix benchmark test issue.
Tidy imports on Index_Sub_Range.
* Revert Filter_Condition change.
Fix benchmark test issue.
Tidy imports on Index_Sub_Range.
* Can't export constructors unless exported from type in module.
* Fix failing tests.
Ignore gitconfig located in the user's home directory when creating Git instance.
For example, I setup git to automatically sign commits. And all git related tests are failing because of that:
```
[info] - should return last X commits *** FAILED ***
[info] org.eclipse.jgit.api.errors.ServiceUnavailableException: Signing service is not available
[info] at org.eclipse.jgit.api.CommitCommand.sign(CommitCommand.java:328)
[info] at org.eclipse.jgit.api.CommitCommand.call(CommitCommand.java:283)
[info] at org.enso.languageserver.vcsmanager.GitSpec$InitialRepoSetup.setup(GitSpec.scala:360)
[info] at org.enso.languageserver.vcsmanager.GitSpec$InitialRepoSetup.setup$(GitSpec.scala:348)
[info] at org.enso.languageserver.vcsmanager.GitSpec$$anon$16.setup(GitSpec.scala:275)
[info] at org.enso.languageserver.vcsmanager.GitSpec$InitialRepoSetup.$init$(GitSpec.scala:346)
[info] at org.enso.languageserver.vcsmanager.GitSpec$$anon$16.<init>(GitSpec.scala:275)
[info] at org.enso.languageserver.vcsmanager.GitSpec.$anonfun$new$35(GitSpec.scala:275)
[info] at org.scalatest.OutcomeOf.outcomeOf(OutcomeOf.scala:85)
[info] at org.scalatest.OutcomeOf.outcomeOf$(OutcomeOf.scala:83)
[info] ...
```
- Allow `Map` to store a `Nothing` key (fixes `Vector.distinct` with a `Nothing`).
- Add `column_names` method to `Table` as a shorthand.
- Return data flow error when comparing with Nothing (not a Panic or a Polyglot exception).
- Allow milli and micro second for DateTime and Time Of Day
# Important Notes
- Added a load of tests for the various comparison operators to Numbers_Spec.
It appears that we were always adding builtin methods to the scope of the module and the builtin type that shared the same name.
This resulted in some methods being accidentally available even though they shouldn't.
This change treats differently builtins of types and modules and introduces auto-registration feature for builtins.
By default all builtin methods are registered with a type, unless explicitly defined in the annotation property.
Builtin methods that are auto-registered do not have to be explicitly defined and are registered with the underlying type.
Registration correctly infers the right type, depending whether we deal with static or instance methods.
Builtin methods that are not auto-registered have to be explicitly defined **always**. Modules' builtin methods are the prime example.
# Important Notes
Builtins now carry information whether they are static or not (inferred from the lack of `self` parameter).
They also carry a `autoRegister` property to determine if a builtin method should be automatically registered with the type.
Two fixes in `EnsoCompilerTest` to align new parser with the previous behavior.
# Important Notes
Removes two `@Ignore` annotations. One test was already working. Another one is fixed by Kaz's idea to ignore _"empty block"_ application.
Libraries: Revert changes that were necessitated by a new rule we have decided not to introduce.
Parser:
- Support mixed constructors/bindings in types.
- Disallow zero-length hex sequences in character escapes: `\x`, `\u`, `\u{}`, `\U`, `\U{}` are no longer legal synonyms for `\0` (matches old parser behavior).
This change adds support for Version Controlled projects in language server.
Version Control supports operations:
- `init` - initialize VCS for a project
- `save` - commit all changes to the project in VCS
- `restore` - ability to restore project to some past `save`
- `status` - show the status of the project from VCS' perspective
- `list` - show a list of requested saves
# Important Notes
Behind the scenes, Enso's VCS uses git (or rather [jGit](https://www.eclipse.org/jgit/)) but nothing stops us from using a different implementation as long as it conforms to the establish API.
Computing length of a text takes time. Let's cache it after first computation.
# Important Notes
Wrote `StringBenchmarks` that sums lengths of (the same) `Text` present many time in a `Vector`. Initially it took `383.673 ms` per operation. Then it took `0.031 ms/op`. Looks like the `length` calls are returning instantly as they get cached.
This PR mimics test cases from #3860 and makes sure `IR.Syntax.Error` is constructed at appropriate places rather than just yielding an `UnhandledEntity` exception.
# Important Notes
Merge before #3611 to minimize disruption when changing the parser.
Another set of improvements extracted from #3611. This time it includes a fix to the Rust part of the parser.
# Important Notes
After digging into metadata parsing I realized the positions used to query the BTree data structure are wrong. This PR tries to address that by re-arranging the order of serialized fields and passing `startCode` and `endCode` locations in.
Originally I though I need changes on the Rust side to support `in` operator. Turned out I can do that just with changes on the Java side.
Qualified names in imports were missing UUIDs. Fixed now.
To minimize differences between #3611 and `develop` branch I propose to make following code changes that seem to work fine with the old as well as new parser. In addition to that there are new tests comparing the two parsers.
# Important Notes
Old parser is still used everywhere except `EnsoCompilerTest` where the test compares `IR`s constructed by both parsers.
Another set of fixes extracted from #3611. `CodeLocationsTest` test has been made more flexible to allow _"off by one"_ differences in the offset locations between the old and new parser.
Fix bugs in `TreeToIr` (rewrite) and parser. Implement more undocumented features in parser. Emulate some old parser bugs and quirks for compatibility.
Changes in libs:
- Fix some bugs.
- Clean up some odd syntaxes that the old parser translates idiosyncratically.
- Constructors are now required to precede methods.
# Important Notes
Out of 221 files:
- 215 match the old parser
- 6 contain complex types the old parser is known not to handle correctly
So, compared to the old parser, the new parser parses 103% of files correctly.
This PR adds `Period` type, which is a date-only complement to `Duration` builtin type.
# Important Notes
- `Period` replaces `Date_Period`, and `Time_Period`.
- Added shorthand constructors for `Duration` and `Period`. For example: `Period.days 10` instead of `Period.new days=10`.
- `Period` can be compared to other `Period` in some cases, other cases throw an error.
Define start of Enso epoch as 15th of October 1582 - start of the Gregorian calendar.
# Important Notes
- Some (Gregorian) calendar related functionalities within `Date` and `Date_Time` now produces a warning if the receiving Date/Date_Time is before the epoch start, e.g., `week_of_year`, `is_leap_year`, etc.
1. Changes how we do monadic state – rather than a haskelly solution, we now have an implicit env with mutable data inside. It's better for the JVM. It also opens the possibility to have state ratained on exceptions (previously not possible) – both can now be implemented.
2. Introduces permission check system for IO actions.
Moved loading of Builtin Types and Methods to a static initializer. That way the information is available at Native Image build time and one does not have to update a corresponding entry in `reflect-config` which would be a real pain when we start using it in anger.
Fixes https://www.pivotaltracker.com/story/show/183374932
Most of the time, rather than defining the type of the parameter of the builtin, we want to accept every Array-like object i.e. Vector, Array, polyglot Array etc.
Rather than writing all possible combinations, and likely causing bugs on the way anyway as we already saw, one should use `CoerceArrayNode` to convert to Java's `Object[]`.
Added various test cases to illustrate the problem.
Another part of #3611 with few more `TreeToIr` improvements.
# Important Notes
Unofficial `LoadParser.sh` check from #3611 of all library files now reports just 54 failures out of 222 files - e.g. 75% success rate.
A new test to verify that some `Standard.Base` library files can be parsed by the new parser is added. Use it as:
```bash
$ sbt bootstrap
$ sbt buildEngineDistribution
$ sbt "runtime/testOnly *ParseStdLibTest"
```
By having this test instantly available we can block integration of PRs that would decrease the number of parseable files or introduce new files that aren't paseable.
# Important Notes
The test contains a _black list_ of classes that are currently known to fail. Over the time the _black list_ shall get smaller and smaller.
The main culprit of a Vector slowdown (when compared to Array) was the normalization of the index when accessing the elements. Turns out that the Graal was very persistent on **not** inlining that particular fragment and that was degrading the results in benchmarks.
Being unable to force it to do it (looks like a combination of thunk execution and another layer of indirection) we resorted to just moving the normalization to the builtin method. That makes Array and Vector perform roughly the same.
Moved all handling of invalid index into the builtin as well, simplifying the Enso implementation. This also meant that `Vector.unsafe_at` is now obsolete.
Additionally, added support for negative indices in Array, to behave in the same way as for Vector.
# Important Notes
Note that this workaround only addresses this particular perf issue. I'm pretty sure we will have more of such scenarios.
Before the change `averageOverVector` benchmark averaged around `0.033 ms/op` now it does consistently `0.016 ms/op`, similarly to `averageOverArray`.
Another part of #3611 ready for integration into `develop` branch.
# Important Notes
Test `org.enso.compiler.EnsoCompilerTest.testTestGroup` is ignored as it has problems with source offsets - identifiers don't have the appropriate names due to `Tree.codeRepr()` being _off_.
Improve `Unsupported_Argument_Types` error so that it includes the message from the original exception. `arguments` field is retained, but not included in `to_display_text` method.
- Special precedence rules for case-of so that `:` operator works without parens or nospace-grouping.
- Support an old-lambda syntax: `x->x-> x`. According to the usual rules, the first nospace group would be parsed as an operator section. The expression now parses as a lambda that contains a lambda.
- Match old parser treatment of # in doc comments.
- Tweak precedence so (a : B = c) works.
- Documented constructors.
Trying to invoke a foreign method with non-installed language (either not enabled in the Truffle `Context`, or not installed in the GraalVM distribution) results in `Polyglot_Error`, rather than crashing the entire engine.
- Reimplement the `Duration` type to a built-in type.
- `Duration` is an interop type.
- Allow Enso method dispatch on `Duration` interop coming from different languages.
# Important Notes
- The older `Duration` type should now be split into new `Duration` builtin type and a `Period` type.
- This PR does not implement `Period` type, so all the `Period`-related functionality is currently not working, e.g., `Date - Period`.
- This PR removes `Integer.milliseconds`, `Integer.seconds`, ..., `Integer.years` extension methods.
When trying to resolve an invalid method of a polyglot array we were reaching a state where no specialization applied.
Turns out we can now simplify the logic of inferring polyglot call type for arrays and avoid the crash.
- Implement macro-contexts-lite (`from` is now only a keyword at the beginning of a line)
- Support special nospace-group handling for old lambdas (so expressions like this work: `x-> y-> x + y`)
- Fix a text-escape incompatibility
# Important Notes
- There is now an `OperatorFunction`, which is like a `Function` but has an operator for a name, and likewise an `OperatorTypeSignature`.
Can't instantiate the associated type:
```
Exception in thread "main" java.lang.UnsupportedOperationException: Unsupported operation Value.newInstance(Object...) for 'Internal_Repl_Module___'(language: Java, type: com.oracle.truffle.polyglot.PolyglotMap). You can ensure that the operation is supported using Value.canInstantiate().
at org.graalvm.truffle/com.oracle.truffle.polyglot.PolyglotEngineException.unsupported(PolyglotEngineException.java:137)
at org.graalvm.truffle/com.oracle.truffle.polyglot.PolyglotValueDispatch.unsupported(PolyglotValueDispatch.java:1257)
at org.graalvm.truffle/com.oracle.truffle.polyglot.PolyglotValueDispatch.newInstanceUnsupported(PolyglotValueDispatch.java:613)
at org.graalvm.truffle/com.oracle.truffle.polyglot.PolyglotValueDispatch$InteropValue$NewInstanceNode.doCached(PolyglotValueDispatch.java:4382)
...
```
# Important Notes
I thought we had a CI check that would prevent us from introducing such regressions?
EDIT: we don't
`.find(...)` wasn't equivalent to `.map(...).exists(identity)` in this case because of side-effects related to diagnostics reporting. That is why we were reporting errors only for the first erroneous module.
/cc @jdunkerley
c&p failure, so it was generating a very small Vector. Surprisingly, it indicates similar problems with `@ExplodeLoop` in `CatchTypeBranchNode`.
Kudos to @JaroslavTulach for reporting it.
Missing `@TruffleBoundary` annotations and entries in the configs were preventing us from generating native image. Again.
# Important Notes
@mwu-tow This check is easy to miss so it would be good to have it in CI.
Changelog
- fix reporting of runtime type for values annotated with warning
- fix visualizations of values annotated with warnings
- fix `Runtime.get_stack_trace` failure in interactive mode
This change brings by-type pattern matching to Enso.
One can pattern match on Enso types as well as on polyglot types.
For example,
```
case x of
_ : Integer -> ...
_ : Text -> ...
_ -> ...
```
as well as Java's types
```
case y of
_ : ArrayList -> ...
_ : List -> ...
_ : AbstractList -> ...
_ -> ..
```
It is no longer possible to match a value with a corresponding type constructor.
For example
```
case Date.now of
Date -> ...
```
will no longer match and one should match on the type (`_ : Date`) instead.
```
case Date of
Date -> ...
```
is fine though, as requested in the ticket.
The change required further changes to `type_of` logic which wasn't dealing well with polyglot values.
Implements https://www.pivotaltracker.com/story/show/183188846
# Important Notes
~I discovered late in the game that nested patterns involving type patterns, such as `Const (f : Foo) tail -> ...` are not possible due to the old parser logic.
I would prefer to add it in a separate PR because this one is already getting quite large.~ This is now supported!
PR adds special kind of jobs for visualizations. It should
- prevent cancelling visualization jobs when the program is re-executed (resulting in the fact that visualization is not showing up)
- omit unnecessary executions of visualization jobs (the case when the user goes through menu items in the component browser)
I skipped the tests because testing of the last scenario involves indeterminism. I.e. when preparing the test, we can't control which of submitted visualization jobs will be actually executed, and which will be cancelled.
When nodes get invalidated in the cache, they have to be recomputed. Let the IDE know which of the nodes are pending by sending `Api.ExpressionUpdate.Payload.Pending` message.
# Important Notes
This PR introduces new `Api.ExpressionUpdate.Payload.Pending` message. This message is delivered before re-computation of nodes. Later `Api.ExpressionUpdate.Payload.Value` or other is sent to notify the IDE that a value for given node is available.
Trivial implementation of of the `Api.ExpressionUpdate.Payload.Pending` message in the IDE is provided by this PR to (improperly) visualize pending node status - further improvements needed in follow up PRs.
Each builtin `makeFunction` method has to be currently registered for reflection. Adding registration of `SliceVectorMethodGen` to make following example work ag
```bash
enso$ sbt engine-runner-native/buildNativeImage
enso$ ./runner --run engine/runner-native/src/test/resources/Factorial.enso 6
```
# Important Notes
Regression caused by #3724 - Once the above code is executed in the CI, we'll discover such breakages before integration.
Makes statics static. A type and its instances have different methods defined on them, as it should be. Constructors are now scoped in types, and can be imported/exported.
# Important Notes
The method of fixing stdlib chosen here is to just not. All the conses are exported to make all old code work. All such instances are marked with `TODO Dubious constructor export` so that it can be found and fixed.
This change implements a simple `type_of` method that returns a type of a given value, including for polyglot objects.
The change also allows for pattern matching on various time-related instances. It is a nice-to-have on its own, but it was primarily needed here to write some tests. For equality checks on types we currently can't use `==` due to a known _feature_ which essentially does wrong dispatching. This will be improved in the upcoming statics PR so we agreed that there is no point in duplicating that work and we can replace it later.
Also, note that this PR changes `Meta.is_same_object`. Comparing types revealed that it was wrong when comparing polyglot wrappers over the same value.
Use an `ArraySlice` to slice `Vector`.
Avoids memory copying for the slice function.
# Important Notes
| Test | Ref | New |
| --- | --- | --- |
| New Vector | 71.9 | 71.0 |
| Append Single | 26.0 | 27.7 |
| Append Large | 15.1 | 14.9 |
| Sum | 156.4 | 165.8 |
| Drop First 20 and Sum | 171.2 | 165.3 |
| Drop Last 20 and Sum | 170.7 | 163.0 |
| Filter | 76.9 | 76.9 |
| Filter With Index | 166.3 | 168.3 |
| Partition | 278.5 | 273.8 |
| Partition With Index | 392.0 | 393.7 |
| Each | 101.9 | 102.7 |
- Note: the performance of New and Append has got slower from previous tests.
This PR adds a possibility to generate native-image for engine-runner.
Note that due to on-demand loading of stdlib, programs that make use of it are currently not yet supported
(that will be resolved at a later point).
The purpose of this PR is only to make sure that we can generate a bare minimum runner because due to lack TruffleBoundaries or misconfiguration in reflection config, this can get broken very easily.
To generate a native image simply execute:
```
sbt> engine-runner-native/buildNativeImage
... (wait a few minutes)
```
The executable is called `runner` and can be tested via a simple test that is in the resources. To illustrate the benefits
see the timings difference between the non-native and native one:
```
>time built-distribution/enso-engine-0.0.0-dev-linux-amd64/enso-0.0.0-dev/bin/enso --no-ir-caches --in-project test/Tests/ --run engine/runner-native/src/test/resources/Factorial.enso 6
720
real 0m4.503s
user 0m9.248s
sys 0m1.494s
> time ./runner --run engine/runner-native/src/test/resources/Factorial.enso 6
720
real 0m0.176s
user 0m0.042s
sys 0m0.038s
```
# Important Notes
Notice that due to a [bug in GraalVM](https://github.com/oracle/graal/issues/4200), which is already fixed in 22.x, and us still being on 21.x for the time being, I had to add a workaround to our sbt build to build a different fat jar for native image. To workaround it I had to exclude sqlite jar. Hence native image task is on `engine-runner-native` and not on `engine-runner`.
Will need to add the above command to CI.
Turns that if you import a two-part import we had special code that would a) add Main submodule b) add an explicit rename.
b) is problematic because sometimes we only want to import specific names.
E.g.,
```
from Bar.Foo import Bar, Baz
```
would be translated to
```
from Bar.Foo.Main as Foo import Bar, Baz
```
and it should only be translated to
```
from Bar.Foo.Main import Bar, Baz
```
This change detects this scenario and does not add renames in that case.
Fixes [183276486](https://www.pivotaltracker.com/story/show/183276486).
IR cache never really took into account a situation when a binding from the imported module has changed. In other words, it would continue to happily use the serialized metadata without noticing that it changed.
This change forces cache invalidation when any of the imported modules was invalidated (or rather not loaded from cache).
# Important Notes
Added simple test infrastructure that simulates file modifications that would trigger the initial cache invalidation.
If they succeed, cache invalidation is propagated thus causing an error.
`Vector` type is now a builtin type. This requires a bunch of additional builtin methods for its creation:
- Use `Vector.from_array` to convert any array-like structure into a `Vector` [by copy](f628b28f5f)
- Use (already existing) `Vector.from_polyglot_array` to convert any array-like structure into a `Vector` **without** copying
- Use (already existing) `Vector.fill 1 item` to create a singleton `Vector`
Additional, for pattern matching purposes, we had to implement a `VectorBranchNode`. Use following to match on `x` being an instance of `Vector` type:
```
import Standard.Base.Data.Vector
size = case x of
Vector.Vector -> x.length
_ -> 0
```
Finally, `VectorLiterals` pass that transforms `[1,2,3]` to (roughly)
```
a1 = 1
a2 = 2
a3 = 3
Vector (Array (a1,a2, a3))
```
had to be modified to generate
```
a1 = 1
a2 = 2
a3 = 3
Vector.from_array (Array (a1, a2, a3))
```
instead to accomodate to the API changes. As of 025acaa676 all the known CI checks passes. Let's start the review.
# Important Notes
Matching in `case` statement is currently done via `Vector_Data`. Use:
```
case x of
Vector.Vector_Data -> True
```
until a better alternative is found.
The goal of this request is to simplify hello world and other trivial Enso programs. No need to learn any standard library functions, enough to write:
```
main = "Hello World!"
```
and the result is going to be printed:
```bash
enso$ ./built-distribution/enso-engine-0.0.0-dev-linux-amd64/enso-0.0.0-dev/bin/enso --run hello.enso
'Hello World!'
```
the result is only printed, if it is not `Nothing`. E.g. if the last statement is `IO.print ...` (which returns `Nothing`), then no value is printed at the end by the launcher.
Many engine PRs modify builtins or other engine internals and then they are subject to [incremental CI runtime errors](https://www.pivotaltracker.com/n/projects/2539304/stories/182868680) as outdated `IR` caches from global space at `~/.local/share/enso/cache/ir/Standard/Builtins/0.0.0-dev/0.0.0-dev/Standard/Builtins` are read in.
This PR provides solution for that problem by explicitly defining `IR.Module` `serialVersionUID`. By changing the `serialVersionUID` one prevents previously saved `IR` caches to be loaded into the running process. Change the `serialVersionUID` whenever you see errors caused by reading outdated `IR` caches in the CI.
# Important Notes
Whenever one needs to avoid loading previous `IR` caches, go to `case class IR.Module` and change the `@SerialVersionUID(3692L)` to **number of your pull request**.
Found a bug when accessing keys via `get(constructor)`. Providing a test and a fix.
# Important Notes
Marcin, is it correct that the whole set of members of `End` is: `[head, tail, Int, is_empty, IntList]`? What does `Int` and `IntList` do there? Shall test test check for their presence? **Answer**: rename `Int` and `IntList` to lowercase and yes, then the members shall be there. Done in [ca9f42a](ca9f42a2b8).
This is a step towards the new language spec. The `type` keyword now means something. So we now have
```
type Maybe a
Some (from_some : a)
None
```
as a thing one may write. Also `Some` and `None` are not standalone types now – only `Maybe` is.
This halfway to static methods – we still allow for things like `Number + Number` for backwards compatibility. It will disappear in the next PR.
The concept of a type is now used for method dispatch – with great impact on interpreter code density.
Some APIs in the STDLIB may require re-thinking. I take this is going to be up to the libraries team – some choices are not as good with a semantically different language. I've strived to update stdlib with minimal changes – to make sure it still works as it did.
It is worth mentioning the conflicting constructor name convention I've used: if `Foo` only has one constructor, previously named `Foo`, we now have:
```
type Foo
Foo_Data f1 f2 f3
```
This is now necessary, because we still don't have proper statics. When they arrive, this can be changed (quite easily, with SED) to use them, and figure out the actual convention then.
I have also reworked large parts of the builtins system, because it did not work at all with the new concepts.
It also exposes the type variants in SuggestionBuilder, that was the original tiny PR this was based on.
PS I'm so sorry for the size of this. No idea how this could have been smaller. It's a breaking language change after all.
- Added `Zone`, `Date_Time` and `Time_Of_Day` to `Standard.Base`.
- Renamed `Zone` to `Time_Zone`.
- Added `century`.
- Added `is_leap_year`.
- Added `length_of_year`.
- Added `length_of_month`.
- Added `quarter`.
- Added `day_of_year`.
- Added `Day_Of_Week` type and `day_of_week` function.
- Updated `week_of_year` to support ISO.
# Important Notes
- Had to pass locale to formatter for date/time tests to work on my PC.
- Changed default of `week_of_year` to use ISO.
Implements https://www.pivotaltracker.com/story/show/182879865
# Important Notes
Note that removing `set_at` still does not make our arrays fully immutable - `Array.copy` can still be used to mutate them.
* Builtin Date_Time, Time_Of_Day, Zone
Improved polyglot support for Date_Time (formerly Time), Time_Of_Day and
Zone. This follows the pattern introduced for Enso Date.
Minor caveat - in tests for Date, had to bend a lot for JS Date to pass.
This is because JS Date is not really only a Date, but also a Time and
Timezone, previously we just didn't consider the latter.
Also, JS Date does not deal well with setting timezones so the trick I
used is to first call foreign function returning a polyglot JS Date,
which is converted to ZonedDateTime and only then set the correct
timezone. That way none of the existing tests had to be changes or
special cased.
Additionally, JS deals with milliseconds rather than nanoseconds so
there is loss in precision, as noted in Time_Spec.
* Add tests for Java's LocalTime
* changelog
* Make date formatters in table happy
* PR review, add more tests for zone
* More tests and fixed a bug in column reader
Column reader didn't take into account timezone but that was a mistake
since then it wouldn't map to Enso's Date_Time.
Added tests that check it now.
* remove redundant conversion
* Update distribution/lib/Standard/Base/0.0.0-dev/src/Data/Time.enso
Co-authored-by: Radosław Waśko <radoslaw.wasko@enso.org>
* First round of addressing PR review
* don't leak java exceptions in Zone
* Move Date_Time to top-level module
* PR review
Co-authored-by: Radosław Waśko <radoslaw.wasko@enso.org>
Co-authored-by: Jaroslav Tulach <jaroslav.tulach@enso.org>
Use Proxy_Polyglot_Array as a proxy for polyglot arrays, thus unifying
the way the underlying array is accessed in Vector.
Used the opportunity to cleanup builtin lookup, which now actually
respects what is defined in the body of @Builtin_Method annotation.
Also discovered that polyglot null values (in JS, Python and R) were leaking to Enso.
Fixed that by doing explicit translation to `Nothing`.
https://www.pivotaltracker.com/story/show/181123986
This change adds support for matching on constants by:
1) extending parser to allow literals in patterns
2) generate branch node for literals
Related to https://www.pivotaltracker.com/story/show/182743559
This change adds Autosave action for open buffers. The action is scheduled
after every edit request and is cancelled by every explicit save file request, if
necessary. Successful autosave also notifies any active clients of the buffer.
Related to https://www.pivotaltracker.com/story/show/182721656
# Important Notes
WIP
Execution of `sbt runtime/bench` doesn't seem to be part of the gate. As such it can happen a change into the Enso language syntax, standard libraries, runtime & co. can break the benchmarks suite without being noticed. Integrating such PR causes unnecessary disruptions to others using the benchmarks.
Let's make sure verification of the benchmarks (e.g. that they compile and can execute without error) is part of the CI.
# Important Notes
Currently the gate shall fail. The fix is being prepared in parallel PR - #3639. When the two PRs are combined, the gate shall succeed again.
PR allows to attach metod pointers as a visualization expressions. This way it allows to attach a runtime instrument that enables caching of intermediate expressions.
# Important Notes
ℹ️ API is backward compatible.
To attach the visualization with caching support, the same `executionContext/attachVisualisation` method is used, but `VisualisationConfig` message should contain the message pointer.
While `VisualisationConfiguration` message has changed, the language server accepts both new and old formats to keep visualisations working in IDE.
#### Old format
```json
{
"executionContextId": "UUID",
"visualisationModule": "local.Unnamed.Main",
"expression": "x -> x.to_text"
}
```
#### New format
```json
{
"executionContextId": "UUID",
"expression": {
"module": "local.Unnamed.Main",
"definedOnType": "local.Unnamed.Main",
"name": "encode"
}
}
```
`main` method is now special because it is trully static i.e. no
implicit `self` is being generated for it.
But since REPL's `main` isn't called `main` its invocation was missing
an argument.
Follow up on https://github.com/enso-org/enso/pull/3569
# Important Notes
Will work on adding a CI test for REPL to avoid problems with REPL in a
follow up PR.
Importing individual methods didn't work as advertised because parser
would allow them but later drop that information. This slipped by because we never had mixed atoms and methods in stdlib.
# Important Notes
Added some basic tests but we need to ensure that the new parser allows for this.
@jdunkerley will be adding some changes to stdlib that will be testing this functionality as well.
This change allows for importing modules using a qualified name and deals with any conflicts on the way.
Given a module C defined at `A/B/C.enso` with
```
type C
type C a
```
it is now possible to import it as
```
import project.A
...
val x = A.B.C 10
```
Given a module located at `A/B/C/D.enso`, we will generate
intermediate, synthetic, modules that only import and export the successor module along the path.
For example, the contents of a synthetic module B will look like
```
import <namespace>.<pkg-name>.A.B.C
export <namespace>.<pkg-name>.A.B.C
```
If module B is defined already by the developer, the compiler will _inject_ the above statements to the IR.
Also removed the last elements of some lowercase name resolution that managed to survive recent
changes (`Meta.Enso_Project` would now be ambiguous with `enso_project` method).
Finally, added a pass that detects shadowing of the synthetic module by the type defined along the path.
We print a warning in such a situation.
Related to https://www.pivotaltracker.com/n/projects/2539304
# Important Notes
There was an additional request to fix the annoying problem with `from` imports that would always bring
the module into the scope. The changes in stdlib demonstrate how it is now possible to avoid the workaround of
```
from X.Y.Z as Z_Module import A, B
```
(i.e. `as Z_Module` part is almost always unnecessary).
This change modifies the current language by requiring explicit `self` parameter declaration
for methods. Methods without `self` parameter in the first position should be treated as statics
although that is not yet part of this PR. We add an implicit self to all methods
This obviously required updating the whole stdlib and its components, tests etc but the change
is pretty straightforward in the diff.
Notice that this change **does not** change method dispatch, which was removed in the last changes.
This was done on purpose to simplify the implementation for now. We will likely still remove all
those implicit selfs to bring true statics.
Minor caveat - since `main` doesn't actually need self, already removed that which simplified
a lot of code.
Significantly improves the polyglot Date support (as introduced by #3374). It enhances the `Date_Spec` to run it in four flavors:
- with Enso Date (as of now)
- with JavaScript Date
- with JavaScript Date wrapped in (JavaScript) array
- with Java LocalDate allocated directly
The code is then improved by necessary modifications to make the `Date_Spec` pass.
# Important Notes
James has requested in [#181755990](https://www.pivotaltracker.com/n/projects/2539304/stories/181755990) - e.g. _Review and improve InMemory Table support for Dates, Times, DateTimes, BigIntegers_ the following program to work:
```
foreign js dateArr = """
return [1, new Date(), 7]
main =
IO.println <| (dateArr.at 1).week_of_year
```
the program works with here in provided changes and prints `27` as of today.
@jdunkerley has provided tests for proper behavior of date in `Table` and `Column`. Those tests are working as of [f16d07e](f16d07e640). One just needs to accept `List<Value>` and then query `Value` for `isDate()` when needed.
Last round of changes is related to **exception handling**. 8b686b12bd makes sure `makePolyglotError` accepts only polyglot values. Then it wraps plain Java exceptions into `WrapPlainException` with `has_type` method - 60da5e70ed - the remaining changes in the PR are only trying to get all tests working in the new setup.
The support for `Time` isn't part of this PR yet.
There is an Unsafe.set_atom_field operation in Standard library. That operation allows one to create an infinite data structure. Store following program in ones.enso:
```
import Standard.Base.IO
import Standard.Base.Runtime.Unsafe
type Gen
type Empty
type Generator a:Int tail:Gen
ones : Gen
ones =
g = Generator 1 Empty
Unsafe.set_atom_field g 1 g
g
main =
IO.println here.ones
```
running such program then leads to (probably expectable) stack overflow exception:
```
Execution finished with an error: Resource exhausted: Stack overflow
at <enso> Any.to_text(Internal)
...
at <enso> Any.to_text(Internal)
at <enso> Any.to_text(Internal)
at <enso> Any.to_text(Internal)
at <enso> IO.println(Internal)
at <enso> g.main(g.enso:15:5-24)
```
However the bigger problem is that it also crashes our debugger. While producing guest Stack overflow when the guest program is running maybe OK, crashing the engine doesn't seem tolerable.
Try:
```
enso-engine-0.0.0-dev-linux-amd64/enso-0.0.0-dev/bin/enso --inspect --run ones.enso
```
and navigate Chrome dev tools to the line 11 as shown on the attached picture.
Stepping over that line generates following error:
```
at org.enso.interpreter.runtime.callable.atom.Atom.toString(Atom.java:84)
at org.enso.interpreter.runtime.callable.atom.Atom.lambda$toString$0(Atom.java:79)
at java.base/java.util.stream.ReferencePipeline$3$1.accept(ReferencePipeline.java:195)
at java.base/java.util.Spliterators$ArraySpliterator.forEachRemaining(Spliterators.java:948)
at java.base/java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:484)
at java.base/java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:474)
at java.base/java.util.stream.ReduceOps$ReduceOp.evaluateSequential(ReduceOps.java:913)
at java.base/java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234)
at java.base/java.util.stream.ReferencePipeline.collect(ReferencePipeline.java:578)
```
Stack overflow in the engine when computing `Atom.toString()` - I want to prevent that.
# Important Notes
I am able to see a stacktrace in the debugger and I can _step in_ and _step over_, @kustosz:

However there are extra items like `case_branch` which I'd like to avoid, would you know how to do that?
More and more often I need a way to only recover a specific type of a dataflow error (in a similar manner as with panics). So the API for `Error.catch` has been amended to more closely resemble `Panic.catch`, allowing to handle only specific types of dataflow errors, passing others through unchanged. The default is `Any`, meaning all errors are caught by default, and the behaviour of `x.catch` remains unchanged.
Modified UppercaseNames to now resolve methods without an explicit `here` to point to the current module.
`here` was also often used instead of `self` which was allowed by the compiler.
Therefore UppercaseNames pass is now GlobalNames and does some extra work -
it translated method calls without an explicit target into proper applications.
# Important Notes
There was a long-standing bug in scopes usage when compiling standalone expressions.
This resulted in AliasAnalysis generating incorrect graphs and manifested itself only in unit tests
and when running `eval`, thus being a bit hard to locate.
See `runExpression` for details.
Additionally, method name resolution is now case-sensitive.
Obsolete passes like UndefinedVariables and ModuleThisToHere were removed. All tests have been adapted.
Adds support for appending to an existing Excel table.
# Important Notes
- Renamed `Column_Mapping` to `Column_Name_Mapping`
- Changed new type name to `Map_Column`
- Added last modified time and creation time to `File`.
Truffle is using [MultiTier compilation](190e0b2bb7) by default since 21.1.0. That mean every `RootNode` is compiled twice. However benchmarks only care about peak performance. Let's return back the previous behavior and compile only once after profiling in interpreter.
# Important Notes
This change does not influence the peak performance. Just the amount of IGV graphs produced from benchmarks when running:
```
enso$ sbt "project runtime" "withDebug --dumpGraphs benchOnly -- AtomBenchmark"
```
is cut to half.
Try following enso program:
```
main =
here.debug
foreign js debug = """
debugger;
```
it crashes the engine with exception:
```
Execution finished with an error: java.lang.ClassCastException: class com.oracle.truffle.js.runtime.builtins.JSFunctionObject$Unbound cannot be cast to class org.enso.interpreter.runtime.callable.CallerInfo (com.oracle.truffle.js.runtime.builtins.JSFunctionObject$Unbound and org.enso.interpreter.runtime.callable.CallerInfo are in unnamed module of loader com.oracle.graalvm.locator.GraalVMLocator$GuestLangToolsLoader @55cb6996)
at <java> org.enso.interpreter.runtime.callable.function.Function$ArgumentsHelper.getCallerInfo(Function.java:352)
at <java> org.enso.interpreter.instrument.ReplDebuggerInstrument$ReplExecutionEventNodeImpl.onEnter(ReplDebuggerInstrument.java:179)
at <java> org.graalvm.truffle/com.oracle.truffle.api.instrumentation.ProbeNode$EventProviderChainNode.innerOnEnter(ProbeNode.java:1397)
at <java> org.graalvm.truffle/com.oracle.truffle.api.instrumentation.ProbeNode$EventChainNode.onEnter(ProbeNode.java:912)
at <java> org.graalvm.truffle/com.oracle.truffle.api.instrumentation.ProbeNode.onEnter(ProbeNode.java:216)
at <java> com.oracle.truffle.js.nodes.JavaScriptNodeWrapper.execute(JavaScriptNodeWrapper.java:44)
at <java> com.oracle.truffle.js.nodes.control.DiscardResultNode.execute(DiscardResultNode.java:88)
at <java> com.oracle.truffle.js.nodes.function.FunctionBodyNode.execute(FunctionBodyNode.java:73)
at <java> com.oracle.truffle.js.nodes.JavaScriptNodeWrapper.execute(JavaScriptNodeWrapper.java:45)
at <java> com.oracle.truffle.js.nodes.function.FunctionRootNode.executeInRealm(FunctionRootNode.java:150)
at <java> com.oracle.truffle.js.runtime.JavaScriptRealmBoundaryRootNode.execute(JavaScriptRealmBoundaryRootNode.java:93)
at <js> <js> poly_enso_eval(Unknown)
at <epb> <epb> null(Unknown)
at <enso> Prg.debug(Prg.enso:27-28)
```
`AtomBenchmarks` are broken since the introduction of [micro distribution](https://github.com/enso-org/enso/pull/3531). The micro distribution doesn't contain `Range` and as such one cannot use `1.up_to` method.
# Important Notes
I have rewritten enso code to manual `generator`. The results of the benchmark seem comparable. Executed as:
```
sbt:runtime> benchOnly AtomBenchmarks
```
I was modifying `Date_Spec.enso` today and made a mistake. When executing with I could see the error, but the process got stuck...
```
enso/test/Tests/src/Data/Time$ ../../../../built-distribution/enso-engine-0.0.0-dev-linux-amd64/enso-0.0.0-dev/bin/enso --run Date_Spec.enso In module Date_Spec:
Compiler encountered warnings:
Date_Spec.enso[14:29-14:37]: Unused function argument parseDate.
Compiler encountered errors:
Date_Spec.enso[18:13-18:20]: Variable `debugger` is not defined.
Exception in thread "main" Compilation aborted due to errors.
at org.graalvm.sdk/org.graalvm.polyglot.Value.invokeMember(Value.java:932)
at org.enso.polyglot.Module.getAssociatedConstructor(Module.scala:19)
at org.enso.runner.Main$.runMain(Main.scala:755)
at org.enso.runner.Main$.runSingleFile(Main.scala:695)
at org.enso.runner.Main$.run(Main.scala:582)
at org.enso.runner.Main$.main(Main.scala:1031)
at org.enso.runner.Main.main(Main.scala)
^C
```
...had to kill it with Ctrl-C. This PR fixes the problem by moving `getAssociatedConstructor` call into `try` block, catching the exception and exiting properly.
This PR adds sources for Enso language support in IGV (and NetBeans). The support is based on TextMate grammar shown in the editor and registration of the Enso language so IGV can find it. Then this PR adds new GitHub Actions workflow file to build the project using Maven.
A semi-manual s/this/self appied to the whole standard library.
Related to https://www.pivotaltracker.com/story/show/182328601
In the compiler promoted to use constants instead of hardcoded
`this`/`self` whenever possible.
# Important Notes
The PR **does not** require explicit `self` parameter declaration for methods as this part
of the design is still under consideration.
This PR merges existing variants of `LiteralNode` (`Integer`, `BigInteger`, `Decimal`, `Text`) into a single `LiteralNode`. It adds `PatchableLiteralNode` variant (with non `final` `value` field) and uses `Node.replace` to modify the AST to be patchable. With such change one can remove the `UnwindHelper` workaround as `IdExecutionInstrument` now sees _patched_ return values without any tricks.
This introduces a tiny alternative to our stdlib, that can be used for testing the interpreter. There are 2 main advantages of such a solution:
1. Performance: on my machine, `runtime-with-intstruments/test` drops from 146s to 65s, while `runtime/test` drops from 165s to 51s. >6 mins total becoming <2 mins total is awesome. This alone means I'll drink less coffee in these breaks and will be healthier.
2. Better separation of concepts – currently working on a feature that breaks _all_ enso code. The dependency of interpreter tests on the stdlib means I have no means of incremental testing – ALL of stdlib must compile. This is horrible, rendered my work impossible, and resulted in this PR.
New plan to [fix the `sbt` build](https://www.pivotaltracker.com/n/projects/2539304/stories/182209126) and its annoying:
```
log.error(
"Truffle Instrumentation is not up to date, " +
"which will lead to runtime errors\n" +
"Fixes have been applied to ensure consistent Instrumentation state, " +
"but compilation has to be triggered again.\n" +
"Please re-run the previous command.\n" +
"(If this for some reason fails, " +
s"please do a clean build of the $projectName project)"
)
```
When it is hard to fix `sbt` incremental compilation, let's restructure our project sources so that each `@TruffleInstrument` and `@TruffleLanguage` registration is in individual compilation unit. Each such unit is either going to be compiled or not going to be compiled as a batch - that will eliminate the `sbt` incremental compilation issues without addressing them in `sbt` itself.
fa2cf6a33ec4a5b2e3370e1b22c2b5f712286a75 is the first step - it introduces `IdExecutionService` and moves all the `IdExecutionInstrument` API up to that interface. The rest of the `runtime` project then depends only on `IdExecutionService`. Such refactoring allows us to move the `IdExecutionInstrument` out of `runtime` project into independent compilation unit.
Auto-generate all builtin methods for builtin `File` type from method signatures.
Similarly, for `ManagedResource` and `Warning`.
Additionally, support for specializations for overloaded and non-overloaded methods is added.
Coverage can be tracked by the number of hard-coded builtin classes that are now deleted.
## Important notes
Notice how `type File` now lacks `prim_file` field and we were able to get rid off all of those
propagating method calls without writing a single builtin node class.
Similarly `ManagedResource` and `Warning` are now builtins and `Prim_Warnings` stub is now gone.
Drop `Core` implementation (replacement for IR) as it (sadly) looks increasingly
unlikely this effort will be continued. Also, it heavily relies
on implicits which increases some compilation time (~1sec from `clean`)
Related to https://www.pivotaltracker.com/story/show/182359029
@radeusgd discovered that no formatting was being applied to std-bits projects.
This was caused by the fact that `enso` project didn't aggregate them. Compilation and
packaging still worked because one relied on the output of some tasks but
```
sbt> javafmtAll
```
didn't apply it to `std-bits`.
# Important Notes
Apart from `build.sbt` no manual changes were made.
This is the 2nd part of DSL improvements that allow us to generate a lot of
builtins-related boilerplate code.
- [x] generate multiple method nodes for methods/constructors with varargs
- [x] expanded processing to allow for @Builtin to be added to classes and
and generate @BuiltinType classes
- [x] generate code that wraps exceptions to panic via `wrapException`
annotation element (see @Builtin.WrapException`
Also rewrote @Builtin annotations to be more structured and introduced some nesting, such as
@Builtin.Method or @Builtin.WrapException.
This is part of incremental work and a follow up on https://github.com/enso-org/enso/pull/3444.
# Important Notes
Notice the number of boilerplate classes removed to see the impact.
For now only applied to `Array` but should be applicable to other types.
Promoted `with`, `take`, `finalize` to be methods of Managed_Resource
rather than static methods always taking `resource`, for consistency
reasons.
This required function dispatch boilerplate, similarly to `Ref`.
In future iterations we will address this boilerplate code.
Related to https://www.pivotaltracker.com/story/show/182212217
The change promotes static methods of `Ref`, `get` and `put`, to be
methods of `Ref` type.
The change also removes `Ref` module from the default namespace.
Had to mostly c&p functional dispatch for now, in order for the methods
to be found. Will auto-generate that code as part of builtins system.
Related to https://www.pivotaltracker.com/story/show/182138899
Before, when running Enso with `-ea`, some assertions were broken and the interpreter would not start.
This PR fixes two very minor bugs that were the cause of this - now we can successfully run Enso with `-ea`, to test that any assertions in Truffle or in our own libraries are indeed satisfied.
Additionally, this PR adds a setting to SBT that ensures that IntelliJ uses the right language level (Java 17) for our projects.
A low-hanging fruit where we can automate the generation of many
@BuiltinMethod nodes simply from the runtime's methods signatures.
This change introduces another annotation, @Builtin, to distinguish from
@BuiltinType and @BuiltinMethod processing. @Builtin processing will
always be the first stage of processing and its output will be fed to
the latter.
Note that the return type of Array.length() is changed from `int` to
`long` because we probably don't want to add a ton of specializations
for the former (see comparator nodes for details) and it is fine to cast
it in a small number of places.
Progress is visible in the number of deleted hardcoded classes.
This is an incremental step towards #181499077.
# Important Notes
This process does not attempt to cover all cases. Not yet, at least.
We only handle simple methods and constructors (see removed `Array` boilerplate methods).
In order to analyse why the `runner.jar` is slow to start, let's _"self sample"_ it using the [sampler library](https://bits.netbeans.org/dev/javadoc/org-netbeans-modules-sampler/org/netbeans/modules/sampler/Sampler.html). As soon as the `Main.main` is launched, the sampling starts and once the server is up, it writes its data into `/tmp/language-server.npss`.
Open the `/tmp/language-server.npss` with [VisualVM](https://visualvm.github.io) - you should have one copy in your
GraalVM `bin/jvisualvm` directory and there has to be a GraalVM to run Enso.
#### Changelog
- add: the `MethodsSampler` that gathers information in `.npss` format
- add: `--profiling` flag that enables the sampler
- add: language server processes the updates in batches
Finally this pull request proposes `--inspect` option to allow [debugging of `.enso`](e948f2535f/docs/debugger/README.md) in Chrome Developer Tools:
```bash
enso$ ./built-distribution/enso-engine-0.0.0-dev-linux-amd64/enso-0.0.0-dev/bin/enso --inspect --run ./test/Tests/src/Data/Numbers_Spec.enso
Debugger listening on ws://127.0.0.1:9229/Wugyrg9Nm4OUL9YhzdcElmLft71ayZW3LMUPCdPyNAY
For help, see: https://www.graalvm.org/tools/chrome-debugger
E.g. in Chrome open: devtools://devtools/bundled/js_app.html?ws=127.0.0.1:9229/Wugyrg9Nm4OUL9YhzdcElmLft71ayZW3LMUPCdPyNAY
```
copy the printed URL into chrome browser and you should see:
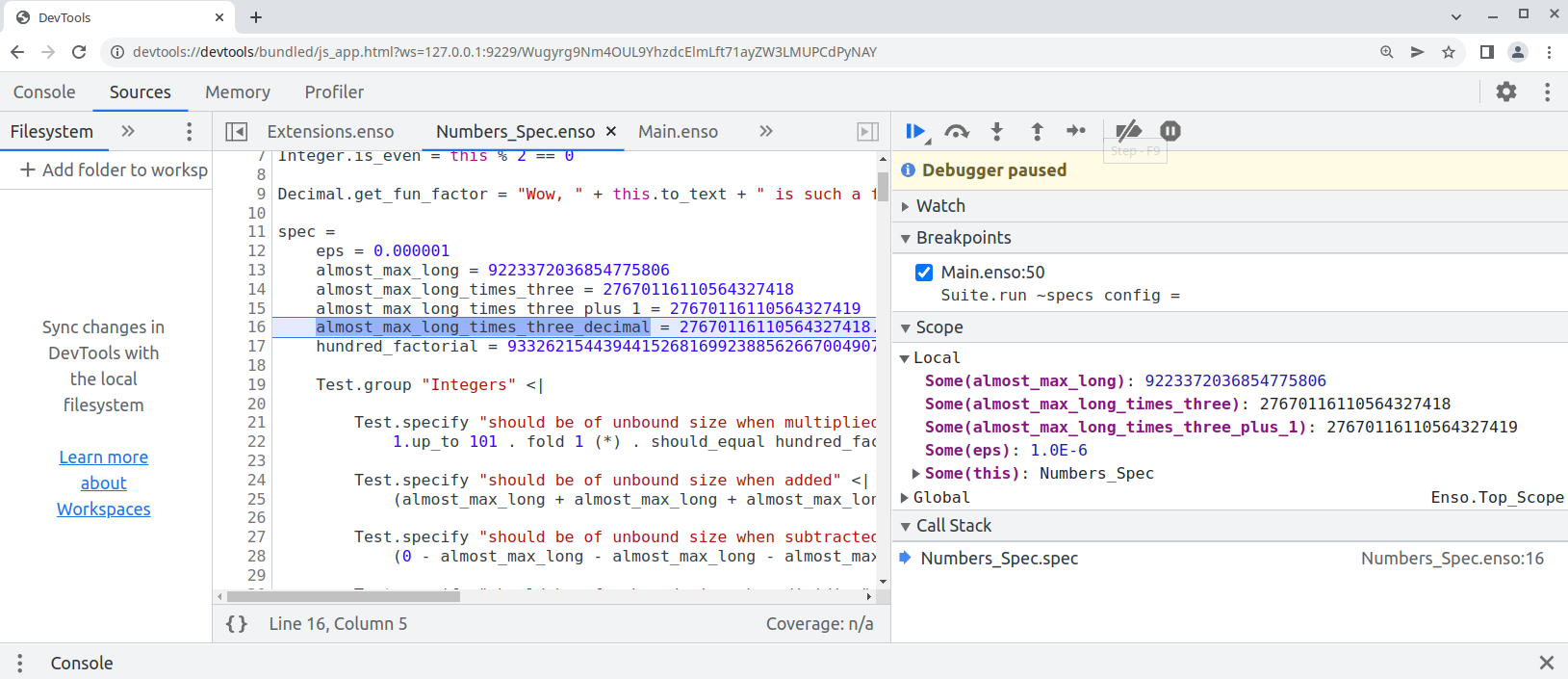
One can also debug the `.enso` files in NetBeans or [VS Code with Apache Language Server extension](https://cwiki.apache.org/confluence/display/NETBEANS/Apache+NetBeans+Extension+for+Visual+Studio+Code) just pass in special JVM arguments:
```bash
enso$ JAVA_OPTS=-agentlib:jdwp=transport=dt_socket,server=y,address=8000 ./built-distribution/enso-engine-0.0.0-dev-linux-amd64/enso-0.0.0-dev/bin/enso --run ./test/Tests/src/Data/Numbers_Spec.enso
Listening for transport dt_socket at address: 8000
```
and then _Debug/Attach Debugger_. Once connected choose the _Toggle Pause in GraalVM Script_ button in the toolbar (the "G" button):
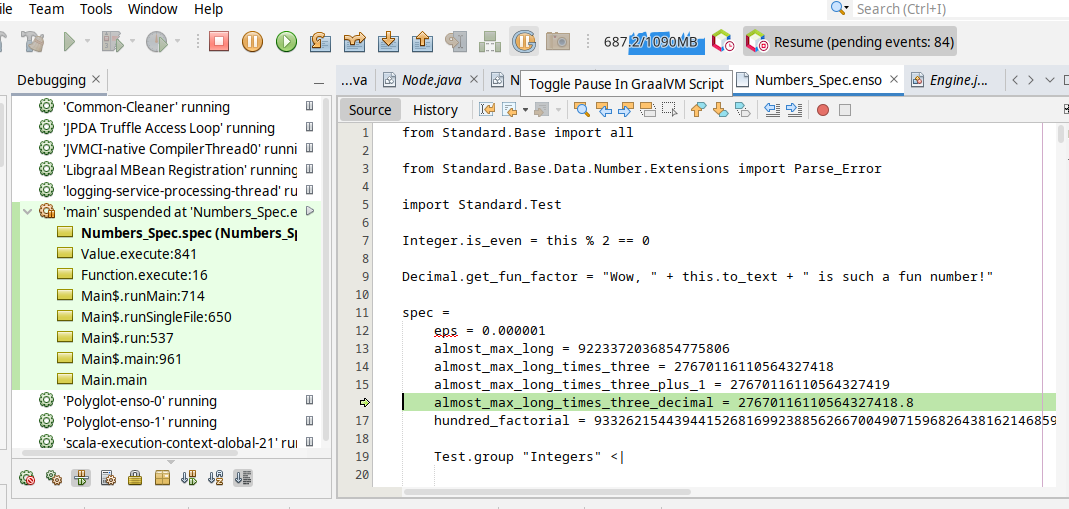
and your execution shall stop on the next `.enso` line of code. This mode allows to debug both - the Enso code as well as Java code.
Originally started as an attempt to write test in Java:
* test written in Java
* support for JUnit in `build.sbt`
* compile Java with `-g` - so it can be debugged
* Implementation of `StatementNode` - only gets created when `materialize` request gets to `BlockNode`
Debug is not imported by default (let me know if it should be?)
# Important Notes
When Debug was part of Builtins.enso everything was imported. Let me know if the new setup is not as expected.
This PR replaces hard-coded `@Builtin_Method` and `@Builtin_Type` nodes in Builtins with an automated solution
that a) collects metadata from such annotations b) generates `BuiltinTypes` c) registers builtin methods with corresponding
constructors.
The main differences are:
1) The owner of the builtin method does not necessarily have to be a builtin type
2) You can now mix regular methods and builtin ones in stdlib
3) No need to keep track of builtin methods and types in various places and register them by hand (a source of many typos or omissions as it found during the process of this PR)
Related to #181497846
Benchmarks also execute within the margin of error.
### Important Notes
The PR got a bit large over time as I was moving various builtin types and finding various corner cases.
Most of the changes however are rather simple c&p from Builtins.enso to the corresponding stdlib module.
Here is the list of the most crucial updates:
- `engine/runtime/src/main/java/org/enso/interpreter/runtime/builtin/Builtins.java` - the core of the changes. We no longer register individual builtin constructors and their methods by hand. Instead, the information about those is read from 2 metadata files generated by annotation processors. When the builtin method is encountered in stdlib, we do not ignore the method. Instead we lookup it up in the list of registered functions (see `getBuiltinFunction` and `IrToTruffle`)
- `engine/runtime/src/main/java/org/enso/interpreter/runtime/callable/atom/AtomConstructor.java` has now information whether it corresponds to the builtin type or not.
- `engine/runtime/src/main/scala/org/enso/compiler/codegen/RuntimeStubsGenerator.scala` - when runtime stubs generator encounters a builtin type, based on the @Builtin_Type annotation, it looks up an existing constructor for it and registers it in the provided scope, rather than creating a new one. The scope of the constructor is also changed to the one coming from stdlib, while ensuring that synthetic methods (for fields) also get assigned correctly
- `engine/runtime/src/main/scala/org/enso/compiler/codegen/IrToTruffle.scala` - when a builtin method is encountered in stdlib we don't generate a new function node for it, instead we look it up in the list of registered builtin methods. Note that Integer and Number present a bit of a challenge because they list a whole bunch of methods that don't have a corresponding method (instead delegating to small/big integer implementations).
During the translation new atom constructors get initialized but we don't want to do it for builtins which have gone through the process earlier, hence the exception
- `lib/scala/interpreter-dsl/src/main/java/org/enso/interpreter/dsl/MethodProcessor.java` - @Builtin_Method processor not only generates the actual code fpr nodes but also collects and writes the info about them (name, class, params) to a metadata file that is read during builtins initialization
- `lib/scala/interpreter-dsl/src/main/java/org/enso/interpreter/dsl/MethodProcessor.java` - @Builtin_Method processor no longer generates only (root) nodes but also collects and writes the info about them (name, class, params) to a metadata file that is read during builtins initialization
- `lib/scala/interpreter-dsl/src/main/java/org/enso/interpreter/dsl/TypeProcessor.java` - Similar to MethodProcessor but handles @Builtin_Type annotations. It doesn't, **yet**, generate any builtin objects. It also collects the names, as present in stdlib, if any, so that we can generate the names automatically (see generated `types/ConstantsGen.java`)
- `engine/runtime/src/main/java/org/enso/interpreter/node/expression/builtin` - various classes annotated with @BuiltinType to ensure that the atom constructor is always properly registered for the builitn. Note that in order to support types fields in those, annotation takes optional `params` parameter (comma separated).
- `engine/runtime/src/bench/scala/org/enso/interpreter/bench/fixtures/semantic/AtomFixtures.scala` - drop manual creation of test list which seemed to be a relict of the old design
A draft of simple changes to the compiler to expose sum type information. Doesn't break the stdlib & at the same time allows for dropdowns. This is still broken, for example it doesn't handle exporting/importing types, only ones defined in the same module as the signature. Still, seems like a step in the right direction – please provide feedback.
# Important Notes
I've decided to make the variant info part of the type, not the argument – it is a property of the type logically.
Also, I've pushed it as far as I'm comfortable – i.e. to the `SuggestionHandler` – I have no idea if this is enough to show in IDE? cc @4e6
Most of the functions in the standard library aren't gonna be invoked during particular program execution. It makes no sense to build their Truffle AST for the functions that are not executing. Let's delay the construction of the tree until a function is first executed.
Changelog:
- fix: `search/completion` request with the position parameter.
- fix: `refactoring/renameProject` request. Previously it did not take into account the library namespace (e.g. `local.`)
[ci no changelog needed]
# Important Notes
The REPL used to use some builtin Java text representation leading to outputs like this:
```
> [1,2,3]
>>> Vector [1, 2, 3]
> 'a,b,c'.split ','
>>> Vector JavaObject[[Ljava.lang.String;@131c0b6f (java.lang.String[])]
```
This PR makes it use `to_text` (if available, otherwise falling back to regular `toString`). This way we get outputs like this:
```
> [1,2,3]
>>> [1, 2, 3]
> 'a,b,c'.split ','
>>> ['a', 'b', 'c']
```
Result of automatic formatting with `scalafmtAll` and `javafmtAll`.
Prerequisite for https://github.com/enso-org/enso/pull/3394
### Important Notes
This touches a lot of files and might conflict with existing PRs that are in progress. If that's the case, just run
`scalafmtAll` and `javafmtAll` after merge and everything should be in order since formatters should be deterministic.
Changelog:
- add: component groups to package descriptions
- add: `executionContext/getComponentGroups` method that returns component groups of libraries that are currently loaded
- doc: cleanup unimplemented undo/redo commands
- refactor: internal component groups datatype
PR adds a monitor that handles messages between the language server and the runtime and dumps them as a CSV file `/tmp/enso-api-events-*********.csv`
```
UTC timestamp,Direction,Request Id,Message class
```
# Important Notes
⚠️ Monitor is enabled when the log level is set to trace. You should pass `-vv` (very verbose) option to the backend when starting IDE
```
enso -- -vv
```
Implements https://www.pivotaltracker.com/story/show/181805693 and finishes the basic set of features of the Aggregate component.
Still not all aggregations are supported everywhere, because for example SQLite has quite limited support for aggregations. Currently the workaround is to bring the table into memory (if possible) and perform the computation locally. Later on, we may add more complex generator features to emulate the missing aggregations with complex sub-queries.
Implements infrastructure for new aggregations in the Database. It comes with only some basic aggregations and limited error-handling. More aggregations and problem handling will be added in subsequent PRs.
# Important Notes
This introduces basic aggregations using our existing codegen and sets-up our testing infrastructure to be able to use the same aggregate tests as in-memory backend for the database backends.
Many aggregations are not yet implemented - they will be added in subsequent tasks.
There are some TODOs left - they will be addressed in the next tasks.
The mechanism follows a similar approach to what is being in functions
with default arguments.
Additionally since InstantiateAtomNode wasn't a subtype of EnsoRootNode it
couldn't be used in the application, which was the primary reason for
issue #181449213.
Alternatively InstantiateAtomNode could have been enhanced to extend
EnsoRootNode rather than RootNode to carry scope info but the former
seemed simpler.
See test cases for previously crashing and invalid cases.
- Added Minimum, Maximum, Longest. Shortest, Mode, Percentile
- Added first and last to Map
- Restructured Faker type more inline with FakerJS
- Created 2,500 row data set
- Tests for group_by
- Performance tests for group_by
Following the Slice and Array.Copy experiment, took just the Array.Copy parts out and built into the Vector class.
This gives big performance wins in common operations:
| Test | Ref | New |
| --- | --- | --- |
| New Vector | 41.5 | 41.4 |
| Append Single | 26.6 | 4.2 |
| Append Large | 26.6 | 4.2 |
| Sum | 230.1 | 99.1 |
| Drop First 20 and Sum | 343.5 | 96.9 |
| Drop Last 20 and Sum | 311.7 | 96.9 |
| Filter | 240.2 | 92.5 |
| Filter With Index | 364.9 | 237.2 |
| Partition | 772.6 | 280.4 |
| Partition With Index | 912.3 | 427.9 |
| Each | 110.2 | 113.3 |
*Benchmarks run on an AWS EC2 r5a.xlarge with 1,000,000 item count, 100 iteration size run 10 times.*
# Important Notes
Have generally tried to push the `@Tail_Call` down from the Vector class and move to calling functions on the range class.
- Expanded benchmarks on Vector
- Added `take` method to Vector
- Added `each_with_index` method to Vector
- Added `filter_with_index` method to Vector
This changes intends to cleanup some directories that are being left
behind after running `sbt test`:
- a random `foobar` directory was being created in the `engine` project
directory
- every run of a test suite would add more temporary directories in `/tmp`
The change does not make use of `deleteOnExit` which can pretty
unreliable. Instead we recursively delete files in directories and
directories to make sure nothing is left behind.
* Implement conversions
start wip branch for conversion methods for collaborating with marcin
add conversions to MethodDispatchLibrary (wip)
start MethodDispatchLibrary implementations
conversions for atoms and functions
Implement a bunch of missing conversion lookups
final bug fixes for merged methoddispatchlibrary implementations
UnresolvedConversion.resolveFor
progress on invokeConversion
start extracting constructors (still not working)
fix a bug
add some initial conversion tests
fix a bug in qualified name resolution, test conversions accross modules
implement error reporting, discover a ton of ignored errors...
start fixing errors that we exposed in the standard library
fix remaining standard lib type errors not caused by the inability to parse type signatures for operators
TODO: fix type signatures for operators. all of them are broken
fix type signature parsing for operators
test cases for meta & polyglot
play nice with polyglot
start pretending unresolved conversions are unresolved symbols
treat UnresolvedConversons as UnresolvedSymbols in enso user land
* update RELEASES.md
* disable test error about from conversions being tail calls. (pivotal issue #181113110)
* add changelog entry
* fix OverloadsResolutionTest
* fix MethodDefinitionsTest
* fix DataflowAnalysisTest
* the field name for a from conversion must be 'that'. Fix remaining tests that aren't ExpressionUpdates vs. ExecutionUpdate behavioral changes
* fix ModuleThisToHereTest
* feat: suppress compilation errors from Builtins
* Revert "feat: suppress compilation errors from Builtins"
This reverts commit 63d069bd4f.
* fix tests
* fix: formatting
Co-authored-by: Dmitry Bushev <bushevdv@gmail.com>
Co-authored-by: Marcin Kostrzewa <marckostrzewa@gmail.com>
* Moving distinct to Map
* Mixed Type Comparable Wrapper
* Missing Bracket
Still an issue with `Integer` in the mixed vector test
* PR comments
* Use naive approach for mixed types
* Enable pending test
* Performance timing function
* Handle incomparable types cleanly
* Tidy up the time_execution function
* PR comments.
* Change log
- Add parser & handler in IDE for `executionContext/visualisationEvaluationFailed` message from Engine (fixes a developer console error "Failed to decode a notification: unknown variant `executionContext/visualisationEvaluationFailed`"). The contents of the error message will now be properly deserialized and printed to Dev Console with appropriate details.
- Fix a bug in an Enso code snippet used internally by the IDE for error visualizations preprocessing. The snippet was using not currently supported double-quote escaping in double-quote delimited strings. This lack of processing is actually a bug in the Engine, and it was reported to the Engine team, but changing the strings to single-quoted makes the snippet also more readable, so it sounds like a win anyway.
- A test is also added to the Engine CI, verifying that the snippet compiles & works correctly, to protect against similar regressions in the future.
Related: #2815
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}