| files | ||
| LICENSE | ||
| README_RUS.md | ||
| README.md | ||
![]()
This repository is a visual cheatsheet on the main topics in Backend-development. All material is divided into chapters that include different topics. There are three main parts to each topic:
- Visual part - various images/tables/cheatsheets for better understanding (may not be available). All pictures and tables are made from scratch, specifically for this repository.
- Summary - A very brief summary with a list of key terms and concepts. The terms are hyperlinked to the appropriate section on Wikipedia or a similar reference resource.
- References to sources - resources where you may find complete information on a particular issue. If possible, the most authoritative sources are indicated, or those that provide information in as simple and comprehensible language as possible.
🛠 The repository is under active development, so it is constantly updated and supplemented (see roadmap).
🤝 If you want to help the project, feel free to send your issues or pull requests.
🌙 For better experiense enable dark theme.
Contents
Network & Internet
Internet is a worldwide system that connects computer networks from around the world into a single network for storing/transferring information. The Internet was originally developed for the military. But soon it began to be implemented in universities, and then it could be used by private companies, which began to organize networks of providers that provide Internet access services to ordinary citizens. By early 2020, the number of Internet users exceeded 4.5 billion.
-
How the Internet works

Your computer does not have direct access to the Internet. Instead, it has access to your local network to which other devices are connected via a wired (Ethernet) or wireless (Wi-Fi) connection. The organizer of such a network is a special minicomputer - router. This device connects you to your Internet Service Provider (ISP), which in turn is connected to other higher-level ISPs. Thus, all these interactions make up the Internet, and your messages always transit through different networks before reaching the final recipient.
- Host
Any device that is on any network.
- Server
A special computer on the network that serves requests from other computers.

- Network topologies
There are several topologies (ways of organizing a network): Point to point, Daisy chain, Bus, Ring, Star and Mesh. The Internet itself cannot be referred to any one topology, because it is an incredibly complex system mixed with different topologies.
- Host
🔗 References
-
What is a domain name

Domain Names are human-readable addresses of web servers available on the Internet. They consist of parts (levels) separated from each other by a dot. Each of these parts provides specific information about the domain name. For example country, service name, localization, etc.
- Who owns domain names
The ICANN Corporation is the founder of the distributed domain registration system. It gives accreditations to companies that want to sell domains. In this way a competitive domain market is formed.
- How to buy a domain name
A domain name cannot be bought forever. It is leased for a certain period of time. It is better to buy domains from accredited registrars (you can find them in almost any country).
- Who owns domain names
-
IP address

IP address is a unique numeric address that is used to recognize a particular device on the network.
- Levels of visibility
- External and publicly accessible IP address that belongs to your ISP and is used to access the Internet by hundreds of other users.
- The IP address of your router in your ISP's local network, the same IP address from which you access the Internet.
- The IP address of your computer in the local (home) network created by the router, to which you can connect your devices. Typically, it looks like 192.168.XXX.XXX.
- The internal IP address of the computer, inaccessible from the outside and used only for communication between the running processes. It is the same for everyone - 127.0.0.1 or just localhost.
- Port
One device (computer) can run many applications that use the network. In order to correctly recognize where and which data coming over the network should be delivered (to which of the applications) a special numerical number - a port is used. That is, each running process on a computer which uses a network connection has its own personal port.
- IPv4
Version 4 of the IP protocol. It was developed in 1981 and limits the address space to about 4.3 billion (2^32) possible unique addresses.
- IPv6
Over time, the allocation of address space began to happen at a much faster rate, forcing the creation of a new version of the IP protocol to store more addresses. IPv6 is capable of issuing 2^128 (is huge number) unique addresses.
- Levels of visibility
🔗 References
- 📺 IP addresses. Explained – YouTube
- 📺 Public IP vs. Private IP and Port Forwarding (Explained by Example) – YouTube
- 📺 Network Ports Explained – YouTube
- 📺 What is IP address and types of IP address - IPv4 and IPv6 – YouTube
- 📺 IP Address - IPv4 vs IPv6 Tutorial – YouTube
- 📄 IP Address Subnet Cheat Sheet – freeCodeCamp
-
What is DNS
DNS (Domain Name System) is a decentralized Internet address naming system that allows you to create human-readable alphabetic names (domain names) corresponding to the numeric IP addresses used by computers.
- Structure of DNS
DNS consists of many independent nodes, each of which stores only those data that fall within its area of responsibility.
- DNS Resolver
A server that is located in close proximity to your Internet Service Provider. It is the server that searches for addresses by domain name, and also caches them (temporarily storing them for quick retrieval in future requests).
- DNS record types
- A record - associates the domain name with an IPv4 address.
- AAAA record - links a domain name with an IPv6 address.
- CNAME record - redirects to another domain name.
- and others - MX record, NS record, PTR record, SOA record.
- Structure of DNS
🔗 References
-
Web application design
Modern web applications consist of two parts: Frontend and Backend. Thus implementing a client-server model.
The tasks of the Frontend are:
- Implementation of the user interface (appearance of the application)
- A special markup language HTML is used to create web pages.
- CSS style language is used to style fonts, layout of content, etc.
- JavaScript programming language is used to add dynamics and interactivity.
As a rule, these tools are rarely used in their pure form, as so-called frameworks and preprocessors exist for more convenient and faster development.
- Creating functionality for generating requests to the server
These are usually different types of input forms that can be conveniently interacted with.
- Receives data from the server and then processes it for output to the client
Tasks of the Backend:
- Handling client requests
Checking for permissions and access, all sorts of validations, etc.
- Implementing business logic
A wide range of tasks can be implied here: working with databases, information processing, computation, etc. This is, so to speak, the heart of the Backend world. This is where all the important and interesting stuff happens.
- Generating a response and sending it to the client
- Implementation of the user interface (appearance of the application)
🔗 References
-
Browsers and how they work

Browser is a client which can be used to send requests to a server for files which can then be used to render web pages. In simple terms, a browser can be thought of as a program for viewing HTML files, which can also search for and download them from the Internet.
- Working Principle
Query handling, page rendering, and the tabs feature (each tab has its own process to prevent the contents of one tab from affecting the contents of the other).
- Extensions
Allow you to change the browser's user interface, modify the contents of web pages, and modify the browser's network requests.
- Chrome DevTools
An indispensable tool for any web developer. It allows you to analyze all possible information related to web pages, monitor their performance, logs and, most importantly for us, track information about network requests.
- Working Principle
🔗 References
- 📄 How browsers work – MDN
- 📄 How browsers work: Behind the scenes of modern web browsers – web.dev
- 📺 What is a web browser? – YouTube
- 📺 Anatomy of the browser 101 (Chrome University 2019) – YouTube
- 📺 Chrome DevTools - Crash Course – YouTube
- 📺 Demystifying the Browser Networking Tab in DevTools – YouTube
- 📺 21+ Browser Dev Tools & Tips You Need To Know – YouTube
-
VPN and Proxy

The use of VPNs and Proxy is quite common in recent years. With the help of these technologies, users can get basic anonymity when surfing the web, as well as bypass various regional blockages.
- VPN (Virtual Private Network)
A technology that allows you to become a member of a private network (similar to your local network), where requests from all participants go through a single public IP address. This allows you to blend in with the general mass of requests from other participants.
- Simple procedure for connection and use.
- Reliable traffic encryption.
- There is no guarantee of 100% anonymity, because the owner of the network knows the IP-addresses of all participants.
- VPNs are useless for dealing with multi-accounts and some programs because all accounts operating from the same VPN are easily detected and blocked.
- Free VPNs tend to be heavily loaded, resulting in unstable performance and slow download speeds.
- Simple procedure for connection and use.
- Proxy (proxy server)
A proxy is a special server on the network that acts as an intermediary between you and the destination server you intend to reach. When you are connected to a proxy server all your requests will be performed on behalf of that server, that is, your IP address and location will be substituted.
- The ability to use an individual IP address, which allows you to work with multi-accounts.
- Stability of the connection due to the absence of high loads.
- Connection via proxy is provided in the operating system and browser, so no additional software is required.
- There are proxy varieties that provide a high level of anonymity.
- The unreliability of free solutions, because the proxy server can see and control everything you do on the Internet.
- The ability to use an individual IP address, which allows you to work with multi-accounts.
- VPN (Virtual Private Network)
🔗 References
- 📄 What is VPN? How It Works, Types of VPN – kaspersky.com
- 📺 VPN (Virtual Private Network) Explained – YouTube
- 📺 What Is a Proxy and How Does It Work? – YouTube
- 📺 What is a Proxy Server? – YouTube
- 📺 Proxy vs. Reverse Proxy (Explained by Example) – YouTube
- 📺 VPN vs Proxy Explained Pros and Cons – YouTube
-
Hosting

Hosting is a special service provided by hosting providers, which allows you to rent space on a server (which is connected to the Internet around the clock), where your data and files can be stored. There are different options for hosting, where you can use not only the disk space of the server, but also the CPU power to run your network applications.
- Virtual hosting
One physical server that distributes its resources to multiple tenants.
- VPS/VDS
Virtual servers that emulate the operation of a separate physical server and are available for rent to the client with maximum privileges.
- Dedicated server
Renting a full physical server with full access to all resources. As a rule, this is the most expensive service.
- Cloud hosting
A service that uses the resources of several servers. When renting, the user pays only for the actual resources used.
- Colocation
A service that gives the customer the opportunity to install their equipment on the provider's premises.
- Virtual hosting
🔗 References
-
OSI network model
№ Level Used protocols 7 Application layer HTTP, DNS, FTP, POP3 6 Presentation layer SSL, SSH, IMAP, JPEG 5 Session layer APIs Sockets 4 Transport layer TCP, UDP 3 Network layer IP, ICMP, IGMP 2 Data link layer Ethernet, MAC, HDLC 1 Physical layer RS-232, RJ45, DSL - Physical layer
At this level, bits (ones/zeros) are encoded into physical signals (current, light, radio waves) and transmitted further by wire (Ethernet) or wirelessly (Wi-Fi).
- Data link layer
Physical signals from layer 1 are decoded back into ones and zeros, errors and defects are corrected, and the sender and receiver MAC addresses are extracted.
- Network layer
This is where traffic routing, DNS queries and IP packet generation take place.
- Transport layer
The layer responsible for data transfer. There are two important protocols:
- TCP is a protocol that ensures reliable data transmission. TCP guarantees data delivery and preserves the order of the messages. This has an impact on the transmission speed. This protocol is used where data loss is unacceptable, such as when sending mail or loading web pages.
- UDP is a simple protocol with fast data transfer. It does not use mechanisms to guarantee the delivery and ordering of data. It is used e.g. in online games where partial packet loss is not crucial, but the speed of data transfer is much more important. Also, requests to DNS servers are made through UDP protocol.
- TCP is a protocol that ensures reliable data transmission. TCP guarantees data delivery and preserves the order of the messages. This has an impact on the transmission speed. This protocol is used where data loss is unacceptable, such as when sending mail or loading web pages.
- Session layer
Responsible for opening and closing communications (sessions) between two devices. Ensures that the session stays open long enough to transfer all necessary data, and then closes quickly to avoid wasting resources.
- Presentation layer
Transmission, encryption/decryption and data compression. This is where data that comes in the form of zeros and ones are converted into desired formats (PNG, MP3, PDF, etc.)
- Application layer
Allows the user's applications to access network services such as database query handler, file access, email forwarding.
- Physical layer
🔗 References
-
HTTP Protocol
HTTP (HyperText Transport Protocol) is the most important protocol on the Internet. It is used to transfer data of any format. The protocol itself works according to a simple principle: request -> response.
- Structure of HTTP messages
HTTP messages consist of a header section containing metadata about the message, followed by an optional message body containing the data being sent.
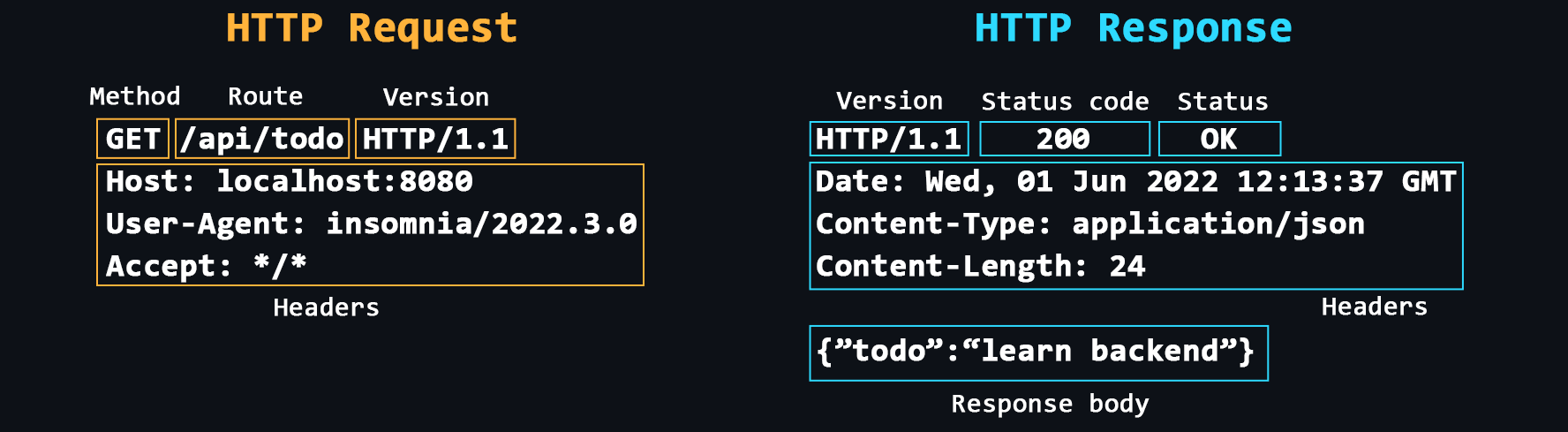
- Headers
Additional service information that is sent with the request/response.
Common headers: Host, User-Agent, If-Modified-Since, Cookie, Referer, Authorization, Cache-Control, Content-Type, Content-Length, Last-Modified, Set-Cookie, Content-Encoding. - Request methods
Main: GET, POST, PUT, DELETE.
Others: HEAD, CONNECT, OPTIONS, TRACE, PATCH. - Response status codes
Each response from the server has a special numeric code that characterizes the state of the sent request. These codes are divided into 5 main classes:
- 1хх - service information
- 2хх - successful request
- 3хх - redirect to another address
- 4хх - client side error
- 5хх - server side error
- 1хх - service information
- HTTPS
Same HTTP, but with encryption support
- Cookie
The HTTP protocol does not provide the ability to save information about the status of previous requests and responses. Cookies are used to solve this problem. Cookies allow the server to store information on the client side that the client can send back to the server. For example, cookies can be used to authenticate users or to store various settings.
- CORS (Cross origin resource sharing)
A technology that allows one domain to securely receive data from another domain.
- CSP (Content Security Policy)
A special header that allows you to recognize and eliminate certain types of web application vulnerabilities.
- HTTP/1.0 vs HTTP/1.1 vs HTTP/2
The main innovation in version 1.1 is the permanent connection mode, which allows you to send several requests per connection. In version 2, the protocol became binary, with the ability to transmit data from multiple streams on the same channel.
- Structure of HTTP messages
🔗 References
- 📄 How HTTP Works and Why it's Important – freeCodeCamp
- 📄 Hypertext Transfer Protocol (HTTP) – MDN
- 📺 Hyper Text Transfer Protocol Crash Course – YouTube
- 📺 Full HTTP Networking Course (5 hours) – YouTube
- 📄 HTTP vs HTTPS – What's the Difference? – freeCodeCamp
- 📺 HTTP Cookies Crash Course – YouTube
- 📺 Cross Origin Resource Sharing (Explained by Example) – YouTube
- 📺 When to use HTTP GET vs POST? – YouTube
- 📺 How HTTP/2 Works, Performance, Pros & Cons and More – YouTube
- 📺 HTTP/2 Critical Limitation that led to HTTP/3 & QUIC – YouTube
- 📺 304 Not Modified HTTP Status (Explained with Code Example and Pros & Cons) – YouTube
- 📺 What is the Largest POST Request the Server can Process? – YouTube
-
TCP/IP stack
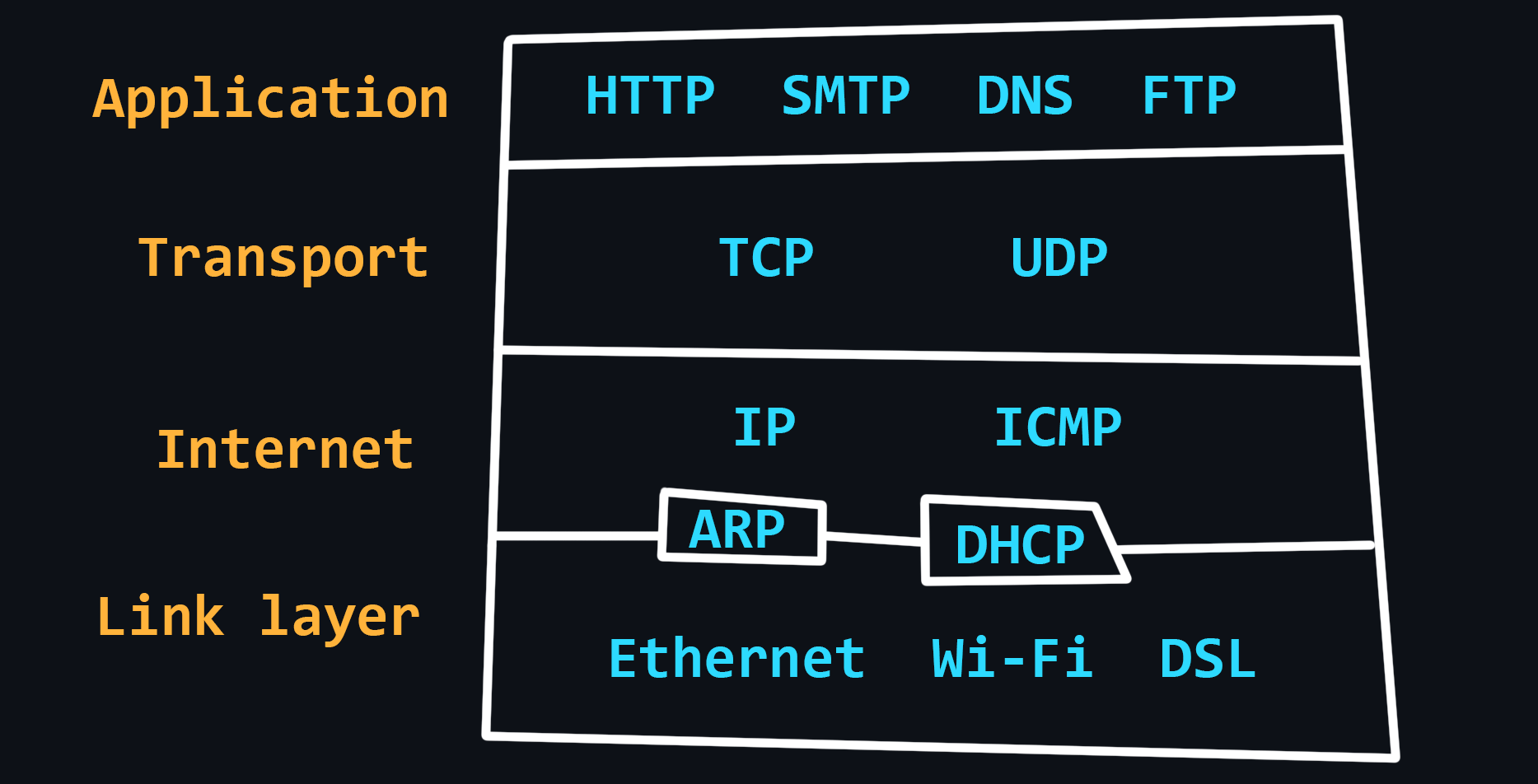
Compared to the OSI model, the TCP/IP stack has a simpler architecture. In general, the TCP/IP model is more widely used and practical, and the OSI model is more theoretical and detailed. Both models describe the same principles, but differ in the approach and protocols they include at their levels.
- Link layer
Defines how data is transmitted over the physical medium, such as cables or wireless signals.
Protocols: Ethernet, Wi-Fi, Bluetooth, Fiber optic. - Internet Layer
Routing data across different networks. It uses IP addresses to identify devices and routes data packets to their destination.
Protocols: IP, ARP, ICMP, IGMP - Transport Layer
Data transmission between two devices. It uses protocols such as TCP - reliable, but slow and UDP - fast, but unreliable.
- Application Layer
Provides services to the end user, such as web browsing, email, and file transfer. It interacts with the lower layers of the stack to transmit data over the network.
Protocols: HTTP, FTP, SMTP, DNS, SNMP.
- Link layer
🔗 References
-
Network problems

The quality of networks, including the Internet, is far from ideal. This is due to the complex structure of networks and their dependence on a huge number of factors. For example, the stability of the connection between the client device and its router, the quality of service of the provider, the power and performance of the server, the physical distance between the client and the server, etc.
- Latency
The time it takes for a data packet to travel from sender to receiver. It depends more on the physical distance.
- Packet loss
Not all packets traveling over the network can reach their destination. This happens most often when using wireless networks or due to network congestion.
- Round Trip Time (RTT)
The time it takes for the data packet to reach its destination + the time to respond that the packet was received successfully.
- Jitter
Delay fluctuations, unstable ping (for example, 50ms, 120ms, 35ms...).
- Packet reordering
The IP protocol does not guarantee that packets are delivered in the order in which they are sent.
- Latency
🔗 References
-
Network diagnostics

- Traceroute
A procedure that allows you to trace to which nodes, with which IP addresses, a packet you send before it reaches its destination. Tracing can be used to identify computer network related problems and to examine/analyze the network.
- Ping scan
The easiest way to check the server for performance.
- Checking for packet loss
Due to dropped connections, not all packets sent over the network reach their destination.
- Wireshark
A powerful program with a graphical interface for analyzing all traffic that passes through the network in real time.
- Traceroute
🔗 References
PC device
-
Main components (hardware)
- Motherboard
The most important PC component to which all other elements are connected.
- Chipset - set of electronic components that responsible for the communication of all motherboard components.
- CPU socket - socket for mounting the processor.
- VRM (Voltage Regulator Module) – module that converts the incoming voltage (usually 12V) to a lower voltage to run the processor, integrated graphics, memory, etc.
- Slots for RAM.
- Expansion slots PCI-Express - designed for connection of video cards, external network/sound cards.
- Slots M.2 / SATA - designed to connect hard disks and SSDs.
- CPU (Central processing unit)
The most important device that executes instructions (programme code). Processors only work with 1 and 0, so all programmes are ultimately a set of binary code.
- Registers - the fastest memory in a PC, has an extremely small capacity, is built into the processor and is designed to temporarily store the data being processed.
- Cache - slightly less fast memory, which is also built into the processor and is used to store a copy of data from frequently used cells in the main memory.
- Processors can have different architectures. Currently, the most common are the x86 architecture (desktop and laptop computers) and ARM (mobile devices as well as the latest Apple computers).
- RAM (Random-access memory)
Fast, low capacity memory (4-16GB) designed to temporarily store program code, as well as input, output and intermediate data processed by the processor.
- Data storage
Large capacity memory (256GB-1TB) designed for long-term storage of files and installed programmes.
- GPU (Graphics card)
A separate card that translates and processes data into images for display on a monitor. This device is also called a discrete graphics card. Usually needed for those who do 3D modelling or play games.
Built-in graphics card is a graphics card built into the processor. It is suitable for daily work. - Network card
A device that receives and transmits data from other devices connected to the local network.
- Sound card
A device that allows you to process sound, output it to other devices, record it with a microphone, etc.
- Power supply unit
A device designed to convert the AC voltage from the mains to DC voltage.
- Motherboard
🔗 References
- 📄 Everything You Need to Know About Computer Hardware
- 📺 What does what in your computer? Computer parts Explained – YouTube
- 📺 Motherboards Explained – YouTube
- 📺 The Fetch-Execute Cycle: What's Your Computer Actually Doing? – YouTube
- 📺 How a CPU Works in 100 Seconds // Apple Silicon M1 vs Intel i9 – YouTube
- 📺 Arm vs x86 - Key Differences Explained – YouTube
-
Operating system design
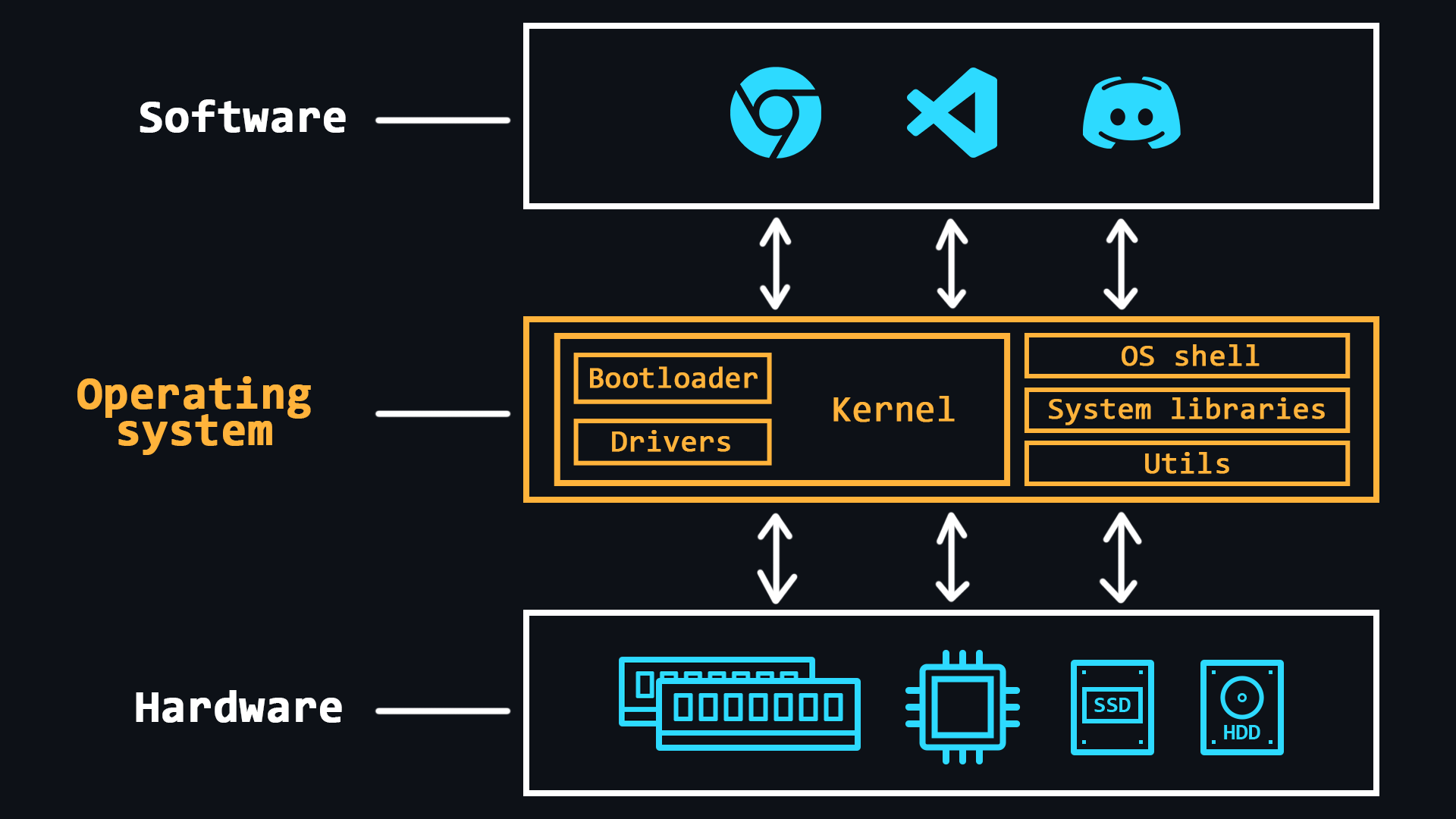
Operating system (OS) is a comprehensive software system designed to manage a computer's resources. With operating systems, people do not have to deal directly with the processor, RAM or other parts of the PC.
OS can be thought of as an abstraction layer that manages the hardware of a computer, thereby providing a simple and convenient environment for user software to run.
- Main features
- RAM management (space allocation for individual programms)
- Loading programms into RAM and their execution
- Execution of requests from user's programms (inputting and outputting data, starting and stopping other programms, freeing up memory or allocating additional memory, etc.)
- Interaction with input and output devices (mouse, keyboard, monitor, etc.)
- Interaction with storage media (HDDs and SSDs)
- Providing a user's interface (console shell or graphical interface)
- Logging of software errors (saving logs)
- Additional functions (may not be available in all OSs)
- Organise multitasking (simultaneous execution of several programms)
- Delimiting access to resources for each process
- Inter-process communication (data exchange, synchronisation)
- Organise the protection of the operating system itself against other programms and the actions of the user
- Provide multi-user mode and differentiate rights between different OS users (admins, guests, etc.)
- OS kernel
The central part of the operating system which is used most intensively. The kernel is constantly in memory, while other parts of the OS are loaded into and unloaded from memory as needed.
- Bootloader
The system software that prepares the environment for the OS to run (puts the hardware in the right state, prepares the memory, loads the OS kernel there and transfers control to it (the kernel).
- Device drivers
Special software that allows the OS to work with a particular piece of equipment.
- Main features
🔗 References
- 📄 What is an OS? Operating System Definition for Beginners – freeCodeCamp
- 📄 Windows vs MacOS vs Linux – Operating System Handbook – freeCodeCamp
- 📺 Operating Systems: Crash Course Computer Science – YouTube
- 📺 Operating System Basics – YouTube
- 📺 Operating System in deep details (playlist) – YouTube
- 📄 Awesome Operating System Stuff – GitHub
-
Processes and threads

- Process
A kind of container in which all the resources needed to run a program are stored. As a rule, the process consists of:
- Executable program code
- Input and output data
- Call stack (order of instructions for execution)
- Heap (a structure for storing intermediate data created during the process)
- Segment descriptor
- File descriptor
- Information about the set of permissible powers
- Processor status information
- Executable program code
- Thread
An entity in which sequences of program actions (procedures) are executed. Threads are within a process and use the same address space. There can be multiple threads in a single process, allowing multiple tasks to be performed. These tasks, thanks to threads, can exchange data, use shared data or the results of other tasks.
- Process
🔗 References
-
Concurrency and parallelism

- Parallelism
The ability to perform multiple tasks simultaneously using multiple processor cores, where each individual core performs a different task.
- Concurrency
The ability to perform multiple tasks, but using a single processor core. This is achieved by dividing tasks into separate blocks of commands which are executed in turn, but switching between these blocks is so fast that for users it seems as if these processes are running simultaneously.
- Parallelism
🔗 References
-
Inter-process communication
A mechanism which allows to exchange data between threads of one or different processes. Processes can be run on the same computer or on different computers connected by a network. Inter-process communication can be done in different ways.
- File
The easiest way to exchange data. One process writes data to a certain file, another process reads the same file and thus receives data from the first process.
- Signal (IPC)
Asynchronous notification of one process about an event which occurred in another process.
- Network socket
In particular, IP addresses and ports are used to communicate between computers using the TCP/IP protocol stack. This pair defines a socket (socket corresponding to the address and port).
- Semaphore
A counter over which only 2 operations can be performed: increasing and decreasing (and for 0 the decreasing operation is blocked).
- Message passing & Message queue
- Pipelines
Redirecting the output of one process to the input of another (similar to a pipe).
- File
🔗 References
Linux Basics
Operating systems based on Linux kernel are the standard in the world of server development, since most servers run on such operating systems. Using Linux on servers is profitable because it is free.
There are a huge number of Linux distributions (preinstalled software bundles) to suit all tastes. One of the most popular is Ubuntu. This is where you can start your dive into server development.
Install Ubuntu on a separate PC or laptop. If this is not possible, you can use a special program Virtual Box where you can run other OS on top of the main OS. You can also run Docker Ubuntu image container (Docker is a separate topic that is exists in this repository).
-
Working with the terminal
Terminal is a program that uses special text commands to control your computer. Generally, servers do not have graphical interfaces, so you will definitely need terminal skills.
- Basic commands for navigating the file system
ls # list directory contents cd <path> # go to specified directory cd .. # move to a higher level (to the parent directory) touch <file> # create a file cat > <file> # enter text into the file (overwrite) cat >> <file> # enter text at the end of the file (append) cat/more/less <file> # to view the file contents head/tail <file> # view the first/last lines of a file pwd # print path to current directory mkdir <name> # create a directory rmdir <name> # delete a directory cp <file> <path> # copy a file or directory mv <file> <path># moving or renaming rm <file> # deleting a file or directory find <string># file system search du <file># output file or directory size - Commands for help information
man <command> # allows you to view a manual for any command apropos <string> # search for a command with a description that has a specified word man -k <string> # similar to the command above whatis <command> # a brief description of the command - Super user rights
Analogue to running as administrator in Windows
sudo <command> # executes a command with superuser privileges - Text editor
Study any in order to read and edit files freely through the terminal. The easiest – nano. The most advanced – Vim.
- Basic commands for navigating the file system
🔗 References
-
Package manager
The Package Manager is a utility that allows you to install/update software packages from the terminal.
Linux distributions can be divided into several groups, depending on which package manager they use: apt (in Debian based distributions), RPM (the Red Hat package management system) and Pacman (the package manager in Arch-like distributions)
Ubuntu is based on Debian, so it uses apt (advanced packaging tool) package manager.
- Basic Commands
apt install <package> # install the package apt remove <package> # remove the package, but keep the configuration apt purge <package> # remove the package along with the configuration apt update # update information about new versions of packages apt upgrade # update the packages installed in the system apt list --installed # list of packages installed on the system apt list --upgradable # list of packages that need to be updated apt search <package> # searching for packages by name on the network apt show <package> # package information
- Basic Commands
🔗 References
-
Bash scripts
You can use scripts to automate the sequential input of any number of commands. In Bash you can create different conditions (branching), loops, timers, etc. to perform all kinds of actions related to console input.
- Basics of Bash Scripts
The most basic and frequently used features such as: variables, I/O, loops, conditions, etc.
- Practice
Solve challenges on sites like HackerRank and Codewars. Start using Bash to automate routine activities on your computer. If you're already a programmer, create scripts to easily build your project, to install settings, and so on.
- ShellCheck script analysis tool
It will point out possible mistakes and teach you best practices for writing really good scripts.
- Additional resources
Repositories such as awesome bash and awesome shell have entire collections of useful resources and tools to help you develop even more skills with Bash and the terminal in general.
- Basics of Bash Scripts
🔗 References
-
Users and groups
Linux-based operating systems are multi-user. This means that several people can run many different applications at the same time on the same computer. For the Linux system to be able to "recognize" a user, he must be logged in and therefore each user must have a unique name and a secret password.
- Working with users
useradd <name> [flags] # create a new user passwd <name> # set a password for the user usermod <name> [flags] # edit a user usermod -L <name> # block a user usermod -U <name> # unblock a user userdel <name> [flags] # delete a user - Working with groups
groupadd <group> [flags] # create a group groupmod <group> [flags] # edit group groupdel <group> [flags] # delete group usermod -a -G <groups> <user> # add a user to groups gpasswd --delete <user> <groups> # remove a user from groups - System files
/etc/passwd # a file containing basic information about users /etc/shadow # a file containing encrypted passwords /etc/group # a file containing basic information about groups /etc/gshadow # a file containing encrypted group passwords
- Working with users
🔗 References
-
Permissions

In Linux, it is possible to share privileges between users, limit access to unwanted files or features, control available actions for services, and much more. In Linux, there are only three kinds of rights - read, write and execute - and three categories of users to which they can be applied - file owner, file group and everyone else.
- Basic commands for working with rights
chown <user> <file> # changes the owner and/or group for the specified files chmod <rights> <file> # changes access rights to files and directories chgrp <group> <file> # allows users to change groups - Extended rights SUID and GUID, sticky bit
- ACL (Access control list)
An advanced subsystem for managing access rights.
- Basic commands for working with rights
🔗 References
-
Working with processes
Linux processes can be described as containers in which all information about the state of a running program is stored. If a program hangs and you need to restore it, then you need the skills to manage the processes.
- Basic Commands
ps # display a snapshot of the processes of all users top # real-time task manager <command> & # running the process in the background, (without occupying the console) jobs # list of processes running in the background fg <PID> # return the process back to the active mode by its number bg <PID> # start a stopped process in the background kill <PID> # terminate the process by PID killall <programm> # terminate all processes related to one program
- Basic Commands
🔗 References
-
Working with SSH
SSH allows remote access to another computer's terminal. In the case of a personal computer, this may be needed to solve an urgent problem, and in the case of a server, it is generally the primary method of connection.
- Basic commands
apt install openssh-server # installing SSH (out of the box almost everywhere) service ssh start # start SSH service ssh stop # stop SSH ssh -p <port> user@remote_host # connecting to a remote PC via SSH ssh-keygen -t rsa # RSA key generation for passwordless login ssh-copy-id -i ~/.ssh/id_rsa user@remote_host # copying a key to a remote machine
- Basic commands
🔗 References
-
Network utils
For Linux there are many built-in and third-party utilities to help you configure your network, analyze it and fix possible problems.
- Simple utils
ip address # show info about IPv4 and IPv6 addresses of your devices ip monitor # real time monitor the state of devices ifconfig # config the network adapter and IP protocol settings traceroute <host> # show the route taken by packets to reach the host tracepath <host> # traces the network host to destination discovering MTU ping <host> # check connectivity to host ss -at # show the list of all listening TCP connections dig <host> # show info about the DNS name server host <host | ip-address> # show the IP address of a specified domain mtr <host | ip-address> # combination of ping and traceroute utilities nslookup # query Internet name servers interactively whois <host> # show info about domain registration ifplugstatus # detect the link status of a local Linux ethernet device iftop # show bandwidth usage ethtool <device name> # show detalis about your ethernet device nmap # tool to explore and audit network security bmon # bandwidth monitor and rate estimator firewalld # add, configure and remove rules on firewall ipref # perform network performance measurement and tuning speedtest-cli # check your network download/upload speed wget <link> # download files from the Internet tcpdumpA console utility that allows you to intercept and analyze all network traffic passing through your computer.
netcatUtility for reading from and writing to network connections using TCP or UDP. It includes port scanning, transferring files, and port listening: as with any server, it can be used as a backdoor.
iptablesUser-space utility program that allows configure the IP packet filter rules of the Linux kernel firewall, implemented as different Netfilter modules. The filters are organized in different tables, which contain chains of rules for how to treat network traffic packets.
curlCommand-line tool for transferring data using various network protocols.
- Simple utils
🔗 References
- 📄 21 Basic Linux Networking Commands You Should Know
- 📄 Using tcpdump Command in Linux to Analyze Network
- 📺 tcpdump - Traffic Capture & Analysis – YouTube
- 📺 tcpdumping Node.js server – YouTube
- 📄 Beginner’s guide to Netcat for hackers
- 📄 Iptables Tutorial
- 📄 An intro to cURL: The basics of the transfer tool
- 📺 Basic cURL Tutorial – YouTube
- 📺 Using curl better - tutorial by curl creator Daniel Stenberg – YouTube
- 📄 Linux Shell Tools for Network
-
Task Scheduler

Schedulers allow you to flexibly manage the delayed running of commands and scripts. Linux has a built-in cron scheduler that can be used to easily perform necessary actions at certain intervals.
-
Main commands
crontab -e # edit the crontab file of the current user crontab -l # output the contents of the current schedule file crontab -r # deleting the current schedule file -
Config files
/etc/crontab # base config /etc/cron.d/ # crontab files used to manage the entire system # config files for automatically run programs: /etc/cron.daily/ # every day /etc/cron.weekly/ # every week /etc/cron.monthly/ # every month
-
🔗 References
-
System logs
Log files are special text files that contain all information about the operation of a computer, program, or user. They are especially useful when bugs and errors occur in the operation of a program or server. It is recommended to periodically review log files, even if nothing suspicious happens.
- Main log files
/var/log/syslog or /var/log/messages # information about the kernel, # various services detected, devices, network interfaces, etc. /var/log/auth.log or /var/log/secure # user authorization information /var/log/faillog # failed login attempts /var/log/dmesg # information about device drivers /var/log/boot.log # operating system boot information /var/log/cron # cron task scheduler report - lnav utility
Designed for easy viewing of log files (highlighting, reading different formats, searching, etc.)
- Log rotation with logrotate
Allows you to configure automatic deletion (cleaning) of log files so as not to clog memory.
- Demon journald
Collects data from all available sources and stores it in binary format for convenient and dynamic control
- Main log files
🔗 References
-
Linux problems
- Problems with commands in the terminal
Occur due to erroneous actions of the user. Often associated with typos, lack of rights, incorrectly specified options, etc.
- Driver problems
All free Linux drivers are built right into its kernel. Therefore, everything should work "out of the box" after installing the system (problems may occur with brand new hardware which has just been released on the market). Drivers whose source code is closed are considered proprietary and are not included in the kernel but are installed manually (like Nvidia graphics drivers).
- Problems with kernel
Kernel panic can occur due to an error when mounting the root file system. This is best helped by the skill of reading the logs to find problems (
dmesgcommand). - Segmentation fault
Occurs when a process accesses invalid memory locations.
- Disk and file system problems
Can occur due to lack of space.
- Problems with commands in the terminal
General knowledge
-
Numeral systems
Numeral system is a set of symbols and rules for denoting numbers. In computer science, it is customary to distinguish four main number systems: binary, octal, decimal, and hexadecimal. It is connected, first of all, with their use in various branches of programming.
- Binary number
The most important system for computing technology. Its use is justified by the fact that the logic of the processor is based on only two states (on/off, open/closed, high/low, true/false, yes/no, high/low).
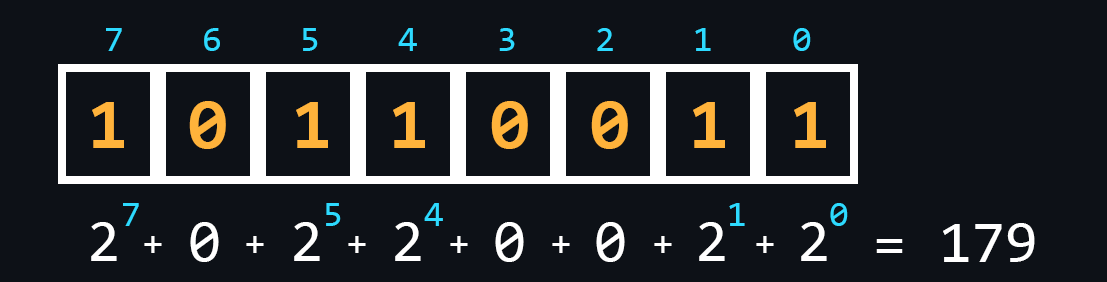
- Octal
It is used e.g. in Linux systems to grant access rights.

- Decimal
A system that is easy to understand for most people.
- Hexadecimal
The letters A, B, C, D, E, F are additionally used for recording. It is widely used in low-level programming and computer documentation because the minimum addressable memory unit is an 8-bit byte, the values of which are conveniently written in two hexadecimal digits.

- Translation between different number systems
You can try online converter for a better understanding.
- Binary number
🔗 References
-
Logical connective
Logical connective are widely used in programming to handle boolean types (true/false or 1/0). The result of a boolean expression is also a value of a boolean type.
AND
a b a AND b 0 0 0 0 1 0 1 0 0 1 1 1 OR
a b a OR b 0 0 0 0 1 1 1 0 1 1 1 1 XOR
a b a XOR b 0 0 0 0 1 1 1 0 1 1 1 0 - Basic logical operations
They are the basis of other all kinds of operations.
There are three in total: Operation AND (&&, Conjunction), operation OR (||, Disjunction), operation NOT (!, Negation). - Operation Exclusive OR (XOR, Modulo 2 Addition)
An important operation that is fundamental to coding theory and computer networks.
- Truth Tables
For logical operations, there are special tables that describe the input data and the return result.
- Priority of operations
The
NOToperator has the highest priority, followed by theANDoperator, and then theORoperator. You can change this behavior using round brackets.
- Basic logical operations
🔗 References
-
Data structures
Data structures are containers in which data is stored according to certain rules. Depending on these rules, the data structure will be effective in some tasks and ineffective in others. Therefore, it is necessary to understand when and where to use this or that structure.
- Array
A data structure that allows you to store data of the same type, where each element is assigned a different sequence number.

- Linked list
A data structure where all elements, in addition to the data, contain references to the next and/or previous element. There are 3 varieties:
- A singly linked list is a list where each element stores a link to the next element only (one direction).
- A doubly linked list is a list where the items contain links to both the next item and the previous one (two directions).
- A circular linked list is a kind of bilaterally linked list, where the last element of the ring list contains a pointer to the first and the first to the last.

- Stack
Structure where data storage works on the principle of last in - first out (LIFO).

- Queue
Structure where data storage is based on the principle of first in - first out (FIFO).

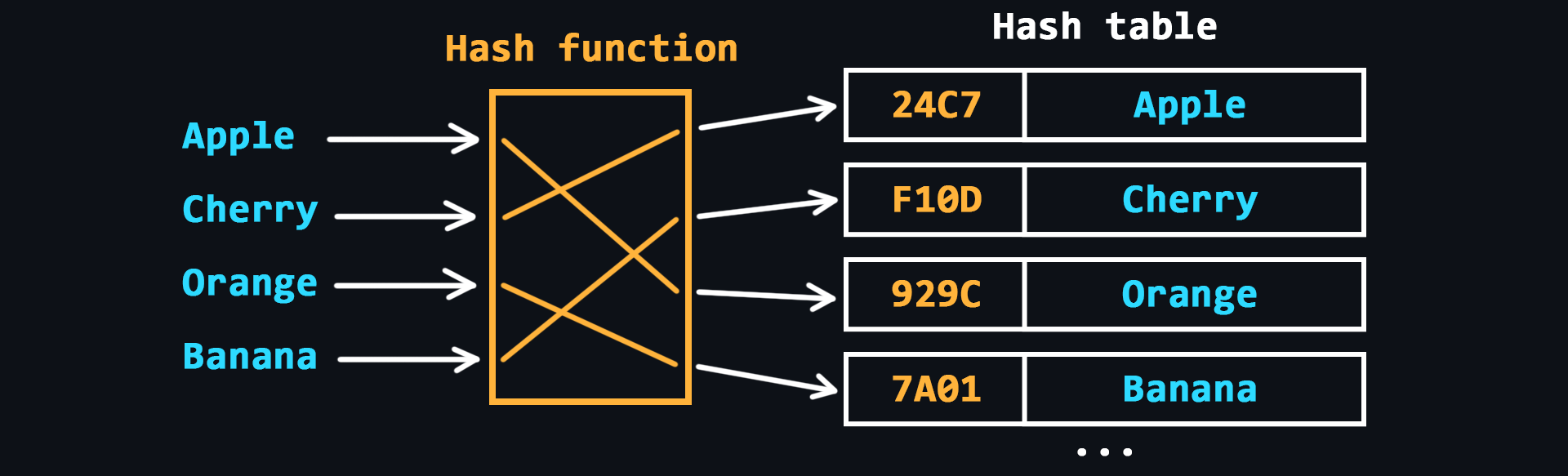
- Hash table
In other words, it is an associative array. Here, each of the elements is accessed with a corresponding key value, which is calculated using hash function according to a certain algorithm.
- Tree
Structure with a hierarchical model, as a set of related elements, usually not ordered in any way.

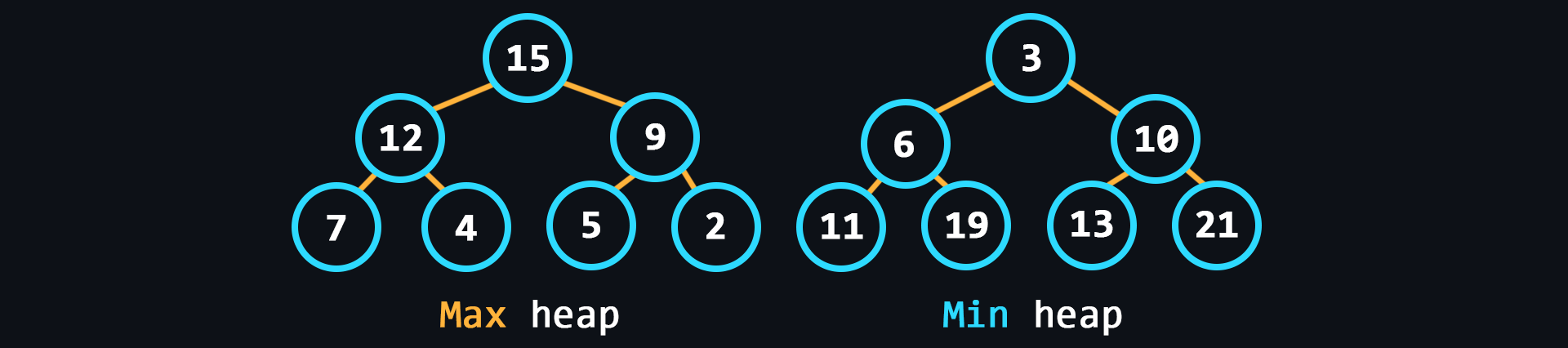
- Heap
Similar to the tree, but in the heap, the items with the largest key is the root node (max-heap). But it may be the other way around, then it is a min heap.
- Graph
A structure that is designed to work with a large number of links.

- Array
🔗 References
- 📺 CS50 2022 - Lecture about Data Structures – YouTube
- 📺 Data Structures Easy to Advanced Course – YouTube
- 📄 Free courses to learn data structures and algorithms in depth – freeCodeCamp
- 📄 Data Structures: collection of topics – GeeksForGeeks
- 📄 JavaScript Data Structures and Algorithms – GitHub
- 📄 Go Data Structures – GitHub
-
Basic algorithms
Algorithms refer to sets of sequential instructions (steps) that lead to the solution of a given problem. Throughout human history, a huge number of algorithms have been invented to solve certain problems in the most efficient way. Accordingly, the correct choice of algorithms in programming will allow you to create the fastest and most resource-intensive solutions.
There is a very good book about algorithms for beginners – Grokking algorithms. You can start learning a programming language in parallel with reading it.
- Binary search
Maximum efficient search algorithm for sorted lists.
- Selection sort
At each step of the algorithm, the minimum element is searched for and then swapped with the current iteration element.
- Recursion
When a function can call itself and so on to infinity. On the one hand, recursion-based solutions look very elegant, but on the other hand, this approach quickly leads to stack overflow and is recommended to be avoided.
- Bubble sort
At each iteration neighboring elements are sequentially compared, and if the order of the pair is wrong, the elements are swapped.
- Quicksort
Improved bubble sorting method.
- Breadth-first search
Allows to find all shortest paths from a given vertex of the graph.
- Dijkstra's algorithm
Finds the shortest paths between all vertices of a graph and their length.
- Greedy algorithm
An algorithm that at each step makes locally the best choice in the hope that the final solution will be optimal.
- Binary search
🔗 References
-
Algorithm complexity

In the world of programming there is a special unit of measure Big O notation. It describes how the complexity of an algorithm increases with the amount of input data. Big O estimates how many actions (steps/iterations) it takes to execute the algorithm, while always showing the worst case scenario.
- Main types of complexity
- Constant O(1) – the fastest.
- Linear O(n)
- Logarithmic O(log n)
- Linearimetric O(n * log n)
- Quadratic O(n^2)
- Stepwise O(2^n)
- Factorical O(!n) – the slowest.
- Constant O(1) – the fastest.
- Time complexity
When you know in advance on which machine the algorithm will be executed, you can measure the execution time of the algorithm. Again, on very good hardware the execution time of the algorithm can be quite acceptable, but the same algorithm on a weaker hardware can run for hundreds of milliseconds or even a few seconds. Such delays will be very sensitive if your application handles user requests over the network.
- Space complexity
In addition to time, you need to consider how much memory is spent on the work of an algorithm. It is important when you working with limited memory resources.
- Main types of complexity
-
Data storage formats
Different file formats can be used to store and transfer data over the network. Text files are human-readable, so they are used for configuration files, for example. But transferring data in text formats over the network is not always rational, because they weigh more than their corresponding binary files.
-
Text formats
- JSON (JavaScript Object Notation)
Represents an object in which data is stored as key-value pairs.
- YAML (Yet Another Markup Language)
The format is close to markup languages like HTML. Minimalist, because it has no opening or closing tags. Easy to edit.
- XML (eXtensible Markup Language)
The format is closer to HTML. Here the data is wrapped in opening and closing tags.
- JSON (JavaScript Object Notation)
-
Binary formats
- Message Pack
Binary analog of JSON. Allows you to pack data 15-20% more efficiently.
- BSON (Binary JavaScript Object Notation)
It is a superset of JSON, including additionally regular expressions, binary data and dates.
- ProtoBuf (Protocol Buffers)
Binary alternative to XML text format. Simpler, more compact and faster.
- Message Pack
-
🔗 References
-
Text encodings
Computers work only with numbers, or more precisely, only with 0 and 1. It is already clear how to convert numbers from different number systems to binary. But you can't do that with text. That's why special tables called encodings were invented, in which text characters are assigned numeric equivalents.
- ASCII (American standard code for information interchange)
The simplest encoding created specifically for the American alphabet. Consists of 128 characters.
- Unicode
This is an international character table that, in addition to the English alphabet, contains the alphabets of almost all countries. It can hold more than a million different characters (the table is currently incomplete).
- UTF-8 (Unicode Transformation Format)
UTF-8 is a variable-length encoding that can be used to represent any unicode character.
- UTF-16
Its main difference from UTF-8 is that its structural unit is not one but two bytes. That is, in UTF-16 any Unicode character can be encoded by either two or four bytes.
- ASCII (American standard code for information interchange)
🔗 References
Programming Language
At this stage you have to choose one programming language to study. There is plenty of information on various languages in the Internet (books, courses, thematic sites, etc.), so you should have no problem finding information.
Below is a list of specific languages that personally, in my opinion are good for backend development (⚠️ may not agree with the opinions of others, including those more competent in this matter).
- Python
A very popular language with a wide range of applications. Easy to learn due to its simple syntax.
- JavaScript
No less popular and practically the only language for full-fledged Web-development. Thanks to the platform Node.js last few years is gaining popularity in the field of backend development as well.
- Go
A language created internally by Google. It was created specifically for high-load server development. Minimalistic syntax, high performance and rich standard library.
- Kotlin
A kind of modern version of Java. Simpler and more concise syntax, better type-safety, built-in tools for multithreading. One of the best choices for Android development.
Find a good book or online tutorial in English at this repository. There is a large collection for different languages and frameworks.
Look for a special awesome repository - a resource that contains a huge number of useful links to materials for your language (libraries, cheat sheets, blogs and other various resources).
-
Classification of programming languages
There are many programming languages. They are all created for a reason. Some languages may be very specific and used only for certain purposes. Also, different languages may use different approaches to writing programs. They may even run differently on a computer. In general, there are many different classifications, which would be useful to understand.
- Depending on language level
- Low level languages
As close to machine code, complex to write, but as productive as possible. As a rule, it provides access to all of the computer's resources.
- High-level languages
They have a fairly high level of abstraction, which makes them easy to write and easy to use. As a rule, they are safer because they do not provide access to all of the computer's resources.
- Low level languages
- Compiled, interpreted and embedded languages
- Compilation
Allows you to convert the source code of a program to an executable file.
- Interpretation
The source code of a program is translated and immediately executed (interpreted) by a special interpreter program.
- Compilation
- Depending on the programming paradigm
- Imperative
Focuses on describing the steps to solve a problem through a sequence of statements or commands.
- Declarative
Focuses on describing what the program should do, rather than how it should do it. Examples of declarative languages include SQL and HTML.
- Functional
Based on the idea of treating computation as the evaluation of mathematical functions. It emphasizes immutability, avoiding side effects, and using higher-order functions. Examples of functional languages include Haskell, Lisp, and Clojure.
- Object-Oriented
Revolves around creating objects that contain both data and behavior, with the goal of modeling real-world concepts. Examples of object-oriented languages include Java, Python, and C++.
- Concurrent
Focused on handling multiple tasks or threads at the same time, and is used in systems that require high performance and responsiveness. Examples of concurrent languages include Go and Erlang.
- Imperative
- Depending on language level
🔗 References
-
Language Basics
By foundations are meant some fundamental ideas present in every language.
- Variables and constants
Are names assigned to a memory location in the program to store some data.
- Data types
Define the type of data that can be stored in a variable. The main data types are integers, floating point numbers, symbols, strings, and boolean.
- Operators
Used to perform operations on variables or values. Common operators include arithmetic operators, comparison operators, logical operators, and assignment operators.
- Flow control
Loops, conditions
if else,switch casestatements. - Functions
Are blocks of code that can be called multiple times in a program. They allow for code reusability and modularization. Functions are an important concept for understanding the scope of variables.
- Data structures
Special containers in which data are stored according to certain rules. Main data structures are arrays, maps, trees, graphs.
- Standard library
This refers to the language's built-in features for manipulating data structures, working with the file system, network, cryptography, etc.
- Error handling
Used to handle unexpected events that can occur during program execution.
- Regular expressions
A powerful tool for working with strings. Be sure to familiarize yourself with it in your language, at least on a basic level.
- Modules
Writing the code of the whole program in one file is not at all convenient. It is much more readable to break it up into smaller modules and import them into the right places.
- Package Manager
Sooner or later, there will be a desire to use third-party libraries.
After mastering the minimal base for writing the simplest programs, there is not much point in continuing to learn without having specific goals (without practice, everything will be forgotten). You need to think of/find something that you would like to create yourself (a game, a chatbot, a website, a mobile/desktop application, whatever). For inspiration, check out these repositories: Build your own x and Project based learning.
At this point, the most productive part of learning begins: You just look for all kinds of information to implement your project. Your best friends are Google, YouTube, and Stack Overflow.
- Variables and constants
🔗 References
- 📄 Free Interactive Python Tutorial
- 📺 Python Tutorial for Beginners – YouTube
- 📄 Python cheatsheet – Learn X in Y minutes
- 📄 Python cheatsheet – quickref.me
- 📄 Free Interactive JavaScript Tutorial
- 📺 JavaScript Programming - Full Course – YouTube
- 📄 The Modern JavaScript Tutorial
- 📄 JavaScript cheatsheet – Learn X in Y minutes
- 📄 JavaScript cheatsheet – quickref.me
- 📄 Go Tour – learn most important features of the language
- 📺 Learn Go Programming - Golang Tutorial for Beginners – YouTube
- 📄 Go cheatsheet – Learn X in Y minutes
- 📄 Go cheatsheet – quickref.me
- 📄 Learn Go by Examples
- 📄 Get started with Kotlin
- 📺 Learn Kotlin Programming – Full Course for Beginners – YouTube
- 📄 Kotlin cheatsheet – Learn X in Y minutes
- 📄 Kotlin cheatsheet – devhints.io
- 📄 Learn Regex step by step, from zero to advanced
- 📄 Projectbook – The Great Big List of Software Project Ideas
-
Object-oriented programming
OOP is one of the most successful and convenient approaches for modeling real-world things. This approach combines several very important principles which allow to write modular, extensible and loosely coupled code.
- Understanding Classes
A class can be understood as a custom data type (a kind of template) in which you describe the structure of future objects that will implement the class. Classes can contain
properties(these are specific fields in which data of a particular data type can be stored) andmethods(these are functions that have access to properties and the ability to manipulate, modify them). - Understanding objects
An object is a specific implementation of a class. If, for example, the name property with type string is described in a class, the object will have a specific value for that field, for example "Alex".
- Inheritance principle
Ability to create new classes that inherit properties and methods of their parents. This allows you to reuse code and create a hierarchy of classes.
- Encapsulation principle
Ability to hide certain properties/methods from external access, leaving only a simplified interface for interacting with the object.
- Polymorphism principle
The ability to implement the same method differently in descendant classes.
- Composition over inheritance
Often the principle of
inheritancecan complicate and confuse your program if you do not think carefully about how to build the future hierarchy. That is why there is an alternative (more flexible) approach called composition. In particular, Go language lacks classes and many OOP principles, but widely uses composition.
- Understanding Classes
🔗 References
- 📺 Intro to Object Oriented Programming - Crash Course – YouTube
- 📄 OOP Meaning – What is Object-Oriented Programming? – freeCodeCamp
- 📺 OOP in Python (CS50 lecture) – YouTube
- 📄 OOP tutorial from Python docs
- 📺 OOP in JavaScript: Made Super Simple – YouTube
- 📄 OOP in Go by examples
- 📺 Object Oriented Programming is not what I thought - Talk by Anjana Vakil – YouTube
- 📺 The Flaws of Inheritance (tradeoffs between Inheritance and Composition) – YouTube
-
Server development
- Creating and running a local HTTP server
- Handing out static files
Hosting HTML pages, pictures, PDFs, etc.
- Routing
Creation of endpoints (URLs) which will call the appropriate handler on the server when accessed.
- Processing requests
As a rule, HTTP handlers have a special object which receives all information about user request (headers, method, request body, full url with parameters, etc.)
- Processing responses
Sending an appropriate message to a received request (HTTP status and code, response body, headers, etc.)
- Error handling
You should always consider cases where the user could send invalid data, the database failed to execute the operation, or an unexpected error occurred in the application, so that the server does not crash but responds with an error message.
- Sending requests
Often, within one application, you will need to access another application over the network. That's why it's important to be able to send HTTP requests using the built-in features of the language.
- Template processor
Is a special module that uses a more convenient syntax to generate HTML based on dynamic data.
🔗 References
- 📄 Learn Django – Python-based web framework
- 📺 Python Django 7 Hour Course – YouTube
- 📄 A curated list of awesome things related to Django – GitHub
- 📺 Build servers in pure Node.js – YouTube
- 📄 Learn Express – web framework for Node.js
- 📺 Express.js 2022 Course – YouTube
- 📄 A curated list of awesome Express.js resources – GitHub
- 📄 How to build servers in Go
- 📺 Golang server development course – YouTube
- 📄 List of libraries for working with network in Go – GitHub
- 📄 Learn Ktor – web framework for Kotlin
- 📺 Ktor - REST API Tutorials – YouTube
- 📄 Kotlin for server side
-
Multithreading
Computers today have processors with several physical and virtual cores, and if we take into account server machines, their number can reach up to hundreds. All of these available resources would be good to use to the fullest, for maximum application performance. That is why modern server development cannot do without implementing multithreading and paralleling.
- Race conditions & data races
The main problems that arise when using multithreading.
- Creating processes
- Creating threads
- Corutines
Lightweight code execution threads organized on top of operating system threads. They can exist as separate libraries or be already built into the kernel.
- Linearizability
Operations that are performed completely, or not performed at all.
- Lockouts
Using semaphores and mutexes to synchronize data.
- Race conditions & data races
🔗 References
- 📺 Multithreading Code - Computerphile – YouTube
- 📺 Threading vs multiprocessing in Python – YouTube
- 📺 When is NodeJS Single-Threaded and when is it Multi-Threaded? – YouTube
- 📺 How to use Multithreading with "worker threads" in Node.js? – YouTube
- 📺 Concurrency in Go – YouTube
- 📺 Kotlin coroutines – YouTube
-
Advanced Topics
- Garbage collector
A process that has made high-level languages very popular - it allows the programmer not to worry about memory allocation and freeing. Be sure to familiarize yourself with the subtleties of its operation in your own language.
- Debuger
Handy tool for analyzing program code and identifying errors.
- Garbage collector
🔗 References
-
Code quality
During these long years that programming has existed, a huge amount of code, programs and entire systems have been written. And as a consequence, there have been all sorts of problems in the development of all this. First of all they were related to scaling, support, and the entry threshold for new developers. Clever people, of course, did not sit still and started to solve these problems, thus creating so-called patterns/principles/approaches for writing high-quality code.
By learning programming best practices, you will not only make things better for yourself, but also for others, because other developers will be working with your code.
- DRY (Don't Repeat Yourself)
- KISS (Keep It Simple, Stupid)
- YAGNI (You Aren't Gonna Need It)
- SOLID principles
- GRASP (General Responsibility Assignment Software Patterns)
For many languages there are special style guides and coding conventions. They usually compare the right and wrong way of writing code and explain why this is the case.
🔗 References
- 📄 KISS, SOLID, YAGNI And Other Fun Acronyms
- 📺 Naming Things in Code – YouTube
- 📺 Why You Shouldn't Nest Your Code – YouTube
- 📺 Why you shouldn't write comments in your code – YouTube
- 📺 Uncle Bob SOLID principles – YouTube
- 📄 SOLID Principles explained in Python – medium
- 📄 SOLID Principles in JavaScript – freeCodeCamp
- 📄 Google style guides – GitHub
Databases
Databases (DB) – a set of data that are organized according to certain rules (for example, a library is a database for books).
Database management system (DBMS) is a software that allows you to create a database and manipulate it conveniently (perform various operations on the data). An example of a DBMS is a librarian. He can easily and efficiently work with the books in the library: give out requested books, take them back, add new ones, etc.
-
Database classification
Databases can differ significantly from each other and therefore have different areas of application. To understand what database is suitable for this or that task, it is necessary to understand the classification.
- Relational DB
These are repositories where data is organized as a set of tables (with rows and columns). Interactions between data are organized on the basis of links between these tables. This type of database provides fast and efficient access to structured information.
- Object-oriented DB
Here data is represented as objects with a set of attributes and methods. Suitable for cases where you need high-performance processing of data with a complex structure.
- Distributed DB
Composed of several parts located on different computers (servers). Such databases may completely exclude information duplication, or completely duplicate it in each distributed copy (for example, as Blockchain).
- NoSQL
Stores and processes unstructured or weakly structured data. This type of database is subdivided into subtypes:
- Key–value DB
- Column family DB
- Document-oriented DB (store data as a hierarchy of documents)
- Graph DB (are used for data with a large number of links)
- Key–value DB
- Relational DB
🔗 References
-
Relational database
The most popular relational databases: MySQL, PostgreSQL, MariaDB, Oracle. A special language SQL (Structured Query Language) is used to work with these databases. It is quite simple and intuitive.
- SQL basics
Learn the basic cycle of creating/receiving/updating/deleting data. Everything else as needed.
- Merging tables
- Querying data from multiple tables
Operator
JOIN; Combinations with other operators;JOINtypes. - Relationships between tables
References from one table to another; foreign keys.
- Querying data from multiple tables
- Subquery Expressions
Query inside another SQL query.
- Indexes
Data structure that allows you to quickly determine the position of the data of interest in the database.
- Transactions
Sequences of commands that must be executed completely, or not executed at all.
- Command
START TRANSACTION - Commands
COMMITandROLLBACK
- Command
- Working with a programming language
To do this, you need to install a database driver (adapter) for your language. (For example psycopg2 for Python, node-postgres for Node.js, pgx for Go)
- ORM (Object-Relational Mapping) libraries
Writing SQL queries in code is difficult. It's easy to make mistakes and typos in them, because they are just strings that are not validated in any way. To solve this problem, there are so-called ORM libraries, which allow you to execute SQL queries as if you were simply calling methods on an object. Unfortunately, even with them all is not so smooth, because "under the hood" queries that are generated by these libraries are not the most optimal in terms of performance (so be prepared to work with ORM, as well as with pure SQL).
Popular ORMs: SQLAlchemy for Python, Sequelize for Node.js, GORM for Go. - Optimization and performance
- SQL basics
🔗 References
- 📺 SQL Crash Course - Beginner to Intermediate – YouTube
- 📺 SQL Tutorial - Full Database Course for Beginners – YouTube
- 📺 MySQL - The Basics. Learn SQL in 23 Easy Steps – YouTube
- 📄 MySQL command-line client commands
- 📺 Learn PostgreSQL Tutorial - Full Course for Beginners – YouTube
- 📄 Postgres Cheat Sheet
- 📺 Database Indexing Explained (with PostgreSQL) – YouTube
- 📄 SQL Indexing and Tuning e-Book
- 📺 What is a Database transaction? – YouTube
- 📺 SQL Server Performance Essentials – Full Course – YouTube
- 📺 ORM: The Good, the Great, and the Ugly – YouTube
- 📺 I Would Never Use an ORM, by Matteo Collina – YouTube
- 📄 Awesome SQL – GitHub
-
MongoDB
MongoDB is a popular NoSQL database that stores data in flexible, JSON-like documents, allowing for dynamic and scalable data structures. It offers high performance, horizontal scalability, and a powerful query language, making it a preferred choice for modern web applications.
- Basic commands
Learn the basic cycle of creating/reading/updating/deleting data. Everything else as needed.
- Aggregations
MongoDB provides a powerful aggregation framework for performing complex queries and calculations. Learn how to use aggregation pipelines.
- Working with Indexes
Indexing is an important concept in MongoDB for improving performance.
- Working with a programming language
For this you need to install MongoDB driver for your language.
- Best practices
Learn best practices for schema design, indexing, and query optimization. Read up on these to ensure your applications are performant and scalable.
- Scaling
Learn about scaling to handle large datasets and high traffic. MongoDB provides sharding and replica sets for scaling horizontally and vertically.
- Basic commands
🔗 References
-
Redis
Redis is a fast data storage working with key-value structures. It can be used as a database, cache, message broker or queue.
- Data types
String / Bitmap / Bitfield / List / Set / Hash / Sorted sets / Geospatial / Hyperlog / Stream
- Basic operations
SET key "value" # setting the key with the value "value" GET key # retrieve a value from the specified key SETNX key "data" # setting the value / creation of a key MSET key1 "1" key2 "2" key3 "3" # setting multiple keys MGET key1 key2 key3 # getting values for several keys at once DEL key # remove the key-value pair INCR someNumber # increase the numeric value by 1 DECR someNumber # decrease the numeric value by 1 EXPIRE key 1000 # set a key life timer of 1000 seconds TTL key # get information about the lifetime of the key-value pair # -1 the key exists, but has no expiration date # -2 the key does not exist # <another number> key lifetime in seconds SETEX key 1000 "value" # consolidation of commands SET and EXPIRE - Transactions
MULTI— start recording commands for the transaction.
EXEC— execute the recorded commands.
DISCARD— delete all recorded commands.
WATCH— command that provides execution only if other clients have not changed the value of the variable. Otherwise EXEC will not execute the written commands.
- Data types
🔗 References
-
ACID Requirements
ACID is an acronym consisting of the names of the four main properties that guarantee the reliability of transactions in the database.
- Atomicity
Guarantees that the transaction will be executed completely or not executed at all.
- Consistency
Ensures that each successful transaction captures only valid results (any inconsistencies are excluded).
- Isolation
Guarantees that one transaction cannot affect the other in any way.
- Durability
Guarantees that the changes made by the transaction are saved.
- Atomicity
🔗 References
-
Designing databases
Database design is a very important topic that is often overlooked. A well-designed database will ensure long-term scalability and ease of data maintenance. There are several basic steps in database design:
- Definition of entities
An entity is an object, concept, or event that has its own set of attributes. For example, if you're designing a database for a library, entities might include books, authors, publishers, and borrowers.
- Define the attributes to each entity
Each entity has a set of specific attributes. For example, attributes of a book might include its title, author, ISBN, and publication date. Each attribute has a specific data type, be it a string, an integer, a boolaen, and so on.
- Add constraints
Attribute values may have certain limitations. For example, strings can only be unique or have a limit on the maximum number of characters.
- Define relationships
Entities can be linked to one another by one type of relationship: one to one, one to many or many to many. For example, a book might have one or more authors, and an author might write one or more books. You can represent these relationships by creating a foreign key in one table that references the primary key in another table.
- Normalization
It is the process of separating data into separate related tables. Normalization eliminates data redundancy and thus avoids data integrity violations when data changes.
- Optimize for performance
Create indexes on frequently queried columns, tune the database configuration, and optimize the queries that you use to access the data.
- Definition of entities
🔗 References
API development
API (Application Programming Interface) an interface which describes a certain set of rules by which different programs (applications, bots, websites...) can interact with each other. With API calls you can execute certain functions of a program without knowing how it works.
When developing server applications, different API formats can be used, depending on the tasks and requirements.
-
REST API
REST (Representational State Transfer) an architectural approach that describes a set of rules for how a programmer organizes the writing of server application code so that all systems can easily exchange data and the application can be easily scaled. When building a REST API, HTTP protocol methods are widely used.
Basic rules for writing a good REST API:
- Using HTTP methods
As a rule, a single URL route is used to work on a particular data model (e.g. for users -
/api/user). To perform different operations (get/create/edit/delete), this route must implement handlers for the corresponding HTTP methods (GET/POST/PUT/DELETE). - Use of plural names
For example, a URL to retrieve one user by id looks like this:
/user/42, and to retrieve all users like this:/users. - Sending the appropriate HTTP response codes
The most commonly used: 200, 201, 204, 304, 400, 401, 403, 404, 405, 410, 415, 422, 429.
- Versioning
Over time you may want or need to fundamentally change the way your REST API service works. To avoid breaking applications using the current version, you can leave it where it is and implement the new version over a different URL route, e.g.
/api/v2.
- Using HTTP methods
🔗 References
- 📄 What Is Restful API? – AWS
- 📺 What is REST API? – YouTube
- 📺 APIs for Beginners 2023 - How to use an API (Full Course) – YouTube
- 📺 Build Web APIs with Python – Django REST Framework Course – YouTube
- 📺 Build an API from Scratch with Node.js Express – YouTube
- 📺 Build REST API on Vanilla Node.js – YouTube
- 📺 Build a Rest API with GoLang – YouTube
- 📺 Spring Kotlin - Building a Rest API Tutorial – YouTube
- 📄 REST API design full guide – GitHub
- 📄 Awesome REST – GitHub
-
GraphQL
GraphQL is a query language and server-side runtime for APIs that allows you to retrieve and modify data from a server using a single URL endpoint. It provides several benefits, including the ability to retrieve only the data you need (reducing traffic consumption), aggregation of data from multiple sources and a strict type system for describing data.
- Schema and types
Learn how to describe data using GraphQL schema and general types.
- Queries and Mutations
Queries are used to retrieve data from a server, while Mutations are used to modify (create, update or delete) data on a server.
- Resolvers
Resolvers are functions that determine how to retrieve the data for a particular field in the GraphQL schema.
- Data sources
Are places where you retrieve data from, such as databases or APIs. Data sources are connected to the GraphQL server through resolvers.
- Performance optimization
- Best Practices
- Schema and types
🔗 References
-
WebSockets
WebSockets is an advanced technology that allows you to open a persistent bidirectional network connection between the client and the server. With its API you can send a message to the server and receive a response without making an HTTP request, thereby implementing real-time communication.
The basic idea is that you do not need to send requests to the server for new information. When the connection is established, the server itself will send a new batch of data to connected clients as soon as that data is available. Web sockets are widely used to create chat rooms, online games, trading applications, etc.
- Opening a web socket
Sending an HTTP request with a specific set of headers:
Connection: Upgrade,Upgrade: websocket,Sec-WebSocket-Key,Sec-WebSocket-Version. - Connection states
CONNECTING,OPEN,CLOSING,CLOSED. - Events
Open,Message,Error,Close. - Connection closing codes
1000,1001,1006,1009,1011, etc.
- Opening a web socket
🔗 References
- 📺 A Beginner's Guide to WebSockets – YouTube
- 📺 WebSockets Crash Course - Handshake, Use-cases, Pros & Cons and more – YouTube
- 📄 Introducing WebSockets - Bringing Sockets to the Web
- 📺 WebSockets with Python tutorial – YouTube
- 📺 WebSockets with Node.js tutorial – YouTube
- 📺 WebSockets with Go tutorial – YouTube
- 📄 Awesome WebSockets – GitHub
-
RPC (Remote Procedure Call)
RPC is simply a function call to the server with a set of specific arguments, which returns the response usually encoded in a certain format, such as JSON or XML. There are several protocols that implement RPC.
- XML-based protocols
The are two main protocols: XML-RPC and SOAP (Simple Object Access Protocol)
They are considered deprecated and not recommended for new projects because they are heavyweight and complex compared to newer alternatives such as REST, GraphQL and newer RPC protocols. - JSON-RPC
A protocol with a very simple specification. All requests and responses are serialized in JSON format.
- A request to the server includes:
method- the name of the method to be invoked;params- object or array of values to be passed as parameters to the defined method;id- identificator used to match the response with the request. - A response includes:
result- data returned by the invoked method;error- object with error or null for success;id- the same as in the request.
- A request to the server includes:
- gRPC
RPC framework developed by Google. It works by defining a service using Protocol Buffers, a language-agnostic binary serialization format, that generates to client and server code for various programming languages.
- Understand protobuf fundamentals.
- See turorials for your language: Python, Node.js, Go, Kotlin, etc.
- Learn style guides.
- XML-based protocols
🔗 References
- 📺 What is RPC? gRPC Introduction – YouTube
- 📄 Learning gRPC with an Example
- 📺 gRPC Crash Course - Modes, Examples, Pros & Cons and more – YouTube
- 📺 This is why gRPC was invented – YouTube
- 📺 gRPC with Python - microservice complete tutorial – YouTube
- 📺 Implementing a gRPC client and server in Typescript with Node.js – YouTube
- 📺 Build a gRPC server with Go - Step by step tutorial – YouTube
- 📄 Awesome gRPC – GitHub
-
WebRTC
WebRTC an open-source project for streaming data (video, audio) in a browser. WebRTC operation is based on peer to peer connection, however, there are implementations that allow you to organize complex group sessions. For example, the video-calling service Google Meet makes extensive use of WebRTC.
🔗 References
Software
-
Git version control system
Git a special system for managing the history of changes to the source code. Any changes that are made to Git can be saved, allowing you to rollback (revert) to a previously saved copy of the project. Git is currently the standard for development.
- Basic commands
git init # initialize Git in the current folder git add [file] # add a file to Git git add . # add all the files in the folder to Git git reset [file] # cancel the addition of the specified file git reset # cancel the addition of all files git commit -m "your message" # create a commit (save) git status # shows the status of added files git push # send current commits to a remote repository git pull # load changes from a remote repository git clone [link] # clone the specified repository to your PC - Working with branches
Branching allows you to deviate from the main branch of development and continue to work independently.
git branch # show a list of current threads git branch [name] # create a new branch from the current commit git checkout [name] # create a new branch from the current commit git merge [name] # merge the specified branch into the current branch git branch -d [name] # delete the specified branch - Cancel commits
git revert HEAD --no-edit # create a new commit that overrides the changes of the previous one git revert [hash] --no-edit # the same action, but with the specified commit - Log history
git log [branch] # show the commits of the specified branch git log -3 # show the last 3 commits of the current branch git log [file] # show the commit history of the specified file
- Basic commands
🔗 References
-
Docker
Docker a special program that allows you to run isolated sandboxes (containers) with different preinstalled environments (be it a specific operating system, a database, etc.). Containerization technology, that Docker provides is similar to virtual machines, but unlike virtual machines, containers use the host OS kernel, which requires far fewer resources.
- Docker image
A special fixed template that contains a description of the environment to run the application (OS, source code, libraries, environment variables, configuration files, etc.). The images can be downloaded from official site and used to create your own.
- Docker container
An isolated environment created from an image. It is essentially a running process on a computer which internally contains the environment described in the image.
- Console commands
docker pull [image_name] # Download the image docker images # List of available images docker run [image_id] # Running a container based on the selected image # Some flags for the run command: -d # Starting with a return to the console --name [name] # Name the container --rm # Remove the container after stopping -p [local_port][port_iside_container] # Port forwarding docker build [path_to_Dockerfile] # Creating an image based on a Dockerfile docker ps # List of running containers docker ps -a # List of all containers docker stop [id/container_name] # Stop the container docker start [id/container_name] # Start an existing container docker attach [id/container_name] # Connect to the container console docker logs [id/container_name] # Output the container logs docker rm [id/container_name] # Delete container docker container prune # Delete all containers docker rmi [image_id] # Delete image - Instructions for Dockerfile
Dockerfile is a file with a set of instructions and arguments for creating images.
FROM [image_name] # Setting a base image WORKDIR [path] # Setting the root directory inside the container COPY [path_relative_Dockefile] [path_in_container] # Copying files ADD [path] [path] # Similar to the command above RUN [command] # A command that runs only when the image is initialized CMD ["command"] # The command that runs every time you start the container ENV KEY="VALUE" # Setting Environment Variables ARG KEY=VALUE # Setting variables to pass to Docker during image building ENTRYPOINT ["command"] # The command that runs when the container is running EXPOSE port/protocol # Indicates the need to open a port VOLUME ["path"] # Creates a mount point for working with persistent storage - Docker-compose
A tool for defining and running multi-container Docker applications. It allows you to define the services that make up your application in a single file, and then start and stop all of the services with a single command. In a sense, it is a Dockerfile on maximal.
- Docker image
🔗 References
- 📺 Learn Docker in 7 Easy Steps - Full Beginner's Tutorial – YouTube
- 📺 Docker Crash Course Tutorial (playlist) – YouTube
- 📄 The Ultimate Docker Cheat Sheet
- 📺 Docker Compose Tutorial – YouTube
- 📺 Docker networking – everything you need to know – YouTube
- 📄 Developing Inside a Container
- 📄 Awesome Docker – GitHub
-
Postman/Insomnia
When creating a server application, it is necessary to test its performance. This can be done in different ways. One of the easiest is to use the console utility curl. But this is good for very simple applications. Much more efficient is to use special software for testing, which have a user-friendly interface and all the necessary functionality to create collections of queries.
- Postman
A very popular and feature-rich program. It definitely has everything you might need and more: from the trivial creation of collections to raising mock-servers. The basic functionality of the application is free of charge.
- Insomnia
Not as popular, but a very nice tool. The interface in Insomnia, minimalist and clear. It has less functionality, but everything you need: collections, variables, work with GraphQL, gRPC, WebSocket, etc. It is possible to install third-party plugins.
- Postman
🔗 References
-
Web servers
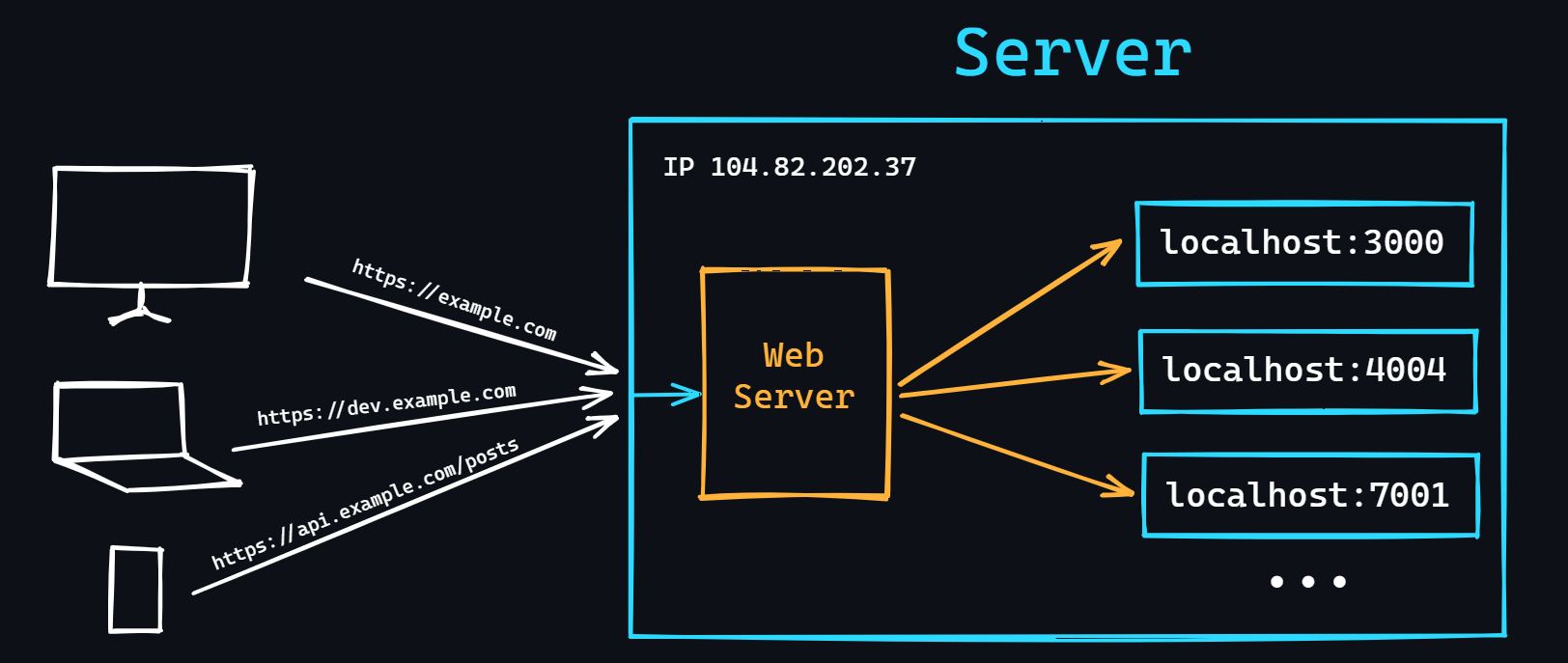
A web server is a program designed to handle incoming HTTP requests. In addition, it can keep error logs (logs), perform authentication and authorization, store rules for file processing, etc.
- What is it for?
- Not all languages can have a built-in web server (e.g. PHP). Therefore, to run web applications written in such languages, a third-party one is needed.
- A single server (virtual or dedicated) can run several applications, but only one external IP address. A configured web server solves this problem and can redirect incoming requests to the right applications.
- Popular web servers
- What is it for?
🔗 References
- 📺 What are web servers and how do they work – YouTube
- 📺 Web Server Concepts and Examples – YouTube
- 📺 The NGINX Crash Course – YouTube
- 📺 Nginx Server Complete Course – YouTube
- 📄 6 Best Courses to learn Nginx in depth – medium
- 📄 NGINX: Advanced Load Balancer, Web Server, & Reverse Proxy – dev.to
- 📄 Awesome NGINX – GitHub
-
Message brokers

When creating a large-scale backend system, the problem of communication between a large number of microservices may arise. In order not to complicate existing services (establish a reliable communication system, distribute the load, provide for various errors, etc.) you can use a separate service, which is called a message broker (or message queue).
The broker takes the responsibility of creating a reliable and fault-tolerant system of communication between services (performs balancing, guarantees delivery, monitors recipients, maintains logs, buffering, etc.)
A message is an ordinary HTTP request/response with data of a certain format.
🔗 References
-
Ngrok
Ngrok is a tool for creating public tunnels on the internet that allows local network applications (web servers, web services, etc.) to be accessible from outside.
- How does it work?
Ngrok creates a temporary public URL that can be used to access your local server from the Internet. Once Ngrok is started, you have access to the console, where you can monitor requests, handling and responses to those requests, and configure additional features such as authentication and encryption.
- What to use it for?
For example, to test web sites and APIs, to demonstrate running applications on a local server, to access local network applications over the Internet without having to set up a router, firewall, proxy server, etc.
- How does it work?
🔗 References
Security
-
Web application vulnerabilities
- Cross-site scripting (XSS)
An attack that allows an attacker to inject malicious code through a website into the browsers of other users.
- SQL injection
An attack is possible if the user input that is passed to the SQL query is able to change the meaning of the statement or add another query to it.
- Cross-site request forgery (CSRF)
When a site uses a POST request to perform a transaction, the attacker can forge a form, such as in an email, and send it to the victim. The victim, who is an authorized user interacting with this email, can then unknowingly send a request to the site with the data that the attacker has set.
- Clickjacking
The principle is based on the fact that an invisible layer is placed on top of the visible web page, in which the page the intruder wants is loaded, while the control (button, link) needed to perform the desired action is combined with the visible link or button the user is expected to click on.
- Denial of Service (DoS attack)
A hacker attack that overloads the server running the web application by sending a huge number of requests.
- Man-in-the-Middle attack
A type of attack in which an attacker gets into the chain between two (or more) communicating parties to intercept a conversation or data transmission.
- Incorrect security configuration
Using default configuration settings can be dangerous because it is common knowledge. For example, a common vulnerability is that network administrators leave the default logins and passwords admin:admin.
- Cross-site scripting (XSS)
🔗 References
- 📺 7 Security Risks and Hacking Stories for Web Developers – YouTube
- 📄 Top 10 Web Application Security Risks
- 📺 Web App Vulnerabilities - DevSecOps Course for Beginners – YouTube
- 📺 DDoS Attack Explained – YouTube
- 📺 Securing Web Applications – MIT lecture – YouTube
- 📺 Scan for Vulnerabilities on Any Website Using Nikto – YouTube
-
Environment variables
Often your applications may use various tokens (e.g. to access a third-party paid API), logins and passwords (to connect to a database), various secret keys for signatures and so on. All this data should not be known and available to outsiders, so you can't leave them in the program code in any case. To solve this problem, there are environment variables.
- The
.envfileA special file in which you can store all environment variables.
- Parsing the
.envfileVariables are passed to the program using command line arguments. To do the same with the
.envfile, you need to use a special library for your language. - Storage and transfer
.envfilesLearn how to upload
.envfiles to the hosting services and remember that such files cannot be commited to remote repositories, so do not forget to add them to exceptions via the.gitignorefile.
- The
🔗 References
-
Hashing

Cryptographic algorithms based on hash functions are widely used for network security.
- Hashing
The process of converting an array of information (from a single letter to an entire literary work) into a unique short string of characters (called hash), which is unique to that array of information. Moreover, if you change even one character in this information array, the new hash will differ dramatically.
Hashing is an irreversible process, that is, the resulting hash cannot be recovered from the original data. - Checksums
Hashes can be used as checksums that serve as proof of data integrity.
- Collisions
Cases where hashing different sets of information results in the same hash.
- Salt (in cryptography)
A random string of data, which is added to the input data before hashing, to calculate the hash. This is necessary to make brute-force hacking more difficult.
Popular encryption algorithms:
- SHA family (Secure Hash Algorithm)
SHA-256 is the most popular encryption algorithm. It is used, for example, in Bitcoin.
- MD family (Message Digest)
The most popular algorithm of the family is MD5. It is now considered very vulnerable to collisions (there are even collision generators for MD5).
- BLAKE family
- RIPEMD family
- Streebog
- Hashing
🔗 References
-
Authentication and authorization
Authentication is a procedure that is usually performed by comparing the password entered by the user with the password stored in the database. Also, this often includes identification - a procedure for identifying the user by his unique identifier (usually a regular login or email). This is needed to know exactly which user is being authenticated.
Authorization - the procedure of granting access rights to a certain user to perform certain operations. For example, ordinary users of the online store can view products and add them to cart. But only administrators can add new products or delete existing ones.
- Basic Authentication
The simplest authentication scheme where the username and password of the user are passed in the Authorization header in unencrypted (base64-encoded) form. It is relatively secure when using HTTPS.
- SSO (Single Sign-On)
Technology that implements the ability to move from one service to another (not related to the first), without reauthorization.
- OAuth / OAuth 2.0
Authorization protocol, which allows you to register in various applications using popular services (Google, Facebook, GitHub, etc.)
- OpenID
An open standard that allows you to create a single account for authenticating to multiple unrelated services.
- JWT (Json Web Token)
An authentication standard based on access tokens. Tokens are created by the server, signed with a secret key and transmitted to the client, who then uses the token to verify his identity.
- Basic Authentication
🔗 References
-
SSL/TLS
SSL (Secure Socket Layer) and TLS (Transport Layer Security) are cryptographic protocols that allow secure transmission of data between two computers on a network. These protocols work essentially the same and there are no differences. SSL is considered obsolete, although it is still used to support older devices.
- Certificate Authority (CA)
TLS/SSL uses digital certificates issued by a certificate authority. One of the most popular is Let’s Encrypt.
- Certificate configuration and installation
You need to know how to generate certificates and install them properly to make your server work over HTTPS.
- Handshake process
To establish a secure connection between the client and the server, a special process must take place which includes the exchange of secret keys and information about encryption algorithms.
- Certificate Authority (CA)
🔗 References
Testing
Testing is the process of assessing that all parts of the program behave as expected of them. Covering the product with the proper amount of testing, allows you to quickly check later to see if anything in the application is broken after adding new or changing old functionality.
-
Unit Tests
The simplest kind of tests. As a rule, about 70-80% of all tests are exactly unit-tests. "Unit" means that not the whole system is tested, but small and separate parts of it (functions, methods, components, etc.) in isolation from others. All dependent external environment is usually covered by mocks.
- What are the benefits of unit tests?
To give you an example, let's imagine a car. Its "units" are the engine, brakes, dashboard, etc. You can check them individually before assembly and, if necessary, replace or repair them. But you can assemble the car without having tested the units, and it will not go. You will have to disassemble everything and check every detail.
- What do I need to start writing unit tests?
As a rule, the means of the standard language library are enough to write quality tests. But for more convenient and faster writing of tests, it is better to use third-party tools. For example:
- For Python it uses pytest, although the standard unittest is enough to start with.
- For JavaScript/TypeScript, the best choices are Jest.
- For Go – testify.
- And so on...
- What are the benefits of unit tests?
🔗 References
-
Integration tests
Integration testing involves testing individual modules (components) in conjunction with others (that is, in integration). What was covered by a stub during Unit testing is now an actual component or an entire module.
- Why it's needed?
Integration tests are the next step after units. Having tested each component individually, we cannot yet say that the basic functionality of the program works without errors. Potentially, there may still be many problems that will only surface after the different parts of the program interact with each other.
- Strategies for writing integration tests
- Big Bang: Most of the modules developed are connected together to form either the whole system or most of it. If everything works, you can save a lot of time this way.
- incremental approach: By connecting two or more logically connected modules and then gradually adding more and more modules until the whole system is tested.
- Bottom-up approach: each module at lower levels is tested with the modules of the next higher level until all modules have been tested.
- Why it's needed?
🔗 References
-
E2E tests
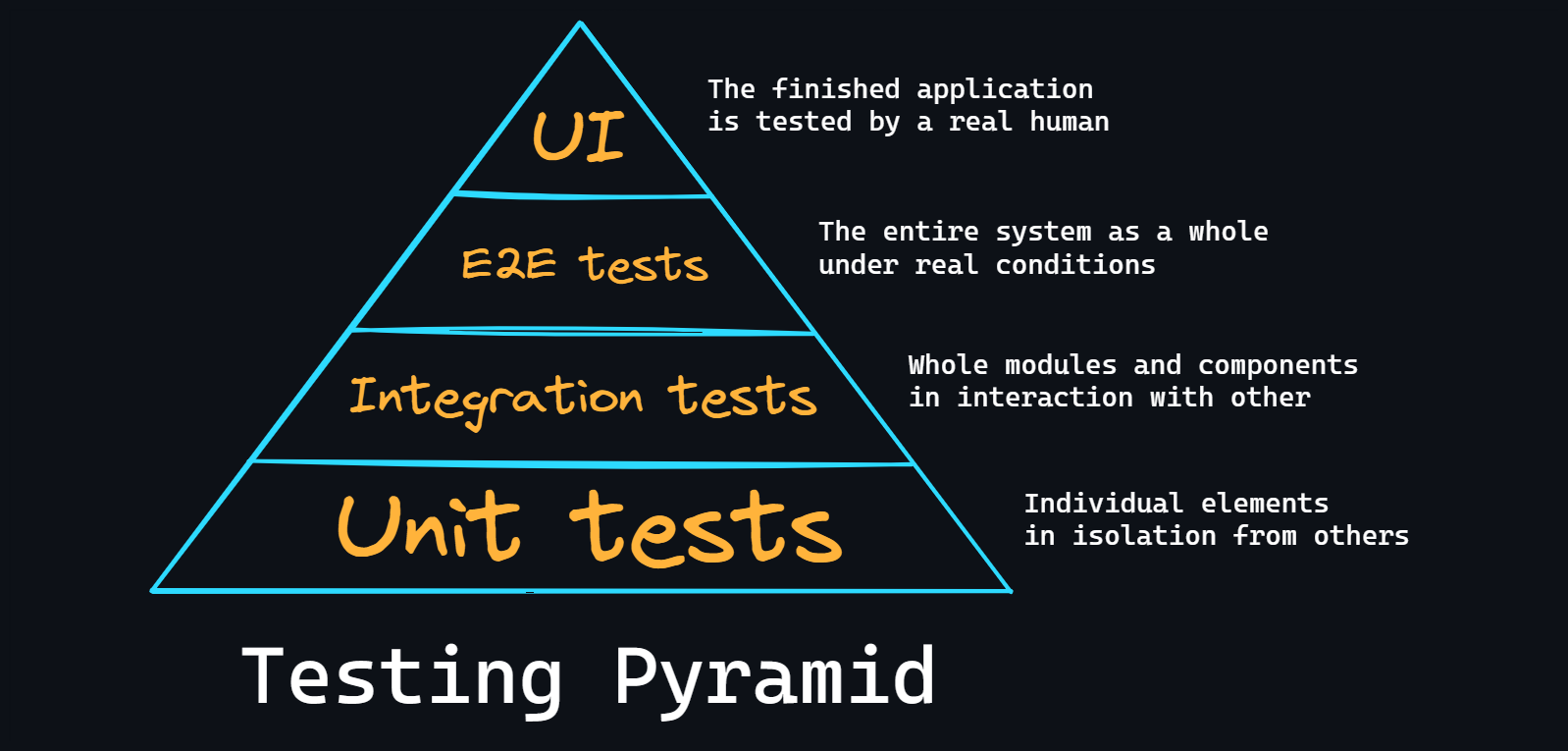
End-to-end tests imply checking the operation of the entire system as a whole. In this type of testing, the environment is implemented as close to real-life conditions as possible. We can draw the analogy that a robot sits at the computer and presses the buttons in the specified order, as a real user would do.
- When to use?
E2E is the most complex type of test. They take a long time to write and to execute, because they involve the whole application. So if your application is small (e.g. you are the only one developing it), writing Unit and some integration tests will probably be enough.
- When to use?
🔗 References
- 📄 What is End-to-End Testing and When Should You Use It? – freeCodeCamp
- 📺 End to End Testing - Explained – YouTube
- 📺 Testing Node.js Server with Jest and Supertest – YouTube
- 📺 End to End - Test Driven Development (TDD) to create a REST API in Go – YouTube
- 📺 How to test HTTP handlers in Go – YouTube
- 📄 Awesome Testing – GitHub
-
Load testing
When you create a large application that needs to serve a large number of requests, there is a need to test this very ability to withstand heavy loads. There are many utilities available to create artificial load.
- JMeter
User-friendly interface, cross-platform, multi-threading support, extensibility, excellent reporting capabilities, support for many protocols for queries.
- LoadRunner
It has an interesting feature of virtual users, who do something with the application under test in parallel. This allows you to understand how the work of some users actively doing something with the service affects the work of others.
- Gatling
A very powerful tool oriented to more experienced users. The Scala programming language is used to describe the scripts.
- Taurus
A whole framework for easier work on JMeter, Gatling and so on. JSON or YAML is used to describe tests.
- JMeter
🔗 References
-
Regression testing
Regression testing is a type of testing aimed at detecting errors in already tested portions of the source code.
- Why use it?
Statistically, the reappearance of the same bugs in code is quite frequent. And, most interestingly, the patches/fixes issued for them also stop working in time. Therefore it is considered good practice to create a test for it when fixing a bug and run it regularly for next modifications.
- Why use it?
🔗 References
Deployment (CI/CD)
-
Cloud services
Before you can deploy your code, you need to decide where you want to host it. You can rent your own server or use the services of cloud providers, which have great functionality for process automation, monitoring, load balancing, data storing and so on.
- AWS (Amazon Web Services)
Provides a wide range of services for computing, storage, database management, networking, security, and more. AWS is one of the oldest and most established cloud service providers.
- Google Cloud
It is known for its focus on machine learning and artificial intelligence, as well as its integration with other Google services like Google Analytics and Google Maps.
- Microsoft Azure
Azure is known for its integration with other Microsoft services like Office 365 and Dynamics 365, as well as its support for a wide range of programming languages and frameworks.
- Digital Ocean
This service provides virtual private servers (VPS) for developers and small businesses. It is also known for its simplicity and ease of use, as well as its competitive pricing.
- Heroku
Heroku is known for its ease of use and integration with popular development tools like Git, as well as its support for multiple programming languages and frameworks. It was a very popular choice for open source projects as long as there was a free plan (it costs money now).
As a rule, all of these services have an intuitive simple interface, detailed documentation, as well as many video tutorials on YouTube.
- AWS (Amazon Web Services)
🔗 References
- 📺 Big Vs Small Public Cloud Providers – YouTube
- 📺 Top 50+ AWS Services Explained in 10 Minutes – YouTube
- 📺 AWS Certified Cloud Practitioner Certification Course – YouTube
- 📺 Google Cloud Associate Cloud Engineer Course – YouTube
- 📺 Microsoft Azure Fundamentals Certification Course – YouTube
- 📺 Full DigitalOcean Crash Course – YouTube
-
Container orchestration
Container orchestration is the process of managing and automating the deployment, scaling, and maintenance of containerized applications and dependencies into a portable, lightweight container format to use them in a cluster of machines.
- Docker in production
The easiest way to manage containers is to use Docker directly, following a list of rules to keep your applications stable and safe in a production environment.
- Store your Docker images in a private registry to prevent unauthorized access and ensure security.
- Use secure authentication mechanisms for access to your Docker registry and implement security measures such as firewall rules to limit access to your Docker environment.
- Keep the size of your containers as small as possible by minimizing the number of unnecessary packages and dependencies.
- Use separate containers for different services (ex. application server, database, cache, metrics etc.).
- Use Docker volumes to store persistent data such as database files, logs, and configuration files.
- Docker swarm
It is a native orchestration tool for Docker to manage, scale and automate tasks such as container updates, recovery, traffic balancing, service discovery and so on.
- Kubernetes (K8s)
Is a very popular orchestration platform that can work with a variety of container runtimes including Docker. Kubernetes offers a more comprehensive set of features (than Docker swarm), including advanced scheduling, storage orchestration, and self-healing capabilities.
- Docker in production
🔗 References
- 📄 How To Optimize Docker Images for Production – Digital Ocean
- 📄 Docker Compose in production
- 📄 Top 8 Docker Best Practices for using Docker in Production – dev.to
- 📺 Best practices around creating a production web app with Docker and Docker Compose – YouTube
- 📺 Docker Swarm Tutorial – YouTube
- 📄 Kubernetes VS Docker Swarm – What is the Difference?
- 📄 Kubernetes Roadmap
- 📺 Docker Containers and Kubernetes Fundamentals – Full Hands-On Course – YouTube
- 📺 Kubernetes Course - Full Beginners Tutorial (Containerize Your Apps!) – YouTube
Optimization
-
Profiling
Profiling is a program performance analysis, which reveals bottlenecks where the highest CPU and/or memory load occurs.
- What is it for?
The information obtained after profiling can be very useful for performance optimization. Profiling can also be useful for debugging the program to find bugs and errors.
- When should this be done?
As needed - when there are obvious problems or suspicions.
- What specific tools are there for this?
For Python, use: cProfile, line_profiler.
For Node.js: built-in Profiler, Clinic.js, Trace events module.
For Go: runtime/pprof, trace utility.
- What is it for?
🔗 References
-
Benchmarks
Benchmark (in software) is a tool for measuring the execution time of program code. As a rule, the measurement is done by multiple runs of the same code (or a certain part of it), where the average time is then calculated, and can also provide information about the number of operations performed and the amount of memory allocated.
- What is it for?
Benchmarks are useful for both evaluating performance and choosing the most effective solution to the problem at hand.
- What specific tools are there for this?
For Python: timeit, pytest-benchmark.
For Node.js: console.time, Artillery.
For Go: testing.B, Benchstat.
There are benchmarks to measure the performance of networked applications, where you can get detailed information about the average request processing time, the maximum number of supported connections, data transfer rates and so on (see list of HTTP benchmarks).
- What is it for?
🔗 References
-
Caching
Caching is one of the most effective solutions for optimizing the performance of web applications. With caching, you can reuse previously received resources (static files), thereby reducing latency, reducing network traffic, and reducing the time it takes to fully load content.
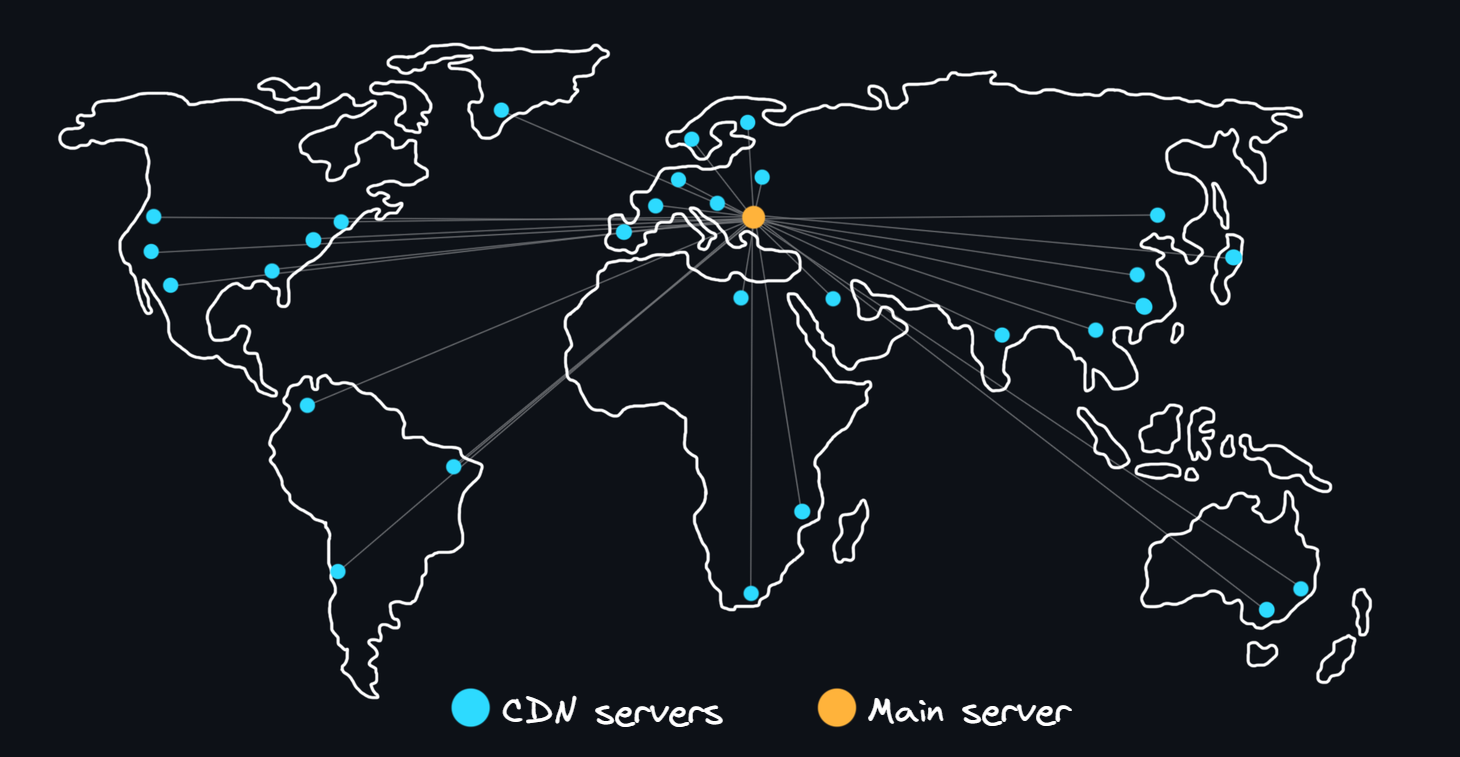
- CDN (Content Delivery Network)
A system of servers located around the world. Such servers allow you to store duplicate static content and deliver it much faster to users who are in close geographical proximity. Also when using CDN reduces the load on the main server.
- Browser-based (client-side) caching
Based on loading pages and other static data from the local cache. To do this, the browser (client) is given special headers: 304 Not Modified, Expires, Strict-Transport-Security.
- Memcached
A daemon program that implements high-performance RAM caching based on key-value pairs. Unlike Redis it cannot be a reliable and long-term storage, so it is only suitable for caches.
- CDN (Content Delivery Network)
🔗 References
- 📺 How Caching Works? | Why is Caching Important? – YouTube
- 📺 Basic Caching Techniques Explained – YouTube
- 📺 HTTP Caching with E-Tags - (Explained by Example) – YouTube
- 📺 What Is A CDN? How Does It Work? – YouTube
- 📺 Everything you need to know about HTTP Caching – YouTube
- 📺 Memcached Architecture - Crash Course with Docker, Telnet, NodeJS – YouTube
-
Load balancing
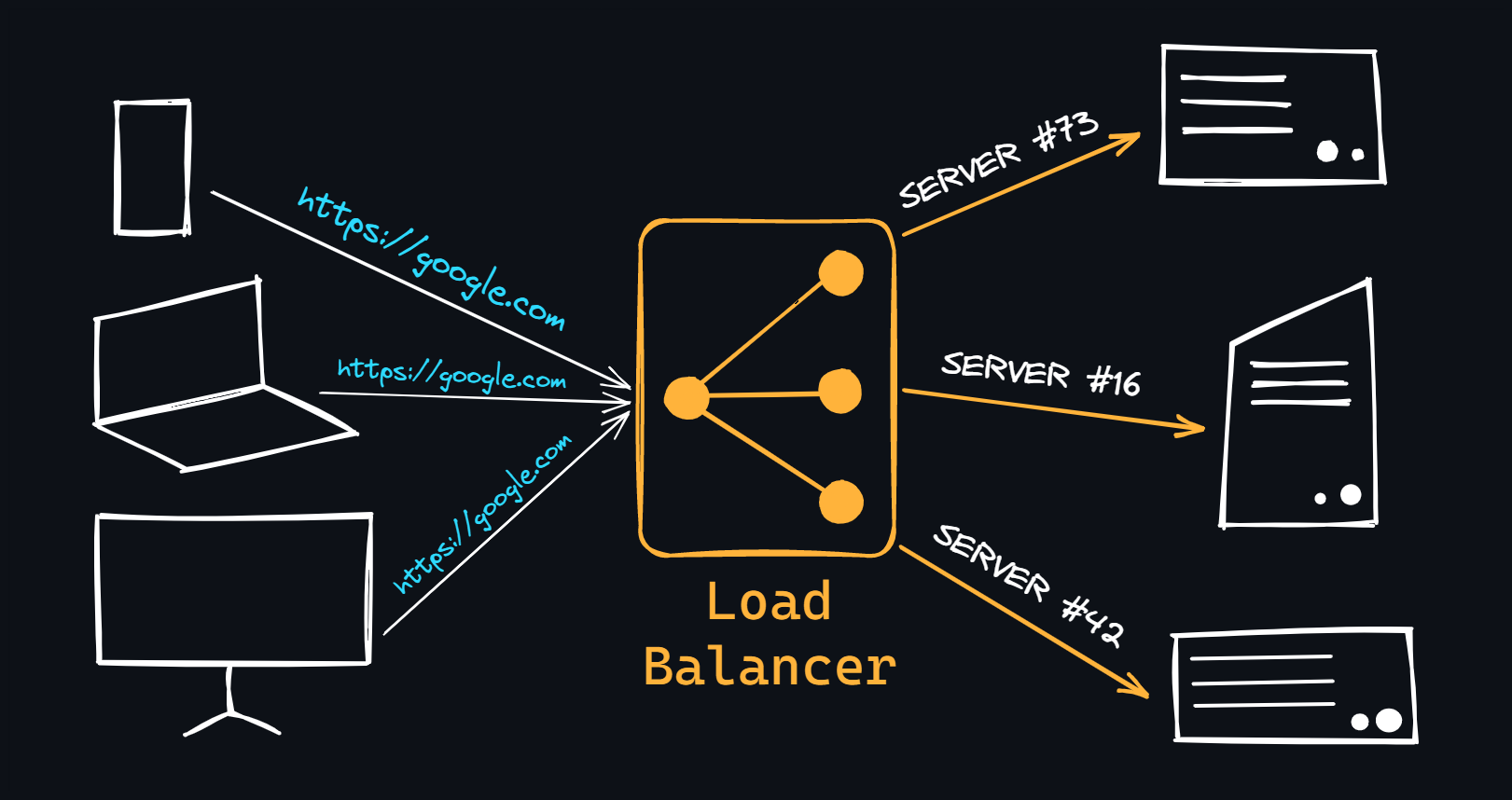
When the entire application code is maximally optimized and the server capacity is reaching its limits, and the load keeps growing, you have to resort to the clustering and balancing mechanisms. The idea is to combine groups of servers into clusters, where the load is distributed between them using special methods and algorithms, called balancing.
- Balancing at the network level
- DNS Balancing. For one domain name is allocated several IP-addresses and the server to which the request will be redirected is determined by an algorithm Round Robin.
- Building a NLB cluster. Used to manage two or more servers as one virtual cluster.
- Balancing by territory. An example is the Anycast mailing method.
- Balancing on the transport level
Communication with the client is locked to the balancer, which acts as a proxy. It communicates with servers on its own behalf, passing information about the client in additional data and headers. Example – HAProxy.
- Balancing at the application level
The balancer analyzes client requests and redirects them to different servers depending on the nature of the requested content. Examples are Upstream module in Nginx (which is responsible for balancing) and pgpool from the PostgreSQL database (for example, it can be used to distribute read requests to one server and write requests to another).
- Balancing algorithms
- Round Robin. Each request is sent in turn to each server (first to the first, then to the second and so on in a circle).
- Weighted Round Robin. Improved algorithm Round Robin, which also takes into account the performance of the server.
- Least Connections. Each subsequent request is sent to the server with the smallest number of supported connections.
- Destination Hash Scheduling. The server that processes the request is selected from a static table based on the recipient's IP address.
- Source Hash Scheduling. The server that will process the request is selected from the table by the sender's IP address.
- Sticky Sessions. Requests are distributed based on the user's IP address. Sticky Sessions assumes that requests from the same client will be routed to the same server rather than bouncing around in a pool.
- Balancing at the network level
🔗 References
Documentation
-
Markdown
A standard in the development world. An incredibly simple, yet powerful markup language for describing your projects. As a matter of fact, the resource you are reading right now is written with Markdown.
- Markdown cheatsheet
A cheatsheet on all the syntactic possibilities of the language.
- Awesome Markdown
A collection of various resources for working with Markdown.
- Awesome README
A collection of beautifull README.md files (this is the main file of any repository on GitHub that uses Markdown).
- Markdown for your notes
Markdown is not only used for writing documentation. This incredible tool is great for learning - creating digital notes. Personally, I use Obsidian editor for outlining new material.
- Markdown cheatsheet
🔗 References
-
Documentation inside code
For every modern programming language there are special tools which allow you to write documentation directly in the program code. So you can read the description of methods, functions, structures and so on right inside your IDE. As a rule, this kind of documentation is done in the form of ordinary comments, taking into account some syntactic peculiarities.
- Why do you need it?
To make your work and the work of other developers easier. In the long run this will save more time than traveling through the code to figure out how everything works, what parameters to pass to functions or to find out what methods this or that class has. Over time you will inevitably forget your own code, so already written documentation will be useful to you personally.
- What does it take to get started?
For each language, it's different. Many have their own well-established approaches:
- Docstring for Python.
- JSDoc for JavaScript.
- Godoc for Go.
- KDoc and Dokka for Kotlin.
- Javadoc for Java.
- And look for others on request:
documentation engine for <your lang>.
- Why do you need it?
🔗 References
-
API Documentation
Easy-to-understand documentation will allow other users to understand and use your product faster. Writing documentation from scratch is a tedious process. There are common specifications and auto-generation tools to solve this problem.
- OpenAPI
A specification that describes how the API should be documented so that it is readable by humans and machines alike.
- Swagger
A set of tools that allows you to create convenient API documentation based on the OpenAPI specification.
- Swagger UI
A tool that allows you to automatically generate interactive documentation, which you can not only read but also actively interact with it (send HTTP requests).
- Swagger editor
A kind of playground in which you can write documentation and immediately see the result of the generated page. You can use YAML or JSON format file for this.
- Swagger codegen
Allows you to automatically create API client libraries, server stubs and documentation.
- OpenAPI
🔗 References
-
Static generators
Over time, when your project grows and has many modules, one README page on GitHub may not be enough. It will be appropriate to create a separate site for the documentation of your project. You don't need to learn how to make it, because there are many generators for creating nice-looking and handy documentation.
- GitBook
Probably the most popular documentation generator using GitHub/Git and Markdown.
- Docusaurus
Open-source generator from Facebook (Meta).
- MkDocs
A simple and widely customizable Markdown documentation generator.
- Slate
Minimalistic documentation generator for REST API.
- Docsify
Another simple, light and minimalistic static generator.
- Astro
A generator with a modern and advanced design.
- mdBook
A static generator from the developers of the Rust language.
- And others...
- GitBook
🔗 References
Building architecture
-
Architectural patterns
- Layered
Used to structure programs that can be decomposed into groups of subtasks, each of which is at a particular level of abstraction. Each layer provides services to the next higher layer.
- Client-server
The server component will provide services to multiple client components. Clients request services from the server and the server provides relevant services to those clients.
- Master-slave
The master component distributes the work among identical slave components, and computes a final result from the results which the slaves return.
- Pipe-filter
Each processing step is enclosed within a filter component. Data to be processed is passed through pipes. These pipes can be used for buffering or for synchronization purposes.
- Broker pattern
A broker component is responsible for the coordination of communication among components.
- Peer-to-peer
Peers may function both as a client, requesting services from other peers, and as a server, providing services to other peers. A peer may act as a client or as a server or as both, and it can change its role dynamically with time.
- Event-bus
Has 4 major components; event source, event listener, channel and event bus. Sources publish messages to particular channels on an event bus.
- Model-view-controller
Separate internal representations of information from the ways information is presented to, and accepted from, the user.
- Blackboard
Useful for problems for which no deterministic solution strategies are known.
- Interpreter
Used for designing a component that interprets programs written in a dedicated language.
- Layered
🔗 References
-
Design patterns
- Creational Patterns
Provide various object creation mechanisms, which increase flexibility and reuse of existing code.
- Structural Patterns
Explain how to assemble objects and classes into larger structures, while keeping these structures flexible and efficient.
- Behavioral Patterns
Concerned with algorithms and the assignment of responsibilities between objects.
- Creational Patterns
🔗 References
-
Monolithic and microservice architecture

A monolith is a complete application that contains a single code base (written in a single technology stack and stored in a single repository) and has a single entry point to run the entire application. This is the most common approach for building applications alone or with a small team.
- Advantages:
- Ease of development (everything in one style and in one place).
- Ease of deployment.
- Easy to scale at the start.
- Ease of development (everything in one style and in one place).
- Disadvantages:
- Increasing complexity (as the project grows, the entry threshold for new developers increases).
- Time to assemble and start up is growing.
- Making it harder to add new functionality that affects old functionality.
- It is difficult (or impossible) to apply new technologies.
- Increasing complexity (as the project grows, the entry threshold for new developers increases).
A microservice is also a complete application with a single code base. But, unlike a monolith, such an application is responsible for only one functional unit. That is, it is a small service that solves only one task, but well.
- Advantages:
- Each individual microservice can have its own technology stack and be developed independently.
- Easy to add new functionality (just create a new microservice).
- A lower entry threshold for new developers.
- Low time required for buildings and startups.
- Each individual microservice can have its own technology stack and be developed independently.
- Disadvantages:
- The complexity of implementing interaction between all microservices.
- More difficult to operate than several copies of the monolith.
- Complexity of performing transactions.
- Changes affecting multiple microservices must be coordinated.
- The complexity of implementing interaction between all microservices.
- Advantages:
🔗 References
- 📺 What are Microservices? – YouTube
- 📺 Microservices Explained and their Pros & Cons – YouTube
- 📺 Microservice Architecture and System Design with Python & Kubernetes – Full Course – YouTube
- 📺 NodeJS Microservices Full Course - Event-Driven Architecture with RabbitMQ – YouTube
- 📺 Building Microservices in Go (playlist) – YouTube
- 📄 Awesome Microservices: collection of principles and technologies – GitHub
-
Horizontal and vertical scaling
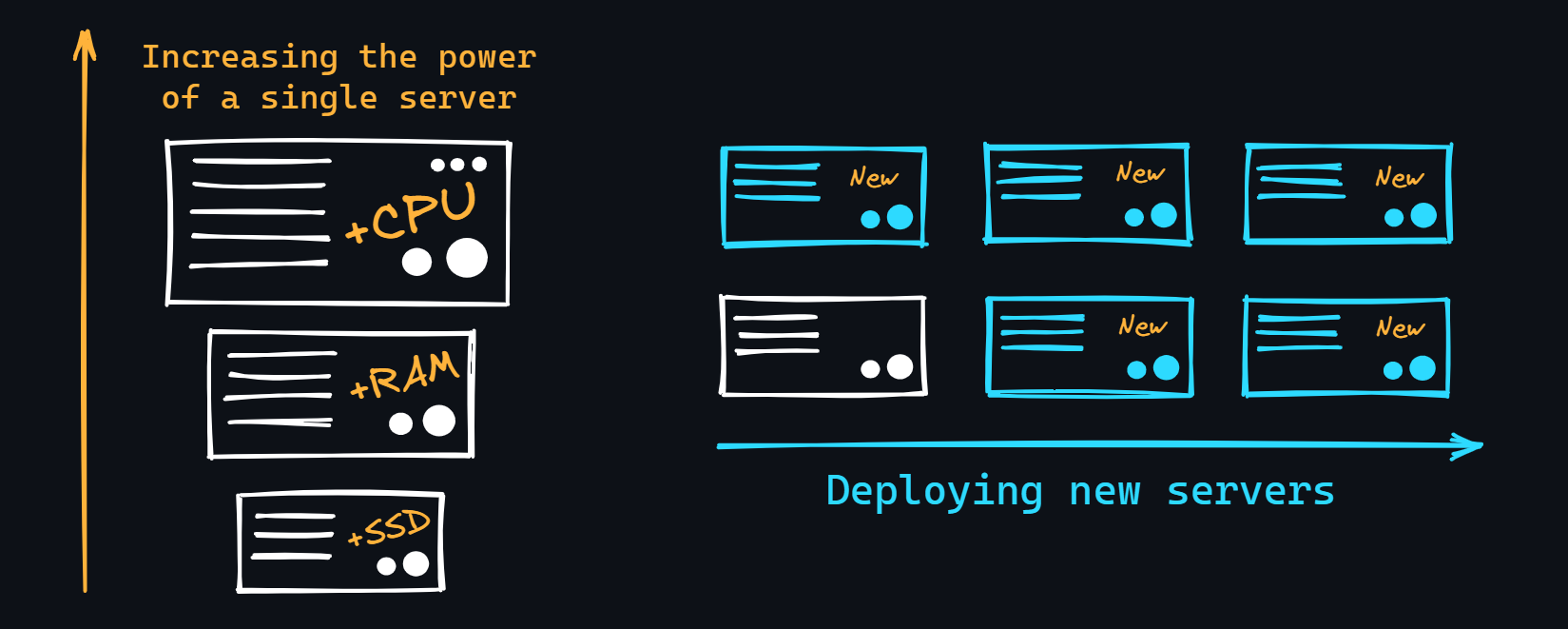
Over time, when the load on your application starts to grow (more users come, new functionality appears and, as a consequence, more CPU time is involved), it becomes necessary to increase the server capacity. There are 2 main approaches for this:
- Vertical scaling
It means increasing the capacity of the existing server. For example, this may include increasing the size of RAM, installing faster storage or increasing its volume, as well as the purchase of a new processor with a high clock frequency and/or a large number of cores and threads. Vertical scaling has its own limit, because we cannot increase the capacity of a single server for a long time.
- Horizontal scaling
The process of deploying new servers. This approach requires building a robust and scalable architecture that allows you to distribute the logic of the entire application across multiple physical machines.
- Vertical scaling
🔗 References
Additional and similar resources
- Backend Developer Roadmap: Learn to become a modern backend developer
- Hussein Nasser – YouTube channel about network engineering
- CS50 2022 – Harvard University's course about programming
- Harvard CS50’s Web Programming with Python and JavaScript
- A curated and opinionated list of resources for Backend developers
- Most important skills for Backend Developer
- System Design Course