If you have a large amount of data, or "fast moving" data in Postgres, Hasura now allows you to instantly create an API for clients to fetch that data as a continuous stream. This API can be safely exposed to internal or external HTTP clients.
- Uses GraphQL subscriptions, and works with any GraphQL client that supports subscriptions over websockets
- Each client can only read relevant events in a stream: Create fine-grained authorization rules at a "row" (or event) and "column" (or field) level, that integrates with any authentication provider
- Use relationships to enrich event payload data with data in other models at query time
- Scale to a massive number of concurrent clients. This post discusses a [benchmark of streaming to 1M clients concurrently](#performance-benchmarks) streaming data with **independent stream offsets** and **independent authz rules**
However, once this data has been captured, securely exposing this data as a continuous stream to a large number of HTTP clients concurrently is a challenge.
These are the challenges that Hasura aims to address:
1. Allow for authorization rules so that clients can only consume the subset of the stream they have access to
2. Prevent missing events and allow each client to move through its stream independently
3. Scale and manage websocket connections to support hundreds of thousands to millions of HTTP clients concurrently
Hasura's new streaming API on Postgres addresses these challenges so that teams focus on how their streams are modelled and secured instead of building and scaling the API.
In this post, we will look at the architecture of streaming subscriptions, how our batching and multiplexing implementation works with declarative authorization. We will take a look at initial performance benchmarks that test for high concurrency and large volumes of data. And finally, we’ll highlight a few common use-cases and modeling patterns.
1. Step 1: Deploy Hasura as a [docker image](https://hasura.io/docs/latest/getting-started/docker-simple/) or on [Hasura Cloud](https://cloud.hasura.io)
2. Step 2: Connect a Postgres database to Hasura as a source:
- Connect a new or existing Postgres database to it
3. Step 3: Track an existing table, or create a new table with an monotonically increasing, unique id (eg: bigserial).
```sql
CREATE TABLE public.message (
id integer NOT NULL,
username text NOT NULL,
text text NOT NULL,
"timestamp" timestamp with time zone DEFAULT now() NOT NULL
);
```
4. Step 4: Run a GraphQL subscription to try out the streaming API on that table
<imgsrc="https://graphql-engine-cdn.hasura.io/assets/blog/streaming-subscriptions/logs-use-case-I.png"width="80%"alt="Distribute logs via a global edge"/>
1. Create a messages model that has references to channel or groups that describe authorization rules
2. Messages can be sent (aka published) directly via Hasura GraphQL mutations (with authz rules) , or can be handled by custom logic that processes them and inserts them into the messages channel
Note: Messaging channels are a great candidate for sharding by channel_id or other channel metadata. Hasura supports YugaByte, Citus with support for Cockroach coming soon.
- Use logical replication to replicate a subset of the data to a secondary Postgres
- Set up triggers on the second Postgres as suggested above
Note on capturing data from the WAL:
- LR slots are expensive. Maintaining unique cursors and authorization rules for each HTTP client can get prohibitively expensive. Instead, capture data from the WAL and insert that into a flattened table in a second Postgres. This table will now contain the entire WAL, and Hasura can help clients stream data from that table.
### Create a fire-and-forget channel for ephemeral data
Typing indicators, live locations sharing, multiplayer mouse-pointer like information are ideal candidates for fire-and-forget type channels. These types of applications usually require lower e2e latency as well.
Note: The advantage of using Postgres is that we can leverage its query engine for authorization (via Hasura's predicate push down) and independent cursors per stream. Furthermore, the data retention policy can also be fine-grained and controlled quite easily. Furthermore, given that Hasura allows adding multiple Postgres instances to the same GraphQL Engine configuration, we can tune an entirely separate Postgres server to trade increased read & write performance for data-loss.
## Notes on architecture
Hasura already supports the ability to subscribe to the latest value of a query (aka a live query) over GraphQL subscriptions, which works well for use-cases that don't need a continuous stream of data or events. Eg: the current set of online users, the latest value of an aggregate etc. Read more about how these live queries work in Hasura [here](https://github.com/hasura/graphql-engine/blob/master/architecture/live-queries.md).
Streaming however, is a different GraphQL subscription field that is now provided by Hasura, ideal for streaming a large result set continuously or for consuming events continuously in a robust way.
### API design goals
These were the goals and constraints we put on the design of the API:
1. Should work with GraphQL subscriptions out of the box
2. Should compose well with Hasura's existing relatonships and authorization system
3. Should allow the client to quote its own offset
### Making GraphQL calls efficient
Before we dive in to the specifics, let us look at how Hasura handles an incoming subscriber, ie. a GraphQL query.
Part of Hasura is a transpiler that uses the metadata of mapping information for the data models to the GraphQL schema to “compile” GraphQL queries to the SQL queries to fetch data from the database.
The SQL is run with current cursor value, the response is sent to the subscriber and once the response is processed, the cursor value is updated for the next data set. This works well for a single subscriber for a given query.
### Batching multiple streaming consumers into one SQL query
When there are a multiple connected clients that perform streaming subscriptions, the graphql-engine "multiplexes" subscriptions
that are similar.
For example:
Let's say `n` clients run the following streaming subscription with different values of `id`.
We have seen how Hasura makes performant queries. But what about Authorization?
The naive approach would be to fetch the data from the database (involves IO), apply authorization checks for each element in the response (involes IO and compute) and then send the result back to the client. The problem with this approach is that the initial data fetch is not definitive. The data is being filtered based on rules post the fetching from the database and as data becomes bigger, compute and latency becomes high and so does the load on the database.
It is impossible to load large streams of data in memory and apply authorization rules for filtering data before sending it back to the client. The Hasura approach to this problem is two fold. Make the data fetching performant and make authorization declarative by applying them at the query layer.
We just saw above how the transpiler in Hasura with batching helps in making performant queries. But this in itself isn't enough as resolvers also enforce authorization rules by only fetching the data that is allowed. We will therefore need to embed these authorization rules into the generated SQL.
Authorization when it comes to accessing data is essentially a constraint that depends on the values of data (or rows) being fetched combined with application-user specific “session variables” that are provided dynamically. For example, in the most trivial case, a row might container a user_id that denotes the data ownership. Or documents that are viewable by a user might be represented in a related table, document_viewers. In other scenarios the session variable itself might contain the data ownership information pertinent to a row, for eg, an account manager has access to any account [1,2,3…] where that information is not present in the current database but present in the session variable (probably provided by some other data system).
Authorization is declarative and available at a table, view or even a function (if the function returns SETOF) level. It is possible to create a single SQL query that has these authorization rules added to it as additional predicateds in the query (additional clauses to the WHERE clause).
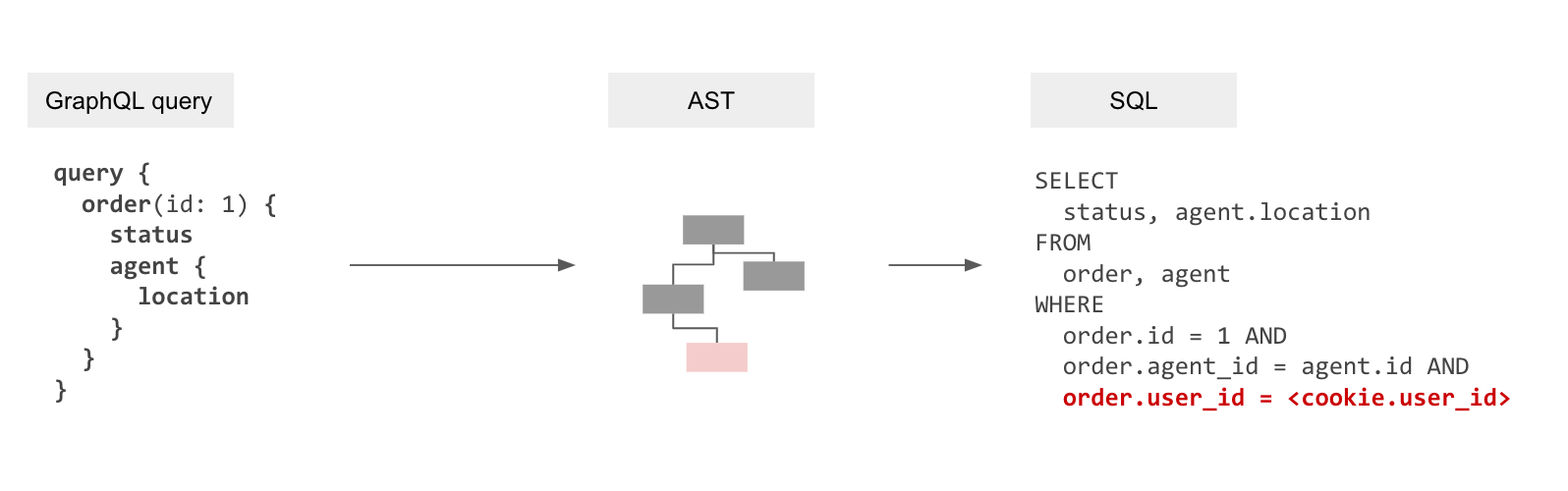
The resultant query processing pipeline is now: GraphQL query → GraphQL AST → Internal AST with authorization rules → SQL AST → SQL
Backpressure is the mechanism that “pushes back” on the producer to not be overwhelmed by data. While streaming, it is plausible that the server keeps on sending new events to a client while the client already has a huge backlog of events to process. Because Hasura is able to handle disconnects elegantly, clients can disconnect from the stream at any point of time (say when an internal counter indicating a backlog of unprocessed events), and reconnect when they're ready. Once the client is ready to accept new events it can start a new streaming subscription from the last cursor value it processed.
Hasura’s subscriptions can easily be scaled horizontally by adding more Hasura instances. The underlying Postgres database can be scaled vertically and with read-replicas or with sharding (with some [supported Postgres flavours](https://hasura.io/docs/latest/databases/postgres/index/#postgres-flavours)).
Hasura also supports working with multiple Postgres databases as sources (each with their own schema), it becomes possible to separate out specific workloads into tuned Postgres instances.
Read more about the benchmark setup here - [https://github.com/hasura/streaming-subscriptions-benchmark](https://github.com/hasura/streaming-subscriptions-benchmark)
We use a similar schema and authorization rule setup as in the "messaging channels" use-case above.
Our aim in this benchmark is to verify that Hasura can handle a large number of concurrent subscribers without undue load on the underlying database.
1. Each subscriber has an independent stream. Each maintains its own offset, and connects with a different authorization rule.
2. We scale from 20k concurrent to 1M concurrent and observe:
a. Load on Hasura instances
b. Database CPU load
c. Number of database connections required
3. Configuration:
a. Database: Single Postgres instance (RDS - 16x CPU, 32GB RAM)
b. Hasura: 100x instances on App runner (4xCPU, 8GB RAM)