[pre-commit.ci] auto fixes from pre-commit.com hooks
for more information, see https://pre-commit.ci
@ -1,3 +1,3 @@
|
||||
outputs/
|
||||
src/
|
||||
configs/webui/userconfig_streamlit.yaml
|
||||
configs/webui/userconfig_streamlit.yaml
|
||||
|
||||
2
.gitattributes
vendored
@ -1,4 +1,4 @@
|
||||
* text=auto
|
||||
*.{cmd,[cC][mM][dD]} text eol=crlf
|
||||
*.{bat,[bB][aA][tT]} text eol=crlf
|
||||
*.sh text eol=lf
|
||||
*.sh text eol=lf
|
||||
|
||||
6
.github/ISSUE_TEMPLATE/bug_report.yml
vendored
@ -40,7 +40,7 @@ body:
|
||||
- type: dropdown
|
||||
id: os
|
||||
attributes:
|
||||
label: Where are you running the webui?
|
||||
label: Where are you running the webui?
|
||||
multiple: true
|
||||
options:
|
||||
- Windows
|
||||
@ -52,7 +52,7 @@ body:
|
||||
attributes:
|
||||
label: Custom settings
|
||||
description: If you are running the webui with specifi settings, please paste them here for reference (like --nitro)
|
||||
render: shell
|
||||
render: shell
|
||||
- type: textarea
|
||||
id: logs
|
||||
attributes:
|
||||
@ -66,4 +66,4 @@ body:
|
||||
description: By submitting this issue, you agree to follow our [Code of Conduct](https://docs.github.com/en/site-policy/github-terms/github-community-code-of-conduct)
|
||||
options:
|
||||
- label: I agree to follow this project's Code of Conduct
|
||||
required: true
|
||||
required: true
|
||||
|
||||
2
.github/PULL_REQUEST_TEMPLATE.md
vendored
@ -13,4 +13,4 @@ Closes: # (issue)
|
||||
- [ ] I have changed the base branch to `dev`
|
||||
- [ ] I have performed a self-review of my own code
|
||||
- [ ] I have commented my code in hard-to-understand areas
|
||||
- [ ] I have made corresponding changes to the documentation
|
||||
- [ ] I have made corresponding changes to the documentation
|
||||
|
||||
2
.github/workflows/deploy.yml
vendored
@ -37,4 +37,4 @@ jobs:
|
||||
# The GH actions bot is used by default if you didn't specify the two fields.
|
||||
# You can swap them out with your own user credentials.
|
||||
user_name: github-actions[bot]
|
||||
user_email: 41898282+github-actions[bot]@users.noreply.github.com
|
||||
user_email: 41898282+github-actions[bot]@users.noreply.github.com
|
||||
|
||||
2
.github/workflows/test-deploy.yml
vendored
@ -21,4 +21,4 @@ jobs:
|
||||
- name: Install dependencies
|
||||
run: yarn install
|
||||
- name: Test build website
|
||||
run: yarn build
|
||||
run: yarn build
|
||||
|
||||
28
README.md
@ -6,7 +6,7 @@
|
||||
|
||||
## Installation instructions for:
|
||||
|
||||
- **[Windows](https://sygil-dev.github.io/sygil-webui/docs/Installation/windows-installation)**
|
||||
- **[Windows](https://sygil-dev.github.io/sygil-webui/docs/Installation/windows-installation)**
|
||||
- **[Linux](https://sygil-dev.github.io/sygil-webui/docs/Installation/linux-installation)**
|
||||
|
||||
### Want to ask a question or request a feature?
|
||||
@ -34,10 +34,10 @@ Check the [Contribution Guide](CONTRIBUTING.md)
|
||||
|
||||
* Run additional upscaling models on CPU to save VRAM
|
||||
|
||||
* Textual inversion: [Reaserch Paper](https://textual-inversion.github.io/)
|
||||
* Textual inversion: [Reaserch Paper](https://textual-inversion.github.io/)
|
||||
|
||||
* K-Diffusion Samplers: A great collection of samplers to use, including:
|
||||
|
||||
|
||||
- `k_euler`
|
||||
- `k_lms`
|
||||
- `k_euler_a`
|
||||
@ -95,8 +95,8 @@ An easy way to work with Stable Diffusion right from your browser.
|
||||
To give a token (tag recognized by the AI) a specific or increased weight (emphasis), add `:0.##` to the prompt, where `0.##` is a decimal that will specify the weight of all tokens before the colon.
|
||||
Ex: `cat:0.30, dog:0.70` or `guy riding a bicycle :0.7, incoming car :0.30`
|
||||
|
||||
Negative prompts can be added by using `###` , after which any tokens will be seen as negative.
|
||||
Ex: `cat playing with string ### yarn` will negate `yarn` from the generated image.
|
||||
Negative prompts can be added by using `###` , after which any tokens will be seen as negative.
|
||||
Ex: `cat playing with string ### yarn` will negate `yarn` from the generated image.
|
||||
|
||||
Negatives are a very powerful tool to get rid of contextually similar or related topics, but **be careful when adding them since the AI might see connections you can't**, and end up outputting gibberish
|
||||
|
||||
@ -131,7 +131,7 @@ Lets you improve faces in pictures using the GFPGAN model. There is a checkbox i
|
||||
|
||||
If you want to use GFPGAN to improve generated faces, you need to install it separately.
|
||||
Download [GFPGANv1.4.pth](https://github.com/TencentARC/GFPGAN/releases/download/v1.3.4/GFPGANv1.4.pth) and put it
|
||||
into the `/sygil-webui/models/gfpgan` directory.
|
||||
into the `/sygil-webui/models/gfpgan` directory.
|
||||
|
||||
### RealESRGAN
|
||||
|
||||
@ -141,7 +141,7 @@ Lets you double the resolution of generated images. There is a checkbox in every
|
||||
There is also a separate tab for using RealESRGAN on any picture.
|
||||
|
||||
Download [RealESRGAN_x4plus.pth](https://github.com/xinntao/Real-ESRGAN/releases/download/v0.1.0/RealESRGAN_x4plus.pth) and [RealESRGAN_x4plus_anime_6B.pth](https://github.com/xinntao/Real-ESRGAN/releases/download/v0.2.2.4/RealESRGAN_x4plus_anime_6B.pth).
|
||||
Put them into the `sygil-webui/models/realesrgan` directory.
|
||||
Put them into the `sygil-webui/models/realesrgan` directory.
|
||||
|
||||
### LSDR
|
||||
|
||||
@ -174,8 +174,8 @@ which is available on [GitHub](https://github.com/CompVis/latent-diffusion). PDF
|
||||
|
||||
[Stable Diffusion](#stable-diffusion-v1) is a latent text-to-image diffusion
|
||||
model.
|
||||
Thanks to a generous compute donation from [Stability AI](https://stability.ai/) and support from [LAION](https://laion.ai/), we were able to train a Latent Diffusion Model on 512x512 images from a subset of the [LAION-5B](https://laion.ai/blog/laion-5b/) database.
|
||||
Similar to Google's [Imagen](https://arxiv.org/abs/2205.11487),
|
||||
Thanks to a generous compute donation from [Stability AI](https://stability.ai/) and support from [LAION](https://laion.ai/), we were able to train a Latent Diffusion Model on 512x512 images from a subset of the [LAION-5B](https://laion.ai/blog/laion-5b/) database.
|
||||
Similar to Google's [Imagen](https://arxiv.org/abs/2205.11487),
|
||||
this model uses a frozen CLIP ViT-L/14 text encoder to condition the model on text prompts.
|
||||
With its 860M UNet and 123M text encoder, the model is relatively lightweight and runs on a GPU with at least 10GB VRAM.
|
||||
See [this section](#stable-diffusion-v1) below and the [model card](https://huggingface.co/CompVis/stable-diffusion).
|
||||
@ -184,26 +184,26 @@ See [this section](#stable-diffusion-v1) below and the [model card](https://hugg
|
||||
|
||||
Stable Diffusion v1 refers to a specific configuration of the model
|
||||
architecture that uses a downsampling-factor 8 autoencoder with an 860M UNet
|
||||
and CLIP ViT-L/14 text encoder for the diffusion model. The model was pretrained on 256x256 images and
|
||||
and CLIP ViT-L/14 text encoder for the diffusion model. The model was pretrained on 256x256 images and
|
||||
then finetuned on 512x512 images.
|
||||
|
||||
*Note: Stable Diffusion v1 is a general text-to-image diffusion model and therefore mirrors biases and (mis-)conceptions that are present
|
||||
in its training data.
|
||||
in its training data.
|
||||
Details on the training procedure and data, as well as the intended use of the model can be found in the corresponding [model card](https://huggingface.co/CompVis/stable-diffusion).
|
||||
|
||||
## Comments
|
||||
|
||||
- Our code base for the diffusion models builds heavily on [OpenAI's ADM codebase](https://github.com/openai/guided-diffusion)
|
||||
and [https://github.com/lucidrains/denoising-diffusion-pytorch](https://github.com/lucidrains/denoising-diffusion-pytorch).
|
||||
and [https://github.com/lucidrains/denoising-diffusion-pytorch](https://github.com/lucidrains/denoising-diffusion-pytorch).
|
||||
Thanks for open-sourcing!
|
||||
|
||||
- The implementation of the transformer encoder is from [x-transformers](https://github.com/lucidrains/x-transformers) by [lucidrains](https://github.com/lucidrains?tab=repositories).
|
||||
- The implementation of the transformer encoder is from [x-transformers](https://github.com/lucidrains/x-transformers) by [lucidrains](https://github.com/lucidrains?tab=repositories).
|
||||
|
||||
## BibTeX
|
||||
|
||||
```
|
||||
@misc{rombach2021highresolution,
|
||||
title={High-Resolution Image Synthesis with Latent Diffusion Models},
|
||||
title={High-Resolution Image Synthesis with Latent Diffusion Models},
|
||||
author={Robin Rombach and Andreas Blattmann and Dominik Lorenz and Patrick Esser and Björn Ommer},
|
||||
year={2021},
|
||||
eprint={2112.10752},
|
||||
|
||||
@ -21,7 +21,7 @@ This model card focuses on the model associated with the Stable Diffusion model,
|
||||
|
||||
# Uses
|
||||
|
||||
## Direct Use
|
||||
## Direct Use
|
||||
The model is intended for research purposes only. Possible research areas and
|
||||
tasks include
|
||||
|
||||
@ -68,11 +68,11 @@ Using the model to generate content that is cruel to individuals is a misuse of
|
||||
considerations.
|
||||
|
||||
### Bias
|
||||
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.
|
||||
Stable Diffusion v1 was trained on subsets of [LAION-2B(en)](https://laion.ai/blog/laion-5b/),
|
||||
which consists of images that are primarily limited to English descriptions.
|
||||
Texts and images from communities and cultures that use other languages are likely to be insufficiently accounted for.
|
||||
This affects the overall output of the model, as white and western cultures are often set as the default. Further, the
|
||||
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.
|
||||
Stable Diffusion v1 was trained on subsets of [LAION-2B(en)](https://laion.ai/blog/laion-5b/),
|
||||
which consists of images that are primarily limited to English descriptions.
|
||||
Texts and images from communities and cultures that use other languages are likely to be insufficiently accounted for.
|
||||
This affects the overall output of the model, as white and western cultures are often set as the default. Further, the
|
||||
ability of the model to generate content with non-English prompts is significantly worse than with English-language prompts.
|
||||
|
||||
|
||||
@ -84,7 +84,7 @@ The model developers used the following dataset for training the model:
|
||||
- LAION-2B (en) and subsets thereof (see next section)
|
||||
|
||||
**Training Procedure**
|
||||
Stable Diffusion v1 is a latent diffusion model which combines an autoencoder with a diffusion model that is trained in the latent space of the autoencoder. During training,
|
||||
Stable Diffusion v1 is a latent diffusion model which combines an autoencoder with a diffusion model that is trained in the latent space of the autoencoder. During training,
|
||||
|
||||
- Images are encoded through an encoder, which turns images into latent representations. The autoencoder uses a relative downsampling factor of 8 and maps images of shape H x W x 3 to latents of shape H/f x W/f x 4
|
||||
- Text prompts are encoded through a ViT-L/14 text-encoder.
|
||||
@ -108,12 +108,12 @@ filtered to images with an original size `>= 512x512`, estimated aesthetics scor
|
||||
- **Batch:** 32 x 8 x 2 x 4 = 2048
|
||||
- **Learning rate:** warmup to 0.0001 for 10,000 steps and then kept constant
|
||||
|
||||
## Evaluation Results
|
||||
## Evaluation Results
|
||||
Evaluations with different classifier-free guidance scales (1.5, 2.0, 3.0, 4.0,
|
||||
5.0, 6.0, 7.0, 8.0) and 50 PLMS sampling
|
||||
steps show the relative improvements of the checkpoints:
|
||||
|
||||

|
||||

|
||||
|
||||
Evaluated using 50 PLMS steps and 10000 random prompts from the COCO2017 validation set, evaluated at 512x512 resolution. Not optimized for FID scores.
|
||||
## Environmental Impact
|
||||
@ -137,4 +137,3 @@ Based on that information, we estimate the following CO2 emissions using the [Ma
|
||||
}
|
||||
|
||||
*This model card was written by: Robin Rombach and Patrick Esser and is based on the [DALL-E Mini model card](https://huggingface.co/dalle-mini/dalle-mini).*
|
||||
|
||||
|
||||
@ -582,4 +582,4 @@
|
||||
"outputs": []
|
||||
}
|
||||
]
|
||||
}
|
||||
}
|
||||
|
||||
@ -23,7 +23,7 @@ Hopefully demand will be high, we want to train **hundreds** of new concepts!
|
||||
|
||||
# What does `most inventive use` mean?
|
||||
|
||||
Whatever you want it to mean! be creative! experiment!
|
||||
Whatever you want it to mean! be creative! experiment!
|
||||
|
||||
There are several categories we will look at:
|
||||
|
||||
@ -33,7 +33,7 @@ There are several categories we will look at:
|
||||
|
||||
* composition; meaning anything related to how big things are, their position, the angle, etc
|
||||
|
||||
* styling;
|
||||
* styling;
|
||||
|
||||

|
||||
|
||||
@ -45,7 +45,7 @@ There are several categories we will look at:
|
||||
|
||||
## `The Sims(TM): Stable Diffusion edition` ?
|
||||
|
||||
For this event the theme is “The Sims: Stable Diffusion edition”.
|
||||
For this event the theme is “The Sims: Stable Diffusion edition”.
|
||||
|
||||
So we have selected a subset of [products from Amazon Berkely Objects dataset](https://github.com/sd-webui/abo).
|
||||
|
||||
|
||||
@ -17,5 +17,5 @@
|
||||
"type_vocab_size": 2,
|
||||
"vocab_size": 30522,
|
||||
"encoder_width": 768,
|
||||
"add_cross_attention": true
|
||||
"add_cross_attention": true
|
||||
}
|
||||
|
||||
@ -21,7 +21,7 @@ init_lr: 1e-5
|
||||
image_size: 384
|
||||
|
||||
# generation configs
|
||||
max_length: 20
|
||||
max_length: 20
|
||||
min_length: 5
|
||||
num_beams: 3
|
||||
prompt: 'a picture of '
|
||||
@ -30,4 +30,3 @@ prompt: 'a picture of '
|
||||
weight_decay: 0.05
|
||||
min_lr: 0
|
||||
max_epoch: 5
|
||||
|
||||
|
||||
@ -17,5 +17,5 @@
|
||||
"type_vocab_size": 2,
|
||||
"vocab_size": 30524,
|
||||
"encoder_width": 768,
|
||||
"add_cross_attention": true
|
||||
"add_cross_attention": true
|
||||
}
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
image_root: '/export/share/datasets/vision/NLVR2/'
|
||||
image_root: '/export/share/datasets/vision/NLVR2/'
|
||||
ann_root: 'annotation'
|
||||
|
||||
# set pretrained as a file path or an url
|
||||
@ -6,8 +6,8 @@ pretrained: 'https://storage.googleapis.com/sfr-vision-language-research/BLIP/mo
|
||||
|
||||
#size of vit model; base or large
|
||||
vit: 'base'
|
||||
batch_size_train: 16
|
||||
batch_size_test: 64
|
||||
batch_size_train: 16
|
||||
batch_size_test: 64
|
||||
vit_grad_ckpt: False
|
||||
vit_ckpt_layer: 0
|
||||
max_epoch: 15
|
||||
@ -18,4 +18,3 @@ image_size: 384
|
||||
weight_decay: 0.05
|
||||
init_lr: 3e-5
|
||||
min_lr: 0
|
||||
|
||||
|
||||
@ -12,4 +12,4 @@ image_size: 384
|
||||
max_length: 20
|
||||
min_length: 5
|
||||
num_beams: 3
|
||||
prompt: 'a picture of '
|
||||
prompt: 'a picture of '
|
||||
|
||||
@ -1,7 +1,7 @@
|
||||
train_file: ['/export/share/junnan-li/VL_pretrain/annotation/coco_karpathy_train.json',
|
||||
'/export/share/junnan-li/VL_pretrain/annotation/vg_caption.json',
|
||||
]
|
||||
laion_path: ''
|
||||
laion_path: ''
|
||||
|
||||
# size of vit model; base or large
|
||||
vit: 'base'
|
||||
@ -22,6 +22,3 @@ warmup_lr: 1e-6
|
||||
lr_decay_rate: 0.9
|
||||
max_epoch: 20
|
||||
warmup_steps: 3000
|
||||
|
||||
|
||||
|
||||
|
||||
@ -31,4 +31,3 @@ negative_all_rank: True
|
||||
weight_decay: 0.05
|
||||
min_lr: 0
|
||||
max_epoch: 6
|
||||
|
||||
|
||||
@ -31,4 +31,3 @@ negative_all_rank: False
|
||||
weight_decay: 0.05
|
||||
min_lr: 0
|
||||
max_epoch: 6
|
||||
|
||||
|
||||
@ -9,4 +9,4 @@ vit: 'base'
|
||||
batch_size: 64
|
||||
k_test: 128
|
||||
image_size: 384
|
||||
num_frm_test: 8
|
||||
num_frm_test: 8
|
||||
|
||||
@ -8,8 +8,8 @@ pretrained: 'https://storage.googleapis.com/sfr-vision-language-research/BLIP/mo
|
||||
|
||||
# size of vit model; base or large
|
||||
vit: 'base'
|
||||
batch_size_train: 16
|
||||
batch_size_test: 32
|
||||
batch_size_train: 16
|
||||
batch_size_test: 32
|
||||
vit_grad_ckpt: False
|
||||
vit_ckpt_layer: 0
|
||||
init_lr: 2e-5
|
||||
@ -22,4 +22,4 @@ inference: 'rank'
|
||||
# optimizer
|
||||
weight_decay: 0.05
|
||||
min_lr: 0
|
||||
max_epoch: 10
|
||||
max_epoch: 10
|
||||
|
||||
@ -83,4 +83,4 @@ lightning:
|
||||
increase_log_steps: False
|
||||
|
||||
trainer:
|
||||
benchmark: True
|
||||
benchmark: True
|
||||
|
||||
@ -95,4 +95,4 @@ lightning:
|
||||
increase_log_steps: False
|
||||
|
||||
trainer:
|
||||
benchmark: True
|
||||
benchmark: True
|
||||
|
||||
@ -15,7 +15,7 @@ model:
|
||||
conditioning_key: crossattn
|
||||
monitor: val/loss
|
||||
use_ema: False
|
||||
|
||||
|
||||
unet_config:
|
||||
target: ldm.modules.diffusionmodules.openaimodel.UNetModel
|
||||
params:
|
||||
@ -37,7 +37,7 @@ model:
|
||||
use_spatial_transformer: true
|
||||
transformer_depth: 1
|
||||
context_dim: 512
|
||||
|
||||
|
||||
first_stage_config:
|
||||
target: ldm.models.autoencoder.VQModelInterface
|
||||
params:
|
||||
@ -59,7 +59,7 @@ model:
|
||||
dropout: 0.0
|
||||
lossconfig:
|
||||
target: torch.nn.Identity
|
||||
|
||||
|
||||
cond_stage_config:
|
||||
target: ldm.modules.encoders.modules.ClassEmbedder
|
||||
params:
|
||||
|
||||
@ -82,4 +82,4 @@ lightning:
|
||||
increase_log_steps: False
|
||||
|
||||
trainer:
|
||||
benchmark: True
|
||||
benchmark: True
|
||||
|
||||
@ -82,4 +82,4 @@ lightning:
|
||||
increase_log_steps: False
|
||||
|
||||
trainer:
|
||||
benchmark: True
|
||||
benchmark: True
|
||||
|
||||
@ -88,4 +88,4 @@ lightning:
|
||||
|
||||
|
||||
trainer:
|
||||
benchmark: True
|
||||
benchmark: True
|
||||
|
||||
@ -65,4 +65,4 @@ model:
|
||||
lossconfig:
|
||||
target: torch.nn.Identity
|
||||
cond_stage_config:
|
||||
target: torch.nn.Identity
|
||||
target: torch.nn.Identity
|
||||
|
||||
@ -70,5 +70,3 @@ model:
|
||||
params:
|
||||
freeze: True
|
||||
layer: "penultimate"
|
||||
|
||||
|
||||
|
||||
@ -73,4 +73,3 @@ model:
|
||||
params:
|
||||
freeze: True
|
||||
layer: "penultimate"
|
||||
|
||||
|
||||
@ -12,7 +12,7 @@
|
||||
# GNU Affero General Public License for more details.
|
||||
|
||||
# You should have received a copy of the GNU Affero General Public License
|
||||
# along with this program. If not, see <http://www.gnu.org/licenses/>.
|
||||
# along with this program. If not, see <http://www.gnu.org/licenses/>.
|
||||
|
||||
# UI defaults configuration file. Is read automatically if located at configs/webui/webui.yaml, or specify path via --defaults.
|
||||
|
||||
|
||||
@ -436,4 +436,4 @@ model_manager:
|
||||
files:
|
||||
sygil_diffusion:
|
||||
file_name: "sygil-diffusion-v0.4.ckpt"
|
||||
download_link: "https://huggingface.co/Sygil/Sygil-Diffusion/resolve/main/sygil-diffusion-v0.4.ckpt"
|
||||
download_link: "https://huggingface.co/Sygil/Sygil-Diffusion/resolve/main/sygil-diffusion-v0.4.ckpt"
|
||||
|
||||
48
daisi_app.py
@ -1,26 +1,46 @@
|
||||
import os, subprocess
|
||||
import yaml
|
||||
|
||||
print (os.getcwd)
|
||||
print(os.getcwd)
|
||||
|
||||
try:
|
||||
with open("environment.yaml") as file_handle:
|
||||
environment_data = yaml.safe_load(file_handle, Loader=yaml.FullLoader)
|
||||
with open("environment.yaml") as file_handle:
|
||||
environment_data = yaml.safe_load(file_handle, Loader=yaml.FullLoader)
|
||||
except FileNotFoundError:
|
||||
try:
|
||||
with open(os.path.join("..", "environment.yaml")) as file_handle:
|
||||
environment_data = yaml.safe_load(file_handle, Loader=yaml.FullLoader)
|
||||
except:
|
||||
pass
|
||||
try:
|
||||
with open(os.path.join("..", "environment.yaml")) as file_handle:
|
||||
environment_data = yaml.safe_load(file_handle, Loader=yaml.FullLoader)
|
||||
except:
|
||||
pass
|
||||
|
||||
try:
|
||||
for dependency in environment_data["dependencies"]:
|
||||
package_name, package_version = dependency.split("=")
|
||||
os.system("pip install {}=={}".format(package_name, package_version))
|
||||
for dependency in environment_data["dependencies"]:
|
||||
package_name, package_version = dependency.split("=")
|
||||
os.system("pip install {}=={}".format(package_name, package_version))
|
||||
except:
|
||||
pass
|
||||
pass
|
||||
|
||||
try:
|
||||
subprocess.run(['python', '-m', 'streamlit', "run" ,os.path.join("..","scripts/webui_streamlit.py"), "--theme.base dark"], stdout=subprocess.DEVNULL)
|
||||
subprocess.run(
|
||||
[
|
||||
"python",
|
||||
"-m",
|
||||
"streamlit",
|
||||
"run",
|
||||
os.path.join("..", "scripts/webui_streamlit.py"),
|
||||
"--theme.base dark",
|
||||
],
|
||||
stdout=subprocess.DEVNULL,
|
||||
)
|
||||
except FileExistsError:
|
||||
subprocess.run(['python', '-m', 'streamlit', "run" ,"scripts/webui_streamlit.py", "--theme.base dark"], stdout=subprocess.DEVNULL)
|
||||
subprocess.run(
|
||||
[
|
||||
"python",
|
||||
"-m",
|
||||
"streamlit",
|
||||
"run",
|
||||
"scripts/webui_streamlit.py",
|
||||
"--theme.base dark",
|
||||
],
|
||||
stdout=subprocess.DEVNULL,
|
||||
)
|
||||
|
||||
@ -10580,4 +10580,4 @@ zdzisław beksinski
|
||||
Ödön Márffy
|
||||
Þórarinn B Þorláksson
|
||||
Þórarinn B. Þorláksson
|
||||
Ștefan Luchian
|
||||
Ștefan Luchian
|
||||
|
||||
@ -102634,4 +102634,4 @@ zzislaw beksinski
|
||||
🦑 design
|
||||
🦩🪐🐞👩🏻🦳
|
||||
🧒 📸 🎨
|
||||
🪔 🎨;🌞🌄
|
||||
🪔 🎨;🌞🌄
|
||||
|
||||
@ -101,4 +101,4 @@ graffiti art
|
||||
lineart
|
||||
pixel art
|
||||
poster art
|
||||
vector art
|
||||
vector art
|
||||
|
||||
@ -197,4 +197,4 @@ verdadism
|
||||
video art
|
||||
viennese actionism
|
||||
visual art
|
||||
vorticism
|
||||
vorticism
|
||||
|
||||
@ -15,4 +15,4 @@ reddit
|
||||
shutterstock
|
||||
tumblr
|
||||
unsplash
|
||||
zbrush central
|
||||
zbrush central
|
||||
|
||||
@ -157,4 +157,4 @@
|
||||
/r/ImaginaryWitches
|
||||
/r/ImaginaryWizards
|
||||
/r/ImaginaryWorldEaters
|
||||
/r/ImaginaryWorlds
|
||||
/r/ImaginaryWorlds
|
||||
|
||||
@ -1799,7 +1799,7 @@ vacbed
|
||||
vaginal-birth
|
||||
vaginal-sticker
|
||||
vampire
|
||||
variant-set
|
||||
variant-set
|
||||
vegetablenabe
|
||||
vel
|
||||
very-long-hair
|
||||
@ -1933,4 +1933,4 @@ zenzai-monaka
|
||||
zijou
|
||||
zin-crow
|
||||
zinkurou
|
||||
zombie
|
||||
zombie
|
||||
|
||||
@ -23,7 +23,7 @@ Food Art
|
||||
Tattoo
|
||||
Digital
|
||||
Pixel
|
||||
Embroidery
|
||||
Embroidery
|
||||
Line
|
||||
Pointillism
|
||||
Single Color
|
||||
@ -60,4 +60,4 @@ Street
|
||||
Realistic
|
||||
Photo Realistic
|
||||
Hyper Realistic
|
||||
Doodle
|
||||
Doodle
|
||||
|
||||
@ -6,7 +6,7 @@ denoising_strength: 0.55
|
||||
variation: 3
|
||||
initial_seed: 1
|
||||
|
||||
# put foreground onto background
|
||||
# put foreground onto background
|
||||
size: 512, 512
|
||||
color: 0,0,0
|
||||
|
||||
@ -16,7 +16,7 @@ color:0,0,0,0
|
||||
resize: 300, 300
|
||||
pos: 256, 350
|
||||
|
||||
// select mask by probing some pixels from the image
|
||||
// select mask by probing some pixels from the image
|
||||
mask_by_color_at: 15, 15, 15, 256, 85, 465, 100, 480
|
||||
mask_by_color_threshold:80
|
||||
mask_by_color_space: HLS
|
||||
|
||||
@ -27,7 +27,7 @@ transform3d_max_mask: 255
|
||||
transform3d_inpaint_radius: 1
|
||||
transform3d_inpaint_method: 0
|
||||
|
||||
## put foreground onto background
|
||||
## put foreground onto background
|
||||
size: 512, 512
|
||||
|
||||
|
||||
|
||||
@ -4,7 +4,7 @@ ddim_steps: 50
|
||||
denoising_strength: 0.5
|
||||
initial_seed: 2
|
||||
|
||||
# put foreground onto background
|
||||
# put foreground onto background
|
||||
size: 512, 512
|
||||
|
||||
## create foreground
|
||||
|
||||
@ -23,4 +23,4 @@
|
||||
"8": ["seagreen", "darkseagreen"]
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
@ -36701,4 +36701,4 @@
|
||||
}
|
||||
]
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
@ -14,7 +14,7 @@ Home Page: https://github.com/Sygil-Dev/sygil-webui
|
||||
|
||||
- Open the `installer` folder and copy the `install.bat` to the root folder next to the `webui.bat`
|
||||
|
||||
- Double-click the `install.bat` file and wait for it to handle everything for you.
|
||||
- Double-click the `install.bat` file and wait for it to handle everything for you.
|
||||
|
||||
### Installation on Linux:
|
||||
|
||||
@ -26,4 +26,4 @@ Home Page: https://github.com/Sygil-Dev/sygil-webui
|
||||
|
||||
- Wait for the installer to handle everything for you.
|
||||
|
||||
After installation, you can run the `webui.cmd` file (on Windows) or `webui.sh` file (on Linux/Mac) to start the WebUI.
|
||||
After installation, you can run the `webui.cmd` file (on Windows) or `webui.sh` file (on Linux/Mac) to start the WebUI.
|
||||
|
||||
@ -37,45 +37,45 @@ along with this program. If not, see <http://www.gnu.org/licenses/>.
|
||||
|
||||
* Open Miniconda3 Prompt from your start menu after it has been installed
|
||||
|
||||
* _(Optional)_ Create a new text file in your root directory `/sygil-webui/custom-conda-path.txt` that contains the path to your relevant Miniconda3, for example `C:\Users\<username>\miniconda3` (replace `<username>` with your own username). This is required if you have more than 1 miniconda installation or are using custom installation location.
|
||||
* _(Optional)_ Create a new text file in your root directory `/sygil-webui/custom-conda-path.txt` that contains the path to your relevant Miniconda3, for example `C:\Users\<username>\miniconda3` (replace `<username>` with your own username). This is required if you have more than 1 miniconda installation or are using custom installation location.
|
||||
|
||||
## Cloning the repo
|
||||
|
||||
Type `git clone https://github.com/Sygil-Dev/sygil-webui.git` into the prompt.
|
||||
Type `git clone https://github.com/Sygil-Dev/sygil-webui.git` into the prompt.
|
||||
|
||||
This will create the `sygil-webui` directory in your Windows user folder.
|
||||
This will create the `sygil-webui` directory in your Windows user folder.
|
||||
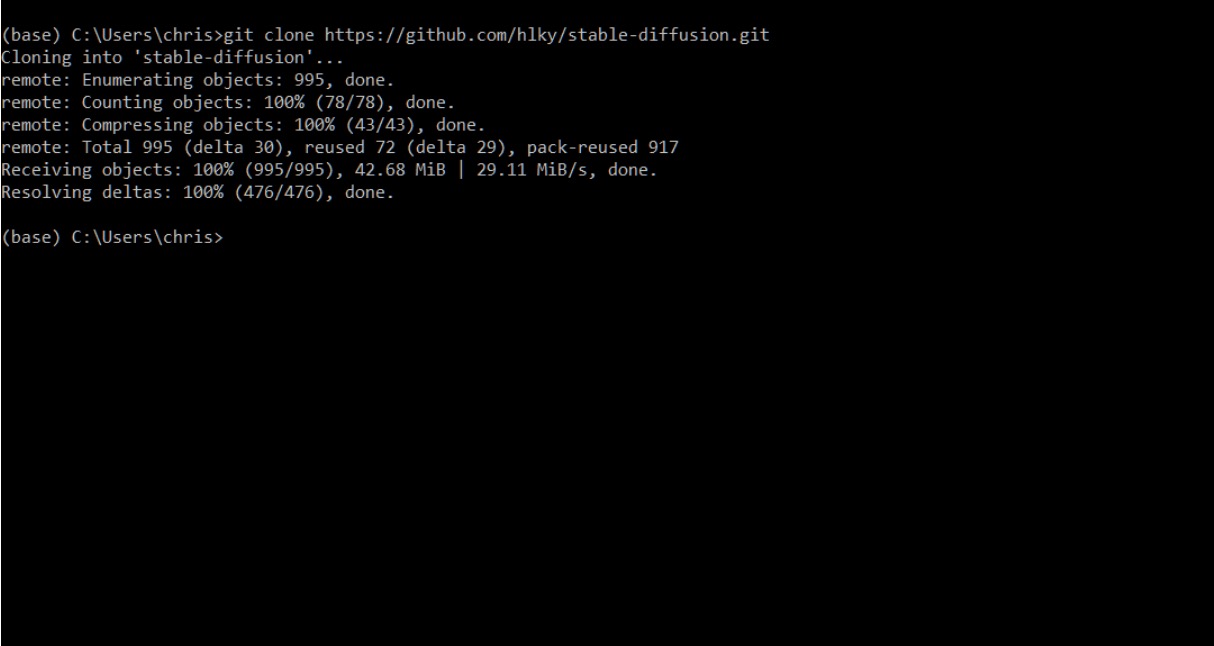
|
||||
|
||||
---
|
||||
---
|
||||
|
||||
Once a repo has been cloned, updating it is as easy as typing `git pull` inside of Miniconda when in the repo’s topmost directory downloaded by the clone command. Below you can see I used the `cd` command to navigate into that folder.
|
||||
|
||||
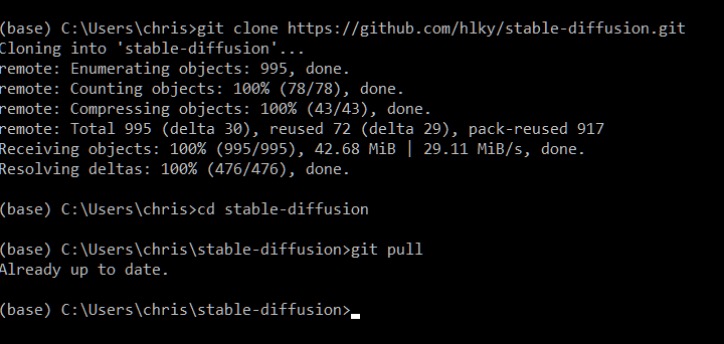
|
||||
|
||||
* Next you are going to want to create a Hugging Face account: [https://huggingface.co/](https://huggingface.co/)
|
||||
* Next you are going to want to create a Hugging Face account: [https://huggingface.co/](https://huggingface.co/)
|
||||
|
||||
* After you have signed up, and are signed in go to this link and click on Authorize: [https://huggingface.co/CompVis/stable-diffusion-v-1-4-original](https://huggingface.co/CompVis/stable-diffusion-v-1-4-original)
|
||||
* After you have signed up, and are signed in go to this link and click on Authorize: [https://huggingface.co/CompVis/stable-diffusion-v-1-4-original](https://huggingface.co/CompVis/stable-diffusion-v-1-4-original)
|
||||
|
||||
* After you have authorized your account, go to this link to download the model weights for version 1.4 of the model, future versions will be released in the same way, and updating them will be a similar process :
|
||||
* After you have authorized your account, go to this link to download the model weights for version 1.4 of the model, future versions will be released in the same way, and updating them will be a similar process :
|
||||
[https://huggingface.co/CompVis/stable-diffusion-v-1-4-original/resolve/main/sd-v1-4.ckpt](https://huggingface.co/CompVis/stable-diffusion-v-1-4-original/resolve/main/sd-v1-4.ckpt)
|
||||
|
||||
* Download the model into this directory: `C:\Users\<username>\sygil-webui\models\ldm\stable-diffusion-v1`
|
||||
|
||||
* Rename `sd-v1-4.ckpt` to `model.ckpt` once it is inside the stable-diffusion-v1 folder.
|
||||
|
||||
* Since we are already in our sygil-webui folder in Miniconda, our next step is to create the environment Stable Diffusion needs to work.
|
||||
* Since we are already in our sygil-webui folder in Miniconda, our next step is to create the environment Stable Diffusion needs to work.
|
||||
|
||||
* _(Optional)_ If you already have an environment set up for an installation of Stable Diffusion named ldm open up the `environment.yaml` file in `\sygil-webui\` change the environment name inside of it from `ldm` to `ldo`
|
||||
|
||||
---
|
||||
---
|
||||
|
||||
## First run
|
||||
|
||||
* `webui.cmd` at the root folder (`\sygil-webui\`) is your main script that you'll always run. It has the functions to automatically do the followings:
|
||||
|
||||
* Create conda env
|
||||
|
||||
* Create conda env
|
||||
* Install and update requirements
|
||||
* Run the relauncher and webui.py script for gradio UI options
|
||||
* Run the relauncher and webui.py script for gradio UI options
|
||||
|
||||
* Run `webui.cmd` by double clicking the file.
|
||||
|
||||
@ -83,7 +83,7 @@ Once a repo has been cloned, updating it is as easy as typing `git pull` inside
|
||||
|
||||

|
||||
|
||||
* You'll receive warning messages on **GFPGAN**, **RealESRGAN** and **LDSR** but these are optionals and will be further explained below.
|
||||
* You'll receive warning messages on **GFPGAN**, **RealESRGAN** and **LDSR** but these are optionals and will be further explained below.
|
||||
|
||||
* In the meantime, you can now go to your web browser and open the link to [http://localhost:7860/](http://localhost:7860/).
|
||||
|
||||
@ -91,9 +91,9 @@ Once a repo has been cloned, updating it is as easy as typing `git pull` inside
|
||||
|
||||
* You should be able to see progress in your `webui.cmd` window. The [http://localhost:7860/](http://localhost:7860/) will be automatically updated to show the final image once progress reach 100%
|
||||
|
||||
* Images created with the web interface will be saved to `\sygil-webui\outputs\` in their respective folders alongside `.yaml` text files with all of the details of your prompts for easy referencing later. Images will also be saved with their seed and numbered so that they can be cross referenced with their `.yaml` files easily.
|
||||
* Images created with the web interface will be saved to `\sygil-webui\outputs\` in their respective folders alongside `.yaml` text files with all of the details of your prompts for easy referencing later. Images will also be saved with their seed and numbered so that they can be cross referenced with their `.yaml` files easily.
|
||||
|
||||
---
|
||||
---
|
||||
|
||||
### Optional additional models
|
||||
|
||||
@ -104,12 +104,12 @@ There are three more models that we need to download in order to get the most ou
|
||||
### GFPGAN
|
||||
|
||||
1. If you want to use GFPGAN to improve generated faces, you need to install it separately.
|
||||
2. Download [GFPGANv1.3.pth](https://github.com/TencentARC/GFPGAN/releases/download/v1.3.0/GFPGANv1.3.pth) and [GFPGANv1.4.pth](https://github.com/TencentARC/GFPGAN/releases/download/v1.3.4/GFPGANv1.4.pth) and put it into the `/sygil-webui/models/gfpgan` directory.
|
||||
2. Download [GFPGANv1.3.pth](https://github.com/TencentARC/GFPGAN/releases/download/v1.3.0/GFPGANv1.3.pth) and [GFPGANv1.4.pth](https://github.com/TencentARC/GFPGAN/releases/download/v1.3.4/GFPGANv1.4.pth) and put it into the `/sygil-webui/models/gfpgan` directory.
|
||||
|
||||
### RealESRGAN
|
||||
|
||||
1. Download [RealESRGAN_x4plus.pth](https://github.com/xinntao/Real-ESRGAN/releases/download/v0.1.0/RealESRGAN_x4plus.pth) and [RealESRGAN_x4plus_anime_6B.pth](https://github.com/xinntao/Real-ESRGAN/releases/download/v0.2.2.4/RealESRGAN_x4plus_anime_6B.pth).
|
||||
2. Put them into the `sygil-webui/models/realesrgan` directory.
|
||||
2. Put them into the `sygil-webui/models/realesrgan` directory.
|
||||
|
||||
### LDSR
|
||||
|
||||
@ -117,7 +117,7 @@ There are three more models that we need to download in order to get the most ou
|
||||
2. Git clone [Hafiidz/latent-diffusion](https://github.com/Hafiidz/latent-diffusion) into your `/sygil-webui/src/` folder.
|
||||
3. Run `/sygil-webui/models/ldsr/download_model.bat` to automatically download and rename the models.
|
||||
4. Wait until it is done and you can confirm by confirming two new files in `sygil-webui/models/ldsr/`
|
||||
5. _(Optional)_ If there are no files there, you can manually download **LDSR** [project.yaml](https://heibox.uni-heidelberg.de/f/31a76b13ea27482981b4/?dl=1) and [model last.cpkt](https://heibox.uni-heidelberg.de/f/578df07c8fc04ffbadf3/?dl=1).
|
||||
5. _(Optional)_ If there are no files there, you can manually download **LDSR** [project.yaml](https://heibox.uni-heidelberg.de/f/31a76b13ea27482981b4/?dl=1) and [model last.cpkt](https://heibox.uni-heidelberg.de/f/578df07c8fc04ffbadf3/?dl=1).
|
||||
6. Rename last.ckpt to model.ckpt and place both under `sygil-webui/models/ldsr/`.
|
||||
7. Refer to [here](https://github.com/Sygil-Dev/sygil-webui/issues/488) for any issue.
|
||||
|
||||
|
||||
@ -46,7 +46,7 @@ along with this program. If not, see <http://www.gnu.org/licenses/>.
|
||||
|
||||
**Step 3:** Make the script executable by opening the directory in your Terminal and typing `chmod +x linux-sd.sh`, or whatever you named this file as.
|
||||
|
||||
**Step 4:** Run the script with `./linux-sd.sh`, it will begin by cloning the [WebUI Github Repo](https://github.com/Sygil-Dev/sygil-webui) to the directory the script is located in. This folder will be named `sygil-webui`.
|
||||
**Step 4:** Run the script with `./linux-sd.sh`, it will begin by cloning the [WebUI Github Repo](https://github.com/Sygil-Dev/sygil-webui) to the directory the script is located in. This folder will be named `sygil-webui`.
|
||||
|
||||
**Step 5:** The script will pause and ask that you move/copy the downloaded 1.4 AI models to the `sygil-webui` folder. Press Enter once you have done so to continue.
|
||||
|
||||
@ -67,8 +67,8 @@ The user will have the ability to set these to yes or no using the menu choices.
|
||||
|
||||
**Building the Conda environment may take upwards of 15 minutes, depending on your network connection and system specs. This is normal, just leave it be and let it finish. If you are trying to update and the script hangs at `Installing PIP Dependencies` for more than 10 minutes, you will need to `Ctrl-C` to stop the script, delete your `src` folder, and rerun `linux-sd.sh` again.**
|
||||
|
||||
**Step 8:** Once the conda environment has been created and the upscaler models have been downloaded, then the user is presented with a choice to choose between the Streamlit or Gradio versions of the WebUI Interface.
|
||||
- Streamlit:
|
||||
**Step 8:** Once the conda environment has been created and the upscaler models have been downloaded, then the user is presented with a choice to choose between the Streamlit or Gradio versions of the WebUI Interface.
|
||||
- Streamlit:
|
||||
- Has A More Modern UI
|
||||
- More Features Planned
|
||||
- Will Be The Main UI Going Forward
|
||||
|
||||
@ -56,9 +56,9 @@ Requirements:
|
||||
* Host computer is AMD64 architecture (e.g. Intel/AMD x86 64-bit CPUs)
|
||||
* Host computer operating system (Linux or Windows with WSL2 enabled)
|
||||
* See [Microsoft WSL2 Installation Guide for Windows 10] (https://learn.microsoft.com/en-us/windows/wsl/) for more information on installing.
|
||||
* Ubuntu (Default) for WSL2 is recommended for Windows users
|
||||
* Ubuntu (Default) for WSL2 is recommended for Windows users
|
||||
* Host computer has Docker, or compatible container runtime
|
||||
* Docker Compose (v1.29+) or later
|
||||
* Docker Compose (v1.29+) or later
|
||||
* See [Install Docker Engine] (https://docs.docker.com/engine/install/#supported-platforms) to learn more about installing Docker on your Linux operating system
|
||||
* 10+ GB Free Disk Space (used by Docker base image, the Stable Diffusion WebUI Docker image for dependencies, model files/weights)
|
||||
|
||||
@ -78,7 +78,7 @@ to issues with AMDs support of GPU passthrough. You also _must_ have ROCm driver
|
||||
```
|
||||
docker compose -f docker-compose.yml -f docker-compose.amd.yml ...
|
||||
```
|
||||
or, by setting
|
||||
or, by setting
|
||||
```
|
||||
export COMPOSE_FILE=docker-compose.yml:docker-compose.amd.yml
|
||||
```
|
||||
|
||||
@ -98,22 +98,22 @@ It is hierarchical, so each layer can have their own child layers.
|
||||
In the frontend you can find a brief documentation for the syntax, examples and reference for the various arguments.
|
||||
Here a summary:
|
||||
|
||||
Markdown headings, e.g. '# layer0', define layers.
|
||||
The content of sections define the arguments for image generation.
|
||||
Markdown headings, e.g. '# layer0', define layers.
|
||||
The content of sections define the arguments for image generation.
|
||||
Arguments are defined by lines of the form 'arg:value' or 'arg=value'.
|
||||
|
||||
Layers are hierarchical, i.e. each layer can contain more layers.
|
||||
Layers are hierarchical, i.e. each layer can contain more layers.
|
||||
The number of '#' increases in the headings of a child layers.
|
||||
Child layers are blended together by their image masks, like layers in image editors.
|
||||
By default alpha composition is used for blending.
|
||||
By default alpha composition is used for blending.
|
||||
Other blend modes from [ImageChops](https://pillow.readthedocs.io/en/stable/reference/ImageChops.html) can also be used.
|
||||
|
||||
Sections with "prompt" and child layers invoke Image2Image, without child layers they invoke Text2Image.
|
||||
Sections with "prompt" and child layers invoke Image2Image, without child layers they invoke Text2Image.
|
||||
The result of blending child layers will be the input for Image2Image.
|
||||
|
||||
Without "prompt" they are just images, useful for mask selection, image composition, etc.
|
||||
Images can be initialized with "color", resized with "resize" and their position specified with "pos".
|
||||
Rotation and rotation center are "rotation" and "center".
|
||||
Rotation and rotation center are "rotation" and "center".
|
||||
|
||||
Mask can automatically be selected by color, color at pixels of the image, or by estimated depth.
|
||||
|
||||
@ -128,15 +128,15 @@ The poses describe the camera position and orientation as x,y,z,rotate_x,rotate_
|
||||
The camera coordinate system is the pinhole camera as described and pictured in [OpenCV "Camera Calibration and 3D Reconstruction" documentation](https://docs.opencv.org/4.x/d9/d0c/group__calib3d.html).
|
||||
|
||||
When the camera pose `transform3d_from_pose` where the input image was taken is not specified, the camera pose `transform3d_to_pose` to which the image is to be transformed is in terms of the input camera coordinate system:
|
||||
Walking forwards one depth unit in the input image corresponds to a position `0,0,1`.
|
||||
Walking to the right is something like `1,0,0`.
|
||||
Walking forwards one depth unit in the input image corresponds to a position `0,0,1`.
|
||||
Walking to the right is something like `1,0,0`.
|
||||
Going downwards is then `0,1,0`.
|
||||
|
||||
## Gradio Optional Customizations
|
||||
|
||||
---
|
||||
|
||||
Gradio allows for a number of possible customizations via command line arguments/terminal parameters. If you are running these manually, they would need to be run like this: `python scripts/webui.py --param`. Otherwise, you may add your own parameter customizations to `scripts/relauncher.py`, the program that automatically relaunches the Gradio interface should a crash happen.
|
||||
Gradio allows for a number of possible customizations via command line arguments/terminal parameters. If you are running these manually, they would need to be run like this: `python scripts/webui.py --param`. Otherwise, you may add your own parameter customizations to `scripts/relauncher.py`, the program that automatically relaunches the Gradio interface should a crash happen.
|
||||
|
||||
Inside of `relauncher.py` are a few preset defaults most people would likely access:
|
||||
|
||||
@ -171,7 +171,7 @@ additional_arguments = ""
|
||||
|
||||
---
|
||||
|
||||
This is a list of the full set of optional parameters you can launch the Gradio Interface with.
|
||||
This is a list of the full set of optional parameters you can launch the Gradio Interface with.
|
||||
|
||||
```
|
||||
usage: webui.py [-h] [--ckpt CKPT] [--cli CLI] [--config CONFIG] [--defaults DEFAULTS] [--esrgan-cpu] [--esrgan-gpu ESRGAN_GPU] [--extra-models-cpu] [--extra-models-gpu] [--gfpgan-cpu] [--gfpgan-dir GFPGAN_DIR] [--gfpgan-gpu GFPGAN_GPU] [--gpu GPU]
|
||||
|
||||
@ -61,7 +61,7 @@ To use GoBig, you will need to download the RealESRGAN models as directed above.
|
||||
LSDR is a 4X upscaler with high VRAM usage that uses a Latent Diffusion model to upscale the image. This will accentuate the details of an image, but won't change the composition. This might introduce sharpening, but it is great for textures or compositions with plenty of details. However, it is slower and will use more VRAM.
|
||||
|
||||
If you want to use LSDR to upscale your images, you need to download the models for it separately if you are on Windows or doing so manually on Linux.
|
||||
Download the LDSR [project.yaml](https://heibox.uni-heidelberg.de/f/31a76b13ea27482981b4/?dl=1) and [ model last.cpkt](https://heibox.uni-heidelberg.de/f/578df07c8fc04ffbadf3/?dl=1). Rename `last.ckpt` to `model.ckpt` and place both in the `sygil-webui/models/ldsr` directory after you have setup the conda environment for the first time.
|
||||
Download the LDSR [project.yaml](https://heibox.uni-heidelberg.de/f/31a76b13ea27482981b4/?dl=1) and [ model last.cpkt](https://heibox.uni-heidelberg.de/f/578df07c8fc04ffbadf3/?dl=1). Rename `last.ckpt` to `model.ckpt` and place both in the `sygil-webui/models/ldsr` directory after you have setup the conda environment for the first time.
|
||||
|
||||
## GoLatent (Gradio only currently)
|
||||
|
||||
|
||||
@ -6,4 +6,4 @@
|
||||
|
||||

|
||||
|
||||
The Concept Library allows for the easy usage of custom textual inversion models. These models may be loaded into `models/custom/sd-concepts-library` and will appear in the Concepts Library in Streamlit. To use one of these custom models in a prompt, either copy it using the button on the model, or type `<model-name>` in the prompt where you wish to use it.
|
||||
The Concept Library allows for the easy usage of custom textual inversion models. These models may be loaded into `models/custom/sd-concepts-library` and will appear in the Concepts Library in Streamlit. To use one of these custom models in a prompt, either copy it using the button on the model, or type `<model-name>` in the prompt where you wish to use it.
|
||||
|
||||
@ -18,7 +18,7 @@ You should have received a copy of the GNU Affero General Public License
|
||||
along with this program. If not, see <http://www.gnu.org/licenses/>.
|
||||
-->
|
||||
|
||||
You can use other *versions* of Stable Diffusion, and *fine-tunes* of Stable Diffusion.
|
||||
You can use other *versions* of Stable Diffusion, and *fine-tunes* of Stable Diffusion.
|
||||
|
||||
Any model with the `.ckpt` extension can be placed into the `models/custom` folder and used in the UI. The filename of the model will be used to show the model on the drop-down menu on the UI from which you can select and use your custom model so, make sure it has a good filename so you can recognize it from the drop-down menu.
|
||||
|
||||
@ -44,7 +44,7 @@ Any model with the `.ckpt` extension can be placed into the `models/custom` fold
|
||||
|
||||
- ### [Trinart v2](https://huggingface.co/naclbit/trinart_stable_diffusion_v2)
|
||||
|
||||
-
|
||||
-
|
||||
|
||||
## Unofficial Model List:
|
||||
|
||||
|
||||
@ -27,7 +27,7 @@ const config = {
|
||||
defaultLocale: 'en',
|
||||
locales: ['en'],
|
||||
},
|
||||
|
||||
|
||||
// ...
|
||||
plugins: [
|
||||
[
|
||||
@ -108,7 +108,7 @@ const config = {
|
||||
/** @type {import('@docusaurus/preset-classic').Options} */
|
||||
({
|
||||
docs: {
|
||||
|
||||
|
||||
sidebarCollapsed: false,
|
||||
sidebarPath: require.resolve('./sidebars.js'),
|
||||
// Please change this to your repo.
|
||||
@ -193,4 +193,4 @@ const config = {
|
||||
}),
|
||||
};
|
||||
|
||||
module.exports = config;
|
||||
module.exports = config;
|
||||
|
||||
@ -13,7 +13,7 @@
|
||||
# GNU Affero General Public License for more details.
|
||||
|
||||
# You should have received a copy of the GNU Affero General Public License
|
||||
# along with this program. If not, see <http://www.gnu.org/licenses/>.
|
||||
# along with this program. If not, see <http://www.gnu.org/licenses/>.
|
||||
#
|
||||
# Starts the webserver inside the docker container
|
||||
#
|
||||
|
||||
@ -13,7 +13,7 @@ name: ldm
|
||||
# GNU Affero General Public License for more details.
|
||||
|
||||
# You should have received a copy of the GNU Affero General Public License
|
||||
# along with this program. If not, see <http://www.gnu.org/licenses/>.
|
||||
# along with this program. If not, see <http://www.gnu.org/licenses/>.
|
||||
channels:
|
||||
- pytorch
|
||||
- defaults
|
||||
|
||||
@ -20,4 +20,4 @@ module.exports = {
|
||||
'no-console': process.env.NODE_ENV === 'production' ? 'warn' : 'off',
|
||||
'no-debugger': process.env.NODE_ENV === 'production' ? 'warn' : 'off'
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
@ -1,7 +1,7 @@
|
||||
/* ----------------------------------------------
|
||||
* Generated by Animista on 2022-9-3 12:0:51
|
||||
* Licensed under FreeBSD License.
|
||||
* See http://animista.net/license for more info.
|
||||
* See http://animista.net/license for more info.
|
||||
* w: http://animista.net, t: @cssanimista
|
||||
* ---------------------------------------------- */
|
||||
|
||||
@ -26,7 +26,7 @@
|
||||
opacity: 1;
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
|
||||
/* CSS HEX */
|
||||
:root {
|
||||
@ -130,7 +130,7 @@ background-color:#9d85fbdf!important;
|
||||
border: none!important;}
|
||||
/* Background for Gradio stuff along with colors for text */
|
||||
.dark .gr-box {
|
||||
|
||||
|
||||
|
||||
background-color:rgba(55, 55, 55, 0.105)!important;
|
||||
border: solid 0.5px!important;
|
||||
@ -206,4 +206,3 @@ button, select, textarea {
|
||||
.dark .gr-check-radio{
|
||||
background-color: #373737ff!important;
|
||||
}
|
||||
|
||||
|
||||
@ -18,4 +18,4 @@ along with this program. If not, see <http://www.gnu.org/licenses/>.
|
||||
.wrap .m-12 svg { display:none!important; }
|
||||
.wrap .m-12::before { content:"Loading..." }
|
||||
.progress-bar { display:none!important; }
|
||||
.meta-text { display:none!important; }
|
||||
.meta-text { display:none!important; }
|
||||
|
||||
@ -146,7 +146,7 @@ div.gallery:hover {
|
||||
.css-jn99sy {
|
||||
display: none
|
||||
}
|
||||
|
||||
|
||||
/* Make the text area widget have a similar height as the text input field */
|
||||
.st-dy{
|
||||
height: 54px;
|
||||
@ -154,14 +154,14 @@ div.gallery:hover {
|
||||
}
|
||||
.css-17useex{
|
||||
gap: 3px;
|
||||
|
||||
|
||||
}
|
||||
|
||||
/* Remove some empty spaces to make the UI more compact. */
|
||||
.css-18e3th9{
|
||||
padding-left: 10px;
|
||||
padding-right: 30px;
|
||||
position: unset !important; /* Fixes the layout/page going up when an expander or another item is expanded and then collapsed */
|
||||
position: unset !important; /* Fixes the layout/page going up when an expander or another item is expanded and then collapsed */
|
||||
}
|
||||
.css-k1vhr4{
|
||||
padding-top: initial;
|
||||
|
||||
@ -12,7 +12,7 @@
|
||||
# GNU Affero General Public License for more details.
|
||||
|
||||
# You should have received a copy of the GNU Affero General Public License
|
||||
# along with this program. If not, see <http://www.gnu.org/licenses/>.
|
||||
# along with this program. If not, see <http://www.gnu.org/licenses/>.
|
||||
from os import path
|
||||
import json
|
||||
|
||||
@ -28,7 +28,7 @@ def readTextFile(*args):
|
||||
def css(opt):
|
||||
styling = readTextFile("css", "styles.css")
|
||||
if not opt.no_progressbar_hiding:
|
||||
styling += readTextFile("css", "no_progress_bar.css")
|
||||
styling += readTextFile("css", "no_progress_bar.css")
|
||||
return styling
|
||||
|
||||
|
||||
|
||||
@ -10,4 +10,4 @@
|
||||
<div id="app"></div>
|
||||
|
||||
</body>
|
||||
</html>
|
||||
</html>
|
||||
|
||||
@ -187,7 +187,7 @@ PERFORMANCE OF THIS SOFTWARE.
|
||||
***************************************************************************** */var Oa=function(){return Oa=Object.assign||function(t){for(var n,r=1,i=arguments.length;r<i;r++){n=arguments[r];for(var o in n)Object.prototype.hasOwnProperty.call(n,o)&&(t[o]=n[o])}return t},Oa.apply(this,arguments)},sO={thumbnail:!0,animateThumb:!0,currentPagerPosition:"middle",alignThumbnails:"middle",thumbWidth:100,thumbHeight:"80px",thumbMargin:5,appendThumbnailsTo:".lg-components",toggleThumb:!1,enableThumbDrag:!0,enableThumbSwipe:!0,thumbnailSwipeThreshold:10,loadYouTubeThumbnail:!0,youTubeThumbSize:1,thumbnailPluginStrings:{toggleThumbnails:"Toggle thumbnails"}},ys={afterAppendSlide:"lgAfterAppendSlide",init:"lgInit",hasVideo:"lgHasVideo",containerResize:"lgContainerResize",updateSlides:"lgUpdateSlides",afterAppendSubHtml:"lgAfterAppendSubHtml",beforeOpen:"lgBeforeOpen",afterOpen:"lgAfterOpen",slideItemLoad:"lgSlideItemLoad",beforeSlide:"lgBeforeSlide",afterSlide:"lgAfterSlide",posterClick:"lgPosterClick",dragStart:"lgDragStart",dragMove:"lgDragMove",dragEnd:"lgDragEnd",beforeNextSlide:"lgBeforeNextSlide",beforePrevSlide:"lgBeforePrevSlide",beforeClose:"lgBeforeClose",afterClose:"lgAfterClose",rotateLeft:"lgRotateLeft",rotateRight:"lgRotateRight",flipHorizontal:"lgFlipHorizontal",flipVertical:"lgFlipVertical",autoplay:"lgAutoplay",autoplayStart:"lgAutoplayStart",autoplayStop:"lgAutoplayStop"},oO=function(){function e(t,n){return this.thumbOuterWidth=0,this.thumbTotalWidth=0,this.translateX=0,this.thumbClickable=!1,this.core=t,this.$LG=n,this}return e.prototype.init=function(){this.settings=Oa(Oa({},sO),this.core.settings),this.thumbOuterWidth=0,this.thumbTotalWidth=this.core.galleryItems.length*(this.settings.thumbWidth+this.settings.thumbMargin),this.translateX=0,this.setAnimateThumbStyles(),this.core.settings.allowMediaOverlap||(this.settings.toggleThumb=!1),this.settings.thumbnail&&(this.build(),this.settings.animateThumb?(this.settings.enableThumbDrag&&this.enableThumbDrag(),this.settings.enableThumbSwipe&&this.enableThumbSwipe(),this.thumbClickable=!1):this.thumbClickable=!0,this.toggleThumbBar(),this.thumbKeyPress())},e.prototype.build=function(){var t=this;this.setThumbMarkup(),this.manageActiveClassOnSlideChange(),this.$lgThumb.first().on("click.lg touchend.lg",function(n){var r=t.$LG(n.target);!r.hasAttribute("data-lg-item-id")||setTimeout(function(){if(t.thumbClickable&&!t.core.lgBusy){var i=parseInt(r.attr("data-lg-item-id"));t.core.slide(i,!1,!0,!1)}},50)}),this.core.LGel.on(ys.beforeSlide+".thumb",function(n){var r=n.detail.index;t.animateThumb(r)}),this.core.LGel.on(ys.beforeOpen+".thumb",function(){t.thumbOuterWidth=t.core.outer.get().offsetWidth}),this.core.LGel.on(ys.updateSlides+".thumb",function(){t.rebuildThumbnails()}),this.core.LGel.on(ys.containerResize+".thumb",function(){!t.core.lgOpened||setTimeout(function(){t.thumbOuterWidth=t.core.outer.get().offsetWidth,t.animateThumb(t.core.index),t.thumbOuterWidth=t.core.outer.get().offsetWidth},50)})},e.prototype.setThumbMarkup=function(){var t="lg-thumb-outer ";this.settings.alignThumbnails&&(t+="lg-thumb-align-"+this.settings.alignThumbnails);var n='<div class="'+t+`">
|
||||
<div class="lg-thumb lg-group">
|
||||
</div>
|
||||
</div>`;this.core.outer.addClass("lg-has-thumb"),this.settings.appendThumbnailsTo===".lg-components"?this.core.$lgComponents.append(n):this.core.outer.append(n),this.$thumbOuter=this.core.outer.find(".lg-thumb-outer").first(),this.$lgThumb=this.core.outer.find(".lg-thumb").first(),this.settings.animateThumb&&this.core.outer.find(".lg-thumb").css("transition-duration",this.core.settings.speed+"ms").css("width",this.thumbTotalWidth+"px").css("position","relative"),this.setThumbItemHtml(this.core.galleryItems)},e.prototype.enableThumbDrag=function(){var t=this,n={cords:{startX:0,endX:0},isMoved:!1,newTranslateX:0,startTime:new Date,endTime:new Date,touchMoveTime:0},r=!1;this.$thumbOuter.addClass("lg-grab"),this.core.outer.find(".lg-thumb").first().on("mousedown.lg.thumb",function(i){t.thumbTotalWidth>t.thumbOuterWidth&&(i.preventDefault(),n.cords.startX=i.pageX,n.startTime=new Date,t.thumbClickable=!1,r=!0,t.core.outer.get().scrollLeft+=1,t.core.outer.get().scrollLeft-=1,t.$thumbOuter.removeClass("lg-grab").addClass("lg-grabbing"))}),this.$LG(window).on("mousemove.lg.thumb.global"+this.core.lgId,function(i){!t.core.lgOpened||r&&(n.cords.endX=i.pageX,n=t.onThumbTouchMove(n))}),this.$LG(window).on("mouseup.lg.thumb.global"+this.core.lgId,function(){!t.core.lgOpened||(n.isMoved?n=t.onThumbTouchEnd(n):t.thumbClickable=!0,r&&(r=!1,t.$thumbOuter.removeClass("lg-grabbing").addClass("lg-grab")))})},e.prototype.enableThumbSwipe=function(){var t=this,n={cords:{startX:0,endX:0},isMoved:!1,newTranslateX:0,startTime:new Date,endTime:new Date,touchMoveTime:0};this.$lgThumb.on("touchstart.lg",function(r){t.thumbTotalWidth>t.thumbOuterWidth&&(r.preventDefault(),n.cords.startX=r.targetTouches[0].pageX,t.thumbClickable=!1,n.startTime=new Date)}),this.$lgThumb.on("touchmove.lg",function(r){t.thumbTotalWidth>t.thumbOuterWidth&&(r.preventDefault(),n.cords.endX=r.targetTouches[0].pageX,n=t.onThumbTouchMove(n))}),this.$lgThumb.on("touchend.lg",function(){n.isMoved?n=t.onThumbTouchEnd(n):t.thumbClickable=!0})},e.prototype.rebuildThumbnails=function(){var t=this;this.$thumbOuter.addClass("lg-rebuilding-thumbnails"),setTimeout(function(){t.thumbTotalWidth=t.core.galleryItems.length*(t.settings.thumbWidth+t.settings.thumbMargin),t.$lgThumb.css("width",t.thumbTotalWidth+"px"),t.$lgThumb.empty(),t.setThumbItemHtml(t.core.galleryItems),t.animateThumb(t.core.index)},50),setTimeout(function(){t.$thumbOuter.removeClass("lg-rebuilding-thumbnails")},200)},e.prototype.setTranslate=function(t){this.$lgThumb.css("transform","translate3d(-"+t+"px, 0px, 0px)")},e.prototype.getPossibleTransformX=function(t){return t>this.thumbTotalWidth-this.thumbOuterWidth&&(t=this.thumbTotalWidth-this.thumbOuterWidth),t<0&&(t=0),t},e.prototype.animateThumb=function(t){if(this.$lgThumb.css("transition-duration",this.core.settings.speed+"ms"),this.settings.animateThumb){var n=0;switch(this.settings.currentPagerPosition){case"left":n=0;break;case"middle":n=this.thumbOuterWidth/2-this.settings.thumbWidth/2;break;case"right":n=this.thumbOuterWidth-this.settings.thumbWidth}this.translateX=(this.settings.thumbWidth+this.settings.thumbMargin)*t-1-n,this.translateX>this.thumbTotalWidth-this.thumbOuterWidth&&(this.translateX=this.thumbTotalWidth-this.thumbOuterWidth),this.translateX<0&&(this.translateX=0),this.setTranslate(this.translateX)}},e.prototype.onThumbTouchMove=function(t){return t.newTranslateX=this.translateX,t.isMoved=!0,t.touchMoveTime=new Date().valueOf(),t.newTranslateX-=t.cords.endX-t.cords.startX,t.newTranslateX=this.getPossibleTransformX(t.newTranslateX),this.setTranslate(t.newTranslateX),this.$thumbOuter.addClass("lg-dragging"),t},e.prototype.onThumbTouchEnd=function(t){t.isMoved=!1,t.endTime=new Date,this.$thumbOuter.removeClass("lg-dragging");var n=t.endTime.valueOf()-t.startTime.valueOf(),r=t.cords.endX-t.cords.startX,i=Math.abs(r)/n;return i>.15&&t.endTime.valueOf()-t.touchMoveTime<30?(i+=1,i>2&&(i+=1),i=i+i*(Math.abs(r)/this.thumbOuterWidth),this.$lgThumb.css("transition-duration",Math.min(i-1,2)+"settings"),r=r*i,this.translateX=this.getPossibleTransformX(this.translateX-r),this.setTranslate(this.translateX)):this.translateX=t.newTranslateX,Math.abs(t.cords.endX-t.cords.startX)<this.settings.thumbnailSwipeThreshold&&(this.thumbClickable=!0),t},e.prototype.getThumbHtml=function(t,n){var r=this.core.galleryItems[n].__slideVideoInfo||{},i;return r.youtube&&this.settings.loadYouTubeThumbnail?i="//img.youtube.com/vi/"+r.youtube[1]+"/"+this.settings.youTubeThumbSize+".jpg":i=t,'<div data-lg-item-id="'+n+'" class="lg-thumb-item '+(n===this.core.index?" active":"")+`"
|
||||
</div>`;this.core.outer.addClass("lg-has-thumb"),this.settings.appendThumbnailsTo===".lg-components"?this.core.$lgComponents.append(n):this.core.outer.append(n),this.$thumbOuter=this.core.outer.find(".lg-thumb-outer").first(),this.$lgThumb=this.core.outer.find(".lg-thumb").first(),this.settings.animateThumb&&this.core.outer.find(".lg-thumb").css("transition-duration",this.core.settings.speed+"ms").css("width",this.thumbTotalWidth+"px").css("position","relative"),this.setThumbItemHtml(this.core.galleryItems)},e.prototype.enableThumbDrag=function(){var t=this,n={cords:{startX:0,endX:0},isMoved:!1,newTranslateX:0,startTime:new Date,endTime:new Date,touchMoveTime:0},r=!1;this.$thumbOuter.addClass("lg-grab"),this.core.outer.find(".lg-thumb").first().on("mousedown.lg.thumb",function(i){t.thumbTotalWidth>t.thumbOuterWidth&&(i.preventDefault(),n.cords.startX=i.pageX,n.startTime=new Date,t.thumbClickable=!1,r=!0,t.core.outer.get().scrollLeft+=1,t.core.outer.get().scrollLeft-=1,t.$thumbOuter.removeClass("lg-grab").addClass("lg-grabbing"))}),this.$LG(window).on("mousemove.lg.thumb.global"+this.core.lgId,function(i){!t.core.lgOpened||r&&(n.cords.endX=i.pageX,n=t.onThumbTouchMove(n))}),this.$LG(window).on("mouseup.lg.thumb.global"+this.core.lgId,function(){!t.core.lgOpened||(n.isMoved?n=t.onThumbTouchEnd(n):t.thumbClickable=!0,r&&(r=!1,t.$thumbOuter.removeClass("lg-grabbing").addClass("lg-grab")))})},e.prototype.enableThumbSwipe=function(){var t=this,n={cords:{startX:0,endX:0},isMoved:!1,newTranslateX:0,startTime:new Date,endTime:new Date,touchMoveTime:0};this.$lgThumb.on("touchstart.lg",function(r){t.thumbTotalWidth>t.thumbOuterWidth&&(r.preventDefault(),n.cords.startX=r.targetTouches[0].pageX,t.thumbClickable=!1,n.startTime=new Date)}),this.$lgThumb.on("touchmove.lg",function(r){t.thumbTotalWidth>t.thumbOuterWidth&&(r.preventDefault(),n.cords.endX=r.targetTouches[0].pageX,n=t.onThumbTouchMove(n))}),this.$lgThumb.on("touchend.lg",function(){n.isMoved?n=t.onThumbTouchEnd(n):t.thumbClickable=!0})},e.prototype.rebuildThumbnails=function(){var t=this;this.$thumbOuter.addClass("lg-rebuilding-thumbnails"),setTimeout(function(){t.thumbTotalWidth=t.core.galleryItems.length*(t.settings.thumbWidth+t.settings.thumbMargin),t.$lgThumb.css("width",t.thumbTotalWidth+"px"),t.$lgThumb.empty(),t.setThumbItemHtml(t.core.galleryItems),t.animateThumb(t.core.index)},50),setTimeout(function(){t.$thumbOuter.removeClass("lg-rebuilding-thumbnails")},200)},e.prototype.setTranslate=function(t){this.$lgThumb.css("transform","translate3d(-"+t+"px, 0px, 0px)")},e.prototype.getPossibleTransformX=function(t){return t>this.thumbTotalWidth-this.thumbOuterWidth&&(t=this.thumbTotalWidth-this.thumbOuterWidth),t<0&&(t=0),t},e.prototype.animateThumb=function(t){if(this.$lgThumb.css("transition-duration",this.core.settings.speed+"ms"),this.settings.animateThumb){var n=0;switch(this.settings.currentPagerPosition){case"left":n=0;break;case"middle":n=this.thumbOuterWidth/2-this.settings.thumbWidth/2;break;case"right":n=this.thumbOuterWidth-this.settings.thumbWidth}this.translateX=(this.settings.thumbWidth+this.settings.thumbMargin)*t-1-n,this.translateX>this.thumbTotalWidth-this.thumbOuterWidth&&(this.translateX=this.thumbTotalWidth-this.thumbOuterWidth),this.translateX<0&&(this.translateX=0),this.setTranslate(this.translateX)}},e.prototype.onThumbTouchMove=function(t){return t.newTranslateX=this.translateX,t.isMoved=!0,t.touchMoveTime=new Date().valueOf(),t.newTranslateX-=t.cords.endX-t.cords.startX,t.newTranslateX=this.getPossibleTransformX(t.newTranslateX),this.setTranslate(t.newTranslateX),this.$thumbOuter.addClass("lg-dragging"),t},e.prototype.onThumbTouchEnd=function(t){t.isMoved=!1,t.endTime=new Date,this.$thumbOuter.removeClass("lg-dragging");var n=t.endTime.valueOf()-t.startTime.valueOf(),r=t.cords.endX-t.cords.startX,i=Math.abs(r)/n;return i>.15&&t.endTime.valueOf()-t.touchMoveTime<30?(i+=1,i>2&&(i+=1),i=i+i*(Math.abs(r)/this.thumbOuterWidth),this.$lgThumb.css("transition-duration",Math.min(i-1,2)+"settings"),r=r*i,this.translateX=this.getPossibleTransformX(this.translateX-r),this.setTranslate(this.translateX)):this.translateX=t.newTranslateX,Math.abs(t.cords.endX-t.cords.startX)<this.settings.thumbnailSwipeThreshold&&(this.thumbClickable=!0),t},e.prototype.getThumbHtml=function(t,n){var r=this.core.galleryItems[n].__slideVideoInfo||{},i;return r.youtube&&this.settings.loadYouTubeThumbnail?i="//img.youtube.com/vi/"+r.youtube[1]+"/"+this.settings.youTubeThumbSize+".jpg":i=t,'<div data-lg-item-id="'+n+'" class="lg-thumb-item '+(n===this.core.index?" active":"")+`"
|
||||
style="width:`+this.settings.thumbWidth+"px; height: "+this.settings.thumbHeight+`;
|
||||
margin-right: `+this.settings.thumbMargin+`px;">
|
||||
<img data-lg-item-id="`+n+'" src="'+i+`" />
|
||||
|
||||
{kind=link}
@ -51,4 +51,4 @@
|
||||
<glyph unicode="" glyph-name="message-circle" data-tags="message-circle" d="M938.667 448.128v21.205c0 0.725-0.043 1.621-0.085 2.475-5.803 99.755-47.488 190.336-112.725 258.176-68.352 71.125-162.731 117.419-268.843 123.264-0.683 0.043-1.536 0.085-2.347 0.085h-20.864c-59.947 0.683-122.965-13.227-181.931-43.008-52.181-26.496-97.749-63.488-133.931-108.16-56.405-69.717-89.899-158.080-89.941-253.696-0.597-54.4 10.795-111.36 35.157-165.419l-75.605-226.859c-2.816-8.363-3.072-17.835 0-26.965 7.467-22.357 31.616-34.432 53.973-26.965l226.731 75.563c49.493-22.485 105.984-35.243 165.376-35.115 58.539 0.384 115.797 13.141 168.149 36.949 81.579 37.163 151.040 101.248 193.749 186.667 27.477 53.291 43.307 115.84 43.136 181.803zM853.333 447.872c0.128-52.267-12.459-101.333-33.664-142.464-34.176-68.352-88.832-118.827-153.259-148.139-41.387-18.859-86.827-28.971-133.376-29.269-52.096-0.128-101.163 12.459-142.293 33.664-10.624 5.504-22.528 6.059-33.067 2.56l-162.261-54.101 54.101 162.261c3.755 11.221 2.56 22.912-2.389 32.725-23.552 46.677-34.304 96.171-33.792 142.421 0.043 76.331 26.411 145.92 70.955 200.917 28.629 35.371 64.768 64.725 106.24 85.76 46.592 23.552 96.085 34.304 142.336 33.792h19.456c83.712-4.565 158.037-41.003 212.011-97.152 51.285-53.376 84.139-124.416 89.003-202.795z" />
|
||||
<glyph unicode="" glyph-name="maximize-2" data-tags="maximize-2" d="M793.003 768l-225.835-225.835c-16.683-16.683-16.683-43.691 0-60.331s43.691-16.683 60.331 0l225.835 225.835v-153.003c0-23.552 19.115-42.667 42.667-42.667s42.667 19.115 42.667 42.667v256c0 5.803-1.152 11.307-3.243 16.341s-5.163 9.728-9.216 13.781c-0.043 0.043-0.043 0.043-0.085 0.085-3.925 3.925-8.619 7.083-13.781 9.216-5.035 2.091-10.539 3.243-16.341 3.243h-256c-23.552 0-42.667-19.115-42.667-42.667s19.115-42.667 42.667-42.667zM230.997 85.334l225.835 225.835c16.683 16.683 16.683 43.691 0 60.331s-43.691 16.683-60.331 0l-225.835-225.835v153.003c0 23.552-19.115 42.667-42.667 42.667s-42.667-19.115-42.667-42.667v-256c0-23.552 19.115-42.667 42.667-42.667h256c23.552 0 42.667 19.115 42.667 42.667s-19.115 42.667-42.667 42.667z" />
|
||||
<glyph unicode="" glyph-name="minimize-2" data-tags="minimize-2" d="M700.331 554.667l225.835 225.835c16.683 16.683 16.683 43.691 0 60.331s-43.691 16.683-60.331 0l-225.835-225.835v153.003c0 23.552-19.115 42.667-42.667 42.667s-42.667-19.115-42.667-42.667v-256c0-5.803 1.152-11.307 3.243-16.341s5.163-9.728 9.216-13.781c0.043-0.043 0.043-0.043 0.085-0.085 3.925-3.925 8.619-7.083 13.781-9.216 5.035-2.091 10.539-3.243 16.341-3.243h256c23.552 0 42.667 19.115 42.667 42.667s-19.115 42.667-42.667 42.667zM158.165 12.502l225.835 225.835v-153.003c0-23.552 19.115-42.667 42.667-42.667s42.667 19.115 42.667 42.667v256c0 5.803-1.152 11.307-3.243 16.341s-5.163 9.728-9.216 13.781c-0.043 0.043-0.043 0.043-0.085 0.085-4.096 4.053-8.789 7.125-13.781 9.216-5.035 2.091-10.539 3.243-16.341 3.243h-256c-23.552 0-42.667-19.115-42.667-42.667s19.115-42.667 42.667-42.667h153.003l-225.835-225.835c-16.683-16.683-16.683-43.691 0-60.331s43.691-16.683 60.331 0z" />
|
||||
</font></defs></svg>
|
||||
</font></defs></svg>
|
||||
|
||||
|
Before Width: | Height: | Size: 12 KiB After Width: | Height: | Size: 12 KiB |
2
frontend/dists/sd-gallery/dist/index.html
vendored
@ -10,4 +10,4 @@
|
||||
<div id="app"></div>
|
||||
|
||||
</body>
|
||||
</html>
|
||||
</html>
|
||||
|
||||
1358
frontend/frontend.py
@ -12,8 +12,8 @@
|
||||
# GNU Affero General Public License for more details.
|
||||
|
||||
# You should have received a copy of the GNU Affero General Public License
|
||||
# along with this program. If not, see <http://www.gnu.org/licenses/>.
|
||||
''' Class to store image generation parameters to be stored as metadata in the image'''
|
||||
# along with this program. If not, see <http://www.gnu.org/licenses/>.
|
||||
""" Class to store image generation parameters to be stored as metadata in the image"""
|
||||
from __future__ import annotations
|
||||
from dataclasses import dataclass, asdict
|
||||
from typing import Dict, Optional
|
||||
@ -21,6 +21,7 @@ from PIL import Image
|
||||
from PIL.PngImagePlugin import PngInfo
|
||||
import copy
|
||||
|
||||
|
||||
@dataclass
|
||||
class ImageMetadata:
|
||||
prompt: str = None
|
||||
@ -40,11 +41,15 @@ class ImageMetadata:
|
||||
return info
|
||||
|
||||
def as_dict(self) -> Dict[str, str]:
|
||||
return {f"SD:{key}": str(value) for key, value in asdict(self).items() if value is not None}
|
||||
return {
|
||||
f"SD:{key}": str(value)
|
||||
for key, value in asdict(self).items()
|
||||
if value is not None
|
||||
}
|
||||
|
||||
@classmethod
|
||||
def set_on_image(cls, image: Image, metadata: ImageMetadata) -> None:
|
||||
''' Sets metadata on image, in both text form and as an ImageMetadata object '''
|
||||
"""Sets metadata on image, in both text form and as an ImageMetadata object"""
|
||||
if metadata:
|
||||
image.info = metadata.as_dict()
|
||||
else:
|
||||
@ -53,8 +58,8 @@ class ImageMetadata:
|
||||
|
||||
@classmethod
|
||||
def get_from_image(cls, image: Image) -> Optional[ImageMetadata]:
|
||||
''' Gets metadata from an image, first looking for an ImageMetadata,
|
||||
then if not found tries to construct one from the info '''
|
||||
"""Gets metadata from an image, first looking for an ImageMetadata,
|
||||
then if not found tries to construct one from the info"""
|
||||
metadata = image.info.get("ImageMetadata", None)
|
||||
if not metadata:
|
||||
found_metadata = False
|
||||
|
||||
@ -8,4 +8,4 @@
|
||||
<div id="app"></div>
|
||||
<script type="module" src="/src/main.ts"></script>
|
||||
</body>
|
||||
</html>
|
||||
</html>
|
||||
|
||||
@ -12,11 +12,11 @@
|
||||
# GNU Affero General Public License for more details.
|
||||
|
||||
# You should have received a copy of the GNU Affero General Public License
|
||||
# along with this program. If not, see <http://www.gnu.org/licenses/>.
|
||||
''' Provides simple job management for gradio, allowing viewing and stopping in-progress multi-batch generations '''
|
||||
# along with this program. If not, see <http://www.gnu.org/licenses/>.
|
||||
""" Provides simple job management for gradio, allowing viewing and stopping in-progress multi-batch generations """
|
||||
from __future__ import annotations
|
||||
import gradio as gr
|
||||
from gradio.components import Component, Gallery, Slider
|
||||
from gradio.components import Component, Gallery
|
||||
from threading import Event, Timer
|
||||
from typing import Callable, List, Dict, Tuple, Optional, Any
|
||||
from dataclasses import dataclass, field
|
||||
@ -82,11 +82,9 @@ def triggerChangeEvent():
|
||||
@dataclass
|
||||
class JobManagerUi:
|
||||
def wrap_func(
|
||||
self,
|
||||
func: Callable,
|
||||
inputs: List[Component],
|
||||
outputs: List[Component]) -> Tuple[Callable, List[Component], List[Component]]:
|
||||
''' Takes a gradio event listener function and its input/outputs and returns wrapped replacements which will
|
||||
self, func: Callable, inputs: List[Component], outputs: List[Component]
|
||||
) -> Tuple[Callable, List[Component], List[Component]]:
|
||||
"""Takes a gradio event listener function and its input/outputs and returns wrapped replacements which will
|
||||
be managed by JobManager
|
||||
Parameters:
|
||||
func (Callable) the original event listener to be wrapped.
|
||||
@ -101,10 +99,9 @@ class JobManagerUi:
|
||||
Returns:
|
||||
Tuple(newFunc (Callable), newInputs (List[Component]), newOutputs (List[Component]), which should be used as
|
||||
replacements for the passed in function, inputs and outputs
|
||||
'''
|
||||
"""
|
||||
return self._job_manager._wrap_func(
|
||||
func=func, inputs=inputs, outputs=outputs,
|
||||
job_ui=self
|
||||
func=func, inputs=inputs, outputs=outputs, job_ui=self
|
||||
)
|
||||
|
||||
_refresh_btn: gr.Button
|
||||
@ -123,7 +120,9 @@ class JobManagerUi:
|
||||
|
||||
|
||||
class JobManager:
|
||||
JOB_MAX_START_TIME = 5.0 # How long can a job be stuck 'starting' before assuming it isn't running
|
||||
JOB_MAX_START_TIME = (
|
||||
5.0 # How long can a job be stuck 'starting' before assuming it isn't running
|
||||
)
|
||||
|
||||
def __init__(self, max_jobs: int):
|
||||
self._max_jobs: int = max_jobs
|
||||
@ -133,66 +132,106 @@ class JobManager:
|
||||
self._session_key: gr.JSON = None
|
||||
|
||||
def draw_gradio_ui(self) -> JobManagerUi:
|
||||
''' draws the job manager ui in gradio
|
||||
Returns:
|
||||
ui (JobManagerUi): object which can connect functions to the ui
|
||||
'''
|
||||
assert gr.context.Context.block is not None, "draw_gradio_ui must be called within a 'gr.Blocks' 'with' context"
|
||||
"""draws the job manager ui in gradio
|
||||
Returns:
|
||||
ui (JobManagerUi): object which can connect functions to the ui
|
||||
"""
|
||||
assert (
|
||||
gr.context.Context.block is not None
|
||||
), "draw_gradio_ui must be called within a 'gr.Blocks' 'with' context"
|
||||
with gr.Tabs():
|
||||
with gr.TabItem("Job Controls"):
|
||||
with gr.Row():
|
||||
stop_btn = gr.Button("Stop All Batches", elem_id="stop", variant="secondary")
|
||||
refresh_btn = gr.Button("Refresh Finished Batches", elem_id="refresh", variant="secondary")
|
||||
status_text = gr.Textbox(placeholder="Job Status", interactive=False, show_label=False)
|
||||
stop_btn = gr.Button(
|
||||
"Stop All Batches", elem_id="stop", variant="secondary"
|
||||
)
|
||||
refresh_btn = gr.Button(
|
||||
"Refresh Finished Batches",
|
||||
elem_id="refresh",
|
||||
variant="secondary",
|
||||
)
|
||||
status_text = gr.Textbox(
|
||||
placeholder="Job Status", interactive=False, show_label=False
|
||||
)
|
||||
with gr.Row():
|
||||
active_image_stop_btn = gr.Button("Skip Active Batch", variant="secondary")
|
||||
active_image_refresh_btn = gr.Button("View Batch Progress", variant="secondary")
|
||||
active_image = gr.Image(type="pil", interactive=False, visible=False, elem_id="active_iteration_image")
|
||||
active_image_stop_btn = gr.Button(
|
||||
"Skip Active Batch", variant="secondary"
|
||||
)
|
||||
active_image_refresh_btn = gr.Button(
|
||||
"View Batch Progress", variant="secondary"
|
||||
)
|
||||
active_image = gr.Image(
|
||||
type="pil",
|
||||
interactive=False,
|
||||
visible=False,
|
||||
elem_id="active_iteration_image",
|
||||
)
|
||||
with gr.TabItem("Batch Progress Settings"):
|
||||
with gr.Row():
|
||||
record_steps_checkbox = gr.Checkbox(value=False, label="Enable Batch Progress Grid")
|
||||
record_steps_checkbox = gr.Checkbox(
|
||||
value=False, label="Enable Batch Progress Grid"
|
||||
)
|
||||
record_steps_interval_slider = gr.Slider(
|
||||
value=3, label="Record Interval (steps)", minimum=1, maximum=25, step=1)
|
||||
with gr.Row() as record_steps_box:
|
||||
steps_to_gallery_checkbox = gr.Checkbox(value=False, label="Save Progress Grid to Gallery")
|
||||
steps_to_file_checkbox = gr.Checkbox(value=False, label="Save Progress Grid to File")
|
||||
value=3,
|
||||
label="Record Interval (steps)",
|
||||
minimum=1,
|
||||
maximum=25,
|
||||
step=1,
|
||||
)
|
||||
with gr.Row():
|
||||
steps_to_gallery_checkbox = gr.Checkbox(
|
||||
value=False, label="Save Progress Grid to Gallery"
|
||||
)
|
||||
steps_to_file_checkbox = gr.Checkbox(
|
||||
value=False, label="Save Progress Grid to File"
|
||||
)
|
||||
with gr.TabItem("Maintenance"):
|
||||
with gr.Row():
|
||||
gr.Markdown(
|
||||
"Stop all concurrent sessions, or free memory associated with jobs which were finished after the browser was closed")
|
||||
"Stop all concurrent sessions, or free memory associated with jobs which were finished after the browser was closed"
|
||||
)
|
||||
with gr.Row():
|
||||
stop_all_sessions_btn = gr.Button(
|
||||
"Stop All Sessions", elem_id="stop_all", variant="secondary"
|
||||
)
|
||||
free_done_sessions_btn = gr.Button(
|
||||
"Clear Finished Jobs", elem_id="clear_finished", variant="secondary"
|
||||
"Clear Finished Jobs",
|
||||
elem_id="clear_finished",
|
||||
variant="secondary",
|
||||
)
|
||||
|
||||
return JobManagerUi(_refresh_btn=refresh_btn, _stop_btn=stop_btn, _status_text=status_text,
|
||||
_stop_all_session_btn=stop_all_sessions_btn, _free_done_sessions_btn=free_done_sessions_btn,
|
||||
_active_image=active_image, _active_image_stop_btn=active_image_stop_btn,
|
||||
_active_image_refresh_btn=active_image_refresh_btn,
|
||||
_rec_steps_checkbox=record_steps_checkbox,
|
||||
_save_rec_steps_to_gallery_chkbx=steps_to_gallery_checkbox,
|
||||
_save_rec_steps_to_file_chkbx=steps_to_file_checkbox,
|
||||
_rec_steps_intrvl_sldr=record_steps_interval_slider, _job_manager=self)
|
||||
return JobManagerUi(
|
||||
_refresh_btn=refresh_btn,
|
||||
_stop_btn=stop_btn,
|
||||
_status_text=status_text,
|
||||
_stop_all_session_btn=stop_all_sessions_btn,
|
||||
_free_done_sessions_btn=free_done_sessions_btn,
|
||||
_active_image=active_image,
|
||||
_active_image_stop_btn=active_image_stop_btn,
|
||||
_active_image_refresh_btn=active_image_refresh_btn,
|
||||
_rec_steps_checkbox=record_steps_checkbox,
|
||||
_save_rec_steps_to_gallery_chkbx=steps_to_gallery_checkbox,
|
||||
_save_rec_steps_to_file_chkbx=steps_to_file_checkbox,
|
||||
_rec_steps_intrvl_sldr=record_steps_interval_slider,
|
||||
_job_manager=self,
|
||||
)
|
||||
|
||||
def clear_all_finished_jobs(self):
|
||||
''' Removes all currently finished jobs, across all sessions.
|
||||
Useful to free memory if a job is started and the browser is closed
|
||||
before it finishes '''
|
||||
"""Removes all currently finished jobs, across all sessions.
|
||||
Useful to free memory if a job is started and the browser is closed
|
||||
before it finishes"""
|
||||
for session in self._sessions.values():
|
||||
session.finished_jobs.clear()
|
||||
|
||||
def stop_all_jobs(self):
|
||||
''' Stops all active jobs, across all sessions'''
|
||||
"""Stops all active jobs, across all sessions"""
|
||||
for session in self._sessions.values():
|
||||
for job in session.jobs.values():
|
||||
job.should_stop.set()
|
||||
job.stop_cur_iter.set()
|
||||
|
||||
def _get_job_token(self, block: bool = False) -> Optional[int]:
|
||||
''' Attempts to acquire a job token, optionally blocking until available '''
|
||||
"""Attempts to acquire a job token, optionally blocking until available"""
|
||||
token = None
|
||||
while token is None:
|
||||
try:
|
||||
@ -212,27 +251,31 @@ class JobManager:
|
||||
return token
|
||||
|
||||
def _release_job_token(self, token: int) -> None:
|
||||
''' Returns a job token to allow another job to start '''
|
||||
"""Returns a job token to allow another job to start"""
|
||||
self._avail_job_tokens.append(token)
|
||||
self._run_queued_jobs()
|
||||
|
||||
def _refresh_func(self, func_key: FuncKey, session_key: str) -> List[Component]:
|
||||
''' Updates information from the active job '''
|
||||
"""Updates information from the active job"""
|
||||
session_info, job_info = self._get_call_info(func_key, session_key)
|
||||
if job_info is None:
|
||||
return [None, f"Session {session_key} was not running function {func_key}"]
|
||||
return [triggerChangeEvent(), job_info.job_status]
|
||||
|
||||
def _stop_wrapped_func(self, func_key: FuncKey, session_key: str) -> List[Component]:
|
||||
''' Marks that the job should be stopped'''
|
||||
def _stop_wrapped_func(
|
||||
self, func_key: FuncKey, session_key: str
|
||||
) -> List[Component]:
|
||||
"""Marks that the job should be stopped"""
|
||||
session_info, job_info = self._get_call_info(func_key, session_key)
|
||||
if job_info is None:
|
||||
return f"Session {session_key} was not running function {func_key}"
|
||||
job_info.should_stop.set()
|
||||
return "Stopping after current batch finishes"
|
||||
|
||||
def _refresh_cur_iter_func(self, func_key: FuncKey, session_key: str) -> List[Component]:
|
||||
''' Updates information from the active iteration '''
|
||||
def _refresh_cur_iter_func(
|
||||
self, func_key: FuncKey, session_key: str
|
||||
) -> List[Component]:
|
||||
"""Updates information from the active iteration"""
|
||||
session_info, job_info = self._get_call_info(func_key, session_key)
|
||||
if job_info is None:
|
||||
return [None, f"Session {session_key} was not running function {func_key}"]
|
||||
@ -240,19 +283,26 @@ class JobManager:
|
||||
job_info.refresh_active_image_requested.set()
|
||||
if job_info.refresh_active_image_done.wait(timeout=20.0):
|
||||
job_info.refresh_active_image_done.clear()
|
||||
return [gr.Image.update(value=job_info.active_image, visible=True), f"Sample iteration {job_info.active_iteration_cnt}"]
|
||||
return [
|
||||
gr.Image.update(value=job_info.active_image, visible=True),
|
||||
f"Sample iteration {job_info.active_iteration_cnt}",
|
||||
]
|
||||
return [gr.Image.update(visible=False), "Timed out getting image"]
|
||||
|
||||
def _stop_cur_iter_func(self, func_key: FuncKey, session_key: str) -> List[Component]:
|
||||
''' Marks that the active iteration should be stopped'''
|
||||
def _stop_cur_iter_func(
|
||||
self, func_key: FuncKey, session_key: str
|
||||
) -> List[Component]:
|
||||
"""Marks that the active iteration should be stopped"""
|
||||
session_info, job_info = self._get_call_info(func_key, session_key)
|
||||
if job_info is None:
|
||||
return [None, f"Session {session_key} was not running function {func_key}"]
|
||||
job_info.stop_cur_iter.set()
|
||||
return [gr.Image.update(visible=False), "Stopping current iteration"]
|
||||
|
||||
def _get_call_info(self, func_key: FuncKey, session_key: str) -> Tuple[SessionInfo, JobInfo]:
|
||||
''' Helper to get the SessionInfo and JobInfo. '''
|
||||
def _get_call_info(
|
||||
self, func_key: FuncKey, session_key: str
|
||||
) -> Tuple[SessionInfo, JobInfo]:
|
||||
"""Helper to get the SessionInfo and JobInfo."""
|
||||
session_info = self._sessions.get(session_key, None)
|
||||
if not session_info:
|
||||
print(f"Couldn't find session {session_key} for call to {func_key}")
|
||||
@ -268,7 +318,7 @@ class JobManager:
|
||||
return session_info, job_info
|
||||
|
||||
def _run_queued_jobs(self) -> None:
|
||||
''' Runs queued jobs for any available slots '''
|
||||
"""Runs queued jobs for any available slots"""
|
||||
if self._avail_job_tokens:
|
||||
try:
|
||||
# Notify next queued job it may begin
|
||||
@ -282,10 +332,18 @@ class JobManager:
|
||||
pass # No queued jobs
|
||||
|
||||
def _pre_call_func(
|
||||
self, func_key: FuncKey, output_dummy_obj: Component, refresh_btn: gr.Button, stop_btn: gr.Button,
|
||||
status_text: gr.Textbox, active_image: gr.Image, active_refresh_btn: gr.Button, active_stop_btn: gr.Button,
|
||||
session_key: str) -> List[Component]:
|
||||
''' Called when a job is about to start '''
|
||||
self,
|
||||
func_key: FuncKey,
|
||||
output_dummy_obj: Component,
|
||||
refresh_btn: gr.Button,
|
||||
stop_btn: gr.Button,
|
||||
status_text: gr.Textbox,
|
||||
active_image: gr.Image,
|
||||
active_refresh_btn: gr.Button,
|
||||
active_stop_btn: gr.Button,
|
||||
session_key: str,
|
||||
) -> List[Component]:
|
||||
"""Called when a job is about to start"""
|
||||
session_info, job_info = self._get_call_info(func_key, session_key)
|
||||
|
||||
# If we didn't already get a token then queue up for one
|
||||
@ -293,16 +351,23 @@ class JobManager:
|
||||
job_info.job_token = self._get_job_token(block=True)
|
||||
|
||||
# Buttons don't seem to update unless value is set on them as well...
|
||||
return {output_dummy_obj: triggerChangeEvent(),
|
||||
refresh_btn: gr.Button.update(variant="primary", value=refresh_btn.value),
|
||||
stop_btn: gr.Button.update(variant="primary", value=stop_btn.value),
|
||||
status_text: gr.Textbox.update(value="Generation has started. Click 'Refresh' to see finished images, 'View Batch Progress' for active images"),
|
||||
active_refresh_btn: gr.Button.update(variant="primary", value=active_refresh_btn.value),
|
||||
active_stop_btn: gr.Button.update(variant="primary", value=active_stop_btn.value),
|
||||
}
|
||||
return {
|
||||
output_dummy_obj: triggerChangeEvent(),
|
||||
refresh_btn: gr.Button.update(variant="primary", value=refresh_btn.value),
|
||||
stop_btn: gr.Button.update(variant="primary", value=stop_btn.value),
|
||||
status_text: gr.Textbox.update(
|
||||
value="Generation has started. Click 'Refresh' to see finished images, 'View Batch Progress' for active images"
|
||||
),
|
||||
active_refresh_btn: gr.Button.update(
|
||||
variant="primary", value=active_refresh_btn.value
|
||||
),
|
||||
active_stop_btn: gr.Button.update(
|
||||
variant="primary", value=active_stop_btn.value
|
||||
),
|
||||
}
|
||||
|
||||
def _call_func(self, func_key: FuncKey, session_key: str) -> List[Component]:
|
||||
''' Runs the real function with job management. '''
|
||||
"""Runs the real function with job management."""
|
||||
session_info, job_info = self._get_call_info(func_key, session_key)
|
||||
if session_info is None or job_info is None:
|
||||
return []
|
||||
@ -310,7 +375,9 @@ class JobManager:
|
||||
job_info.started = True
|
||||
try:
|
||||
if job_info.should_stop.is_set():
|
||||
raise Exception(f"Job {job_info} requested a stop before execution began")
|
||||
raise Exception(
|
||||
f"Job {job_info} requested a stop before execution began"
|
||||
)
|
||||
outputs = job_info.func(*job_info.inputs, job_info=job_info)
|
||||
except Exception as e:
|
||||
job_info.job_status = f"Error: {e}"
|
||||
@ -334,35 +401,56 @@ class JobManager:
|
||||
return tuple(filtered_output)
|
||||
|
||||
def _post_call_func(
|
||||
self, func_key: FuncKey, output_dummy_obj: Component, refresh_btn: gr.Button, stop_btn: gr.Button,
|
||||
status_text: gr.Textbox, active_image: gr.Image, active_refresh_btn: gr.Button, active_stop_btn: gr.Button,
|
||||
session_key: str) -> List[Component]:
|
||||
''' Called when a job completes '''
|
||||
return {output_dummy_obj: triggerChangeEvent(),
|
||||
refresh_btn: gr.Button.update(variant="secondary", value=refresh_btn.value),
|
||||
stop_btn: gr.Button.update(variant="secondary", value=stop_btn.value),
|
||||
status_text: gr.Textbox.update(value="Generation has finished!"),
|
||||
active_refresh_btn: gr.Button.update(variant="secondary", value=active_refresh_btn.value),
|
||||
active_stop_btn: gr.Button.update(variant="secondary", value=active_stop_btn.value),
|
||||
active_image: gr.Image.update(visible=False)
|
||||
}
|
||||
self,
|
||||
func_key: FuncKey,
|
||||
output_dummy_obj: Component,
|
||||
refresh_btn: gr.Button,
|
||||
stop_btn: gr.Button,
|
||||
status_text: gr.Textbox,
|
||||
active_image: gr.Image,
|
||||
active_refresh_btn: gr.Button,
|
||||
active_stop_btn: gr.Button,
|
||||
session_key: str,
|
||||
) -> List[Component]:
|
||||
"""Called when a job completes"""
|
||||
return {
|
||||
output_dummy_obj: triggerChangeEvent(),
|
||||
refresh_btn: gr.Button.update(variant="secondary", value=refresh_btn.value),
|
||||
stop_btn: gr.Button.update(variant="secondary", value=stop_btn.value),
|
||||
status_text: gr.Textbox.update(value="Generation has finished!"),
|
||||
active_refresh_btn: gr.Button.update(
|
||||
variant="secondary", value=active_refresh_btn.value
|
||||
),
|
||||
active_stop_btn: gr.Button.update(
|
||||
variant="secondary", value=active_stop_btn.value
|
||||
),
|
||||
active_image: gr.Image.update(visible=False),
|
||||
}
|
||||
|
||||
def _update_gallery_event(self, func_key: FuncKey, session_key: str) -> List[Component]:
|
||||
''' Updates the gallery with results from the given job.
|
||||
Frees the images after return if the job is finished.
|
||||
Triggered by changing the update_gallery_obj dummy object '''
|
||||
def _update_gallery_event(
|
||||
self, func_key: FuncKey, session_key: str
|
||||
) -> List[Component]:
|
||||
"""Updates the gallery with results from the given job.
|
||||
Frees the images after return if the job is finished.
|
||||
Triggered by changing the update_gallery_obj dummy object"""
|
||||
session_info, job_info = self._get_call_info(func_key, session_key)
|
||||
if session_info is None or job_info is None:
|
||||
return []
|
||||
|
||||
return job_info.images
|
||||
|
||||
def _wrap_func(self, func: Callable, inputs: List[Component],
|
||||
outputs: List[Component],
|
||||
job_ui: JobManagerUi) -> Tuple[Callable, List[Component]]:
|
||||
''' handles JobManageUI's wrap_func'''
|
||||
def _wrap_func(
|
||||
self,
|
||||
func: Callable,
|
||||
inputs: List[Component],
|
||||
outputs: List[Component],
|
||||
job_ui: JobManagerUi,
|
||||
) -> Tuple[Callable, List[Component]]:
|
||||
"""handles JobManageUI's wrap_func"""
|
||||
|
||||
assert gr.context.Context.block is not None, "wrap_func must be called within a 'gr.Blocks' 'with' context"
|
||||
assert (
|
||||
gr.context.Context.block is not None
|
||||
), "wrap_func must be called within a 'gr.Blocks' 'with' context"
|
||||
|
||||
# Create a unique key for this job
|
||||
func_key = FuncKey(job_id=uuid.uuid4().hex, func=func)
|
||||
@ -370,8 +458,11 @@ class JobManager:
|
||||
# Create a unique session key (next gradio release can use gr.State, see https://gradio.app/state_in_blocks/)
|
||||
if self._session_key is None:
|
||||
# When this gradio object is received as an event handler input it will resolve to a unique per-session id
|
||||
self._session_key = gr.JSON(value=lambda: uuid.uuid4().hex, visible=False,
|
||||
elem_id="JobManagerDummyObject_sessionKey")
|
||||
self._session_key = gr.JSON(
|
||||
value=lambda: uuid.uuid4().hex,
|
||||
visible=False,
|
||||
elem_id="JobManagerDummyObject_sessionKey",
|
||||
)
|
||||
|
||||
# Pull the gallery out of the original outputs and assign it to the gallery update dummy object
|
||||
gallery_comp = None
|
||||
@ -389,25 +480,25 @@ class JobManager:
|
||||
partial(self._update_gallery_event, func_key),
|
||||
[self._session_key],
|
||||
[gallery_comp],
|
||||
queue=False
|
||||
queue=False,
|
||||
)
|
||||
|
||||
if job_ui._refresh_btn:
|
||||
job_ui._refresh_btn.variant = 'secondary'
|
||||
job_ui._refresh_btn.variant = "secondary"
|
||||
job_ui._refresh_btn.click(
|
||||
partial(self._refresh_func, func_key),
|
||||
[self._session_key],
|
||||
[update_gallery_obj, job_ui._status_text],
|
||||
queue=False
|
||||
queue=False,
|
||||
)
|
||||
|
||||
if job_ui._stop_btn:
|
||||
job_ui._stop_btn.variant = 'secondary'
|
||||
job_ui._stop_btn.variant = "secondary"
|
||||
job_ui._stop_btn.click(
|
||||
partial(self._stop_wrapped_func, func_key),
|
||||
[self._session_key],
|
||||
[job_ui._status_text],
|
||||
queue=False
|
||||
queue=False,
|
||||
)
|
||||
|
||||
if job_ui._active_image and job_ui._active_image_refresh_btn:
|
||||
@ -415,7 +506,7 @@ class JobManager:
|
||||
partial(self._refresh_cur_iter_func, func_key),
|
||||
[self._session_key],
|
||||
[job_ui._active_image, job_ui._status_text],
|
||||
queue=False
|
||||
queue=False,
|
||||
)
|
||||
|
||||
if job_ui._active_image_stop_btn:
|
||||
@ -423,19 +514,15 @@ class JobManager:
|
||||
partial(self._stop_cur_iter_func, func_key),
|
||||
[self._session_key],
|
||||
[job_ui._active_image, job_ui._status_text],
|
||||
queue=False
|
||||
queue=False,
|
||||
)
|
||||
|
||||
if job_ui._stop_all_session_btn:
|
||||
job_ui._stop_all_session_btn.click(
|
||||
self.stop_all_jobs, [], [],
|
||||
queue=False
|
||||
)
|
||||
job_ui._stop_all_session_btn.click(self.stop_all_jobs, [], [], queue=False)
|
||||
|
||||
if job_ui._free_done_sessions_btn:
|
||||
job_ui._free_done_sessions_btn.click(
|
||||
self.clear_all_finished_jobs, [], [],
|
||||
queue=False
|
||||
self.clear_all_finished_jobs, [], [], queue=False
|
||||
)
|
||||
|
||||
# (ab)use gr.JSON to forward events.
|
||||
@ -452,18 +539,26 @@ class JobManager:
|
||||
# Since some parameters are optional it makes sense to use the 'dict' return value type, which requires
|
||||
# the Component as a key... so group together the UI components that the event listeners are going to update
|
||||
# to make it easy to append to function calls and outputs
|
||||
job_ui_params = [job_ui._refresh_btn, job_ui._stop_btn, job_ui._status_text,
|
||||
job_ui._active_image, job_ui._active_image_refresh_btn, job_ui._active_image_stop_btn]
|
||||
job_ui_params = [
|
||||
job_ui._refresh_btn,
|
||||
job_ui._stop_btn,
|
||||
job_ui._status_text,
|
||||
job_ui._active_image,
|
||||
job_ui._active_image_refresh_btn,
|
||||
job_ui._active_image_stop_btn,
|
||||
]
|
||||
job_ui_outputs = [comp for comp in job_ui_params if comp is not None]
|
||||
|
||||
# Here a chain is constructed that will make a 'pre' call, a 'run' call, and a 'post' call,
|
||||
# to be able to update the UI before and after, as well as run the actual call
|
||||
post_call_dummyobj = gr.JSON(visible=False, elem_id="JobManagerDummyObject_postCall")
|
||||
post_call_dummyobj = gr.JSON(
|
||||
visible=False, elem_id="JobManagerDummyObject_postCall"
|
||||
)
|
||||
post_call_dummyobj.change(
|
||||
partial(self._post_call_func, func_key, update_gallery_obj, *job_ui_params),
|
||||
[self._session_key],
|
||||
[update_gallery_obj] + job_ui_outputs,
|
||||
queue=False
|
||||
queue=False,
|
||||
)
|
||||
|
||||
call_dummyobj = gr.JSON(visible=False, elem_id="JobManagerDummyObject_runCall")
|
||||
@ -471,20 +566,27 @@ class JobManager:
|
||||
partial(self._call_func, func_key),
|
||||
[self._session_key],
|
||||
outputs + [post_call_dummyobj],
|
||||
queue=False
|
||||
queue=False,
|
||||
)
|
||||
|
||||
pre_call_dummyobj = gr.JSON(visible=False, elem_id="JobManagerDummyObject_preCall")
|
||||
pre_call_dummyobj = gr.JSON(
|
||||
visible=False, elem_id="JobManagerDummyObject_preCall"
|
||||
)
|
||||
pre_call_dummyobj.change(
|
||||
partial(self._pre_call_func, func_key, call_dummyobj, *job_ui_params),
|
||||
[self._session_key],
|
||||
[call_dummyobj] + job_ui_outputs,
|
||||
queue=False
|
||||
queue=False,
|
||||
)
|
||||
|
||||
# Add any components that we want the runtime values for
|
||||
added_inputs = [self._session_key, job_ui._rec_steps_checkbox, job_ui._save_rec_steps_to_gallery_chkbx,
|
||||
job_ui._save_rec_steps_to_file_chkbx, job_ui._rec_steps_intrvl_sldr]
|
||||
added_inputs = [
|
||||
self._session_key,
|
||||
job_ui._rec_steps_checkbox,
|
||||
job_ui._save_rec_steps_to_gallery_chkbx,
|
||||
job_ui._save_rec_steps_to_file_chkbx,
|
||||
job_ui._rec_steps_intrvl_sldr,
|
||||
]
|
||||
|
||||
# Now replace the original function with one that creates a JobInfo and triggers the dummy obj
|
||||
def wrapped_func(*wrapped_inputs):
|
||||
@ -505,12 +607,19 @@ class JobManager:
|
||||
if func_key in session_info.jobs:
|
||||
job_info = session_info.jobs[func_key]
|
||||
# If the job seems stuck in 'starting' then go ahead and toss it
|
||||
if not job_info.started and time.time() > job_info.timestamp + JobManager.JOB_MAX_START_TIME:
|
||||
if (
|
||||
not job_info.started
|
||||
and time.time() > job_info.timestamp + JobManager.JOB_MAX_START_TIME
|
||||
):
|
||||
job_info.should_stop.set()
|
||||
job_info.stop_cur_iter.set()
|
||||
session_info.jobs.pop(func_key)
|
||||
return {job_ui._status_text: "Canceled possibly hung job. Try again"}
|
||||
return {job_ui._status_text: "This session is already running that function!"}
|
||||
return {
|
||||
job_ui._status_text: "Canceled possibly hung job. Try again"
|
||||
}
|
||||
return {
|
||||
job_ui._status_text: "This session is already running that function!"
|
||||
}
|
||||
|
||||
# Is this a new run of a previously finished job? Clear old info
|
||||
if func_key in session_info.finished_jobs:
|
||||
@ -518,9 +627,17 @@ class JobManager:
|
||||
|
||||
job_token = self._get_job_token(block=False)
|
||||
job = JobInfo(
|
||||
inputs=job_inputs, func=func, removed_output_idxs=removed_idxs, session_key=session_key,
|
||||
job_token=job_token, rec_steps_enabled=record_steps_enabled, rec_steps_intrvl=rec_steps_interval,
|
||||
rec_steps_to_gallery=save_rec_steps_grid, rec_steps_to_file=save_rec_steps_file, timestamp=time.time())
|
||||
inputs=job_inputs,
|
||||
func=func,
|
||||
removed_output_idxs=removed_idxs,
|
||||
session_key=session_key,
|
||||
job_token=job_token,
|
||||
rec_steps_enabled=record_steps_enabled,
|
||||
rec_steps_intrvl=rec_steps_interval,
|
||||
rec_steps_to_gallery=save_rec_steps_grid,
|
||||
rec_steps_to_file=save_rec_steps_file,
|
||||
timestamp=time.time(),
|
||||
)
|
||||
session_info.jobs[func_key] = job
|
||||
|
||||
ret = {pre_call_dummyobj: triggerChangeEvent()}
|
||||
@ -528,4 +645,8 @@ class JobManager:
|
||||
ret[job_ui._status_text] = "Job is queued"
|
||||
return ret
|
||||
|
||||
return wrapped_func, inputs + added_inputs, [pre_call_dummyobj, job_ui._status_text]
|
||||
return (
|
||||
wrapped_func,
|
||||
inputs + added_inputs,
|
||||
[pre_call_dummyobj, job_ui._status_text],
|
||||
)
|
||||
|
||||
@ -240,4 +240,4 @@ svg.no-preview-icon {
|
||||
border-color: var(--primary-color);
|
||||
color: var(--primary-color);
|
||||
} */
|
||||
</style>
|
||||
</style>
|
||||
|
||||
@ -49,4 +49,3 @@ body, html {
|
||||
|
||||
|
||||
</style>
|
||||
|
||||
|
||||
{kind=link}
@ -1 +1 @@
|
||||
<svg xmlns="http://www.w3.org/2000/svg" viewBox="0 0 32 32" fill="#fff"><path d="M 16 2 C 14.742188 2 13.847656 2.890625 13.40625 4 L 5 4 L 5 29 L 27 29 L 27 4 L 18.59375 4 C 18.152344 2.890625 17.257813 2 16 2 Z M 16 4 C 16.554688 4 17 4.445313 17 5 L 17 6 L 20 6 L 20 8 L 12 8 L 12 6 L 15 6 L 15 5 C 15 4.445313 15.445313 4 16 4 Z M 7 6 L 10 6 L 10 10 L 22 10 L 22 6 L 25 6 L 25 27 L 7 27 Z M 21.28125 13.28125 L 15 19.5625 L 11.71875 16.28125 L 10.28125 17.71875 L 14.28125 21.71875 L 15 22.40625 L 15.71875 21.71875 L 22.71875 14.71875 Z"/></svg>
|
||||
<svg xmlns="http://www.w3.org/2000/svg" viewBox="0 0 32 32" fill="#fff"><path d="M 16 2 C 14.742188 2 13.847656 2.890625 13.40625 4 L 5 4 L 5 29 L 27 29 L 27 4 L 18.59375 4 C 18.152344 2.890625 17.257813 2 16 2 Z M 16 4 C 16.554688 4 17 4.445313 17 5 L 17 6 L 20 6 L 20 8 L 12 8 L 12 6 L 15 6 L 15 5 C 15 4.445313 15.445313 4 16 4 Z M 7 6 L 10 6 L 10 10 L 22 10 L 22 6 L 25 6 L 25 27 L 7 27 Z M 21.28125 13.28125 L 15 19.5625 L 11.71875 16.28125 L 10.28125 17.71875 L 14.28125 21.71875 L 15 22.40625 L 15.71875 21.71875 L 22.71875 14.71875 Z"/></svg>
|
||||
|
||||
|
Before Width: | Height: | Size: 550 B After Width: | Height: | Size: 551 B |
{kind=link}
@ -1 +1 @@
|
||||
<svg xmlns="http://www.w3.org/2000/svg" viewBox="0 0 32 32" fill="#fff"><path d="M 15 3 C 13.742188 3 12.847656 3.890625 12.40625 5 L 5 5 L 5 28 L 13 28 L 13 30 L 27 30 L 27 14 L 25 14 L 25 5 L 17.59375 5 C 17.152344 3.890625 16.257813 3 15 3 Z M 15 5 C 15.554688 5 16 5.445313 16 6 L 16 7 L 19 7 L 19 9 L 11 9 L 11 7 L 14 7 L 14 6 C 14 5.445313 14.445313 5 15 5 Z M 7 7 L 9 7 L 9 11 L 21 11 L 21 7 L 23 7 L 23 14 L 13 14 L 13 26 L 7 26 Z M 15 16 L 25 16 L 25 28 L 15 28 Z"/></svg>
|
||||
<svg xmlns="http://www.w3.org/2000/svg" viewBox="0 0 32 32" fill="#fff"><path d="M 15 3 C 13.742188 3 12.847656 3.890625 12.40625 5 L 5 5 L 5 28 L 13 28 L 13 30 L 27 30 L 27 14 L 25 14 L 25 5 L 17.59375 5 C 17.152344 3.890625 16.257813 3 15 3 Z M 15 5 C 15.554688 5 16 5.445313 16 6 L 16 7 L 19 7 L 19 9 L 11 9 L 11 7 L 14 7 L 14 6 C 14 5.445313 14.445313 5 15 5 Z M 7 7 L 9 7 L 9 11 L 21 11 L 21 7 L 23 7 L 23 14 L 13 14 L 13 26 L 7 26 Z M 15 16 L 25 16 L 25 28 L 15 28 Z"/></svg>
|
||||
|
||||
|
Before Width: | Height: | Size: 481 B After Width: | Height: | Size: 482 B |
{kind=link}
@ -1 +1 @@
|
||||
<svg xmlns="http://www.w3.org/2000/svg" viewBox="0 0 32 32" fill="#3F6078"><path d="M 30.335938 12.546875 L 20.164063 11.472656 L 16 2.132813 L 11.835938 11.472656 L 1.664063 12.546875 L 9.261719 19.394531 L 7.140625 29.398438 L 16 24.289063 L 24.859375 29.398438 L 22.738281 19.394531 Z"/></svg>
|
||||
<svg xmlns="http://www.w3.org/2000/svg" viewBox="0 0 32 32" fill="#3F6078"><path d="M 30.335938 12.546875 L 20.164063 11.472656 L 16 2.132813 L 11.835938 11.472656 L 1.664063 12.546875 L 9.261719 19.394531 L 7.140625 29.398438 L 16 24.289063 L 24.859375 29.398438 L 22.738281 19.394531 Z"/></svg>
|
||||
|
||||
|
Before Width: | Height: | Size: 296 B After Width: | Height: | Size: 297 B |
{kind=link}
@ -1 +1 @@
|
||||
<svg xmlns="http://www.w3.org/2000/svg" viewBox="0 0 32 32" fill="#3F6078"><path d="M 30.335938 12.546875 L 20.164063 11.472656 L 16 2.132813 L 11.835938 11.472656 L 1.664063 12.546875 L 9.261719 19.394531 L 7.140625 29.398438 L 16 24.289063 L 24.859375 29.398438 L 22.738281 19.394531 Z"/></svg>
|
||||
<svg xmlns="http://www.w3.org/2000/svg" viewBox="0 0 32 32" fill="#3F6078"><path d="M 30.335938 12.546875 L 20.164063 11.472656 L 16 2.132813 L 11.835938 11.472656 L 1.664063 12.546875 L 9.261719 19.394531 L 7.140625 29.398438 L 16 24.289063 L 24.859375 29.398438 L 22.738281 19.394531 Z"/></svg>
|
||||
|
||||
|
Before Width: | Height: | Size: 296 B After Width: | Height: | Size: 297 B |
@ -5,7 +5,7 @@
|
||||
<h1 class="err__title">Component Error</h1>
|
||||
<div class="err__msg">Message: {{ componentError }}</div>
|
||||
</div>
|
||||
<!--
|
||||
<!--
|
||||
Else render the component slot and pass Streamlit event data in `args` props to it.
|
||||
Don't render until we've gotten our first RENDER_EVENT from Streamlit.
|
||||
All components get disabled while the app is being re-run, and become re-enabled when the re-run has finished.
|
||||
|
||||
@ -12,122 +12,170 @@
|
||||
# GNU Affero General Public License for more details.
|
||||
|
||||
# You should have received a copy of the GNU Affero General Public License
|
||||
# along with this program. If not, see <http://www.gnu.org/licenses/>.
|
||||
# along with this program. If not, see <http://www.gnu.org/licenses/>.
|
||||
import re
|
||||
import gradio as gr
|
||||
from PIL import Image, ImageFont, ImageDraw, ImageFilter, ImageOps
|
||||
from PIL import Image
|
||||
from io import BytesIO
|
||||
import base64
|
||||
import re
|
||||
|
||||
|
||||
def change_image_editor_mode(choice, cropped_image, masked_image, resize_mode, width, height):
|
||||
def change_image_editor_mode(
|
||||
choice, cropped_image, masked_image, resize_mode, width, height
|
||||
):
|
||||
if choice == "Mask":
|
||||
update_image_result = update_image_mask(cropped_image, resize_mode, width, height)
|
||||
return [gr.update(visible=False), update_image_result, gr.update(visible=False), gr.update(visible=True), gr.update(visible=False), gr.update(visible=True), gr.update(visible=True), gr.update(visible=True)]
|
||||
update_image_result = update_image_mask(
|
||||
cropped_image, resize_mode, width, height
|
||||
)
|
||||
return [
|
||||
gr.update(visible=False),
|
||||
update_image_result,
|
||||
gr.update(visible=False),
|
||||
gr.update(visible=True),
|
||||
gr.update(visible=False),
|
||||
gr.update(visible=True),
|
||||
gr.update(visible=True),
|
||||
gr.update(visible=True),
|
||||
]
|
||||
|
||||
update_image_result = update_image_mask(
|
||||
masked_image["image"] if masked_image is not None else None,
|
||||
resize_mode,
|
||||
width,
|
||||
height,
|
||||
)
|
||||
return [
|
||||
update_image_result,
|
||||
gr.update(visible=False),
|
||||
gr.update(visible=True),
|
||||
gr.update(visible=False),
|
||||
gr.update(visible=True),
|
||||
gr.update(visible=False),
|
||||
gr.update(visible=False),
|
||||
gr.update(visible=False),
|
||||
]
|
||||
|
||||
update_image_result = update_image_mask(masked_image["image"] if masked_image is not None else None, resize_mode, width, height)
|
||||
return [update_image_result, gr.update(visible=False), gr.update(visible=True), gr.update(visible=False), gr.update(visible=True), gr.update(visible=False), gr.update(visible=False), gr.update(visible=False)]
|
||||
|
||||
def update_image_mask(cropped_image, resize_mode, width, height):
|
||||
resized_cropped_image = resize_image(resize_mode, cropped_image, width, height) if cropped_image else None
|
||||
resized_cropped_image = (
|
||||
resize_image(resize_mode, cropped_image, width, height)
|
||||
if cropped_image
|
||||
else None
|
||||
)
|
||||
return gr.update(value=resized_cropped_image, visible=True)
|
||||
|
||||
|
||||
def toggle_options_gfpgan(selection):
|
||||
if 0 in selection:
|
||||
return gr.update(visible=True)
|
||||
else:
|
||||
return gr.update(visible=False)
|
||||
|
||||
|
||||
def toggle_options_upscalers(selection):
|
||||
if 1 in selection:
|
||||
return gr.update(visible=True)
|
||||
else:
|
||||
return gr.update(visible=False)
|
||||
|
||||
|
||||
def toggle_options_realesrgan(selection):
|
||||
if selection == 0 or selection == 1 or selection == 3:
|
||||
return gr.update(visible=True)
|
||||
else:
|
||||
return gr.update(visible=False)
|
||||
|
||||
|
||||
def toggle_options_gobig(selection):
|
||||
if selection == 1:
|
||||
#print(selection)
|
||||
# print(selection)
|
||||
return gr.update(visible=True)
|
||||
if selection == 3:
|
||||
return gr.update(visible=True)
|
||||
else:
|
||||
return gr.update(visible=False)
|
||||
|
||||
|
||||
def toggle_options_ldsr(selection):
|
||||
if selection == 2 or selection == 3:
|
||||
return gr.update(visible=True)
|
||||
else:
|
||||
return gr.update(visible=False)
|
||||
|
||||
|
||||
def increment_down(value):
|
||||
return value - 1
|
||||
|
||||
|
||||
def increment_up(value):
|
||||
return value + 1
|
||||
|
||||
|
||||
def copy_img_to_lab(img):
|
||||
try:
|
||||
image_data = re.sub('^data:image/.+;base64,', '', img)
|
||||
image_data = re.sub("^data:image/.+;base64,", "", img)
|
||||
processed_image = Image.open(BytesIO(base64.b64decode(image_data)))
|
||||
tab_update = gr.update(selected='imgproc_tab')
|
||||
img_update = gr.update(value=processed_image)
|
||||
return processed_image, tab_update,
|
||||
tab_update = gr.update(selected="imgproc_tab")
|
||||
gr.update(value=processed_image)
|
||||
return (
|
||||
processed_image,
|
||||
tab_update,
|
||||
)
|
||||
except IndexError:
|
||||
return [None, None]
|
||||
|
||||
|
||||
def copy_img_params_to_lab(params):
|
||||
try:
|
||||
prompt = params[0][0].replace('\n', ' ').replace('\r', '')
|
||||
prompt = params[0][0].replace("\n", " ").replace("\r", "")
|
||||
seed = int(params[1][1])
|
||||
steps = int(params[7][1])
|
||||
cfg_scale = float(params[9][1])
|
||||
sampler = params[11][1]
|
||||
return prompt,seed,steps,cfg_scale,sampler
|
||||
return prompt, seed, steps, cfg_scale, sampler
|
||||
except IndexError:
|
||||
return [None, None]
|
||||
|
||||
|
||||
def copy_img_to_input(img):
|
||||
try:
|
||||
image_data = re.sub('^data:image/.+;base64,', '', img)
|
||||
image_data = re.sub("^data:image/.+;base64,", "", img)
|
||||
processed_image = Image.open(BytesIO(base64.b64decode(image_data)))
|
||||
tab_update = gr.update(selected='img2img_tab')
|
||||
img_update = gr.update(value=processed_image)
|
||||
return processed_image, processed_image , tab_update
|
||||
tab_update = gr.update(selected="img2img_tab")
|
||||
gr.update(value=processed_image)
|
||||
return processed_image, processed_image, tab_update
|
||||
except IndexError:
|
||||
return [None, None]
|
||||
|
||||
|
||||
def copy_img_to_edit(img):
|
||||
try:
|
||||
image_data = re.sub('^data:image/.+;base64,', '', img)
|
||||
image_data = re.sub("^data:image/.+;base64,", "", img)
|
||||
processed_image = Image.open(BytesIO(base64.b64decode(image_data)))
|
||||
tab_update = gr.update(selected='img2img_tab')
|
||||
img_update = gr.update(value=processed_image)
|
||||
mode_update = gr.update(value='Crop')
|
||||
tab_update = gr.update(selected="img2img_tab")
|
||||
gr.update(value=processed_image)
|
||||
mode_update = gr.update(value="Crop")
|
||||
return processed_image, tab_update, mode_update
|
||||
except IndexError:
|
||||
return [None, None]
|
||||
|
||||
|
||||
def copy_img_to_mask(img):
|
||||
try:
|
||||
image_data = re.sub('^data:image/.+;base64,', '', img)
|
||||
image_data = re.sub("^data:image/.+;base64,", "", img)
|
||||
processed_image = Image.open(BytesIO(base64.b64decode(image_data)))
|
||||
tab_update = gr.update(selected='img2img_tab')
|
||||
img_update = gr.update(value=processed_image)
|
||||
mode_update = gr.update(value='Mask')
|
||||
tab_update = gr.update(selected="img2img_tab")
|
||||
gr.update(value=processed_image)
|
||||
mode_update = gr.update(value="Mask")
|
||||
return processed_image, tab_update, mode_update
|
||||
except IndexError:
|
||||
return [None, None]
|
||||
|
||||
|
||||
|
||||
def copy_img_to_upscale_esrgan(img):
|
||||
tabs_update = gr.update(selected='realesrgan_tab')
|
||||
image_data = re.sub('^data:image/.+;base64,', '', img)
|
||||
tabs_update = gr.update(selected="realesrgan_tab")
|
||||
image_data = re.sub("^data:image/.+;base64,", "", img)
|
||||
processed_image = Image.open(BytesIO(base64.b64decode(image_data)))
|
||||
return processed_image, tabs_update
|
||||
|
||||
@ -147,8 +195,11 @@ help_text = """
|
||||
If anything breaks, try switching modes again, switch tabs, clear the image, or reload.
|
||||
"""
|
||||
|
||||
|
||||
def resize_image(resize_mode, im, width, height):
|
||||
LANCZOS = (Image.Resampling.LANCZOS if hasattr(Image, 'Resampling') else Image.LANCZOS)
|
||||
LANCZOS = (
|
||||
Image.Resampling.LANCZOS if hasattr(Image, "Resampling") else Image.LANCZOS
|
||||
)
|
||||
if resize_mode == 0:
|
||||
res = im.resize((width, height), resample=LANCZOS)
|
||||
elif resize_mode == 1:
|
||||
@ -174,28 +225,45 @@ def resize_image(resize_mode, im, width, height):
|
||||
|
||||
if ratio < src_ratio:
|
||||
fill_height = height // 2 - src_h // 2
|
||||
res.paste(resized.resize((width, fill_height), box=(0, 0, width, 0)), box=(0, 0))
|
||||
res.paste(resized.resize((width, fill_height), box=(0, resized.height, width, resized.height)), box=(0, fill_height + src_h))
|
||||
res.paste(
|
||||
resized.resize((width, fill_height), box=(0, 0, width, 0)), box=(0, 0)
|
||||
)
|
||||
res.paste(
|
||||
resized.resize(
|
||||
(width, fill_height), box=(0, resized.height, width, resized.height)
|
||||
),
|
||||
box=(0, fill_height + src_h),
|
||||
)
|
||||
elif ratio > src_ratio:
|
||||
fill_width = width // 2 - src_w // 2
|
||||
res.paste(resized.resize((fill_width, height), box=(0, 0, 0, height)), box=(0, 0))
|
||||
res.paste(resized.resize((fill_width, height), box=(resized.width, 0, resized.width, height)), box=(fill_width + src_w, 0))
|
||||
res.paste(
|
||||
resized.resize((fill_width, height), box=(0, 0, 0, height)), box=(0, 0)
|
||||
)
|
||||
res.paste(
|
||||
resized.resize(
|
||||
(fill_width, height), box=(resized.width, 0, resized.width, height)
|
||||
),
|
||||
box=(fill_width + src_w, 0),
|
||||
)
|
||||
|
||||
return res
|
||||
|
||||
|
||||
def update_dimensions_info(width, height):
|
||||
pixel_count_formated = "{:,.0f}".format(width * height)
|
||||
return f"Aspect ratio: {round(width / height, 5)}\nTotal pixel count: {pixel_count_formated}"
|
||||
|
||||
def get_png_nfo( image: Image ):
|
||||
|
||||
def get_png_nfo(image: Image):
|
||||
info_text = ""
|
||||
visible = bool(image and any(image.info))
|
||||
if visible:
|
||||
for key,value in image.info.items():
|
||||
for key, value in image.info.items():
|
||||
info_text += f"{key}: {value}\n"
|
||||
info_text = info_text.rstrip('\n')
|
||||
info_text = info_text.rstrip("\n")
|
||||
return gr.Textbox.update(value=info_text, visible=visible)
|
||||
|
||||
|
||||
def load_settings(*values):
|
||||
new_settings, key_names, checkboxgroup_info = values[-3:]
|
||||
values = list(values[:-3])
|
||||
@ -205,7 +273,9 @@ def load_settings(*values):
|
||||
if os.path.exists(new_settings):
|
||||
with open(new_settings, "r", encoding="utf8") as f:
|
||||
new_settings = yaml.safe_load(f)
|
||||
elif new_settings.startswith("file://") and os.path.exists(new_settings[7:]):
|
||||
elif new_settings.startswith("file://") and os.path.exists(
|
||||
new_settings[7:]
|
||||
):
|
||||
with open(new_settings[7:], "r", encoding="utf8") as f:
|
||||
new_settings = yaml.safe_load(f)
|
||||
else:
|
||||
@ -216,7 +286,10 @@ def load_settings(*values):
|
||||
new_settings = new_settings["txt2img"]
|
||||
target = new_settings.pop("target", "txt2img")
|
||||
if target != "txt2img":
|
||||
print(f"Warning: applying settings to txt2img even though {target} is specified as target.", file=sys.stderr)
|
||||
print(
|
||||
f"Warning: applying settings to txt2img even though {target} is specified as target.",
|
||||
file=sys.stderr,
|
||||
)
|
||||
|
||||
skipped_settings = {}
|
||||
for key in new_settings.keys():
|
||||
@ -228,7 +301,7 @@ def load_settings(*values):
|
||||
print(f"Settings could not be applied: {skipped_settings}", file=sys.stderr)
|
||||
|
||||
# Convert lists of checkbox indices to lists of checkbox labels:
|
||||
for (cbg_index, cbg_choices) in checkboxgroup_info:
|
||||
for cbg_index, cbg_choices in checkboxgroup_info:
|
||||
values[cbg_index] = [cbg_choices[i] for i in values[cbg_index]]
|
||||
|
||||
return values
|
||||
|
||||
@ -13,7 +13,7 @@
|
||||
:: GNU Affero General Public License for more details.
|
||||
|
||||
:: You should have received a copy of the GNU Affero General Public License
|
||||
:: along with this program. If not, see <http://www.gnu.org/licenses/>.
|
||||
:: along with this program. If not, see <http://www.gnu.org/licenses/>.
|
||||
:: Run all commands using this script's directory as the working directory
|
||||
cd %~dp0
|
||||
|
||||
|
||||
@ -13,7 +13,7 @@
|
||||
# GNU Affero General Public License for more details.
|
||||
|
||||
# You should have received a copy of the GNU Affero General Public License
|
||||
# along with this program. If not, see <http://www.gnu.org/licenses/>.
|
||||
# along with this program. If not, see <http://www.gnu.org/licenses/>.
|
||||
# Start the Stable Diffusion WebUI for Linux Users
|
||||
|
||||
DIRECTORY="."
|
||||
@ -33,9 +33,9 @@ REALESRGAN_ANIME_MODEL="https://github.com/xinntao/Real-ESRGAN/releases/download
|
||||
SD_CONCEPT_REPO="https://github.com/Sygil-Dev/sd-concepts-library/archive/refs/heads/main.zip"
|
||||
|
||||
|
||||
if [[ -f $ENV_MODIFED_FILE ]]; then
|
||||
if [[ -f $ENV_MODIFED_FILE ]]; then
|
||||
ENV_MODIFIED_CACHED=$(<${ENV_MODIFED_FILE})
|
||||
else
|
||||
else
|
||||
ENV_MODIFIED_CACHED=0
|
||||
fi
|
||||
|
||||
@ -93,7 +93,7 @@ sd_model_loading () {
|
||||
printf "\n\n########## MOVE MODEL FILE ##########\n\n"
|
||||
printf "Please download the 1.4 AI Model from Huggingface (or another source) and place it inside of the sygil-webui folder\n\n"
|
||||
read -p "Once you have sd-v1-4.ckpt in the project root, Press Enter...\n\n"
|
||||
|
||||
|
||||
# Check to make sure checksum of models is the original one from HuggingFace and not a fake model set
|
||||
printf "fe4efff1e174c627256e44ec2991ba279b3816e364b49f9be2abc0b3ff3f8556 sd-v1-4.ckpt" | sha256sum --check || exit 1
|
||||
mv sd-v1-4.ckpt $DIRECTORY/models/ldm/stable-diffusion-v1/model.ckpt
|
||||
@ -166,4 +166,4 @@ start_initialization () {
|
||||
|
||||
}
|
||||
|
||||
start_initialization "$@"
|
||||
start_initialization "$@"
|
||||
|
||||
{kind=link}
|
Before Width: | Height: | Size: 6.3 KiB After Width: | Height: | Size: 6.3 KiB |
@ -3,7 +3,11 @@ from torch.utils.data import DataLoader
|
||||
from torchvision import transforms
|
||||
from torchvision.transforms.functional import InterpolationMode
|
||||
|
||||
from data.coco_karpathy_dataset import coco_karpathy_train, coco_karpathy_caption_eval, coco_karpathy_retrieval_eval
|
||||
from data.coco_karpathy_dataset import (
|
||||
coco_karpathy_train,
|
||||
coco_karpathy_caption_eval,
|
||||
coco_karpathy_retrieval_eval,
|
||||
)
|
||||
from data.nocaps_dataset import nocaps_eval
|
||||
from data.flickr30k_dataset import flickr30k_train, flickr30k_retrieval_eval
|
||||
from data.vqa_dataset import vqa_dataset
|
||||
@ -11,77 +15,154 @@ from data.nlvr_dataset import nlvr_dataset
|
||||
from data.pretrain_dataset import pretrain_dataset
|
||||
from transform.randaugment import RandomAugment
|
||||
|
||||
def create_dataset(dataset, config, min_scale=0.5):
|
||||
|
||||
normalize = transforms.Normalize((0.48145466, 0.4578275, 0.40821073), (0.26862954, 0.26130258, 0.27577711))
|
||||
|
||||
transform_train = transforms.Compose([
|
||||
transforms.RandomResizedCrop(config['image_size'],scale=(min_scale, 1.0),interpolation=InterpolationMode.BICUBIC),
|
||||
def create_dataset(dataset, config, min_scale=0.5):
|
||||
normalize = transforms.Normalize(
|
||||
(0.48145466, 0.4578275, 0.40821073), (0.26862954, 0.26130258, 0.27577711)
|
||||
)
|
||||
|
||||
transform_train = transforms.Compose(
|
||||
[
|
||||
transforms.RandomResizedCrop(
|
||||
config["image_size"],
|
||||
scale=(min_scale, 1.0),
|
||||
interpolation=InterpolationMode.BICUBIC,
|
||||
),
|
||||
transforms.RandomHorizontalFlip(),
|
||||
RandomAugment(2,5,isPIL=True,augs=['Identity','AutoContrast','Brightness','Sharpness','Equalize',
|
||||
'ShearX', 'ShearY', 'TranslateX', 'TranslateY', 'Rotate']),
|
||||
RandomAugment(
|
||||
2,
|
||||
5,
|
||||
isPIL=True,
|
||||
augs=[
|
||||
"Identity",
|
||||
"AutoContrast",
|
||||
"Brightness",
|
||||
"Sharpness",
|
||||
"Equalize",
|
||||
"ShearX",
|
||||
"ShearY",
|
||||
"TranslateX",
|
||||
"TranslateY",
|
||||
"Rotate",
|
||||
],
|
||||
),
|
||||
transforms.ToTensor(),
|
||||
normalize,
|
||||
])
|
||||
transform_test = transforms.Compose([
|
||||
transforms.Resize((config['image_size'],config['image_size']),interpolation=InterpolationMode.BICUBIC),
|
||||
transforms.ToTensor(),
|
||||
normalize,
|
||||
])
|
||||
|
||||
if dataset=='pretrain':
|
||||
dataset = pretrain_dataset(config['train_file'], config['laion_path'], transform_train)
|
||||
return dataset
|
||||
|
||||
elif dataset=='caption_coco':
|
||||
train_dataset = coco_karpathy_train(transform_train, config['image_root'], config['ann_root'], prompt=config['prompt'])
|
||||
val_dataset = coco_karpathy_caption_eval(transform_test, config['image_root'], config['ann_root'], 'val')
|
||||
test_dataset = coco_karpathy_caption_eval(transform_test, config['image_root'], config['ann_root'], 'test')
|
||||
]
|
||||
)
|
||||
transform_test = transforms.Compose(
|
||||
[
|
||||
transforms.Resize(
|
||||
(config["image_size"], config["image_size"]),
|
||||
interpolation=InterpolationMode.BICUBIC,
|
||||
),
|
||||
transforms.ToTensor(),
|
||||
normalize,
|
||||
]
|
||||
)
|
||||
|
||||
if dataset == "pretrain":
|
||||
dataset = pretrain_dataset(
|
||||
config["train_file"], config["laion_path"], transform_train
|
||||
)
|
||||
return dataset
|
||||
|
||||
elif dataset == "caption_coco":
|
||||
train_dataset = coco_karpathy_train(
|
||||
transform_train,
|
||||
config["image_root"],
|
||||
config["ann_root"],
|
||||
prompt=config["prompt"],
|
||||
)
|
||||
val_dataset = coco_karpathy_caption_eval(
|
||||
transform_test, config["image_root"], config["ann_root"], "val"
|
||||
)
|
||||
test_dataset = coco_karpathy_caption_eval(
|
||||
transform_test, config["image_root"], config["ann_root"], "test"
|
||||
)
|
||||
return train_dataset, val_dataset, test_dataset
|
||||
|
||||
elif dataset=='nocaps':
|
||||
val_dataset = nocaps_eval(transform_test, config['image_root'], config['ann_root'], 'val')
|
||||
test_dataset = nocaps_eval(transform_test, config['image_root'], config['ann_root'], 'test')
|
||||
return val_dataset, test_dataset
|
||||
|
||||
elif dataset=='retrieval_coco':
|
||||
train_dataset = coco_karpathy_train(transform_train, config['image_root'], config['ann_root'])
|
||||
val_dataset = coco_karpathy_retrieval_eval(transform_test, config['image_root'], config['ann_root'], 'val')
|
||||
test_dataset = coco_karpathy_retrieval_eval(transform_test, config['image_root'], config['ann_root'], 'test')
|
||||
return train_dataset, val_dataset, test_dataset
|
||||
|
||||
elif dataset=='retrieval_flickr':
|
||||
train_dataset = flickr30k_train(transform_train, config['image_root'], config['ann_root'])
|
||||
val_dataset = flickr30k_retrieval_eval(transform_test, config['image_root'], config['ann_root'], 'val')
|
||||
test_dataset = flickr30k_retrieval_eval(transform_test, config['image_root'], config['ann_root'], 'test')
|
||||
return train_dataset, val_dataset, test_dataset
|
||||
|
||||
elif dataset=='vqa':
|
||||
train_dataset = vqa_dataset(transform_train, config['ann_root'], config['vqa_root'], config['vg_root'],
|
||||
train_files = config['train_files'], split='train')
|
||||
test_dataset = vqa_dataset(transform_test, config['ann_root'], config['vqa_root'], config['vg_root'], split='test')
|
||||
|
||||
elif dataset == "nocaps":
|
||||
val_dataset = nocaps_eval(
|
||||
transform_test, config["image_root"], config["ann_root"], "val"
|
||||
)
|
||||
test_dataset = nocaps_eval(
|
||||
transform_test, config["image_root"], config["ann_root"], "test"
|
||||
)
|
||||
return val_dataset, test_dataset
|
||||
|
||||
elif dataset == "retrieval_coco":
|
||||
train_dataset = coco_karpathy_train(
|
||||
transform_train, config["image_root"], config["ann_root"]
|
||||
)
|
||||
val_dataset = coco_karpathy_retrieval_eval(
|
||||
transform_test, config["image_root"], config["ann_root"], "val"
|
||||
)
|
||||
test_dataset = coco_karpathy_retrieval_eval(
|
||||
transform_test, config["image_root"], config["ann_root"], "test"
|
||||
)
|
||||
return train_dataset, val_dataset, test_dataset
|
||||
|
||||
elif dataset == "retrieval_flickr":
|
||||
train_dataset = flickr30k_train(
|
||||
transform_train, config["image_root"], config["ann_root"]
|
||||
)
|
||||
val_dataset = flickr30k_retrieval_eval(
|
||||
transform_test, config["image_root"], config["ann_root"], "val"
|
||||
)
|
||||
test_dataset = flickr30k_retrieval_eval(
|
||||
transform_test, config["image_root"], config["ann_root"], "test"
|
||||
)
|
||||
return train_dataset, val_dataset, test_dataset
|
||||
|
||||
elif dataset == "vqa":
|
||||
train_dataset = vqa_dataset(
|
||||
transform_train,
|
||||
config["ann_root"],
|
||||
config["vqa_root"],
|
||||
config["vg_root"],
|
||||
train_files=config["train_files"],
|
||||
split="train",
|
||||
)
|
||||
test_dataset = vqa_dataset(
|
||||
transform_test,
|
||||
config["ann_root"],
|
||||
config["vqa_root"],
|
||||
config["vg_root"],
|
||||
split="test",
|
||||
)
|
||||
return train_dataset, test_dataset
|
||||
|
||||
elif dataset=='nlvr':
|
||||
train_dataset = nlvr_dataset(transform_train, config['image_root'], config['ann_root'],'train')
|
||||
val_dataset = nlvr_dataset(transform_test, config['image_root'], config['ann_root'],'val')
|
||||
test_dataset = nlvr_dataset(transform_test, config['image_root'], config['ann_root'],'test')
|
||||
return train_dataset, val_dataset, test_dataset
|
||||
|
||||
|
||||
|
||||
elif dataset == "nlvr":
|
||||
train_dataset = nlvr_dataset(
|
||||
transform_train, config["image_root"], config["ann_root"], "train"
|
||||
)
|
||||
val_dataset = nlvr_dataset(
|
||||
transform_test, config["image_root"], config["ann_root"], "val"
|
||||
)
|
||||
test_dataset = nlvr_dataset(
|
||||
transform_test, config["image_root"], config["ann_root"], "test"
|
||||
)
|
||||
return train_dataset, val_dataset, test_dataset
|
||||
|
||||
|
||||
def create_sampler(datasets, shuffles, num_tasks, global_rank):
|
||||
samplers = []
|
||||
for dataset,shuffle in zip(datasets,shuffles):
|
||||
sampler = torch.utils.data.DistributedSampler(dataset, num_replicas=num_tasks, rank=global_rank, shuffle=shuffle)
|
||||
for dataset, shuffle in zip(datasets, shuffles):
|
||||
sampler = torch.utils.data.DistributedSampler(
|
||||
dataset, num_replicas=num_tasks, rank=global_rank, shuffle=shuffle
|
||||
)
|
||||
samplers.append(sampler)
|
||||
return samplers
|
||||
return samplers
|
||||
|
||||
|
||||
def create_loader(datasets, samplers, batch_size, num_workers, is_trains, collate_fns):
|
||||
loaders = []
|
||||
for dataset,sampler,bs,n_worker,is_train,collate_fn in zip(datasets,samplers,batch_size,num_workers,is_trains,collate_fns):
|
||||
for dataset, sampler, bs, n_worker, is_train, collate_fn in zip(
|
||||
datasets, samplers, batch_size, num_workers, is_trains, collate_fns
|
||||
):
|
||||
if is_train:
|
||||
shuffle = (sampler is None)
|
||||
shuffle = sampler is None
|
||||
drop_last = True
|
||||
else:
|
||||
shuffle = False
|
||||
@ -95,7 +176,6 @@ def create_loader(datasets, samplers, batch_size, num_workers, is_trains, collat
|
||||
shuffle=shuffle,
|
||||
collate_fn=collate_fn,
|
||||
drop_last=drop_last,
|
||||
)
|
||||
)
|
||||
loaders.append(loader)
|
||||
return loaders
|
||||
|
||||
return loaders
|
||||
|
||||
@ -1,11 +1,12 @@
|
||||
from abc import abstractmethod
|
||||
from torch.utils.data import Dataset, ConcatDataset, ChainDataset, IterableDataset
|
||||
from torch.utils.data import IterableDataset
|
||||
|
||||
|
||||
class Txt2ImgIterableBaseDataset(IterableDataset):
|
||||
'''
|
||||
"""
|
||||
Define an interface to make the IterableDatasets for text2img data chainable
|
||||
'''
|
||||
"""
|
||||
|
||||
def __init__(self, num_records=0, valid_ids=None, size=256):
|
||||
super().__init__()
|
||||
self.num_records = num_records
|
||||
@ -13,11 +14,11 @@ class Txt2ImgIterableBaseDataset(IterableDataset):
|
||||
self.sample_ids = valid_ids
|
||||
self.size = size
|
||||
|
||||
print(f'{self.__class__.__name__} dataset contains {self.__len__()} examples.')
|
||||
print(f"{self.__class__.__name__} dataset contains {self.__len__()} examples.")
|
||||
|
||||
def __len__(self):
|
||||
return self.num_records
|
||||
|
||||
@abstractmethod
|
||||
def __iter__(self):
|
||||
pass
|
||||
pass
|
||||
|
||||
@ -8,119 +8,121 @@ from PIL import Image
|
||||
|
||||
from data.utils import pre_caption
|
||||
|
||||
|
||||
class coco_karpathy_train(Dataset):
|
||||
def __init__(self, transform, image_root, ann_root, max_words=30, prompt=''):
|
||||
'''
|
||||
def __init__(self, transform, image_root, ann_root, max_words=30, prompt=""):
|
||||
"""
|
||||
image_root (string): Root directory of images (e.g. coco/images/)
|
||||
ann_root (string): directory to store the annotation file
|
||||
'''
|
||||
url = 'https://storage.googleapis.com/sfr-vision-language-research/datasets/coco_karpathy_train.json'
|
||||
filename = 'coco_karpathy_train.json'
|
||||
"""
|
||||
url = "https://storage.googleapis.com/sfr-vision-language-research/datasets/coco_karpathy_train.json"
|
||||
filename = "coco_karpathy_train.json"
|
||||
|
||||
download_url(url,ann_root)
|
||||
|
||||
self.annotation = json.load(open(os.path.join(ann_root,filename),'r'))
|
||||
download_url(url, ann_root)
|
||||
|
||||
self.annotation = json.load(open(os.path.join(ann_root, filename), "r"))
|
||||
self.transform = transform
|
||||
self.image_root = image_root
|
||||
self.max_words = max_words
|
||||
self.max_words = max_words
|
||||
self.prompt = prompt
|
||||
|
||||
self.img_ids = {}
|
||||
|
||||
self.img_ids = {}
|
||||
n = 0
|
||||
for ann in self.annotation:
|
||||
img_id = ann['image_id']
|
||||
img_id = ann["image_id"]
|
||||
if img_id not in self.img_ids.keys():
|
||||
self.img_ids[img_id] = n
|
||||
n += 1
|
||||
|
||||
def __len__(self):
|
||||
return len(self.annotation)
|
||||
|
||||
def __getitem__(self, index):
|
||||
|
||||
ann = self.annotation[index]
|
||||
|
||||
image_path = os.path.join(self.image_root,ann['image'])
|
||||
image = Image.open(image_path).convert('RGB')
|
||||
image = self.transform(image)
|
||||
|
||||
caption = self.prompt+pre_caption(ann['caption'], self.max_words)
|
||||
n += 1
|
||||
|
||||
return image, caption, self.img_ids[ann['image_id']]
|
||||
|
||||
|
||||
class coco_karpathy_caption_eval(Dataset):
|
||||
def __init__(self, transform, image_root, ann_root, split):
|
||||
'''
|
||||
image_root (string): Root directory of images (e.g. coco/images/)
|
||||
ann_root (string): directory to store the annotation file
|
||||
split (string): val or test
|
||||
'''
|
||||
urls = {'val':'https://storage.googleapis.com/sfr-vision-language-research/datasets/coco_karpathy_val.json',
|
||||
'test':'https://storage.googleapis.com/sfr-vision-language-research/datasets/coco_karpathy_test.json'}
|
||||
filenames = {'val':'coco_karpathy_val.json','test':'coco_karpathy_test.json'}
|
||||
|
||||
download_url(urls[split],ann_root)
|
||||
|
||||
self.annotation = json.load(open(os.path.join(ann_root,filenames[split]),'r'))
|
||||
self.transform = transform
|
||||
self.image_root = image_root
|
||||
|
||||
def __len__(self):
|
||||
return len(self.annotation)
|
||||
|
||||
def __getitem__(self, index):
|
||||
|
||||
|
||||
def __getitem__(self, index):
|
||||
ann = self.annotation[index]
|
||||
|
||||
image_path = os.path.join(self.image_root,ann['image'])
|
||||
image = Image.open(image_path).convert('RGB')
|
||||
image = self.transform(image)
|
||||
|
||||
img_id = ann['image'].split('/')[-1].strip('.jpg').split('_')[-1]
|
||||
|
||||
return image, int(img_id)
|
||||
|
||||
|
||||
class coco_karpathy_retrieval_eval(Dataset):
|
||||
def __init__(self, transform, image_root, ann_root, split, max_words=30):
|
||||
'''
|
||||
|
||||
image_path = os.path.join(self.image_root, ann["image"])
|
||||
image = Image.open(image_path).convert("RGB")
|
||||
image = self.transform(image)
|
||||
|
||||
caption = self.prompt + pre_caption(ann["caption"], self.max_words)
|
||||
|
||||
return image, caption, self.img_ids[ann["image_id"]]
|
||||
|
||||
|
||||
class coco_karpathy_caption_eval(Dataset):
|
||||
def __init__(self, transform, image_root, ann_root, split):
|
||||
"""
|
||||
image_root (string): Root directory of images (e.g. coco/images/)
|
||||
ann_root (string): directory to store the annotation file
|
||||
split (string): val or test
|
||||
'''
|
||||
urls = {'val':'https://storage.googleapis.com/sfr-vision-language-research/datasets/coco_karpathy_val.json',
|
||||
'test':'https://storage.googleapis.com/sfr-vision-language-research/datasets/coco_karpathy_test.json'}
|
||||
filenames = {'val':'coco_karpathy_val.json','test':'coco_karpathy_test.json'}
|
||||
|
||||
download_url(urls[split],ann_root)
|
||||
|
||||
self.annotation = json.load(open(os.path.join(ann_root,filenames[split]),'r'))
|
||||
"""
|
||||
urls = {
|
||||
"val": "https://storage.googleapis.com/sfr-vision-language-research/datasets/coco_karpathy_val.json",
|
||||
"test": "https://storage.googleapis.com/sfr-vision-language-research/datasets/coco_karpathy_test.json",
|
||||
}
|
||||
filenames = {"val": "coco_karpathy_val.json", "test": "coco_karpathy_test.json"}
|
||||
|
||||
download_url(urls[split], ann_root)
|
||||
|
||||
self.annotation = json.load(open(os.path.join(ann_root, filenames[split]), "r"))
|
||||
self.transform = transform
|
||||
self.image_root = image_root
|
||||
|
||||
|
||||
def __len__(self):
|
||||
return len(self.annotation)
|
||||
|
||||
def __getitem__(self, index):
|
||||
ann = self.annotation[index]
|
||||
|
||||
image_path = os.path.join(self.image_root, ann["image"])
|
||||
image = Image.open(image_path).convert("RGB")
|
||||
image = self.transform(image)
|
||||
|
||||
img_id = ann["image"].split("/")[-1].strip(".jpg").split("_")[-1]
|
||||
|
||||
return image, int(img_id)
|
||||
|
||||
|
||||
class coco_karpathy_retrieval_eval(Dataset):
|
||||
def __init__(self, transform, image_root, ann_root, split, max_words=30):
|
||||
"""
|
||||
image_root (string): Root directory of images (e.g. coco/images/)
|
||||
ann_root (string): directory to store the annotation file
|
||||
split (string): val or test
|
||||
"""
|
||||
urls = {
|
||||
"val": "https://storage.googleapis.com/sfr-vision-language-research/datasets/coco_karpathy_val.json",
|
||||
"test": "https://storage.googleapis.com/sfr-vision-language-research/datasets/coco_karpathy_test.json",
|
||||
}
|
||||
filenames = {"val": "coco_karpathy_val.json", "test": "coco_karpathy_test.json"}
|
||||
|
||||
download_url(urls[split], ann_root)
|
||||
|
||||
self.annotation = json.load(open(os.path.join(ann_root, filenames[split]), "r"))
|
||||
self.transform = transform
|
||||
self.image_root = image_root
|
||||
|
||||
self.text = []
|
||||
self.image = []
|
||||
self.txt2img = {}
|
||||
self.img2txt = {}
|
||||
|
||||
|
||||
txt_id = 0
|
||||
for img_id, ann in enumerate(self.annotation):
|
||||
self.image.append(ann['image'])
|
||||
self.image.append(ann["image"])
|
||||
self.img2txt[img_id] = []
|
||||
for i, caption in enumerate(ann['caption']):
|
||||
self.text.append(pre_caption(caption,max_words))
|
||||
for i, caption in enumerate(ann["caption"]):
|
||||
self.text.append(pre_caption(caption, max_words))
|
||||
self.img2txt[img_id].append(txt_id)
|
||||
self.txt2img[txt_id] = img_id
|
||||
txt_id += 1
|
||||
|
||||
|
||||
def __len__(self):
|
||||
return len(self.annotation)
|
||||
|
||||
def __getitem__(self, index):
|
||||
|
||||
image_path = os.path.join(self.image_root, self.annotation[index]['image'])
|
||||
image = Image.open(image_path).convert('RGB')
|
||||
image = self.transform(image)
|
||||
|
||||
return image, index
|
||||
def __getitem__(self, index):
|
||||
image_path = os.path.join(self.image_root, self.annotation[index]["image"])
|
||||
image = Image.open(image_path).convert("RGB")
|
||||
image = self.transform(image)
|
||||
|
||||
return image, index
|
||||
|
||||
@ -8,86 +8,87 @@ from PIL import Image
|
||||
|
||||
from data.utils import pre_caption
|
||||
|
||||
|
||||
class flickr30k_train(Dataset):
|
||||
def __init__(self, transform, image_root, ann_root, max_words=30, prompt=''):
|
||||
'''
|
||||
def __init__(self, transform, image_root, ann_root, max_words=30, prompt=""):
|
||||
"""
|
||||
image_root (string): Root directory of images (e.g. flickr30k/)
|
||||
ann_root (string): directory to store the annotation file
|
||||
'''
|
||||
url = 'https://storage.googleapis.com/sfr-vision-language-research/datasets/flickr30k_train.json'
|
||||
filename = 'flickr30k_train.json'
|
||||
"""
|
||||
url = "https://storage.googleapis.com/sfr-vision-language-research/datasets/flickr30k_train.json"
|
||||
filename = "flickr30k_train.json"
|
||||
|
||||
download_url(url,ann_root)
|
||||
|
||||
self.annotation = json.load(open(os.path.join(ann_root,filename),'r'))
|
||||
download_url(url, ann_root)
|
||||
|
||||
self.annotation = json.load(open(os.path.join(ann_root, filename), "r"))
|
||||
self.transform = transform
|
||||
self.image_root = image_root
|
||||
self.max_words = max_words
|
||||
self.max_words = max_words
|
||||
self.prompt = prompt
|
||||
|
||||
self.img_ids = {}
|
||||
|
||||
self.img_ids = {}
|
||||
n = 0
|
||||
for ann in self.annotation:
|
||||
img_id = ann['image_id']
|
||||
img_id = ann["image_id"]
|
||||
if img_id not in self.img_ids.keys():
|
||||
self.img_ids[img_id] = n
|
||||
n += 1
|
||||
|
||||
n += 1
|
||||
|
||||
def __len__(self):
|
||||
return len(self.annotation)
|
||||
|
||||
def __getitem__(self, index):
|
||||
|
||||
ann = self.annotation[index]
|
||||
|
||||
image_path = os.path.join(self.image_root,ann['image'])
|
||||
image = Image.open(image_path).convert('RGB')
|
||||
image = self.transform(image)
|
||||
|
||||
caption = self.prompt+pre_caption(ann['caption'], self.max_words)
|
||||
|
||||
return image, caption, self.img_ids[ann['image_id']]
|
||||
|
||||
|
||||
def __getitem__(self, index):
|
||||
ann = self.annotation[index]
|
||||
|
||||
image_path = os.path.join(self.image_root, ann["image"])
|
||||
image = Image.open(image_path).convert("RGB")
|
||||
image = self.transform(image)
|
||||
|
||||
caption = self.prompt + pre_caption(ann["caption"], self.max_words)
|
||||
|
||||
return image, caption, self.img_ids[ann["image_id"]]
|
||||
|
||||
|
||||
class flickr30k_retrieval_eval(Dataset):
|
||||
def __init__(self, transform, image_root, ann_root, split, max_words=30):
|
||||
'''
|
||||
def __init__(self, transform, image_root, ann_root, split, max_words=30):
|
||||
"""
|
||||
image_root (string): Root directory of images (e.g. flickr30k/)
|
||||
ann_root (string): directory to store the annotation file
|
||||
split (string): val or test
|
||||
'''
|
||||
urls = {'val':'https://storage.googleapis.com/sfr-vision-language-research/datasets/flickr30k_val.json',
|
||||
'test':'https://storage.googleapis.com/sfr-vision-language-research/datasets/flickr30k_test.json'}
|
||||
filenames = {'val':'flickr30k_val.json','test':'flickr30k_test.json'}
|
||||
|
||||
download_url(urls[split],ann_root)
|
||||
|
||||
self.annotation = json.load(open(os.path.join(ann_root,filenames[split]),'r'))
|
||||
"""
|
||||
urls = {
|
||||
"val": "https://storage.googleapis.com/sfr-vision-language-research/datasets/flickr30k_val.json",
|
||||
"test": "https://storage.googleapis.com/sfr-vision-language-research/datasets/flickr30k_test.json",
|
||||
}
|
||||
filenames = {"val": "flickr30k_val.json", "test": "flickr30k_test.json"}
|
||||
|
||||
download_url(urls[split], ann_root)
|
||||
|
||||
self.annotation = json.load(open(os.path.join(ann_root, filenames[split]), "r"))
|
||||
self.transform = transform
|
||||
self.image_root = image_root
|
||||
|
||||
|
||||
self.text = []
|
||||
self.image = []
|
||||
self.txt2img = {}
|
||||
self.img2txt = {}
|
||||
|
||||
|
||||
txt_id = 0
|
||||
for img_id, ann in enumerate(self.annotation):
|
||||
self.image.append(ann['image'])
|
||||
self.image.append(ann["image"])
|
||||
self.img2txt[img_id] = []
|
||||
for i, caption in enumerate(ann['caption']):
|
||||
self.text.append(pre_caption(caption,max_words))
|
||||
for i, caption in enumerate(ann["caption"]):
|
||||
self.text.append(pre_caption(caption, max_words))
|
||||
self.img2txt[img_id].append(txt_id)
|
||||
self.txt2img[txt_id] = img_id
|
||||
txt_id += 1
|
||||
|
||||
|
||||
def __len__(self):
|
||||
return len(self.annotation)
|
||||
|
||||
def __getitem__(self, index):
|
||||
|
||||
image_path = os.path.join(self.image_root, self.annotation[index]['image'])
|
||||
image = Image.open(image_path).convert('RGB')
|
||||
image = self.transform(image)
|
||||
|
||||
return image, index
|
||||
def __getitem__(self, index):
|
||||
image_path = os.path.join(self.image_root, self.annotation[index]["image"])
|
||||
image = Image.open(image_path).convert("RGB")
|
||||
image = self.transform(image)
|
||||
|
||||
return image, index
|
||||
|
||||
@ -11,7 +11,12 @@ from tqdm import tqdm
|
||||
from torch.utils.data import Dataset, Subset
|
||||
|
||||
import taming.data.utils as tdu
|
||||
from taming.data.imagenet import str_to_indices, give_synsets_from_indices, download, retrieve
|
||||
from taming.data.imagenet import (
|
||||
str_to_indices,
|
||||
give_synsets_from_indices,
|
||||
download,
|
||||
retrieve,
|
||||
)
|
||||
from taming.data.imagenet import ImagePaths
|
||||
|
||||
from ldm.modules.image_degradation import degradation_fn_bsr, degradation_fn_bsr_light
|
||||
@ -20,13 +25,13 @@ from ldm.modules.image_degradation import degradation_fn_bsr, degradation_fn_bsr
|
||||
def synset2idx(path_to_yaml="data/index_synset.yaml"):
|
||||
with open(path_to_yaml) as f:
|
||||
di2s = yaml.load(f)
|
||||
return dict((v,k) for k,v in di2s.items())
|
||||
return dict((v, k) for k, v in di2s.items())
|
||||
|
||||
|
||||
class ImageNetBase(Dataset):
|
||||
def __init__(self, config=None):
|
||||
self.config = config or OmegaConf.create()
|
||||
if not type(self.config)==dict:
|
||||
if not type(self.config) == dict:
|
||||
self.config = OmegaConf.to_container(self.config)
|
||||
self.keep_orig_class_label = self.config.get("keep_orig_class_label", False)
|
||||
self.process_images = True # if False we skip loading & processing images and self.data contains filepaths
|
||||
@ -46,13 +51,17 @@ class ImageNetBase(Dataset):
|
||||
raise NotImplementedError()
|
||||
|
||||
def _filter_relpaths(self, relpaths):
|
||||
ignore = set([
|
||||
"n06596364_9591.JPEG",
|
||||
])
|
||||
relpaths = [rpath for rpath in relpaths if not rpath.split("/")[-1] in ignore]
|
||||
ignore = set(
|
||||
[
|
||||
"n06596364_9591.JPEG",
|
||||
]
|
||||
)
|
||||
relpaths = [rpath for rpath in relpaths if rpath.split("/")[-1] not in ignore]
|
||||
if "sub_indices" in self.config:
|
||||
indices = str_to_indices(self.config["sub_indices"])
|
||||
synsets = give_synsets_from_indices(indices, path_to_yaml=self.idx2syn) # returns a list of strings
|
||||
synsets = give_synsets_from_indices(
|
||||
indices, path_to_yaml=self.idx2syn
|
||||
) # returns a list of strings
|
||||
self.synset2idx = synset2idx(path_to_yaml=self.idx2syn)
|
||||
files = []
|
||||
for rpath in relpaths:
|
||||
@ -67,20 +76,24 @@ class ImageNetBase(Dataset):
|
||||
SIZE = 2655750
|
||||
URL = "https://heibox.uni-heidelberg.de/f/9f28e956cd304264bb82/?dl=1"
|
||||
self.human_dict = os.path.join(self.root, "synset_human.txt")
|
||||
if (not os.path.exists(self.human_dict) or
|
||||
not os.path.getsize(self.human_dict)==SIZE):
|
||||
if (
|
||||
not os.path.exists(self.human_dict)
|
||||
or not os.path.getsize(self.human_dict) == SIZE
|
||||
):
|
||||
download(URL, self.human_dict)
|
||||
|
||||
def _prepare_idx_to_synset(self):
|
||||
URL = "https://heibox.uni-heidelberg.de/f/d835d5b6ceda4d3aa910/?dl=1"
|
||||
self.idx2syn = os.path.join(self.root, "index_synset.yaml")
|
||||
if (not os.path.exists(self.idx2syn)):
|
||||
if not os.path.exists(self.idx2syn):
|
||||
download(URL, self.idx2syn)
|
||||
|
||||
def _prepare_human_to_integer_label(self):
|
||||
URL = "https://heibox.uni-heidelberg.de/f/2362b797d5be43b883f6/?dl=1"
|
||||
self.human2integer = os.path.join(self.root, "imagenet1000_clsidx_to_labels.txt")
|
||||
if (not os.path.exists(self.human2integer)):
|
||||
self.human2integer = os.path.join(
|
||||
self.root, "imagenet1000_clsidx_to_labels.txt"
|
||||
)
|
||||
if not os.path.exists(self.human2integer):
|
||||
download(URL, self.human2integer)
|
||||
with open(self.human2integer, "r") as f:
|
||||
lines = f.read().splitlines()
|
||||
@ -95,7 +108,11 @@ class ImageNetBase(Dataset):
|
||||
self.relpaths = f.read().splitlines()
|
||||
l1 = len(self.relpaths)
|
||||
self.relpaths = self._filter_relpaths(self.relpaths)
|
||||
print("Removed {} files from filelist during filtering.".format(l1 - len(self.relpaths)))
|
||||
print(
|
||||
"Removed {} files from filelist during filtering.".format(
|
||||
l1 - len(self.relpaths)
|
||||
)
|
||||
)
|
||||
|
||||
self.synsets = [p.split("/")[0] for p in self.relpaths]
|
||||
self.abspaths = [os.path.join(self.datadir, p) for p in self.relpaths]
|
||||
@ -122,11 +139,12 @@ class ImageNetBase(Dataset):
|
||||
|
||||
if self.process_images:
|
||||
self.size = retrieve(self.config, "size", default=256)
|
||||
self.data = ImagePaths(self.abspaths,
|
||||
labels=labels,
|
||||
size=self.size,
|
||||
random_crop=self.random_crop,
|
||||
)
|
||||
self.data = ImagePaths(
|
||||
self.abspaths,
|
||||
labels=labels,
|
||||
size=self.size,
|
||||
random_crop=self.random_crop,
|
||||
)
|
||||
else:
|
||||
self.data = self.abspaths
|
||||
|
||||
@ -157,8 +175,9 @@ class ImageNetTrain(ImageNetBase):
|
||||
self.datadir = os.path.join(self.root, "data")
|
||||
self.txt_filelist = os.path.join(self.root, "filelist.txt")
|
||||
self.expected_length = 1281167
|
||||
self.random_crop = retrieve(self.config, "ImageNetTrain/random_crop",
|
||||
default=True)
|
||||
self.random_crop = retrieve(
|
||||
self.config, "ImageNetTrain/random_crop", default=True
|
||||
)
|
||||
if not tdu.is_prepared(self.root):
|
||||
# prep
|
||||
print("Preparing dataset {} in {}".format(self.NAME, self.root))
|
||||
@ -166,8 +185,12 @@ class ImageNetTrain(ImageNetBase):
|
||||
datadir = self.datadir
|
||||
if not os.path.exists(datadir):
|
||||
path = os.path.join(self.root, self.FILES[0])
|
||||
if not os.path.exists(path) or not os.path.getsize(path)==self.SIZES[0]:
|
||||
if (
|
||||
not os.path.exists(path)
|
||||
or not os.path.getsize(path) == self.SIZES[0]
|
||||
):
|
||||
import academictorrents as at
|
||||
|
||||
atpath = at.get(self.AT_HASH, datastore=self.root)
|
||||
assert atpath == path
|
||||
|
||||
@ -179,7 +202,7 @@ class ImageNetTrain(ImageNetBase):
|
||||
print("Extracting sub-tars.")
|
||||
subpaths = sorted(glob.glob(os.path.join(datadir, "*.tar")))
|
||||
for subpath in tqdm(subpaths):
|
||||
subdir = subpath[:-len(".tar")]
|
||||
subdir = subpath[: -len(".tar")]
|
||||
os.makedirs(subdir, exist_ok=True)
|
||||
with tarfile.open(subpath, "r:") as tar:
|
||||
tar.extractall(path=subdir)
|
||||
@ -187,7 +210,7 @@ class ImageNetTrain(ImageNetBase):
|
||||
filelist = glob.glob(os.path.join(datadir, "**", "*.JPEG"))
|
||||
filelist = [os.path.relpath(p, start=datadir) for p in filelist]
|
||||
filelist = sorted(filelist)
|
||||
filelist = "\n".join(filelist)+"\n"
|
||||
filelist = "\n".join(filelist) + "\n"
|
||||
with open(self.txt_filelist, "w") as f:
|
||||
f.write(filelist)
|
||||
|
||||
@ -222,8 +245,9 @@ class ImageNetValidation(ImageNetBase):
|
||||
self.datadir = os.path.join(self.root, "data")
|
||||
self.txt_filelist = os.path.join(self.root, "filelist.txt")
|
||||
self.expected_length = 50000
|
||||
self.random_crop = retrieve(self.config, "ImageNetValidation/random_crop",
|
||||
default=False)
|
||||
self.random_crop = retrieve(
|
||||
self.config, "ImageNetValidation/random_crop", default=False
|
||||
)
|
||||
if not tdu.is_prepared(self.root):
|
||||
# prep
|
||||
print("Preparing dataset {} in {}".format(self.NAME, self.root))
|
||||
@ -231,8 +255,12 @@ class ImageNetValidation(ImageNetBase):
|
||||
datadir = self.datadir
|
||||
if not os.path.exists(datadir):
|
||||
path = os.path.join(self.root, self.FILES[0])
|
||||
if not os.path.exists(path) or not os.path.getsize(path)==self.SIZES[0]:
|
||||
if (
|
||||
not os.path.exists(path)
|
||||
or not os.path.getsize(path) == self.SIZES[0]
|
||||
):
|
||||
import academictorrents as at
|
||||
|
||||
atpath = at.get(self.AT_HASH, datastore=self.root)
|
||||
assert atpath == path
|
||||
|
||||
@ -242,7 +270,10 @@ class ImageNetValidation(ImageNetBase):
|
||||
tar.extractall(path=datadir)
|
||||
|
||||
vspath = os.path.join(self.root, self.FILES[1])
|
||||
if not os.path.exists(vspath) or not os.path.getsize(vspath)==self.SIZES[1]:
|
||||
if (
|
||||
not os.path.exists(vspath)
|
||||
or not os.path.getsize(vspath) == self.SIZES[1]
|
||||
):
|
||||
download(self.VS_URL, vspath)
|
||||
|
||||
with open(vspath, "r") as f:
|
||||
@ -261,18 +292,23 @@ class ImageNetValidation(ImageNetBase):
|
||||
filelist = glob.glob(os.path.join(datadir, "**", "*.JPEG"))
|
||||
filelist = [os.path.relpath(p, start=datadir) for p in filelist]
|
||||
filelist = sorted(filelist)
|
||||
filelist = "\n".join(filelist)+"\n"
|
||||
filelist = "\n".join(filelist) + "\n"
|
||||
with open(self.txt_filelist, "w") as f:
|
||||
f.write(filelist)
|
||||
|
||||
tdu.mark_prepared(self.root)
|
||||
|
||||
|
||||
|
||||
class ImageNetSR(Dataset):
|
||||
def __init__(self, size=None,
|
||||
degradation=None, downscale_f=4, min_crop_f=0.5, max_crop_f=1.,
|
||||
random_crop=True):
|
||||
def __init__(
|
||||
self,
|
||||
size=None,
|
||||
degradation=None,
|
||||
downscale_f=4,
|
||||
min_crop_f=0.5,
|
||||
max_crop_f=1.0,
|
||||
random_crop=True,
|
||||
):
|
||||
"""
|
||||
Imagenet Superresolution Dataloader
|
||||
Performs following ops in order:
|
||||
@ -296,12 +332,16 @@ class ImageNetSR(Dataset):
|
||||
self.LR_size = int(size / downscale_f)
|
||||
self.min_crop_f = min_crop_f
|
||||
self.max_crop_f = max_crop_f
|
||||
assert(max_crop_f <= 1.)
|
||||
assert max_crop_f <= 1.0
|
||||
self.center_crop = not random_crop
|
||||
|
||||
self.image_rescaler = albumentations.SmallestMaxSize(max_size=size, interpolation=cv2.INTER_AREA)
|
||||
self.image_rescaler = albumentations.SmallestMaxSize(
|
||||
max_size=size, interpolation=cv2.INTER_AREA
|
||||
)
|
||||
|
||||
self.pil_interpolation = False # gets reset later if incase interp_op is from pillow
|
||||
self.pil_interpolation = (
|
||||
False # gets reset later if incase interp_op is from pillow
|
||||
)
|
||||
|
||||
if degradation == "bsrgan":
|
||||
self.degradation_process = partial(degradation_fn_bsr, sf=downscale_f)
|
||||
@ -311,27 +351,30 @@ class ImageNetSR(Dataset):
|
||||
|
||||
else:
|
||||
interpolation_fn = {
|
||||
"cv_nearest": cv2.INTER_NEAREST,
|
||||
"cv_bilinear": cv2.INTER_LINEAR,
|
||||
"cv_bicubic": cv2.INTER_CUBIC,
|
||||
"cv_area": cv2.INTER_AREA,
|
||||
"cv_lanczos": cv2.INTER_LANCZOS4,
|
||||
"pil_nearest": PIL.Image.NEAREST,
|
||||
"pil_bilinear": PIL.Image.BILINEAR,
|
||||
"pil_bicubic": PIL.Image.BICUBIC,
|
||||
"pil_box": PIL.Image.BOX,
|
||||
"pil_hamming": PIL.Image.HAMMING,
|
||||
"pil_lanczos": PIL.Image.LANCZOS,
|
||||
"cv_nearest": cv2.INTER_NEAREST,
|
||||
"cv_bilinear": cv2.INTER_LINEAR,
|
||||
"cv_bicubic": cv2.INTER_CUBIC,
|
||||
"cv_area": cv2.INTER_AREA,
|
||||
"cv_lanczos": cv2.INTER_LANCZOS4,
|
||||
"pil_nearest": PIL.Image.NEAREST,
|
||||
"pil_bilinear": PIL.Image.BILINEAR,
|
||||
"pil_bicubic": PIL.Image.BICUBIC,
|
||||
"pil_box": PIL.Image.BOX,
|
||||
"pil_hamming": PIL.Image.HAMMING,
|
||||
"pil_lanczos": PIL.Image.LANCZOS,
|
||||
}[degradation]
|
||||
|
||||
self.pil_interpolation = degradation.startswith("pil_")
|
||||
|
||||
if self.pil_interpolation:
|
||||
self.degradation_process = partial(TF.resize, size=self.LR_size, interpolation=interpolation_fn)
|
||||
self.degradation_process = partial(
|
||||
TF.resize, size=self.LR_size, interpolation=interpolation_fn
|
||||
)
|
||||
|
||||
else:
|
||||
self.degradation_process = albumentations.SmallestMaxSize(max_size=self.LR_size,
|
||||
interpolation=interpolation_fn)
|
||||
self.degradation_process = albumentations.SmallestMaxSize(
|
||||
max_size=self.LR_size, interpolation=interpolation_fn
|
||||
)
|
||||
|
||||
def __len__(self):
|
||||
return len(self.base)
|
||||
@ -346,14 +389,20 @@ class ImageNetSR(Dataset):
|
||||
image = np.array(image).astype(np.uint8)
|
||||
|
||||
min_side_len = min(image.shape[:2])
|
||||
crop_side_len = min_side_len * np.random.uniform(self.min_crop_f, self.max_crop_f, size=None)
|
||||
crop_side_len = min_side_len * np.random.uniform(
|
||||
self.min_crop_f, self.max_crop_f, size=None
|
||||
)
|
||||
crop_side_len = int(crop_side_len)
|
||||
|
||||
if self.center_crop:
|
||||
self.cropper = albumentations.CenterCrop(height=crop_side_len, width=crop_side_len)
|
||||
self.cropper = albumentations.CenterCrop(
|
||||
height=crop_side_len, width=crop_side_len
|
||||
)
|
||||
|
||||
else:
|
||||
self.cropper = albumentations.RandomCrop(height=crop_side_len, width=crop_side_len)
|
||||
self.cropper = albumentations.RandomCrop(
|
||||
height=crop_side_len, width=crop_side_len
|
||||
)
|
||||
|
||||
image = self.cropper(image=image)["image"]
|
||||
image = self.image_rescaler(image=image)["image"]
|
||||
@ -366,8 +415,8 @@ class ImageNetSR(Dataset):
|
||||
else:
|
||||
LR_image = self.degradation_process(image=image)["image"]
|
||||
|
||||
example["image"] = (image/127.5 - 1.0).astype(np.float32)
|
||||
example["LR_image"] = (LR_image/127.5 - 1.0).astype(np.float32)
|
||||
example["image"] = (image / 127.5 - 1.0).astype(np.float32)
|
||||
example["LR_image"] = (LR_image / 127.5 - 1.0).astype(np.float32)
|
||||
|
||||
return example
|
||||
|
||||
@ -379,7 +428,9 @@ class ImageNetSRTrain(ImageNetSR):
|
||||
def get_base(self):
|
||||
with open("data/imagenet_train_hr_indices.p", "rb") as f:
|
||||
indices = pickle.load(f)
|
||||
dset = ImageNetTrain(process_images=False,)
|
||||
dset = ImageNetTrain(
|
||||
process_images=False,
|
||||
)
|
||||
return Subset(dset, indices)
|
||||
|
||||
|
||||
@ -390,5 +441,7 @@ class ImageNetSRValidation(ImageNetSR):
|
||||
def get_base(self):
|
||||
with open("data/imagenet_val_hr_indices.p", "rb") as f:
|
||||
indices = pickle.load(f)
|
||||
dset = ImageNetValidation(process_images=False,)
|
||||
dset = ImageNetValidation(
|
||||
process_images=False,
|
||||
)
|
||||
return Subset(dset, indices)
|
||||
|
||||
@ -7,13 +7,9 @@ from torchvision import transforms
|
||||
|
||||
|
||||
class LSUNBase(Dataset):
|
||||
def __init__(self,
|
||||
txt_file,
|
||||
data_root,
|
||||
size=None,
|
||||
interpolation="bicubic",
|
||||
flip_p=0.5
|
||||
):
|
||||
def __init__(
|
||||
self, txt_file, data_root, size=None, interpolation="bicubic", flip_p=0.5
|
||||
):
|
||||
self.data_paths = txt_file
|
||||
self.data_root = data_root
|
||||
with open(self.data_paths, "r") as f:
|
||||
@ -21,16 +17,16 @@ class LSUNBase(Dataset):
|
||||
self._length = len(self.image_paths)
|
||||
self.labels = {
|
||||
"relative_file_path_": [l for l in self.image_paths],
|
||||
"file_path_": [os.path.join(self.data_root, l)
|
||||
for l in self.image_paths],
|
||||
"file_path_": [os.path.join(self.data_root, l) for l in self.image_paths],
|
||||
}
|
||||
|
||||
self.size = size
|
||||
self.interpolation = {"linear": PIL.Image.LINEAR,
|
||||
"bilinear": PIL.Image.BILINEAR,
|
||||
"bicubic": PIL.Image.BICUBIC,
|
||||
"lanczos": PIL.Image.LANCZOS,
|
||||
}[interpolation]
|
||||
self.interpolation = {
|
||||
"linear": PIL.Image.LINEAR,
|
||||
"bilinear": PIL.Image.BILINEAR,
|
||||
"bicubic": PIL.Image.BICUBIC,
|
||||
"lanczos": PIL.Image.LANCZOS,
|
||||
}[interpolation]
|
||||
self.flip = transforms.RandomHorizontalFlip(p=flip_p)
|
||||
|
||||
def __len__(self):
|
||||
@ -45,9 +41,14 @@ class LSUNBase(Dataset):
|
||||
# default to score-sde preprocessing
|
||||
img = np.array(image).astype(np.uint8)
|
||||
crop = min(img.shape[0], img.shape[1])
|
||||
h, w, = img.shape[0], img.shape[1]
|
||||
img = img[(h - crop) // 2:(h + crop) // 2,
|
||||
(w - crop) // 2:(w + crop) // 2]
|
||||
(
|
||||
h,
|
||||
w,
|
||||
) = (
|
||||
img.shape[0],
|
||||
img.shape[1],
|
||||
)
|
||||
img = img[(h - crop) // 2 : (h + crop) // 2, (w - crop) // 2 : (w + crop) // 2]
|
||||
|
||||
image = Image.fromarray(img)
|
||||
if self.size is not None:
|
||||
@ -61,32 +62,54 @@ class LSUNBase(Dataset):
|
||||
|
||||
class LSUNChurchesTrain(LSUNBase):
|
||||
def __init__(self, **kwargs):
|
||||
super().__init__(txt_file="data/lsun/church_outdoor_train.txt", data_root="data/lsun/churches", **kwargs)
|
||||
super().__init__(
|
||||
txt_file="data/lsun/church_outdoor_train.txt",
|
||||
data_root="data/lsun/churches",
|
||||
**kwargs
|
||||
)
|
||||
|
||||
|
||||
class LSUNChurchesValidation(LSUNBase):
|
||||
def __init__(self, flip_p=0., **kwargs):
|
||||
super().__init__(txt_file="data/lsun/church_outdoor_val.txt", data_root="data/lsun/churches",
|
||||
flip_p=flip_p, **kwargs)
|
||||
def __init__(self, flip_p=0.0, **kwargs):
|
||||
super().__init__(
|
||||
txt_file="data/lsun/church_outdoor_val.txt",
|
||||
data_root="data/lsun/churches",
|
||||
flip_p=flip_p,
|
||||
**kwargs
|
||||
)
|
||||
|
||||
|
||||
class LSUNBedroomsTrain(LSUNBase):
|
||||
def __init__(self, **kwargs):
|
||||
super().__init__(txt_file="data/lsun/bedrooms_train.txt", data_root="data/lsun/bedrooms", **kwargs)
|
||||
super().__init__(
|
||||
txt_file="data/lsun/bedrooms_train.txt",
|
||||
data_root="data/lsun/bedrooms",
|
||||
**kwargs
|
||||
)
|
||||
|
||||
|
||||
class LSUNBedroomsValidation(LSUNBase):
|
||||
def __init__(self, flip_p=0.0, **kwargs):
|
||||
super().__init__(txt_file="data/lsun/bedrooms_val.txt", data_root="data/lsun/bedrooms",
|
||||
flip_p=flip_p, **kwargs)
|
||||
super().__init__(
|
||||
txt_file="data/lsun/bedrooms_val.txt",
|
||||
data_root="data/lsun/bedrooms",
|
||||
flip_p=flip_p,
|
||||
**kwargs
|
||||
)
|
||||
|
||||
|
||||
class LSUNCatsTrain(LSUNBase):
|
||||
def __init__(self, **kwargs):
|
||||
super().__init__(txt_file="data/lsun/cat_train.txt", data_root="data/lsun/cats", **kwargs)
|
||||
super().__init__(
|
||||
txt_file="data/lsun/cat_train.txt", data_root="data/lsun/cats", **kwargs
|
||||
)
|
||||
|
||||
|
||||
class LSUNCatsValidation(LSUNBase):
|
||||
def __init__(self, flip_p=0., **kwargs):
|
||||
super().__init__(txt_file="data/lsun/cat_val.txt", data_root="data/lsun/cats",
|
||||
flip_p=flip_p, **kwargs)
|
||||
def __init__(self, flip_p=0.0, **kwargs):
|
||||
super().__init__(
|
||||
txt_file="data/lsun/cat_val.txt",
|
||||
data_root="data/lsun/cats",
|
||||
flip_p=flip_p,
|
||||
**kwargs
|
||||
)
|
||||
|
||||
@ -9,70 +9,71 @@ from PIL import Image
|
||||
|
||||
from data.utils import pre_caption
|
||||
|
||||
|
||||
class nlvr_dataset(Dataset):
|
||||
def __init__(self, transform, image_root, ann_root, split):
|
||||
'''
|
||||
image_root (string): Root directory of images
|
||||
def __init__(self, transform, image_root, ann_root, split):
|
||||
"""
|
||||
image_root (string): Root directory of images
|
||||
ann_root (string): directory to store the annotation file
|
||||
split (string): train, val or test
|
||||
'''
|
||||
urls = {'train':'https://storage.googleapis.com/sfr-vision-language-research/datasets/nlvr_train.json',
|
||||
'val':'https://storage.googleapis.com/sfr-vision-language-research/datasets/nlvr_dev.json',
|
||||
'test':'https://storage.googleapis.com/sfr-vision-language-research/datasets/nlvr_test.json'}
|
||||
filenames = {'train':'nlvr_train.json','val':'nlvr_dev.json','test':'nlvr_test.json'}
|
||||
|
||||
download_url(urls[split],ann_root)
|
||||
self.annotation = json.load(open(os.path.join(ann_root,filenames[split]),'r'))
|
||||
|
||||
"""
|
||||
urls = {
|
||||
"train": "https://storage.googleapis.com/sfr-vision-language-research/datasets/nlvr_train.json",
|
||||
"val": "https://storage.googleapis.com/sfr-vision-language-research/datasets/nlvr_dev.json",
|
||||
"test": "https://storage.googleapis.com/sfr-vision-language-research/datasets/nlvr_test.json",
|
||||
}
|
||||
filenames = {
|
||||
"train": "nlvr_train.json",
|
||||
"val": "nlvr_dev.json",
|
||||
"test": "nlvr_test.json",
|
||||
}
|
||||
|
||||
download_url(urls[split], ann_root)
|
||||
self.annotation = json.load(open(os.path.join(ann_root, filenames[split]), "r"))
|
||||
|
||||
self.transform = transform
|
||||
self.image_root = image_root
|
||||
|
||||
|
||||
def __len__(self):
|
||||
return len(self.annotation)
|
||||
|
||||
|
||||
def __getitem__(self, index):
|
||||
|
||||
def __getitem__(self, index):
|
||||
ann = self.annotation[index]
|
||||
|
||||
image0_path = os.path.join(self.image_root,ann['images'][0])
|
||||
image0 = Image.open(image0_path).convert('RGB')
|
||||
image0 = self.transform(image0)
|
||||
|
||||
image1_path = os.path.join(self.image_root,ann['images'][1])
|
||||
image1 = Image.open(image1_path).convert('RGB')
|
||||
image1 = self.transform(image1)
|
||||
|
||||
sentence = pre_caption(ann['sentence'], 40)
|
||||
|
||||
if ann['label']=='True':
|
||||
image0_path = os.path.join(self.image_root, ann["images"][0])
|
||||
image0 = Image.open(image0_path).convert("RGB")
|
||||
image0 = self.transform(image0)
|
||||
|
||||
image1_path = os.path.join(self.image_root, ann["images"][1])
|
||||
image1 = Image.open(image1_path).convert("RGB")
|
||||
image1 = self.transform(image1)
|
||||
|
||||
sentence = pre_caption(ann["sentence"], 40)
|
||||
|
||||
if ann["label"] == "True":
|
||||
label = 1
|
||||
else:
|
||||
label = 0
|
||||
|
||||
words = sentence.split(' ')
|
||||
|
||||
if 'left' not in words and 'right' not in words:
|
||||
if random.random()<0.5:
|
||||
|
||||
words = sentence.split(" ")
|
||||
|
||||
if "left" not in words and "right" not in words:
|
||||
if random.random() < 0.5:
|
||||
return image0, image1, sentence, label
|
||||
else:
|
||||
return image1, image0, sentence, label
|
||||
else:
|
||||
if random.random()<0.5:
|
||||
if random.random() < 0.5:
|
||||
return image0, image1, sentence, label
|
||||
else:
|
||||
new_words = []
|
||||
for word in words:
|
||||
if word=='left':
|
||||
new_words.append('right')
|
||||
elif word=='right':
|
||||
new_words.append('left')
|
||||
if word == "left":
|
||||
new_words.append("right")
|
||||
elif word == "right":
|
||||
new_words.append("left")
|
||||
else:
|
||||
new_words.append(word)
|
||||
|
||||
sentence = ' '.join(new_words)
|
||||
new_words.append(word)
|
||||
|
||||
sentence = " ".join(new_words)
|
||||
return image1, image0, sentence, label
|
||||
|
||||
|
||||
|
||||
@ -6,27 +6,29 @@ from torchvision.datasets.utils import download_url
|
||||
|
||||
from PIL import Image
|
||||
|
||||
|
||||
class nocaps_eval(Dataset):
|
||||
def __init__(self, transform, image_root, ann_root, split):
|
||||
urls = {'val':'https://storage.googleapis.com/sfr-vision-language-research/datasets/nocaps_val.json',
|
||||
'test':'https://storage.googleapis.com/sfr-vision-language-research/datasets/nocaps_test.json'}
|
||||
filenames = {'val':'nocaps_val.json','test':'nocaps_test.json'}
|
||||
|
||||
download_url(urls[split],ann_root)
|
||||
|
||||
self.annotation = json.load(open(os.path.join(ann_root,filenames[split]),'r'))
|
||||
def __init__(self, transform, image_root, ann_root, split):
|
||||
urls = {
|
||||
"val": "https://storage.googleapis.com/sfr-vision-language-research/datasets/nocaps_val.json",
|
||||
"test": "https://storage.googleapis.com/sfr-vision-language-research/datasets/nocaps_test.json",
|
||||
}
|
||||
filenames = {"val": "nocaps_val.json", "test": "nocaps_test.json"}
|
||||
|
||||
download_url(urls[split], ann_root)
|
||||
|
||||
self.annotation = json.load(open(os.path.join(ann_root, filenames[split]), "r"))
|
||||
self.transform = transform
|
||||
self.image_root = image_root
|
||||
|
||||
|
||||
def __len__(self):
|
||||
return len(self.annotation)
|
||||
|
||||
def __getitem__(self, index):
|
||||
|
||||
|
||||
def __getitem__(self, index):
|
||||
ann = self.annotation[index]
|
||||
|
||||
image_path = os.path.join(self.image_root,ann['image'])
|
||||
image = Image.open(image_path).convert('RGB')
|
||||
image = self.transform(image)
|
||||
|
||||
return image, int(ann['img_id'])
|
||||
|
||||
image_path = os.path.join(self.image_root, ann["image"])
|
||||
image = Image.open(image_path).convert("RGB")
|
||||
image = self.transform(image)
|
||||
|
||||
return image, int(ann["img_id"])
|
||||
|
||||
@ -8,92 +8,92 @@ from torchvision import transforms
|
||||
import random
|
||||
|
||||
imagenet_templates_smallest = [
|
||||
'a photo of a {}',
|
||||
"a photo of a {}",
|
||||
]
|
||||
|
||||
imagenet_templates_small = [
|
||||
'a photo of a {}',
|
||||
'a rendering of a {}',
|
||||
'a cropped photo of the {}',
|
||||
'the photo of a {}',
|
||||
'a photo of a clean {}',
|
||||
'a photo of a dirty {}',
|
||||
'a dark photo of the {}',
|
||||
'a photo of my {}',
|
||||
'a photo of the cool {}',
|
||||
'a close-up photo of a {}',
|
||||
'a bright photo of the {}',
|
||||
'a cropped photo of a {}',
|
||||
'a photo of the {}',
|
||||
'a good photo of the {}',
|
||||
'a photo of one {}',
|
||||
'a close-up photo of the {}',
|
||||
'a rendition of the {}',
|
||||
'a photo of the clean {}',
|
||||
'a rendition of a {}',
|
||||
'a photo of a nice {}',
|
||||
'a good photo of a {}',
|
||||
'a photo of the nice {}',
|
||||
'a photo of the small {}',
|
||||
'a photo of the weird {}',
|
||||
'a photo of the large {}',
|
||||
'a photo of a cool {}',
|
||||
'a photo of a small {}',
|
||||
"a photo of a {}",
|
||||
"a rendering of a {}",
|
||||
"a cropped photo of the {}",
|
||||
"the photo of a {}",
|
||||
"a photo of a clean {}",
|
||||
"a photo of a dirty {}",
|
||||
"a dark photo of the {}",
|
||||
"a photo of my {}",
|
||||
"a photo of the cool {}",
|
||||
"a close-up photo of a {}",
|
||||
"a bright photo of the {}",
|
||||
"a cropped photo of a {}",
|
||||
"a photo of the {}",
|
||||
"a good photo of the {}",
|
||||
"a photo of one {}",
|
||||
"a close-up photo of the {}",
|
||||
"a rendition of the {}",
|
||||
"a photo of the clean {}",
|
||||
"a rendition of a {}",
|
||||
"a photo of a nice {}",
|
||||
"a good photo of a {}",
|
||||
"a photo of the nice {}",
|
||||
"a photo of the small {}",
|
||||
"a photo of the weird {}",
|
||||
"a photo of the large {}",
|
||||
"a photo of a cool {}",
|
||||
"a photo of a small {}",
|
||||
]
|
||||
|
||||
imagenet_dual_templates_small = [
|
||||
'a photo of a {} with {}',
|
||||
'a rendering of a {} with {}',
|
||||
'a cropped photo of the {} with {}',
|
||||
'the photo of a {} with {}',
|
||||
'a photo of a clean {} with {}',
|
||||
'a photo of a dirty {} with {}',
|
||||
'a dark photo of the {} with {}',
|
||||
'a photo of my {} with {}',
|
||||
'a photo of the cool {} with {}',
|
||||
'a close-up photo of a {} with {}',
|
||||
'a bright photo of the {} with {}',
|
||||
'a cropped photo of a {} with {}',
|
||||
'a photo of the {} with {}',
|
||||
'a good photo of the {} with {}',
|
||||
'a photo of one {} with {}',
|
||||
'a close-up photo of the {} with {}',
|
||||
'a rendition of the {} with {}',
|
||||
'a photo of the clean {} with {}',
|
||||
'a rendition of a {} with {}',
|
||||
'a photo of a nice {} with {}',
|
||||
'a good photo of a {} with {}',
|
||||
'a photo of the nice {} with {}',
|
||||
'a photo of the small {} with {}',
|
||||
'a photo of the weird {} with {}',
|
||||
'a photo of the large {} with {}',
|
||||
'a photo of a cool {} with {}',
|
||||
'a photo of a small {} with {}',
|
||||
"a photo of a {} with {}",
|
||||
"a rendering of a {} with {}",
|
||||
"a cropped photo of the {} with {}",
|
||||
"the photo of a {} with {}",
|
||||
"a photo of a clean {} with {}",
|
||||
"a photo of a dirty {} with {}",
|
||||
"a dark photo of the {} with {}",
|
||||
"a photo of my {} with {}",
|
||||
"a photo of the cool {} with {}",
|
||||
"a close-up photo of a {} with {}",
|
||||
"a bright photo of the {} with {}",
|
||||
"a cropped photo of a {} with {}",
|
||||
"a photo of the {} with {}",
|
||||
"a good photo of the {} with {}",
|
||||
"a photo of one {} with {}",
|
||||
"a close-up photo of the {} with {}",
|
||||
"a rendition of the {} with {}",
|
||||
"a photo of the clean {} with {}",
|
||||
"a rendition of a {} with {}",
|
||||
"a photo of a nice {} with {}",
|
||||
"a good photo of a {} with {}",
|
||||
"a photo of the nice {} with {}",
|
||||
"a photo of the small {} with {}",
|
||||
"a photo of the weird {} with {}",
|
||||
"a photo of the large {} with {}",
|
||||
"a photo of a cool {} with {}",
|
||||
"a photo of a small {} with {}",
|
||||
]
|
||||
|
||||
per_img_token_list = [
|
||||
'א',
|
||||
'ב',
|
||||
'ג',
|
||||
'ד',
|
||||
'ה',
|
||||
'ו',
|
||||
'ז',
|
||||
'ח',
|
||||
'ט',
|
||||
'י',
|
||||
'כ',
|
||||
'ל',
|
||||
'מ',
|
||||
'נ',
|
||||
'ס',
|
||||
'ע',
|
||||
'פ',
|
||||
'צ',
|
||||
'ק',
|
||||
'ר',
|
||||
'ש',
|
||||
'ת',
|
||||
"א",
|
||||
"ב",
|
||||
"ג",
|
||||
"ד",
|
||||
"ה",
|
||||
"ו",
|
||||
"ז",
|
||||
"ח",
|
||||
"ט",
|
||||
"י",
|
||||
"כ",
|
||||
"ל",
|
||||
"מ",
|
||||
"נ",
|
||||
"ס",
|
||||
"ע",
|
||||
"פ",
|
||||
"צ",
|
||||
"ק",
|
||||
"ר",
|
||||
"ש",
|
||||
"ת",
|
||||
]
|
||||
|
||||
|
||||
@ -103,16 +103,15 @@ class PersonalizedBase(Dataset):
|
||||
data_root,
|
||||
size=None,
|
||||
repeats=100,
|
||||
interpolation='bicubic',
|
||||
interpolation="bicubic",
|
||||
flip_p=0.5,
|
||||
set='train',
|
||||
placeholder_token='*',
|
||||
set="train",
|
||||
placeholder_token="*",
|
||||
per_image_tokens=False,
|
||||
center_crop=False,
|
||||
mixing_prob=0.25,
|
||||
coarse_class_text=None,
|
||||
):
|
||||
|
||||
self.data_root = data_root
|
||||
|
||||
self.image_paths = [
|
||||
@ -137,15 +136,15 @@ class PersonalizedBase(Dataset):
|
||||
per_img_token_list
|
||||
), f"Can't use per-image tokens when the training set contains more than {len(per_img_token_list)} tokens. To enable larger sets, add more tokens to 'per_img_token_list'."
|
||||
|
||||
if set == 'train':
|
||||
if set == "train":
|
||||
self._length = self.num_images * repeats
|
||||
|
||||
self.size = size
|
||||
self.interpolation = {
|
||||
'linear': PIL.Image.LINEAR,
|
||||
'bilinear': PIL.Image.BILINEAR,
|
||||
'bicubic': PIL.Image.BICUBIC,
|
||||
'lanczos': PIL.Image.LANCZOS,
|
||||
"linear": PIL.Image.LINEAR,
|
||||
"bilinear": PIL.Image.BILINEAR,
|
||||
"bicubic": PIL.Image.BICUBIC,
|
||||
"lanczos": PIL.Image.LANCZOS,
|
||||
}[interpolation]
|
||||
self.flip = transforms.RandomHorizontalFlip(p=flip_p)
|
||||
|
||||
@ -156,32 +155,31 @@ class PersonalizedBase(Dataset):
|
||||
example = {}
|
||||
image = Image.open(self.image_paths[i % self.num_images])
|
||||
|
||||
if not image.mode == 'RGB':
|
||||
image = image.convert('RGB')
|
||||
if not image.mode == "RGB":
|
||||
image = image.convert("RGB")
|
||||
|
||||
placeholder_string = self.placeholder_token
|
||||
if self.coarse_class_text:
|
||||
placeholder_string = (
|
||||
f'{self.coarse_class_text} {placeholder_string}'
|
||||
)
|
||||
placeholder_string = f"{self.coarse_class_text} {placeholder_string}"
|
||||
|
||||
if self.per_image_tokens and np.random.uniform() < self.mixing_prob:
|
||||
text = random.choice(imagenet_dual_templates_small).format(
|
||||
placeholder_string, per_img_token_list[i % self.num_images]
|
||||
)
|
||||
else:
|
||||
text = random.choice(imagenet_templates_small).format(
|
||||
placeholder_string
|
||||
)
|
||||
text = random.choice(imagenet_templates_small).format(placeholder_string)
|
||||
|
||||
example['caption'] = text
|
||||
example["caption"] = text
|
||||
|
||||
# default to score-sde preprocessing
|
||||
img = np.array(image).astype(np.uint8)
|
||||
|
||||
if self.center_crop:
|
||||
crop = min(img.shape[0], img.shape[1])
|
||||
h, w, = (
|
||||
(
|
||||
h,
|
||||
w,
|
||||
) = (
|
||||
img.shape[0],
|
||||
img.shape[1],
|
||||
)
|
||||
@ -192,11 +190,9 @@ class PersonalizedBase(Dataset):
|
||||
|
||||
image = Image.fromarray(img)
|
||||
if self.size is not None:
|
||||
image = image.resize(
|
||||
(self.size, self.size), resample=self.interpolation
|
||||
)
|
||||
image = image.resize((self.size, self.size), resample=self.interpolation)
|
||||
|
||||
image = self.flip(image)
|
||||
image = np.array(image).astype(np.uint8)
|
||||
example['image'] = (image / 127.5 - 1.0).astype(np.float32)
|
||||
example["image"] = (image / 127.5 - 1.0).astype(np.float32)
|
||||
return example
|
||||
|
||||
@ -8,70 +8,70 @@ from torchvision import transforms
|
||||
import random
|
||||
|
||||
imagenet_templates_small = [
|
||||
'a painting in the style of {}',
|
||||
'a rendering in the style of {}',
|
||||
'a cropped painting in the style of {}',
|
||||
'the painting in the style of {}',
|
||||
'a clean painting in the style of {}',
|
||||
'a dirty painting in the style of {}',
|
||||
'a dark painting in the style of {}',
|
||||
'a picture in the style of {}',
|
||||
'a cool painting in the style of {}',
|
||||
'a close-up painting in the style of {}',
|
||||
'a bright painting in the style of {}',
|
||||
'a cropped painting in the style of {}',
|
||||
'a good painting in the style of {}',
|
||||
'a close-up painting in the style of {}',
|
||||
'a rendition in the style of {}',
|
||||
'a nice painting in the style of {}',
|
||||
'a small painting in the style of {}',
|
||||
'a weird painting in the style of {}',
|
||||
'a large painting in the style of {}',
|
||||
"a painting in the style of {}",
|
||||
"a rendering in the style of {}",
|
||||
"a cropped painting in the style of {}",
|
||||
"the painting in the style of {}",
|
||||
"a clean painting in the style of {}",
|
||||
"a dirty painting in the style of {}",
|
||||
"a dark painting in the style of {}",
|
||||
"a picture in the style of {}",
|
||||
"a cool painting in the style of {}",
|
||||
"a close-up painting in the style of {}",
|
||||
"a bright painting in the style of {}",
|
||||
"a cropped painting in the style of {}",
|
||||
"a good painting in the style of {}",
|
||||
"a close-up painting in the style of {}",
|
||||
"a rendition in the style of {}",
|
||||
"a nice painting in the style of {}",
|
||||
"a small painting in the style of {}",
|
||||
"a weird painting in the style of {}",
|
||||
"a large painting in the style of {}",
|
||||
]
|
||||
|
||||
imagenet_dual_templates_small = [
|
||||
'a painting in the style of {} with {}',
|
||||
'a rendering in the style of {} with {}',
|
||||
'a cropped painting in the style of {} with {}',
|
||||
'the painting in the style of {} with {}',
|
||||
'a clean painting in the style of {} with {}',
|
||||
'a dirty painting in the style of {} with {}',
|
||||
'a dark painting in the style of {} with {}',
|
||||
'a cool painting in the style of {} with {}',
|
||||
'a close-up painting in the style of {} with {}',
|
||||
'a bright painting in the style of {} with {}',
|
||||
'a cropped painting in the style of {} with {}',
|
||||
'a good painting in the style of {} with {}',
|
||||
'a painting of one {} in the style of {}',
|
||||
'a nice painting in the style of {} with {}',
|
||||
'a small painting in the style of {} with {}',
|
||||
'a weird painting in the style of {} with {}',
|
||||
'a large painting in the style of {} with {}',
|
||||
"a painting in the style of {} with {}",
|
||||
"a rendering in the style of {} with {}",
|
||||
"a cropped painting in the style of {} with {}",
|
||||
"the painting in the style of {} with {}",
|
||||
"a clean painting in the style of {} with {}",
|
||||
"a dirty painting in the style of {} with {}",
|
||||
"a dark painting in the style of {} with {}",
|
||||
"a cool painting in the style of {} with {}",
|
||||
"a close-up painting in the style of {} with {}",
|
||||
"a bright painting in the style of {} with {}",
|
||||
"a cropped painting in the style of {} with {}",
|
||||
"a good painting in the style of {} with {}",
|
||||
"a painting of one {} in the style of {}",
|
||||
"a nice painting in the style of {} with {}",
|
||||
"a small painting in the style of {} with {}",
|
||||
"a weird painting in the style of {} with {}",
|
||||
"a large painting in the style of {} with {}",
|
||||
]
|
||||
|
||||
per_img_token_list = [
|
||||
'א',
|
||||
'ב',
|
||||
'ג',
|
||||
'ד',
|
||||
'ה',
|
||||
'ו',
|
||||
'ז',
|
||||
'ח',
|
||||
'ט',
|
||||
'י',
|
||||
'כ',
|
||||
'ל',
|
||||
'מ',
|
||||
'נ',
|
||||
'ס',
|
||||
'ע',
|
||||
'פ',
|
||||
'צ',
|
||||
'ק',
|
||||
'ר',
|
||||
'ש',
|
||||
'ת',
|
||||
"א",
|
||||
"ב",
|
||||
"ג",
|
||||
"ד",
|
||||
"ה",
|
||||
"ו",
|
||||
"ז",
|
||||
"ח",
|
||||
"ט",
|
||||
"י",
|
||||
"כ",
|
||||
"ל",
|
||||
"מ",
|
||||
"נ",
|
||||
"ס",
|
||||
"ע",
|
||||
"פ",
|
||||
"צ",
|
||||
"ק",
|
||||
"ר",
|
||||
"ש",
|
||||
"ת",
|
||||
]
|
||||
|
||||
|
||||
@ -81,14 +81,13 @@ class PersonalizedBase(Dataset):
|
||||
data_root,
|
||||
size=None,
|
||||
repeats=100,
|
||||
interpolation='bicubic',
|
||||
interpolation="bicubic",
|
||||
flip_p=0.5,
|
||||
set='train',
|
||||
placeholder_token='*',
|
||||
set="train",
|
||||
placeholder_token="*",
|
||||
per_image_tokens=False,
|
||||
center_crop=False,
|
||||
):
|
||||
|
||||
self.data_root = data_root
|
||||
|
||||
self.image_paths = [
|
||||
@ -110,15 +109,15 @@ class PersonalizedBase(Dataset):
|
||||
per_img_token_list
|
||||
), f"Can't use per-image tokens when the training set contains more than {len(per_img_token_list)} tokens. To enable larger sets, add more tokens to 'per_img_token_list'."
|
||||
|
||||
if set == 'train':
|
||||
if set == "train":
|
||||
self._length = self.num_images * repeats
|
||||
|
||||
self.size = size
|
||||
self.interpolation = {
|
||||
'linear': PIL.Image.LINEAR,
|
||||
'bilinear': PIL.Image.BILINEAR,
|
||||
'bicubic': PIL.Image.BICUBIC,
|
||||
'lanczos': PIL.Image.LANCZOS,
|
||||
"linear": PIL.Image.LINEAR,
|
||||
"bilinear": PIL.Image.BILINEAR,
|
||||
"bicubic": PIL.Image.BICUBIC,
|
||||
"lanczos": PIL.Image.LANCZOS,
|
||||
}[interpolation]
|
||||
self.flip = transforms.RandomHorizontalFlip(p=flip_p)
|
||||
|
||||
@ -129,8 +128,8 @@ class PersonalizedBase(Dataset):
|
||||
example = {}
|
||||
image = Image.open(self.image_paths[i % self.num_images])
|
||||
|
||||
if not image.mode == 'RGB':
|
||||
image = image.convert('RGB')
|
||||
if not image.mode == "RGB":
|
||||
image = image.convert("RGB")
|
||||
|
||||
if self.per_image_tokens and np.random.uniform() < 0.25:
|
||||
text = random.choice(imagenet_dual_templates_small).format(
|
||||
@ -141,14 +140,17 @@ class PersonalizedBase(Dataset):
|
||||
self.placeholder_token
|
||||
)
|
||||
|
||||
example['caption'] = text
|
||||
example["caption"] = text
|
||||
|
||||
# default to score-sde preprocessing
|
||||
img = np.array(image).astype(np.uint8)
|
||||
|
||||
if self.center_crop:
|
||||
crop = min(img.shape[0], img.shape[1])
|
||||
h, w, = (
|
||||
(
|
||||
h,
|
||||
w,
|
||||
) = (
|
||||
img.shape[0],
|
||||
img.shape[1],
|
||||
)
|
||||
@ -159,11 +161,9 @@ class PersonalizedBase(Dataset):
|
||||
|
||||
image = Image.fromarray(img)
|
||||
if self.size is not None:
|
||||
image = image.resize(
|
||||
(self.size, self.size), resample=self.interpolation
|
||||
)
|
||||
image = image.resize((self.size, self.size), resample=self.interpolation)
|
||||
|
||||
image = self.flip(image)
|
||||
image = np.array(image).astype(np.uint8)
|
||||
example['image'] = (image / 127.5 - 1.0).astype(np.float32)
|
||||
example["image"] = (image / 127.5 - 1.0).astype(np.float32)
|
||||
return example
|
||||
|
||||
@ -1,59 +1,56 @@
|
||||
import json
|
||||
import os
|
||||
import random
|
||||
|
||||
from torch.utils.data import Dataset
|
||||
|
||||
from PIL import Image
|
||||
from PIL import ImageFile
|
||||
|
||||
ImageFile.LOAD_TRUNCATED_IMAGES = True
|
||||
Image.MAX_IMAGE_PIXELS = None
|
||||
|
||||
from data.utils import pre_caption
|
||||
import os,glob
|
||||
import os, glob
|
||||
|
||||
|
||||
class pretrain_dataset(Dataset):
|
||||
def __init__(self, ann_file, laion_path, transform):
|
||||
|
||||
def __init__(self, ann_file, laion_path, transform):
|
||||
self.ann_pretrain = []
|
||||
for f in ann_file:
|
||||
print('loading '+f)
|
||||
ann = json.load(open(f,'r'))
|
||||
print("loading " + f)
|
||||
ann = json.load(open(f, "r"))
|
||||
self.ann_pretrain += ann
|
||||
|
||||
|
||||
self.laion_path = laion_path
|
||||
if self.laion_path:
|
||||
self.laion_files = glob.glob(os.path.join(laion_path,'*.json'))
|
||||
self.laion_files = glob.glob(os.path.join(laion_path, "*.json"))
|
||||
|
||||
print('loading '+self.laion_files[0])
|
||||
with open(self.laion_files[0],'r') as f:
|
||||
self.ann_laion = json.load(f)
|
||||
print("loading " + self.laion_files[0])
|
||||
with open(self.laion_files[0], "r") as f:
|
||||
self.ann_laion = json.load(f)
|
||||
|
||||
self.annotation = self.ann_pretrain + self.ann_laion
|
||||
else:
|
||||
self.annotation = self.ann_pretrain
|
||||
|
||||
|
||||
self.transform = transform
|
||||
|
||||
|
||||
def reload_laion(self, epoch):
|
||||
n = epoch%len(self.laion_files)
|
||||
print('loading '+self.laion_files[n])
|
||||
with open(self.laion_files[n],'r') as f:
|
||||
self.ann_laion = json.load(f)
|
||||
|
||||
self.annotation = self.ann_pretrain + self.ann_laion
|
||||
|
||||
|
||||
n = epoch % len(self.laion_files)
|
||||
print("loading " + self.laion_files[n])
|
||||
with open(self.laion_files[n], "r") as f:
|
||||
self.ann_laion = json.load(f)
|
||||
|
||||
self.annotation = self.ann_pretrain + self.ann_laion
|
||||
|
||||
def __len__(self):
|
||||
return len(self.annotation)
|
||||
|
||||
def __getitem__(self, index):
|
||||
|
||||
ann = self.annotation[index]
|
||||
|
||||
image = Image.open(ann['image']).convert('RGB')
|
||||
|
||||
def __getitem__(self, index):
|
||||
ann = self.annotation[index]
|
||||
|
||||
image = Image.open(ann["image"]).convert("RGB")
|
||||
image = self.transform(image)
|
||||
caption = pre_caption(ann['caption'],30)
|
||||
|
||||
return image, caption
|
||||
caption = pre_caption(ann["caption"], 30)
|
||||
|
||||
return image, caption
|
||||
|
||||
@ -9,16 +9,16 @@ class AddMiDaS(object):
|
||||
self.transform = load_midas_transform(model_type)
|
||||
|
||||
def pt2np(self, x):
|
||||
x = ((x + 1.0) * .5).detach().cpu().numpy()
|
||||
x = ((x + 1.0) * 0.5).detach().cpu().numpy()
|
||||
return x
|
||||
|
||||
def np2pt(self, x):
|
||||
x = torch.from_numpy(x) * 2 - 1.
|
||||
x = torch.from_numpy(x) * 2 - 1.0
|
||||
return x
|
||||
|
||||
def __call__(self, sample):
|
||||
# sample['jpg'] is tensor hwc in [-1, 1] at this point
|
||||
x = self.pt2np(sample['jpg'])
|
||||
x = self.pt2np(sample["jpg"])
|
||||
x = self.transform({"image": x})["image"]
|
||||
sample['midas_in'] = x
|
||||
return sample
|
||||
sample["midas_in"] = x
|
||||
return sample
|
||||
|
||||
@ -1,7 +1,6 @@
|
||||
from torch.utils.data import Dataset
|
||||
from torchvision.datasets.utils import download_url
|
||||
|
||||
from PIL import Image
|
||||
import torch
|
||||
import numpy as np
|
||||
import random
|
||||
@ -13,67 +12,84 @@ from data.utils import pre_caption
|
||||
|
||||
decord.bridge.set_bridge("torch")
|
||||
|
||||
|
||||
class ImageNorm(object):
|
||||
"""Apply Normalization to Image Pixels on GPU
|
||||
"""
|
||||
"""Apply Normalization to Image Pixels on GPU"""
|
||||
|
||||
def __init__(self, mean, std):
|
||||
self.mean = torch.tensor(mean).view(1, 3, 1, 1)
|
||||
self.std = torch.tensor(std).view(1, 3, 1, 1)
|
||||
|
||||
def __call__(self, img):
|
||||
|
||||
def __call__(self, img):
|
||||
if torch.max(img) > 1 and self.mean.max() <= 1:
|
||||
img.div_(255.)
|
||||
img.div_(255.0)
|
||||
return img.sub_(self.mean).div_(self.std)
|
||||
|
||||
|
||||
def load_jsonl(filename):
|
||||
with open(filename, "r") as f:
|
||||
return [json.loads(l.strip("\n")) for l in f.readlines()]
|
||||
|
||||
|
||||
class VideoDataset(Dataset):
|
||||
|
||||
def __init__(self, video_root, ann_root, num_frm=4, frm_sampling_strategy="rand", max_img_size=384, video_fmt='.mp4'):
|
||||
'''
|
||||
|
||||
class VideoDataset(Dataset):
|
||||
def __init__(
|
||||
self,
|
||||
video_root,
|
||||
ann_root,
|
||||
num_frm=4,
|
||||
frm_sampling_strategy="rand",
|
||||
max_img_size=384,
|
||||
video_fmt=".mp4",
|
||||
):
|
||||
"""
|
||||
image_root (string): Root directory of video
|
||||
ann_root (string): directory to store the annotation file
|
||||
'''
|
||||
url = 'https://storage.googleapis.com/sfr-vision-language-research/datasets/msrvtt_test.jsonl'
|
||||
filename = 'msrvtt_test.jsonl'
|
||||
"""
|
||||
url = "https://storage.googleapis.com/sfr-vision-language-research/datasets/msrvtt_test.jsonl"
|
||||
filename = "msrvtt_test.jsonl"
|
||||
|
||||
download_url(url, ann_root)
|
||||
self.annotation = load_jsonl(os.path.join(ann_root, filename))
|
||||
|
||||
download_url(url,ann_root)
|
||||
self.annotation = load_jsonl(os.path.join(ann_root,filename))
|
||||
|
||||
self.num_frm = num_frm
|
||||
self.frm_sampling_strategy = frm_sampling_strategy
|
||||
self.max_img_size = max_img_size
|
||||
self.video_root = video_root
|
||||
self.video_fmt = video_fmt
|
||||
self.img_norm = ImageNorm(mean=(0.48145466, 0.4578275, 0.40821073), std=(0.26862954, 0.26130258, 0.27577711))
|
||||
self.img_norm = ImageNorm(
|
||||
mean=(0.48145466, 0.4578275, 0.40821073),
|
||||
std=(0.26862954, 0.26130258, 0.27577711),
|
||||
)
|
||||
|
||||
self.text = [pre_caption(ann['caption'],40) for ann in self.annotation]
|
||||
self.text = [pre_caption(ann["caption"], 40) for ann in self.annotation]
|
||||
self.txt2video = [i for i in range(len(self.annotation))]
|
||||
self.video2txt = self.txt2video
|
||||
|
||||
|
||||
self.video2txt = self.txt2video
|
||||
|
||||
def __len__(self):
|
||||
return len(self.annotation)
|
||||
|
||||
def __getitem__(self, index):
|
||||
ann = self.annotation[index]
|
||||
|
||||
ann = self.annotation[index]
|
||||
video_path = os.path.join(self.video_root, ann["clip_name"] + self.video_fmt)
|
||||
|
||||
video_path = os.path.join(self.video_root, ann['clip_name'] + self.video_fmt)
|
||||
|
||||
vid_frm_array = self._load_video_from_path_decord(video_path, height=self.max_img_size, width=self.max_img_size)
|
||||
vid_frm_array = self._load_video_from_path_decord(
|
||||
video_path, height=self.max_img_size, width=self.max_img_size
|
||||
)
|
||||
|
||||
video = self.img_norm(vid_frm_array.float())
|
||||
|
||||
return video, ann['clip_name']
|
||||
|
||||
|
||||
return video, ann["clip_name"]
|
||||
|
||||
def _load_video_from_path_decord(self, video_path, height=None, width=None, start_time=None, end_time=None, fps=-1):
|
||||
def _load_video_from_path_decord(
|
||||
self,
|
||||
video_path,
|
||||
height=None,
|
||||
width=None,
|
||||
start_time=None,
|
||||
end_time=None,
|
||||
fps=-1,
|
||||
):
|
||||
try:
|
||||
if not height or not width:
|
||||
vr = VideoReader(video_path)
|
||||
@ -83,26 +99,36 @@ class VideoDataset(Dataset):
|
||||
vlen = len(vr)
|
||||
|
||||
if start_time or end_time:
|
||||
assert fps > 0, 'must provide video fps if specifying start and end time.'
|
||||
assert (
|
||||
fps > 0
|
||||
), "must provide video fps if specifying start and end time."
|
||||
|
||||
start_idx = min(int(start_time * fps), vlen)
|
||||
end_idx = min(int(end_time * fps), vlen)
|
||||
else:
|
||||
start_idx, end_idx = 0, vlen
|
||||
|
||||
if self.frm_sampling_strategy == 'uniform':
|
||||
frame_indices = np.arange(start_idx, end_idx, vlen / self.num_frm, dtype=int)
|
||||
elif self.frm_sampling_strategy == 'rand':
|
||||
if self.frm_sampling_strategy == "uniform":
|
||||
frame_indices = np.arange(
|
||||
start_idx, end_idx, vlen / self.num_frm, dtype=int
|
||||
)
|
||||
elif self.frm_sampling_strategy == "rand":
|
||||
frame_indices = sorted(random.sample(range(vlen), self.num_frm))
|
||||
elif self.frm_sampling_strategy == 'headtail':
|
||||
frame_indices_head = sorted(random.sample(range(vlen // 2), self.num_frm // 2))
|
||||
frame_indices_tail = sorted(random.sample(range(vlen // 2, vlen), self.num_frm // 2))
|
||||
elif self.frm_sampling_strategy == "headtail":
|
||||
frame_indices_head = sorted(
|
||||
random.sample(range(vlen // 2), self.num_frm // 2)
|
||||
)
|
||||
frame_indices_tail = sorted(
|
||||
random.sample(range(vlen // 2, vlen), self.num_frm // 2)
|
||||
)
|
||||
frame_indices = frame_indices_head + frame_indices_tail
|
||||
else:
|
||||
raise NotImplementedError('Invalid sampling strategy {} '.format(self.frm_sampling_strategy))
|
||||
raise NotImplementedError(
|
||||
"Invalid sampling strategy {} ".format(self.frm_sampling_strategy)
|
||||
)
|
||||
|
||||
raw_sample_frms = vr.get_batch(frame_indices)
|
||||
except Exception as e:
|
||||
except Exception:
|
||||
return None
|
||||
|
||||
raw_sample_frms = raw_sample_frms.permute(0, 3, 1, 2)
|
||||
|
||||
@ -1,6 +1,5 @@
|
||||
import os
|
||||
import json
|
||||
import random
|
||||
from PIL import Image
|
||||
|
||||
import torch
|
||||
@ -9,80 +8,99 @@ from data.utils import pre_question
|
||||
|
||||
from torchvision.datasets.utils import download_url
|
||||
|
||||
|
||||
class vqa_dataset(Dataset):
|
||||
def __init__(self, transform, ann_root, vqa_root, vg_root, train_files=[], split="train"):
|
||||
self.split = split
|
||||
def __init__(
|
||||
self, transform, ann_root, vqa_root, vg_root, train_files=[], split="train"
|
||||
):
|
||||
self.split = split
|
||||
|
||||
self.transform = transform
|
||||
self.vqa_root = vqa_root
|
||||
self.vg_root = vg_root
|
||||
|
||||
if split=='train':
|
||||
urls = {'vqa_train':'https://storage.googleapis.com/sfr-vision-language-research/datasets/vqa_train.json',
|
||||
'vqa_val':'https://storage.googleapis.com/sfr-vision-language-research/datasets/vqa_val.json',
|
||||
'vg_qa':'https://storage.googleapis.com/sfr-vision-language-research/datasets/vg_qa.json'}
|
||||
|
||||
|
||||
if split == "train":
|
||||
urls = {
|
||||
"vqa_train": "https://storage.googleapis.com/sfr-vision-language-research/datasets/vqa_train.json",
|
||||
"vqa_val": "https://storage.googleapis.com/sfr-vision-language-research/datasets/vqa_val.json",
|
||||
"vg_qa": "https://storage.googleapis.com/sfr-vision-language-research/datasets/vg_qa.json",
|
||||
}
|
||||
|
||||
self.annotation = []
|
||||
for f in train_files:
|
||||
download_url(urls[f],ann_root)
|
||||
self.annotation += json.load(open(os.path.join(ann_root,'%s.json'%f),'r'))
|
||||
download_url(urls[f], ann_root)
|
||||
self.annotation += json.load(
|
||||
open(os.path.join(ann_root, "%s.json" % f), "r")
|
||||
)
|
||||
else:
|
||||
download_url('https://storage.googleapis.com/sfr-vision-language-research/datasets/vqa_test.json',ann_root)
|
||||
self.annotation = json.load(open(os.path.join(ann_root,'vqa_test.json'),'r'))
|
||||
|
||||
download_url('https://storage.googleapis.com/sfr-vision-language-research/datasets/answer_list.json',ann_root)
|
||||
self.answer_list = json.load(open(os.path.join(ann_root,'answer_list.json'),'r'))
|
||||
|
||||
|
||||
download_url(
|
||||
"https://storage.googleapis.com/sfr-vision-language-research/datasets/vqa_test.json",
|
||||
ann_root,
|
||||
)
|
||||
self.annotation = json.load(
|
||||
open(os.path.join(ann_root, "vqa_test.json"), "r")
|
||||
)
|
||||
|
||||
download_url(
|
||||
"https://storage.googleapis.com/sfr-vision-language-research/datasets/answer_list.json",
|
||||
ann_root,
|
||||
)
|
||||
self.answer_list = json.load(
|
||||
open(os.path.join(ann_root, "answer_list.json"), "r")
|
||||
)
|
||||
|
||||
def __len__(self):
|
||||
return len(self.annotation)
|
||||
|
||||
def __getitem__(self, index):
|
||||
|
||||
|
||||
def __getitem__(self, index):
|
||||
ann = self.annotation[index]
|
||||
|
||||
if ann['dataset']=='vqa':
|
||||
image_path = os.path.join(self.vqa_root,ann['image'])
|
||||
elif ann['dataset']=='vg':
|
||||
image_path = os.path.join(self.vg_root,ann['image'])
|
||||
|
||||
image = Image.open(image_path).convert('RGB')
|
||||
image = self.transform(image)
|
||||
|
||||
if self.split == 'test':
|
||||
question = pre_question(ann['question'])
|
||||
question_id = ann['question_id']
|
||||
|
||||
if ann["dataset"] == "vqa":
|
||||
image_path = os.path.join(self.vqa_root, ann["image"])
|
||||
elif ann["dataset"] == "vg":
|
||||
image_path = os.path.join(self.vg_root, ann["image"])
|
||||
|
||||
image = Image.open(image_path).convert("RGB")
|
||||
image = self.transform(image)
|
||||
|
||||
if self.split == "test":
|
||||
question = pre_question(ann["question"])
|
||||
question_id = ann["question_id"]
|
||||
return image, question, question_id
|
||||
|
||||
elif self.split == "train":
|
||||
question = pre_question(ann["question"])
|
||||
|
||||
elif self.split=='train':
|
||||
|
||||
question = pre_question(ann['question'])
|
||||
|
||||
if ann['dataset']=='vqa':
|
||||
if ann["dataset"] == "vqa":
|
||||
answer_weight = {}
|
||||
for answer in ann['answer']:
|
||||
for answer in ann["answer"]:
|
||||
if answer in answer_weight.keys():
|
||||
answer_weight[answer] += 1/len(ann['answer'])
|
||||
answer_weight[answer] += 1 / len(ann["answer"])
|
||||
else:
|
||||
answer_weight[answer] = 1/len(ann['answer'])
|
||||
answer_weight[answer] = 1 / len(ann["answer"])
|
||||
|
||||
answers = list(answer_weight.keys())
|
||||
weights = list(answer_weight.values())
|
||||
|
||||
elif ann['dataset']=='vg':
|
||||
answers = [ann['answer']]
|
||||
weights = [0.2]
|
||||
elif ann["dataset"] == "vg":
|
||||
answers = [ann["answer"]]
|
||||
weights = [0.2]
|
||||
|
||||
return image, question, answers, weights
|
||||
|
||||
|
||||
|
||||
|
||||
def vqa_collate_fn(batch):
|
||||
image_list, question_list, answer_list, weight_list, n = [], [], [], [], []
|
||||
for image, question, answer, weights in batch:
|
||||
image_list.append(image)
|
||||
question_list.append(question)
|
||||
weight_list += weights
|
||||
weight_list += weights
|
||||
answer_list += answer
|
||||
n.append(len(answer))
|
||||
return torch.stack(image_list,dim=0), question_list, answer_list, torch.Tensor(weight_list), n
|
||||
return (
|
||||
torch.stack(image_list, dim=0),
|
||||
question_list,
|
||||
answer_list,
|
||||
torch.Tensor(weight_list),
|
||||
n,
|
||||
)
|
||||
|
||||
@ -1 +0,0 @@
|
||||
from ldm.devices.devices import choose_autocast_device, choose_torch_device
|
||||
@ -1,24 +1,26 @@
|
||||
import torch
|
||||
from torch import autocast
|
||||
from contextlib import contextmanager, nullcontext
|
||||
from contextlib import nullcontext
|
||||
|
||||
|
||||
def choose_torch_device() -> str:
|
||||
'''Convenience routine for guessing which GPU device to run model on'''
|
||||
"""Convenience routine for guessing which GPU device to run model on"""
|
||||
if torch.cuda.is_available():
|
||||
return 'cuda'
|
||||
if hasattr(torch.backends, 'mps') and torch.backends.mps.is_available():
|
||||
return 'mps'
|
||||
return 'cpu'
|
||||
return "cuda"
|
||||
if hasattr(torch.backends, "mps") and torch.backends.mps.is_available():
|
||||
return "mps"
|
||||
return "cpu"
|
||||
|
||||
|
||||
def choose_autocast_device(device):
|
||||
'''Returns an autocast compatible device from a torch device'''
|
||||
device_type = device.type # this returns 'mps' on M1
|
||||
"""Returns an autocast compatible device from a torch device"""
|
||||
device_type = device.type # this returns 'mps' on M1
|
||||
# autocast only for cuda, but GTX 16xx have issues with it
|
||||
if device_type == 'cuda':
|
||||
if device_type == "cuda":
|
||||
device_name = torch.cuda.get_device_name()
|
||||
if 'GeForce GTX 1660' in device_name or 'GeForce GTX 1650' in device_name:
|
||||
return device_type,nullcontext
|
||||
if "GeForce GTX 1660" in device_name or "GeForce GTX 1650" in device_name:
|
||||
return device_type, nullcontext
|
||||
else:
|
||||
return device_type,autocast
|
||||
return device_type, autocast
|
||||
else:
|
||||
return 'cpu',nullcontext
|
||||
return "cpu", nullcontext
|
||||
|
||||
@ -5,32 +5,47 @@ class LambdaWarmUpCosineScheduler:
|
||||
"""
|
||||
note: use with a base_lr of 1.0
|
||||
"""
|
||||
def __init__(self, warm_up_steps, lr_min, lr_max, lr_start, max_decay_steps, verbosity_interval=0):
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
warm_up_steps,
|
||||
lr_min,
|
||||
lr_max,
|
||||
lr_start,
|
||||
max_decay_steps,
|
||||
verbosity_interval=0,
|
||||
):
|
||||
self.lr_warm_up_steps = warm_up_steps
|
||||
self.lr_start = lr_start
|
||||
self.lr_min = lr_min
|
||||
self.lr_max = lr_max
|
||||
self.lr_max_decay_steps = max_decay_steps
|
||||
self.last_lr = 0.
|
||||
self.last_lr = 0.0
|
||||
self.verbosity_interval = verbosity_interval
|
||||
|
||||
def schedule(self, n, **kwargs):
|
||||
if self.verbosity_interval > 0:
|
||||
if n % self.verbosity_interval == 0: print(f"current step: {n}, recent lr-multiplier: {self.last_lr}")
|
||||
if n % self.verbosity_interval == 0:
|
||||
print(f"current step: {n}, recent lr-multiplier: {self.last_lr}")
|
||||
if n < self.lr_warm_up_steps:
|
||||
lr = (self.lr_max - self.lr_start) / self.lr_warm_up_steps * n + self.lr_start
|
||||
lr = (
|
||||
self.lr_max - self.lr_start
|
||||
) / self.lr_warm_up_steps * n + self.lr_start
|
||||
self.last_lr = lr
|
||||
return lr
|
||||
else:
|
||||
t = (n - self.lr_warm_up_steps) / (self.lr_max_decay_steps - self.lr_warm_up_steps)
|
||||
t = (n - self.lr_warm_up_steps) / (
|
||||
self.lr_max_decay_steps - self.lr_warm_up_steps
|
||||
)
|
||||
t = min(t, 1.0)
|
||||
lr = self.lr_min + 0.5 * (self.lr_max - self.lr_min) * (
|
||||
1 + np.cos(t * np.pi))
|
||||
1 + np.cos(t * np.pi)
|
||||
)
|
||||
self.last_lr = lr
|
||||
return lr
|
||||
|
||||
def __call__(self, n, **kwargs):
|
||||
return self.schedule(n,**kwargs)
|
||||
return self.schedule(n, **kwargs)
|
||||
|
||||
|
||||
class LambdaWarmUpCosineScheduler2:
|
||||
@ -38,15 +53,24 @@ class LambdaWarmUpCosineScheduler2:
|
||||
supports repeated iterations, configurable via lists
|
||||
note: use with a base_lr of 1.0.
|
||||
"""
|
||||
def __init__(self, warm_up_steps, f_min, f_max, f_start, cycle_lengths, verbosity_interval=0):
|
||||
assert len(warm_up_steps) == len(f_min) == len(f_max) == len(f_start) == len(cycle_lengths)
|
||||
|
||||
def __init__(
|
||||
self, warm_up_steps, f_min, f_max, f_start, cycle_lengths, verbosity_interval=0
|
||||
):
|
||||
assert (
|
||||
len(warm_up_steps)
|
||||
== len(f_min)
|
||||
== len(f_max)
|
||||
== len(f_start)
|
||||
== len(cycle_lengths)
|
||||
)
|
||||
self.lr_warm_up_steps = warm_up_steps
|
||||
self.f_start = f_start
|
||||
self.f_min = f_min
|
||||
self.f_max = f_max
|
||||
self.cycle_lengths = cycle_lengths
|
||||
self.cum_cycles = np.cumsum([0] + list(self.cycle_lengths))
|
||||
self.last_f = 0.
|
||||
self.last_f = 0.0
|
||||
self.verbosity_interval = verbosity_interval
|
||||
|
||||
def find_in_interval(self, n):
|
||||
@ -60,17 +84,25 @@ class LambdaWarmUpCosineScheduler2:
|
||||
cycle = self.find_in_interval(n)
|
||||
n = n - self.cum_cycles[cycle]
|
||||
if self.verbosity_interval > 0:
|
||||
if n % self.verbosity_interval == 0: print(f"current step: {n}, recent lr-multiplier: {self.last_f}, "
|
||||
f"current cycle {cycle}")
|
||||
if n % self.verbosity_interval == 0:
|
||||
print(
|
||||
f"current step: {n}, recent lr-multiplier: {self.last_f}, "
|
||||
f"current cycle {cycle}"
|
||||
)
|
||||
if n < self.lr_warm_up_steps[cycle]:
|
||||
f = (self.f_max[cycle] - self.f_start[cycle]) / self.lr_warm_up_steps[cycle] * n + self.f_start[cycle]
|
||||
f = (self.f_max[cycle] - self.f_start[cycle]) / self.lr_warm_up_steps[
|
||||
cycle
|
||||
] * n + self.f_start[cycle]
|
||||
self.last_f = f
|
||||
return f
|
||||
else:
|
||||
t = (n - self.lr_warm_up_steps[cycle]) / (self.cycle_lengths[cycle] - self.lr_warm_up_steps[cycle])
|
||||
t = (n - self.lr_warm_up_steps[cycle]) / (
|
||||
self.cycle_lengths[cycle] - self.lr_warm_up_steps[cycle]
|
||||
)
|
||||
t = min(t, 1.0)
|
||||
f = self.f_min[cycle] + 0.5 * (self.f_max[cycle] - self.f_min[cycle]) * (
|
||||
1 + np.cos(t * np.pi))
|
||||
1 + np.cos(t * np.pi)
|
||||
)
|
||||
self.last_f = f
|
||||
return f
|
||||
|
||||
@ -79,20 +111,25 @@ class LambdaWarmUpCosineScheduler2:
|
||||
|
||||
|
||||
class LambdaLinearScheduler(LambdaWarmUpCosineScheduler2):
|
||||
|
||||
def schedule(self, n, **kwargs):
|
||||
cycle = self.find_in_interval(n)
|
||||
n = n - self.cum_cycles[cycle]
|
||||
if self.verbosity_interval > 0:
|
||||
if n % self.verbosity_interval == 0: print(f"current step: {n}, recent lr-multiplier: {self.last_f}, "
|
||||
f"current cycle {cycle}")
|
||||
if n % self.verbosity_interval == 0:
|
||||
print(
|
||||
f"current step: {n}, recent lr-multiplier: {self.last_f}, "
|
||||
f"current cycle {cycle}"
|
||||
)
|
||||
|
||||
if n < self.lr_warm_up_steps[cycle]:
|
||||
f = (self.f_max[cycle] - self.f_start[cycle]) / self.lr_warm_up_steps[cycle] * n + self.f_start[cycle]
|
||||
f = (self.f_max[cycle] - self.f_start[cycle]) / self.lr_warm_up_steps[
|
||||
cycle
|
||||
] * n + self.f_start[cycle]
|
||||
self.last_f = f
|
||||
return f
|
||||
else:
|
||||
f = self.f_min[cycle] + (self.f_max[cycle] - self.f_min[cycle]) * (self.cycle_lengths[cycle] - n) / (self.cycle_lengths[cycle])
|
||||
f = self.f_min[cycle] + (self.f_max[cycle] - self.f_min[cycle]) * (
|
||||
self.cycle_lengths[cycle] - n
|
||||
) / (self.cycle_lengths[cycle])
|
||||
self.last_f = f
|
||||
return f
|
||||
|
||||
|
||||
@ -12,23 +12,24 @@ from ldm.util import instantiate_from_config
|
||||
|
||||
|
||||
class VQModel(pl.LightningModule):
|
||||
def __init__(self,
|
||||
ddconfig,
|
||||
lossconfig,
|
||||
n_embed,
|
||||
embed_dim,
|
||||
ckpt_path=None,
|
||||
ignore_keys=[],
|
||||
image_key="image",
|
||||
colorize_nlabels=None,
|
||||
monitor=None,
|
||||
batch_resize_range=None,
|
||||
scheduler_config=None,
|
||||
lr_g_factor=1.0,
|
||||
remap=None,
|
||||
sane_index_shape=False, # tell vector quantizer to return indices as bhw
|
||||
use_ema=False
|
||||
):
|
||||
def __init__(
|
||||
self,
|
||||
ddconfig,
|
||||
lossconfig,
|
||||
n_embed,
|
||||
embed_dim,
|
||||
ckpt_path=None,
|
||||
ignore_keys=[],
|
||||
image_key="image",
|
||||
colorize_nlabels=None,
|
||||
monitor=None,
|
||||
batch_resize_range=None,
|
||||
scheduler_config=None,
|
||||
lr_g_factor=1.0,
|
||||
remap=None,
|
||||
sane_index_shape=False, # tell vector quantizer to return indices as bhw
|
||||
use_ema=False,
|
||||
):
|
||||
super().__init__()
|
||||
self.embed_dim = embed_dim
|
||||
self.n_embed = n_embed
|
||||
@ -36,19 +37,25 @@ class VQModel(pl.LightningModule):
|
||||
self.encoder = Encoder(**ddconfig)
|
||||
self.decoder = Decoder(**ddconfig)
|
||||
self.loss = instantiate_from_config(lossconfig)
|
||||
self.quantize = VectorQuantizer(n_embed, embed_dim, beta=0.25,
|
||||
remap=remap,
|
||||
sane_index_shape=sane_index_shape)
|
||||
self.quantize = VectorQuantizer(
|
||||
n_embed,
|
||||
embed_dim,
|
||||
beta=0.25,
|
||||
remap=remap,
|
||||
sane_index_shape=sane_index_shape,
|
||||
)
|
||||
self.quant_conv = torch.nn.Conv2d(ddconfig["z_channels"], embed_dim, 1)
|
||||
self.post_quant_conv = torch.nn.Conv2d(embed_dim, ddconfig["z_channels"], 1)
|
||||
if colorize_nlabels is not None:
|
||||
assert type(colorize_nlabels)==int
|
||||
assert type(colorize_nlabels) == int
|
||||
self.register_buffer("colorize", torch.randn(3, colorize_nlabels, 1, 1))
|
||||
if monitor is not None:
|
||||
self.monitor = monitor
|
||||
self.batch_resize_range = batch_resize_range
|
||||
if self.batch_resize_range is not None:
|
||||
print(f"{self.__class__.__name__}: Using per-batch resizing in range {batch_resize_range}.")
|
||||
print(
|
||||
f"{self.__class__.__name__}: Using per-batch resizing in range {batch_resize_range}."
|
||||
)
|
||||
|
||||
self.use_ema = use_ema
|
||||
if self.use_ema:
|
||||
@ -84,7 +91,9 @@ class VQModel(pl.LightningModule):
|
||||
print("Deleting key {} from state_dict.".format(k))
|
||||
del sd[k]
|
||||
missing, unexpected = self.load_state_dict(sd, strict=False)
|
||||
print(f"Restored from {path} with {len(missing)} missing and {len(unexpected)} unexpected keys")
|
||||
print(
|
||||
f"Restored from {path} with {len(missing)} missing and {len(unexpected)} unexpected keys"
|
||||
)
|
||||
if len(missing) > 0:
|
||||
print(f"Missing Keys: {missing}")
|
||||
print(f"Unexpected Keys: {unexpected}")
|
||||
@ -115,7 +124,7 @@ class VQModel(pl.LightningModule):
|
||||
return dec
|
||||
|
||||
def forward(self, input, return_pred_indices=False):
|
||||
quant, diff, (_,_,ind) = self.encode(input)
|
||||
quant, diff, (_, _, ind) = self.encode(input)
|
||||
dec = self.decode(quant)
|
||||
if return_pred_indices:
|
||||
return dec, diff, ind
|
||||
@ -133,7 +142,9 @@ class VQModel(pl.LightningModule):
|
||||
# do the first few batches with max size to avoid later oom
|
||||
new_resize = upper_size
|
||||
else:
|
||||
new_resize = np.random.choice(np.arange(lower_size, upper_size+16, 16))
|
||||
new_resize = np.random.choice(
|
||||
np.arange(lower_size, upper_size + 16, 16)
|
||||
)
|
||||
if new_resize != x.shape[2]:
|
||||
x = F.interpolate(x, size=new_resize, mode="bicubic")
|
||||
x = x.detach()
|
||||
@ -147,48 +158,88 @@ class VQModel(pl.LightningModule):
|
||||
|
||||
if optimizer_idx == 0:
|
||||
# autoencode
|
||||
aeloss, log_dict_ae = self.loss(qloss, x, xrec, optimizer_idx, self.global_step,
|
||||
last_layer=self.get_last_layer(), split="train",
|
||||
predicted_indices=ind)
|
||||
aeloss, log_dict_ae = self.loss(
|
||||
qloss,
|
||||
x,
|
||||
xrec,
|
||||
optimizer_idx,
|
||||
self.global_step,
|
||||
last_layer=self.get_last_layer(),
|
||||
split="train",
|
||||
predicted_indices=ind,
|
||||
)
|
||||
|
||||
self.log_dict(log_dict_ae, prog_bar=False, logger=True, on_step=True, on_epoch=True)
|
||||
self.log_dict(
|
||||
log_dict_ae, prog_bar=False, logger=True, on_step=True, on_epoch=True
|
||||
)
|
||||
return aeloss
|
||||
|
||||
if optimizer_idx == 1:
|
||||
# discriminator
|
||||
discloss, log_dict_disc = self.loss(qloss, x, xrec, optimizer_idx, self.global_step,
|
||||
last_layer=self.get_last_layer(), split="train")
|
||||
self.log_dict(log_dict_disc, prog_bar=False, logger=True, on_step=True, on_epoch=True)
|
||||
discloss, log_dict_disc = self.loss(
|
||||
qloss,
|
||||
x,
|
||||
xrec,
|
||||
optimizer_idx,
|
||||
self.global_step,
|
||||
last_layer=self.get_last_layer(),
|
||||
split="train",
|
||||
)
|
||||
self.log_dict(
|
||||
log_dict_disc, prog_bar=False, logger=True, on_step=True, on_epoch=True
|
||||
)
|
||||
return discloss
|
||||
|
||||
def validation_step(self, batch, batch_idx):
|
||||
log_dict = self._validation_step(batch, batch_idx)
|
||||
with self.ema_scope():
|
||||
log_dict_ema = self._validation_step(batch, batch_idx, suffix="_ema")
|
||||
self._validation_step(batch, batch_idx, suffix="_ema")
|
||||
return log_dict
|
||||
|
||||
def _validation_step(self, batch, batch_idx, suffix=""):
|
||||
x = self.get_input(batch, self.image_key)
|
||||
xrec, qloss, ind = self(x, return_pred_indices=True)
|
||||
aeloss, log_dict_ae = self.loss(qloss, x, xrec, 0,
|
||||
self.global_step,
|
||||
last_layer=self.get_last_layer(),
|
||||
split="val"+suffix,
|
||||
predicted_indices=ind
|
||||
)
|
||||
aeloss, log_dict_ae = self.loss(
|
||||
qloss,
|
||||
x,
|
||||
xrec,
|
||||
0,
|
||||
self.global_step,
|
||||
last_layer=self.get_last_layer(),
|
||||
split="val" + suffix,
|
||||
predicted_indices=ind,
|
||||
)
|
||||
|
||||
discloss, log_dict_disc = self.loss(qloss, x, xrec, 1,
|
||||
self.global_step,
|
||||
last_layer=self.get_last_layer(),
|
||||
split="val"+suffix,
|
||||
predicted_indices=ind
|
||||
)
|
||||
discloss, log_dict_disc = self.loss(
|
||||
qloss,
|
||||
x,
|
||||
xrec,
|
||||
1,
|
||||
self.global_step,
|
||||
last_layer=self.get_last_layer(),
|
||||
split="val" + suffix,
|
||||
predicted_indices=ind,
|
||||
)
|
||||
rec_loss = log_dict_ae[f"val{suffix}/rec_loss"]
|
||||
self.log(f"val{suffix}/rec_loss", rec_loss,
|
||||
prog_bar=True, logger=True, on_step=False, on_epoch=True, sync_dist=True)
|
||||
self.log(f"val{suffix}/aeloss", aeloss,
|
||||
prog_bar=True, logger=True, on_step=False, on_epoch=True, sync_dist=True)
|
||||
if version.parse(pl.__version__) >= version.parse('1.4.0'):
|
||||
self.log(
|
||||
f"val{suffix}/rec_loss",
|
||||
rec_loss,
|
||||
prog_bar=True,
|
||||
logger=True,
|
||||
on_step=False,
|
||||
on_epoch=True,
|
||||
sync_dist=True,
|
||||
)
|
||||
self.log(
|
||||
f"val{suffix}/aeloss",
|
||||
aeloss,
|
||||
prog_bar=True,
|
||||
logger=True,
|
||||
on_step=False,
|
||||
on_epoch=True,
|
||||
sync_dist=True,
|
||||
)
|
||||
if version.parse(pl.__version__) >= version.parse("1.4.0"):
|
||||
del log_dict_ae[f"val{suffix}/rec_loss"]
|
||||
self.log_dict(log_dict_ae)
|
||||
self.log_dict(log_dict_disc)
|
||||
@ -196,17 +247,21 @@ class VQModel(pl.LightningModule):
|
||||
|
||||
def configure_optimizers(self):
|
||||
lr_d = self.learning_rate
|
||||
lr_g = self.lr_g_factor*self.learning_rate
|
||||
lr_g = self.lr_g_factor * self.learning_rate
|
||||
print("lr_d", lr_d)
|
||||
print("lr_g", lr_g)
|
||||
opt_ae = torch.optim.Adam(list(self.encoder.parameters())+
|
||||
list(self.decoder.parameters())+
|
||||
list(self.quantize.parameters())+
|
||||
list(self.quant_conv.parameters())+
|
||||
list(self.post_quant_conv.parameters()),
|
||||
lr=lr_g, betas=(0.5, 0.9))
|
||||
opt_disc = torch.optim.Adam(self.loss.discriminator.parameters(),
|
||||
lr=lr_d, betas=(0.5, 0.9))
|
||||
opt_ae = torch.optim.Adam(
|
||||
list(self.encoder.parameters())
|
||||
+ list(self.decoder.parameters())
|
||||
+ list(self.quantize.parameters())
|
||||
+ list(self.quant_conv.parameters())
|
||||
+ list(self.post_quant_conv.parameters()),
|
||||
lr=lr_g,
|
||||
betas=(0.5, 0.9),
|
||||
)
|
||||
opt_disc = torch.optim.Adam(
|
||||
self.loss.discriminator.parameters(), lr=lr_d, betas=(0.5, 0.9)
|
||||
)
|
||||
|
||||
if self.scheduler_config is not None:
|
||||
scheduler = instantiate_from_config(self.scheduler_config)
|
||||
@ -214,14 +269,14 @@ class VQModel(pl.LightningModule):
|
||||
print("Setting up LambdaLR scheduler...")
|
||||
scheduler = [
|
||||
{
|
||||
'scheduler': LambdaLR(opt_ae, lr_lambda=scheduler.schedule),
|
||||
'interval': 'step',
|
||||
'frequency': 1
|
||||
"scheduler": LambdaLR(opt_ae, lr_lambda=scheduler.schedule),
|
||||
"interval": "step",
|
||||
"frequency": 1,
|
||||
},
|
||||
{
|
||||
'scheduler': LambdaLR(opt_disc, lr_lambda=scheduler.schedule),
|
||||
'interval': 'step',
|
||||
'frequency': 1
|
||||
"scheduler": LambdaLR(opt_disc, lr_lambda=scheduler.schedule),
|
||||
"interval": "step",
|
||||
"frequency": 1,
|
||||
},
|
||||
]
|
||||
return [opt_ae, opt_disc], scheduler
|
||||
@ -248,7 +303,8 @@ class VQModel(pl.LightningModule):
|
||||
if plot_ema:
|
||||
with self.ema_scope():
|
||||
xrec_ema, _ = self(x)
|
||||
if x.shape[1] > 3: xrec_ema = self.to_rgb(xrec_ema)
|
||||
if x.shape[1] > 3:
|
||||
xrec_ema = self.to_rgb(xrec_ema)
|
||||
log["reconstructions_ema"] = xrec_ema
|
||||
return log
|
||||
|
||||
@ -257,7 +313,7 @@ class VQModel(pl.LightningModule):
|
||||
if not hasattr(self, "colorize"):
|
||||
self.register_buffer("colorize", torch.randn(3, x.shape[1], 1, 1).to(x))
|
||||
x = F.conv2d(x, weight=self.colorize)
|
||||
x = 2.*(x-x.min())/(x.max()-x.min()) - 1.
|
||||
x = 2.0 * (x - x.min()) / (x.max() - x.min()) - 1.0
|
||||
return x
|
||||
|
||||
|
||||
@ -283,27 +339,28 @@ class VQModelInterface(VQModel):
|
||||
|
||||
|
||||
class AutoencoderKL(pl.LightningModule):
|
||||
def __init__(self,
|
||||
ddconfig,
|
||||
lossconfig,
|
||||
embed_dim,
|
||||
ckpt_path=None,
|
||||
ignore_keys=[],
|
||||
image_key="image",
|
||||
colorize_nlabels=None,
|
||||
monitor=None,
|
||||
):
|
||||
def __init__(
|
||||
self,
|
||||
ddconfig,
|
||||
lossconfig,
|
||||
embed_dim,
|
||||
ckpt_path=None,
|
||||
ignore_keys=[],
|
||||
image_key="image",
|
||||
colorize_nlabels=None,
|
||||
monitor=None,
|
||||
):
|
||||
super().__init__()
|
||||
self.image_key = image_key
|
||||
self.encoder = Encoder(**ddconfig)
|
||||
self.decoder = Decoder(**ddconfig)
|
||||
self.loss = instantiate_from_config(lossconfig)
|
||||
assert ddconfig["double_z"]
|
||||
self.quant_conv = torch.nn.Conv2d(2*ddconfig["z_channels"], 2*embed_dim, 1)
|
||||
self.quant_conv = torch.nn.Conv2d(2 * ddconfig["z_channels"], 2 * embed_dim, 1)
|
||||
self.post_quant_conv = torch.nn.Conv2d(embed_dim, ddconfig["z_channels"], 1)
|
||||
self.embed_dim = embed_dim
|
||||
if colorize_nlabels is not None:
|
||||
assert type(colorize_nlabels)==int
|
||||
assert type(colorize_nlabels) == int
|
||||
self.register_buffer("colorize", torch.randn(3, colorize_nlabels, 1, 1))
|
||||
if monitor is not None:
|
||||
self.monitor = monitor
|
||||
@ -354,29 +411,75 @@ class AutoencoderKL(pl.LightningModule):
|
||||
|
||||
if optimizer_idx == 0:
|
||||
# train encoder+decoder+logvar
|
||||
aeloss, log_dict_ae = self.loss(inputs, reconstructions, posterior, optimizer_idx, self.global_step,
|
||||
last_layer=self.get_last_layer(), split="train")
|
||||
self.log("aeloss", aeloss, prog_bar=True, logger=True, on_step=True, on_epoch=True)
|
||||
self.log_dict(log_dict_ae, prog_bar=False, logger=True, on_step=True, on_epoch=False)
|
||||
aeloss, log_dict_ae = self.loss(
|
||||
inputs,
|
||||
reconstructions,
|
||||
posterior,
|
||||
optimizer_idx,
|
||||
self.global_step,
|
||||
last_layer=self.get_last_layer(),
|
||||
split="train",
|
||||
)
|
||||
self.log(
|
||||
"aeloss",
|
||||
aeloss,
|
||||
prog_bar=True,
|
||||
logger=True,
|
||||
on_step=True,
|
||||
on_epoch=True,
|
||||
)
|
||||
self.log_dict(
|
||||
log_dict_ae, prog_bar=False, logger=True, on_step=True, on_epoch=False
|
||||
)
|
||||
return aeloss
|
||||
|
||||
if optimizer_idx == 1:
|
||||
# train the discriminator
|
||||
discloss, log_dict_disc = self.loss(inputs, reconstructions, posterior, optimizer_idx, self.global_step,
|
||||
last_layer=self.get_last_layer(), split="train")
|
||||
discloss, log_dict_disc = self.loss(
|
||||
inputs,
|
||||
reconstructions,
|
||||
posterior,
|
||||
optimizer_idx,
|
||||
self.global_step,
|
||||
last_layer=self.get_last_layer(),
|
||||
split="train",
|
||||
)
|
||||
|
||||
self.log("discloss", discloss, prog_bar=True, logger=True, on_step=True, on_epoch=True)
|
||||
self.log_dict(log_dict_disc, prog_bar=False, logger=True, on_step=True, on_epoch=False)
|
||||
self.log(
|
||||
"discloss",
|
||||
discloss,
|
||||
prog_bar=True,
|
||||
logger=True,
|
||||
on_step=True,
|
||||
on_epoch=True,
|
||||
)
|
||||
self.log_dict(
|
||||
log_dict_disc, prog_bar=False, logger=True, on_step=True, on_epoch=False
|
||||
)
|
||||
return discloss
|
||||
|
||||
def validation_step(self, batch, batch_idx):
|
||||
inputs = self.get_input(batch, self.image_key)
|
||||
reconstructions, posterior = self(inputs)
|
||||
aeloss, log_dict_ae = self.loss(inputs, reconstructions, posterior, 0, self.global_step,
|
||||
last_layer=self.get_last_layer(), split="val")
|
||||
aeloss, log_dict_ae = self.loss(
|
||||
inputs,
|
||||
reconstructions,
|
||||
posterior,
|
||||
0,
|
||||
self.global_step,
|
||||
last_layer=self.get_last_layer(),
|
||||
split="val",
|
||||
)
|
||||
|
||||
discloss, log_dict_disc = self.loss(inputs, reconstructions, posterior, 1, self.global_step,
|
||||
last_layer=self.get_last_layer(), split="val")
|
||||
discloss, log_dict_disc = self.loss(
|
||||
inputs,
|
||||
reconstructions,
|
||||
posterior,
|
||||
1,
|
||||
self.global_step,
|
||||
last_layer=self.get_last_layer(),
|
||||
split="val",
|
||||
)
|
||||
|
||||
self.log("val/rec_loss", log_dict_ae["val/rec_loss"])
|
||||
self.log_dict(log_dict_ae)
|
||||
@ -385,13 +488,17 @@ class AutoencoderKL(pl.LightningModule):
|
||||
|
||||
def configure_optimizers(self):
|
||||
lr = self.learning_rate
|
||||
opt_ae = torch.optim.Adam(list(self.encoder.parameters())+
|
||||
list(self.decoder.parameters())+
|
||||
list(self.quant_conv.parameters())+
|
||||
list(self.post_quant_conv.parameters()),
|
||||
lr=lr, betas=(0.5, 0.9))
|
||||
opt_disc = torch.optim.Adam(self.loss.discriminator.parameters(),
|
||||
lr=lr, betas=(0.5, 0.9))
|
||||
opt_ae = torch.optim.Adam(
|
||||
list(self.encoder.parameters())
|
||||
+ list(self.decoder.parameters())
|
||||
+ list(self.quant_conv.parameters())
|
||||
+ list(self.post_quant_conv.parameters()),
|
||||
lr=lr,
|
||||
betas=(0.5, 0.9),
|
||||
)
|
||||
opt_disc = torch.optim.Adam(
|
||||
self.loss.discriminator.parameters(), lr=lr, betas=(0.5, 0.9)
|
||||
)
|
||||
return [opt_ae, opt_disc], []
|
||||
|
||||
def get_last_layer(self):
|
||||
@ -419,7 +526,7 @@ class AutoencoderKL(pl.LightningModule):
|
||||
if not hasattr(self, "colorize"):
|
||||
self.register_buffer("colorize", torch.randn(3, x.shape[1], 1, 1).to(x))
|
||||
x = F.conv2d(x, weight=self.colorize)
|
||||
x = 2.*(x-x.min())/(x.max()-x.min()) - 1.
|
||||
x = 2.0 * (x - x.min()) / (x.max() - x.min()) - 1.0
|
||||
return x
|
||||
|
||||
|
||||
|
||||
@ -1,11 +1,12 @@
|
||||
'''
|
||||
"""
|
||||
* Copyright (c) 2022, salesforce.com, inc.
|
||||
* All rights reserved.
|
||||
* SPDX-License-Identifier: BSD-3-Clause
|
||||
* For full license text, see LICENSE.txt file in the repo root or https://opensource.org/licenses/BSD-3-Clause
|
||||
* By Junnan Li
|
||||
'''
|
||||
"""
|
||||
import warnings
|
||||
|
||||
warnings.filterwarnings("ignore")
|
||||
|
||||
from .vit import VisionTransformer, interpolate_pos_embed
|
||||
@ -14,225 +15,291 @@ from transformers import BertTokenizer
|
||||
|
||||
import torch
|
||||
from torch import nn
|
||||
#import torch.nn.functional as F
|
||||
|
||||
# import torch.nn.functional as F
|
||||
|
||||
import os
|
||||
from urllib.parse import urlparse
|
||||
from timm.models.hub import download_cached_file
|
||||
|
||||
|
||||
class BLIP_Base(nn.Module):
|
||||
def __init__(self,
|
||||
med_config = 'configs/blip/med_config.json',
|
||||
image_size = 224,
|
||||
vit = 'base',
|
||||
vit_grad_ckpt = False,
|
||||
vit_ckpt_layer = 0,
|
||||
):
|
||||
def __init__(
|
||||
self,
|
||||
med_config="configs/blip/med_config.json",
|
||||
image_size=224,
|
||||
vit="base",
|
||||
vit_grad_ckpt=False,
|
||||
vit_ckpt_layer=0,
|
||||
):
|
||||
"""
|
||||
Args:
|
||||
med_config (str): path for the mixture of encoder-decoder model's configuration file
|
||||
image_size (int): input image size
|
||||
vit (str): model size of vision transformer
|
||||
"""
|
||||
"""
|
||||
super().__init__()
|
||||
|
||||
self.visual_encoder, vision_width = create_vit(vit,image_size, vit_grad_ckpt, vit_ckpt_layer)
|
||||
self.tokenizer = init_tokenizer()
|
||||
|
||||
self.visual_encoder, vision_width = create_vit(
|
||||
vit, image_size, vit_grad_ckpt, vit_ckpt_layer
|
||||
)
|
||||
self.tokenizer = init_tokenizer()
|
||||
med_config = BertConfig.from_json_file(med_config)
|
||||
med_config.encoder_width = vision_width
|
||||
self.text_encoder = BertModel(config=med_config, add_pooling_layer=False)
|
||||
self.text_encoder = BertModel(config=med_config, add_pooling_layer=False)
|
||||
|
||||
|
||||
def forward(self, image, caption, mode):
|
||||
|
||||
assert mode in ['image', 'text', 'multimodal'], "mode parameter must be image, text, or multimodal"
|
||||
text = self.tokenizer(caption, return_tensors="pt").to(image.device)
|
||||
|
||||
if mode=='image':
|
||||
assert mode in [
|
||||
"image",
|
||||
"text",
|
||||
"multimodal",
|
||||
], "mode parameter must be image, text, or multimodal"
|
||||
text = self.tokenizer(caption, return_tensors="pt").to(image.device)
|
||||
|
||||
if mode == "image":
|
||||
# return image features
|
||||
image_embeds = self.visual_encoder(image)
|
||||
image_embeds = self.visual_encoder(image)
|
||||
return image_embeds
|
||||
|
||||
elif mode=='text':
|
||||
|
||||
elif mode == "text":
|
||||
# return text features
|
||||
text_output = self.text_encoder(text.input_ids, attention_mask = text.attention_mask,
|
||||
return_dict = True, mode = 'text')
|
||||
text_output = self.text_encoder(
|
||||
text.input_ids,
|
||||
attention_mask=text.attention_mask,
|
||||
return_dict=True,
|
||||
mode="text",
|
||||
)
|
||||
return text_output.last_hidden_state
|
||||
|
||||
elif mode=='multimodal':
|
||||
|
||||
elif mode == "multimodal":
|
||||
# return multimodel features
|
||||
image_embeds = self.visual_encoder(image)
|
||||
image_atts = torch.ones(image_embeds.size()[:-1],dtype=torch.long).to(image.device)
|
||||
|
||||
text.input_ids[:,0] = self.tokenizer.enc_token_id
|
||||
output = self.text_encoder(text.input_ids,
|
||||
attention_mask = text.attention_mask,
|
||||
encoder_hidden_states = image_embeds,
|
||||
encoder_attention_mask = image_atts,
|
||||
return_dict = True,
|
||||
)
|
||||
image_embeds = self.visual_encoder(image)
|
||||
image_atts = torch.ones(image_embeds.size()[:-1], dtype=torch.long).to(
|
||||
image.device
|
||||
)
|
||||
|
||||
text.input_ids[:, 0] = self.tokenizer.enc_token_id
|
||||
output = self.text_encoder(
|
||||
text.input_ids,
|
||||
attention_mask=text.attention_mask,
|
||||
encoder_hidden_states=image_embeds,
|
||||
encoder_attention_mask=image_atts,
|
||||
return_dict=True,
|
||||
)
|
||||
return output.last_hidden_state
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
class BLIP_Decoder(nn.Module):
|
||||
def __init__(self,
|
||||
med_config = 'configs/blip/med_config.json',
|
||||
image_size = 384,
|
||||
vit = 'base',
|
||||
vit_grad_ckpt = False,
|
||||
vit_ckpt_layer = 0,
|
||||
prompt = 'a picture of ',
|
||||
):
|
||||
def __init__(
|
||||
self,
|
||||
med_config="configs/blip/med_config.json",
|
||||
image_size=384,
|
||||
vit="base",
|
||||
vit_grad_ckpt=False,
|
||||
vit_ckpt_layer=0,
|
||||
prompt="a picture of ",
|
||||
):
|
||||
"""
|
||||
Args:
|
||||
med_config (str): path for the mixture of encoder-decoder model's configuration file
|
||||
image_size (int): input image size
|
||||
vit (str): model size of vision transformer
|
||||
"""
|
||||
"""
|
||||
super().__init__()
|
||||
|
||||
self.visual_encoder, vision_width = create_vit(vit,image_size, vit_grad_ckpt, vit_ckpt_layer)
|
||||
self.tokenizer = init_tokenizer()
|
||||
|
||||
self.visual_encoder, vision_width = create_vit(
|
||||
vit, image_size, vit_grad_ckpt, vit_ckpt_layer
|
||||
)
|
||||
self.tokenizer = init_tokenizer()
|
||||
med_config = BertConfig.from_json_file(med_config)
|
||||
med_config.encoder_width = vision_width
|
||||
self.text_decoder = BertLMHeadModel(config=med_config)
|
||||
|
||||
self.prompt = prompt
|
||||
self.prompt_length = len(self.tokenizer(self.prompt).input_ids)-1
|
||||
self.text_decoder = BertLMHeadModel(config=med_config)
|
||||
|
||||
self.prompt = prompt
|
||||
self.prompt_length = len(self.tokenizer(self.prompt).input_ids) - 1
|
||||
|
||||
|
||||
def forward(self, image, caption):
|
||||
|
||||
image_embeds = self.visual_encoder(image)
|
||||
image_atts = torch.ones(image_embeds.size()[:-1],dtype=torch.long).to(image.device)
|
||||
|
||||
text = self.tokenizer(caption, padding='longest', truncation=True, max_length=40, return_tensors="pt").to(image.device)
|
||||
|
||||
text.input_ids[:,0] = self.tokenizer.bos_token_id
|
||||
|
||||
decoder_targets = text.input_ids.masked_fill(text.input_ids == self.tokenizer.pad_token_id, -100)
|
||||
decoder_targets[:,:self.prompt_length] = -100
|
||||
|
||||
decoder_output = self.text_decoder(text.input_ids,
|
||||
attention_mask = text.attention_mask,
|
||||
encoder_hidden_states = image_embeds,
|
||||
encoder_attention_mask = image_atts,
|
||||
labels = decoder_targets,
|
||||
return_dict = True,
|
||||
)
|
||||
image_embeds = self.visual_encoder(image)
|
||||
image_atts = torch.ones(image_embeds.size()[:-1], dtype=torch.long).to(
|
||||
image.device
|
||||
)
|
||||
|
||||
text = self.tokenizer(
|
||||
caption,
|
||||
padding="longest",
|
||||
truncation=True,
|
||||
max_length=40,
|
||||
return_tensors="pt",
|
||||
).to(image.device)
|
||||
|
||||
text.input_ids[:, 0] = self.tokenizer.bos_token_id
|
||||
|
||||
decoder_targets = text.input_ids.masked_fill(
|
||||
text.input_ids == self.tokenizer.pad_token_id, -100
|
||||
)
|
||||
decoder_targets[:, : self.prompt_length] = -100
|
||||
|
||||
decoder_output = self.text_decoder(
|
||||
text.input_ids,
|
||||
attention_mask=text.attention_mask,
|
||||
encoder_hidden_states=image_embeds,
|
||||
encoder_attention_mask=image_atts,
|
||||
labels=decoder_targets,
|
||||
return_dict=True,
|
||||
)
|
||||
loss_lm = decoder_output.loss
|
||||
|
||||
|
||||
return loss_lm
|
||||
|
||||
def generate(self, image, sample=False, num_beams=3, max_length=30, min_length=10, top_p=0.9, repetition_penalty=1.0):
|
||||
|
||||
def generate(
|
||||
self,
|
||||
image,
|
||||
sample=False,
|
||||
num_beams=3,
|
||||
max_length=30,
|
||||
min_length=10,
|
||||
top_p=0.9,
|
||||
repetition_penalty=1.0,
|
||||
):
|
||||
image_embeds = self.visual_encoder(image)
|
||||
|
||||
if not sample:
|
||||
image_embeds = image_embeds.repeat_interleave(num_beams,dim=0)
|
||||
|
||||
image_atts = torch.ones(image_embeds.size()[:-1],dtype=torch.long).to(image.device)
|
||||
model_kwargs = {"encoder_hidden_states": image_embeds, "encoder_attention_mask":image_atts}
|
||||
|
||||
image_embeds = image_embeds.repeat_interleave(num_beams, dim=0)
|
||||
|
||||
image_atts = torch.ones(image_embeds.size()[:-1], dtype=torch.long).to(
|
||||
image.device
|
||||
)
|
||||
model_kwargs = {
|
||||
"encoder_hidden_states": image_embeds,
|
||||
"encoder_attention_mask": image_atts,
|
||||
}
|
||||
|
||||
prompt = [self.prompt] * image.size(0)
|
||||
input_ids = self.tokenizer(prompt, return_tensors="pt").input_ids.to(image.device)
|
||||
input_ids[:,0] = self.tokenizer.bos_token_id
|
||||
input_ids = input_ids[:, :-1]
|
||||
input_ids = self.tokenizer(prompt, return_tensors="pt").input_ids.to(
|
||||
image.device
|
||||
)
|
||||
input_ids[:, 0] = self.tokenizer.bos_token_id
|
||||
input_ids = input_ids[:, :-1]
|
||||
|
||||
if sample:
|
||||
#nucleus sampling
|
||||
outputs = self.text_decoder.generate(input_ids=input_ids,
|
||||
max_length=max_length,
|
||||
min_length=min_length,
|
||||
do_sample=True,
|
||||
top_p=top_p,
|
||||
num_return_sequences=1,
|
||||
eos_token_id=self.tokenizer.sep_token_id,
|
||||
pad_token_id=self.tokenizer.pad_token_id,
|
||||
repetition_penalty=1.1,
|
||||
**model_kwargs)
|
||||
# nucleus sampling
|
||||
outputs = self.text_decoder.generate(
|
||||
input_ids=input_ids,
|
||||
max_length=max_length,
|
||||
min_length=min_length,
|
||||
do_sample=True,
|
||||
top_p=top_p,
|
||||
num_return_sequences=1,
|
||||
eos_token_id=self.tokenizer.sep_token_id,
|
||||
pad_token_id=self.tokenizer.pad_token_id,
|
||||
repetition_penalty=1.1,
|
||||
**model_kwargs
|
||||
)
|
||||
else:
|
||||
#beam search
|
||||
outputs = self.text_decoder.generate(input_ids=input_ids,
|
||||
max_length=max_length,
|
||||
min_length=min_length,
|
||||
num_beams=num_beams,
|
||||
eos_token_id=self.tokenizer.sep_token_id,
|
||||
pad_token_id=self.tokenizer.pad_token_id,
|
||||
repetition_penalty=repetition_penalty,
|
||||
**model_kwargs)
|
||||
|
||||
captions = []
|
||||
for output in outputs:
|
||||
caption = self.tokenizer.decode(output, skip_special_tokens=True)
|
||||
captions.append(caption[len(self.prompt):])
|
||||
return captions
|
||||
|
||||
# beam search
|
||||
outputs = self.text_decoder.generate(
|
||||
input_ids=input_ids,
|
||||
max_length=max_length,
|
||||
min_length=min_length,
|
||||
num_beams=num_beams,
|
||||
eos_token_id=self.tokenizer.sep_token_id,
|
||||
pad_token_id=self.tokenizer.pad_token_id,
|
||||
repetition_penalty=repetition_penalty,
|
||||
**model_kwargs
|
||||
)
|
||||
|
||||
def blip_decoder(pretrained='',**kwargs):
|
||||
captions = []
|
||||
for output in outputs:
|
||||
caption = self.tokenizer.decode(output, skip_special_tokens=True)
|
||||
captions.append(caption[len(self.prompt) :])
|
||||
return captions
|
||||
|
||||
|
||||
def blip_decoder(pretrained="", **kwargs):
|
||||
model = BLIP_Decoder(**kwargs)
|
||||
if pretrained:
|
||||
model,msg = load_checkpoint(model,pretrained)
|
||||
assert(len(msg.missing_keys)==0)
|
||||
return model
|
||||
|
||||
def blip_feature_extractor(pretrained='',**kwargs):
|
||||
model, msg = load_checkpoint(model, pretrained)
|
||||
assert len(msg.missing_keys) == 0
|
||||
return model
|
||||
|
||||
|
||||
def blip_feature_extractor(pretrained="", **kwargs):
|
||||
model = BLIP_Base(**kwargs)
|
||||
if pretrained:
|
||||
model,msg = load_checkpoint(model,pretrained)
|
||||
assert(len(msg.missing_keys)==0)
|
||||
return model
|
||||
model, msg = load_checkpoint(model, pretrained)
|
||||
assert len(msg.missing_keys) == 0
|
||||
return model
|
||||
|
||||
|
||||
def init_tokenizer():
|
||||
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
|
||||
tokenizer.add_special_tokens({'bos_token':'[DEC]'})
|
||||
tokenizer.add_special_tokens({'additional_special_tokens':['[ENC]']})
|
||||
tokenizer.enc_token_id = tokenizer.additional_special_tokens_ids[0]
|
||||
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
|
||||
tokenizer.add_special_tokens({"bos_token": "[DEC]"})
|
||||
tokenizer.add_special_tokens({"additional_special_tokens": ["[ENC]"]})
|
||||
tokenizer.enc_token_id = tokenizer.additional_special_tokens_ids[0]
|
||||
return tokenizer
|
||||
|
||||
|
||||
def create_vit(vit, image_size, use_grad_checkpointing=False, ckpt_layer=0, drop_path_rate=0):
|
||||
|
||||
assert vit in ['base', 'large'], "vit parameter must be base or large"
|
||||
if vit=='base':
|
||||
def create_vit(
|
||||
vit, image_size, use_grad_checkpointing=False, ckpt_layer=0, drop_path_rate=0
|
||||
):
|
||||
assert vit in ["base", "large"], "vit parameter must be base or large"
|
||||
if vit == "base":
|
||||
vision_width = 768
|
||||
visual_encoder = VisionTransformer(img_size=image_size, patch_size=16, embed_dim=vision_width, depth=12,
|
||||
num_heads=12, use_grad_checkpointing=use_grad_checkpointing, ckpt_layer=ckpt_layer,
|
||||
drop_path_rate=0 or drop_path_rate
|
||||
)
|
||||
elif vit=='large':
|
||||
visual_encoder = VisionTransformer(
|
||||
img_size=image_size,
|
||||
patch_size=16,
|
||||
embed_dim=vision_width,
|
||||
depth=12,
|
||||
num_heads=12,
|
||||
use_grad_checkpointing=use_grad_checkpointing,
|
||||
ckpt_layer=ckpt_layer,
|
||||
drop_path_rate=0 or drop_path_rate,
|
||||
)
|
||||
elif vit == "large":
|
||||
vision_width = 1024
|
||||
visual_encoder = VisionTransformer(img_size=image_size, patch_size=16, embed_dim=vision_width, depth=24,
|
||||
num_heads=16, use_grad_checkpointing=use_grad_checkpointing, ckpt_layer=ckpt_layer,
|
||||
drop_path_rate=0.1 or drop_path_rate
|
||||
)
|
||||
visual_encoder = VisionTransformer(
|
||||
img_size=image_size,
|
||||
patch_size=16,
|
||||
embed_dim=vision_width,
|
||||
depth=24,
|
||||
num_heads=16,
|
||||
use_grad_checkpointing=use_grad_checkpointing,
|
||||
ckpt_layer=ckpt_layer,
|
||||
drop_path_rate=0.1 or drop_path_rate,
|
||||
)
|
||||
return visual_encoder, vision_width
|
||||
|
||||
|
||||
def is_url(url_or_filename):
|
||||
parsed = urlparse(url_or_filename)
|
||||
return parsed.scheme in ("http", "https")
|
||||
|
||||
def load_checkpoint(model,url_or_filename):
|
||||
|
||||
def load_checkpoint(model, url_or_filename):
|
||||
if is_url(url_or_filename):
|
||||
cached_file = download_cached_file(url_or_filename, check_hash=False, progress=True)
|
||||
checkpoint = torch.load(cached_file, map_location='cpu')
|
||||
elif os.path.isfile(url_or_filename):
|
||||
checkpoint = torch.load(url_or_filename, map_location='cpu')
|
||||
cached_file = download_cached_file(
|
||||
url_or_filename, check_hash=False, progress=True
|
||||
)
|
||||
checkpoint = torch.load(cached_file, map_location="cpu")
|
||||
elif os.path.isfile(url_or_filename):
|
||||
checkpoint = torch.load(url_or_filename, map_location="cpu")
|
||||
else:
|
||||
raise RuntimeError('checkpoint url or path is invalid')
|
||||
|
||||
state_dict = checkpoint['model']
|
||||
|
||||
state_dict['visual_encoder.pos_embed'] = interpolate_pos_embed(state_dict['visual_encoder.pos_embed'],model.visual_encoder)
|
||||
if 'visual_encoder_m.pos_embed' in model.state_dict().keys():
|
||||
state_dict['visual_encoder_m.pos_embed'] = interpolate_pos_embed(state_dict['visual_encoder_m.pos_embed'],
|
||||
model.visual_encoder_m)
|
||||
raise RuntimeError("checkpoint url or path is invalid")
|
||||
|
||||
state_dict = checkpoint["model"]
|
||||
|
||||
state_dict["visual_encoder.pos_embed"] = interpolate_pos_embed(
|
||||
state_dict["visual_encoder.pos_embed"], model.visual_encoder
|
||||
)
|
||||
if "visual_encoder_m.pos_embed" in model.state_dict().keys():
|
||||
state_dict["visual_encoder_m.pos_embed"] = interpolate_pos_embed(
|
||||
state_dict["visual_encoder_m.pos_embed"], model.visual_encoder_m
|
||||
)
|
||||
for key in model.state_dict().keys():
|
||||
if key in state_dict.keys():
|
||||
if state_dict[key].shape!=model.state_dict()[key].shape:
|
||||
if state_dict[key].shape != model.state_dict()[key].shape:
|
||||
del state_dict[key]
|
||||
|
||||
msg = model.load_state_dict(state_dict,strict=False)
|
||||
print('load checkpoint from %s'%url_or_filename)
|
||||
return model,msg
|
||||
|
||||
|
||||
msg = model.load_state_dict(state_dict, strict=False)
|
||||
print("load checkpoint from %s" % url_or_filename)
|
||||
return model, msg
|
||||
|
||||