mirror of
https://github.com/sd-webui/stable-diffusion-webui.git
synced 2024-12-13 18:02:31 +03:00
remove old doc files
move docker guide inside docs/
This commit is contained in:
parent
4b5d48b499
commit
ed3d9176e7
@ -1,115 +0,0 @@
|
||||
# Installation
|
||||
|
||||
**This page describes Windows installation.
|
||||
[To install on Linux, see this page.](https://github.com/sd-webui/stable-diffusion-webui/wiki/Linux-Automated-Setup-Guide)
|
||||
[To install on Colab, see Altryne's notebook.](https://github.com/altryne/sd-webui-colab)**
|
||||
|
||||
# Windows - step by step Installation guide
|
||||
|
||||
# Initial Setup
|
||||
|
||||
## Pre requisites
|
||||
|
||||
### Install Git & Miniconda :
|
||||
|
||||
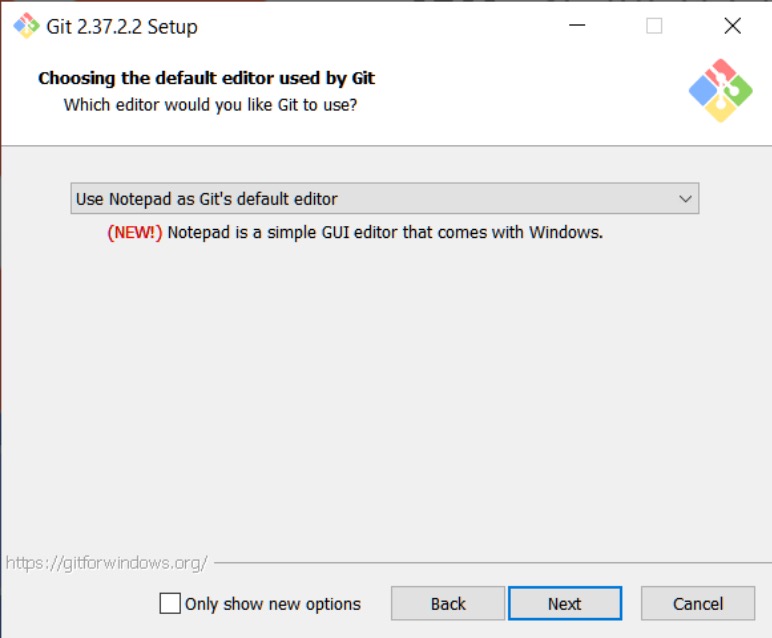
* https://gitforwindows.org/ Download this, and accept all of the default settings it offers except for the default editor selection. Once it asks for what the default editor is, most people who are unfamiliar with this should just choose Notepad because everyone has Notepad on Windows.
|
||||
|
||||
|
||||
|
||||
|
||||
* Download Miniconda3:
|
||||
[https://repo.anaconda.com/miniconda/Miniconda3-latest-Windows-x86_64.exe](https://repo.anaconda.com/miniconda/Miniconda3-latest-Windows-x86_64.exe) Get this installed so that you have access to the Miniconda3 Prompt Console.
|
||||
|
||||
* Open Miniconda3 Prompt from your start menu after it has been installed
|
||||
|
||||
* _(Optional)_ Create a new text file in your root directory `/stable-diffusion-webui/custom-conda-path.txt` that contains the path to your relevant Miniconda3, for example `C:\Users\<username>\miniconda3` (replace `<username>` with your own username). This is required if you have more than 1 miniconda installation or are using custom installation location.
|
||||
|
||||
## Cloning the repo
|
||||
|
||||
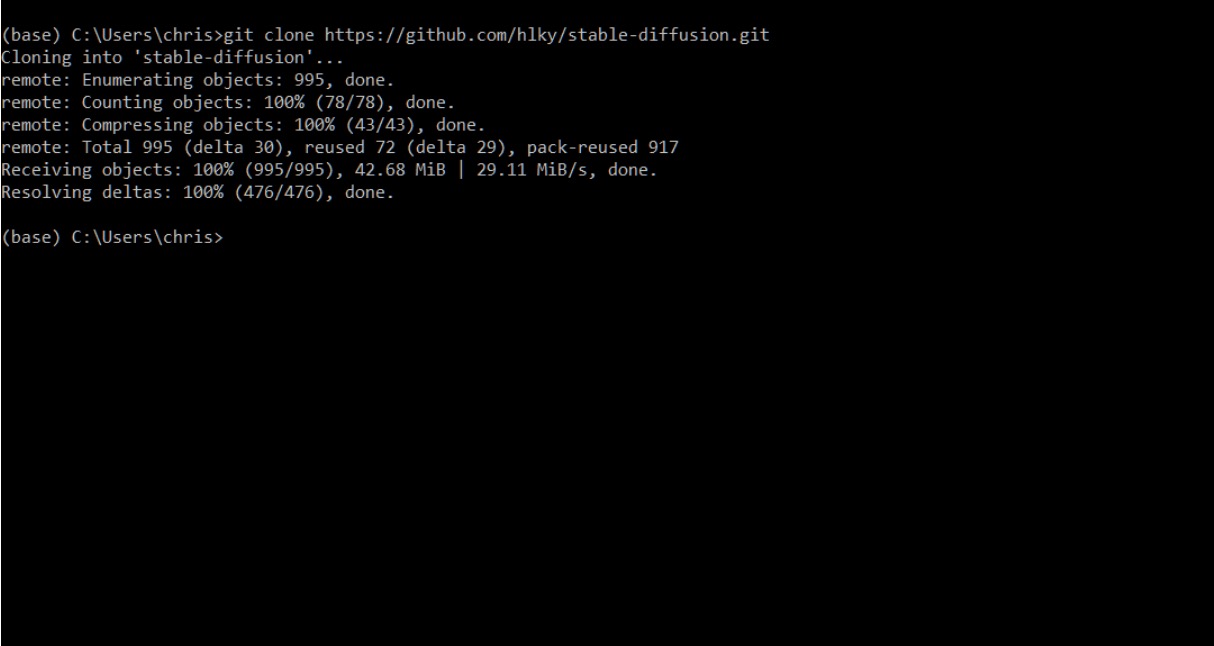
Type `git clone https://github.com/sd-webui/stable-diffusion-webui.git` into the prompt.
|
||||
|
||||
This will create the `stable-diffusion-webui` directory in your Windows user folder.
|
||||
|
||||
|
||||
---
|
||||
|
||||
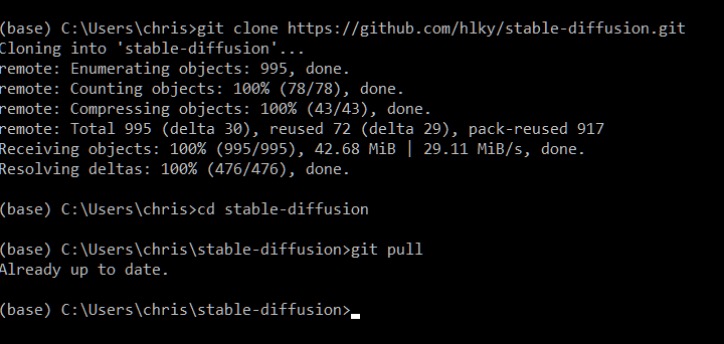
Once a repo has been cloned, updating it is as easy as typing `git pull` inside of Miniconda when in the repo’s topmost directory downloaded by the clone command. Below you can see I used the `cd` command to navigate into that folder.
|
||||
|
||||
|
||||
|
||||
|
||||
* Next you are going to want to create a Hugging Face account: [https://huggingface.co/](https://huggingface.co/)
|
||||
|
||||
|
||||
* After you have signed up, and are signed in go to this link and click on Authorize: [https://huggingface.co/CompVis/stable-diffusion-v-1-4-original](https://huggingface.co/CompVis/stable-diffusion-v-1-4-original)
|
||||
|
||||
|
||||
* After you have authorized your account, go to this link to download the model weights for version 1.4 of the model, future versions will be released in the same way, and updating them will be a similar process :
|
||||
[https://huggingface.co/CompVis/stable-diffusion-v-1-4-original/resolve/main/sd-v1-4.ckpt](https://huggingface.co/CompVis/stable-diffusion-v-1-4-original/resolve/main/sd-v1-4.ckpt)
|
||||
|
||||
|
||||
* Download the model into this directory: `C:\Users\<username>\stable-diffusion-webui\models\ldm\stable-diffusion-v1`
|
||||
|
||||
|
||||
* Rename `sd-v1-4.ckpt` to `model.ckpt` once it is inside the stable-diffusion-v1 folder.
|
||||
|
||||
|
||||
* Since we are already in our stable-diffusion-webui folder in Miniconda, our next step is to create the environment Stable Diffusion needs to work.
|
||||
|
||||
|
||||
* _(Optional)_ If you already have an environment set up for an installation of Stable Diffusion named ldm open up the `environment.yaml` file in `\stable-diffusion-webui\` change the environment name inside of it from `ldm` to `ldo`
|
||||
|
||||
---
|
||||
|
||||
## First run
|
||||
* `webui.cmd` at the root folder (`\stable-diffusion-webui\`) is your main script that you'll always run. It has the functions to automatically do the followings:
|
||||
* Create conda env
|
||||
* Install and update requirements
|
||||
* Run the relauncher and webui.py script for gradio UI options
|
||||
|
||||
* Run `webui.cmd` by double clicking the file.
|
||||
|
||||
* Wait for it to process, this could take some time. Eventually it’ll look like this:
|
||||
|
||||

|
||||
|
||||
* You'll receive warning messages on **GFPGAN**, **RealESRGAN** and **LDSR** but these are optionals and will be further explained below.
|
||||
|
||||
* In the meantime, you can now go to your web browser and open the link to [http://localhost:7860/](http://localhost:7860/).
|
||||
|
||||
* Enter the text prompt required and click generate.
|
||||
|
||||
* You should be able to see progress in your `webui.cmd` window. The [http://localhost:7860/](http://localhost:7860/) will be automatically updated to show the final image once progress reach 100%
|
||||
|
||||
* Images created with the web interface will be saved to `\stable-diffusion-webui\outputs\` in their respective folders alongside `.yaml` text files with all of the details of your prompts for easy referencing later. Images will also be saved with their seed and numbered so that they can be cross referenced with their `.yaml` files easily.
|
||||
|
||||
---
|
||||
|
||||
### Optional additional models
|
||||
|
||||
There are three more models that we need to download in order to get the most out of the functionality offered by sd-webui.
|
||||
|
||||
> The models are placed inside `src` folder. If you don't have `src` folder inside your root directory it means that you haven't installed the dependencies for your environment yet. [Follow this step](#first-run) before proceeding.
|
||||
|
||||
### GFPGAN
|
||||
1. If you want to use GFPGAN to improve generated faces, you need to install it separately.
|
||||
1. Download [GFPGANv1.3.pth](https://github.com/TencentARC/GFPGAN/releases/download/v1.3.0/GFPGANv1.3.pth) and put it
|
||||
into the `/stable-diffusion-webui/src/gfpgan/experiments/pretrained_models` directory.
|
||||
|
||||
### RealESRGAN
|
||||
1. Download [RealESRGAN_x4plus.pth](https://github.com/xinntao/Real-ESRGAN/releases/download/v0.1.0/RealESRGAN_x4plus.pth) and [RealESRGAN_x4plus_anime_6B.pth](https://github.com/xinntao/Real-ESRGAN/releases/download/v0.2.2.4/RealESRGAN_x4plus_anime_6B.pth).
|
||||
1. Put them into the `stable-diffusion-webui/src/realesrgan/experiments/pretrained_models` directory.
|
||||
|
||||
### LDSR
|
||||
1. Detailed instructions [here](https://github.com/Hafiidz/latent-diffusion). Brief instruction as follows.
|
||||
1. Git clone [Hafiidz/latent-diffusion](https://github.com/Hafiidz/latent-diffusion) into your `/stable-diffusion-webui/src/` folder.
|
||||
1. Run `/stable-diffusion-webui/src/latent-diffusion/download_model.bat` to automatically download and rename the models.
|
||||
1. Wait until it is done and you can confirm by confirming two new files in `stable-diffusion-webui/src/latent-diffusion/experiments/pretrained_models/`
|
||||
1. _(Optional)_ If there are no files there, you can manually download **LDSR** [project.yaml](https://heibox.uni-heidelberg.de/f/31a76b13ea27482981b4/?dl=1) and [model last.cpkt](https://heibox.uni-heidelberg.de/f/578df07c8fc04ffbadf3/?dl=1).
|
||||
1. Rename last.ckpt to model.ckpt and place both under `stable-diffusion-webui/src/latent-diffusion/experiments/pretrained_models/`.
|
||||
1. Refer to [here](https://github.com/sd-webui/stable-diffusion-webui/issues/488) for any issue.
|
||||
|
||||
|
||||
# Credits
|
||||
> Big thanks to Arkitecc#0339 from the Stable Diffusion discord for the original guide (support them [here](https://ko-fi.com/arkitecc)).
|
||||
> Modified by [Hafiidz](https://github.com/Hafiidz) with helps from sd-webui discord and team.
|
||||
@ -1,110 +0,0 @@
|
||||
# Installation for Linux
|
||||
|
||||
### The definitive Stable Diffusion experience ™ Now 100% Linux Compatible!
|
||||
#### Created by [Joshua Kimsey](https://github.com/JoshuaKimsey)
|
||||
|
||||
#### Based on: [GUITARD](https://rentry.org/guitard) by [hlky](https://github.com/hlky)
|
||||
(Please refer to there if something breaks or updates in Stable Diffusion itself, I will try to keep this guide updated as necessary)
|
||||
|
||||
## Features
|
||||
- Automates the process of installing and running the hlky fork of Stable Diffusion for Linux-based OS users.
|
||||
- Handles updating from the hlky fork automatically if the users wishes to do so.
|
||||
- Allows the user to decide whether to run the Standard or Optimized forms of Ultimate Stable Diffusion.
|
||||
|
||||
## Change Log
|
||||
|
||||
**PLEASE NOTE: In order to upgrade to version 1.7 or later of this script, you must delete your pre-existing `ultimate-stable-diffusion` folder and do a clean re-install using the script. You can copy your `outputs` folder in there to save it elsewhere and then add it back once the re-install is done. Also, make sure your original 1.4 models are saved somewhere, or else you will need to re-download them from Hugging Face. The models file can be found in `ultimate-stable-diffusion/models/ldm/stablediffusion-v1/Model.ckpt`, if you do not have them saved elsewhere. Rename it to `sd-v1-4.ckpt` to make them work as expected with the script.**
|
||||
|
||||
**Please Note: Version 1.8 and above now make use of the unified Stable-Diffusion WebUI repo on GitHub. Your old outputs are safe in the `ultimate-stable-diffusion` folder as a new folder will be generated for this unified repo. Feel free to copy your outputs folder from `ultimate-stable-diffusion` over to the new `stable-diffusion-webui` folder. Don't forget the model weights inside of `ultimate-stable-diffusion` as well, if you don't have them saved elsewhere. Once this is done, you may safely delete the `ultimate-stable-diffusion` folder, as it is no longer used or needed.**
|
||||
|
||||
* Version 1.8:
|
||||
- Added: Support for newly unified {Stable Diffusion WebUI}(https://github.com/sd-webui/stable-diffusion-webui) GitHub repo.
|
||||
|
||||
* Version 1.7:
|
||||
- Added: New arguments manager for `relauncher.py`.
|
||||
- Added: Handling for LDSR upsclaer setup.
|
||||
- Changed: Significantly cleaned up menu options for handling customization.
|
||||
- Version 1.7.1: Changed repo updating to be less prone to issues
|
||||
|
||||
* Version 1.6:
|
||||
- Added: Improved startup procedure to speed up start to launch times
|
||||
- Fixed: Potential updating issue with the environment.yaml file
|
||||
|
||||
* Version 1.5:
|
||||
- Added: Ability to load previously used parameters, speeding up launch times.
|
||||
- Added: Foundations for loading in new Stable Diffusion AI Models once that becomes a reality.
|
||||
- Changed: Cleaned up script code significantly.
|
||||
|
||||
* Version 1.4:
|
||||
- Added: Choice to launch hlky's Ultimate Stable Diffusion using Standard mode for faster inference or Optimized mode for lower VRAM usage.
|
||||
- Fixed: Significantly cleaned up code and made things prettier when running the script.
|
||||
- Removed: Now unnecessary code for basuljindal's Optimized SD, now that hlky's version supports it instead.
|
||||
|
||||
* Version 1.3:
|
||||
- ~~Added: Foundation for choosing which version of Stable Diffusion you would like to install and run, Ultimate or Optimized.~~
|
||||
- Fixed: Code layout using functions now.
|
||||
- Broken: Optimized won't install correctly and I'm not sure why, currently a WIP. (Update: No Longer an issue)
|
||||
|
||||
* Version 1.2:
|
||||
- Added the ability to choose to update from the hlky SD repo at the start of the script.
|
||||
- Fixed potential env naming issue in generated script. Please delete your `linux-setup.sh` file inside of the stable-diffusion directory before running the new script
|
||||
|
||||
* Version 1.1:
|
||||
- Added support for realESRGAN feature added to the hlky GitHub repo
|
||||
|
||||
* Version 1.0: Initial Release
|
||||
|
||||
## Initial Start Guide
|
||||
**Note:** This guide assumes you have installed Anaconda already, and have it set up properly. If you have not, please visit the [Anaconda](https://www.anaconda.com/products/distribution) website to download the file for your system and install it.
|
||||
|
||||
**WARNING: Multiple Linux users have reported issues using this script, and potentially Stable Diffusion in general, with Miniconda. As such, I can not recommend using it due to these issues with unknown causes. Please use the full release of Anaconda instead.**
|
||||
|
||||
**Step 1:** Create a folder/directory on your system and place this [script](https://github.com/JoshuaKimsey/Linux-StableDiffusion-Script/blob/main/linux-sd.sh) in it, named `linux-sd.sh`. This directory will be where the files for Stable Diffusion will be downloaded.
|
||||
|
||||
**Step 2:** Download the 1.4 AI model from HuggingFace (or another location, the original guide has some links to mirrors of the model) and place it in the same directory as the script.
|
||||
|
||||
**Step 3:** Make the script executable by opening the directory in your Terminal and typing `chmod +x linux-sd.sh`, or whatever you named this file as.
|
||||
|
||||
**Step 4:** Run the script with `./linux-sd.sh`, it will begin by cloning the [WebUI Github Repo](https://github.com/sd-webui/stable-diffusion-webui) to the directory the script is located in. This folder will be named `stable-diffusion-webui`.
|
||||
|
||||
**Step 5:** The script will pause and ask that you move/copy the downloaded 1.4 AI models to a newly created, **temporary** directory called `Models`. Press Enter once you have done so to continue.
|
||||
|
||||
**If you are running low on storage space, you can just move the 1.4 AI models file directly to this directory, it will not be deleted, simply moved and renamed. However my personal suggestion is to just **copy** it to the Models folder, in case you desire to delete and rebuild your Ultimate Stable Diffusion build again.**
|
||||
|
||||
**Step 6:** The script will then proceed to generate the Conda environment for the project. It will be created using the name `lsd` (not a mistake ;) ), which is short for `Linux Stable Diffusion`.
|
||||
|
||||
**If a Conda environment of this name already exists, it will ask you before deleting it. If you do not wish to continue, press `CTRL-C` to exit the program. Otherwise, press Enter to continue.**
|
||||
|
||||
**Building the Conda environment may take upwards of 15 minutes, depending on your network connection and system specs. This is normal, just leave it be and let it finish.**
|
||||
|
||||
**Step 7:** Once the Conda environment has been created successfully, GFPGAN, realESRGAN, and LDSR upscaler models will be downloaded and placed in their correct location automatically.
|
||||
|
||||
**Step 8:** Next, the script will ask if you wish to customize any of the launch arguments for Ultimate Stable Diffusion. IF yes, then a series of options will be presented to the user:
|
||||
- Use the CPU for Extra Upscaler Models to save on VRAM
|
||||
- Automatically open a new browser window or tab on first launch
|
||||
- Use Optimized mode for Ultimate Stable Diffusion, which only requires 4GB of VRAM at the cost of speed
|
||||
- Use Optimized Turbo which uses more VRAM than regular optimized, but is faster (Incompatible with regular optimized mode)
|
||||
- Open a public xxxxx.gradi.app URL to share your interface with others
|
||||
|
||||
The user will have the ability to set these to yes or no using the menu choices.
|
||||
|
||||
**Step 9:** After this, the last step is the script will, at first launch, generate another script within the `ultimate-stable-diffusion` directory, which will be called via BASH in interactive mode to launch Stable Diffusion itself. This is necessary due to oddities with how Conda handles being executed from scripts. This second script launches the python file that begins to run the web gui for Ultimate Stable Diffusion.
|
||||
|
||||
**On first launch this process may take a bit longer than on successive runs, but shouldn't take as long as building the Conda environment did.**
|
||||
|
||||
**Step 10:** I everything has gone successfully, you should see `Running on local URL: http://localhost:7860/` in your Terminal. Copy that and open it in your browser and you should now have access to the Gradio interface for Stable Diffusion! Generated images will be located in the `outputs` directory inside of `ultimate-stable-diffusion`. Enjoy the definitive Ultimate Stable Diffusion Experience on Linux! :)
|
||||
|
||||
## Ultimate Stable Diffusion Customizations
|
||||
|
||||
When running the script again after the initial use, the user will be presented with a choice to run Ultimate Stable Diffusion with the last used parameters used to launch it. If the user chooses `Yes`, then all customization steps will be skipped and Ultimate Stable Diffusion will launch.
|
||||
|
||||
If the user choose to Customize their setup, then they will be presented with these options on how to customize their Ultimate Stable Diffusion setup:
|
||||
|
||||
- Update the Stable Diffusion WebUI fork from the GitHub Repo
|
||||
- Load a new Stable Diffusion AI Model ==Currently Disabled. Will be enabled once multiple Stable Diffusion AI Models becomes a reality.==
|
||||
- Customize the launch arguments for Ultimate Stable Diffusion (See Above)
|
||||
|
||||
### Refer back to the original [guide](https://rentry.org/guitard) (potentially outdated now) for useful tips and links to other resources that can improve your Stable Diffusion experience
|
||||
|
||||
## Planned Additions
|
||||
- Investigate ways to handle Anaconda/Miniconda automatic installation on a user's system.
|
||||
@ -1,70 +0,0 @@
|
||||
# Setting command line options
|
||||
|
||||
Edit `scripts/relauncher.py` `python scripts/webui.py` becomes `python scripts/webui.py --no-half --precision=full`
|
||||
|
||||
# List of command line options
|
||||
|
||||
```
|
||||
optional arguments:
|
||||
-h, --help show this help message and exit
|
||||
--ckpt CKPT path to checkpoint of model (default: models/ldm/stable-diffusion-v1/model.ckpt)
|
||||
--cli CLI don't launch web server, take Python function kwargs from this file. (default: None)
|
||||
--config CONFIG path to config which constructs model (default: configs/stable-diffusion/v1-inference.yaml)
|
||||
--defaults DEFAULTS path to configuration file providing UI defaults, uses same format as cli parameter (default:
|
||||
configs/webui/webui.yaml)
|
||||
--esrgan-cpu run ESRGAN on cpu (default: False)
|
||||
--esrgan-gpu ESRGAN_GPU
|
||||
run ESRGAN on specific gpu (overrides --gpu) (default: 0)
|
||||
--extra-models-cpu run extra models (GFGPAN/ESRGAN) on cpu (default: False)
|
||||
--extra-models-gpu run extra models (GFGPAN/ESRGAN) on gpu (default: False)
|
||||
--gfpgan-cpu run GFPGAN on cpu (default: False)
|
||||
--gfpgan-dir GFPGAN_DIR
|
||||
GFPGAN directory (default: ./src/gfpgan)
|
||||
--gfpgan-gpu GFPGAN_GPU
|
||||
run GFPGAN on specific gpu (overrides --gpu) (default: 0)
|
||||
--gpu GPU choose which GPU to use if you have multiple (default: 0)
|
||||
--grid-format GRID_FORMAT
|
||||
png for lossless png files; jpg:quality for lossy jpeg; webp:quality for lossy webp, or
|
||||
webp:-compression for lossless webp (default: jpg:95)
|
||||
--inbrowser automatically launch the interface in a new tab on the default browser (default: False)
|
||||
--ldsr-dir LDSR_DIR LDSR directory (default: ./src/latent-diffusion)
|
||||
--n_rows N_ROWS rows in the grid; use -1 for autodetect and 0 for n_rows to be same as batch_size (default:
|
||||
-1) (default: -1)
|
||||
--no-half do not switch the model to 16-bit floats (default: False)
|
||||
--no-progressbar-hiding
|
||||
do not hide progressbar in gradio UI (we hide it because it slows down ML if you have hardware
|
||||
accleration in browser) (default: False)
|
||||
--no-verify-input do not verify input to check if it's too long (default: False)
|
||||
--optimized-turbo alternative optimization mode that does not save as much VRAM but runs siginificantly faster
|
||||
(default: False)
|
||||
--optimized load the model onto the device piecemeal instead of all at once to reduce VRAM usage at the
|
||||
cost of performance (default: False)
|
||||
--outdir_img2img [OUTDIR_IMG2IMG]
|
||||
dir to write img2img results to (overrides --outdir) (default: None)
|
||||
--outdir_imglab [OUTDIR_IMGLAB]
|
||||
dir to write imglab results to (overrides --outdir) (default: None)
|
||||
--outdir_txt2img [OUTDIR_TXT2IMG]
|
||||
dir to write txt2img results to (overrides --outdir) (default: None)
|
||||
--outdir [OUTDIR] dir to write results to (default: None)
|
||||
--filename_format [FILENAME_FORMAT]
|
||||
filenames format (default: None)
|
||||
--port PORT choose the port for the gradio webserver to use (default: 7860)
|
||||
--precision {full,autocast}
|
||||
evaluate at this precision (default: autocast)
|
||||
--realesrgan-dir REALESRGAN_DIR
|
||||
RealESRGAN directory (default: ./src/realesrgan)
|
||||
--realesrgan-model REALESRGAN_MODEL
|
||||
Upscaling model for RealESRGAN (default: RealESRGAN_x4plus)
|
||||
--save-metadata Store generation parameters in the output png. Drop saved png into Image Lab to read
|
||||
parameters (default: False)
|
||||
--share-password SHARE_PASSWORD
|
||||
Sharing is open by default, use this to set a password. Username: webui (default: None)
|
||||
--share Should share your server on gradio.app, this allows you to use the UI from your mobile app
|
||||
(default: False)
|
||||
--skip-grid do not save a grid, only individual samples. Helpful when evaluating lots of samples (default:
|
||||
False)
|
||||
--skip-save do not save indiviual samples. For speed measurements. (default: False)
|
||||
--no-job-manager Don't use the experimental job manager on top of gradio (default: False)
|
||||
--max-jobs MAX_JOBS Maximum number of concurrent 'generate' commands (default: 1)
|
||||
--tiling Generate tiling images (default: False)
|
||||
```
|
||||
@ -1,23 +0,0 @@
|
||||
# Custom models
|
||||
|
||||
You can use other *versions* of Stable Diffusion, and *finetunes* of Stable Diffusion.
|
||||
|
||||
## Stable Diffusion versions
|
||||
|
||||
### v1-3
|
||||
|
||||
### v1-4
|
||||
|
||||
### 🔜™️ v1-5 🔜™️
|
||||
|
||||
## Finetunes
|
||||
|
||||
## TrinArt/Trin-sama
|
||||
|
||||
### [v1](https://huggingface.co/naclbit/trinart_stable_diffusion)
|
||||
|
||||
### [v2](https://huggingface.co/naclbit/trinart_stable_diffusion_v2)
|
||||
|
||||
## [Waifu Diffusion](https://huggingface.co/hakurei/waifu-diffusion)
|
||||
|
||||
### [v2](https://storage.googleapis.com/ws-store2/wd-v1-2-full-ema.ckpt) [trimmed](https://huggingface.co/crumb/pruned-waifu-diffusion)
|
||||
@ -1,23 +0,0 @@
|
||||
# **Upscalers**
|
||||
|
||||
### It is currently open to discussion whether all these different **upscalers** should be only usable on their respective standalone tabs.
|
||||
|
||||
### _**Why?**_
|
||||
|
||||
* When you generate a large batch of images, will every image be good enough to deserve upscaling?
|
||||
* Images are upscaled after generation, this delays the generation of the next image in the batch, it's better to wait for the batch to finish then decide whether the image needs upscaling
|
||||
* Clutter: more upscalers = more gui options
|
||||
|
||||
### What if I _need_ upscaling after generation and can't just do it as post-processing?
|
||||
|
||||
* One solution would be to hide the options by default, and have a cli switch to enable them
|
||||
* One issue with the above solution is needing to still maintain gui options for all new upscalers
|
||||
* Another issue is how to ensure people who need it know about it without people who don't need it accidentally activating it then getting unexpected results?
|
||||
|
||||
### Which upscalers are planned?
|
||||
|
||||
* **goBIG**: this was implemented but reverted due to a bug and then the decision was made to wait until other upscalers were added to reimplement
|
||||
* **SwinIR-L 4x**
|
||||
* **CodeFormer**
|
||||
* _**more, suggestions welcome**_
|
||||
* if the idea of keeping all upscalers as post-processing is accepted then a single **'Upscalers'** tab with all upscalers could simplify the process and the UI
|
||||
Loading…
Reference in New Issue
Block a user