mirror of
https://github.com/hasura/graphql-engine.git
synced 2024-12-15 01:12:56 +03:00
164 lines
13 KiB
Markdown
164 lines
13 KiB
Markdown
|
|
# 借助 GraphQL 承载 100万活动订阅(实时查询)
|
|||
|
|
|
|||
|
|
Hasura 是基于 Postgres数据库的 GraphQL 引擎,提供可控制权限的开箱即用的 GraphQL API。到 [hasura.io](https://hasura.io/) 和 [github.com/hasura/graphql-engine](https://github.com/hasura/graphql-engine) 了解更多。
|
|||
|
|
|
|||
|
|
Hasura 可为客户端提供实时查询(基于 GraphQL 订阅)。例如,一个外卖应用使用实时查询显示某特定用户的订单实时状态。
|
|||
|
|
|
|||
|
|
本文档描述 Hasura 的架构,阐述它是如何支撑百万个并发实时查询的。
|
|||
|
|
|
|||
|
|
##### 目录
|
|||
|
|
- [结论](#结论)
|
|||
|
|
- [GraphQL 与订阅](#GraphQL-与订阅)
|
|||
|
|
- [实现 GraphQL 实时查询](#实现-GraphQL-实时查询)
|
|||
|
|
- [再获取 GraphQL 查询结果](#再获取-GraphQL-查询结果)
|
|||
|
|
- [Hasura 的方法](#Hasura-的方法)
|
|||
|
|
- [测试](#测试)
|
|||
|
|
- [本方法的优势](#本方法的优势)
|
|||
|
|
|
|||
|
|
## 结论
|
|||
|
|
|
|||
|
|
**设置:** 每个客户端(Web 或 移动应用)用认证令牌登录并订阅一个实时查询结果。数据存放于 Postgres 数据库。每秒钟更新 Postgres 数据库中的一百万行数据,并确保推送一个新查询结果到客户端。Hasura 是 GraphQL API 的提供者(包含授权)。
|
|||
|
|
|
|||
|
|
**测试:** Hasura 可以并发处理多少个客户端的实施订阅?Hasura 是否可以纵向或横向性能伸缩扩展?
|
|||
|
|
|
|||
|
|
<img src="https://storage.googleapis.com/graphql-engine-cdn.hasura.io/img/subscriptions-images/main-image-fs8.png" width="500px" />
|
|||
|
|
|
|||
|
|

|
|||
|
|
|
|||
|
|
|单例配置| 活动实时查询数量 | CPU 平均负载 |
|
|||
|
|
|--------|----------------|--------------|
|
|||
|
|
| 1xCPU, 2GB RAM | 5000 | 60% |
|
|||
|
|
| 2xCPU, 4GB RAM | 10000 | 73% |
|
|||
|
|
| 4xCPU, 8GB RAM | 20000 | 90% |
|
|||
|
|
|
|||
|
|
<img alt="results-horizontally-scaled" src="https://storage.googleapis.com/graphql-engine-cdn.hasura.io/img/subscriptions-images/horizontal-scalability.png" width="80%" />
|
|||
|
|
|
|||
|
|
当一百万个实时查询的时候,Postgres 的负载不超过 28%,连接数峰值在 850 左右。
|
|||
|
|
|
|||
|
|
关于配置的说明:
|
|||
|
|
- AWS RDS postgres, Fargate, 使用 ELB 的默认配置,无任何微调
|
|||
|
|
- RDS Postgres: 16xCPU, 64GB RAM, Postgres 11
|
|||
|
|
- Hasura 运行在 Fargate (4xCPU, 8GB RAM per instance) ,采用默认配置
|
|||
|
|
|
|||
|
|
## GraphQL 与订阅
|
|||
|
|
|
|||
|
|
GraphQL 让应用开发者轻松地从 API 中精确获取他们想要的数据。
|
|||
|
|
|
|||
|
|
比如,我们要创建一个外卖应用。Postgres 的架构看起来像这样:
|
|||
|
|
|
|||
|
|
<img src="https://storage.googleapis.com/graphql-engine-cdn.hasura.io/img/subscriptions-images/pg-schema.png" alt="postgres schema for food delivery app" width="700px" style="width: 60%; min-width: 400px;" />
|
|||
|
|
|
|||
|
|
应用界面会显示当前用户订单的状态,GraphQL 查询会获取订单最新状态和配送员的定位。
|
|||
|
|
|
|||
|
|
<img alt="order-graphql-query" src="https://storage.googleapis.com/graphql-engine-cdn.hasura.io/img/subscriptions-images/images2/basic-query-fs8.png" width="700px" style="width: 70%; min-width: 400px;" />
|
|||
|
|
|
|||
|
|
在底层,查询被当作字符串发送给服务器,经解析、授权后,从数据库中获取应用所需的数据。返回的 JSON 数据结构与请求时的相同。
|
|||
|
|
|
|||
|
|
进入实时查询:实时查询的主意是订阅特定查询的最新结果。一旦底层的数据改变,服务器应该推送最新结果到客户端。
|
|||
|
|
|
|||
|
|
乍一看,这完美符合 GraphQL 的使用场景,因为 GraphQL 客户端支持处理大量 websocket 连接。用 subscription 替换 query 就能转换查询到实时查询。就是这么简单,如果 GraphQL 服务器可实现的话。
|
|||
|
|
|
|||
|
|
<img alt="order-subscription-query" src="https://storage.googleapis.com/graphql-engine-cdn.hasura.io/img/subscriptions-images/images2/subscription-query-fs8.png" width="700px" style="width: 70%; min-width: 400px;" />
|
|||
|
|
|
|||
|
|
## 实现 GraphQL 实时查询
|
|||
|
|
|
|||
|
|
实现实时查询是个痛苦的过程。当你的数据库查询包含授权规则,那么当变更事件发生时,会增加查询结果的计算量。这在 web服务上是一个挑战。像 Postgres 这样的数据库,这相当于在底层表更改时,要保持物化视图最新一样困难困难。另一种方法是为特定查询重新获取全部数据(针对特定授权规则的客户端)。这是我们目前采取的方法。
|
|||
|
|
|
|||
|
|
其次,构建一个 web服务以一种可伸缩的方式来处理 websockets 有时也有点麻烦,但是某些框架和语言确实使并发编程更容易处理。
|
|||
|
|
|
|||
|
|
### 再获取 GraphQL 查询结果
|
|||
|
|
|
|||
|
|
为了理解为什么这里使用再获取(refetching) GraphQL 查询不好,我们来看一个典型的 GraphQL 查询过程:
|
|||
|
|
|
|||
|
|
<img alt="graphql-resolvers" src="https://storage.googleapis.com/graphql-engine-cdn.hasura.io/img/subscriptions-images/resolvers-fs8.png" width="700px" style="width: 70%; min-width: 400px;" />
|
|||
|
|
|
|||
|
|
在 GraphQL 查询中,授权 + 数据获取逻辑必须为每个节点运行一次。这很可怕,因为即使稍大一点的查询都会轻易拖垮数据库。运用 ORM 不当时,N+1 问题也是个常见问题,这对数据库性能不好,且难以优化 Postgres 查询。Data loader 类型模式可以缓解该问题,但在底层仍然会多次查询 Postgres 数据库(减少为 GraphQL 查询中有多少个节点)。
|
|||
|
|
|
|||
|
|
实时查询中,该问题更为严重,因为每个客户端的查询都有一个独一无二的再获取。尽管查询是相同的,考虑到授权规则创建不同的会话变量,每个客户端需要单独的再获取。
|
|||
|
|
|
|||
|
|
### Hasura 的方法
|
|||
|
|
|
|||
|
|
如何做得更好?如果申明式映射数据模型到 GraphQL 模式,并使用它创建单个 SQL 数据库查询?这样就能避免多次捣鼓数据库,无论返回中是否有大量项目或 GraphQL 查询中有很多节点。
|
|||
|
|
|
|||
|
|
#### 主意 #1:编译 一个 GraphQL 查询为单个 SQL 查询
|
|||
|
|
|
|||
|
|
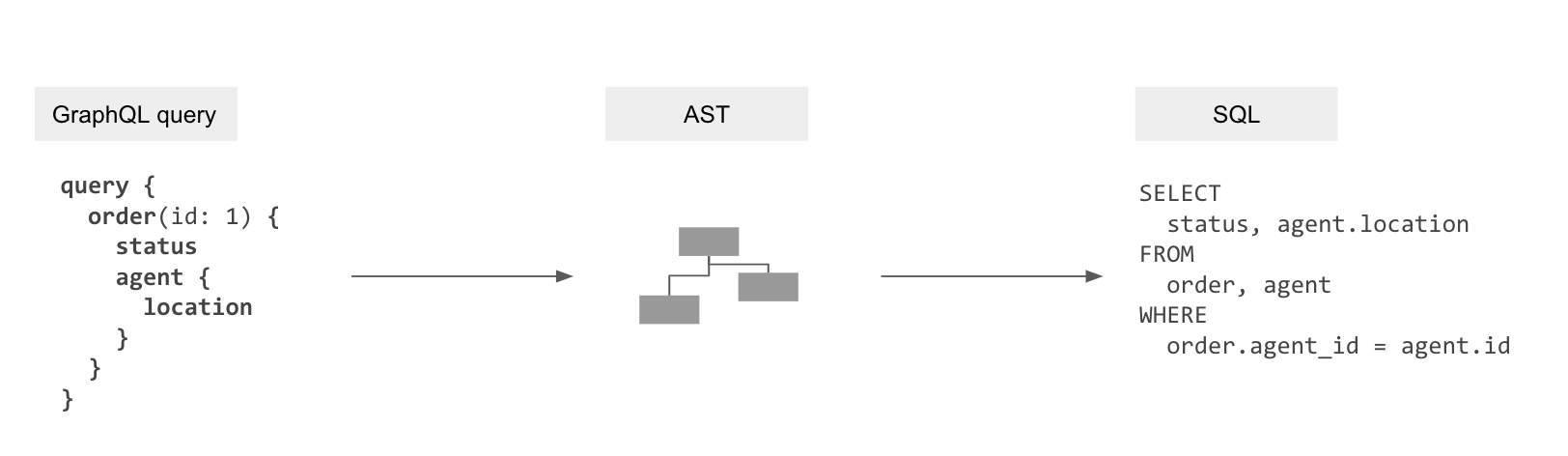
Hasura 部分功能是作为转译器,它使用数据模型到 GraphQL 模式的映射信息的元数据,编译 GraphQL 查询为 SQL 查询,来从数据库获取数据。
|
|||
|
|
|
|||
|
|
GraphQL 查询 GraphQL 抽象语法树(AST) SQL 抽象语法树 SQL
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
这消除了 N+1 查询问题,并允许数据库优化数据获取。
|
|||
|
|
|
|||
|
|
但这不够,因为解析器(resolver)还应用了授权来强制它只获取权限范围内的数据。因此我们需要将授权规则嵌入到生成的 SQL 中。
|
|||
|
|
|
|||
|
|
#### 主意 #2:使授权具有声明性
|
|||
|
|
|
|||
|
|
访问数据时的授权本质上是一种约束,它取决于所获取的数据(或行)的值,以及动态提供的应用程序特定用户的会话变量。例如最普通的,一行数据包含表示数据所有权的字段 `user_id`。或有个关联表 `document_viewers` 来表示用户可查看哪些文档。其他场景中,会话变量本身可能包含与行相关的数据所有权信息,例如,账户管理员可以访问任何帐户 [1,2,3],其中该信息不存在于当前数据库中,而是存在于会话变量(可能由其他数据系统提供)。
|
|||
|
|
|
|||
|
|
为了对此建模,我们在 API 层实现了类似于 Postgres RLS 的授权层,以提供用于配置访问控制的声明性框架。如果您熟悉 RLS,可以类比 SQL查询中的当前会话变量为来自 cookie、JWTs 或 HTTP头的 HTTP会话变量。
|
|||
|
|
|
|||
|
|
顺便说一句,因为我们在许多年前就开始了 Hasura 工程,所以我们在 Postgres RLS特性加入 Postgres 之前就在应用层实现了该特性。我们甚至在的 insert 返回子句中也有与已修复的 Postgres RLS 相同的 bug https://www.postgresql.org/about/news/1614/。
|
|||
|
|
|
|||
|
|
因为在 Hasura 应用层面实现了授权(而不是使用 RLS,传递用户详情给 Postgres 连接的当前会话),这带来一个显著优势,我们等下会看到。
|
|||
|
|
|
|||
|
|
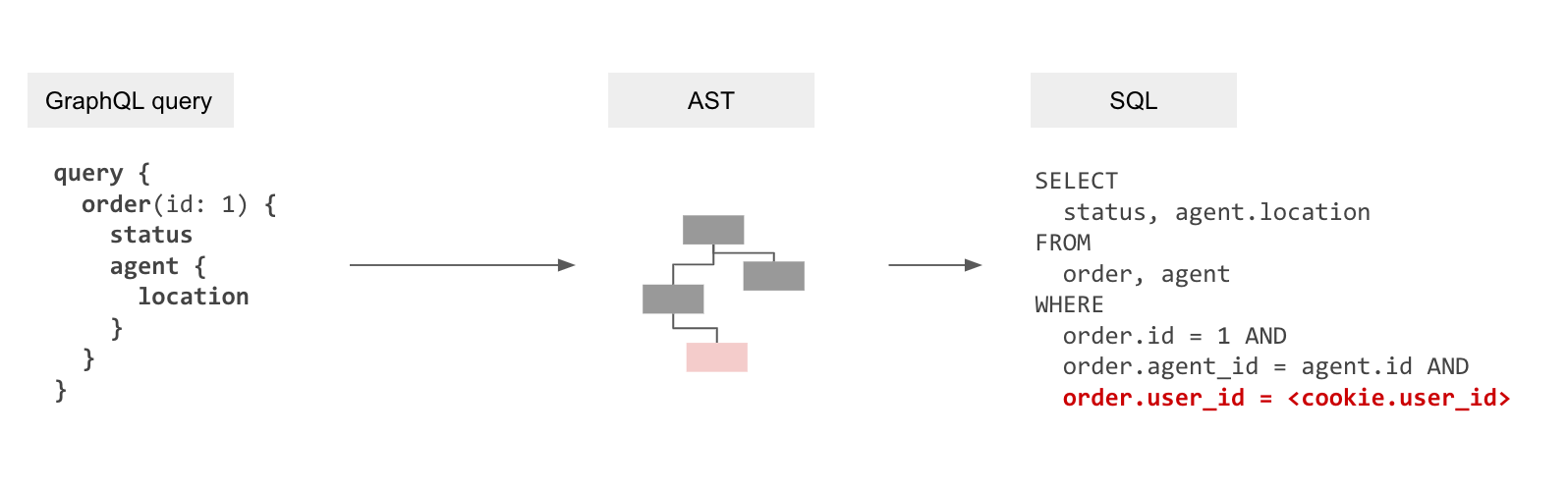
总而言之,既然授权是声明性的,并且可以在表、视图甚至函数(如果函数返回 SETOF)中使用,那么就可以创建具有授权规则的单个 SQL查询。
|
|||
|
|
|
|||
|
|
GraphQL 查询 GraphQL 抽象语法树 包含授权规则的内部抽象语法树 SQL 抽象语法树 SQL
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
#### 主意 #3:在单个 SQL 查询中批处理多个实时查询
|
|||
|
|
|
|||
|
|
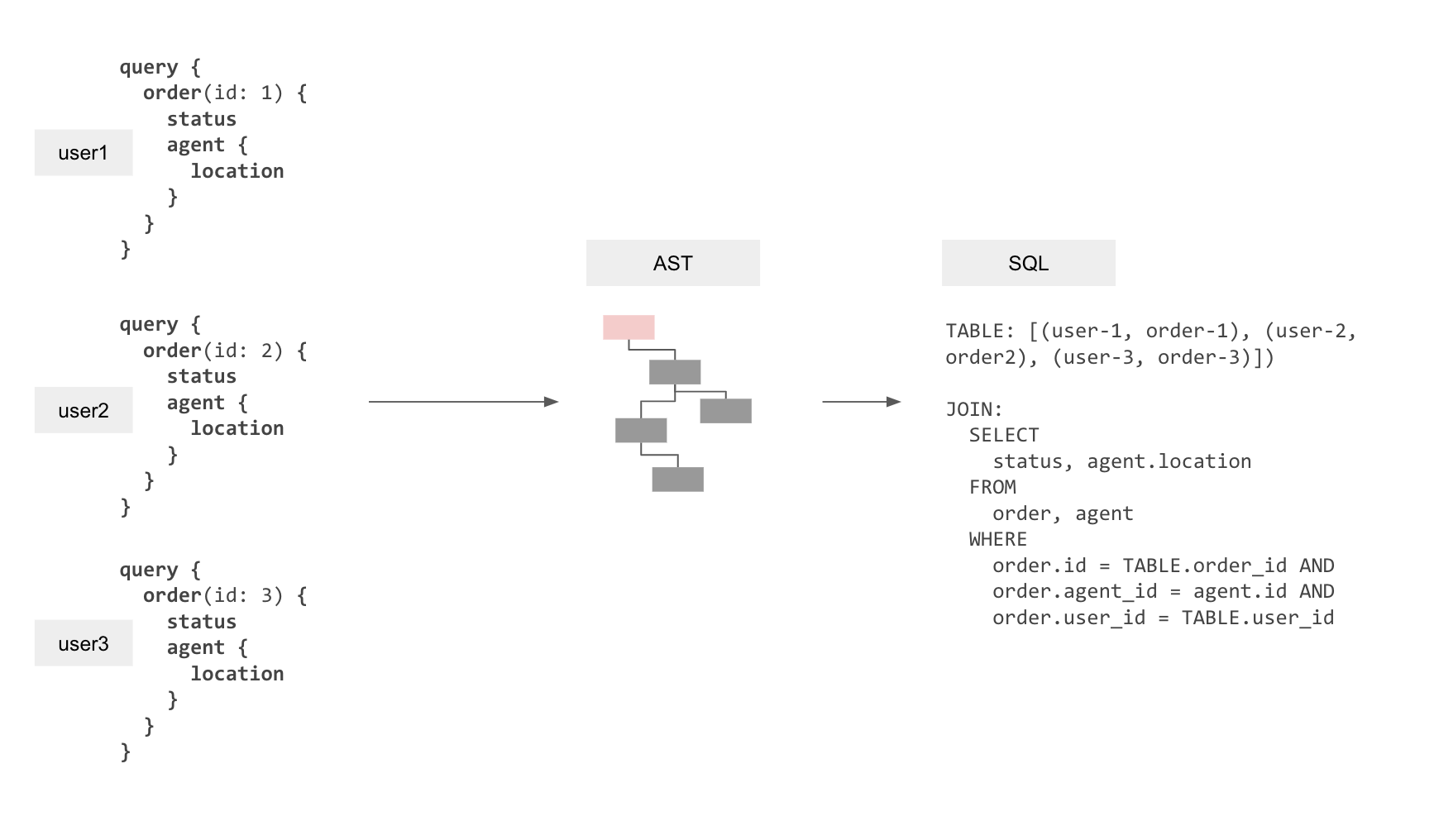
仅凭主意 [#1](#主意-1编译-一个-graphql-查询为单个-sql-查询)、[#2](#主意-2使授权具有声明性) 的实现,我们仍会导致这样的情况:连接了 100k 个客户端可能会导致相称的 100k 个 Postgres查询来获取最新数据(假如 100k 个更新,每个更新对应一个客户端)。
|
|||
|
|
|
|||
|
|
然而,考虑到我们在 API层有所有应用程序用户级会话变量可用,我们实际上可以创建单个 SQL查询来一次为许多客户端再次获取数据!
|
|||
|
|
|
|||
|
|
假设有客户端运行一个订阅,以获取最新的订单状态和配送员位置。我们可以在查询中创建一个关系,其中包含作为不同行的所有查询变量(订单id)和会话变量(用户id)。然后join查询以获取具有此关系的实际数据,以确保在单个响应中获取多个客户端的最新数据。这将允许同时为多个用户获取最新的结果,即使它们提供的参数和会话变量是完全动态的,并且仅在查询时可用。
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
#### 何时执行再获取(refetch)?
|
|||
|
|
|
|||
|
|
我们尝试了多种方法,获取底层数据库更新事件时来再获取查询。
|
|||
|
|
|
|||
|
|
1. 监听、通知:需要用触发器检测所有表,在消费端(web服务器)重启或网络中断的情况下,被消费事件可能会被丢弃。
|
|||
|
|
2. WAL(译注:Write-ahead logging,预写式日志):Reliable stream,但是 LR 插槽使得横向性能扩展非常困难,并且在托管数据库供应商上通常不可用。繁重的写入负载会污染 WAL,并且需要在应用层进行节流。
|
|||
|
|
|
|||
|
|
在这些尝试后,我们当前回退到基于时间间隔的轮询来再获取查询。因此,我们不是在有适当事件时再获取,而是根据一个时间间隔再获取查询。这样做有两个主要原因:
|
|||
|
|
1. 当实时查询中使用的声明性权限和条件很简单时,在某种程度上可以将数据库事件映射到特定客户端的动态查询上(比如 `order_id` = 1 and `user_id` = cookie.`session_id`),但是对于复杂的查询会变得棘手(比如查询 `'status' ILIKE 'failed_%'`)。声明性权限有时也可以跨表使用。我们在研究这种方法以及基本的增量更新方面投入了大量的精力,并且在生产中有[几个小项目](https://www.postgresql.eu/events/pgconfeu2018/sessions/session/2195/slides/144/Implementing%20Incremental%20View%20Maintenance%20on%20PostgreSQL%20.pdf)采用了类似的方法。
|
|||
|
|
2. 对于任何应用程序,除非写吞吐量很小,否则无论如何,您最终都会在一个时间间隔内对事件进行节流/防抖(throttling/debouncing)。
|
|||
|
|
|
|||
|
|
这种方法的缺点是写负载很小时存在延迟。再获取可以立即完成,而不是在几毫秒后。通过适当地调整再获取间隔和批量大小,可以容易地缓解这一问题。到目前为止,我们首先关注的是消除开销最大的瓶颈,即再获取查询。也就是说,我们将在接下来的几个月里继续关注改进,特别是使用事件依赖(在适用的情况下),来潜在地减少实时查询中每隔一段时间再获取的的数量。
|
|||
|
|
|
|||
|
|
请注意,我们在内部有其他基于事件的方法的驱动程序,如果你有一个用例,目前的方法不能满足你的要求,我们愿意与你合作与提供协助!
|
|||
|
|
|
|||
|
|
## 测试
|
|||
|
|
|
|||
|
|
测试基于 Websocket 的实时查询的性能扩展性与可靠性是一项挑战。我们花了几周来构建测试套件和基础自动化工具。设置如下所示:
|
|||
|
|
|
|||
|
|
1. 一个 nodejs脚本,它运行大量的 GraphQL实时查询客户端,并在内存中记录事件,这些事件随后被存储到数据库中。[\[github\]](https://github.com/hasura/subscription-benchmark)
|
|||
|
|
2. 一个在数据库上创建写负载的脚本,从而导致所有运行实时查询的客户端之间发生更改(每秒更新一百万行)。
|
|||
|
|
3. 一旦测试套件完成运行,验证脚本就会在数据库中运行,在该数据库中提取日志/事件以验证没有错误并且所有事件已被接收到。
|
|||
|
|
4. 仅在以下情况下才认为测试有效:
|
|||
|
|
- 收到的有效载荷错误数为 0
|
|||
|
|
- 从创建事件到客户端接收的平均延迟小于 1000毫秒
|
|||
|
|
|
|||
|
|
<img alt="testing-architecture" src="https://storage.googleapis.com/graphql-engine-cdn.hasura.io/img/subscriptions-images/test-architecture.png" width="700px" />
|
|||
|
|
|
|||
|
|
## 本方法的优势
|
|||
|
|
|
|||
|
|
Hasura 使实时查询变得触手可及。查询的概念很容易扩展到实时查询,而不需要使用 GraphQL 的开发人员做任何额外工作。这对我们来说是最重要的。
|
|||
|
|
|
|||
|
|
1. 功能特性丰富的实时查询,全面支持 Postgres operators/aggregations/views/functions 等
|
|||
|
|
2. 性能可估
|
|||
|
|
3. 性能可纵向与横向伸缩扩展
|
|||
|
|
4. 可运行于所有云、数据库供应商平台
|
|||
|
|
|
|||
|
|
## 未来展望
|
|||
|
|
|
|||
|
|
减少 Postgres 负载,通过:
|
|||
|
|
|
|||
|
|
1. 映射事件到实时查询
|
|||
|
|
2. 结果集的增量计算
|