In #385, I introduced a dependency on the `uint8array-json-parser` npm package, but used a fork because of a typescript error. This was resolved in evanw/uint8array-json-parser#1 and published as part of `uint8array-json-parser@0.0.2`. Let's use the upstream.
This also conveniently fixes a new typechecking error that was preventing deployment. The error looked like this:
```
src/import/utils.ts(2,26): error TS2306: File '\''/Users/jlfwong/code/speedscope/node_modules/uint8array-json-parser/uint8array-json-parser.ts'\'' is not a module.'
```
After updating to the upstream, the problem is fixed.
Browsers have a limit on how big you can make strings. In Chrome on a 64 bit machine, this is around 512MB, which explains why in #340, a 600MB file fails to load.
To work around this issue, we avoid making strings this large.
To do so, we need two core changes:
1. Instead of sending large strings as the import mechanism to different file format importers, we introduce a new `TextFileContent` interface which exposes methods to get the lines in the file or the JSON representation. In the case of line splitting, we assume that no single line exceeds the 512MB limit.
2. We introduce a dependency on https://github.com/evanw/uint8array-json-parser to allow us to parse JSON files contained in `Uint8Array` objects
To ensure that this code doesn't code rot without introducing 600MB test files or test file generation into the repository, we also re-run a small set of tests with a mocked maximum string size of 100 bytes. You can see that the chunked string representation code is getting executed via test coverage.
Fixes#340
This is an experiment in replacing redux entirely with a tiny library I wrote for global application state management.
Redux has been okay, but all of the redux actions in speedscope are setters, which always made me think there must be a simpler way. This is an attempt to find that simpler way.
See `src/lib/atom.ts` for the library.
This PR adds the ability to remap an already-loaded profile using a JavaScript source map. This is useful for e.g. recording minified profiles in production, and then remapping their symbols when the source map isn't made directly available to the browser in production.
This is a bit of a hidden feature. The way it works is to drop a profile into speedscope, then drop the sourcemap file on top of it.
To test this, I used a small project @cricklet made (https://gist.github.com/cricklet/0deaaa7dd63657adb6818f0a52362651), and also tested against speedscope itself.
To test against speedscope itself, I profiled loading a file in speedscope in Chrome, then dropped the resulting Chrome timeline profile into speedscope, and dropped speedscope's own sourcemap on top. Before dropping the source map, the symbols look like this:
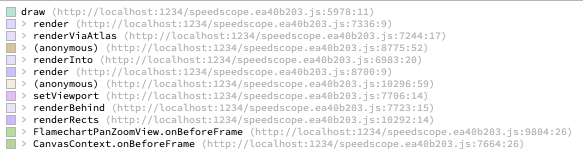
After dropping the source map, they look like this:
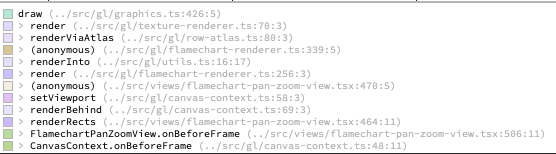
I also added automated tests using a small JS bundle constructed with various different JS bundlers to make sure it was doing a sensible thing in each case.
# Background
Remapping symbols in profiles using source-maps proved to be more complex than I originally thought because of an idiosyncrasy of which line & column are referenced for stack frames in browsers. Rather than the line & column referencing the first character of the symbol, they instead reference the opening paren for the function definition.
Here's an example file where it's not immediately apparent which line & column is going to be referenced by each stack frame:
```
class Kludge {
constructor() {
alpha()
}
zap() {
alpha()
}
}
function alpha() {
for (let i = 0; i < 1000; i++) {
beta()
delta()
}
}
function beta() {
for (let i = 0; i < 10; i++) {
gamma()
}
}
const delta = function () {
for (let i = 0; i < 10; i++) {
gamma()
}
}
const gamma =
() => {
let prod = 1
for (let i = 1; i < 1000; i++) {
prod *= i
}
return prod
}
const k = new Kludge()
k.zap()
```
The resulting profile looks like this:
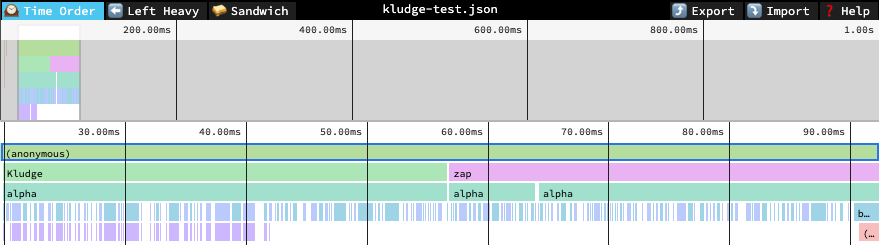
The relevant line & column for each function are...
```
// Kludge: line 2, column 14
class Kludge {
constructor() {
^
...
// zap: line 6, column 6
zap() {
^
...
// alpha: line 11, column 15
function alpha() {
^
...
// delta: line 24, column 24
const delta = function () {
^
...
// gamma: line 31, column 1
const gamma =
() => {
^
```
If we look up the source map entry that corresponds to the opening paren, we'll nearly always get nothing. Instead, we'll look at the entry *preceding* the one which contains the opening paren, and hope that has our symbol name. It seems this works at least some of the time.
Another complication is that some, but not all source maps include the original names of functions. For ones that don't, but do include the original source-code, we try to deduce it ourselves with varying amounts of success.
Supersedes #306Fixes#139
I'd like to try writing new components using hooks, and to do that I need to upgrade from preact 8 to preact X.
For reasons that are... complicated, in order to upgrade without breaking part of my build process, I had to remove the dependency on `preact-redux` altogether. This led me to write my own implementation, and as part of that I realized I could remove `createContainer` in favour of some simple hooks that use redux.
Before landing:
- [x] Investigate performance issues in the sandwich views
- [x] Investigate es-lint checks for exhaustive hook dependencies
Fixes#268
I fixed it by dropping the dependency on quicktype entirely, and using its dependency directly. I still don't understand why the version of typescript used in this repository affects what quicktype is doing, but it seems like the issue is in quicktype, not its dependency.
I validated this change was correct by diffing the output of `node scripts/generate-file-format-schema-json.js` with what's currently on http://speedscope.app/file-format-schema.json. There's no difference.
This PR also includes changes to the CI script to ensure that we can catch this before hitting master next time.
@JustinBeckwith pointed out in #262 that `npm install` was broken in node 13.x, and @DanielRuf pointed in #254 that test fail for node 11+ because of a change to stability of sorting.
This PR seeks to address both of those.
The installation issue was fixed by just regenerating `package-lock.json` without needing to bump any of the direct dependency versions. The test failure issue requires manual intervention.
To fix the sort stability issue, I updated the tests to use the stable sort values (these were all the correct values, though some of the test values were incorrect).
To make the suite still pass for node 10, I added a hack where I override `Array.prototype.sort` with a stable implementation that's *only* used in tests (See comments in code for a justification for why)
## Test Plan
Before this PR: `npm install` on node 13.x fails & `npm run jest` results in test failures
After this PR: `npm install` on node 13.x passes & `npm run jest` passes for node 10, 12, and 13.
I ended up in a horrible peer dependency hell and apparently needed to bump the versions of quicktype, typescript, ts-jest, *and* jest to get out of it. But I think I got out of it!
Local builds and deployment builds both seem to work after these changes.
This PR adds support for importing from Google's pprof format, which is a gzipped, protobuf encoded file format (that's incredibly well documented!) The [pprof http library](https://golang.org/pkg/net/http/pprof/) also offers an output of the trace file format, which continues to not be supported in speedscope to date (See #77). This will allow importing of profiles generated by the standard library go profiler for analysis of profiles containing heap allocation information, CPU profile information, and a few other things like coroutine creation information.
In order to add support for that a number of dependent bits of functionality were added, which should each provide an easier path for future binary input sources
- A protobuf decoding library was included ([protobufjs](https://www.npmjs.com/package/protobufjs)) which includes both a protobuf parser generator based on a .proto file & TypeScript definition generation from the resulting generated JavaScript file
- More generic binary file import. Before this PR, all supported sources were plaintext, with the exception of Instruments 10 support, which takes a totally different codepath. Now binary file import should work when files are dropped, opened via file browsing, or opened via invocation of the speedscope CLI.
- Transparent gzip decoding of imported files (this means that if you were to gzip compress another JSON file, then importing it should still work fine)
Fixes#60.
--
This is a [donation motivated](https://github.com/jlfwong/speedscope/issues/60#issuecomment-419660710) PR motivated by donations by @davecheney & @jmoiron to [/dev/color](https://www.devcolor.org/welcome) 🎉
{kind=link}
{kind=link}
{kind=link}