| .. | ||
| bench_countdown_1000.png | ||
| bench_countdown_2000.png | ||
| bench_countdown_3000.png | ||
| bench_filesize_1000.png | ||
| bench_filesize_2000.png | ||
| bench_filesize_3000.png | ||
| README.md | ||
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Benchmarks
Introduction
The benchmark suite of effectful compares performance of the most popular
extensible effects libraries in several scenarios. It implements two benchmarks:
-
countdown - a microbenchmark that effectively measures performance of monadic binds and the effect dispatch.
-
filesize - a more down to earth benchmark that does various things, including I/O.
Each benchmark has two flavours that affect the amount of effects available in the context:
-
shallow - only effects necessary for the benchmark.
-
deep - necessary effects + 5 redundant effects put into the context before and after the relevant ones (10 in total). This simulates a typical scenario in which the code uses only a portion of the total amount of effects available to the application.
Moreover, the benchmarked code was annotated with NOINLINE pragmas to prevent
GHC from inlining it and/or specializing away type class constraints related to
effects. This is crucial in order to get realistic results, as for any
non-trivial, multi-module application the compiler will not be able to do this
as that would essentially mean performing whole program specialization.
Results
The code was compiled with GHC 9.2.3 and run on a Ryzen 9 5950x.
Note: below results are from a 1000 iteration run. Runs with more iterations are not included in the analysis since they are proportionally the same, but can be found here.
Countdown

Analysis:
-
effectfultakes the lead. Its static dispatch is on par with the reference implementation that uses theSTmonad, so it offers no additional overhead. Its dynamic dispatch is also very fast. -
cleffuses similar implementation techniques aseffectful(the only major difference is that its internal environment that stores effects is immutable), so they trade blows:- Its thread-local
Stateis only slightly slower thaneffectful. - Its
Stateimplemented viaIORefis the fastest of the dynamically dispatched effects, but it's worth noting that it's neither properly thread-local nor shared as the underlyingIORefis shared, but can't be safely accessed withgetandputfrom multiple threads.
- Its thread-local
-
freer-simpledoes surprisingly well for a solution that's based on free monads. -
mtlcomes next and unfortunately here's when the conventional wisdom stating that it is fast crumbles. The deep version is 50 times slower than the reference implementation!This is a direct consequence of how type classes are compiled. To be more precise, during compilation type class constraints are translated by the compiler to regular arguments. These arguments are class dictionaries, i.e. data types containing all functions that the type class contains.
Now, because usage of
mtlstyle effects requires the monad to be polymorphic, such functions at runtime are passed a dictionary ofMonadspecific methods and have to call them. In particular, this applies to the monadic bind. That's the crux of a problem - bind is called in between every monadic operation, so making it a function call has a disastrous effect on performance.Why is the result for the deep stack so much worse than for the shallow one though? It's because in reality, each call to bind performs O(n) function calls, where n is the number of monad transformers on the stack. That's because the implementation of bind for every monad transformer refers to the bind of a monad it transforms.
Compare that to
effectful, where monadic binds are known function calls and can be eliminated by the compiler. What is more, the only piece of data passed via class constraints are dictionaries of:>, each represented by a singleIntpointing at the place in the stack where the relevant effect is located. -
fused-effectsexhibits similar behavior asmtl. This comes as no surprise since it uses the same implementation techniques. It augments them with additional machinery for convenience, which seems to add even more overhead though. -
polysemyis based on free monads just asfreer-simpleand performs similarly, though with a much higher initial overhead.
Filesize
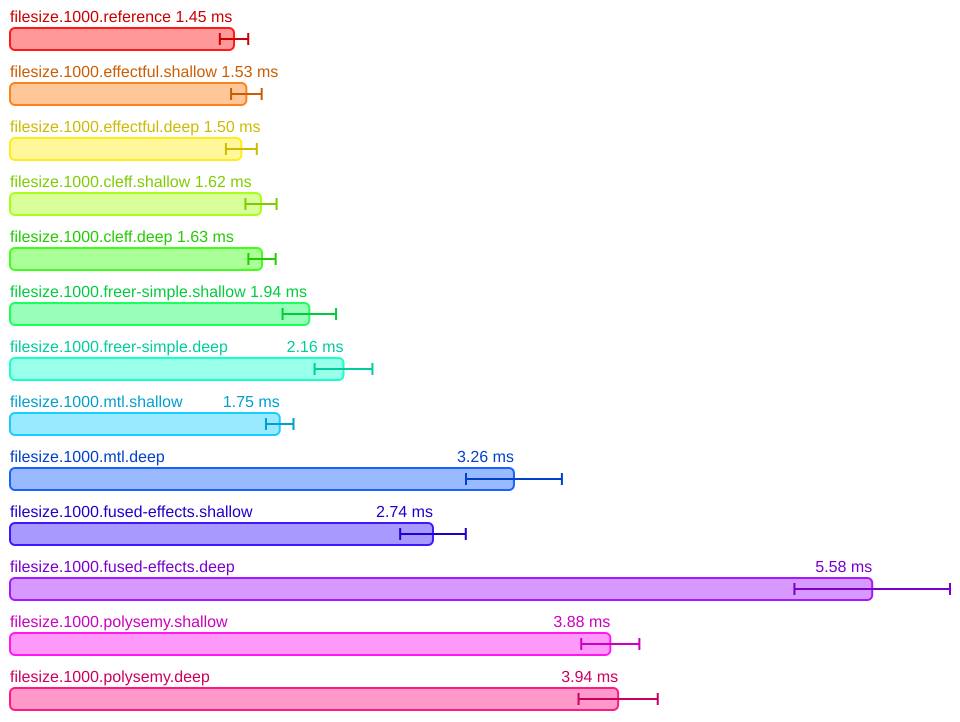
The results are similar to the ones of the countdown benchmark. It's worth noting though that introduction of other effects and I/O makes the difference in performance between libraries not nearly as pronounced.