Fixes#7279 by detecting missing `getClose()` and yielding an `UnclosedTextLiteral`.
# Important Notes
Special care must be taken for _text blocks_. They have `null` `getClose()`.
- Previous GraalVM update: https://github.com/enso-org/enso/pull/6750
Removed warnings:
- Remove deprecated `ConditionProfile.createCountingProfile()`.
- Add `@Shared` to some `@Cached` parameters (Truffle now emits warnings about potential `@Share` usage).
- Specialization method names should not start with execute
- Add limit attribute to some specialization methods
- Add `@NeverDefault` for some cached initializer expressions
- Add `@Idempotent` or `@NonIdempotent` where appropriate
BigInteger and potential Node inlining are tracked in follow-up issues.
# Important Notes
For `SDKMan` users:
```
sdk install java 17.0.7-graalce
sdk use java 17.0.7-graalce
```
For other users - download link can be found at https://github.com/graalvm/graalvm-ce-builds/releases/tag/jdk-17.0.7
Release notes: https://www.graalvm.org/release-notes/JDK_17/
R component was dropped from the release 23.0.0, only `python` is available to install via `gu install python`.
This PR does three related things:
- Fails more gracefully when a non-string is passed to compile_regex
- Don't pass a non-string to compile_regex
- Allow a Regex param to parse_to_table
The current instructions to _build, use and debug_ `project-manager` and its engine/ls process are complicated and require a lot of symlinks to properly point to each other. This pull requests simplifies all of that by introduction of `ENSO_ENGINE_PATH` and `ENSO_JVM_PATH` environment variables. Then it hides all the complexity behind a simple _sbt command_: `runProjectManagerDistribution --debug`.
# Important Notes
I decided to tackle this problem as I have three repositories with different branches of Enso and switching between them requires me to mangle the symlinks. I hope I will not need to do that anymore with the introduction of the `runProjectManagerDistribution` command.
This PR modifies the builtin method processor such that it forbids arrays of non-primitive and non-guest objects in builtin methods. And provides a proper implementation for the builtin methods in `EnsoFile`.
- Remove last `to_array` calls from `File.enso`
Less dependencies on `EnsoContext` - `Module` shall exist without it. `Module` is a result of a `Compiler` and shall be created before its execution - e.g. requiring `EnsoContext` (with all its runtime information) is a bit too _demanding_.
# Important Notes
The only reason why `Module` wanted `EnsoContext` was to create its (associated) `Type`. `Type`'s constructor needed a parent type and the code was asking for `Any` from the context. That's unnecessary at creation time - we can just use some constant (like `null`) and turning it into `Any` during execution. Benchmarks show that there is no slowdown doing so.
On a quest to avoid dependencies on `EnsoContext` from `Compiler`. Step one. The ultimate goal is to move `Compiler` and all its `IRPasses` into a dedicated `runtime/compiler` module that could be used from #7054.
part of #7178
Changelog:
- add: `text/fileModifiedOnDisk` notification
- update: during the auto-save, check if the file is modified on disk and send the notification. I.e. auto-save does not overwrite the file if it was changed on disk (but the save command does)
- update: IDE handles the file-modified-on-disk notification and reloads the module from disk
# Important Notes
Currently, the auto-save (and the check that the file is modified on disk) is triggered only after the file was edited. The proper check (using the file-watcher service) will be added in the next PR
https://github.com/enso-org/enso/assets/357683/ff91f3e6-2f7a-4c01-a745-98cb140e1964
As discovered in #7224, Json RPC protocol was added to the asynchronous resource initialization stage, as part of #6306, but was not in fact initialized at that point.
Instead it was initialized when the server was started to be able to serve correctly the initialization messages. A classic Catch-22. It was really hard to discover this just by looking at the code, but the profiling clearly showed where the time was spent.
This change splits Language Server's protocol into two:
- the first one accepts `heartbeat/init` and `session/initProtocolConnection`
- the second one enriches it with the full set of supported messages
This shifts the initialization from blocking for 0.5 sec to only ~30ms, and performing the second stage asynchronously.
Closes#7224.
# Important Notes
Before the change (blocking server startup):


After the change (1st stage):

After the change (2nd, asynchronous initialization, stage):

- Removed Array methods: `new`, `copy` and `new_[1234]`.
- New builtins for `Vector.insert`, `Vector.remove` and `Vector.flatten`.
- Replaced `Vector_Builder` use of `Array.copy` to a `Vector.Builder` approach.
Package's config information, once loaded, never changed. While there is typically no need for it, this was problematic when the config became out-of-sync with the filesystem, like in the case of project rename action.
In rename, the config's properties would be updated in the FS, but that would never be reflected in module's package. Therefore further compilations would continue to ask for the old namespace.
Most of the changes are cosmetic (s/`.config`/`.getConfig()`) except for the new `reloadConfig` method on `Package` that is being called in `RenameProjectCmd` handler.
Closes#7062.
# Important Notes
The reported `ExecutionFailed` error should have been mostly fixed already via #7143. This change makes sure that all the related warnings are gone as well and the compiler uses the updated namespace.
`executionFailed` instead is sent when an evaulation finishes with a a critical failure or a non-critical error.
The PR tries to miniminally modify the change in the messages exchange so as to avoid a major redesign at this point.
Closes#7002.
# Important Notes
Unblocks IDE which will need to modify to this new setup.
Mostly stuff to tidy up the static methods in the CB.
- Remove default pattern from `parse_to_table` (caused IDE to freeze).
- Rename any `_` arguments to what they are.
- Merge `Date.now` into `Date.today`
- Merge the Interval constructors into a single constructor.
- Hide various methods.
Fixes#6955 by:
- using `visualisationModule` to specify the module where the visualization is to be used
- referring to method in `Meta.get_annotation` with `.method_name` - e.g. unresolved symbol notation
- evaluating arguments to `Meta.get_annotation` in the context of the user module (which can access the extension functions)
Partially revert https://github.com/enso-org/enso/pull/6849, which introduced a regression in TCO in the presence of warnings. Rather than modifying the tail call status, `TailCallException` now propagates the extracted warnings and appends them to the final result.
Closes#7093
# Important Notes
Compared to the previous attempt we don't pay the penalty of adding the warnings or even checking for them because it is being dealt in a separate specialization.
Function bodies cannot be instrumented even if the function is right
inside a binding. Consider a scenario when a function is assigned to a
variable and then applied to a `map` method of a really large vector.
The instrumentation will render execution extremely slow.
Alternatively we would still support instrumenting function bodies in
this limited case but take into account the number of times function is
actually called.
Previously, static method calls on `Any` have not worked as expected. For example, `Any.to_text` returned Function instead of Text. That is because the function resolution for `Any.to_text` finds `Any.type.to_text` method on eigentype which expects two `self` arguments, but only one argument is provided.
Note that `Boolean.to_text` worked previously, and returned "Boolean" as expected. This is because the method resolution finds `Any.to_text` method that takes just one `self` argument.
This PR solves this issue by introducing special handling for static method dispatch on `Any`. Simply put, an additional `self` argument is prepended to the argument list.
# Important Notes
A new child node is introduced to `InvokeMethodNode`. This child node is a copy of the current `invokeFunctionNode` with one more `CallArgumentInfo` in its schema.
There is an issue that after a clean build, the compiler is unable to resolve some types, i.e
```py
$ ./built-distribution/enso-engine-0.0.0-dev-linux-amd64/enso-0.0.0-dev/bin/enso --run ~/enso/projects/Unnamed/
/home/dbushev/projects/luna/enso/built-distribution/enso-engine-0.0.0-dev-linux-amd64/enso-0.0.0-dev/lib/Standard/Database/0.0.0-dev/src/Connection/Database.enso:24:11: error: The name `Connection_Details` could not be found.
24 | connect : Connection_Details -> Connection_Options -> Connection ! SQL_Error
| ^~~~~~~~~~~~~~~~~~
/home/dbushev/projects/luna/enso/built-distribution/enso-engine-0.0.0-dev-linux-amd64/enso-0.0.0-dev/lib/Standard/Database/0.0.0-dev/src/Connection/Database.enso:24:33: error: The name `Connection_Options` could not be found.
24 | connect : Connection_Details -> Connection_Options -> Connection ! SQL_Error
| ^~~~~~~~~~~~~~~~~~
/home/dbushev/projects/luna/enso/built-distribution/enso-engine-0.0.0-dev-linux-amd64/enso-0.0.0-dev/lib/Standard/Database/0.0.0-dev/src/Connection/Database.enso:24:55: error: The name `Connection` could not be found.
24 | connect : Connection_Details -> Connection_Options -> Connection ! SQL_Error
| ^~~~~~~~~~
/home/dbushev/projects/luna/enso/built-distribution/enso-engine-0.0.0-dev-linux-amd64/enso-0.0.0-dev/lib/Standard/Database/0.0.0-dev/src/Connection/Database.enso:24:68: error: The name `SQL_Error` could not be found.
24 | connect : Connection_Details -> Connection_Options -> Connection ! SQL_Error
| ^~~~~~~~~
/home/dbushev/projects/luna/enso/built-distribution/enso-engine-0.0.0-dev-linux-amd64/enso-0.0.0-dev/lib/Standard/Database/0.0.0-dev/src/Connection/Database.enso:25:25: error: The name `Connection_Options` could not be found.
25 | connect details options=Connection_Options.Value =
| ^~~~~~~~~~~~~~~~~~
/home/dbushev/projects/luna/enso/built-distribution/enso-engine-0.0.0-dev-linux-amd64/enso-0.0.0-dev/lib/Standard/Database/0.0.0-dev/src/Connection/Database.enso:29:29: error: The name `Widget` could not be found.
29 | connection_details_widget : Widget
| ^~~~~~
/home/dbushev/projects/luna/enso/built-distribution/enso-engine-0.0.0-dev-linux-amd64/enso-0.0.0-dev/lib/Standard/Database/0.0.0-dev/src/Connection/Database.enso:31:28: error: The name `Vector` could not be found.
31 | default_constructors = Vector.from_polyglot_array <|
| ^~~~~~
/home/dbushev/projects/luna/enso/built-distribution/enso-engine-0.0.0-dev-linux-amd64/enso-0.0.0-dev/lib/Standard/Database/0.0.0-dev/src/Connection/Database.enso:32:63: error: The name `False` could not be found.
32 | DatabaseConnectionDetailsSPI.get_default_constructors False
| ^~~~~
/home/dbushev/projects/luna/enso/built-distribution/enso-engine-0.0.0-dev-linux-amd64/enso-0.0.0-dev/lib/Standard/Database/0.0.0-dev/src/Connection/Database.enso:36:9: error: The name `Option` could not be found.
36 | Option name code
| ^~~~~~
/home/dbushev/projects/luna/enso/built-distribution/enso-engine-0.0.0-dev-linux-amd64/enso-0.0.0-dev/lib/Standard/Database/0.0.0-dev/src/Connection/Database.enso:37:5: error: The name `Single_Choice` could not be found.
37 | Single_Choice display=Display.Always values=choices
| ^~~~~~~~~~~~~
/home/dbushev/projects/luna/enso/built-distribution/enso-engine-0.0.0-dev-linux-amd64/enso-0.0.0-dev/lib/Standard/Database/0.0.0-dev/src/Connection/Database.enso:37:27: error: The name `Display` could not be found.
37 | Single_Choice display=Display.Always values=choices
| ^~~~~~~
Aborting due to 11 errors and 0 warnings.
Execution finished with an error: Compilation aborted due to errors.
```
The compiler can't resolve those symbols because the `IR` cache for `Standard.Database.Connection.Database` is missing. What happens during the `buildEngineDistribution` is:
- Compiler processes libraries one by one
- Compiler processes (and compiles and generates caches) `Standard.Database` library
- Compiler starts processing `Standard.Visualization` library
- During the compilation of `Standard.Database.Connection.Database` module, it sees that the module was loaded from the cache. But some of the required dependencies from `Standard.Table` library were not loaded from the cache. But at this point, the `Standard.Table` library has not been processed yet and the caches for it don't exist. The compiler decides that the `Database` file was changed, and the cache is invalid and should be cleaned.
- Removed `module` argument from `enso_project` (new `Project_Description.new` API).
- Removed the custom option from date and time parse/format dropdowns.
- The `format` dropdown uses the value to create the dropdown. (Screenshot below)
- Removed `StorageType` coalescing rules and replaced them with simpler logic in `ObjectStorage`.
- Update signature for `add_row_number` and add aliases.
Request Timeouts started plaguing IDE due to numerous `executionContext/***Visualization` requests. While caused by a bug they revealed a bigger problem in the Language Server when serving large amounts of requests:
1) Long and short lived jobs are fighting for various locks. Lock contention leads to some jobs waiting for a longer than desired leading to unexpected request timeouts. Increasing timeout value is just delaying the problem.
2) Requests coming from IDE are served almost instantly and handled by various commands. Commands can issue further jobs that serve request. We apparently have and always had a single-thread thread pool for serving such jobs, leading to immediate thread starvation.
Both reasons increase the chances of Request Timeouts when dealing with a large number of requests. For 2) I noticed that while we used to set the `enso-runtime-server.jobParallelism` option descriptor key to some machine-dependent value (most likely > 1), the value set would **only** be available for instrumentation. `JobExecutionEngine` where it is actually used would always get the default, i.e. a single-threaded ThreadPool. This means that this option descriptor was simply misused since its introduction. Moved that option to runtime options so that it can be set and retrieved during normal operation.
Adding parallelism intensified problem 1), because now we could execute multiple jobs and they would compete for resources. It also revealed a scenario for a yet another deadlock scenario, due to invalid order of lock acquisition. See `ExecuteJob` vs `UpsertVisualisationJob` order for details.
Still, a number of requests would continue to randomly timeout due to lock contention. It became apparent that
`Attach/Modify/Detach-VisualisationCmd` should not wait until a triggered `UpsertVisualisationJob` sends a response to the client; long and short lived jobs will always compete for resources and we cannot guarantee that they will not timeout that way. That is why the response is sent immediately from the command handler and not from the job executed after it.
This brings another problematic scenario:
1. `AttachVisualisationCmd` is executed, response sent to the client, `UpsertVisualisationJob` scheduled.
2. In the meantime `ModifyVisualisationCmd` comes and fails; command cannot find the visualization that will only be added by `UpsertVisualisationJob`, which might have not yet been scheduled to run.
Remedied that by checking visualisation-related jobs that are still in progress. It also allowed for cancelling jobs which results wouldn't be used anyway (`ModifyVisualisationCmd` sends its own `UpsertVisualisationJob`). This is not a theoretical scenario, it happened frequently on IDE startup.
This change does not fully solve the rather problematic setup of numerous locks, which are requested by short and long lived jobs. A better design should still be investigated. But it significantly reduces the chances of Request Timeouts which IDE had to deal with.
With this change I haven't been able to experience Request Timeouts for relatively modest projects anymore.
I added the possibility of logging wait times for locks to better investigate further problems.
Closes#7005
- Add type detection for `Mixed` columns when calling column functions.
- Excel uses column name for missing headers.
- Add aliases for parse functions on text.
- Adjust `Date`, `Time_Of_Day` and `Date_Time` parse functions to not take `Nothing` anymore and provide dropdowns.
- Removed built-in parses.
- All support Locale.
- Add support for missing day or year for parsing a Date.
- All will trim values automatically.
- Added ability to list AWS profiles.
- Added ability to list S3 buckets.
- Workaround for Table.aggregate so default item added works.
close#6936
Changelog:
- add: new suggestion type Getter that is not exposed to the api
- update: do not return suggestion of type getter when doing a global search (without specifying self types)
Private suggestions and modules mentioned in the issue will be filtered out after we finish the work on the new (refined) exports algorithm.
# Important Notes

As demonstrated in https://github.com/enso-org/enso/actions/runs/5175688022/jobs/9323585204?pr=6940
```
org.enso.interpreter.test.instrument.RuntimeAsyncCommandsTest *** ABORTED ***
org.graalvm.polyglot.PolyglotException: java.util.NoSuchElementException
at java.base/java.util.WeakHashMap$HashIterator.nextEntry(WeakHashMap.java:811)
at java.base/java.util.WeakHashMap$EntryIterator.next(WeakHashMap.java:848)
at java.base/java.util.WeakHashMap$EntryIterator.next(WeakHashMap.java:846)
at org.enso.interpreter.runtime.ThreadExecutors.shutdown(ThreadExecutors.java:46)
at org.enso.interpreter.runtime.EnsoContext.shutdown(EnsoContext.java:198)
at org.enso.interpreter.EnsoLanguage.finalizeContext(EnsoLanguage.java:179)
at org.enso.interpreter.EnsoLanguage.finalizeContext(EnsoLanguage.java:65)
at org.graalvm.truffle/com.oracle.truffle.api.LanguageAccessor$LanguageImpl.finalizeContext(LanguageAccessor.java:326)
at org.graalvm.truffle/com.oracle.truffle.polyglot.PolyglotLanguageContext.finalizeContext(PolyglotLanguageContext.java:404)
at org.graalvm.truffle/com.oracle.truffle.polyglot.PolyglotContextImpl.finalizeContext(PolyglotContextImpl.java:2925)
```
There was an inherent race condition between edit, close & open commands which could not be prevented solely using locks. `EditFileCmd` triggered `EnsureCompiledJob` which was applying edits collected over time. At the same `CloseFileCmd` and `OpenFileCmd` were executed asynchronously and required locks on compilation unit and file lock.
Additionally, open file was resetting the module's runtime source irrespective of any edits that could already have been applied with the asynchronous execution in `EnsureCompiledJob`. This was visible especially during early manipulation of the project when open/close was performed due to a bug in IDE (#6843).
Now commands can be run either synchronously or asynchronously. Only that way can we ensure that `close` & `open` commands finish by the time any editions are being applied to module's sources.
Closes#6841.
# Important Notes
In the given video, `"foo"` would be greyed out because it would never be part of the module's (runtime) sources. Therefore no IR would be generated for it or instrumentation, meaning it would be present in `expressionUpdates` information necessary for IDE.
[Kazam_screencast_00014.webm](https://github.com/enso-org/enso/assets/292128/226a17b8-729a-415a-803f-003a9695b2f1)
close#6900
This is a follow-up to the discussion of the imports/exports meeting.
Right now we have no control over the visibility of atom constructor arguments. One way to hide them is a convention of filtering getters by an `internal` prefix or suffix.
Related to #6912
It essentially solves it by removing any builtins that would take an EnsoDate/EnsoTimeOfDay/EnsoTimeZone and replacing them with Java utils that do the same operation.
This is not a proper solution - the builtin conversion is still invalid for the date/time types - but at this moment we may just no longer use the invalid conversion so it is much less of an issue. We still need to be aware of this if we want to introduce builtins taking date/time in the future.
At the beginning of the execution `EnsureCompiledJob` acquired write compilation lock. When compiling individual modules it would then
- acquire file lock
- acquire read compilation lock
The second one was spurious since it already kept the write lock. This sequence meant however that `CloseFileCmd` or `OpenFileCmd` can lead to a deadlock when requests come in close succession. This is because commands:
- acquire file lock
- acquire read compilation lock
So `EnsureCompiledJob` might have the (write) compilation lock but the commands could have file lock. And the second required lock for either the job or the command could never be acquired.
Flipping the order did the trick.
Partially solves #6841.
# Important Notes
For some reason we don't get updates for the newly added node, as illustrated in the screenshot, but that could be related to the close/open action. Will need to dig more.

Previously, a `RuntimeException` would be thrown when an attempt would be made to curry a conversion function. That is problematic for IDE where `executionFailed` means we can't enter functions due to lack of method pointers info.
Closes#6897.

# Important Notes
A more generic solution that allows to recover from execution failures will need a follow up.
close#6800
Update the `executionContext/expressionUpdates` notification and send the list of not applied arguments in addition to the method pointer.
# Important Notes
IDE is updated to support the new API.
Throwing `TailCallException` meant that exceptions that were extracted from the expression before the call was made could not be appended. This change catches the `TailCallException`, adds warnings to it and propagates it further, thus ensuring that we don't loose the information.
Closes#6765.
# Important Notes
Removed workarounds introduced in stdlib.
Add diagnosis for unresolved symbols in `from ... import sym1, sym2, ...` statements.
- Adds a new compiler pass, `ImportSymbolAnalysis`, that checks these statements and iterates through the symbols and checks if all the symbols can be resolved.
- Works with `BindingsMap` metadata.
- Add `ImportExportTest` that creates various modules with various imports/exports and checks their generated `BindingMap`.
---------
Co-authored-by: mergify[bot] <37929162+mergify[bot]@users.noreply.github.com>
Co-authored-by: Jaroslav Tulach <jaroslav.tulach@enso.org>
The change adds an additional field to `ExpressionUpdates` messages sent by `ProgramExecutionSupport` to indicate if the type of value (or its method pointer) has changed and therefore would potentially require a suggestions' update.
Prior to #3729 that check was done during the instrumentation. However we still want to continue to support "pending expression" functionality therefore `SuggestionsHandler` will use the additional information to filter only the required expression updates.
Most of the changes are related to adapting our tests to the new field.
Closes#6706.
# Important Notes
The associated project now loads and navigates smoothly.
Also attaching a screenshot from the project that illustrates that pending functionality continues to work:
[Kazam_screencast_00006.webm](https://github.com/enso-org/enso/assets/292128/35918841-f84f-4e1c-b1b0-40e45d97e111)
close#6611
Changelog:
- update: run compiler passes on the `ascribedType` field of the constructor arguments
- update: suggestion builder uses the type information attached to `ascribedType`
- feat: resolve qualified names in type signatures
Related to #6410
# Important Notes
- Updated some `Meta` methods (needed for error handling):
- `Meta.Type` now has `name` and `qualified_name`.
- `Meta.Constructor` has `declaring_type` allowing to get the type that this constructor is associated with.
Fixes#6609 by
- e380e647af - running whole `Vector_Spec` on `java.util.ArrayList`
- 9b1229fe20 - introducing a node to handle interop values
# Important Notes
Contains additional DSL processor fix:
- 415623dcb9 - to not crash the compiler, but to properly report compiler error
Artifically limiting the number of reported warnings to 100. Also added benchmarks with random Ints to investigate perf issues when dealing with warnings (future task).
Ideally we would have a custom set-like collection that allows us internally to specify a maximal number of elements. But `EnsoHashMap` (and potentially `EnsoSet`) are still WIP when it comes to being PE-friendly.
The change also allows for checking if the limit for the number of reported warnings has been reached. It will visualize by adding an additional "Warnings limit reached." to the visualization.
The limit is configurable via `--warnings-limit` parameter to `run`.
Closes#6283.
Add format to the in-memory Column
# Important Notes
Also updates .format in date types.
Some rearrangement of date formatting builtins / Java libraries.
Engine Benchmark job runs only engine benchmarks, not Enso benchmarks.
Enso benchmarks do not report their output anywhere, and take more than 5 hours to run nowadays.
We might define a new job in the future and probably rename it to "Library benchmarks".
But that is the responsibility of the lib team.
Deeply nested modules (of depth at least 3) would have the incorrect name inferred for synthetic modules. This also became apparent in a much bigger rewrite.
Instead of having module `A.B.C`, as described in the test, it would infer the name to be `B.A.C`, which would break when trying to reference symbols from `C`.
# Important Notes
No ticket reference, as this was something that @radeusgd discovered while working on another component.
The PR includes a minimal example that would previously fail to compile.
Remove the magical code generation of `enso_project` method from codegen phase and reimplement it as a proper builtin method.
The old behavior of `enso_project` was special, and violated the language semantics (regarding the `self` argument):
- It was implicitly declared in every module, so it could be called without a self argument.
- It can be called with explicit module as self argument, e.g. `Base.enso_project`, or `Visualizations.enso_project`.
Let's avoid implicit methods on modules and let's be explicit. Let's reimplement the `enso_project` as a builtin method. To comply with the language semantics, we will have to change the signature a bit:
- `enso_project` is a static method in the `Standard.Base.Meta.Enso_Project` module.
- It takes an optional `project` argument (instead of taking it as an explicit self argument).
Having the `enso_project` defined as a (shadowed) builtin method, we will automatically have suggestions created for it.
# Important Notes
- Truffle nodes are no longer generated in codegen phase for the `enso_project` method. It is a standard builtin now.
- The minimal import to use `enso_project` is now `from Standard.Base.Meta.Enso_Project import enso_project`.
- Tested implicitly by `org.enso.compiler.ExecCompilerTest#testInvalidEnsoProjectRef`.
close#6324
Changelog
- feat: DataflowAnalysis compiler pass preserves the order of dependencies. This way when attaching the visualization to the sub-expression, the engine can find the first cached parent node, and properly invalidate it.
- update: runtime visualization test is updated to reproduce the issue
# Important Notes
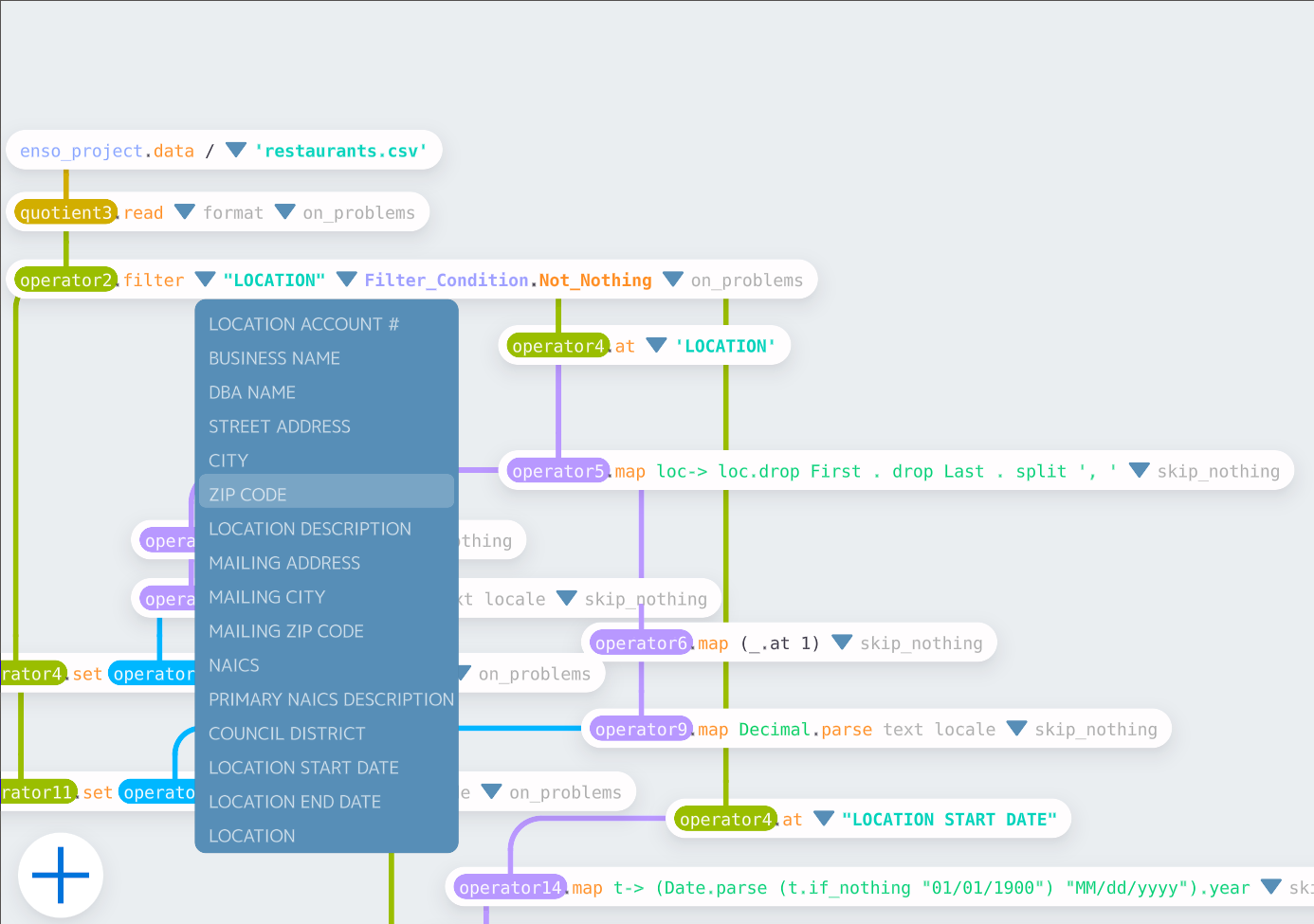
The dropdown for the column `"LOCATION"` is available right after the Restaurants project startup.
Dead Letter logging is occasionally flooding our logs which is confusing to users reporting bugs. Left the possibility of a single report so that we know that something is happening.
There is 572 threads during `RuntimeServerTest` execution create. They stay around because the context isn't closed after each test finishes. Adding `afterEach` cleanup sequence to `runtime-with-instruments` tests. Improving robustness of overall `EnsoContext` [shutdown](https://github.com/enso-org/enso/pull/6468#discussion_r1180348303).
- Adjusted `Context.is_enabled` to support default argument (moved built in so can have defaults).
- Made `environment` case-insensitive.
- Bug fix for play button.
- Short hand to execute within an enabled context.
- Forbid file writing if the Output context is disabled with a `Forbidden_Operation` error.
- Add temporary file support via `File.create_temporary_file` which is deleted on exit of JVM.
- Execution Context first pass in `Text.write`.
- Added dry run warning.
- Writes to a temporary file if disabled.
- Created a `DryRunFileManager` which will create and manage the temporary files.
- Added `format` dropdown to `File.read` and `Data.read`.
- Renamed `JSON_File` to `JSON_Format` to be consistent.
(still to unit test).
Fixes#6416 by introducing `InlineableNode`. It runs fast even on GraalVM CE, fixes ([forever broken](https://github.com/enso-org/enso/pull/6442#discussion_r1178782635)) `Debug.eval` with `<|` and [removes discouraged subclassing](https://github.com/enso-org/enso/pull/6442#discussion_r1178778968) of `DirectCallNode`. Introduces `@BuiltinMethod.needsFrame` - something that was requested by #6293. Just in this PR the attribute is optional - its implicit value continues to be derived from `VirtualFrame` presence/absence in the builtin method argument list. A lot of methods had to be modified to pass the `VirtualFrame` parameter along to propagate it where needed.
During initialization JGit may attempt to resolve hostname. On some systems this can take more than desired triggering timeouts. This change does two things:
- sets the default committer for changes, lack of which probably triggered the check
- sets the default hostname to `localhost` (we don't care), in case something else in JGit still wants to resolve hostname
Closes#6447.
# Important Notes
I wasn't able to reproduce this so relying on @mwu-tow since apparently he can repro it reliably.
This change modifies method dispatch for methods that override Any's definitions. When an overrided method is invoked statically we call Any's method to stay consistent.
This change primarily addresses the plethora of problems related to `to_text` invocations. It does not attempt to completely modify method dispatch logic.
Closes#6300.
Fixes the runtime test
```
- should recompute expressions changing an execution environment *** FAILED ***
"[live]" did not equal "[design]" (RuntimeServerTest.scala:2721)
Analysis:
"[live]" -> "[design]"
```
- Missing tests from number parsing.
- Fix type signature on some warning methods.
- Fix warnings on `Standard.Database.Data.Table.parse_values`.
- Added test for `Nothing` and empty string on `use_first_row_as_names`.
- New API for `Number.format` taking a simple format string and `Locale`.
- Add ellipsis to truncated `Text.to_display_text`.
- Adjusted built-in `to_display_text` for numbers to not include type (but also to display BigInteger as value).
- Remove `Noise.Generator` interface type.
- Json: Added `to_display_text` to `JS_Object`.
- Time: Added `to_display_text` for `Date`, `Time_Of_Day`, `Date_Time`, `Duration` and `Period`.
- Text: Added `to_display_text` to `Locale`, `Case_Sensitivity`, `Encoding`, `Text_Sub_Range`, `Span`, `Utf_16_Span`.
- System: Added `to_display_text` to `File`, `File_Permissions`, `Process_Result` and `Exit_Code`.
- Network: Added `to_display_text` to `URI`, `HTTP_Status_Code` and `Header`.
- Added `to_display_text` to `Maybe`, `Regression`, `Pair`, `Range`, `Filter_Condition`.
- Added support for `to_js_object` and `to_display_text` to `Random_Number_Generator`.
- Verified all error types have `to_display_text`.
- Removed `BigInt`, `Date`, `Date_Time` and `Time_Of_Day` JS based rendering as using `to_display_text` now.
- Added support for rendering nested structures in the table viz.
related #6323
The engine can skip compilation when applying changes that do not require execution. It is more efficient to process the changes in a batch, than triggering compilations every time such edit is received.
While Enso runs single-threaded, its `ResourceManager` required additional asynchronous thread to execute its _"finalizers"_. What has been necessary back then is no longer needed since _GraalVM 21.1_. GraalVM now provides support for submitting `ThreadLocalAction` that gets then picked and executed via `TruffleSafepoint` locations. This PR uses such mechanism to _"inject"_ finalizer execution into already running Enso evaluation thread.
Requiring more than one thread has complicated Enso's co-existence with other Truffle language. For example Graal.js is strictly singlethreaded and used to refuse (simple) co-existence with Enso. By allowing Enso to perform all its actions in a single thread, the synergy with Graal.js becomes better.
`Number.nan` can be used as a key in `Map`. This PR basically implements the support for [JavaScript's Same Value Zero Equality](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Equality_comparisons_and_sameness#same-value-zero_equality) so that `Number.nan` can be used as a key in `Map`.
# Important Notes
- For NaN, it holds that `Meta.is_same_object Number.nan Number.nan`, and `Number.nan != Number.nan` - inspired by JS spec.
- `Meta.is_same_object x y` implies `Any.== x y`, except for `Number.nan`.
`Vector.sort` does some custom method dispatch logic which always expected a function as `by` and `on` arguments. At the same time, `UnresolvedSymbol` is treated like a (to be resolved) `Function` and under normal circumstances there would be no difference between `_.foo` and `.foo` provided as arguments.
Rather than adding an additional phase that does some form of eta-expansion, to accomodate for this custom dispatch, this change only fixes the problem locally. We accept `Function` and `UnresolvedSymbol` and perform the resolution on the fly. Ideally, we would have a specialization on the latter but again, it would be dependent on the contents of the `Vector` so unclear if that is better.
Closes#6276,
# Important Notes
There was a suggestion to somehow modify our codegen to accomodate for this scenario but I went against it. In fact a lot of name literals have `isMethod` flag and that information is used in the passes but it should not control how (late) codegen is done. If we were to make this more generic, I would suggest maybe to add separate eta-expansion pass. But it could affect other things and could be potentially a significant change with limited potential initially, so potential future work item.
https://github.com/orgs/enso-org/discussions/6344 requested to change the order of arguments when controlling context permissions.
# Important Notes
The change brings it closer to the design doc but IMHO also a bit cumbersome to use (see changed tests) - applications involving default arguments don't play well when the last argument is not the default 🤷 .`
close#6306
Changelog:
- add: `AsyncResourceInitialization` component
- update: initialize language server resources asynchronously
# Important Notes
Speeds up `session/InitProtocolConnection` request by ~300ms (~10%) 3051ms (before) vs 2740ms (after) on my machine.
* Update type ascriptions in some operators in Any
* Add @GenerateUncached to AnyToTextNode.
Will be used in another node with @GenerateUncached.
* Add tests for "sort handles incomparable types"
* Vector.sort handles incomparable types
* Implement sort handling for different comparators
* Comparison operators in Any do not throw Type_Error
* Fix some issues in Ordering_Spec
* Remove the remaining comparison operator overrides for numbers.
* Consolidate all sorting functionality into a single builtin node.
* Fix warnings attachment in sort
* PrimitiveValuesComparator handles other types than primitives
* Fix byFunc calling
* on function can be called from the builtin
* Fix build of native image
* Update changelog
* Add VectorSortTest
* Builtin method should not throw DataflowError.
If yes, the message is discarded (a bug?)
* TypeOfNode may not return only Type
* UnresolvedSymbol is not supported as `on` argument to Vector.sort_builtin
* Fix docs
* Fix bigint spec in LessThanNode
* Small fixes
* Small fixes
* Nothings and Nans are sorted at the end of default comparator group.
But not at the whole end of the resulting vector.
* Fix checking of `by` parameter - now accepts functions with default arguments.
* Fix changelog formatting
* Fix imports in DebuggingEnsoTest
* Remove Array.sort_builtin
* Add comparison operators to micro-distribution
* Remove Array.sort_builtin
* Replace Incomparable_Values by Type_Error in some tests
* Add on_incomparable argument to Vector.sort_builtin
* Fix after merge - Array.sort delegates to Vector.sort
* Add more tests for problem_behavior on Vector.sort
* SortVectorNode throws only Incomparable_Values.
* Delete Collections helper class
* Add test for expected failure for custom incomparable values
* Cosmetics.
* Fix test expecting different comparators warning
* isNothing is checked via interop
* Remove TruffleLogger from SortVectorNode
* Small review refactorings
* Revert "Remove the remaining comparison operator overrides for numbers."
This reverts commit 0df66b1080.
* Improve bench_download.py tool's `--compare` functionality.
- Output table is sorted by benchmark labels.
- Do not fail when there are different benchmark labels in both runs.
* Wrap potential interop values with `HostValueToEnsoNode`
* Use alter function in Vector_Spec
* Update docs
* Invalid comparison throws Incomparable_Values rather than Type_Error
* Number comparison builtin methods return Nothing in case of incomparables
The primary motivation for this change was
https://github.com/enso-org/enso/issues/6248, which requested the possibility of defining `to_display_text` methods of common errors via regular method definitions. Until now one could only define them via builtins.
To be able to support that, polyglot invocation had to report `to_display_text` in the list of (invokable) members, which it didn't. Until now, it only considered fields of constructors and builtin methods. That is now fixed as indicated by the change in `Atom`.
Closes#6248.
# Important Notes
Once most of builtins have been translated to regular Enso code, it became apparent how the usage of `.` at the end of the message is not consistent and inflexible. The pure message should never follow with a dot or it makes it impossible to pretty print consistently for the purpose of error reporting. Otherwise we regularly end up with errors ending with `..` or worse. So I went medieval on the reasons for failures and removed all the dots.
The overall result is mostly the same except now we are much more consistent.
Finally, there was a bit of a good reason for using builtins as it simplified our testing.
Take for example `No_Such_Method.Error`. If we do not import `Errors.Common` module we only rely on builtin error types. The type obviously has the constructor but it **does not have** `to_display_text` in scope; the latter is no longer a builtin method but a regular method. This is not really a problem for users who will always import stdlib but our tests often don't. Hence the number of changes and sometimes lack of human-readable errors there.
close#6232
Changelog:
- remove: `SqlVersionsRepo`
- update: `SuggestionsDatabaseModuleUpdateNotification` message removing the version
- update: cleanup versions repo usages in the language server
As per design, IOContexts controlled via type signatures are going away. They are replaced by explicit `Context.if_enabled` runtime checks that will be added to particular method implementations.
`production`/`development` `IOPermissions` are replaced with `live` and `design` execution enviornment. Currently, the `live` env has a hardcoded list of allowed contexts i.e. `Input` and `Output`.
# Important Notes
As per design PR-55. Closes#6129. Closes#6131.
close#6080
Changelog
- add: implement `SuggestionsRepo.insertAll` as a batch SQL insert
- update: `search/getSuggestionsDatabase` returns empty suggestions. Currently, the method is only used at startup and returns the empty response anyway because the libs are not loaded at that point.
- update: serialize only global (defined in the module scope) suggestions during the distribution building. There's no sense in storing the local library suggestions.
- update: sqlite dependency
- remove: unused methods from `SuggestionsRepo`
- remove: Arguments table
# Important Notes
Speeds up libraries loading by ~1 second.


Implements #6134.
# Important Notes
One can define lazy atom fields as:
```haskell
type Lazy
Value ~x ~y
```
the evaluation of the `x` and `y` fields is then delayed until they are needed. The evaluation happens once. Then the computed value is kept in the atom for further use.
Fixes#5898 by removing `Catch.panic` and speeding the `sieve.enso` benchmark from 1058 ms to 514 ms. Should there be no dedicated conversion, let's use one defined on `Any` type - e.g. defining a conversion `from(Any)` makes such a conversion is always available.
Delay creation of `EnsoFile` until it is needed.
# Important Notes
By putting breakpoint into `Atom` constructor I realized few `EnsoProjectNode` instances may be created when parsing the project. It makes no sense to also create `EnsoFile` for them - until it is needed.
Modification to various tests disabled when #5917 was integrated to pass with new parser. Fixes#5894.
# Important Notes
Some tests can be fixed just by changes on the `IR` side. Some (especially error simulating ones) would benefit from changes in the `Tree` structure or at least @kazcw evaluation.
close#6139close#6137
When the project is renamed, the engine cleans up affected modules and initiates modules re-indexing to fill the suggestions database with new records. This way it reduces the amount of information stored in the suggestions database and helps implement #6080 optimization.
Changelog:
- remove: rename features from the suggestions database
- update: rename command to initiate modules cleanup and project re-execution
- fix: #6137
`--compile` command would run the compilation pipeline but silently omit any encountered errors, thus skipping the serialization. This maybe was a good idea in the past but it was problematic now that we generate indexes on build time.
This resulted in rather obscure errors (#6092) for modules that were missing their caches.
The change should significantly improve developers' experience when working on stdlib.
# Important Notes
Making compilation more resilient to sudden cache misses is a separate item to be worked on.
Avoid displaying just `Execution finished with an error: java.lang.NullPointerException` without any additional detail.
# Important Notes
When there is an execution error outside of Enso code (identified by the fact that all stack frames belong to `java` language), let's print the whole stack rather than printing nothing. To simulate one can:
```diff
diff --git engine/runtime/src/main/scala/org/enso/compiler/Compiler.scala engine/runtime/src/main/scala/org/enso/compiler/Compiler.scala
index ff0636bc66..42e5eae32e 100644
--- engine/runtime/src/main/scala/org/enso/compiler/Compiler.scala
+++ engine/runtime/src/main/scala/org/enso/compiler/Compiler.scala
@@ -453,7 +453,8 @@ class Compiler(
pool
)
} else {
- CompletableFuture.completedFuture(ensureParsedAndAnalyzed(module))
+ // CompletableFuture.completedFuture(ensureParsedAndAnalyzed(module))
+ CompletableFuture.completedFuture(())
}
}
```
It is sometimes impossible to figure out the real reason for invalid text edit request. Added a bit of context to failures to narrow down the cause of the failure.
# Important Notes
Should help with diagnosing issues like #6099.
The primary delivery of this PR is a design of `SerdeCompilerTest` - a testing suite that allows us to write sample projects, parse them with and without caches and verify they still produce the same `IR`. This is a similar idea to #3723 which compared the old and new parser `IR`s.
With infrastructure like this we can start addressing #5567 without any (significant) fear of breaking something essential.
Treat `Boolean.False` and `Boolean.True` as the corresponding primitives. Now, `Boolean.False == False` returns true.
# Important Notes
`False` and `True` constructs, that are converted to `ConstructorNode` during Truffle codegen, are handled specially in `ConstructorNode`. The easiest fix was to implement a similar special handling in `QualifiedAccessorNode`, although not the cleanest one.
A better solution would be to provide transformation of `Boolean.True` IR to a true literal in `ApplicationSaturation` compiler pass. But `ApplicationSaturation` pass does not handle `True`. Moreover, for our case, it is unnecessarily complicated.
Instrumentation of calls involving warning values never really worked because:
1) newly created nodes didn't set the UUID of their children
2) the instrumentable wrappers always had an empty (i.e. null) UUID and
they never referred `get`/`setId` calls to their delegates
On the surface, everything worked fine. Except when one actually relied on the instrumentation of values with warnings for proper setup. Then no instrumentation (replacement of nodes) was performed due to empty UUID (as required by `hasTag` of `FunctionCallInstrumentationNode`).
Closes#6045. Discovered in #5893.
close#5874
Changelog:
- add: `isStatic` parameter to `search/completion` request to search by the `static` suggestion attribute
- update: search non-static suggestions when opening component browser
# Important Notes
Component browser doesn't show `Table.new` and `Table.from_rows` suggestions when a `Table` node is selected.
- Fixes InvokeCallableNode to support warnings.
- Strips warnings from annotations in `get_widget_json`.
- Remove `get_full_annotations_json`.
- Fix warnings on Dialect.
Exporting types named the same as the module where they are defined in `Main` modules of library components may lead to accidental name conflicts. This became apparent when trying to access `Problem_Behavior` module via a fully qualified name and the compiler rejected it. This is due to the fact that `Main` module exported `Error` type defined in `Standard.Base.Error` module, thus making it impossible to access any other submodules of `Standard.Base.Error` via a fully qualified name.
This change adds a warning to FullyQualifiedNames pass that detects any such future problems.
While only `Error` module was affected, it was widely used in the stdlib, hence the number of changes.
Closes#5902.
# Important Notes
I left out the potential conflict in micro-distribution, thus ensuring we actually detect and report the warning.
close#5881
Changelog
- add: ProtocolFactory object that initializes and returns the protocol object
- update: Add protocol initialization to the initialization component
close#5911
In interactive mode, perform writing IR caches in the background jobs queue. Background jobs execution is delayed until the first execution is complete.
Fixing #5768 and #5765 and co. Introducing `Meta.Type` and giving it the desired methods.
# Important Notes
`Type` is no longer a `Meta.Atom`, but it has a dedicated `Meta.Type` representation.
Fixes#5826.
# Important Notes
- Change frontend representation of negation.
- Fix a precedence issue: The `.` operators in -1.x and -1.2 must have different precedences.
- Remove a no-longer-needed special case from backend translation.
- Add tests for this case after all translations.
Give Cache subclasses a chance to control the output stream format. Use that functionality to avoid persisting `UUID` into standard library `.ir` caches. Gets the number of caches down to 42MB from 48MB.
# Important Notes
I believe UUIDs are not really useful for standard libraries and can be omitted. Am I right?
The `logAvailableComponentsForDebugging` will check and install all necessary components of GraalVM for every mentioned version. While not harmful, it adds up to startup time.
Additionally added an option in language server startup to skip installation of GraalVM components. The latter is already performed by project-manager when opening the project and it is unnecessary to do it twice. Due to LS' architecture this configuration has to be passed around via multiple configs.
Finally, skipped the attempt to install Python component on Windows - this is not supported by GraalVM atm.
Closes#5749.
# Important Notes
The impact of this problem could be really felt the more versions of Enso and GraalVM one had since it would go through all of them.
Implement new Enso documentation parser; remove old Scala Enso parser.
Performance: Total time parsing documentation is now ~2ms.
# Important Notes
- Doc parsing is now done only in the frontend.
- Some engine tests had never been switched to the new parser. We should investigate tests that don't pass after the switch: #5894.
- The option to run the old searcher has been removed, as it is obsolete and was already broken before this (see #5909).
- Some interfaces used only by the old searcher have been removed.
When generating import/export bindings in local cache, they are included in the distribution.
Additionally, removed the hardcoded value for suggestions cache. Now one can generate them for local as well as for global cache, based on the presence or lack of `--no-global-cache` parameter.
Closes#5890.
close#5889
Changelog:
- update: make `DetachVisualizationJob` a unique job to make sure that they are not canceled during the re-compilation after `text/applyEdit` command.
close#5892
Changelog:
add: feature to delay background jobs execution
add: start background jobs when program finishes
add: start background jobs on `search/completion` request
Fixes#5805 by returning `[]` as list of fields of `Type`.
# Important Notes
`Type` is recognized as `Meta.is_atom` since #3671. However `Type` isn't an `Atom` internally. We have to provide special handling for it where needed.
Adds a common project that allows sharing code between the `runtime` and `std-bits`.
Due to classpath separation and the way it is compiled, the classes will be duplicated - we will have one copy for the `runtime` classpath and another copy as a small JAR for `Standard.Base` library.
This is still much better than having the code duplicated - now at least we have a single source of truth for the shared implementations.
Due to the copying we should not expand this project too much, but I encourage to put here any methods that would otherwise require us to copy the code itself.
This may be a good place to put parts of the hashing logic to then allow sharing the logic between the `runtime` and the `MultiValueKey` in the `Table` library (cc: @Akirathan).
close#5070
Changelog:
- Include the original exception to log expressions
- Enable logging of Akka Actors' lifecycle events on debug logging level
- Decrease the severity of interruption log messages because interruptions are part of the workflow. The computation can be interrupted at any time, and still be recomputed after. Warnings are just misleading in this case.
Merge _ordered_ and _unordered_ comparators into a single one.
# Important Notes
Comparator is now required to have only `compare` method:
```
type Comparator
comapre : T -> T -> (Ordering|Nothing)
hash : T -> Integer
```
Removing special handling of `AtomConstructor` in `Meta.is_a` check.
# Important Notes
A lot of tests are about to fail. Many of them indirectly call `Meta.is_a` with a constructor rather than type.
This change downgrades hashing algorithm used in caching IR and library bindings to SHA-1. It is sufficient and significantly faster for the purpose of simple checksum we use it for.
Additionally, don't calculate the digest for serialized bytes - if we get the expected object type then we are confident about the integrity.
Don't initialize Jackson's ObjectMapper for every metadata serialization/de-serialization. Initialization is very costly.
Avoid unnecessary conversions between Scala and Java. Those back-and-forth `asScala` and `asJava` are pretty expensive.
Finally fix an SBT warning when generating library cache.
Closes https://github.com/enso-org/enso/issues/5763
# Important Notes
The change cuts roughly 0.8-1s from the overall startup.
This change will certainly lead to invalidation of existing caches. It is advised to simply start with a clean slate.
- Fix issue with Geo Map viz.
- Handle invalid format strings better in `Data_Formatter`.
- New constants for the ISO format strings (and a special ENSO_ZONED_DATE_TIME)
- Consistent Date Time format for parsing in all places.
- Avoid throwing exception in datetime parsing.
- Support for milliseconds (well nanoseconds) in Date_Time and Time_Of_Day.
- `Column.map` stays within Enso.
- Allow `Aggregate_Column.Group_By` in `cross_tab` group_by parameter.
Coerce values obtained from polyglot calls to fix#5177.
# Important Notes
Adds `IntHolder` class into the `test/Tests` project to simulate access to a class with integer field.
Closes#5113
Fixes a bug where read-only files would be overwritten if File.write was used in backup mode, and added tests to avoid such regression. To implement it, introduced a `is_writable` property on `File`.
This change adds serialization and deserialization of library bindings.
In order to be functional, one needs to first generate IR and
serialize bindings using `--compiled <path-to-library>` command. The bindings
will be stored under the library with `.bindings` suffix.
Bindings are being generated during `buildEngineDistribution` task, thus not
requiring any extra steps.
When resolving import/exports the compiler will first try to load
module's bindings from cache. If successful, it will not schedule its
imports/exports for immediate compilation, as we always did, but use the
bindings info to infer the dependent modules.
The current change does not make any optimizations when it comes to
compiling the modules, yet. It only delays the actual
compilation/loading IR from cache so that it can be done in bulk.
Further optimizations will come from this opportunity such as parallel
loading of caches or lazily inferring only the necessary modules.
Part of https://github.com/enso-org/enso/issues/5568 work.
Resolving #5055 - avoid putting single constructor into suggestion database.
# Important Notes
Another way to fix#5055 is to keep the single constructor information in the suggestion database and let the IDE filter that out.
- Handle `WithWarnings` in `IndirectInvokeCallableNode`.
- Handle no RootNode in `ErrorResolver`.
- Allow table vizualisation to cope if no `data` passed.
- Add `Warning.has_warnings` to check if warnings present.
- Adjust `set_value` for `JS_Object` so creates a new object each time.
Put `Nothing` into an empty array rather than `null`. When running with `assert` on (unit tests), check the content of the array and `AssertError` quickly when a `null` is found.
Critical performance improvements after #4067
# Important Notes
- Replace if-then-else expressions in `Any.==` with case expressions.
- Fix caching in `EqualsNode`.
- This includes fixing specializations, along with fallback guard.
Creating two `findExceptionMessage` methods in `HostEnsoUtils` and in `VisualizationResult`. Why two? Because one of them is using `org.graalvm.polyglot` SDK as it runs in _"normal Java"_ mode. The other one is using Truffle API as it is running inside of partially evaluated instrument.
There is a `FindExceptionMessageTest` to guarantee consistency between the two methods. It simulates some exceptions in Enso code and checks that both methods extract the same _"message"_ from the exception. The tests verifies hosted and well as Enso exceptions - however testing other polyglot languages is only possible in other modules - as such I created `PolyglotFindExceptionMessageTest` - but that one doesn't have access to Truffle API - e.g. it doesn't really check the consistency - just that a reasonable message is extracted from a JavaScript exception.
# Important Notes
This is not full fix of #5260 - something needs to be done on the IDE side, as the IDE seems to ignore the delivered JSON message - even if it contains properly extracted exception message.
Implements the #5643 idea. As soon as `MainModule` creates `Context` for GraalVM execution, it schedules a background task to initialize JavaScript. The initialization finishes sooner than Enso compiler is ready to work, saving time when it is actually needed.
# Important Notes
Only modifies boot sequence of `MainModule` (used in the IDE) and `VerifyJavaScriptIsAvailableTest` (to verify the _"context passing logic"_ works OK between threads). Regular CLI execution remains unchanged for now assuming batch execution may not need JavaScript in all the cases and if it does the initialization speed isn't that critical.
When the `project.yaml` specifies an unknown edition, the project is started with the fallback edition (current engine version). It works this way:
- IDE sends project/open request to project manager (specifying only which project to open)
- project manager resolves the project edition (based on `project.yaml`) or selects the fallback if the requested edition cannot be loaded
- project manager starts the language server specifying the edition with the `--server-edition` command line parameter
- language server specifies the correct edition when creates the runtime context
Serialization of FQNs' metadata was broken - we attempted to serialiaze concrete modules and that's against the design.
Added a test illustrating the problem which would previously fail during serialization.
Closes#5037
# Important Notes
It is still hard to discover problems like this because SerializationManager creates system threads; when the exception occurs, it is typically not the real cause. Creating regular threads via `createThread` seems to be problematic for `native-image`. There is a simple workaround for the former but will leave it out for another PR to simplify the review.
Add `Comparator` type class emulation for all types. Migrate all the types in stdlib to this new `Comparator` API. The main documentation is in `Ordering.enso`.
Fixes these pivotals:
- https://www.pivotaltracker.com/story/show/183945328
- https://www.pivotaltracker.com/story/show/183958734
- https://www.pivotaltracker.com/story/show/184380208
# Important Notes
- The new Comparator API forces users to specify both `equals` and `hash` methods on their custom comparators.
- All the `compare_to` overrides were replaced by definition of a custom _ordered_ comparator.
- All the call sites of `x.compare_to y` method were replaced with `Ordering.compare x y`.
- `Ordering.compare` is essentially a shortcut for `Comparable.from x . compare x y`.
- The default comparator for `Any` is `Default_Unordered_Comparator`, which just forwards to the builtin `EqualsNode` and `HashCodeNode` nodes.
- For `x`, one can get its hash with `Comparable.from x . hash x`.
- This makes `hash` as _hidden_ as possible. There are no other public methods to get a hash code of an object.
- Comparing `x` and `y` can be done either by `Ordering.compare x y` or `Comparable.from x . compare x y` instead of `x.compare_to y`.
An exception encountered during serialization prevents engine from continuing because it enters an infinite loop(!).
# Important Notes
The aim of this PR is to make it possible for engine to recover from the serialization failures. Any failure would mean that we enter an infinite loop in deserialization which is in turn waiting for the serialization to finish (which will never happen).
In this particular case FQNs are [referencing concrete modules](https://github.com/enso-org/enso/issues/5037). A separate PR will address that.
Expressions returning polyglot values were not reporting the type of the result because we have to do additional magic that infers the correct Enso type. Since this is exactly what `TypeOfNode` does, I re-used the logic.
Straightforward solution failed in tests because of assertions:
```
[enso] WARNING: Execution of function main failed (Invalid library usage. Cached library must be adopted by a RootNode before it is executed.).
java.lang.AssertionError: Invalid library usage. Cached library must be adopted by a RootNode before it is executed.
```
That is why this PR replaces `ExecutionEventListener` with `ExecutionEventNodeFactory`.
# Important Notes
Usage of `TypeOfNode` for programs that **do not** import stdlib means that we report types that do not involve stdlib e.g.
`Standard.Builtins.Main.Integer` instead of `Standard.Base.Data.Numbers.Integer`. While surprising, this is correct and I would say desirable. While reviewing the code, notice the difference in expectations in our runtime tests.
- Fixes the display of Date, Time_Of_Day and Date_Time so doesn't wrap.
- Adjust serialization of large integer values for JS and display within table.
- Workaround for issue with using `.lines` in the Table (new bug filed).
- Disabled warning on no specified `separator` on `Concatenate`.
Does not include fix for aggregation on integer values outside of `long` range.
Closes#5036
Move the logic that looks up method pointers from the language server to IDE. This way we can keep the suggestion updates and expression updates async, otherwise it will hurt the initial startup time of LS.
Fixes the issue when some expression updates does not contain the method pointer.
Follow up on
16ba57d465 which marked the tests as flaky.
This test goes back to the original implementation where JGit did all its book-keeping synchronously. When we switched to asynchronous operation, cleaning up the test directory would sometimes not succeed because there would be a race-condition with the ongoing work of JGit.
# Important Notes
In the current setup tagging a test as flaky is only valid for Windows. The other platforms ignore the flag. So we were still getting random failures.
Closes#5038
- Use the proper widget structure.
- Provide new method `get_widget_json` with whole structure, but keep `get_full_annotations_json` in old form.
- Start to get to some reusable functions.
- Added widget to JS_Object field selections.
Start `project-manager` with following options to provide first 20s of the startup sequence:
```
$ project-manager --profiling-events-log-path=start.log --profiling-path=start.npss --profiling-time=20
```
once the `start.log` and `start.npss` files are generated (next to each other), open them in GraalVM's VisualVM:
```
$ graalvm/bin/jvisualvm --openfile start.npss
```
analyze.
Implementation of https://www.pivotaltracker.com/story/show/184012743https://user-images.githubusercontent.com/919491/214082311-cf49e43c-1d1f-4654-903c-a4224cd954d8.mp4
This is also a step towards more general widget support. The widget metadata is queried using `Meta.get_annotation` method through a dedicated visualization. For now only `Single_Choice` case is handled, and always all suggestions are is returned.
# Important Notes
There are limitations as to which node segments receive a widget. Only chain method calls are supported now (`thing.method` syntax), and only outside of lambda scope. Widgets in lambdas will require support for visualisations of lambda subexpressions, which is currently missing in the engine. The IDE technically tries to place the widgets there, but the data never arrives. It should work once the engine support is added.
This PR includes a mock for `Meta.get_annotation` call that only supports `Table.at` method. Real implementation is a separate task that is already in progress.
JGit ops generally run fast (as in a few milliseconds) except for the first commit. The initialization + first commit was taking at least 3.5 seconds constistenly, but only in the first test case. Now, this led to frequent timeouts down the chain when the request was expected to finish fast.
The bookkeeping involved some timestamping and other expensive calls in order to calculate clock drift. The default appears to be to run it in a blocking mode, hence adding at least 3 seconds to the first command call.
Setting the job to run in the background makes the cost of the repo initialization acceptable (~300 milliseconds on a cold JVM). The other commands are unaffected and take < 10 milliseconds.
# Important Notes
Added a test to ensure that we don't introduce the regression. Marked it as potentially flaky because it uses timestamps and it is therefore prone to random system hiccups.
There is no need for JGit to try to save file attributes to its config in `<home>/jgit/config`. This change ensures that JGit operates on a stub file, without polluting users' configs, similarly to user's git config.
Additionally, noticed that all FS operations during `init` are rather slow and saw at least on one occassion when the handler timed out because of that (https://www.pivotaltracker.com/story/show/184359934). This change provides an init-specific timeout for `vcs/init`.
# Important Notes
This change should reduce chances of failures during VCS initialization.
- New `set` function design - takes a `Column` and works with that more easily and supports control of `Set_Mode`.
- New simple `parse` API on `Column`.
- Separated expression support for `filter` to new `filter_by_expression` on `Table`.
- New `compute` function allowing creation of a column from an expression.
- Added case sensitivity argument to `Column` based on `starts_with`, `ends_with` and `contains`.
- Added case sensitivity argument to `Filter_Condition` for `Starts_With`, `Ends_With`, `Contains` and `Not_Contains`.
- Fixed the issue in JS Table visualisation where JavaScript date was incorrectly set.
- Some dynamic dropdown expressions - experimenting with ways to use them.
- Fixed issue with `.pretty` that wasn't escaping `\`.
- Changed default Postgres DB to `postgres`.
- Fixed SQLite support for starts_with, ends_with and contains to be consistent (using GLOB not LIKE).
When a large long would be passed to a host call expecting a double, it would crash with a
```
Cannot convert '<some long>'(language: Java, type: java.lang.Long) to Java type 'double': Invalid or lossy primitive coercion
```
That is unlikely to be expected by users. It also came up in the Statistics examples during Sum. One could workaround it by forcing the conversion manually with `.to_decimal` but it is not a permanent solution.
Instead this change adds a custom type mapping from Long to Double that will do it behind the scenes with no user interaction. The mapping kicks in only for really large longs.
# Important Notes
Note that the _safe_ range is hardcoded in Truffle and it is not accessible in enso packages. Therefore a simple c&p for that max safe long value was necessary.
In order to investigate `engine/language-server` project, I need to be able to open its sources in IGV and NetBeans.
# Important Notes
By adding same Java source (this time `package-info.java`) and compiling with our Frgaal compiler the necessary `.enso-sources*` files are generated for `engine/language-server` and then the `enso4igv` plugin can open them and properly understand their compile settings.

In addition to that this PR enhances the _"logical view"_ presentation of the project by including all source roots found under `src/*/*`.
https://github.com/enso-org/enso/pull/3764 introduced static wrappers for instance methods. Except it had a limitation to only be allowed for types with at least a single constructor.
That excluded builtin types as well which, by default, don't have them. This limitation is problematic for Array/Vector consolidation and makes builtin types somehow second-citizens.
This change lifts the limitation for builtin types only. Note that we do want to share the implementation of the generated builtin methods. At the same time due to the additional argument we have to adjust the starting index of the arguments.
This change avoids messing with the existing dispatch logic, to avoid unnecessary complexity.
As a result it is now possible to call builtin types' instance methods, statically:
```
arr = Array.new_1 42
Array.length arr
```
That would previously lead to missing method exception in runtime.
# Important Notes
The only exception is `Nothing`. Primarily because it requires `Nothing` to have a proper eigentype (`Nothing.type`) which would messed up a lot of existing logic for no obvious benefit (no more calling of `foo=Nothing` in parameters being one example).
For graying out the nodes, the engine need to send IDE a set of values that will be computed before executing the program (and the IDE colors them gray). In general, it is tricky to do because we cannot know for sure which exactly nodes will be computed without running the program. But we can estimate based on the invalidated values, which nodes are expected to be executed during the next run, and send them to the IDE. This logic is simpler than the previous approach, and turned out working pretty well in practice.
[Peek-gray-out.webm](https://user-images.githubusercontent.com/357683/215092755-0010e41d-a2cf-447a-900e-4619408effa0.webm)
In the event when the action of the underlying actor crashes really bad, the result of the future will be `Failure`. All such results will be then wrapped in `Status.Failure` via `pipeTo` (unlike `Success` which just forwards the response).
In some cases we don't handle `Status.Failure` messages, meaning we are rather left in the dark to the reason of the failure with a non-informative message `Received unknown message: class akka.actor.Status$Failure`.
I'm keeping this change small on purpose to keep this change self-contained. I think there are more cases but it needs careful investigation into how messages are being sent.
# Important Notes
This PR does not attempt to fix the underlying problem of the ticket, yet. We should however have a better overview where/why things go wrong.
Enso unit tests were running without `-ea` check enabled and as such various invariant checks in Truffle code were not executed. Let's turn the `-ea` flag on and fix all the code misbehaves.
LS needs to notify runtime that modules' sources need to be reloaded from FS, once its own buffer has been reloaded as well.
# Important Notes
Discovered during integration of https://github.com/enso-org/enso/pull/4050.
The test illustrates the problem if we don't reload module's sources - the sources essentially become stale even though they have changed.
When the function is visualized with the `default_preprocessor` method, it returns a dataflow error that shows up in the logs as
```
Cannot encode class org.enso.interpreter.runtime.error.DataflowError to byte array.
```
PR handles dataflow errors in the preprocessor and fallbacks the `to_display_text` value. As a bonus, we get a function visualization.
- add: `GeneralAnnotation` IR node for `@name expression` annotations
- update: compilation pipeline to process the annotation expressions
- update: rewrite `OverloadsResolution` compiler pass so that it keeps the order of module definitions
- add: `Meta.get_annotation` builtin function that returns the result of annotation expression
- misc: improvements (private methods, lazy arguments, build.sbt cleanup)
Introduces unboxed (and arity-specialized) storage schemes for Atoms. It results in improvements both in memory consumption and runtime.
Memory wise: instead of using an array, we now use object fields. We also enable unboxing. This cuts a good few pointers in an unboxed object. E.g. a quadruple of integers is now 64 bytes (4x8 bytes for long fields + 16 bytes for layout and constructor pointers + 16 bytes for a class header). It used to be 168 bytes (4x24 bytes for boxed Longs + 16 bytes for array header + 32 bytes for array contents + 8 bytes for constructor ptr + 16 bytes for class header), so we're saving 104 bytes a piece. In the least impressive scenarios (all-boxed fields) we're saving 8 bytes per object (saving 16 bytes for array header, using 8 bytes for the new layout field). In the most-benchmarked case (list of longs), we save 32 bytes per cons-cell.
Time wise:
All list-summing benchmarks observe a ~2x speedup. List generation benchmarks get ~25x speedups, probably both due to less GC activity and better allocation characteristics (only allocating one object per Cons, rather than Cons + Object[] for fields). The "map-reverse" family gets a neat 10x speedup (part of the work is reading, which is 2x faster, the other is allocating, which is now 25x faster, we end up with 10x when combined).
`@` should not be legal to use as a binary operator. I accepted it in the parser because it occurred in the .enso sources, but it was actually used to create a syntax error to test error recovery.
See: https://www.pivotaltracker.com/story/show/184054024
* Hash codes prototype
* Remove Any.hash_code
* Improve caching of hashcode in atoms
* [WIP] Add Hash_Map type
* Implement Any.hash_code builtin for primitives and vectors
* Add some values to ValuesGenerator
* Fix example docs on Time_Zone.new
* [WIP] QuickFix for HashCodeTest before PR #3956 is merged
* Fix hash code contract in HashCodeTest
* Add times and dates values to HashCodeTest
* Fix docs
* Remove hashCodeForMetaInterop specialization
* Introduce snapshoting of HashMapBuilder
* Add unit tests for EnsoHashMap
* Remove duplicate test in Map_Spec.enso
* Hash_Map.to_vector caches result
* Hash_Map_Spec is a copy of Map_Spec
* Implement some methods in Hash_Map
* Add equalsHashMaps specialization to EqualsAnyNode
* get and insert operations are able to work with polyglot values
* Implement rest of Hash_Map API
* Add test that inserts elements with keys with same hash code
* EnsoHashMap.toDisplayString use builder storage directly
* Add separate specialization for host objects in EqualsAnyNode
* Fix specialization for host objects in EqualsAnyNode
* Add polyglot hash map tests
* EconomicMap keeps reference to EqualsNode and HashCodeNode.
Rather than passing these nodes to `get` and `insert` methods.
* HashMapTest run in polyglot context
* Fix containsKey index handling in snapshots
* Remove snapshots field from EnsoHashMapBuilder
* Prepare polyglot hash map handling.
- Hash_Map builtin methods are separate nodes
* Some bug fixes
* Remove ForeignMapWrapper.
We would have to wrap foreign maps in assignments for this to be efficient.
* Improve performance of Hash_Map.get_builtin
Also, if_nothing parameter is suspended
* Remove to_flat_vector.
Interop API requires nested vector (our previous to_vector implementation). Seems that I have misunderstood the docs the first time I read it.
- to_vector does not sort the vector by keys by default
* Fix polyglot hash maps method dispatch
* Add tests that effectively test hash code implementation.
Via hash map that behaves like a hash set.
* Remove Hashcode_Spec
* Add some polyglot tests
* Add Text.== tests for NFD normalization
* Fix NFD normalization bug in Text.java
* Improve performance of EqualsAnyNode.equalsTexts specialization
* Properly compute hash code for Atom and cache it
* Fix Text specialization in HashCodeAnyNode
* Add Hash_Map_Spec as part of all tests
* Remove HashMapTest.java
Providing all the infrastructure for all the needed Truffle nodes is no longer manageable.
* Remove rest of identityHashCode message implementations
* Replace old Map with Hash_Map
* Add some docs
* Add TruffleBoundaries
* Formatting
* Fix some tests to accept unsorted vector from Map.to_vector
* Delete Map.first and Map.last methods
* Add specialization for big integer hash
* Introduce proper HashCodeTest and EqualsTest.
- Use jUnit theories.
- Call nodes directly
* Fix some specializations for primitives in HashCodeAnyNode
* Fix host object specialization
* Remove Any.hash_code
* Fix import in Map.enso
* Update changelog
* Reformat
* Add truffle boundary to BigInteger.hashCode
* Fix performance of HashCodeTest - initialize DataPoints just once
* Fix MetaIsATest
* Fix ValuesGenerator.textual - Java's char is not Text
* Fix indent in Map_Spec.enso
* Add maps to datapoints in HashCodeTest
* Add specialization for maps in HashCodeAnyNode
* Add multiLevelAtoms to ValuesGenerator
* Provide a workaround for non-linear key inserts
* Fix specializations for double and BigInteger
* Cosmetics
* Add truffle boundaries
* Add allowInlining=true to some truffle boundaries.
Increases performance a lot.
* Increase the size of vectors, and warmup time for Vector.Distinct benchmark
* Various small performance fixes.
* Fix Geo_Spec tests to accept unsorted Map.to_vector
* Implement Map.remove
* FIx Visualization tests to accept unsorted Map.to_vector
* Treat java.util.Properties as Map
* Add truffle boundaries
* Invoke polyglot methods on java.util.Properties
* Ignore python tests if python lang is missing
Added a separate pass, `FullyQualifiedNames`, that partially resolves fully qualified names. The pass only resolves the library part of the name and replaces it with a reference to the `Main` module.
There are 2 scenarios that could be potentially:
1) the code uses a fully qualified name to a component that has been
parsed/compiled
2) the code uses a fully qualified name to a component that has **not** be
imported
For the former case, it is sufficient to just check `PackageRepository` for the presence of the library name.
In the latter we have to ensure that the library has been already parsed and all its imports are resolved. That would require the reference to `Compiler` in the `FullyQualifiedNames` pass, which could then trigger a full compilation for missing library. Since it has some undesired consequences (tracking of dependencies becomes rather complex) we decided to exclude that scenario until it is really needed.
# Important Notes
With this change, one can use a fully qualified name directly.
e.g.
```
import Standard.Base
main =
Standard.Base.IO.println "Hello world!"
```
Unsetting literal sources during the `text/fileClose` operation would also unlink sources from the actual file. That would be never set back during the reopening of the file, resulting in an NPE during application of changes at a later point.
# Important Notes
Revealed during https://github.com/enso-org/enso/pull/4050 which was the first(?) to do close/open of the file.
The exception showing up in GUI and preventing further actions is now gone.
The new `TreeToIr` conversion class inherited usage of `UnhandledEntity` to signal parser errors from the previous `AstToIr` Scala based convertor. Over the time we were improving error recovery - however only _step by step_. This pull request exterminates _all the panics_ for once and forever!
# Important Notes
Unlike Scala, Java has concept of [checked exceptions](http://wiki.apidesign.org/wiki/Checked_exception) - an exception that has to be caught. This PR introduces new checked `SyntaxException` and throws it instead of unchecked `UnhandledEntity`. Because the exception is checked, each method either needs to declare it in its signature or catch it and handle it. No exception can escape or disappear. The main conversion method `TreeToIr.translateModule` doesn't propagate the `SyntaxException`. That provably demonstrates - _all panic states_ are handled and reported as _syntax errors_ in the `IR`.
Component Groups may add additional modules to compilation. This change ensures that whatever modules result from import/export resolution, they are not duplicate. Not only could that lead to unnecessary compilation but also to multiple reports of the same error which would be confusing to users.
This fixes https://www.pivotaltracker.com/story/show/184189980
# Important Notes
No easy way to write unit tests for this, so skipping that on purpose for now.
Use `InteropLibrary.isString` and `asString` to convert any string value to `byte[]`
# Important Notes
Also contains a support for `Metadata.assertInCode` to help locating the right place in the code snippets.
**Vector**
- Adjusted `Vector.sort` to be `Vector.sort order on by`.
- Adjusted other sort to use `order` for direction argument.
- Added `insert`, `remove`, `index_of` and `last_index_of` to `Vector`.
- Added `start` and `if_missing` arguments to `find` on `Vector`, and adjusted default is `Not_Found` error.
- Added type checking to `+` on `Vector`.
- Altered `first`, `second` and `last` to error with `Index_Out_Of_Bounds` on `Vector`.
- Removed `sum`, `exists`, `head`, `init`, `tail`, `rest`, `append`, `prepend` from `Vector`.
**Pair**
- Added `last`, `any`, `all`, `contains`, `find`, `index_of`, `last_index_of`, `reverse`, `each`, `fold` and `reduce` to `Pair`.
- Added `get` to `Pair`.
**Range**
- Added `first`, `second`, `index_of`, `last_index_of`, `reverse` and `reduce` to `Range`.
- Added `at` and `get` to `Range`.
- Added `start` and `if_missing` arguments to `find` on `Range`.
- Simplified `last` and `length` of `Range`.
- Removed `exists` from `Range`.
**List**
- Added `second`, `find`, `index_of`, `last_index_of`, `reverse` and `reduce` to `Range`.
- Added `at` and `get` to `List`.
- Removed `exists` from `List`.
- Made `all` short-circuit if any fail on `List`.
- Altered `is_empty` to not compute the length of `List`.
- Altered `first`, `tail`, `head`, `init` and `last` to error with `Index_Out_Of_Bounds` on `List`.
**Others**
- Added `first`, `second`, `last`, `get` to `Text`.
- Added wrapper methods to the Random_Number_Generator so you can get random values more easily.
- Adjusted `Aggregate_Column` to operate on the first column by default.
- Added `contains_key` to `Map`.
- Added ALIAS to `row_count` and `order_by`.
Potential workaround to line endings problems after `vcs/restore` operation is executed.
# Important Notes
Not really able to reproduce the problem myself so this PR has a lot of _leap of faith_ in it.
Don't propagate errors from `toDisplayString` - construct an error message with `Atom.toString`.
# Important Notes
> currently a failure in to_text is swallowed by `toString` and we cannot detect that something went wrong during the serialization
Not sure how satisfying the solution is, but the error swallowing happens in Truffle and there is little to do with it. We can just catch the error ourselves and produce some meaningful string.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}