Changes compared to `/v1alpha1/graphql` * Changed all graphql responses in **/v1/graphql** endpoint to be 200. All graphql clients expect responses to be HTTP 200. Non-200 responses are considered transport layer errors. * Errors in http and websocket layer are now consistent and have similar structure. |
||
|---|---|---|
| .. | ||
| assets | ||
| bin | ||
| src | ||
| test | ||
| .eslintignore | ||
| .eslintrc | ||
| .gitattributes | ||
| .gitignore | ||
| CONTRIBUTING.md | ||
| package-lock.json | ||
| package.json | ||
| README.md | ||
Firebase to GraphQL
A CLI tool to help you try realtime GraphQL on your firebase data. It takes data exported from firebase and imports it into Postgres via Hasura GraphQL engine.
![]()

Contents
- Getting started
- Installation
- Usage
- Command
- Realtime
- Usage comparison
- Authentication
- Next steps
- More information
- Feedback
Quick start
-
Quickly get the GraphQL Engine running by clicking this button:

Note the URL. It will be of the form:
https://<app-name>.herokuapp.comCheck this page for other deployment options
-
Go to
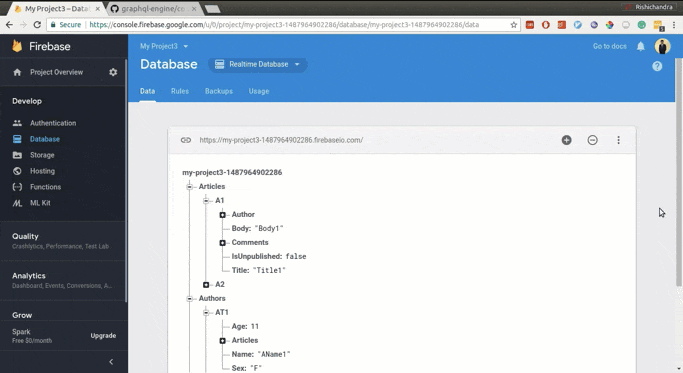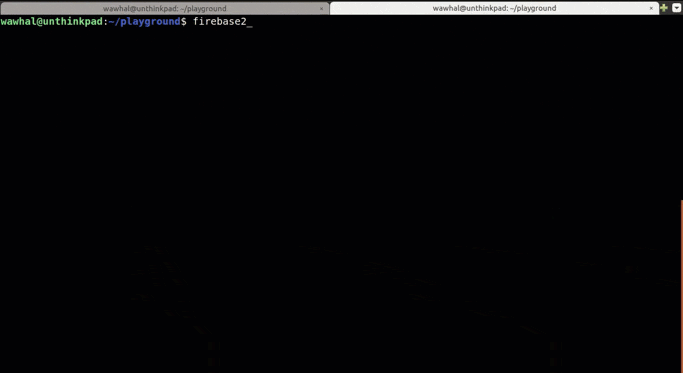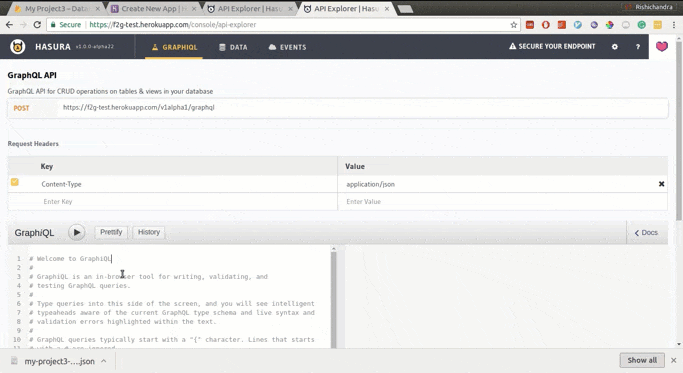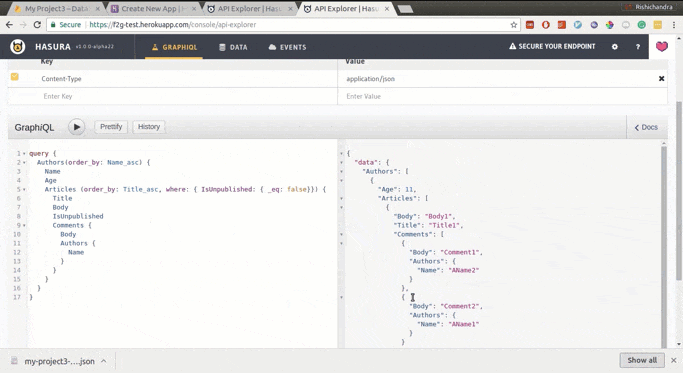
Firebase console > Database > Realtime Databaseand click onExport JSONfrom the options on the upper right corner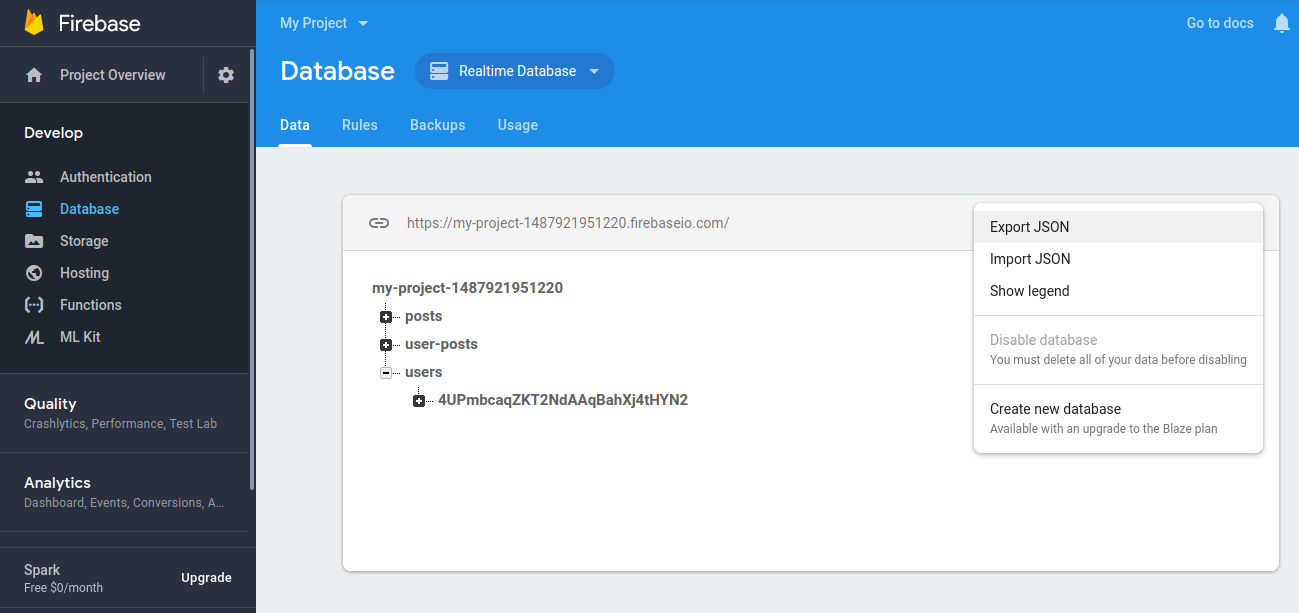
The exported JSON will be something like this:
{ "Articles": { "A1": { "Title": "Title1", "Body": "Body1", "IsUnpublished": false, "Author": { "Name": "AName1", "Age": 11 }, "Comments": { "C1": { "Body": "Comment1", "Author": { "Name": "AName2", "Sex": "M" }, "Date": "22-09-2018" }, "C2": { "Body": "Comment2", "Author": { "Name": "AName1", "Sex": "F" }, "Date": "21-09-2018" } } }, "A2": { "Title": "Title2", "Body": "Body2", "IsUnpublished": true, "Author": { "Name": "AName2", "Age": 22 }, "Comments": { "C3": { "Body": "Comment1", "Author": { "Name": "AName1", "Sex": "F" }, "Date": "23-09-2018" }, "C4": { "Body": "Comment2", "Author": { "Name": "AName2", "Sex": "M" }, "Date": "24-09-2018" } } } }, "Authors": { "AT1": { "Name": "AName1", "Age": 11, "Sex": "F", "Articles": { "A1": { "Title": "Title1" } } }, "AT2": { "Name": "AName2", "Age": 22, "Sex": "M", "Articles": { "A2": { "Title": "Title2" } } } }, "Comments": { "C1": { "Body": "Comment1", "Author": { "Name": "AName2" }, "Date": "22-09-2018" }, "C2": { "Body": "Comment2", "Author": { "Name": "AName1" }, "Date": "21-09-2018" }, "C3": { "Body": "Comment1", "Author": { "Name": "AName1" }, "Date": "23-09-2018" }, "C4": { "Body": "Comment2", "Author": { "Name": "AName2" }, "Date": "24-09-2018" } } } -
Use the CLI to import the data:
npx firebase2graphql https://<app-name>.herokuapp.com --db=./path/to/db.json --normalize -
That's it. You can now go to your GraphQL Engine URL
https://<app-name>.herokuapp.comand make awesome GraphQL Queries like:query { Authors (order_by: {Name:asc}){ Name Age Sex Articles ( order_by: {Title:asc} where: { IsUnpublished: { _eq: false } } ){ Title Body Comments (order_by: {Date:desc}){ Body Authors { Name } Date } } } }
Check out next steps.
Installation
npm install -g firebase2graphql
Usage
Without admin secret
firebase2graphql https://hge.herokuapp.com -d ./path/to/db.json
With admin secret
firebase2graphql https://hge.herokuapp.com -s <admin-secret> -d ./path/to/db.json
Command
firebase2graphql URL [flags]
Args
URL: The URL where Hasura GraphQL Engine is running
Options
-d --db: path to the JS file that exports your sample JSON database-n --normalize: normalize the schema while importing-o --overwrite: (experimental) overwrite tables if they already exist in database-v --version: show CLI version-h, --help: show CLI help
Realtime
With Hasura, you can query the data in Postgres realtime in the form of GraphQL subscriptions. In this way, using this tool, you get exactly the same Firebase API over GraphQL while retaining the live queries feature.
Consider this query:
query {
user {
id
name
email
}
}
You can convert it into a subscription by simply replacing query with subscription.
subscription {
user {
id
name
email
}
}
Usage comparison - Firebase SDK vs GraphQL
A typical query to do a single read from the database using Firebase SDK, (javascript) would look something like:
firebase.database().ref('/users/' + userId).once('value').then(function(snapshot) {
var username = (snapshot.val() && snapshot.val().username) || 'Anonymous';
// ...
});
Equivalent GraphQL Query would look like:
query {
users(where: {uid: {_eq: userId}}) {
uid,
username
}
}
Similarly a write into database using Firebase SDK, would look something like:
firebase.database().ref('users/' + userId).set({
username: name,
email: email,
profile_picture : imageUrl
});
And the equivalent GraphQL Mutation would look like:
mutation {
insert_users(objects:[{
uid: userId
username: name,
email: email,
profile_picture: imageUrl
}])
}
Authentication
Hasura can be integrated with most standard Authentication mechanisms including Firebase and Auth0. Check out the authentication docs here.
Next steps
Once you have imported your data, it is recommended that you make it production ready.
-
Explore the GraphQL Engine Console to play with things such as
-
Set appropriate permissions. GraphQL Engine comes with fine grained control layer that can be integrated with any standard Auth provider.
More information
Working
We flatten the JSON database into tables and create children tables when data nesting is detected.
In this way, you get almost the exact API over GraphQL that you had on Firebase.
If you use the flag --normalize, the CLI finds out if the children tables are duplicates of the original tables and tries to normalize the data by removing duplicates and creating respective relationships.
Normalization
Automatic
The CLI provides a flag called --normalize if you want to normalize your denormalized database.
A lot of guess-work is done by the CLI while normalizing the database. Here are some thing you need to know:
- Root level tables are never deleted. So if there are some relationships that you wish to create manually, you can do so.
- Children tables are deleted if they are detected to be duplicates of some other root or child table.
- In case of some children tables, when the data lacks a unique identifier, an extra unique field is added. In most cases, this field gets deleted while mergine a duplicate table with the original table.
Manual
In some cases, due to inconsistent field names or due to insufficient data, the CLI might not be able to normalize your database; but it makes sure that you do not lose any data.
In such cases, you can normalize the data yourself. Lets look at an example.
Consider this firebase database. This is the database of the official Firebase example app:
{
"posts" : {
"-LMbLFOAW2q6GO1bD-5g" : {
"author" : "Eena",
"authorPic" : "https://lh4.googleusercontent.com/-vPOIBOxCUpo/AAAAAAAAAAI/AAAAAAAAAFo/SKk9hpOB7v4/photo.jpg",
"body" : "My first post content\nAnd body\nANd structure",
"starCount" : 0,
"title" : "My first post",
"uid" : "4UPmbcaqZKT2NdAAqBahXj4tHYN2"
},
"-LMbLIv6VKHYul7p_PZ-" : {
"author" : "Eena",
"authorPic" : "https://lh4.googleusercontent.com/-vPOIBOxCUpo/AAAAAAAAAAI/AAAAAAAAAFo/SKk9hpOB7v4/photo.jpg",
"body" : "AKsdjak\naklsdjaskldjklas\nasdklfjaklsdfjklsda\nasdklfjasklf",
"starCount" : 0,
"title" : "Whatta proaaa",
"uid" : "4UPmbcaqZKT2NdAAqBahXj4tHYN2"
}
},
"user-posts" : {
"4UPmbcaqZKT2NdAAqBahXj4tHYN2" : {
"-LMbLFOAW2q6GO1bD-5g" : {
"author" : "Eena",
"authorPic" : "https://lh4.googleusercontent.com/-vPOIBOxCUpo/AAAAAAAAAAI/AAAAAAAAAFo/SKk9hpOB7v4/photo.jpg",
"body" : "My first post content\nAnd body\nANd structure",
"starCount" : 0,
"title" : "My first post",
"uid" : "4UPmbcaqZKT2NdAAqBahXj4tHYN2"
},
"-LMbLIv6VKHYul7p_PZ-" : {
"author" : "Eena",
"authorPic" : "https://lh4.googleusercontent.com/-vPOIBOxCUpo/AAAAAAAAAAI/AAAAAAAAAFo/SKk9hpOB7v4/photo.jpg",
"body" : "AKsdjak\naklsdjaskldjklas\nasdklfjaklsdfjklsda\nasdklfjasklf",
"starCount" : 0,
"title" : "Whatta proaaa",
"uid" : "4UPmbcaqZKT2NdAAqBahXj4tHYN2"
}
}
},
"users" : {
"4UPmbcaqZKT2NdAAqBahXj4tHYN2" : {
"email" : "rishichandrawawhal@gmail.com",
"profile_picture" : "https://lh4.googleusercontent.com/-vPOIBOxCUpo/AAAAAAAAAAI/AAAAAAAAAFo/SKk9hpOB7v4/photo.jpg",
"username" : "Eena"
}
}
}
In case of this JSON, the CLI will generate the following tables:
users (
_id text not null primary key,
email text,
profile_picture text,
username text
)
posts (
_id text not null primary key,
title text,
body text,
starCount int,
author text,
authorPic text,
uid text
)
user_posts (
_id text not null,
_id_2 text not null,
title text,
body text,
starCount int,
author text,
authorPic text,
uid text
)
As we can see, this is not the most efficient of schemas.
posts(uid)can be a foreign key referencingusers(_id).posts(author)andposts(authorPic)can be deleted ifusersandpostsare related via a foreign key.user_poststable is obsolete ifpostsanduserstables are deleted.
To normalize it, here are the steps you must follow:
-
Create the following foreign key constraints:
ALTER TABLE "posts" ADD CONSTRAINT "posts_users__uid" FOREIGN KEY ("uid") REFERENCES "users"("_id"); ALTER TABLE "posts" DROP COLUMN "author", DROP COLUMN "authorPic"; DROP TABLE "user_posts";To create them, go to the Hasura Console and run the SQL in the
Data > SQLsection. -
Create the relationships. In the console, go the desired table and add the relationship suggested based on the Foreign key. For example for the
poststable in the above schema, the suggested relationship would be suggested like:
Click on
Add. You can name it whatever you like. Lets call itauthorin this case.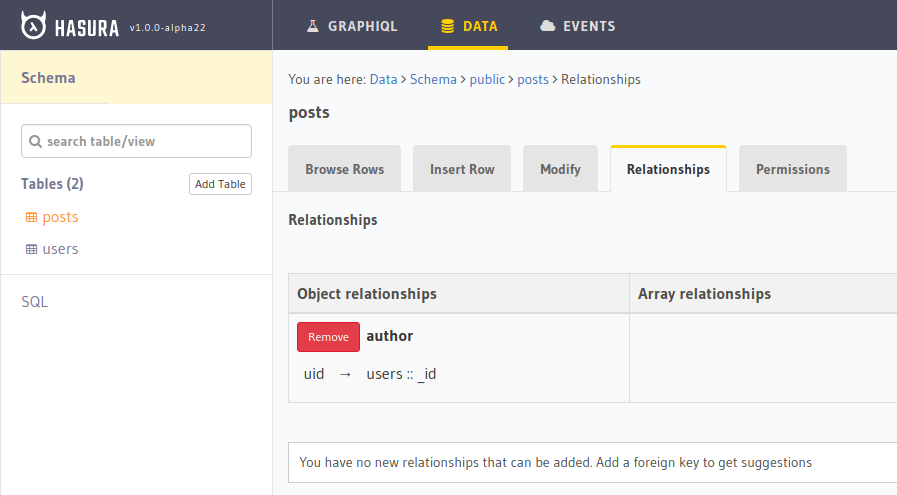
Similarly, add the suggested relationships for other tables as well.
-
Once you have created relationships, you can start making fancy GraphQL queries like:
query { users (order_by: {username:asc}){ username profile_picture email posts (where: { starCount: { _gte: 100}}){ title body starCount } } }
Duplicates
By default, the CLI gives you almost the exact API that you originally had in Firebase (of course, over GraphQL). But in that case, some duplicate tables might be created and you might not be able to leverage the complete power of GraphQL and Postgres.
In such cases, you have three choices:
- Use the API as such if you prefer the exact API.
- Go to the UI Console and delete the duplicates and normalize the database as you feel fit.
- Use the
--normalizeflag and rerun the migration. In this case, the CLI will detect duplicates and make appropriate relationships between root nodes. (This feature is experimental and needs more test cases to attain stability. Contributions are welcome)
Overwrite
If your database already contains tables with the same name as the root fields of your JSON database, the command will fail. If you want to overwrite the database anyway, you should provide an additional flag --overwrite.
Feedback
This project is still in alpha and we are actively looking for feedback about how the tool can be improved. If you are facing an issue, feel free to open one here. Any positive or negative feedback would be appreciated.
Maintained with ❤️ by Hasura