As a drive-by of https://github.com/zed-industries/zed/pull/13654, I've
noticed that the editor felt sluggish after I've undone the changes made
by the replacement. It turns out that we are repeatedly checking whether
there are any edits to estabilish dirty/conflict state of a buffer, even
though this operation is pure; this PR stores away the result of a
computation and refers to it before rerunning it.
Release Notes:
- Improve editor's performance with large undo histories
Buffers carry several pieces of state besides their text: syntax tree,
diagnostics, git diff, and file data. Previously, the buffer maintained
a separate integer version number for each of these four pieces of
state, incrementing it every time that piece of state is updated. This
is used by MultiBuffers to detect when they need to update excerpts.
Previously, for a given buffer, these four version numbers were stored
on the buffer itself, on every snapshot of the buffer, in any
multi-buffer that referenced that buffer, **and** on snapshots of that
multi-buffer. But the only use for the version numbers was reduced down
to a single boolean predicate: whether or not the buffer's state has
changed.
In this PR, I've combined those 4 version numbers into one. I've called
it `non_text_state_update_count` because it tracks all state updates
outside of the text itself. This removes a bunch of unnecessary code,
and reduces the size of buffer snapshots and multi-buffer snapshots.
Release Notes:
- N/A

In the past, Zed used a single switch called `autoclose` to control both
`autoclose` and `auto_surround` functionalities:
+ `autoclose`: when input '(', append ')' automatically.
+ `auto_surround`: when select text and input '(', surround text with
'(' and ')' automatically.
This PR separates `auto_surround` from `autoclose` to support `<`.
Previously, if `autoclose` of `<` was set to `false`, `auto_surround`
couldn't be used. However, setting `autoclose` to `true` would affect
the default behavior of simple expression. For example, `a < b` would
become `a <> b`.
For more information, see #13187.
Fix#12898.
Release Notes:
- Added support for `auto_surround`
([#12898](https://github.com/zed-industries/zed/issues/12898)).
This PR removes the Copilot-specific aliases for the
`inline_completions` and `show_inline_completions` settings.
While these aliases were added to maintain backward-compatibility, the
aliasing behavior here can lead to a confusing experience when both keys
end up in the `settings.json`.
Release Notes:
- Breaking Change: Removed the `copilot` alias for the
`inline_completions` setting. If you have settings under `copilot` they
should get moved to `inline_completions`.
- Breaking Change: Removed the `show_copilot_suggestions` alias for the
`show_inline_completions` setting.
This PR removes the `language_overrides` alias for the `languages`
setting.
I've seen a number of people run into issues where they have both
`languages` and `language_overrides` in their settings and get confused
when their settings don't seem to apply as expected.
This is a breaking change, but I think it is a necessary one to prevent
more users from running into issues.
Release Notes:
- Breaking Change: Removed the `language_overrides` alias for the
`languages` setting. If you have settings under `language_overrides`
they should get moved to `languages`.
This PR adds support for [linked editing of
ranges](https://microsoft.github.io/language-server-protocol/specifications/lsp/3.17/specification/#textDocument_linkedEditingRange),
which in short means that editing one part of a file can now change
related parts in that same file. Think of automatically renaming
HTML/TSX closing tags when the opening one is changed.
TODO:
- [x] proto changes
- [x] Allow disabling linked editing ranges on a per language basis.
Fixes#4535
Release Notes:
- Added support for linked editing ranges LSP request. Editing opening
tags in HTML/TSX files (with vtsls) performs the same edit on the
closing tag as well (and vice versa). It can be turned off on a language-by-language basis with the following setting:
```
"languages": {
"HTML": {
"linked_edits": true
},
}
```
---------
Co-authored-by: Bennet <bennet@zed.dev>
The `worktree` crate mainly provides an in-memory model of a directory
and its git repositories. But because it was originally extracted from
the Project crate, it also contained lingering bits of code that were
outside of that area:
* it had a little bit of logic related to buffers (though most buffer
management lives in `project`)
* it had a *little* bit of logic for storing diagnostics (though the
vast majority of LSP and diagnostic logic lives in `project`)
* it had a little bit of logic for sending RPC message (though the
*receiving* logic for those RPC messages lived in `project`)
In this PR, I've moved those concerns entirely to the project crate
(where they were already dealt with for the most part), so that the
worktree crate can be more focused on its main job, and have fewer
dependencies.
Worktree no longer depends on `client` or `lsp`. It still depends on
`language`, but only because of `impl language::File for
worktree::File`.
Release Notes:
- N/A
Indent guides can be configured per language, meaning that in a multi
buffer we can get excerpts where indent guides should be
disabled/enabled/styled differently than other excerpts.
Imagine the following scenario, i have indent guides disabled in my
settings, but want to enable them for JS and Python. I also want to use
a different line width for python files. Something like this is now
supported:
<img width="445" alt="image"
src="https://github.com/zed-industries/zed/assets/53836821/0c91411c-145c-4210-a883-4c469d5cb828">
And the relevant settings for the example above:
```json
"indent_guides": {
"enabled": false
},
"languages": {
"JavaScript": {
"indent_guides": {
"enabled": true
}
},
"Python": {
"indent_guides": {
"enabled": true,
"line_width": 5
}
}
}
```
Release Notes:
- Respect language specific settings when showing indent guides in a
multibuffer
- Fixes an issue where indent guide specific settings were not
recognized when specified in local settings
When indent guides were still WIP, I thought it might be a good idea to
detect the tab size for every line individually, so we can handle files
with mixed indentations. However, while optimizing the performance of
indent guides I found that getting the language at a given anchor was
pretty expensive, therefore I only resolved the language for the first
visible row. However, this could lead to some weird flickering, where
the indent guides would use different tab sizes depending on the first
visible row (see #12492). This can be fixed by just using the primary
buffer language size.
So as of right now indent guides cannot handle files with mixed
indentations. Im not sure if anyone actually does/expects this, but one
use case I could imagine is something like this:
User x has a svelte file, where the tab size is set to `4`. However the
svelte code uses typescript inside a script tag, which User x wants to
use a tab size of `2`. The approach used here would not work for this,
but then again I think our formatter does not even support something
like this. Im probably overcomplicating things, so let's stick with the
simple solution for now.
Release Notes:
- Fixed an issue where indent guides would use an incorrect tab size
([#12492](https://github.com/zed-industries/zed/issues/12492)).
Follow-up of
https://github.com/zed-industries/zed/pull/12095#issuecomment-2123230762
reverting back part of https://github.com/zed-industries/zed/pull/11558
that was related to `language.toml` parsing.
Now all extensions that define `prettier_parser_name` in their language
configs, will enable formatting untitled buffers without any extra
language settings like
```json
{
"languages": {
"JSON": {
"prettier": {
"allowed": true,
"parser": "json"
}
}
}
}
```
Release Notes:
- Improved ergonomics of untitled buffer formatting with prettier, no
extra language settings are needed by default.
In #12003 we found ourselves in need for precise region tracking in
which a given runnable has an effect in order to grab variables from it.
This PR makes it so that in task modal all task variables from queries
overlapping current cursor position.
However, in the process of working on that I've found that we cannot
always use a top-level capture to represent the full match range of
runnable (which has been my assumption up to this point). Tree-sitter
captures cannot capture sibling groups; we did just that in Rust
queries.
Thankfully, none of the extensions are affected as in them, a capture is
always attached to single node. This PR adds annotations to them
nonetheless; we'll be able to get rid of top-level captures in extension
runnables.scm once this PR is in stable version of Zed.
Release Notes:
- N/A
This pull request replaces the static `⋯` character we used to insert
when folding a range with a custom render function that return an
`AnyElement`. We plan to use this in the assistant, but for now this
should be behavior-preserving.
Release Notes:
- N/A
---------
Co-authored-by: Nathan <nathan@zed.dev>
Co-authored-by: Conrad <conrad@zed.dev>
Builds on top of existing work from #2249, but here's a showcase:
https://github.com/zed-industries/zed/assets/53836821/4b346965-6654-496c-b379-75425d9b493f
TODO:
- [x] handle line wrapping
- [x] implement handling in multibuffer (crashes currently)
- [x] add configuration option
- [x] new theme properties? What colors to use?
- [x] Possibly support indents with different colors or background
colors
- [x] investigate edge cases (e.g. indent guides and folds continue on
empty lines even if the next indent is different)
- [x] add more tests (also test `find_active_indent_index`)
- [x] docs (will do in a follow up PR)
- [x] benchmark performance impact
Release Notes:
- Added indent guides
([#5373](https://github.com/zed-industries/zed/issues/5373))
---------
Co-authored-by: Nate Butler <1714999+iamnbutler@users.noreply.github.com>
Co-authored-by: Remco <djsmits12@gmail.com>
This PR changes the interface of ContextProvider, allowing it to inspect
*all* variables set so far during the process of building
`TaskVariables`. This makes it possible to capture e.g. an identifier in
tree-sitter query, process it and then export it as a task variable.
Notably, the list of variables includes captures prefixed with leading
underscore; they are removed after all calls to `build_context`, but it
makes it possible to capture something and then conditionally preserve
it (and perhaps modify it).
Release Notes:
- N/A
Release Notes:
- Added glob support for file_types configuration
([#10765](https://github.com/zed-industries/zed/issues/10765)).
`file_types` can now be written like this:
```json
"file_types": {
"Dockerfile": [
"Dockerfile",
"Dockerfile.*",
]
}
```
I noticed that scrolling the assistant panel was very slow in debug
mode, after running a completion. From profiling, I saw that it was due
to the buffer's `is_dirty` and `has_conflict` checks, which use
`edits_since` to check if there are any non-undone edits since the saved
version.
I optimized this in two ways:
* I introduced a specialized `has_edits_since` method on text buffers,
which allows us to more cheaply check if the buffer has been edited
since a given version, without some of the overhead involved in
computing what the edits actually are.
* In the case of `has_conflict`, we don't even need to call that method
in the case where the buffer doesn't have a file (is untitled, as is the
case in the assistant panel). Buffers without files cannot be in
conflict.
Release Notes:
- Improved performance of editing the assistant panel and untitled
buffers with many edits.
Closes https://github.com/zed-industries/zed/issues/11517
* Removes forced prettier parser name for languages, making `auto`
command to run prettier on every file by default.
* Moves prettier configs away from plugin language declarations into
language settings
Release Notes:
- N/A
While looking into how to implement #4901, noticed that the current
`Goto next/previous diagnostic` behaved a bit weirdly. That is, when
there are multiple errors that have overlapping ranges, only the first
one can be chosen to be active by the `go_to_diagnostic_impl`.
### Previous behavior:
https://github.com/zed-industries/zed/assets/71292737/95897675-f5ee-40e5-869f-0a40066eb8e3
Doesn't go through all the diagnostics, and going backwards and forwards
doesn't show the same diagnostic always.
### New behavior:
https://github.com/zed-industries/zed/assets/71292737/81f7945a-7ad8-4a34-b286-cc2799b10500
Should always go through the diagnostics in a consistent manner.
Release Notes:
* Improved the behavioral consistency of "Go to Next/Previous
Diagnostic"
Part of https://github.com/zed-industries/zed/issues/8081
To avoid confusion and bugs when converting between various row `u32`'s,
use different types for each.
Further PRs should split `Point` into buffer and multi buffer variants
and make the code more readable.
Release Notes:
- N/A
---------
Co-authored-by: Piotr <piotr@zed.dev>
From now on, only top-level captures are treated as runnable tags and
the rest is appended to task context as custom environmental variables
(unless the name is prefixed with _, in which case the capture is
ignored). This is most likely gonna help with Pest-like test runners.
Release Notes:
- N/A
---------
Co-authored-by: Remco <djsmits12@gmail.com>
Notable things I've had to fix due to 1.78:
- Better detection of unused items
- New clippy lint (`assigning_clones`) that points out places where assignment operations with clone rhs could be replaced with more performant `clone_into`
Release Notes:
- N/A
This fixes a tricky intermittent issue I was seeing, where failed to
chunk certain files correctly because of the way we reuse Tree-sitter
`Parser` instances across parses.
I've also accounted for leading comments in chunk boundaries, so that
items are grouped with their leading comments whenever possible when
chunking.
Finally, we've changed the `debug project index` action so that it opens
a simple debug view in a pane, instead of printing paths to the console.
This lets you click into a path and see how it was chunked.
Release Notes:
- N/A
---------
Co-authored-by: Marshall <marshall@zed.dev>
Adds a supermaven provider for completions. There are various other
refactors amidst this branch, primarily to make copilot no longer a
dependency of project as well as show LSP Logs for global LSPs like
copilot properly.
This feature is not enabled by default. We're going to seek to refine it
in the coming weeks.
Release Notes:
- N/A
---------
Co-authored-by: Antonio Scandurra <me@as-cii.com>
Co-authored-by: Nathan Sobo <nathan@zed.dev>
Co-authored-by: Max <max@zed.dev>
Co-authored-by: Max Brunsfeld <maxbrunsfeld@gmail.com>
As an attempt to do things better when showing diff hunks, store diff
base as Rope, not String, to have cheaper clones when the diff base text
is reused, e.g. creating another buffer with the diff base text for hunk
diff expanding.
Release Notes:
- N/A
This chunking strategy uses the existing `outline` query to chunk files.
We try to find chunk boundaries that are:
* at starts or ends of lines
* nested within as few outline items as possible
Release Notes:
- N/A
Release Notes:
- Fixed#10888
This patch addresses behavior of
`Editor::move_to_{beginning|end}_of_line`. It adds a setting,
`stop_at_soft_wraps` when defining a keymap for the
`editor::MoveToBeginningOfLine` and `editor::MoveToEndOfLine` actions.
When `true`, it causes movement to the either end of the line (via, for
example Home or End), to go to the logical end, as opposed to the
nearest soft wrap point in the respective direction.
---------
Co-authored-by: Kirill Bulatov <kirill@zed.dev>
Part of https://github.com/zed-industries/zed/issues/4523
Added two new actions with the default keybindings
```
"cmd-'": "editor::ToggleHunkDiff",
"cmd-\"": "editor::ExpandAllHunkDiffs",
```
that allow to browse git hunk diffs in Zed:
https://github.com/zed-industries/zed/assets/2690773/9a8a7d10-ed06-4960-b4ee-fe28fc5c4768
The hunks are dynamic and alter on user folds and modifications, or
toggle hidden, if the modifications were not adjacent to the expanded
hunk.
Release Notes:
- Added `editor::ToggleHunkDiff` (`cmd-'`) and
`editor::ExpandAllHunkDiffs` (`cmd-"`) actions to browse git hunk diffs
in Zed
This PR adds the ability for the Tailwind language server
(`tailwindcss-language-server`) to be controlled by the
`language_servers` setting.
Now in your settings you can indicate that the Tailwind language server
should be used for a given language, even if that language does not have
the Tailwind language server registered for it already:
```json
{
"languages": {
"My Language": {
"language_servers": ["tailwindcss-language-server", "..."]
}
}
}
```
Release Notes:
- N/A
This PR adds a new `language_servers` setting underneath the language
settings.
This setting controls which of the available language servers for a
given language will run.
The `language_servers` setting is an array of strings. Each item in the
array must be either:
- A language server ID (e.g., `"rust-analyzer"`,
`"typescript-language-server"`, `"eslint"`, etc.) denoting a language
server that should be enabled.
- A language server ID prefixed with a `!` (e.g., `"!rust-analyzer"`,
`"!typescript-language-server"`, `"!eslint"`, etc.) denoting a language
server that should be disabled.
- A `"..."` placeholder, which will be replaced by the remaining
available language servers that haven't already been mentioned in the
array.
For example, to enable the Biome language server in place of the default
TypeScript language server, you would add the following to your
settings:
```json
{
"languages": {
"TypeScript": {
"language_servers": ["biome", "!typescript-language-server", "..."]
}
}
}
```
More details can be found in #10906.
Release Notes:
- Added `language_servers` setting to language settings for customizing
which language server(s) run for a given language.
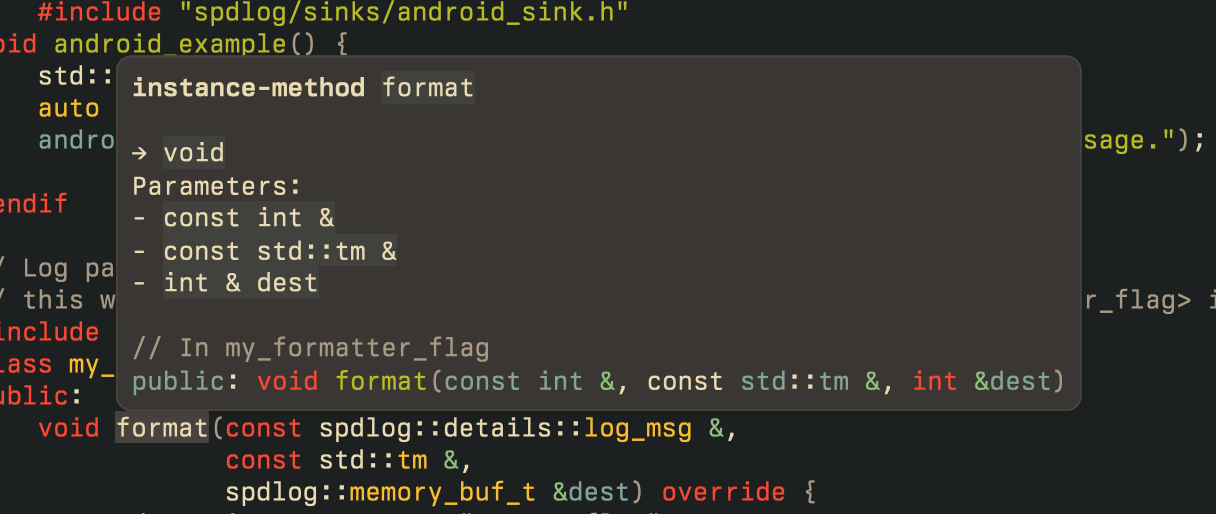
Some code blocks that are returned in tooltips (returned by language
servers, for example) use the language file extension as the language in
the the triple-backtick code blocks.
Example:
```rs
fn rust_code() {}
```
```cpp
fn rust_code() {}
```
Before this change we only looked up the language with the
`rs`/`cpp`/... being interpreted as the language name. Now we also treat
it as a possible file extension.
Release Notes:
- Fixed Markdown code blocks in tooltips not having correct language
highlighting.
Before:
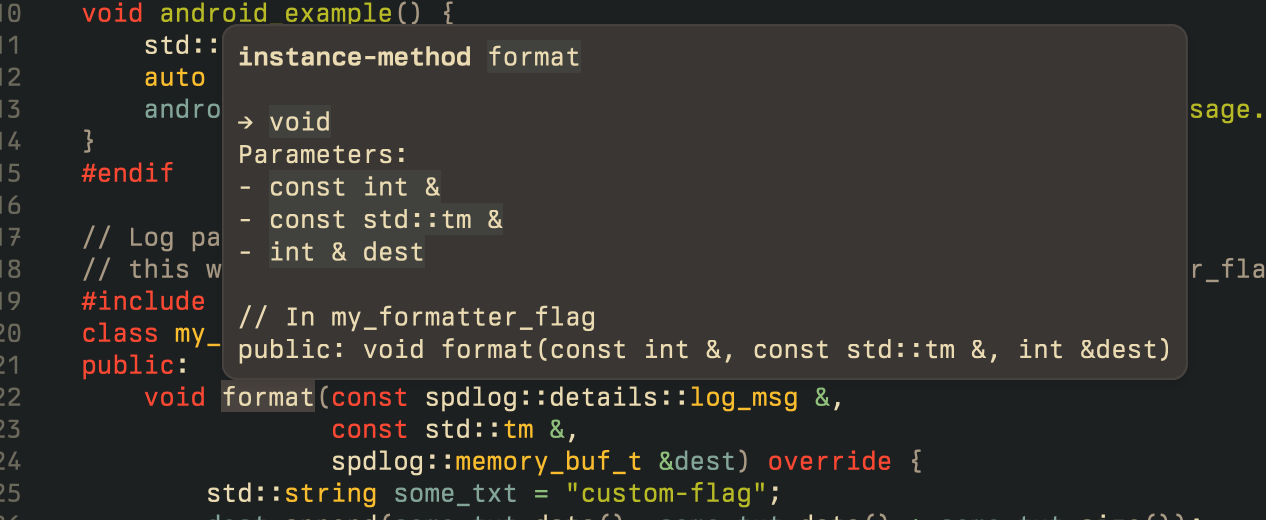
After:
Co-authored-by: Bennet <bennetbo@gmx.de>