| files | ||
| LICENSE | ||
| README.md | ||
Backend cheats
Данный репозиторий представляет собой наглядную шпаргалку по основным темам в области Backend-разработки. Весь материал разбит на темы и подтемы. Структура материала состоит из трех частей:
- Визуальная часть - различные изображения/таблицы/шпаргалки для лучшего понимания (может отсутствовать). Все рисунки и таблицы сделаны с нуля, специально для этого репозитория.
- Краткое описание - очень краткая выжимка информации с перечнем основных терминов и понятий. На термины навешиваются гиперссылки ведущие на соответсвующий раздел в Википедии или подобном справочном ресурсе.
- Ссылки на источники - ресурсы, где можно найти полную информацию по конкретному вопросу. По возможности, указываются максимально авторитетные источники, либо же те, которые предоставляют информацию максимально простым и понятным языком.
🛠 Репозиторий находится в стадии активной разработки, поэтому постоянно обновляется и дополняется
🤝 Если вы хотите помочь проекту, не стесняйтесь присылать свои пулл реквесты
📝 The translation into English will be start after all the main topics have been completed
Содержание
Сеть и интернет
Интернет - это всемирная система объединяющая компьютерные сети со всего мира в единую сеть для хранения/передачи информации. Изначально Интернет разрабатывался для военных. Но вскоре он стал внедряться в учреждения образования (университеты), а затем его смогли использовать частные компании, которые начали организовывать сети провайдеров, предоставляющие услуги доступа в Интернет обычным гражданам. К началу 2020 года количество пользователей в сети Интернет перевалило за 4.5 млрд человек.
-
Как устроен Интернет
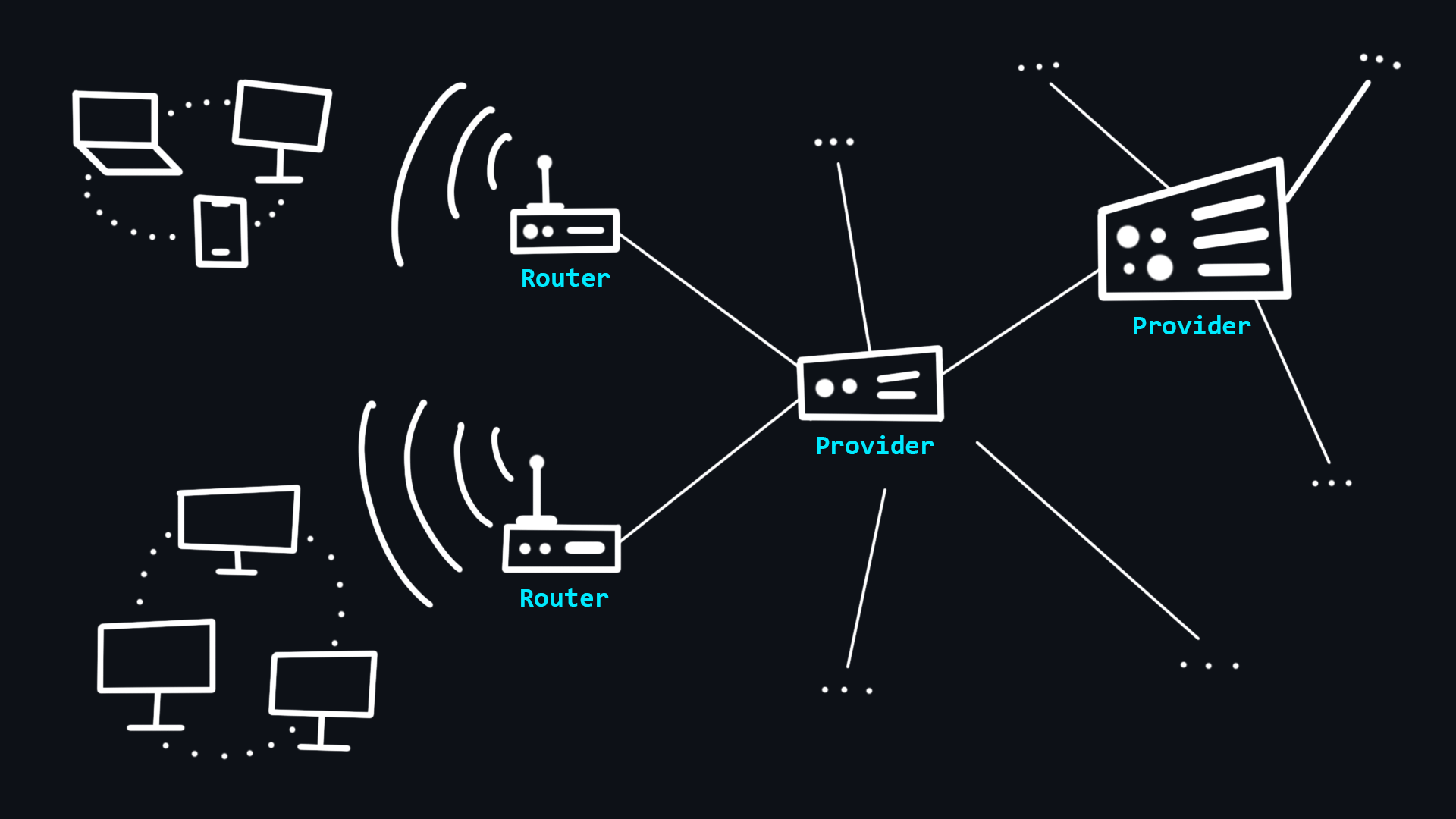
Ваш компьютер никогда не был связан с Интернетом напрямую. Поскольку он способен видеть только свою локальную сеть, в которую проводным (Ethernet) или беспроводным (Wi-Fi, Bluetooth) путем подключены другие устройства. Для связи с Интернетом в вашей локальной сети находиться специальный мини-компьютер – маршрутизатор. Далее он связывает вас с интернет-провайдером, который в свою очередь связан с другими провайдерами более высокого уровня. Таким образом, ваше сообщение, проходит транзитом через сеть нескольких провайдеров, прежде чем достигнет сеть назначения.
Интернет – это всего лишь длинный провод, к которому напрямую присоединены небольшое количество провайдеров первого уровня. Провайдеры уровня ниже просто арендуют доступ.
🔗 Ссылки на материалы
-
Что такое доменное имя

Доменные имена - это человеко-читаемые адреса веб-серверов, доступных в Интернете. Они состоят из частей (уровней) разделенных между собой точкой. Каждая из этих частей предоставляет специфическую информацию о доменном имени. Например страну, название сервиса, локализацию и т.д.
- Кто владеем доменными именами
Корпорация ICANN является основателем распределённой системы регистрации доменов. Она выдаёт аккредитации компаниям, которые хотят заниматься продажей доменов. Таким образом формируется конкурентный доменный рынок.
- Как купить доменное имя
Доменное имя нельзя купить навсегда. Оно выдается в аренду на определенный срок. Покупать домены лучше у аккредитованных регистраторов (найти их можно почти в любой стране).
- Кто владеем доменными именами
🔗 Ссылки на материалы
-
Что такое DNS
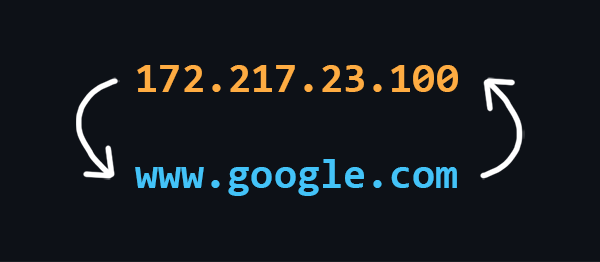
DNS (Domain Name System) - это децентрализованная система именования адресов в Интернете, которая позволяет создавать удобные для человека буквеные наименования (доменные имена) соответствующие числовым IP-адресам, которые используются компьютерами.
- IP-адрес
Специальный номерной идентификатор который используется для распознования того или иного устройства в сети.
- Порт
На одном устройстве (компьютере) может работать множество приложений, которые используют сеть. Для того, чтобы правильно распознать, куда и какие данные, пришедшие по сети, нужно доставить (в какое из приложений) используется специальный числовой номер – порт. То есть, каждый запущенный процесс на компьютере, который использует сетевое подключение, имеет свой личный порт.
- IP-адрес
🔗 Ссылки на материалы
- Что такое DNS-сервер простыми словами
- Система доменных имен DNS — YouTube
- Как это работает: Пара слов о DNS – habr.com
- IP адрес
- Всё об IP адресах и о том, как с ними работать – habr.com
- Порты и перенаправление\открытие портов. Инструкция и объяснения на пальцах – YouTube
- Список зарезервированных портов TCP и UDP – Википедия
-
Устройство веб-приложений
Современные веб-приложения состоят из двух частей: клиентской (frontend) и серверной (backend). Тем самым реализуя клиент-серверную архитектуру.
Задачами клиентской части являются:
- Реализация пользовательского интерфейса (внешний вид приложения)
Для создания веб-страниц использются специальный язык разметки – HTML
Для стилизации шрифтов, расположения содержимого и т.д. используется язык стилей – CSS
Для добавления динамики и интерактивности – язык программирования JavaScript
Как правило в чистом виде эти инструменты используются редко, поскольку для более удобной и быстрой разработки существуют так называемые фреймворки и препроцессоры. - Cоздание функционала для формирования запросов к серверу
Как правило это различного вида формы ввода, с которыми можно удобно взаимодействовать.
- Примем данных от сервера и их последующая обработка для вывода на клиент
Задачи серверной части:
- Обработка клиентских запросов
Проверка на наличие прав и доступа, разного рода валидации и т.д.
- Выполнение бизнес логики
Здесь может подразумеватся широкий спектр задач: работа с базами данных, обработка информации, вычисления и т.д. Это, так сказать, самое сердце мира Backend. Здесь и происходит все самое важное и интересное.
- Формирование ответа и отправка его на клиент
- Реализация пользовательского интерфейса (внешний вид приложения)
🔗 Ссылки на материалы
-
Браузеры и как они работают
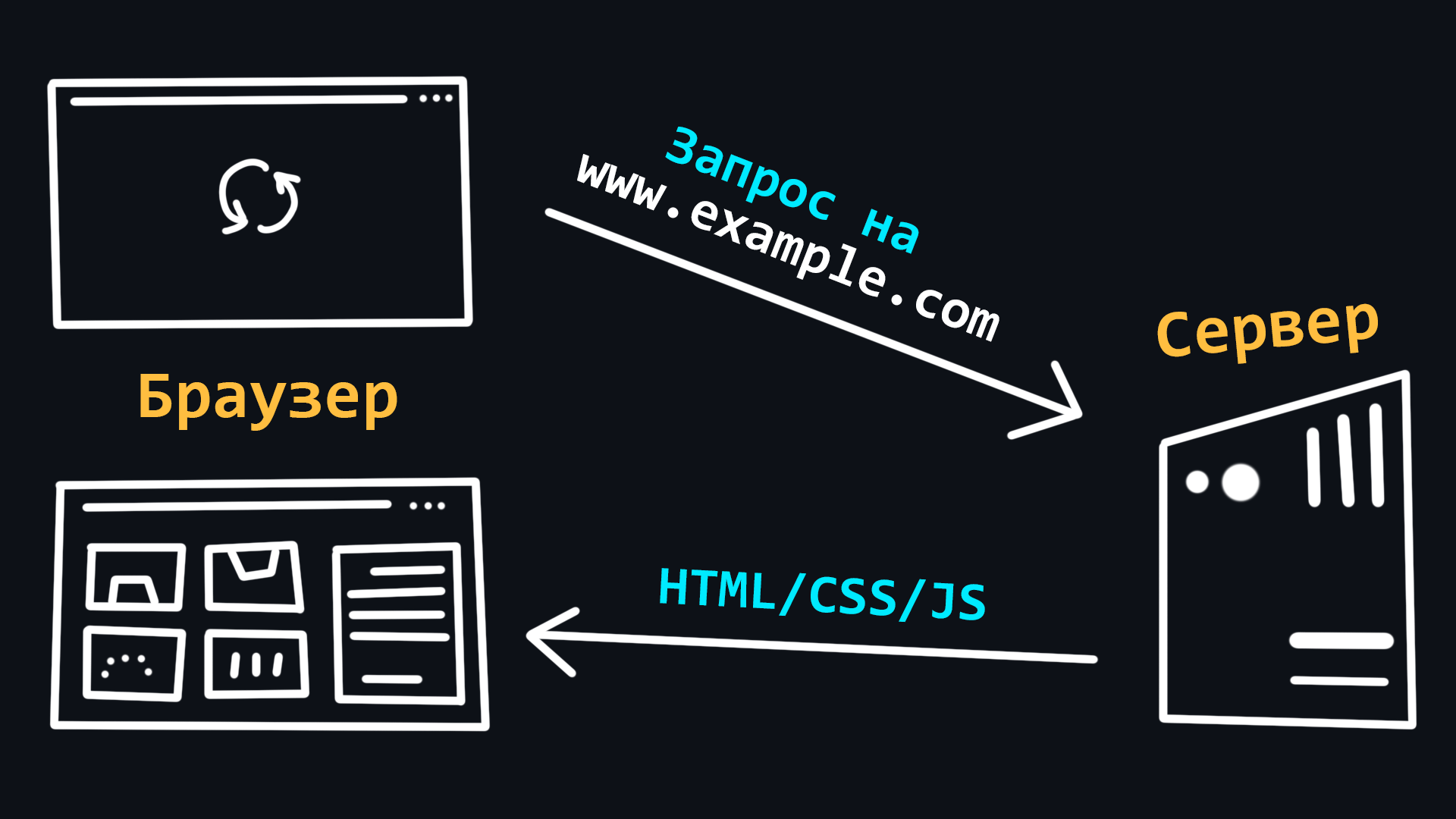
Браузер – клиент, с помощью которого можно отправлять запросы на сервер для получения файлов, которые впоследствии используются для отрисовки web-страниц. Большинство пользователей используют именно браузеры для работы в сети Интернет.
🔗 Ссылки на материалы
- Как работают браузеры — MDN (mozilla.org)
- Как работают браузеры — введение в безопасность веб-приложений – habr.com
- Важные аспекты работы браузера для разработчиков – habr.com
- Что на самом деле происходит, когда пользователь вбивает в браузер адрес google.com – habr.com
- Принципы работы современных веб-браузеров
- Подробное объяснение того, как работает браузер (под капотом)
-
VPN и Proxy
Использование VPN и Proxy довольно распространенноё явление в последние годы. С помощью этих технологий пользователи могут получить базовую анонимность при серфинге в сети, а также обходить различные региональные блокировки.
- VPN (Virtual Private Network)
Технология позволяющая стать участником приватной сети (подобной вашей локальной), где запросы всех участников проходят через единый публичный IP-адрес. Это позволяет Вам смешаться в общей массе запросов от других участников.
- Простая процедура подключения и использования.
- Надежное шифрование трафика.
- Нет гарантии 100% анонимности, поскольку владелец сети знает IP-адреса всех участников.
- VPN бесполезны для работы с мультиаккаунтами и некоторыми программами, поскольку все аккаунты, работающие с одного VPN легко обнаруживаются и блокируются.
- Бесплатные VPN, как правило, имеют большую нагруженность, что приводит к нестабильной работе и снижению скорости загрузки данных.
- Простая процедура подключения и использования.
- Proxy (прокси-сервер)
Прокси это специальный сервер в сети, который выполняет роль посредника между Вами и конечным сервером к которому Вы намереваетесь обратиться. Когда Вы подключены к прокси-серверу все Ваши запросы будут выполняться от имени этого сервера, то есть IP-адрес и местоположение будут подменены.
- Возможность использовать индивидуальный IP-адрес, что позволяет работать с мультиаккаунтами.
- Стабильность соединения из-за отсутствия высоких нагрузок.
- Подключение через прокси предусмотрено в самой ОС и браузере, поэтому доп. ПО не требуется.
- Существуют разновидности прокси, которые обеспечивают высокий уровень анонимности.
- Ненадежность бесплатных решений, поскольку прокси-сервер может видеть и контролировать всё, что вы делаете в интернете.
- Возможность использовать индивидуальный IP-адрес, что позволяет работать с мультиаккаунтами.
- VPN (Virtual Private Network)
🔗 Ссылки на материалы
-
Хостинг
Хостинг (hosting) - специальная услуга, предоставляемая хостинг-провайдерами, которая позволяет арендовать пространство на сервере (который круглосуточно подключён к сети Интернет), где могут храниться ваши данные и файлы. Существуют различные варианты хостинга, где вы можете использовать не только дисковое пространство сервера, но и так же процессорную мощность для работы ваших сетевых приложений.
Основные виды:
- Виртуальный хостинг
Один физический сервер, который распределяет свои ресурсы на нескольких арендаторов.
- VPS/VDS
Виртуальные серверы, эмулирующие работу отдельного физического сервера и предоставляемые в аренду клиенту с максимальными привилегиями.
- Выделенный сервер
Аренда полноценного физического сервера с полным доступом ко всем ресурсам. Как правило, это самая дорогая услуга.
- Облачный хостинг
Услуга которая использует ресурсы нескольких серверов. При аренде пользователь платит только за используемые по факту ресурсы.
- Колокация
Услуга предоставляющая клиенту возможность установить свое оборудование на территории провайдера.
- Виртуальный хостинг
🔗 Ссылки на материалы
- Что такое хостинг, домен и как устроен интернет на понятном языке – YouTube
- Что такое хостинг и домен сайта простыми словами
- Хостинг: что это, зачем и как выбрать
- Хостинг: варианты, сравнения, пользовательская статистика — habr.com
- VPS-хостинг и облачный хостинг: что выбрать и в чем разница? – habr.com
- Колокейшн: как, зачем и почему – habr.com
-
Протокол HTTP
HTTP (HyperText Transport Protocol) - cамый важный протокол интернета. Используется для передачи данных любого формата. Сам по себе протокол работает по простому принципу: запрос –> ответ.
- Структура HTTP-сообщений
Стартовая строка > Заголовки > Тело сообщения
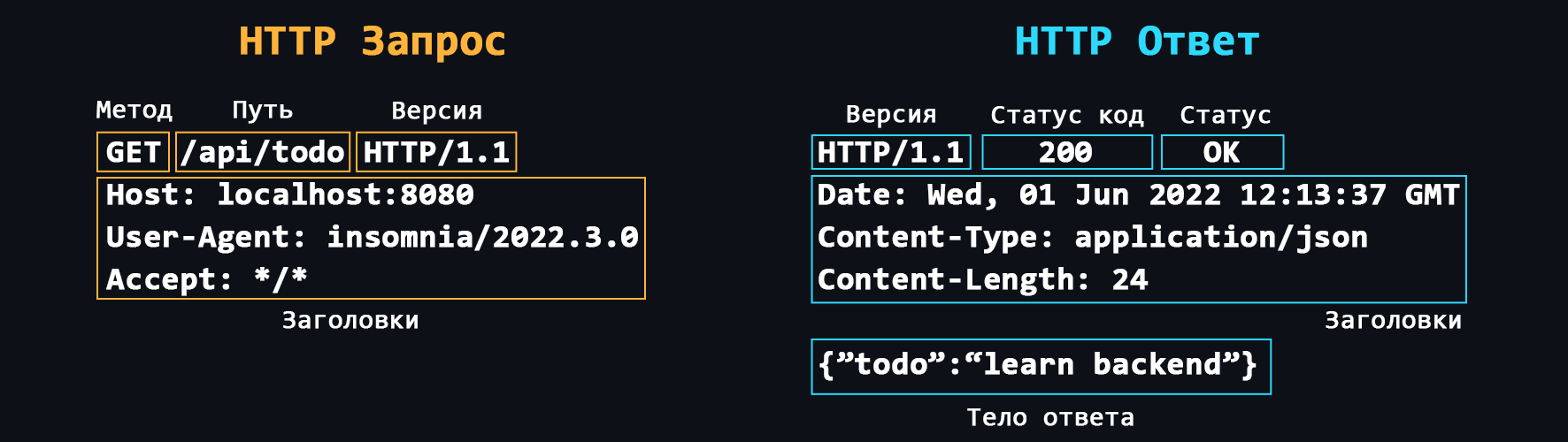
- Заголовки
Дополнительная служебная информация которая отправляется вместе с запросом/ответом.
Основные: Host, User-Agent, If-Modified-Since, Cookie, Referer, Authorization, Cache-Control, Content-Type, Content-Length, Last-Modified, Set-Cookie, Content-Encoding. - Методы запросов
GET - запрос на получение данных
POST - запрос с передачей данных для создания новой записи
PUT - запрос с передачей данных для изменения записи
DELETE - запрос на удаление записи
Другие: HEAD, CONNECT, OPTIONS, TRACE, PATCH. - Коды состояния
Каждый ответ от сервера имеет специальный числовой код, который характеризует состояние отправленного запроса. Эти коды делятся на 5 основных классов:
- 1хх - служебная информация
- 2хх - успешный запрос
- 3хх - перенаправление на другой адресс
- 4хх - ошибка на стороне клиента
- 5хх - ошибка на стороне сервера
- 1хх - служебная информация
- HTTPS
Тот же HTTP, но с поддержкой шифрования
- Cookie
Поскольку протокол HTTP не позволяет сохранять никакой информации о состояниях предыдущих запросов/ответов, возникает необходимость в использовании cookie. Куки позволяют серверу хранить различную информацию на стороне клиента, которую впоследующем клиент может отсылать обратно на сервер. В частности куки могут использоваться для авторизации или для сохранения различных параметров/настроек.
- CORS (Cross origin resource sharing)
Технология, которая позволяет одному домену получать данные от другого.
- CSP (Content Security Policy)
Специальный заголовок позволяющий распознавать и устранять определённые типы уязвимостей веб-приложения.
- HTTP/1.0 vs HTTP/1.1 vs HTTP/2
Главным нововведением в вeрсии 1.1 является режим "постоянного соединения", который позволяет посылать несколько запросов за одно подключение. Во второй версии протокол стал бинарным, появилась возможность передачи данных нескольких потоков по одному каналу.
- Структура HTTP-сообщений
🔗 Ссылки на материалы
- Протокол HTTP – MDN (mozilla.org)
- Протокол HTTP | Курс компьютерные сети – YouTube
- Простым языком об HTTP – habr.com
- Что такое протокол HTTPS, и как он защищает вас в интернете
- Как работает HTTPS? – YouTube
- Что такое cookies браузера – YouTube
- Что такое cookie в браузере и почему на многих сайтах предупреждают об их использовании?
- CORS для чайников: история возникновения, как устроен и оптимальные методы работы – habr.com
- Улучшение сетевой безопасности с помощью Content Security Policy – habr.com
- Путь к HTTP/2 – habr.com
- Evolution of HTTP – MDN (mozilla.org)
-
Cтек протоколов TCP/IP
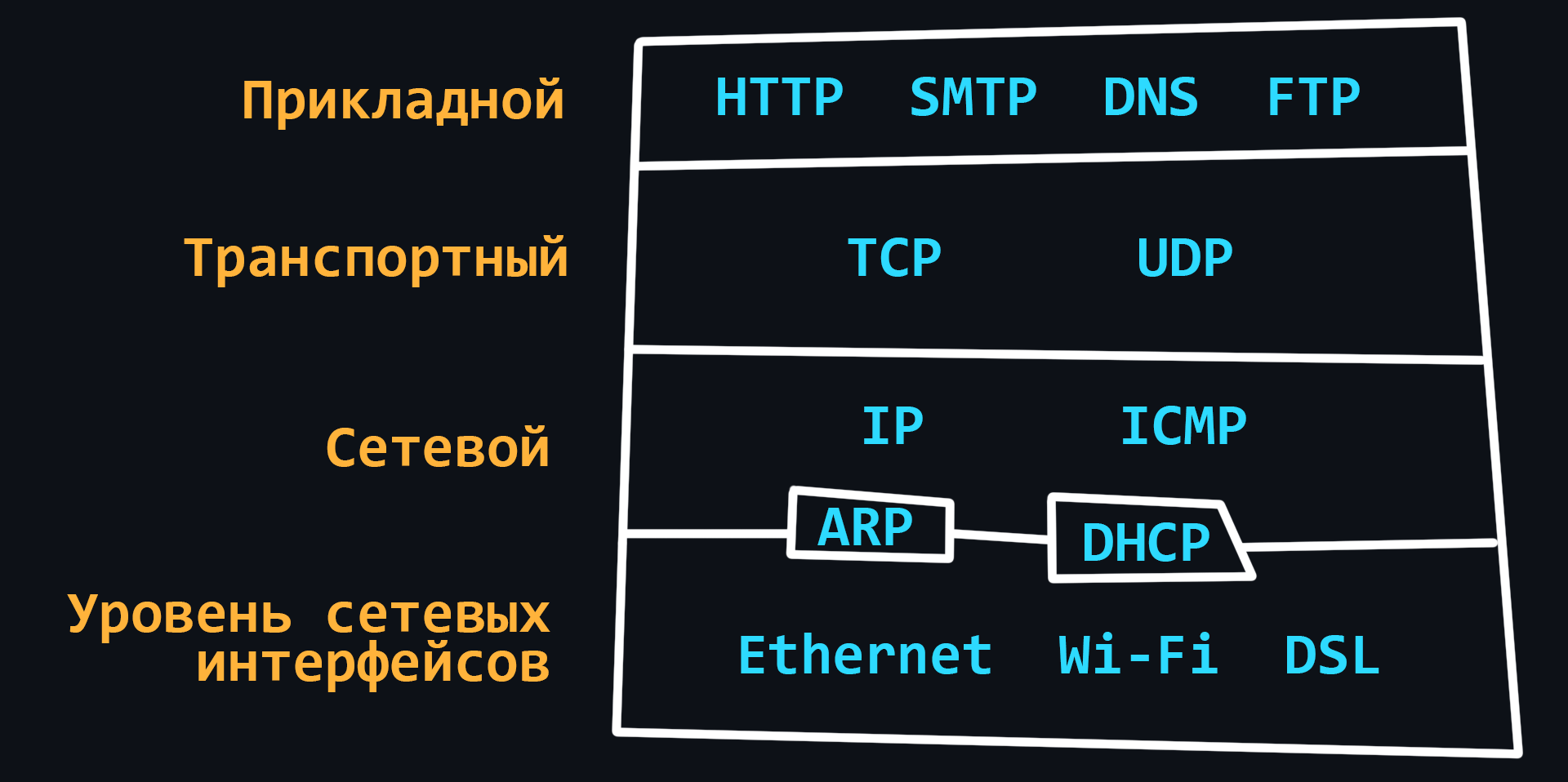
- Стек TCP/IP
Модель (набор правил), которая описывает способ передачи данных от источника информации к получателю. Будет полезно иметь общее представление, как ваши данные проходят через все уровни протоколов.
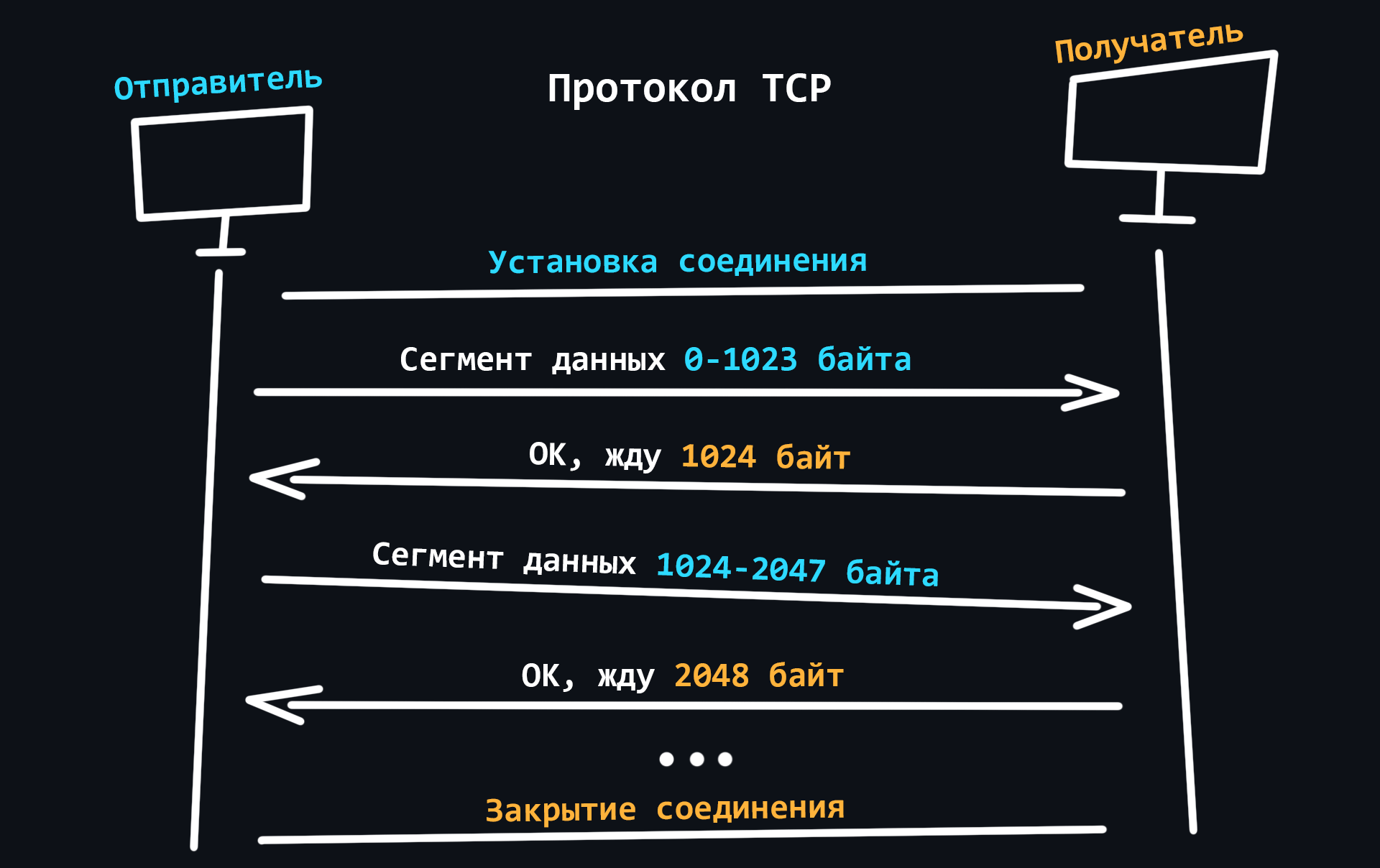
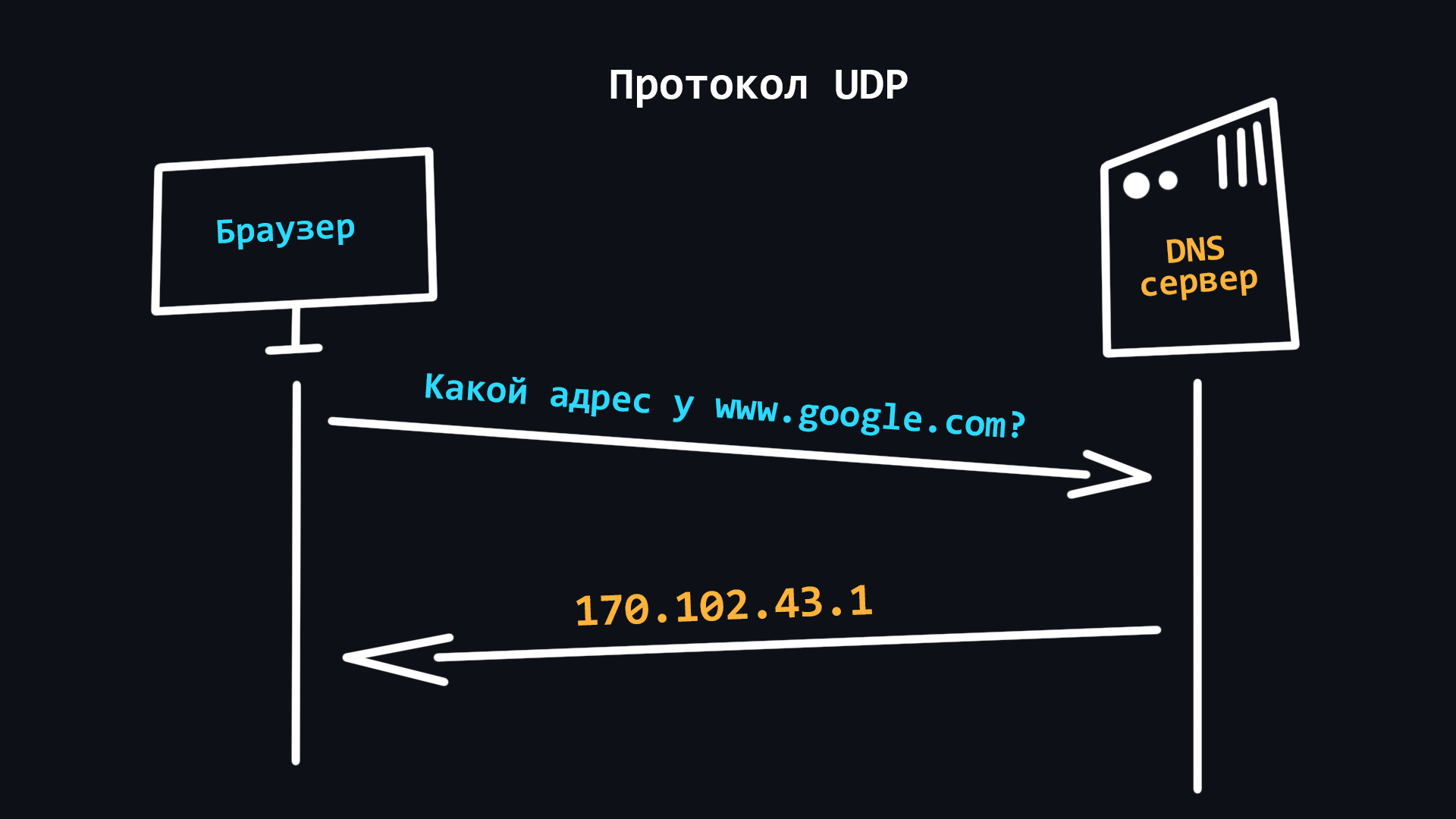
- TCP
Протокол обеспечивающий надежную передачу данных. TCP гарантирует доставку данных и сохранение порядка следования сообщений. Но это сказывается на скорости передачи. Данный протокол используется там, где потеря информации недопустима, например для отправки почты.
- UDP
Простой протокол с быстрой передачей данных. Он не использует механизмов для гарантирования доставки и порядка следования данных. Используется, например в онлайн-играх, где частичная потеря пакетов не критична, но скорость передачи данных имеет гораздо более важное значение. Так же, запросы к DNS-серверам происходят через UDP протокол.
- IP (Internet Protocol)
На этом этапе формируются IP-пакеты, которые содержат все необходимые данные для доставки по сети.
- MAC-адрес
Уникальный идентификатор, назначенный сетевому адаптеру какого-либо устройства.
- Стек TCP/IP
🔗 Ссылки на материалы
-
IPv4 и IPv6

IPv4 и IPv6 – соответственно 4 и 6 версии IP-протокола. IPv4 разработан в 1981 году и ограничивает адресное пространство около 4.3 млрд (2^32) возможными уникальными адресами. Со временем распределение адресного пространства стало происходить значительно более быстрыми темпами, что вынудило создание новой версии IP-протокола для хранения большего количества адресов. IPv6 способен выдать 2^128 уникальных адрессов.
🔗 Ссылки на материалы
-
Проблемы сети

Качество работы сетей, и тем более интернета, далеко от идеала. Это обусловлено сложной и рассредоточенной по разным устройствам структурой сети. Поэтому на функционирование сети влияет огромное количеств факторов. Например: стабильность соединения между устройством клиента и его роутером, качество услуг провайдера, мощность и производительность сервера, физическое расстояние между клиентом и сервером и т.д.
- Latency (задержка)
Время которое требуется, чтобы пакет данных дошёл от отправителя к получателю. В большей степени зависит от физического расстояния.
- Packet loss (потеря пакетов)
Не все пакеты, путешествуя по сети, могут добраться до места назначения. Чаще всего такое происоходит при использовании беспроводных сетей или из-за перегрузок сети.
- Round Trip Time (RTT)
Время, за которое пакет данных доходит до пункта назначения + время на ответ о том, что пакет был получен успешно.
- Jitter
Колебания задержки (нестабильный ping, например, то 50ms, то 120ms, то 35ms...).
- Packet reordering
Протокол IP не гарантирует, что пакеты будут доставляются в том порядке, в котором они были отправлены.
- Latency (задержка)
🔗 Ссылки на материалы
-
Диагностика сети
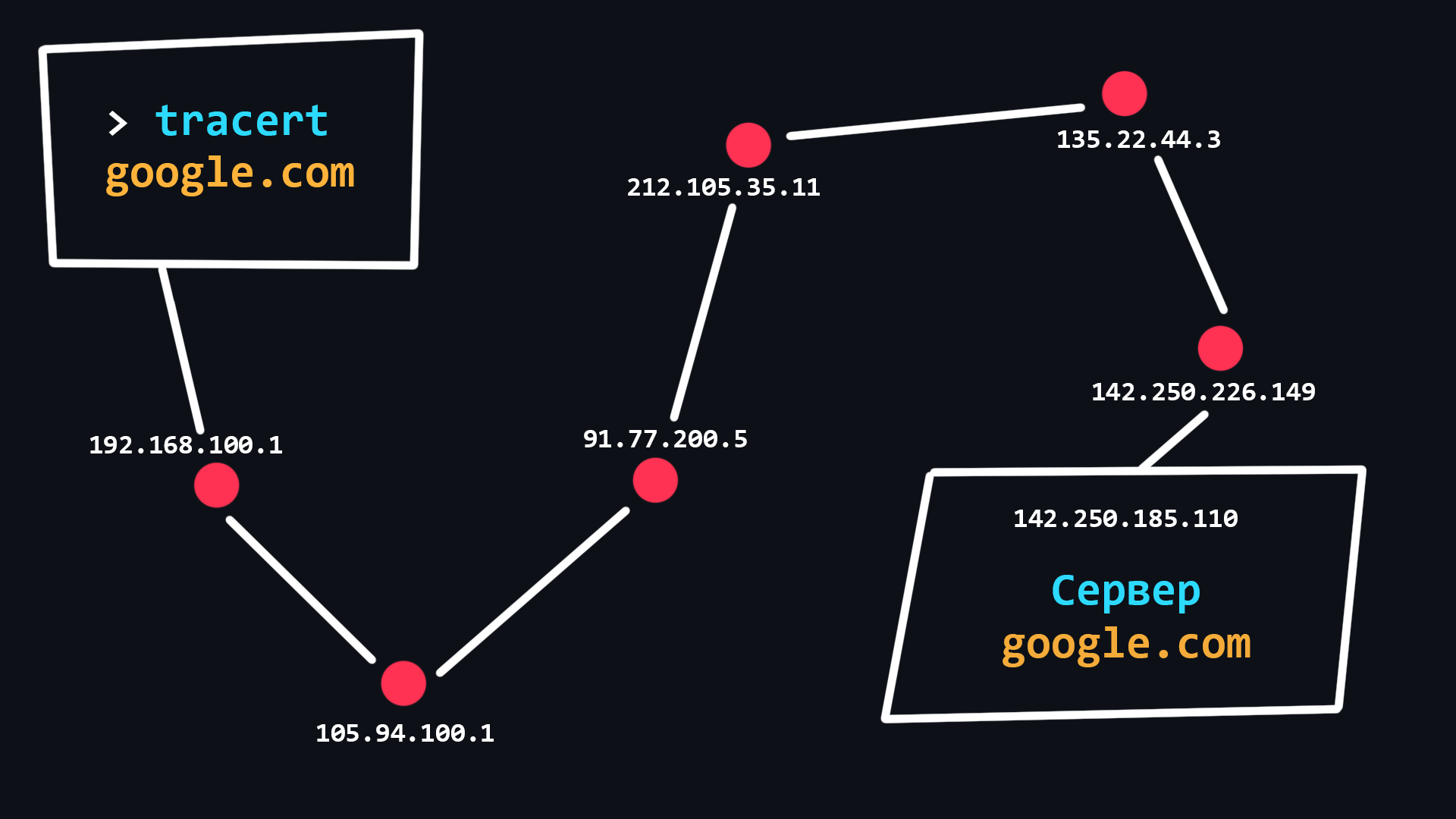
- Трассировка сетевого маршрута
Процедура, позволяющая отследить по каким узлам, с какими IP адресами, передаётся отправленный вами пакет прежде чем он достигнет точки назначения. Трассировка может применяться для выявления связанных с работой компьютерной сети проблем, а также для исследования/анализа сети.
- Ping-сканирование
Самый простой способ проверить сервер на работоспособность.
- Проверка на потерю пакетов
- Wireshark
Мощная программа с графическим интерфейсом для анализа всего трафика, проходящего по сети, в режиме реального времени.
- Трассировка сетевого маршрута
🔗 Ссылки на материалы
- Как находить проблемы с интернетом и кто виноват: часть 1 – habr.com
- Как находить проблемы с интернетом и кто виноват: часть 2 – habr.com
- Прочитай и сделай: проводим сканирование сети самостоятельно – habr.com
- Основы компьютерных сетей. Диагностика и устранение основных проблем – YouTube
- Трассировка сетевого маршрута — hackware.ru
- Wireshark — приручение акулы – habr.com
- Протокол HTTPS в WireShark – YouTube
Операционные системы
Операционная система (ОС) – это комплексная программная система, которая предназначена для управления ресурсами компьютера. Благодаря операционным системам людям не приходится иметь дело непосредственно с процессором, оперативной памятью или другими составляющими ПК.
То есть, ОС можно представить как слой абстракции, который управляет железом (hardware) компьютера, тем самым предоставляя простую и удобную среду для работы пользовательского софта (software).
-
Устройство ОС

- Необходимые понятия
- Компьютерная программа
Последовательность инструкций, предназначенных для выполнения процессором.
- Компьютерная память
Компьютер имеет 2 типа памяти:
- постоянную (для долговременного хранения данных)
- оперативную (для временного хранения кода программы, а также входных, выходных и промежуточных данных, обрабатываемых процессором)
- постоянную (для долговременного хранения данных)
- Процессор (ЦП)
Важнейшее устройство любого компьютера, которое исполняет инструкции (код программы).
- Устройства ввода-вывода
Устройства с помощь которых можно вводить информацию в компьютер (клавиатура, мышь...) и выводить (монитор, наушники...).
- Компьютерная программа
- Основные функции
- Управление оперативной памятью (выделение пространства для отдельных программ)
- Загрузка программ в оперативную память и их выполнение
- Выполнение запросов поступающих от пользовательских программ (ввод и вывод данных, запуск и остановка других программ, высвобождение памяти или выделение дополнительной...)
- Взаимодействие с устройствами ввода и вывода (мышь, клавиатура, монитор...)
- Взаимодействие с носителями информации (жесткие диски, SSD...)
- Предоставление пользовательского интерфейса (консольная оболочка или графичекий интерфейс)
- Введение журнала об программных ошибках (сохранение логов)
- Управление оперативной памятью (выделение пространства для отдельных программ)
- Дополнительные функции (могуть быть не во всех ОС)
- Огранизация многозадачности (одновременное выполнение нескольких программ)
- Разграничивание доступа к ресурсам для каждого процесса
- Взаимодействие между процессами (обмен данными, синхронизация)
- Организация защиты самой ОС от других программ и действий самого пользователя
- Предоставление многопользовательского режима и разграничение прав между разными пользователями ОС (админ, гость...)
- Огранизация многозадачности (одновременное выполнение нескольких программ)
- Ядро ОС
Центральная часть ОС, которая используется наиболее интенсивно. Ядро постоянно находится в памяти, в то время как другие части ОС загружаются в память и выгружаются из неё по мере надобности.
- Загрузчик ОС
Системный софт, который обеспечивает подготовку окружения для запуска ОС (приводит аппарутуру в нужное состояние, подготавливет память, загружает туда ядро ОС и передает ему (ядру) управление).
- Драйверы
Специальное ПО, которое позволяет ОС работать с тем или иным оборудованием.
- Необходимые понятия
🔗 Ссылки на материалы
- Что такое операционная система и как она работает – YouTube
- Плейлист по операционным системам – YouTube
- Что такое операционная система и как она работает? – GitHub
- Что такое ядро операционной системы? Назначение и виды ядер – YouTube
- Устройство компьютерных программ: Как работает программа? Как компилируется код? – YouTube
- Как работает память компьютера – YouTube
- Как работает процессор – YouTube
-
Процессы и потоки
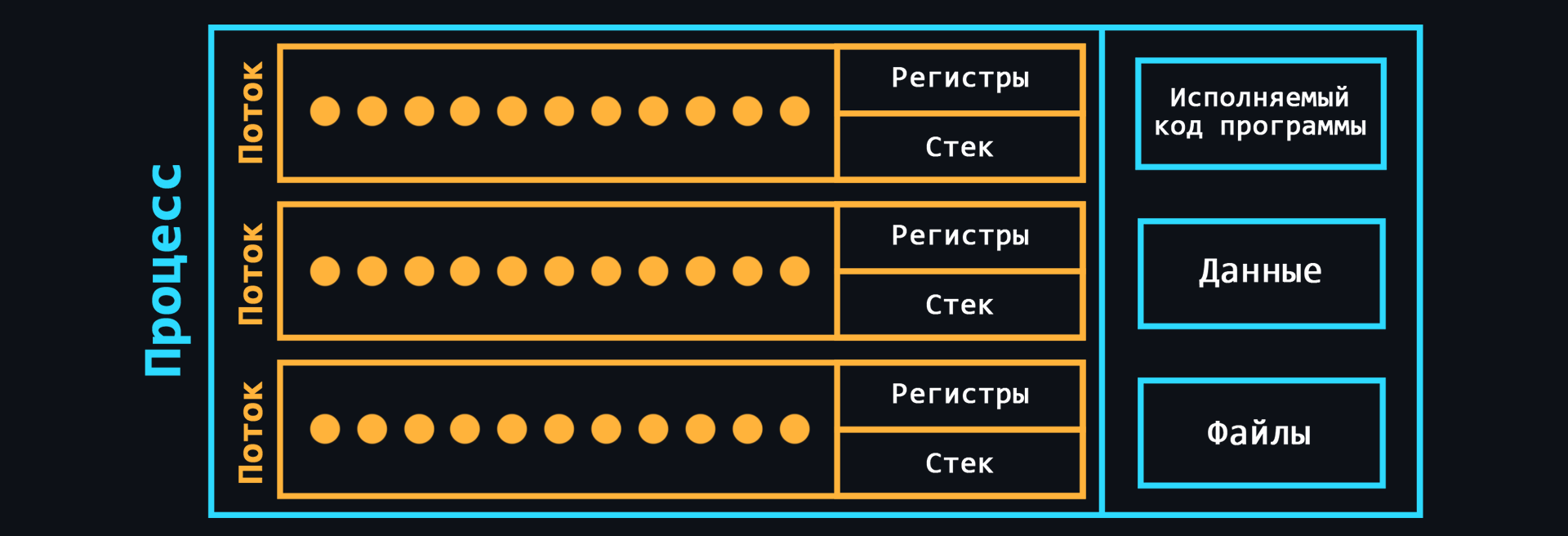
- Процесс
Cвоего рода контейнер, в котором находятся все необходимые ресурсы для работы той или иной программы. Как правило в состав процесса входят:
- Исполняемый код программы
- Входные и выходные данные
- Стек вызовов (порядок инструкций для выполнения)
- Куча (структура для хранения промежуточных данных, создаваемых во время работы процесса)
- Дескриптор сегмента
- Файловые дескрипторы
- Информация о наборе допустипых полномочий
- Информация о состоянии процессора
- Исполняемый код программы
- Поток
Cущность, в которой выполняются последовательности действий (процедуры) программы. Потоки находятся внутри процесса и используют то же адрессное пространство. В одном процессе может быть несколько потоков, что обеспечивает возможность выполнения нескольких задач. Эти задачи, благодаря потокам, могут обмениваться данными, использовать общие данные или результаты других задач.
- Процесс
🔗 Ссылки на материалы
-
Конкурентность и параллелизм

- Параллелизм (Parallelism)
Способность выполнять несколько задач одновременно используя несоклько ядер процессора, где на каждом отдельном ядре выполняется отдельно взятая задача.
- Конкурентность (Concurrency)
Способность выполнять несколько задач, но используя одно ядро процессора. Это достигается путем разделения задач на отдельные блоки команд, которые выполняются по очереди, но переключение между этими блоками происходит настолько быстро, что для пользователей создается впечатление, будто эти процессы выполняются одновременно.
- Параллелизм (Parallelism)
🔗 Ссылки на материалы
-
Менеджер памяти
Менеджер памяти является частью операционной системы (или отдельной программы) основной задачей которого является обработка запросов на выделение и освобождение оперативной памяти. Существует целая иерархия менеджеров памяти:
- Системный менеджер памяти
Менеджер встроенный в ОС.
- Менеджер процесса
Встроенный в стандартную библиотеку языка программирования, берёт у ОС блоки памяти «оптом» и раздаёт их сообразно с нуждами программиста.
- Специализированный менеджер
Динамические структуры данных языка программирования, которые берут память у стандартной библиотеки с запасом.
- Системный менеджер памяти
🔗 Ссылки на материалы
-
Межпроцессорное взаимодействие
Механизм позволяющий организовать обмен данными между потоками одного или разных процессов. Причем, процессы могут быть запущены как на одном и том же компьютере, так и на разных, соединенных сетью. Межпроцессорные взаимодействия бывают разных типов.
- Файл
Самый простой способ организвоать обмен данными. Один процесс записывает данные в определенный файл, другой процесс читает этот же файл и тем самым получает данные от первого процесса.
- Сигнал
Асинхронное уведомление одного процесса о событии произошедшем в другом процессе.
- Сокет
В частности для взаимодействия между компьютерами с помощью стека протоколов TCP/IP используются IP-адреса и порты. Эта пара определяет сокет («гнездо», соответствующее адресу и порту).
- Семафор
Счетчик над которым можно проводить только 2 операции: увеличение и уменьшение (причем для 0 операция уменьшения блокируется).
- Сообщения и очереди сообщений
- Каналы (akа конвееры, pipes)
Перенаправление выходных данных одного процесса на вход другого процесса (подобие трубы).
- Файл
🔗 Ссылки на материалы
- Архитектура ЭВМ. Межпроцессное взаимодействие – YouTube
- Основы программирования. Межпроцессное взаимодействие – YouTube
- IPC: основы межпроцессного взаимодействия
- Интерфейс сокетов | Курс "Компьютерные сети" – YouTube
- Порты, сокеты, статика (для самых маленьких программистов) – YouTube
- Разделяемая память. Семафоры – YouTube
-
Ввод и вывод (I/O)
В современных операционных системах средства ввода-вывода представляют собой способы взаимодействия между обработчиком информации и внешним миром. Сюда можно отнести чтение или запись файлов на жёсткий диск или SSD, отправку и получение данных по сети, отображение информации на мониторе, получение ввода с мыши и клавиатуры.
- Блокирующий ввод/вывод
- Неблокирующий ввод/вывод
- Мультеплексированный ввод/вывод
- Асинхронный ввод/вывод
🔗 Ссылки на материалы
Основы Linux
Операционные системы на базе ядра Linux это стандарт в мире серверной разработки, поскольку большинство серверов работают именно на таких ОС. Использовать Linux на серверах выгодно, ведь он рапространяется бесплатно.
Существует огромное количество дистрибутивов (сборок с набором предустановленного ПО) Linux на любой вкус и цвет. Одним из самых популярных является Ubuntu. Именно с него можно начать своё погружение в серверную разработку.
Установить Ubuntu можно на отдельный ПК или ноутбук. Если такой возможности нет, можно воспользоваться специальной программой Virtual Box, в которой можно запускать другие ОС поверх основной. Так же можно запустить Docker контейнер с образом Ubuntu (Docker - это отдельная тема, которая рассматривается в этом репозитории).
После этого можно быстро пройти вводный курс по Linux и Bash.
-
Работа с терминалом
Терминал (или консоль) - программа в которой для управления компьютером используются специальные текстовые команды. Как правило на серверах отсутствуют графические оболочки, поэтому вам обязательно понадобятся навыки работы с терминалом.
- Основные команды для навигации по файловой системе
ls # просмотр содержимого директории cd <путь> # переход в указанный каталог cd .. # переход на уровень выше (в родительский каталог) touch <файл> # создание файла cat > <файл> # ввод текста в файл из консоли (перезапись) cat >> <файл> # ввод текста в конец файла (добавление) cat/more/less <файл> # просмотр содержимого файла head/tail <файл> # просмотр первых/последних строк файла pwd # путь к текущей директории mkdir <имя> # создать директорию rmdir <имя> # удалить директорию cp <файл> <путь> # копировать файл или директорию mv <файл> <путь># перемещение или переименование rm <файл> # удаление файла или директории find <строка># поиск в файловой системе du <файл># вывод размера файла или каталога - Команды для получения справочной информации
man <название_команды> # позволяет посмотреть руководство по любой команде. apropos <слово> # поиск команды с описанием имеющим указанное слово man -k <слово> # аналогично команде выше whatis <название_команды> # краткое описание команды - Права суперпользователя
Аналог запуска от имени администратора в Windows.
sudo <команда> # выполняет команду с правами суперпользователя
- Основные команды для навигации по файловой системе
🔗 Ссылки на материалы
-
Менеджер пакетов
Встроенный менеджер пакетов apt (advanced packaging tool) позволяет устанавливать/обновлять программные пакеты из сети с помощью терминала.
- Базовые команды
apt install <имя_пакета> # установить пакет apt remove <имя_пакета> # удалить пакет, но оставить конфигурацию apt purge <имя_пакета> # удалить пакет вместе с конфигурацией apt update # обновление информации о новых версиях пакетов apt upgrade # обновление пакетов, установленных в системе apt list --installed # список установленных в системе пакетов apt list --upgradable # список пакетов, которые требуют обновления apt search <имя> # поиск пакетов по имени в сети apt show <имя_пакета> # информация о пакете
- Базовые команды
🔗 Ссылки на материалы
-
Скрипты Bash
С помощью скриптов (сценариев) можно автоматизировать последовательный ввод любого количества команд. В Bash можно создавать различные условия (разветвления), циклы, таймеры и т.д. для выполнения всевозможных действий связанных с вводом в консоль.
- Базовые возможности
Вывод сообщений / Переменные / Математические операции / Условия / Сравнения / Проверки
- Циклы
For / Перебор / While / Вложенные циклы / Управление циклами
- Параметры и ключи командной строки
Чтение параметров / Проверка и подсчет / Shift / Различие ключей и параметров / Стандартные ключи / Ввод паролей
- Ввод и вывод
Дескрипторы / Перенаправление потоков ошибок / Перенаправление ввода и вывода / Создание дескрипторов / Подавление вывода
- Сигналы, фоновые задачи, управление сценариями
Отправка, перехват, модификация сигналов / Остановка процессов / Выполнение в фоновом режиме / Планирование запуска / Задания
- Функции и библиотеки
Return / Аргументы / Переменные / Рекурсивные функции / Работа с библиотеками
- Sed и обработка текстов
Символы-разделители / Выбор фрагментов текста / Удаление, замена строк / Вставка текста в поток
- Регулярные выражения
Специальные символы / Якорные символы / Классы символов / Диапазоны / Группировка
- Expect и автоматизация
Основы expect / Autoexpect / Interact
- Базовые возможности
🔗 Ссылки на материалы
-
Пользователи
ОС на базе Linux являются многопользовательскими. Это означает, что несколько людей могут запускать множество различных приложений одновременно на одном и том же компьютере. Чтобы система Linux смогла «узнать» пользователя, он должен войти в систему, соответсвенно каждый пользователь должен иметь уникальное имя и секретный пароль.
- Работа с пользователями
useradd <имя> [ключи] # создать нового пользователя passwd <имя> # установить пароль пользователю usermod <имя> [ключи] # редактировать пользователя usermod -L <имя> # заблокировать пользователя usermod -U <имя> # разблокировать пользователя userdel <имя> [ключи] # удалить пользователя - Работа с группами
groupadd <группа> [ключи] # создать группу groupmod <группа> [опции] # редактировать группу groupdel <группа> [опции] # удалить группу usermod -a -G <группы(через запятую)> <пользователь> # добивить пользователя в группы gpasswd --delete <пользователь> <группы(через запятую)> # удалить пользователя из групп - Системные файлы
/etc/passwd # файл паролей, содержащий основную информацию о пользователях /etc/shadow # файл теневых шифрованных паролей, содержащий зашифрованные пароли /etc/group # файл групп, содержащий основную информацию о группах /etc/gshadow # файл теневых групп, содержащий шифрованные пароли групп
- Работа с пользователями
🔗 Ссылки на материалы
-
Права доступа
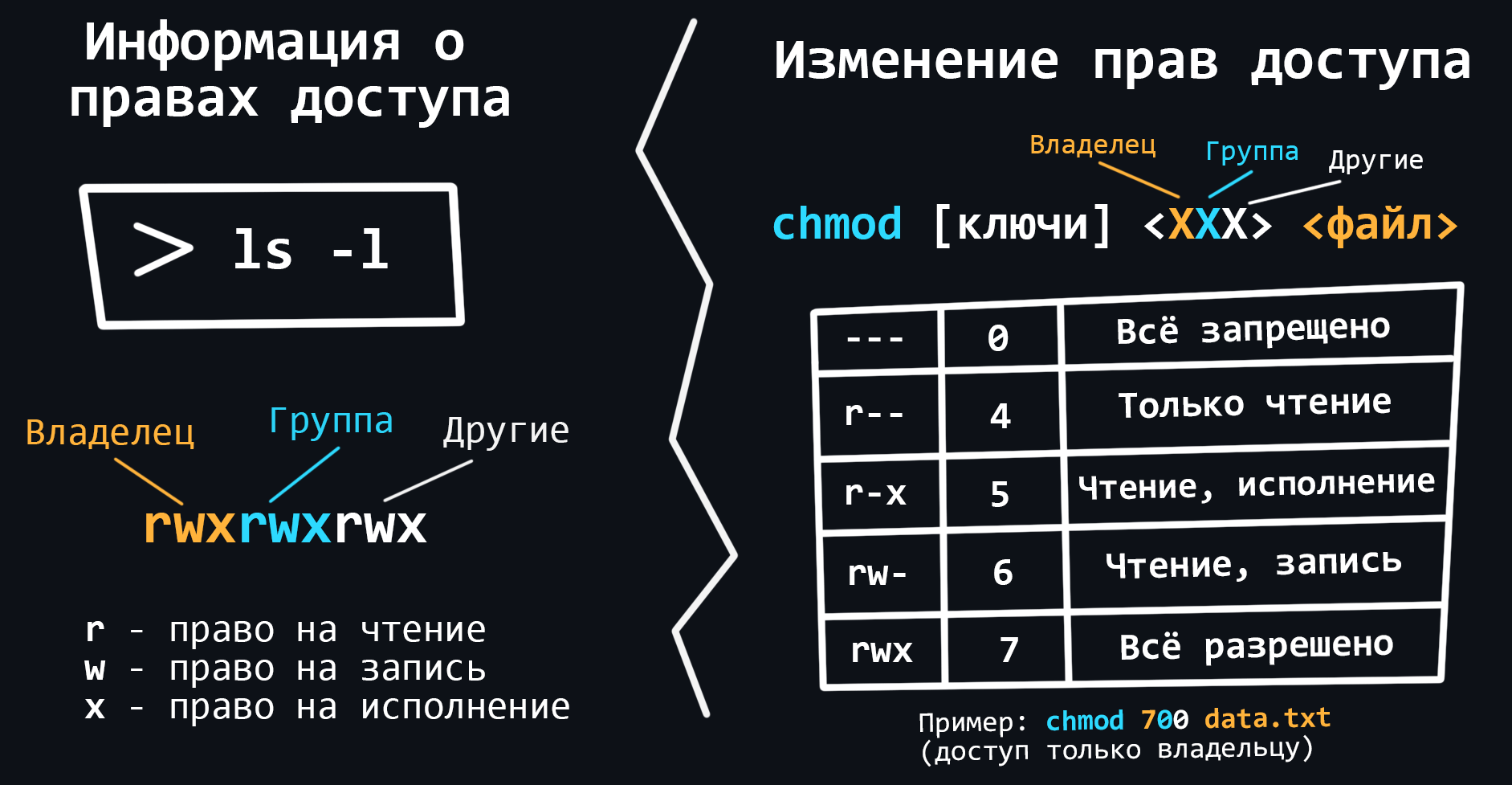
Так как под одной ОС могут работать несколько разных пользователей, то соответственно у каждого такого пользователя будет своё личное файловое пространство. Отсюда вытекает, что у любого файла в Linux должны быть специальные атрибуты – права на доступ. Эти атрибуты должны сообщать, кто имеет право работать c тем или иным файлом.
🔗 Ссылки на материалы
-
Работа с процессами
Процессы в Linux можно описать как контейнеры, в которых хранится вся информация о состоянии выполняемой программы. Если программа работает хорошо, то все нормально, но если она зависла и вам нужно восстановить её работу, тогда вам понадобиться навыки работы по управлению процессами.
- Базовые команды
ps # вывести 'снимок' процессов всех пользователей top # диспетчер задач в реальном времени <команда> & # запуск процесса в фоновом режиме, то есть не занимая консоль jobs # список запущенных в фоновом режиме процессов fg <номер> # вернуть процесс обратно в активный режим по его номеру bg <номер> # запуск остановленного процесса в фоновый режим kill <id процесса> # завершить процесс по id killall <программа> # завершить все процессы связанные с одной программой
- Базовые команды
🔗 Ссылки на материалы
-
Работа с SSH
Служба SSH Позволяет получить удаленный доступ к терминалу другого компьютера. В случае с персональным компьютером, это может понадобиться для срочного решения какой-либо проблемы, а в случае с сервером это вообще очень распространенная практика.
- Базовые комнады
apt install openssh-server # установка SSH (хотя он почти везде идёт из коробки) service ssh start # запуск SSH service ssh stop # остановка SSH ssh -p <Порт> user@remotehost # подключенние к удаленному ПК через SSH ssh-keygen -t rsa # генерация RSA-ключа для беспарольного входа ssh-copy-id -i ~/.ssh/id_rsa user@remotehost # копирование ключа на удаленную машину
- Базовые комнады
🔗 Ссылки на материалы
-
Планировщик задач

Благодаря планировщикам можно гибко управлять отложенным запуском команд и скриптов. В Linux есть встроенный планировщик cron, с помощью которого можно легко выполнять необходимые действия через определенные интервалы времени.
🔗 Ссылки на материалы
-
Системные логи
Файлы журнала (логи) - cпециальные текстовые файлы, в которые заносится вся информация о работе компьютера, программы или пользователя. Они особенно полезны при возникновении багов и ошибок в работе программы или сервера. Рекомендуется периодически просматривать логи, даже если ничего подозрительного не происходит.
- Основные лог файлы
/var/log/syslog или /var/log/messages # информация о ядре, различных службах, обнаруженных устройствах, сетевых интерфейсах и т.д. /var/log/auth.log или /var/log/secure # информация об авторизации пользователей /var/log/faillog # неудачные попытки входа в систему /var/log/dmesg # информация о драйверах устройств /var/log/boot.log # информация о загрузке операционной системы /var/log/cron # отчёт о работе планировщика задач cron - Утилита lnav
Предназначена для удобного просмотра лог файлов (подсветка, чтение разных форматов, поиск и т.д.)
- Ротация логов с помощью logrotate
Позволяет настроить автоматическое удаление (чистку) лог-файлов, чтобы не забивать память.
- Демон journald
Cобирает данные из всех доступных источников и сохраняет их в двоичном формате для удобного и динамичного управления
- Основные лог файлы
🔗 Ссылки на материалы
- Что такое логирование
- Как посмотреть логи в Linux – losst.ru
- Лог файлы Linux по порядку – habr.com
- Что такое «управление конфигурацией»
- Туториал по системным логам Linux
- Логи Linux. Всё о логах и журналировании
- Документация по lnav на русском
- Ротация логов в Linux с помощью logrotate
- Использование journalctl для просмотра и анализа логов: подробный гайд – habr.com
-
Проблемы в Linux
- Проблемы с командами в терминале
Возникают из-за ошибочных действий пользователя. Часто связано с опечатками, отсутствием прав, неправильно указанными опциями и т.д.
- Проблемы с драйверами и ядром
Kernel panic может возникать из-за ошибки при монтировании корневой файловой системы.
Тут лучше всего поможет навык чтения логов для выявления проблем (командаdmesg). - Ошибка сегментации (segmentation fault)
Возникает когда процесс обращается к недействительным участкам памяти.
- Проблемы с диском и файловой системой
Могут возникать из-за отсутствия свободного места.
- Проблемы с командами в терминале
🔗 Ссылки на материалы
Общие знания
-
Системы счисления
Система счисления (СС) представляет собой совокупность символов и правил для обозначения чисел. В информатике принято выделять четыре основных системы счисления: двоичная, восьмеричная, десятичная, шестнадцатеричная. Связано это, в первую очередь, с их использованием в различных отраслях программирования.
- Двоичная СС
Самая важная СС для вычислительной техники. Её использование обосновано, тем, что процессоры компьютеров работают на основе транзисторов, которые могут либо пропускать ток, либо его задерживать. Поэтому вся логика работы процессора построена на основе всего двух состояний (включено/выключено, открыто/закрыто, высокий/низкий, истина/ложь, да/нет, больше/меньше).
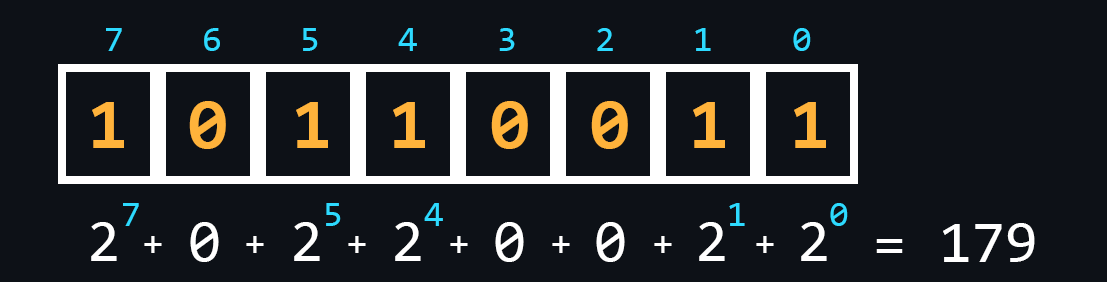
- Восьмиричная СС
Используется, например, в Linux-системах для выдачи прав доступа.

- Десятичная СС
СС которая удобная для восприятия большинству людей.
- Шестнадцатеричная СС
Для записи используются дополнительно буквы: A, B, C, D, E, F. Широко используется в низкоуровневом программировании и компьютерной документации из-за, того что минимальной адресуемой единицей памяти является 8-битный байт, значения которого удобно записывать двумя шестнадцатеричными цифрами.

- Перевод из одной СС в другую
Для лучшего понимания можно попробовать онлайн конвертер
- Двоичная СС
🔗 Ссылки на материалы
-
Логические операции
Логические операции широко используются в программировании для проверки различных условий. Результатом логического выражения всегда является "истина" или "ложь".
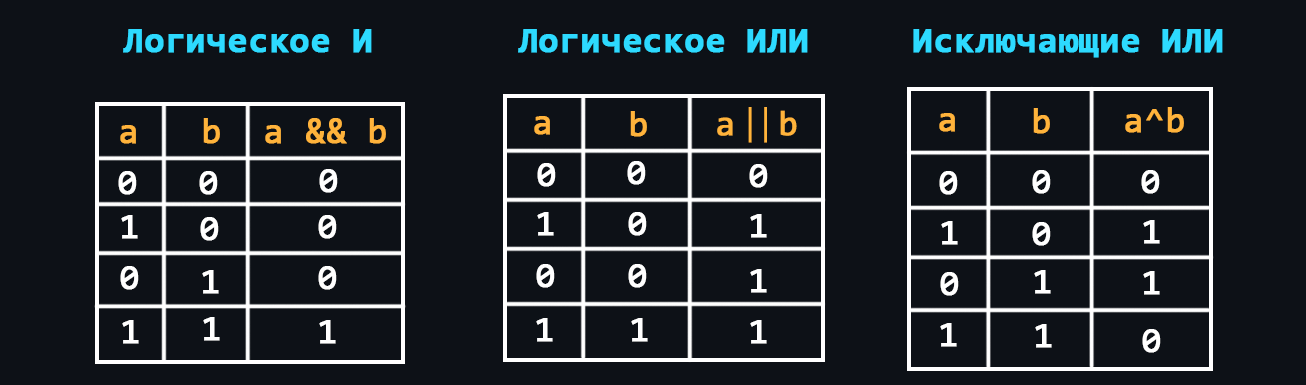
- Логическое "НЕ" (отрицание)
- Логическое "И" (конъюкция)
- Логическое "ИЛИ" (дизъюнкция)
- Исключающее "ИЛИ"
- Эквивалентность
- Неэквивалентность
🔗 Ссылки на материалы
-
Структуры данных
Структуры данных (СД) – это контейнеры в которых данные хранятся по определенным правилам. В зависимости от этих правил структура данных будет эффективна в одних задачах и неэффективна в других. Поэтому необходимо понимать, когда и где использовать ту или инную структуру.
- Массив
СД, которая позволяет хранить данные одинакового типа, где каждому элементу присваивается свой порядковый номер.
- Связный список
СД где все элементы, помимо данных, содержат ссылки на последующий и/или предыдущий элемент. Существуют 3 разновидности:
- Односвязный список – СД, где каждый элемент хранит ссылку только на следующий (одно направление).
- Двусвязный список – СД, где элементы содержат ссылки, как на следующий элемент, так и на предыдущий (два направления).
- Кольцевой спискок – разновидность двусвязного списка, где последний элемент кольцевого списка содержит указатель на первый, а первый — на последний.
- Стек
СД где хранение данных работает по принципу "последним пришел – первым вышел".
- Очередь
СД где хранение данных происходит по принципу "первым пришел – первым вышел".
- Хеш-таблица
По другому ассоциативный массив. Здесь для обращения к каждому из элементов используется соответсвующее ключевое значение, которое вычисляется по определенному алгоритму.
- Дерево
СД с иерархической моделью, в виде набора связанных между собой элементов.
- Куча
СД где элемент с наибольшим ключом всегда является корневым узлом кучи.
- Граф
Структура, которая предназначена для работы с большим количеством связей.
- Массив
🔗 Ссылки на материалы
-
Базовые алгоритмы
Алгоритмы подразумевают под собой наборы последовательных инструкций (шагов), которые приводят к решению поставленной задачи. За всю человеческую историю было придумано огромное количество алгоритмов, которые позволяют решать определенные задачи максимально эффективным способом. Соответственно правильный выбор алгоритмов в программировании позволит создавать максимально быстрые и ресурсоемкие решения.
Существует очень хорошая книжка по алгоритмам – Грокаем алгоритмы. С ней можно параллельно начать изучение языка программирования.
- Двоичный поиск
Максимально эффективный алгоритм поиска для отсортированных списков.
- Сортировка выбором
- Рекурсия
Когда функция может вызывать сама себя и так до бесконечности. С одной стороны решения на основе рекурсии выглядят очень элегантно, а с другой стороны такой подход очень быстро приводит к переполнению стека и его рекомендуют избегать.
- Сорировка пузырьком
- Быстрая сортировка
- Поиск в ширину
- Алгоритм Дейкстры
- Жадный алгоритм
- Двоичный поиск
🔗 Ссылки на материалы
- Алгоритмы и структуры данных. Подготовительный курс (плейлист) – YouTube
- Сортировки выбором – habr.com
- Рекурсия. Занимательные задачки – habr.com
- Пузырьковая сортировка и все-все-все – habr.com
- Алгоритм Дейкстры – habr.com
- Жадные алгоритмы – habr.com
- Сайт с алгоритмами и структурами данных
- Большая коллекция алгоритмов – GitHub
-
Оценка сложности алгоритмов
В мире программирования существует специальная единица измерения Big О (Большое О или О-нотация). Она описывает как сложность алгоритма растёт с увеличением количества входных данных. Дело в том, что один и тот же алгоритм запущенный на разных устройствах выполняется за разное время (завист от производительности устройства). Поэтому такая оценка не может быть релевантной. Вместо этого в Big O алгоритм оценивается по тому, сколько действий (шагов/итераций) необходимо совершить для его выполнения, при этом всегда показывая худший вариант развития событий.
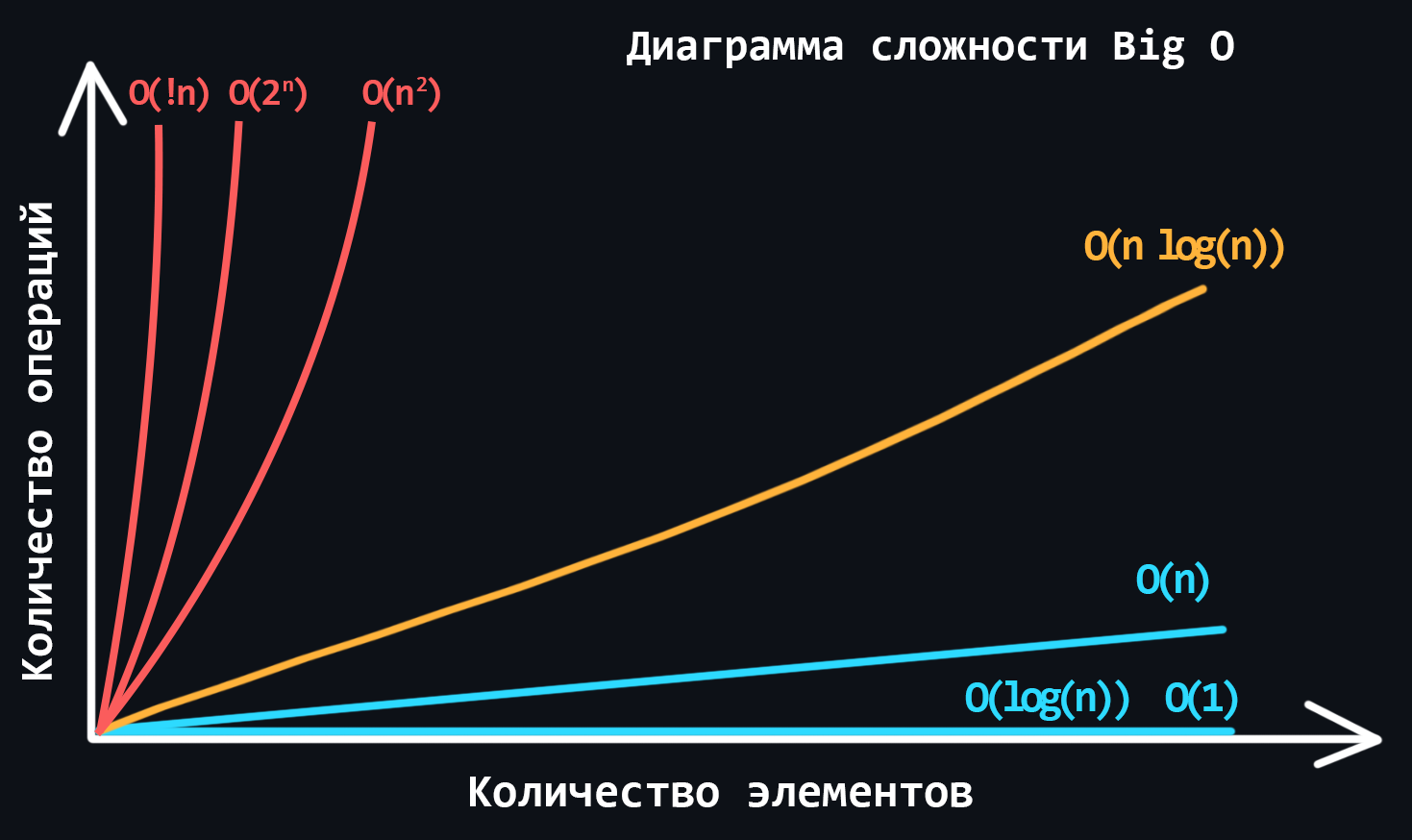
- Основные разновидности сложности алгоритмов
- Константная - O(1)
- Линейная - O(n)
- Логарифмическая - O(log n)
- Линеарифметическая - O(n * log n)
- Квадратичная - O(n^2)
- Степенная - О(2^n)
- Факториальная - O(!n)
- Константная - O(1)
- Основные разновидности сложности алгоритмов
🔗 Ссылки на материалы
-
Форматы хранения данных
Для хранения и передачи данных по сети могут использоватся файлы разных форматов. Текстовые файлы удобны для чтения человеку, поэтому они используются, например, для файлов конфигурации. Но передавать данные в текстовых форматах по сети не всегда рационально, поскольку они весят больше, чем соотвествующие им бинарые файлы.
-
Текстовые форматы
- JSON (JavaScript Object Notation)
Представляет из себя объект, в котом данные хранятся в виде пар ключ-значение.
- YAML (Yet Another Markup Language)
Формат близкий к языкам разметки по типу HTML. Минималистичный, поскольку не имеет открывающих и закрывающих тегов. Удобный для редактирования.
- XML (eXtensible Markup Language)
Формат более близкий к HTML. Здесь данные оборачиваются в открывающие и закрывающие теги.
- JSON (JavaScript Object Notation)
-
Бинарыне форматы
- Message Pack
Бинарный аналог JSON. Позволяет упаковывать данные на 15-20% эффективнее.
- BSON (Binary JavaScript Object Notation)
Является надмножеством JSON, включая дополнительно регулярные выражения, двоичные данные и даты.
- ProtoBuf (Protocol Buffers)
Бинарная альтернатива текстовому формату XML. Проще, компактнее и быстрее.
- Message Pack
-
🔗 Ссылки на материалы
-
Кодировки текста
Компьютеры работают только с числами, а если точнее только с 0 и 1. Как преобразовывать числа из разных систем счисления в двоичную, уже понятно. Но с текстом производить такие преобразования не получится. Именно поэтому были придуманы специальные таблицы, называемые кодировками, в которых текстовым символам присваиваются числовые эквиваленты.
- ASCII (American standard code for information interchange)
Самая простая кодировка, созданная специльно для американского алфавита. Состоит из 128 символов.
- Unicode
Это международная таблица символов, которая помимо английского алфавита, содержит алфавиты почти всех стран. Способна вместить в себя более миллиона различных символов (на данный момент таблица заполнена на полностью).
- UTF-8
Unicode-кодировка переменной длинны, с помощью которой можно представить любой символ unicode.
- UTF-16
Главное ее отличие от UTF-8 состоит в том что структурной единицей в ней является не один а два байта. То есть в кодировке UTF-16 любой символ юникода может быть закодирован либо двумя, либо четырьмя байтами.
- ASCII (American standard code for information interchange)
🔗 Ссылки на материалы
Язык программирования
На этом этапе Вам предстоит выбрать для изучения один из языков программирования. В открытом доступе полно информации по различным языкам, (книги, курсы, тематические сайты и т.д.) поэтому с у Вас не должно возникнуть проблем.
Ниже приведен список конкретных языков, которые лично по моему мнению хорошо подходят для backend-разработки (⚠️ может не совпадать с мнением других людей, в том числе более компитентных в этом вопросе).
- Python
Очень популярный язык с широким спектром применений. Лёгкий в изучении, благодаря простому синтаксису.
- JavaScript
Не менее популярный и практический единственный язык для полноценной Web-разработки. Благодаря платформе Node.js последнее несколько лет набирает популярность и в области backend-разработки.
- Go
Язык созданный внутри компании Google. Создавался специально для высоконагруженной серверной разработки. Минималистичный синтаксис, высокая производительность и богатая стандартная библиотека.
- Kotlin
Этакая современная версия Java. Более простой и локаничный синтаксис, лучшая типобезопасность, наличие встроенных инструментов для многопоточности. Один из лучших выборов для разработки под Android.
После того как вы определились с ЯП, советую поискать специальный awesome-репозиторий – ресурс в котором собрано огромное количество полезных ссылок на материалы под Ваш ЯП (библиотеки, шпаргалки, блоги, сайты и т.д).
В будущем планируется создание шпаргалки по одному из вышеупомянутых языков.
-
Классификация языков программирования
Языков программирования много. Все они созданы не просто так. Некоторые языки могут быть совсем специфическими и использоваться только для определенных целей. Также, разные языки могут использовать разные подходы к написанию программ. А могут вообще по разному исполняться на компьютере. В общем существует множество различных классификаций, в которых было бы полезно разобраться.
- В зависимости от уровня языка
- Языки низкого уровня
Максимально близкие к машинному коду, сложные в написании, но максимально прозводительные. Как правило предоставляют доступ ко всем ресурсам компьютера.
- Языки высокого уровня
Имеют достаточно большой уровень абстракции, за счет чего достигается простота и удобство написания. Как правило безопаснее, поскольку не предоставляют доступ ко всем ресурсам компьютера.
- Языки низкого уровня
- Компилируемые, интерпретируемые и встраиваемые языки
- Компиляция
Позволяет преобразовать исходный код программы в исполняемый файл.
- Интерпретация
Исходный код программы транслируется и сразу выполняется (интерпретируется) с помощью специальной программы-интерпретатора.
- Компиляция
- В зависимости от парадигмы программирования
- В зависимости от уровня языка
🔗 Ссылки на материалы
-
Методы программирования
🔗 Ссылки на материалы
-
Основы языка
Под основами подразумеваются некоторые фундаментальные идеи, присутствующие в каждом ЯП.
- Переменные и константы
- Типы данных
Строки, целые числа, дробные числа, boolean и т.д.
- Операторы
Математические операторы, операторы сравнения, побитовые операторы.
- Функции
Работа с аргументами и возвращаемыми данными.
Понимание области видимости переменных. - Управление потоком
Циклы for, условия if else, switch-case.
- Структуры данных
Массивы, объекты, классы и т.д.
- Стандартная библиотека
Здесь имеется ввиду встроенные возможности языка для манипуляции со строками, числами, массивами и т.д.
- Регулярные выражения
Мощный интсрумент для работы со строками. Обязательно ознакомтесь с этим в своем ЯП, хотя бы на базовом уровне.
- Пакетный менеджер
Рано или поздно, возникнет желание воспользоваться сторонними библиотеками.
🔗 Ссылки на материалы
-
Разработка серверов
- Создание и запуск локального HTTP-сервера
- Раздача статических файлов
Поднятие HTML-страничек; хостинг картинок, PDF-файлов и т.д.
- Маршрутизация
Создание эндпоинтов (URL-адресов) при обращении к которым на сервере будет вызывается соответствующий обработчик.
- Обработка запросов
Как правило в HTTP-обработчиках имеется специальный объект в который приходит вся информация о запросе пользователя (заголовки, метод, тело-запроса, полный url с параметрами и т.д.)
- Обработка ответов
Отправка соответствующего сообщения на поступивший запрос (HTTP-статус и код, тело-ответа, заголовки и т.д.)
- Обработка ошибок
Всегда нужно предусматривать варианты когда пользователь может отправить некорректные данные, база данных не выполнила операцию или просто в приложении произошла непредвиденная ошибка, чтобы сервер не падал, а отвечал ответом с информацией об ошибке.
- Отправка запросов
Часто внутри одного приложения вам придется обращаться по сети к другому. Поэтому важно уметь отправлять HTTP-запросы используя встроенные возможности ЯП.
- Шаблонизатор
Представляет собой специальный модуль, использующий более удобный синтаксис для формирования HTML на основе динамических данных.
🔗 Ссылки на материалы
-
Многопоточность
Сегодня компьютеры имеют процессоры с несколькими физическими и виртуальными ядрами, а если взять в расчет серверные машины, то там их количество может доходить до сотен. Все эти имеющиеся ресурсы хорошо бы задействовать по полной, для максимальной производительности приложения. Поэтому современная серверная разработка не обходится без реализации многопоточности и распараллеливания.
- Race conditions и data races
Основные проблемы которые возникают при использовании многопоточности.
- Создание процессов
- Создание потоков
- Сопрограммы (сorutines)
Легковесные потоки исполнения кода, которые организуются поверх аппаратных (системных) потоков. Могут существовать как отдельные библиотеки или быть уже встроенными в ЯП.
- Атомарные операции
Операции которые выполняются полностью, либо не выполняются вообще.
- Блокировки
Использование семафоров и мьютексов для синхронизации данных.
- Race conditions и data races
🔗 Ссылки на материалы
-
Продвинутые темы
- Сборщик мусора (garbage collector)
Процесс благодаря которому сильно популяризировались языки высокого уровня – позволяет программисту не заботится о выделении и очистке памяти. Обязательно ознакомьтесь с тонкостями его работы в своем ЯП.
- Отладчик кода (debuger)
Удобный инструмент для анализа работы кода программы и выявления ошибок.
- Сборщик мусора (garbage collector)
🔗 Ссылки на материалы
-
Качество кода
За эти долгие годы, что существует программирование было написано огромное количество кода, программ и целых систем. Ну и как следствие, при разработке всего этого возникали разного рода проблемы. В первую очередь они были связаны с масштабированием, поддержкой, а также порогом входа для новых разработчиков. Умные люди, естественно, не сидели на месте и начали решать эти проблемы, тем самым создавая так называемые паттерны/принципы/подходы для написания качественного кода.
Изучив лучшие практики программирования, вы не только сделаете лучше для себя, но и для других, поскольку с вашим кодом будут работать другие разработчики.
🔗 Ссылки на материалы
Базы данных
База данных (БД) – набор данных, которые организованы по определённым правилам. Например, библиотека является базой данных для книг.
Система управления базой данных (СУБД) – программное обеспечение, которое позволяет создать БД и удобно ей манипулировать (выполнять различные операции над данными). Примером СУБД может являться библиотекарь. Он может легко и эффективно работать с книгами в библиотеке: выдавать запрашиваемые книги, принимать их обратно, добавлять новые и т.д.
-
Классификация баз данных
БД могут существенно отличаться друг от друга и соответственно иметь разные области применения. Для понимания какая БД подойдёт для той или иной задачи, необходимо разобраться с классификацией.
- Реляционные БД (relation – отношение, связь)
Представляют из себя хранилища, где данные организованны в виде набора таблиц (со строками и столбцами). Взаимодействия между данными организуются на основе связей между этими таблицами. БД такого типа обеспечивает быстрый и эффективный доступ к структурированной информации.
- Объектно-ориентированные БД
Здесь данные представляются в виде объектов с набором атрибутов и методов. Подходят для тех случаев, когда требуется высокопроизводительная обработка данных, имеющих сложную структуру.
- Распределенные
Состоят из нескольких частей, расположенных на разных компьютерах (серверах). Такие БД могут полностью исключать дублирование информации, либо полностью её дублировать в каждой распределенной копии (например, как блокчейн)
- Нереляционные (NoSQL)
Хранят и обрабатывают неструктурированные или слабоструктурированные данные. Этот тип БД подразделяется на подтипы:
- Модель ключ-значение
- Семейство столбцов (строки и столбцы используются как ключи)
- Документоориентированные (хранят данные в виде иерархии документов)
- Графовые (применяются для данных с большим количеством связей)
- Модель ключ-значение
- Реляционные БД (relation – отношение, связь)
🔗 Ссылки на материалы
-
Реляционная база данных
Наиболее популярные реляционные БД: MySQL, PostgreSQL, MariaDB, Oracle.
SQL (Structured Query Language) – специальный язык для работы с реляционными базами данных. Он довольно простой и интуитивно понятный.
Удобная документация по SQL на русском языке здесь.
- Основы SQL
Не забывайте про точку с запятой в конце каждой команды.
- Создание новой БД
CREATE DATABASE db_name;- Создание новой таблицы
CREATE TABLE users ( id SERIAL PRIMARY KEY, # Уникальный id firstName VARCHAR(100), # Строка lastName VARCHAR(100), # Строка age INT, # Число gender VARCHAR(10), # Строка isMarried BOOLEAN # true/false );- Основыне типы данных
- INT (целые числа от -2^32 до +2^32)
- FLOAT / DOUBLE / DECIMAL (дробные числа)
- CHAR / VARCHAR / TEXT (строки)
- DATA / DATETIME / TIME (дата и время)
- ENUM (перечисления - списки допустимых значений)
- И другие
- Добавление данных в таблицу
INSERT INTO users( firstName, lastName, age, gender, isMarried ) VALUES ( 'Alex', 'Manson' 25, 'male', false );- Выборка данных из таблицы
# SELECT ## Получить всю таблицу users SELECT * FROM users; ## Получить только столбцы firstName и age из таблицы users SELECT firstName, age FROM users; # LIMIT ## Получить первых 20 записей таблицы users SELECT * FROM users LIMIT 20; # DISTINCT ## Получить только уникальные значения из столбца firstName SELECT DISTINCT(firstName) FROM users; # WHERE ## Записи, где столбец gender = 'male' SELECT * FROM users WHERE gender = 'male'; ## AND, OR SELECT * FROM users WHERE age = 25 AND isMarried = falsel SELECT * FROM users WHERE age = 20 OR age = 50; # BETWEEN ## Записи, где значения столбца age находятся в промежутке от 20 до 30 SELECT * FROM users WHERE age BETWEEN 20 AND 30; #NULL ## Записи, где столбец lastName не пуст SELECT * FROM users WHERE lastName IS NOT NULL;- Поиск данных по шаблону
# IN, LIKE, NOT LIKE ## % - подстановочный знак, который указывает на любое кол-во символов ## _ - подстановочный знак, который указывает на один символ ## Записи, где firsName равен 'John', 'Mike' или 'Kane' SELECT * FROM users WHERE firstName IN ('John', 'Mike', 'Kane'); ## Записи, где firsName начинается c буквы 'A' SELECT * FROM users WHERE firstName LIKE 'A%'; ## Записи, где первая буква в firstName равна 'A', 'B' или 'C' SELECT * FROM users WHERE firstName LIKE '[ABC]%'; ## Записи, где вторая буква в firsName не равна 'o' SELECT * FROM users WHERE firstName NOT LIKE '_o%';- Сортировка и фильтрация данных таблиц
# ORDER BY ## ASC - по возрастанию (по умолчанию) ## DESC - по убыванию SELECT * FROM users ORDER BY firstName ASC; SELECT * FROM users ORDER BY age DESC; SELECT * FROM users ORDER BY lastName DESC, isMarried ASC; # HAVING ## Фильтрация результатов группировки- Использование псевдонимов
# AS SELECT firstName AS name FROM users WHERE name = "Alex";- Изменение таблиц
# ALTER TABLE ## Добавить новую колонку city к таблицe users ALTER TABLE users ADD COLUMN city VARCHAR(50); ## Удалить колонку isMarried из тиблицы users ALTER TABLE users DROP COLUMN isMarried; ## Переименовать колокнку firstName в fName в таблицe users ALTER TABLE users RENAME COLUMN firstName TO fName; ## Переименовать таблицу users в consumers ALTER TABLE users RENAME TO consumers;- Изменение данных в таблице
# UPDATE ## Изменить в таблицe users записть с id = 1 UPDATE users SET firstName = 'Kale', age = 33 WHERE id = 1; ## Изменить записи, где gender = 'female' UPDATE users SET city = 'Paris' WHERE gender = 'famale';- Удаление данных из таблицы
# DELETE # Удалить запись в таблице users, где id = 2 DELETE FROM users WHERE id = 2; # Удалить все записи в таблице users, где gender = 'male' DELETE FROM users WHERE gender = 'male'; - Агрегатные функции
Используются для обобщения/подсчёта данных.
# COUNT ## Возвращает количество элементов в таблице users SELECT COUNT(*) FROM users; ## Возвращает количество не повторяющихся значений столбца firstName SELECT COUNT(DISTINCT(firstName)) FROM users; # MAX, MIN SELECT MAX(age) FROM users; SELECT MIN(age) FROM users; # SUM # Сумма всех значений столбца age SELECT SUM(age) FROM users; # AVG ## Среднее значение столбца age SELECT AVG(age) FROM users; - Объединение таблиц
- Запрос данных из нескольких таблиц
Оператор
JOIN; Комбинации с другими операторами; типы JOIN: (внешние/внутренние, левое/правое, перекресные, полные) - Свзяи между таблицами
Ссылки из одной таблицы на другую; внешние ключи (FOREIGN KEY)
- Запрос данных из нескольких таблиц
- Подзапросы
Запрос внутри другого запроса SQL
- Индексы
Структура данных, позволяющая быстро определить положение интересующих данных в базе.
- Транзакции
Последовательности команд, которые должны быть выполнены полностью, либо не выполнены вообще.
- Команда
START TRANSACTION - Команды
COMMITиROLLBACK
- Команда
- Работа с языком программирования
Для этого необходимо установить библиотеку под ваш ЯП. Для более удобной работы существуют ORM-библиотеки, которые позволяют выполнять SQL-запросы, как если бы вы просто вызывали методы у объекта.
- Основы SQL
🔗 Ссылки на материалы
-
MongoDB
MongoDB – документоориентированная БД (является классическим примером NoSQL баз данных), не требующая описания схемы таблиц. Использует JSON-подобные документы и схему БД.
- Основные команды
- Подготовка БД
show dbs // показать список всех БД use db_name // подкючится/создать БД с именем db_name db // вывести имя текущей базы данных db.createCollection("users") // создать коллекцию "notes" show collections // показать список коллекций в текущей БД db.dropDatabase() // удалить текущую БД- Добавление элементов
// Добавить один элемент db.users.insertOne({ name: "Alex", age: 27, isMarried: false, city: "NewYork" }) // Добавить несколько элементов db.users.insertMany([{...}, {...}])- Получение элементов
// Получить все элементы из коллекции db.users.find() // Получить элементы по указанному критерию db.user.find({age: 27}) // Получить один элемент db.users.findOne({name: "Alex"}) // Получить отсортированный список элементов // 1 - по возрастанию; -1 - по убыванию db.users.find().sort({age: 1}) // Получить количество элементов db.users.find().count() // Лимит количества получаемых элементов db.users.find().limit(10) // Выборка с помощью операторов сравнения db.users.find({age: {$gt: 20}}) // > 20 db.users.find({age: {$gte: 20}}) // >= 20 db.users.find({age: {$lt: 50}}) // < 50 db.users.find({age: {$lte: 50}}) // <= 50 db.users.find({age: {$ne: 35}}) // != 35- Изменение элементов
// Полное изменение элемента (первый аргрумент - критерий поиска) db.users.updateOne({name: "Alex"}, {новые_данные}) // Изменение определенных полей элемента db.users.updateOne({name: "Alex"}, {$set: {age: 28, isMarried: true}}) // Переименовать поле у нескольких элементов db.users.updateMany({name: "Alex"}, {&rename: {city: "town"}}) // Удаление элемента/элементов db.users.deleteOne({name: "Alex"}) db.users.deleteMany({name: "Alex"}) - Агрегации
Группировка значений из нескольких документов.
Три способа выполнения агрегации: pipeline, Map-Reduce и одноцелевые методы агрегирования. - Работа с индексами
- Работа с языком программирования
Для этого необходимо установить драйвер MongoDB под ваш ЯП.
- Основные команды
🔗 Ссылки на материалы
Разработка API
API (Application Programming Interface) – программный интерфейс, который описывает определенный набор правил, по которым различные программы (приложения, боты, сайты...) могут взаимодействовать друг с другом. С помощью вызовов API можно выполнить определённые функции программы, не зная, как она работает.
При разработке серверных приложений могут использоваться разные форматы API, в зависимости от поставленных задач и требований.
-
REST API
REST (Representational State Transfer) – архитектурный подход, который описывает набор правил того, как программисту организовать написание кода серверного приложения, чтобы все системы легко обменивались данными и приложение можно было легко масштабировать. При построении REST API широко используются методы HTTP-протокола.
Основные правила написания хорошего REST API:
- Каждый URL-эндпоинт должен быть существитвельным
Для выполнения разных операций (создание/получение/изменение/удаление) этот эндпоинт должен реализовывать обработчики на соответствующие HTTP-методы.
- Использование множественных названий
Например эндпоинт на получение записи по id выглядит так:
/task/:id, а для получения нескольких записей так:/tasks - Использование версионности
Подробная инструкция описана здесь.
- Использование соответствующих HTTP-кодов ответа
Самые часто используемые: 200, 201, 204, 304, 400, 401, 403, 404, 405, 410, 415, 422, 429.
- Каждый URL-эндпоинт должен быть существитвельным
🔗 Ссылки на материалы
-
GraphQL
GraphQL – это язык запросов, который описывает как запрашивать данные, и, в основном, используется клиентом для загрузки данных с сервера. Имеет три основных особенности:
- Позволяет клиенту точно указать, какие данные ему нужны, тем самым уменьшая потребление трафика от ненужных данных.
- Облегчает агрегацию данных из нескольких источников.
- Использует систему типов для описания данных.
Основные моменты:
- Система типов
Типы в GraphQL это кастомные объекты с определенным набором полей.
- Запросы (queries)
Объекты которые описывают способ получения данных.
- Изменения (mutation)
Описывают способы модификации данных на сервере.
- Подписки (subscription)
С помощью подписок поддерживается постоянная связь между клиентами и сервером.
🔗 Ссылки на материалы
-
WebSockets
Веб-сокеты это продвинутая технология, позволяющая открыть постоянное двунаправленное сетевое соединение между клиентом и сервером. С помощью его API вы можете отправить сообщение на сервер и получить ответ без выполнения HTTP-запроса, тем самым реализуя real-time взаимодействие.
Основная идея в том, что вам ненужно посылать запросы на сервер для получения новой информации. Когда соединение установлено, сервер сам будет отправлять новую порцию данных подключенным клиентам, как только эти данные появятся. Веб-сокеты широко используются для создания чатов, онлайн-игр, трейдерских приложений и т.д.
- Открытие веб-сокета
Отправка HTTP-запроса с определенным набором заголовков:
Connection: Upgrade,Upgrade: websocket,Sec-WebSocket-Key,Sec-WebSocket-Version. - Состояния соединения
CONNECTING,OPEN,CLOSING,CLOSED. - События
Open,Message,Error,Close. - Коды закртыия соединения
1000,1001,1006,1009,1011и т.д.
- Открытие веб-сокета
🔗 Ссылки на материалы
-
RPC и gRPC
RPC (remote procedure call) – технология удаленного вызова процедур. Фактически, это просто вызов функции на сервере с набором определенных аргументов, который ответом отдает результат вызова этой функции.
Основные RPC-протоколы:
- SOAP
Протокол работающий с использованием языка XML. Разработан в 1998 году. Из-за сложности XML и большого потребления трафика не рекомендуется к использованию.
- JSON-RPC
Протокол с очень простой спецификацией. Все вызовы и ответы это записи в формате JSON.
- gRPC
Бинарный протокол созданный Google и использующий язык Protobuf.
- SOAP
🔗 Ссылки на материалы
-
WebRTC
WebRTC – open-source проект для организации передачи потоковых данных (видео, звука) в браузере. Работа WebRTC основана на peer to peer соединении, однако существуют реализации позволяющие организовывать сложные групповые сеансы. Например, сервис видео-звонков Google Meet широко использует WebRTC.
🔗 Ссылки на материалы
Программное обеспечение
-
Система контроля версий Git
Git - специальная система для управления историей изменения исходного кода. Любые изменения которые вносятся в Git могут быть сохранены, что позволяет откатываться (возвращаться) на ранее сохраненную копию проекта. На данный момент Git является стандартом для разработки.
- Основные команды
git init # инициализация Git в текущей папке git add [файл] # добавить файл в Git git add . # добавить все файлы в папке в Git git reset [файл] # отменить добавление указанного файла git reset # отменить добавление всех файлов git commit -m "ваш текст" # создать коммит (сохранение) git status # показывает статус добавленных файлов git push # отправить текущие коммиты в удаленный репозиторий git pull # загрузить изменения с удаленного репозитория git clone [ссылка] # склонировать указанный репозиторий к себе на ПК - Работа с ветками
Ветвление позволяет отклонятся от основной линии разработки и продолжать работу независимо.
git branch # показать список текущих веток git branch [имя] # создать новую ветку от текущего коммита git checkout [имя] # переключиться на указанную ветку git merge [имя] # слияние указанной ветки в текущую ветку git branch -d [имя] # удалить указанную ветку - Отмена коммитов
git revert HEAD --no-edit # создать новый коммит который отменяет изменения предыдущего git revert [хэш_коммита] --no-edit # то же действие, но с указанным коммитом - История изменений
git log [ветка] # показать коммиты указанной ветки git log -3 # показать 3 последних коммита текущей ветки git log [файл] # показать историю коммитов указанного файла
- Основные команды
🔗 Ссылки на материалы
-
Docker
Docker - специальная программа, которая позволяет запускать изолированные песочницы (контейнеры) с различным предустановленным окружением (будь-то определенная операционная система, база данных и т.д.). Технология контейнеризации, которую предоставляет Docker, схожа с виртуальными машинами. Но, в отличие от виртуальных машин, контейнеры не создают такой дополнительной нагрузки, поскольку используют ядро хостовой ОС.
- Образ (image)
Специальный фиксированный шаблон, в котором содержится описание среды для запуска приложения (ОС, исходный код, библиотеки, переменные окружения, файлы конфигурации и т.д.). Образы можно скачивать с официального сайта и на их основе создавать свои.
- Контейнер (container)
Изолированная среда, созданная на основе какого-либо образа. По сути это является запущенным процессом на компьютере, который внутри содержит то окружение, которое описано в образе.
- Основные команды
docker pull [имя_образа] # Загрузить образ из сети docker images # Список доступных образов docker run [id_образа] # Запуск контейнера на основе выбранного образа # Некоторые флаги для команды run: -d # Запуск с возвратом в консоль --name [имя] # Задать имя контейнеру --rm # Удалить контейнер после остановки -p [локальный_порт][порт_внутри_контейнера] # Проброс портов docker build [путь_к_Dockerfile] # Создание образа на основе Dockerfile docker ps # Список запущенных контейнеров docker ps -a # Список всех контейнеров docker stop [id/имя_контейнера] # Остановить контейнер docker start [id/имя_контейнера] # Запустить существующий контейнер docker attach [id/имя_контейнера] # Подключится к консоли контейнера docker logs [id/имя_контейнера] # Вывести логи контейнера docker rm [id/имя_контейнера] # Удалить контейнер docker container prune # Удалить все контейнеры docker rmi [id_образа] # Удалить образ - Инструкции Dockerfile
Dockerfile представляет собой файл с набором инструкций и аргументов для создания образов.
FROM [имя_образа] # Задание базового образа WORKDIR [путь] # Задание корневой директории внутри контейнера COPY [путь_относительно_Dockefile] [путь_в_контейнере] # Копирование файлов ADD [путь] [путь] # Аналогично команде выше RUN [команда] # Команда которая запускается только при инициализации образа CMD ["команда"] # Команда которая отрабатывает каждый раз при запуске контейнера ENV КЛЮЧ="ЗНАЧЕНИЕ" # Установка переменных окружения ARG ИМЯ=ЗНАЧЕНИЕ # Задание переменных для передачи Docker во время сборки образа ENTRYPOINT ["команда"] # Команда которая запускается во время работы контейнера EXPOSE порт/протокол # Указывает на необходимость открыть порт VOLUME ["путь"] # Создаёт точку монтирования для работы с постоянным хранилищем - Docker-compose
Специальный инструмент позволяющий одновременно запускать несколько контейнеров с разной инфраструктурой. В каком-то смысле это Dockerfile на максималках.
- Образ (image)
🔗 Ссылки на материалы
-
Postman/Insomnia
При создании серверной части приложения, возникает необходимость в тестировании его работоспособности. Это можно сделать разными способами. Один из самых простых – это воспользоваться консольной утилитой curl. Но такой способ годится если ваше приложение не большое и имеет всего несколько эндпоинтов. Намного эффективнее использовать специальное ПО для тестирования, которое имеют удобный интерфейс и весь необходимый функционал для автоматизации.
- Postman
Очень популярная и многофункциональная программа. Здесь точно есть всё, что Вам может пригодиться и даже больше: начиная от банального создания коллекций до поднятия mock-серверов. Основной функционал приложения предоставляется бесплатно.
- Insomnia
Не такой популярный, но очень приятный инструмент. Интерфейс в Insomnia, минималистичный и понятный. Здесь поменьше функционала, но все самое необходимое есть: коллекции, переменные, автоматические тесты и т.д. Имеется возможность установки сторонних плагинов.
- Postman
🔗 Ссылки на материалы
-
Веб-сервера
Главной задачей любого веб-сервера является обработка клиентских запросов и отправка ответов по протоколу HTTP (HTTPS). Помимо этого веб-сервера могут вести журналы ошибок (логи), производить аунтефикацию и авторизацию, хранить правила на обработку файлов и т.д.
🔗 Ссылки на материалы
- Что такое веб сервер и для чего он нужен? – YouTube
- Что такое Nginx
- Основы Nginx (плейлист) – YouTube
- NGINX изнутри: рожден для производительности и масштабирования – habr.com
- Что такое Apache
- Apache vs Nginx: практический взгляд – habr.com
- Установка web-сервера Apache на Linux Ubuntu и публикация web-сайта – YouTube
- Web-технологии. Web сервера | Технострим – YouTube
- Веб-сервер на Ubuntu 18 с нуля: nginx, HTTP/2, Brotli и HTTPS – YouTube
-
Брокеры сообщений

При создании масштабной backend-системы может возникать проблема коммуникации между большим количеством микросервисов. Чтобы не усложнять уже имеющиеся сервисы (налаживать надеждную систему коммуникации, распределять нагрузку, предусматривать различные ошибки и т.д.) можно использовать отдельный сервис, который назвается брокером сообщений (очередью сообщений).
Брокер берет на себя ответсвенность создания надежной и отказоустойчивой системы коммуникации между сервисами (выполняет балансировку, гарантирует доставки, мониторит получателей, ведёт логи, буферизацию и т.д.)
Под сообщением понимается обычный HTTP запрос/ответ с данными определенного формата.
🔗 Ссылки на материалы
- Системы доставки сообщений, для чего они нужны? – YouTube
- Что такое очередь сообщений? – Amazon)
- Понимание брокеров сообщений. Изучение механики обмена сообщениями – habr.com
- Микросервисы: Коммуникации через очередь сообщений – YouTube
- RabbitMQ Tutorial на русском (плейлист) – YouTube
- Что такое Apache Kafka за 5 минут – YouTube
- Apache Kafka: основы технологии – habr.com
- Про Kafka (основы) – YouTube
- Брокер сообщений Kafka в условиях повышенной нагрузки – YouTube
- Выбор MQ для высоконагруженного проекта – habr.com
Кэширование
Кэширование является одним из самых действенных решений по оптимизации работы веб-приложений. Благодаря кэшированию можно повторно использовать ранее полученные ресурсы (статические файлы), тем самым сокращая задержку, снижая сетевой трафик и уменьшая время, необходимое для полной загрузки контента.
-
CDN
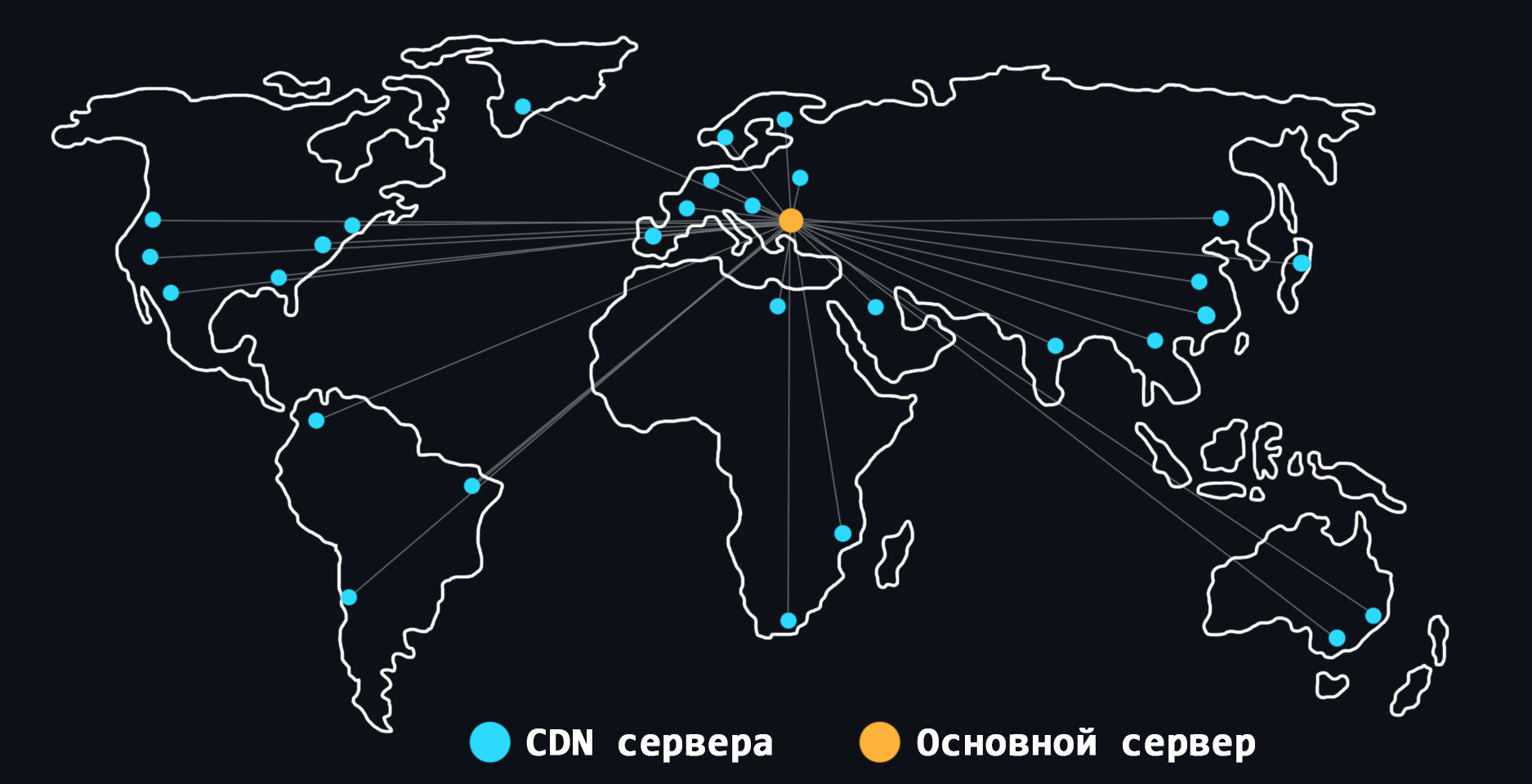
CDN (Content Delivery Network) – система серверов расположенная по всему миру. Такие сервера позволяют хранить дубликаты статического контента и доставлять его намного быстрее тем пользователям, которые находятся в непосредственной географической близости. Так же при использовании CDN снижается нагрузка на главный сервер.
🔗 Ссылки на материалы
-
Client side
Браузерное (клиентское) кэширование основано на загрузке страниц и других статических данных из локального кэша. Для этого браузеру отдается специальный заголовок 304 Not Modified
- Кэширование файлов и картинок
Регулируется заголовком Expires, который задает время актуальности данных из кэша. Из минусов, можно отметить то, что если данные на сервере изменились, то клиент не узнает об этом пока не закончится время действия заголовка или кэш не будет сброшен клиентом вручную.
- Кэширование HTTPS
Заголовок Strict-Transport-Security позволяет закешировать информацию о том, что ресурс досупен по протоколу HTTPS и не нужно дожидаться перенаправления.
- Кэширование центра сертификации
Сохранение информации о достоверности сертификата веб-сайта.
- Кэширование файлов и картинок
🔗 Ссылки на материалы
- Учебное пособие по кэшированию – habr.com
- Кэширование и производительность веб-приложений – habr.com
- Основы кеширования веб-приложений
- HTTP-кеширование – (MDN) mozilla.org
- Четыре уровня кэширования в сети: клиентский, сетевой, серверный и уровень приложения – tproger.ru
- «HTTP Strict-Transport-Security» или как обезопасить себя от атак «man-in-the-middle» и заставить браузер всегда использовать HTTPS – habr.com
-
Redis
Redis – быстрое хранилище данных работающее со струкрурами типа ключ-значение. Может использоватся в качестве базы данных, кэша, брокера сообщений или очереди.
- Типы данных
Строки / Списки / Множества (sets) / Хэш-таблицы (hashes) / Упорядоченные множества (sorted sets)
- Базовые операции
SET key "value" # установка ключа key со значение "value" GET key # получить значение по указанному ключу SETNX key "data" # создание ключа и установика значения, если ключ еще не существует MSET key1 "1" key2 "2" key3 "3" # установка нескольких ключей MGET key1 key2 key3 # получение значений сразу по нескольким ключам DEL key # удалить пару ключ-значение INCR someNumber # увеличение числового значения по ключу на 1 DECR someNumber # уменьшение числового значения по ключу на 1 EXPIRE key 1000 # установить таймер жизни ключа 1000 секунд TTL key # получить информацию о времени жизни пары ключ-значение # -1 ключ существует, но не имеет срока действия # -2 ключ не существует # <другое число> время жизни ключа в секундах SETEX key 1000 "value" # объединение команды SET и EXPIRE - Транзакции
MULTI— начать запись команд для транзакции.
EXEC— выполнить записанные команды.
DISCARD— удалить все записанные команды.
WATCH— команда, обеспечивающая выполнение только в случае, если другие клиенты не изменили значение переменной. Иначе EXEC не выполнит записанные команды.
- Типы данных
🔗 Ссылки на материалы
-
Memcached
Memcached – программа-демон которая реализует высокопроизводительное кэширование в оперативной памяти на основе пар ключ-значение. В отличие от Redis не может являться надеждным и долговременным хранилищем, поэтому подходит только для кэша.
🔗 Ссылки на материалы
Безопасность
-
Уязвимости веб-приложений
- Межсайтовый скриптинг (XSS)
Атака, которая позволяют злоумышленнику внедрять вредоносный код через веб-сайт в браузеры других пользователей.
- SQL-инъекций
Атака может быть возможна если, пользовательский ввод, который передаётся в SQL-запрос, способен изменить смысл оператора или добавить туда другой запрос.
- Подделка межсайтовых запросов (CSRF)
Когда на сайте для выполнения какой-либо операции используется POST-запрос, злоумышленник может подделать форму, например в электронном письме и отправить его жертве. Затем жертва, являющаяся авторизованным пользователем, взаимодействую с этим письмом, не зная того, может отправить запрос на сайт с данными, которые задал злоумышленник.
- Кликджекинг (Clickjacking)
Принцип основан на том, что поверх видимой веб-страницы располагается невидимый слой, в который и загружается нужная злоумышленнику страница, при этом элемент управления (кнопка, ссылка), необходимый для осуществления требуемого действия, совмещается с видимой ссылкой или кнопкой, нажатие на которую ожидается от пользователя.
- DoS-атака (Denial of Service)
Хакерская атака, которая приводит к перегрузке сервера, на котором работает веб-приложение, за счет отправки огромного количества запросов.
- Неверная конфигурация безопасности
Использование параметров конфигурации по умолчанию может быть опасным, поскольку это общеизвестная информация. К примеру, частой уязвимостью является то, что сетевые администраторы оставляют стандартные логины и пароли admin:admin.
- Межсайтовый скриптинг (XSS)
🔗 Ссылки на материалы
- Веб-безопасность – (MDN) mozilla.org
- Безопасность веб-приложений: от уязвимостей до мониторинга – habr.com
- Безопасность: уязвимости вашего приложения – YouTube
- Как защитить веб-приложение: основные советы, инструменты, полезные ссылки – tproger.ru
- Что такое XSS-уязвимость и как тестировщику не пропустить ее – habr.com
- DDoS-атаки: нападение и защита – habr.com
- Безопасность Web-приложений (плейлист) – YouTube
- Безопасность интернет-приложений (плейлист) – YouTube
- Аналитика уязвимостей и угроз веб-приложений за 2019 год
-
Криптография

Для обеспечения безопасности в сети широко используется криптографические алгоритмы на основе хеш-функций.
Основные понятия:
- Хеширование
Процесс преобразования массива информации (от одной буквы и хоть до целого литературного произведения) в некую уникальную короткую строку символов (называемую хэшем), которая присуща только этому массиву информации. Причем если в этом массиве информации изменить хоть один символ, то новый хэш будет отличатся кардинально.
Хеширование является необратимым процессом, то есть по полученному хэшу невозможно восстановить изначальные данные. - Контрольные суммы
Хэши могут использоваться как контрольные суммы, которые служат доказательством целостности данных.
- Коллизии
Cлучаи когда хеширование разного набора информации приводит к одинаковым хэшам.
- Соль (в криптографии)
Случайная строка данных, которая добавляется к входным данным перед хешированием, для вычисления хэша. Это необходимо для усложнения взлома методом перебора.
Основные алгоритмы шифрования:
- Семейство SHA (Secure Hash Algorithm)
SHA-256 наиболее популярный алгоритм шифрования. Используется, например, в Bitcoin.
- Семейство MD (Message Digest)
Наиболее популярный алгоритм семейства – MD5. Сейчас считается очень уязвимым к коллизиям (существуют даже генераторы коллизий для MD5).
- CRC (Cyclic redundancy check)
Алгоритм нахождения контрольной суммы, предназначенный для проверки целостности данных.
- Хеширование
🔗 Ссылки на материалы
- Что такое криптография?
- Хеш-функция, что это такое? – habr.com
- Что такое ХЭШ функция? | Хеширование – YouTube
- Hash/Хеш - просто о сложном – YouTube
- Как работает SHA256 – YouTube
- «Привет, мир»: разбираем каждый шаг хэш-алгоритма SHA-256 – habr.com
- Все методы взлома MD5
- CRC: как защитить программу
- Простой расчет контрольной суммы – habr.com
-
Аунтификация и авторизация
Важно понимать отличие между двумя этими понятиями.
Аунтификация – процедура проверки подлинности пользователя. Как правило выполняется путем сравнения введенного пользователем пароля с паролем, сохраненным в базе данных. Так же, в это понятие часто включают и идентификацию – процедуру выявления пользователя по его уникальному идентификатору (как правило это обычный логин или email). Это нужно, чтобы точно знать для какого пользователя выполняется проверка подлинности.
Авторизация – процедура выдачи прав доступа определенному пользователю на выполнение определенных операций. Например обычные пользователи интрернет-магазина могут просматривать товары, добавлять их в корзину. А вот добавлять новые товары или удалять уже имеющиеся могут только администраторы.
- Basic Authentication
Наиболее простая схема аунтификации, при которой username и password пользователя передаются в заголовке Authorization в незашифрованном виде (base64-encoded). При использовании HTTPS является относительно безопасным.
- SSO (Single Sign-On)
Технология реализующая возможность перехода из одного сервиса в другой (не связанный с первым), без повторной аунтификации.
- OAuth / OAuth 2.0
Протокол авторизации благодаря которому можно зарегистрироваться в различных приложениях с помощью популярных сервисов (Google, Facebook, GitHub и т.д.)
- OpenID
Открытый стандарт, позволяющий создавать единую учётную запись для аутентификации на множестве не связанных друг с другом сервисов.
- JWT (Json Web Token)
Стандарт аунтификации работающий на основе токенов доступа. Токены создаются сервером, подписываются секретным ключом и передаются клиенту, который в дальнейшем использует данный токен для подтверждения своей личности.
- Basic Authentication
🔗 Ссылки на материалы
- Аутентификация и авторизация в микросервисных приложениях – habr.com
- Обзор способов и протоколов аутентификации в веб-приложениях – habr.com
- Как работает single sign-on (технология единого входа)? – habr.com
- Как работает OAuth 2 - введение (просто и понятно) – YouTube
- OAuth 2.0 простым и понятным языком – habr.com
- OpenID Connect. Теория – YouTube
- OpenID Connect простыми словами – habr.com
- Пять простых шагов для понимания JSON Web Tokens (JWT) – habr.com
- Виды авторизации: сессии, JWT-токены. Для чего нужны сессии? Как работает JWT? – YouTube
- JWT. Часть 1. Теория – YouTube
-
SSL/TLS
SSL (Secure Socket Layer) и TLS (Transport Layer Security) – это криптографические протоколы, которые обеспечивают защищёную передачу данных между двумя компьютерами в сети. По сути эти протоколы работают одинаково и отличий у них нет. SSL считается устаревшим, хотя все еще используется для поддержки старых устройств.
🔗 Ссылки на материалы
- Протоколы TLS/SSL | Защищенные сетевые протоколы – YouTube
- Как это работает: знакомство с SSL/TLS – habr.com
- TLS/SSL сертификаты и с чем их едят – YouTube
- Как HTTPS обеспечивает безопасность соединения – habr.com
- Шифрование в TLS/SSL | Защищенные сетевые протоколы – YouTube
- Как получить и настроить LetsEncrypt SSL сертификат для сайта? – YouTube
Тестирование
Тестирование позволяет проверить созданный программный продукт на то, что он работает именно так, как Вы задумали. Покрытие продукта должным количеством тестов, позволяет в дальнейшем проводить быстрые проверки на то, не сломалось ли что-нибудь в приложении, после добавления нового функционала.
Важно понимать: успешное прохождение тестов не даёт 100% гарантии, что Ваше приложение будет работать всегда без багов и ошибок. Тесты пишутся людьми и они физически не могут учесть все возможные варианты использования программы. Поэтому успешные результаты тестов подтверждают лишь должную работу базового функционала.
-
Unit-тесты
Самый простой вид тестов. Как правило, около 70-80% от всех тестов занимают именно unit-тесты. «Unit» означает, что тестируется не вся система в целом, а небольшие и отдельные её части (функции, методы, компоненты и т.д.) в изоляции от других. Всё зависимое внешнее окружнеие, как правило, покрывается моками (mocks).
🔗 Ссылки на материалы
-
Интеграционные тесты
Интеграционное тестирование подразумевает тестирование отдельных модулей (компонентов) в связке с другими (то есть, в интеграции).
🔗 Ссылки на материалы
-
E2E тесты
End-to-end тесты подразумевают тестирование работы всей системы в целом. При этом виде тестирования, реализуется среда максимально близкая к реальным условиям. Проводятся как для API, так и для Frontend-части через браузер.
🔗 Ссылки на материалы
-
Нагрузочное тестирование
Когда вы создаете большое приложение, которое должно обслуживать большое количество запросов, возникает необходимость в тестировании этой самой возможности выдерживать большие нагрузки. Для создания искусственной нагруженности существует множество утилит.
- JMeter
Удобный интерфейс, кроссплатформенность, поддержка многопоточности, расширяемость, отличные возможности по созданию отчётов, поддержка многих протоколов для запросов.
- LoadRunner
Имеет интересную функцию виртуальных пользователей, которые параллельно что-то делают с тестируемым приложением. Это позволяет понять как влияет работа одних пользователей, активно что-то делающих с сервисом, на работу других.
- Gatling
Очень мощный инструмент ориентированный уже не более опытных пользователей. Для описания сценариев используется Scala.
- Taurus
Целый фреймворк для более удобной работы над JMeter, Gatling и так далее. Для описания тестов используется JSON или YAML.
- JMeter
🔗 Ссылки на материалы
-
Регрессионное тестирование
Представим, что у нас уже есть приложение с некоторым работающим и протестированным функционалом. Теперь мы добавляем новую фичу. Естественно мы тоже её тестируем. И вроде бы все хорошо, но не совсем, поскольку мы не знаем, а не сломала ли эта новая фича старый функционал. Так вот для этого и существует регрессионное тестирование (это особенно важно на проектах, над которыми работает большая команда).
🔗 Ссылки на материалы
Построение архитектуры
-
Архитектурные шаблоны
🔗 Ссылки на материалы
-
Паттерны проектирования
Без лишних слов, вот превосходный сайт, где подробно описаны все паттерны, а также приведены примеры на различных ЯП.- Пораждающие паттерны
- Factory
- Abstract factory
- Builder
- Prototype
- Singleton
- Структурные паттерны
- Adapter
- Bridge
- Composite
- Decorator
- Facade
- Flyweight
- Proxy
- Поведенческие паттерны
- Chain of Responsibility
- Command
- Iterator
- Mediator
- Memento
- Observer
- State
- Strategy
- Template
- Visitor
- Пораждающие паттерны
🔗 Ссылки на материалы
Дополнительные и похожие ресурсы
- Backend Developer Roadmap: Learn to become a modern backend developer
- Профессия: бэкенд-разработчик
- Backend Roadmap (from Junior to Senior)
- A curated and opinionated list of resources (English & Russian) for Backend developers
- Timur Shemsedinov – открытые лекции, конференции, митапы по программной инженерии
- Hussein Nasser – один из лучших англоязычных каналов на YouTube по серверной разработке
- Курс по компьютерным сетям начального уровня
- Как освоить бэкенд-разработку в 2022 году: дорожная карта