| .github/workflows | ||
| img | ||
| src | ||
| test | ||
| .gitignore | ||
| LICENSE | ||
| package.yaml | ||
| README.md | ||
| Setup.hs | ||
| stack.yaml | ||
| WhyHaskellMatters.iml | ||
Why Haskell Matters
This is an early draft work in progress article.
Motivation
Haskell was started as an academic research language in the late 1980ies. It was never one of the most popular languages in the software industry.
So why should we concern ourselves with it?
Instead of answering this question directly I'd like to first have a closer look on the reception of Haskell in the software developers community:
A strange development over time
In a talk in 2017 on the Haskell journey since its beginnings in the 1980ies Simon Peyton Jones speaks about the rather unusual life story of Haskell.
First he shows a chart representing the typical life cycle of research languages. They are often created by a single researcher (who is also the single user) and most of them will be abandoned after just a few years:
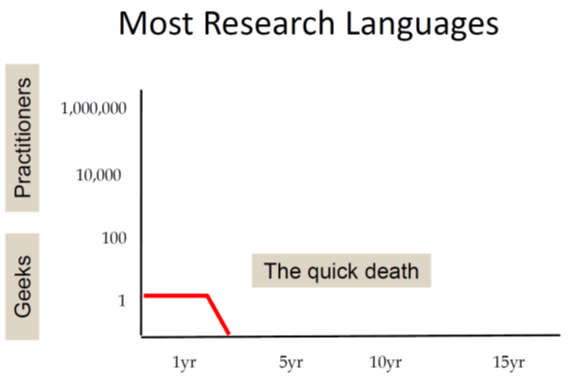
A more successful research language gains some interest in a larger community but will still not escape the ivory tower and typically will die within ten years:
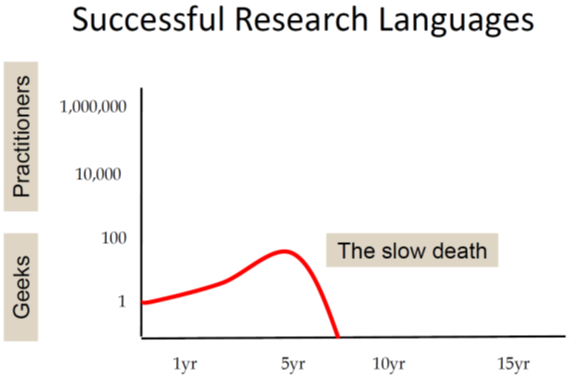
On the other hand we have popular programming languages that are quickly adopted by large numbers of users and thus reach "the threshold of immortality". That is the base of existing code will grow so large that the language will be in use for decades:
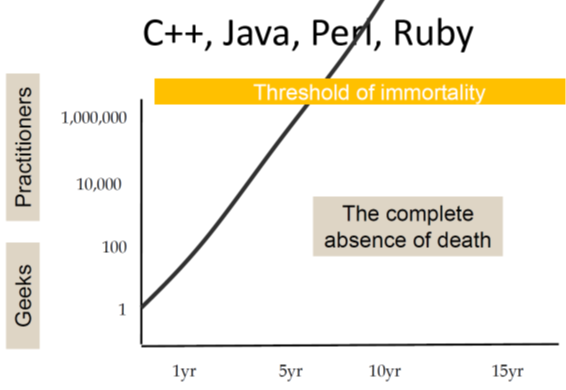
In the next chart he rather jokingly depicts the sad fate of languages designed by committees. They simply never take off:
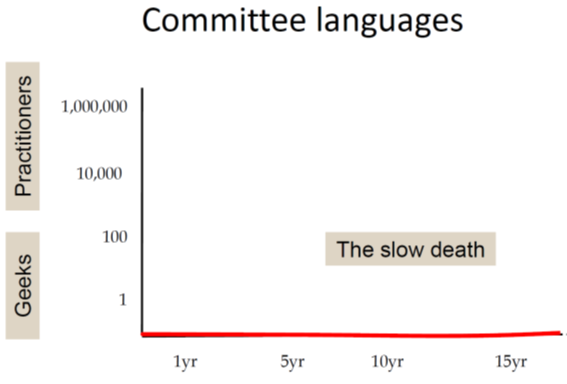
Finally he presents a chart showing the Haskell timeline:
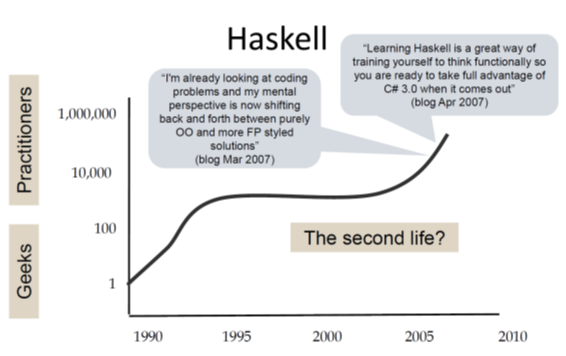
The development shown in this chart is rather unexpected and unusual: Haskell started as a research language and was even designed by a committee; so in all probability it should have been abandoned long before the millennium!
But instead it gained some momentum in the early years followed by a rather quiet phase during the decade of OO hype (Java was released in 1995). And then again we see a continuous growth of interest since about 2005. I'm writing this in early 2020 and we still see this trend.
Being used versus being discussed
Then Simon Peyton Jones points out another interesting characteristic of the reception of Haskell in recent years. In statics that rank programming languages by actual usage Haskell is typically not under the 30 most active languages. But in statistics that instead rank programming languages by the volume of discussions on the internet Haskell typically scores much better (often in the top ten).
So why does Haskell keep to be such a hot topic in the software development community?
A very short answer might be: Haskell has a number of features that are clearly different from those of most other programming languages. Many of these features have proven to be powerful tools to solve basic problems of software development elegantly.
Therefore over time other programming languages have adopted parts of these concepts (e.g. pattern matching or type classes). In discussions about such concepts the origin from Haskell is mentioned and differences between the Haskell concepts and those of other languages are discussed. Sometimes people are encouraged to have a closer look at the source of these concepts to get a deeper understanding of their original intentions. That's why we see a growing number of developers working in Python, Typescript, Scala, Rust, C++, C# or Java starting to dive into Haskell.
A further essential point is that Haskell is still an experimental laboratory for research in areas such as compiler construction, programming language design, theorem-provers, type systems etc. So inevitably Haskell will be a topic in the discussion about these approaches.
In the next section we want to study some of the most distinguishing features of Haskell.
So what exactly are those magic powers of Haskell?
Haskell doesn't solve different problems than other languages. But it solves them differently.
-- unknown
In this section we will examine the most outstanding features of the Haskell language. I'll try to keep the learning curve moderate and so I'll start with some very basic concepts.
Even though I'll try to keep the presentation self-contained it's not intended to be an introduction to the Haskell language (have a look at Learn You a Haskell if you are looking for enjoyable tutorial).
Functions are First-class
In computer science, a programming language is said to have first-class functions if it treats functions as first-class citizens. This means the language supports passing functions as arguments to other functions, returning them as the values from other functions, and assigning them to variables or storing them in data structures.[1] Some programming language theorists require support for anonymous functions (function literals) as well.[2] In languages with first-class functions, the names of functions do not have any special status; they are treated like ordinary variables with a function type.
quoted from Wikipedia
We'll go through this one by one:
functions can be assigned to variables exactly as any other other values
Let's have a look how this looks like in Haskell. First we define some simple values:
-- define constant `aNumber` with a value of 42.
aNumber :: Integer
aNumber = 42
-- define constant `aString` with a value of "hello world"
aString :: String
aString = "Hello World"
In the first line we see a type signature that defines the constant aNumber to be of type Integer.
In the second line we define the value of aNumber to be 42.
In the same way we define the constant aString to be of type String.
Next we define a function square that takes an integer argument and returns the square value of the argument:
square :: Integer -> Integer
square x = x * x
Definition of a function works exactly in the same way as the definition of any other value.
The only thing special is that we declare the type to be a function type by using the -> notation.
So :: Integer -> Integer represents a function from Integer to Integer.
In the second line we define function square to compute x * x for any Integer argument x.
Ok, seems not too difficult, so let's define another function double that doubles its input value:
double :: Integer -> Integer
double n = 2 * n
support for anonymous functions
Anonymous functions, also known as lambda expressions, can be defined in Haskell like this:
\x -> x * x
This expression denotes an anonymous function that takes a single argument x and returns the square of that argument. The backslash is read as λ (the greek letter lambda).
You can use such as expressions everywhere where you would use any other function. For example you could apply the
anonymous function \x -> x * x to a number just like the named function square:
-- use named function:
result = square 5
-- use anonymous function:
result' = (\x -> x * x) 5
We will see more useful applications of anonymous functions in the following section.
Functions can be returned as values from other functions
function composition
Do you remember function composition from your high-school math classes?
Function composition is an operation that takes two functions f and g and produces a function h such that
h(x) = g(f(x))
The resulting composite function is denoted h = g ∘ f where (g ∘ f )(x) = g(f(x)).
Intuitively, composing functions is a chaining process in which the output of function f is used as input of function g.
So looking from a programmers perspective the ∘ operator is a function that
takes two functions as arguments and returns a new composite function.
In Haskell this operator is represented as the dot operator .:
(.) :: (b -> c) -> (a -> b) -> a -> c
(.) f g x = f (g x)
The brackets around the dot are required as we want to use a non-alphabetical symbol as an identifier.
In Haskell such identifiers can be used as infix operators (as we will see below).
Otherwise (.) is defined as any other function.
Please also note how close the syntax is to the original mathematical definition.
Using this operator we can easily create a composite function that first doubles a number and then computes the square of that doubled number:
squareAfterDouble :: Integer -> Integer
squareAfterDouble = square . double
Currying and Partial Application
In this section we look at another interesting example of functions producing
other functions as return values.
We start by defining a function add that takes two Integer arguments and computes their sum:
-- function adding two numbers
add :: Integer -> Integer -> Integer
add x y = x + y
This look quite straightforward. But still there is one interesting detail to note:
the type signature of add is not something like
add :: (Integer, Integer) -> Integer
Instead it is:
add :: Integer -> Integer -> Integer
What does this signature actually mean?
It can be read as "A function taking an Integer argument and returning a function of type Integer -> Integer".
Sounds weird? But that's exactly what Haskell does internally.
So if we call add 2 3 first add is applied to 2 which return a new function of type Integer -> Integer which is then applied to 3.
This technique is called Currying
Currying is widely used in Haskell as it allows another cool thing: partial application.
In the next code snippet we define a function add5 by partially applying the function add to only one argument:
-- partial application: applying add to 5 returns a function of type Integer -> Integer
add5 :: Integer -> Integer
add5 = add 5
The trick is as follows: add 5 returns a function of type Integer -> Integer which will add 5 to any Integer argument.
Partial application thus allows us to write functions that return functions as result values. This technique is frequently used to provide functions with configuration data.
Functions can be passed as arguments to other functions
I could keep this section short by telling you that we have already seen an example for this:
the function composition operator (.).
It accepts two functions as arguments and returns a new one as in:
squareAfterDouble :: Integer -> Integer
squareAfterDouble = square . double
But again I'd like to show you another instructive example.
This is my scrap book (don't look at it)
-
Funktionen sind 1st class citizens (higher order functions, Funktionen könen neue Funktionen erzeugen und andere Funktionen als Argumente haben)
-
Abstraktion über Resource management und Abarbeitung (=> deklarativ)
-
Immutability ("Variables do not Vary")
-
Seiteneffekte müssen in Funktions signaturen explizit gemacht werden. D.H wenn keine Seiteneffekt angegeben ist, verhindert der Compiler, dass welche auftreten ! Damit lässt sich Seiteneffektfreie Programmierung realisieren ("Purity")
-
Evaluierung in Haskell ist "non-strict" (aka "lazy"). Damit lassen sich z.B. abzählbar unendliche Mengen (z.B. alle Primzahlen) sehr elegant beschreiben. Aber auch kontrollstrukturen lassen sich so selbst bauen (super für DSLs)
-
Static and Strong typing (Es gibt kein Casting)
-
Type Inferenz. Der Compiler kann die Typ-Signaturen von Funktionen selbst ermitteln. (Eine explizite Signatur ist aber möglich und oft auch sehr hilfreich für Doku und um Klarheit über Code zu gewinnen.)
-
Polymorphie (Z.B für "operator overloading", Generische Container Datentypen, etc. auf Basis von "TypKlassen")
-
Algebraische Datentypen (Summentypen + Produkttypen) AD helfen typische Fehler, di man von OO Polymorphie kenn zu vermeiden. Sie erlauben es, Code für viele Oerationen auf Datentypen komplett automatisch vom Compiler generieren zu lassen).
-
Pattern Matching erlaubt eine sehr klare Verarbeitung von ADTs
-
Eleganz: Viele Algorithmen lassen sich sehr kompakt und nah an der Problemdomäne formulieren.
-
Data Encapsulation durch Module
-
Weniger Bugs durch
-
Purity, keine Seiteneffekte
-
Starke typisierung. Keine NPEs !
-
Hohe Abstraktion, Programme lassen sich oft wie eine deklarative Spezifikation des Algorithmus lesen
-
sehr gute Testbarkeit durch "Composobility"
-
das "ports & adapters" Beispiel: https://github.com/thma/RestaurantReservation
-
TDD / DDD
-
-
Memory Management (sehr schneller GC)
-
Modulare Programme. Es gibt ein sehr einfaches aber effektive Modul System und eine grosse Vielzahl kuratierter Bibliotheken.
("Ich habe in 5 Jahre Haskell noch nicht ein einziges Mal debuggen müssen")
-
-
Performance: keine VM, sondern sehr optimierter Maschinencode. Mit ein wenig Feinschliff lassen sich oft Geschwindigkeiten wie bei handoptimiertem C-Code erreichen.
toc for code chapters (still in german)
-
Werte
-
Funktionen
-
Listen
-
Lazyness
- List comprehension
- Eigene Kontrollstrukturen
-
Algebraische Datentypen
- Summentypen : Ampelstatus
- Produkttypen (int, int) Beispiel: Baum mit Knoten (int, Ampelstatus) dann mit map ein Ampelstatus
-
deriving (Show, Read) für einfache Serialisierung
-
Homoiconicity (Kind of)
-
Maybe Datentyp
- totale Funktionen
- Verkettung von Maybe operationen
(um die "dreadful Staircase" zu vermeiden) => Monoidal Operations
-
explizite Seiten Effekte -> IO Monade
-
TypKlassen
- Polymorphismus z.B. Num a, Eq a
- Show, Read => Homoiconicity bei Serialisierung
- Automatic deriving (Functor mit Baum Beispiel)
-
Testbarkeit
- TDD, higher order functions assembly, Typklassen dispatch (https://jproyo.github.io/posts/2019-03-17-tagless-final-haskell.html)