- Add type detection for `Mixed` columns when calling column functions.
- Excel uses column name for missing headers.
- Add aliases for parse functions on text.
- Adjust `Date`, `Time_Of_Day` and `Date_Time` parse functions to not take `Nothing` anymore and provide dropdowns.
- Removed built-in parses.
- All support Locale.
- Add support for missing day or year for parsing a Date.
- All will trim values automatically.
- Added ability to list AWS profiles.
- Added ability to list S3 buckets.
- Workaround for Table.aggregate so default item added works.
Fixes performance problems observed when creating/resolving errors (#6674):
|before|after|
|---|---|
|||
This also helps with #6637, although I haven't been able to reproduce the degree of slowness shown there so I can't confirm that this resolves that issue.
# Important Notes
- Disable visualizations until shown. [Faster startup, and all graph changes.]
- 6x faster message deserialization. [Saves 400ms when making a change with many visualizations open.]
- Fast edge recoloring. [Saves 100-150ms when disconnecting an edge in Orders.]
- Add a checked implementation of a `profiler` data structure, used instead of the fast `unsafe` version when `debug-assertions` are enabled.
Several small changes:
- Dropdowns: Populate `GridView` lazily (fixes#6865).
- Clear disconnected edges when editing node (fixes case 1 in #7018).
- Fix regression in node selection rendering (2nd bug in #6975).
- Update profiler docs. The hotkey to *prOfile without exiting* is now `Ctrl+Alt+O` (`Ctrl+Alt+P` has been requisitioned by the CB).
Node selection:
| Pre-`Rectangle` | This PR |
| --- | --- |
|  |  |
# Important Notes
- `Rectangle`: When `inset > border`, the extra space is now between the body and the border, not outside the border.
- More robust node layering logic. Now an inconsistent layer order cannot occur, even if something strange happens (like editing an expression and an edge at the same time).
- The dynamic drop down in the `drop_down` example scene doesn't show any entries before (or after) this, so I can't test the dynamic case.
close#6936
Changelog:
- add: new suggestion type Getter that is not exposed to the api
- update: do not return suggestion of type getter when doing a global search (without specifying self types)
Private suggestions and modules mentioned in the issue will be filtered out after we finish the work on the new (refined) exports algorithm.
# Important Notes

This PR adds facilities for controllers to be aware of what shortcut command is currently being processed. This allows grouping consequences of single user action into a single transaction without hard-coding it separately for all the separate paths case-by-case, which turned out to be challenging and error-prone.
Additionally, a number of minor fixes were carried over from #6877:
* workaround for #6718;
* avoiding creating spurious transactions when dealing with node positions;
* dropping any non-user user-triggered transactions that occur during the IDE project initialization.
Before, we prevented default on every keyboard event, making usage of HTML inputs impossible (both on the dashboard and inside visualizations).
# Important Notes
The list of shortcuts was based on comments in #6364 (where the `preventDefault` was introduced).
Implements #6544 (eliminates 10/42 of the constantly-displayed draw calls).
Fixes#6717. Improves startup CPU time by 5% (250ms, loading Orders on my dev box).
# Important Notes
- Edges: New implementation uses only Rectangle under most conditions.
- Node and action area: Replace some shapes with Rectangle.
- List view: Replace some shapes with Rectangle.
- Display object hierarchy: The lowest-level shape instance types no longer have their own display objects.
- Includes initial support for using `Rectangle` to display triangles.
Fixes#6763
The bug was caused by pushing stack frames in the engine first, then failing to get graph controller - in that case we didn't update graph, but kept the stack, so graph was not synchronized with stack.
This PR changes the approach: we try to open graph first, only then push frames to stack. If _any_ frame will fail, we try to pop those we pushed so far, to restore the previous state. The same fix was applied for leaving nodes.
Also, I realized, that running several "enter node" / "leave node" actions could mix push/pop operations, making a mess with our execution context state. I've added a mutex to ensure we won't do this: the contesting operation will simply fail.
# Important Notes
In case when _restoring_ state fails, I did not have any better idea than just trying until it succeed.
Now, quick typing in component browser and pressing "enter" should not cut off the last part typed. Fixes#6733https://github.com/enso-org/enso/assets/3919101/3979ed5a-ba4e-4e25-93e6-672e731b7bd8
On this occasion, also fixed "go-to-dashboard" button and "Unsupported engine version" being over the full-screen visualization. Fixes#6722
# Important Notes
I did a significant refactoring of Project View:
1. The huge `frp::extend` block was split into multiple `init` methods.
2. Remaining of the "Old searcher" were removed.
3. The "Edited" event from node's input is emitted only when in edit mode (it's consistent with other API terminology, and makes FRP for showing CB much simpler.
The code was _mostly_ moved around, but the check is advised anyway, as there were small changes here and there.
Implements #6792Fixes#6715Fixes#6052Fixes#5689
The dynamic dropdown widgets entries now can specify additional widget configuration as a list of `parameters` of the inner method call. That allows for creating smarter widgets within nested constructors, taking the outer widget's context into account.
<img width="772" alt="image" src="https://github.com/enso-org/enso/assets/919491/97c70654-9170-4cf0-ae4d-2c25c74caa96">
With the changes to the serialization logic, I have also adressed issues related to automatic label generation for both static and dynamic dropdown entries. For access chains (e.g. `Foo.Bar.Baz_Qux`), the label will now always contain only the last segment, and all underscores will be removed (e.g. `Baz Qux`). This also applies to dynamic entries where the label is not explicitly specified in method annotation.
<img width="265" alt="image" src="https://github.com/enso-org/enso/assets/919491/1abe6c77-010b-4622-b252-97cd1543cb48">
Additionaly, now the dynamic entries containing constructors will also be resolved within suggestion database, allowing us to automatically insert relevant import, shorten the actually used expression and wrap it with parentheses if required. That was required for nested widgets to show up, as we depend on properly resolved argument names to show them. The widget definitions in annotations no longer need to wrap the expressions manually. Instead, the constructors used in dropdown entries should be specified using fully qualified names, similarly to how we do it in tag values.
CC @jdunkerley - The dropdown entries containing just a constructor will no longer need added parentheses around them. Instead, the constructors should be specified using fully qualified names, similarly to how we do it in tag values.
<img width="389" alt="image" src="https://github.com/enso-org/enso/assets/919491/19944b5b-d0c7-43ac-bf17-ca1556e0b3f0">
Note that currently the import resolution is attempted even if the used constructor is is not specified using a fully qualified name. To accomplish that, the IDE is performing a more expensive search through whole suggestion database for matching type and module (e.g. in example above, we are searching for a match for `Aggregate_Column.First`). If there are multiple potential matches due to a name collision, it is undefined which one would be preferred. Effectively one will be picked at random. To avoid that, the libraries should over time transition to using fully qualified names wherever possible.
# Important Notes
I have removed the `payload` field from the span tree, and with it the generic argument on its nodes. This was already partially done on the branch with new design, on which I also had a few changes that turned out to be useful for this PR. So I pulled it in as well. It is a nice simplification that will ease our further work on removing the span-tree altogether. The biggest impact it had was on the node output port, where I had to store the port data outside of the span tree. This is the approach we would be taking when transitioning to AST anyway.
Empty edition (null value) was parsed as NaN, which was confusing. This change correctly detects the case before trying different fallback mechanisms.
Addresses invalid warning mentioned in #6806.
Only invalidate the graph editor view at most once per frame. On develop, this saves about 70ms (2%). Testing a recent backend without #6755 as a stress-test, this saves about 5s (45%). This reflects better scalability to large numbers of `SuggestionUpdate` messages.
Fixes#6630.
# Important Notes
- Also fix intermittent profiling failures occurring since the introduction of microtasks.
* Remove unused code: project management in component browser
* Encapsulate internal FRP logic of project list
* Collapse some code paths
* Open project passed on command line through presenter
A project name or ID that is passed on the command line was initialised
in the controller setup, before the presenters and views are set up.
Now, we fully initialise the IDE before opening a project so we have
control over the view while a project is being opened.
* Show a spinner in all cases of opening a project
* Let root presenter open/close projects when switching projects
* Change spinner to make progress over a fixed period
* Resolve issues when Project Manager API isn't available
* Bump wasm size limit
Fixes some of #6662
Issues addressed:
- `ide watch` and `gui watch` should now use the desktop platform
- error screen should now be shown when passing invalid options
- password (both creating password when registering, and resetting password) should now warn on invalid input
# Important Notes
Instead of checking whether `location.hostname === 'localhost'`, I've opted to use a constant defined by the build tool instead. This is to make it easier to merge the cloud IDE and desktop IDE entrypoints in the future, since it would be able to simply set `platform: Platform.cloud` in the build config.
Fixes#6787
# Important Notes
I can't get Project Manager compilation to work locally so I guess I'll be relying on CI to verify that it's working correctly?
Of course, QA should be able to catch any problems too - the websocket API hasn't been changed so it should work out of the box with the current dashboard.
Refactored the logic behind selecting appropriate widgets for span tree nodes. Now the bulk of it is moved into widget methods. When a given widget type is reporting to be not compatible with the expression, it will not be used even if the configuration was overriden using an method argument annotation. In that case, the usual logic for automatically selecting the appropriate widget will kick in.

* Run typecheck and eslint on Lint CI
* Address reviews; fix type errors in `.d.ts` files
* Remove unused parameter
* Run prettier
* Fix lint error
---------
Co-authored-by: Paweł Buchowski <pawel.buchowski@enso.org>
# Important Notes
The mouse handling changes involve an unfortunate huge hack, where we enable mouse events on the mouse shape during box selection. That way we know for sure that no other shape will be able to receive mouse enter event. Then the list editor widget is modified to only actually respond to events when its background is hovered. We will definitely want a more proper way to handle mouse event contention, but it's definitely out of scope for current bugfixing.
This change fixes the rather elusive bug where shutdown hooks could not be fired when shutdown was taking too long and termination was forced.
Under the circumstances described in detail in ticket #6515 there was a small chance that we could have a shutdown race condition. Essentially the messages received when client was disconnected and language server forced the termination could lead to language server not sending the public `ProjectClosed` message which triggers shutdown hook. Now we always do.
Also made sure that multiple `ProjectClosed` messages don't lead to firing multiple shutdown hooks, which was another possibility.
No tests as one would have to be able to introduce different delays in various message handlers to simulate the problem.
Having ability to do such chaos testing would be nice but it is beyond the scope of this ticket.
I was able to reproduce the problem 100% with my specially crafted setup so I'm fairly confident about the change.
Closes#6515.
close#6611
Changelog:
- update: run compiler passes on the `ascribedType` field of the constructor arguments
- update: suggestion builder uses the type information attached to `ascribedType`
- feat: resolve qualified names in type signatures
Fixes#5088. Adds a ensoGL spinner for visualizations waiting on data.
https://user-images.githubusercontent.com/1428930/236801655-67a0ffed-da5d-4e27-8797-cd8126cb86d9.mp4
# Important Notes
This spinner will not show up for the duration where visualizations are processing data on the frontend. If this is a concern, visualization need to implement heir own loading spinner, or we need to provide a unified API for them to keep the spinner visible.
Fixes#6609 by
- e380e647af - running whole `Vector_Spec` on `java.util.ArrayList`
- 9b1229fe20 - introducing a node to handle interop values
# Important Notes
Contains additional DSL processor fix:
- 415623dcb9 - to not crash the compiler, but to properly report compiler error
Artifically limiting the number of reported warnings to 100. Also added benchmarks with random Ints to investigate perf issues when dealing with warnings (future task).
Ideally we would have a custom set-like collection that allows us internally to specify a maximal number of elements. But `EnsoHashMap` (and potentially `EnsoSet`) are still WIP when it comes to being PE-friendly.
The change also allows for checking if the limit for the number of reported warnings has been reached. It will visualize by adding an additional "Warnings limit reached." to the visualization.
The limit is configurable via `--warnings-limit` parameter to `run`.
Closes#6283.
This PR fixes#6560.
The fix has a few elements:
1) Bumps the Engine requirement to the latest release, namely `2023.1.1`.
2) Changed the logic of checking whether a given version matches the requirement. Previously, we relied on `VersionReq` from `semver` crate which did not behave intuitively when the required version had a prerelease suffix. Now we rely directly on Semantic Versioning rules of precedence.
3) Code cleanups, including deduplicating 3 copies of the version-checking code, and moving some tests to more sensible places.
This is a re-creation of #6308.
Creates buttons to switch between cloud and local backends for listing directories, opening projects etc.
# Important Notes
The desktop backend currently uses a hardcoded list of templates, mostly because they look better because they have background images. However, it can easily be changed to use `listSamples` endpoint and switched to the default grey background.
Remove the magical code generation of `enso_project` method from codegen phase and reimplement it as a proper builtin method.
The old behavior of `enso_project` was special, and violated the language semantics (regarding the `self` argument):
- It was implicitly declared in every module, so it could be called without a self argument.
- It can be called with explicit module as self argument, e.g. `Base.enso_project`, or `Visualizations.enso_project`.
Let's avoid implicit methods on modules and let's be explicit. Let's reimplement the `enso_project` as a builtin method. To comply with the language semantics, we will have to change the signature a bit:
- `enso_project` is a static method in the `Standard.Base.Meta.Enso_Project` module.
- It takes an optional `project` argument (instead of taking it as an explicit self argument).
Having the `enso_project` defined as a (shadowed) builtin method, we will automatically have suggestions created for it.
# Important Notes
- Truffle nodes are no longer generated in codegen phase for the `enso_project` method. It is a standard builtin now.
- The minimal import to use `enso_project` is now `from Standard.Base.Meta.Enso_Project import enso_project`.
- Tested implicitly by `org.enso.compiler.ExecCompilerTest#testInvalidEnsoProjectRef`.
This PR fixes#6371.
# Important Notes
@kazcw @wdanilo I don't particularly like this solution, but I don't see any other good way to define the relationship between two instances of the same shape (`Rectangle`) used in different UI elements. If you are aware of a more elegant solution, I’d be happy to hear any suggestions.
Support rendering multiple flavors of a shape system in the same layer. Fixes bugs seen as text disappearing when multiple fonts are used together (#6460 and issue discussed in #6366).
Dead Letter logging is occasionally flooding our logs which is confusing to users reporting bugs. Left the possibility of a single report so that we know that something is happening.
Fixes#6416 by introducing `InlineableNode`. It runs fast even on GraalVM CE, fixes ([forever broken](https://github.com/enso-org/enso/pull/6442#discussion_r1178782635)) `Debug.eval` with `<|` and [removes discouraged subclassing](https://github.com/enso-org/enso/pull/6442#discussion_r1178778968) of `DirectCallNode`. Introduces `@BuiltinMethod.needsFrame` - something that was requested by #6293. Just in this PR the attribute is optional - its implicit value continues to be derived from `VirtualFrame` presence/absence in the builtin method argument list. A lot of methods had to be modified to pass the `VirtualFrame` parameter along to propagate it where needed.
Rewrites node input component. Now the input is composed of multiple widget components arranged in a tree of views with automatic layout. That allows creating complex UI elements on top of the node itself, and further widget positions will be automatically adapted to that. The tree roughly follow the span tree, as it is built by consuming its nodes and eagerly creating widgets from them. The tree is rebuilt every time the expression changes, but that rebuild process reuses as much previously created widgets as possible, and only updates their configuration as needed. Each widget type can have its own configuration options that can be passed to it from the parent, or assigned based on configuration received from the language server.
<img width="773" alt="image" src="https://user-images.githubusercontent.com/919491/233439310-9c39ea88-19bc-43da-9baf-1bb176e2724e.png">
# Important Notes
For now, all span-tree updates are sent over to the shared Frp endpoint of the whole tree, so there is no mechanism for intercepting them by the parent widgets. One idea would be to use existing bubbling/capturing events on widget display objects for that purpose, but I think existing implementation is simpler and more convenient, and we can always easily change that if we have a use for it.
There are some issues with performance due to much more display objects being created on the graph. Expect it to be a little worse, especially at initialization time.
Fixes#6385
Partial rollback of #6364
It turns out that preventing default for mouse events is a bad idea in general. It shouldn't affect other fixed bugs because (afaik) all of them were caused by keyboard events.
We're still preventing default for keyboard events.
Integrate the UI for electing the Execution Environment with the Language Server and unify existing uses. Implements #5930 + actual integration instead of just mocking it.
https://user-images.githubusercontent.com/1428930/232919438-6e1e295a-34fe-4756-86a4-5f5d8f718fa0.mp4
# Important Notes
The console output is only emitted as part of the `INFO` level. A better check would be to look at the messages sent to the backend in the developer console.
Fixes#6317
The `drop` method is available in the WASM object. This can be tested by typing `ensoglApp.wasm.drop()` in the dev console - all objects should be removed and all connections closed.
# Important Notes
* This PR fixed serveral leaks by this occasion
* A new tool for tracking leaks was added to prelude's `debug` module.
Vector Editor widget is improved: replaced old simple widget with List Editor, and added integration for adding elements.
# Important Notes
The widget is still under feature flag: `--feature-preview.vector-editor`.
close#6254
Changelog:
- fix: race when the actor system may be stopped before the shutdown hooks are executed
- fix: project management spec
- fix: recover from `readLine` failure during the shutdown
* Use Rectangle for breadcrumbs background.
* Use Rectangle for status bar bg.
* Use Rectangle for dropdown bg.
* Dirty global_element_depth_order invalidates sublayers
* Setting new parent may invalidate depth order
* Support per-instance pointer_events_enabled
* Remove workaround for #6241
* Don't propagate warnings on suspended arguments
In the current implementation, application of arguments with warnings
first extracts warnings, does the application and appends the warnings
to the result.
This process was however too eager if the suspended argument was a
literal (we don't know if it will be executed after all).
The change modifies method processor to take into account the
`@Suspend` annotation and not gather warnings before the application
takes place.
* PR review
* Test, fix, re-enable buffer compaction.
- Fix a bug involving trying to move tombstones after multiple GCs (#6197).
- Refactor allocator for more testability.
- Add tests with extensive sequence of allocator operations.
* fmt
* Fix.
* Fix#6011. Don't use debug-assertion; fix sanity check that wasn't usually being run.
* Lint.
* Revert "Fix #6011. Don't use debug-assertion; fix sanity check that wasn't usually being run."
This reverts commit 47b9100c2b.
* Fix accidentally committed line
---------
Co-authored-by: Adam Obuchowicz <adam.obuchowicz@enso.org>
close#6232
Changelog:
- remove: `SqlVersionsRepo`
- update: `SuggestionsDatabaseModuleUpdateNotification` message removing the version
- update: cleanup versions repo usages in the language server
Enso will now associate with two file extensions:
* `.enso` — Enso source file.
* If the source file belongs to a project under the Project Manager-managed directory, it will be opened.
* If the source file belongs to a project located elsewhere, it will be imported into the PM-managed directory and opened;
* Otherwise, opening the `.enseo` file will fail. (e.g., loose source file without any project)
* `.enso-project` — Enso project bundle, i.e., `tar.gz` archive containing a compressed Enso project directory.
* it will be imported under the PM-managed directory; a unique directory name shall be generated if needed.
### Important Notes
On Windows, the NSIS installer is expected to handle the file associations.
On macOS, the file associations are expected to be set up after the first time Enso is started,
On Linux, the file associations are not supported yet.
close#6080
Changelog
- add: implement `SuggestionsRepo.insertAll` as a batch SQL insert
- update: `search/getSuggestionsDatabase` returns empty suggestions. Currently, the method is only used at startup and returns the empty response anyway because the libs are not loaded at that point.
- update: serialize only global (defined in the module scope) suggestions during the distribution building. There's no sense in storing the local library suggestions.
- update: sqlite dependency
- remove: unused methods from `SuggestionsRepo`
- remove: Arguments table
# Important Notes
Speeds up libraries loading by ~1 second.


Update shader tools to new version. Notably, this release contains spirv-cross with fixed issue https://github.com/KhronosGroup/SPIRV-Cross/issues/2129.
# Important Notes
Spirv-cross has no versioning that we could use to specify requirements for using system-wide installed versions. Instead, we have to download the prebuilt distribution by default, so we can rely on known good versions. The usage of binaries in PATH can still be enabled with a build flag, but it is discouraged due to severity of the bug and no easy way of detecting it. If the project is built with buggy shader tools version, the application will run, but it will be visually slightly broken in unexpected ways.
Simplified layout algorithm by removing `content_origin`, and instead treating `(0.0, 0.0)` as origin point in every layout object. This change allows overflowing containers that are within auto-layout. The parent element will no longer be moved within the grid cell when its children overflow it.

# Important Notes
When implementing this change, I have found that when object's size was modified without ever touching its position, that change was not being picked up in the "modified children" list, and `on_updated` was never triggered. Because some sprites now are bottom-left aligned, that is now a common case and was reproducible on the auto-layout example scene. I ended up fixing it by introducing another dirty flag for `computed_size` changes. Right now that flag is applied very broadly (on each layout update), but in the future we might make it more precise by actually checking if the size was changed in the process.
I believe that this might also be a fix for #5095, as I cannot reproduce it anymore with those changes.
close#6139close#6137
When the project is renamed, the engine cleans up affected modules and initiates modules re-indexing to fill the suggestions database with new records. This way it reduces the amount of information stored in the suggestions database and helps implement #6080 optimization.
Changelog:
- remove: rename features from the suggestions database
- update: rename command to initiate modules cleanup and project re-execution
- fix: #6137
- Added alignment configuration option for shape systems. That allows creating bottom-left aligned sprites, which will behave much more naturally inside auto-layouts.
- Added support for alignment in manual layouts. When alignment is set, the manual layout will position the child node at the respective border of its bounding box. The size of aligned node will not be affected. The difference from auto-layout alignment is that each node is aligned individually, and it is not affected by its siblings. This allows for constructing more complicated responsive layouts that don't necessarily follow the grid, without creating wrapper auto-layout elements for each child.

Implements #5919
Apart from some fixed glitches, no visual differences are present. This is mostly a refactor.
- Decoupled node edit mode code from existing port implementation, so ports can easily be replaced in the near future without affecting edit functionality.
- Connected ports and widgets are now always hidden in edit mode. Previously in some situations the colored shapes were incorrectly displayed at wrong positions during editing.
- When entering edit mode, the text cursor is placed at the correct location corresponding to clicked code, compensating for shift introduced by argument placeholders.
# Important Notes
There is a remaining known issue with incoming edges being placed at incorrect places during edit mode, sometimes even outside of the node. This issue is also present in develop. It doesn't make sense to resolve it now, as we are planning to rewrite the ports tree very soon. It will be fixed with that rewrite.
It is sometimes impossible to figure out the real reason for invalid text edit request. Added a bit of context to failures to narrow down the cause of the failure.
# Important Notes
Should help with diagnosing issues like #6099.
Implements #5933: adding tooltips to the buttons next to nodes.
To make the UI consistent, I've added tooltips to the `ToggleButton` class directly, since whenever you have an icon button, it seems helpful to have a tooltip.
`ToggleButton` is only used for the profiling button in the top-right corner and the buttons next to nodes. The output context switch button [isn't implemented yet](https://github.com/enso-org/enso/issues/5929), but once it is, adding a tooltip should be one-liner.

close#5874
Changelog:
- add: `isStatic` parameter to `search/completion` request to search by the `static` suggestion attribute
- update: search non-static suggestions when opening component browser
# Important Notes
Component browser doesn't show `Table.new` and `Table.from_rows` suggestions when a `Table` node is selected.
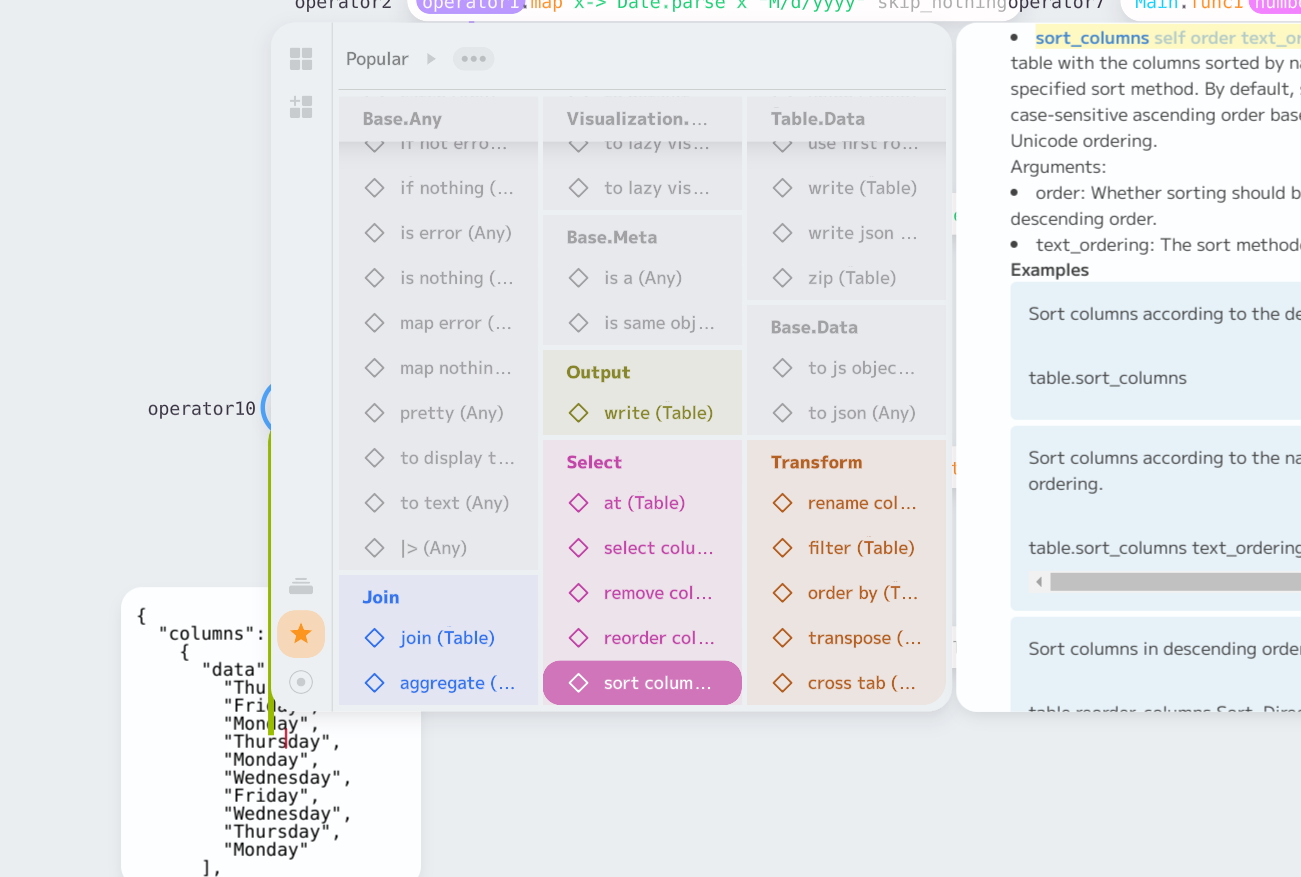
Some small improvements relating to rendering:
- Add a debug option: `-debug.pixel-read-period`. This can be used to measure the performance impact of checking the pointer location on different hardware. [On my development box, it makes no difference to performance.] (Closes#5490).
- Unbind pixel pack buffers after each use. This is recommended practice. It has no performance impact on my machine, and allows SpectorJS to run (`-debug.enable-spector`). (Closes#5941).
Also, simplify the profiling CLI: the `profile.load-profile` and `profile.save-profile` options have been renamed to `profile.load`/`profile.save`; `profile.save` now has a default filename, so you can capture a profile at any time in Electron with Ctrl+Alt+P and it will be written to `profile.json`.
Somebody forgot to apply `./run fmt` before committing to develop, so now we have a lot of whitespace changes in files.
# Important Notes
See https://github.com/enso-org/enso/issues/5166
close#5881
Changelog
- add: ProtocolFactory object that initializes and returns the protocol object
- update: Add protocol initialization to the initialization component
close#5911
In interactive mode, perform writing IR caches in the background jobs queue. Background jobs execution is delayed until the first execution is complete.
Right now, we use the cursor position to determine the target position for dropped items. However, it seems that during dragging of files, we do not always receive mouse events, thus cannot update the cursor position. To avoid this, this PR refactors the functionality to use the location of the drop event, instead of the last known cursor position.
Fixes#5237.
https://user-images.githubusercontent.com/1428930/224735951-9cd6ff62-a749-4ff3-8437-c0bee3c0dd05.mp4
Fixes#5826.
# Important Notes
- Change frontend representation of negation.
- Fix a precedence issue: The `.` operators in -1.x and -1.2 must have different precedences.
- Remove a no-longer-needed special case from backend translation.
- Add tests for this case after all translations.
3rd PR for IDE/Cloud authorization with cognito. This PR introduces registration templates + flows + amplify wrappers for registering & confirming user registration.
Login + Set Username + Forgot Password flows are to be added in next PRs to keep the changes reviewable.
Implements #5640 and #5650
It made sense for me to implement those two together, as I wanted to make sure that the necessary widget API changes will support custom entry values for both dynamic and static data.
- Added support for custom dropdown labels defined on the method annotations
- Added shortening of static dropdown values, which resolves
| dynamic dropdown - custom labels | static dropdown - automatic shortening |
|-|-|
|||
# Important Notes
During implementation I had multiple data update order issues caused by FRP network forming a diamond shape. Two inputs that are often updated together were combined with `all` combinator, and that was further fed into the dropdown. This caused two updates to propagate through the whole network, and one of them was immediately outdated. To fix this and similar future scenarios, I've added an `next_tick` FRP node. It buffers the incoming events until the next browser microtask, preserving only the last received event. Currently if it is called inside a `requestAnimationFrame` callback, the effects of that processing will only be rendered in the next frame. Later this can be mitigated by delaying the rendering logic until the microtask queue is empty.
The `logAvailableComponentsForDebugging` will check and install all necessary components of GraalVM for every mentioned version. While not harmful, it adds up to startup time.
Additionally added an option in language server startup to skip installation of GraalVM components. The latter is already performed by project-manager when opening the project and it is unnecessary to do it twice. Due to LS' architecture this configuration has to be passed around via multiple configs.
Finally, skipped the attempt to install Python component on Windows - this is not supported by GraalVM atm.
Closes#5749.
# Important Notes
The impact of this problem could be really felt the more versions of Enso and GraalVM one had since it would go through all of them.
Implement new Enso documentation parser; remove old Scala Enso parser.
Performance: Total time parsing documentation is now ~2ms.
# Important Notes
- Doc parsing is now done only in the frontend.
- Some engine tests had never been switched to the new parser. We should investigate tests that don't pass after the switch: #5894.
- The option to run the old searcher has been removed, as it is obsolete and was already broken before this (see #5909).
- Some interfaces used only by the old searcher have been removed.
2nd PR for IDE/Cloud authorization with cognito. This PR introduces boilerplate react app + some amplify code to fetch the access token + username of the currently logged in user, if they are already authenticated.
Registration + Login + Set Username + Forgot Password flows are to be added in next PRs to keep the changes reviewable.
Adds a common project that allows sharing code between the `runtime` and `std-bits`.
Due to classpath separation and the way it is compiled, the classes will be duplicated - we will have one copy for the `runtime` classpath and another copy as a small JAR for `Standard.Base` library.
This is still much better than having the code duplicated - now at least we have a single source of truth for the shared implementations.
Due to the copying we should not expand this project too much, but I encourage to put here any methods that would otherwise require us to copy the code itself.
This may be a good place to put parts of the hashing logic to then allow sharing the logic between the `runtime` and the `MultiValueKey` in the `Table` library (cc: @Akirathan).
close#5070
Changelog:
- Include the original exception to log expressions
- Enable logging of Akka Actors' lifecycle events on debug logging level
- Decrease the severity of interruption log messages because interruptions are part of the workflow. The computation can be interrupted at any time, and still be recomputed after. Warnings are just misleading in this case.
Closes#5854
Switches dropdown activation indicator to a triangle shape, and moved it to the horizontal center of a port.

# Important Notes
Modified triangle SDF to be exact. That way the grow operation behaves as expected, rounding the corners. Other than that, it produces the same bound shape at 0 distance.
Precompute MSDFs for all ASCII glyphs; after this, we no longer spend any time on MSDF computations when loading or interacting with the example projects.
Also shader precompilation (during build) is now parallel; if you have many cores and an SSD, it's now practically instant.
Closes#5722.
# Important Notes
- The *dynamic-assets* mechanism now used for MSDF data and shaders is versatile, and could be used to pre-seed any other computation-intensive runtime caches.
Fixes#5807
When implementing [cached icons in the Component Browser](#5779), I assumed pixel_ratio may be only integral (1.0 on normal machines and 2.0 on Retina), but I forgot Windows by default scales its UI by 1.25, breaking the icons entirely.
Added support for named arguments in IDE.
https://user-images.githubusercontent.com/919491/223681303-4c716639-d06e-4e33-aa22-6ebca2801b01.mp4
Named arguments are now recognized in node expressions. The function argument placeholders are rendered around series of named arguments. Insertion and deletion of arguments either by connection dragging or by widget selection will cause arguments around to be rewritten into appropriate form, such that the meaning of the expression doesn't change. We no longer need to introduce any wildcards (`_`) in argument positions when editing an argument list of a resolved method.

For unresolved function calls, the old behaviour remains, as we don't have data about argument names or their desired order.
This change downgrades hashing algorithm used in caching IR and library bindings to SHA-1. It is sufficient and significantly faster for the purpose of simple checksum we use it for.
Additionally, don't calculate the digest for serialized bytes - if we get the expected object type then we are confident about the integrity.
Don't initialize Jackson's ObjectMapper for every metadata serialization/de-serialization. Initialization is very costly.
Avoid unnecessary conversions between Scala and Java. Those back-and-forth `asScala` and `asJava` are pretty expensive.
Finally fix an SBT warning when generating library cache.
Closes https://github.com/enso-org/enso/issues/5763
# Important Notes
The change cuts roughly 0.8-1s from the overall startup.
This change will certainly lead to invalidation of existing caches. It is advised to simply start with a clean slate.
This PR changes build script's `ide watch` and `ide start` commands, so they don't use `electron-builder` to package. Instead, they invoke `electron` directly, significantly reducing time overhead.
`ide watch` will now start Electron process, while continuously rebuilding gui and the client in the background. Changes can be puilled by reloading within the electron, or closing the electron and letting it start once again. To stop, the script should be interrupted with `Ctrl+C`.
This change adds serialization and deserialization of library bindings.
In order to be functional, one needs to first generate IR and
serialize bindings using `--compiled <path-to-library>` command. The bindings
will be stored under the library with `.bindings` suffix.
Bindings are being generated during `buildEngineDistribution` task, thus not
requiring any extra steps.
When resolving import/exports the compiler will first try to load
module's bindings from cache. If successful, it will not schedule its
imports/exports for immediate compilation, as we always did, but use the
bindings info to infer the dependent modules.
The current change does not make any optimizations when it comes to
compiling the modules, yet. It only delays the actual
compilation/loading IR from cache so that it can be done in bulk.
Further optimizations will come from this opportunity such as parallel
loading of caches or lazily inferring only the necessary modules.
Part of https://github.com/enso-org/enso/issues/5568 work.
Fixes#5188
Added a new method `ShapeOps::recolorize` which changes color depending on values on r, g, b channels. It should be explained more in the docs. It will allow us using colored cached icons in the Component Browser.
Fixes#5023
This PR adds the ability to add a parameter to shapes defined, with `shape!` macro being a reference to a cached shape.
The API and results may be read [in the example scene](33b6f5937e/lib/rust/ensogl/example/cached-shape/src/lib.rs)
It also contains many other changes, required to have it working:
* We render cached shapes to texture in a different mode than normal shapes: the alpha channel is replaced with information about signed distance. That allows us using cached shapes as normal shapes, i.e. translate them, add to other shapes etc.
* We initialize and arrange shapes as a part of Word initialization, not in pass.
* We keep and blend colors in RGBA instead of LCHA - this is preparation for replacing colors in the next task, and also speeds up our shaders a bit.
The code was refactored in the process: the cached-shape related things were moved to a single module.
Visualizations closing right after opening was caused by the GUI being unresponsive during loading of some visualizations. This caused the timer for measuring the time between space bar press and space bar release to be inflated. The delayed events triggered the "visualization preview mode”, thus closing the visualization has it seemed that the space bar was held down, even though the events just arrived with some delay.
The problem is mitigated by considering the number of frames that have passed between the space and down and the space bar up event, instead of just the wall clock time. If the number of frames is too low, this indicates that frames were dropped to the time is inflated.
Fixes https://github.com/enso-org/enso/issues/5223
Fixes an error in our scoring algorithm for computing match scores. It now correctly computes scores for patterns that are trailing the target text and ranks patterns at the end of the target text higher than patterns in the middle of the target text.
Closes #4965 (for now).
See also Discussion https://github.com/enso-org/enso/discussions/5649
In cloud we want to allow users to create new project from the template. List of templates is a bit outdated and doesn't contain all from the https://github.com/enso-org/project-templates. This PR simply adds missing ones
A combination of commands triggered separate compilation that only recompiled part of builtins. A mechanism that workaround annotation processor's problems with separate compilation was updated to include changes from https://github.com/enso-org/enso/pull/4111. This was pretty tough to find given the rather unusual circumstances in CI.
# Important Notes
This eliminates the _random_ failures in CI related to separate compilation.
To reproduce a specific set of steps has to be executed:
```
sbt> all buildEngineDistribution engine-runner/assembly runtime/Benchmark/compile language-server/Benchmark/compile searcher/Benchmark/compile
(exit sbt)
sbt> test
```
Expressions returning polyglot values were not reporting the type of the result because we have to do additional magic that infers the correct Enso type. Since this is exactly what `TypeOfNode` does, I re-used the logic.
Straightforward solution failed in tests because of assertions:
```
[enso] WARNING: Execution of function main failed (Invalid library usage. Cached library must be adopted by a RootNode before it is executed.).
java.lang.AssertionError: Invalid library usage. Cached library must be adopted by a RootNode before it is executed.
```
That is why this PR replaces `ExecutionEventListener` with `ExecutionEventNodeFactory`.
# Important Notes
Usage of `TypeOfNode` for programs that **do not** import stdlib means that we report types that do not involve stdlib e.g.
`Standard.Builtins.Main.Integer` instead of `Standard.Base.Data.Numbers.Integer`. While surprising, this is correct and I would say desirable. While reviewing the code, notice the difference in expectations in our runtime tests.
Implementation of https://www.pivotaltracker.com/story/show/184012743https://user-images.githubusercontent.com/919491/214082311-cf49e43c-1d1f-4654-903c-a4224cd954d8.mp4
This is also a step towards more general widget support. The widget metadata is queried using `Meta.get_annotation` method through a dedicated visualization. For now only `Single_Choice` case is handled, and always all suggestions are is returned.
# Important Notes
There are limitations as to which node segments receive a widget. Only chain method calls are supported now (`thing.method` syntax), and only outside of lambda scope. Widgets in lambdas will require support for visualisations of lambda subexpressions, which is currently missing in the engine. The IDE technically tries to place the widgets there, but the data never arrives. It should work once the engine support is added.
This PR includes a mock for `Meta.get_annotation` call that only supports `Table.at` method. Real implementation is a separate task that is already in progress.
This PR contains the first implementation of `cached_shape!` macro, which should help us with reducing draw calls in our application.
```rust
mod icon1 {
use super::*;
ensogl_core::cached_shape! { 32 x 32;
() {
let shape = Circle(16.px()).fill(color::Rgba::green());
shape.into()
}
}
}
mod icon2 {
use super::*;
ensogl_core::cached_shape! { 202 x 312;
() {
let shape = Rect((200.px(), 310.px())).fill(color::Rgba::red());
shape.into()
}
}
}
```
The above code creates two cached shapes. They are similar to normal shapes (created with `shape!` macro), except that:
1. they do not allow for any parametrization
2. They are rendered at the application start to the special texture with cached shapes.
The texture will be used in next PRs to cache all Component Browser icons on the texture and draw all of them just by single, fast draw call. In the future, more shapes can be cached, further reducing draw calls and making them simple.
# Important Notes
The results are presented in `cached_shapes` debug scene: there are two shapes displayed and a scaled cached texture is displayed in the background.
In order to investigate `engine/language-server` project, I need to be able to open its sources in IGV and NetBeans.
# Important Notes
By adding same Java source (this time `package-info.java`) and compiling with our Frgaal compiler the necessary `.enso-sources*` files are generated for `engine/language-server` and then the `enso4igv` plugin can open them and properly understand their compile settings.

In addition to that this PR enhances the _"logical view"_ presentation of the project by including all source roots found under `src/*/*`.
https://github.com/enso-org/enso/pull/3764 introduced static wrappers for instance methods. Except it had a limitation to only be allowed for types with at least a single constructor.
That excluded builtin types as well which, by default, don't have them. This limitation is problematic for Array/Vector consolidation and makes builtin types somehow second-citizens.
This change lifts the limitation for builtin types only. Note that we do want to share the implementation of the generated builtin methods. At the same time due to the additional argument we have to adjust the starting index of the arguments.
This change avoids messing with the existing dispatch logic, to avoid unnecessary complexity.
As a result it is now possible to call builtin types' instance methods, statically:
```
arr = Array.new_1 42
Array.length arr
```
That would previously lead to missing method exception in runtime.
# Important Notes
The only exception is `Nothing`. Primarily because it requires `Nothing` to have a proper eigentype (`Nothing.type`) which would messed up a lot of existing logic for no obvious benefit (no more calling of `foo=Nothing` in parameters being one example).
This PR implements HTML generation from documentation IR for all suggestion database entries and replaces the old documentation panel with a newer one.
Additional adjustments to the looks of the documentation would be applied separately in a future PR. This PR focuses on the fastest possible delivery of a usable documentation panel. We want to test it in real-world use cases and gather feedback for future improvements.
Documentation demo scene with mocked data:
https://user-images.githubusercontent.com/6566674/213436313-88753ed8-346f-423e-956e-7db39f5dc266.mp4
Component browser with actual engine-provided data:
https://user-images.githubusercontent.com/6566674/213436375-d0ec074b-f7a6-4deb-a7de-3adee999cc86.mp4
# Important Notes
- Fixed language protocol data structures.
- Scrolling to the selected method is also implemented here.
- Also, the selected item is highlighted with yellow.
- Only some pieces of information we have are displayed. For example, we don't display return types for methods or types of arguments.
- A bunch of code related to previous implementation is removed, but probably not all of it.
Implements [#183453466](https://www.pivotaltracker.com/story/show/183453466).
https://user-images.githubusercontent.com/1428930/203870063-dd9c3941-ce79-4ce9-a772-a2014e900b20.mp4
# Important Notes
* the best laziness is used for `Text` type, which makes use of its internal representation to send data
* any type will first compute its default string representation and then send the content of that lazy to the IDE
* special handling of files and their content will be implemented in the future
* size of the displayed text can be updated dynamically based on best effort information: if the backend does not yet know the full width/height of the text, it can update the IDE at any time and this will be handled gracefully by updating the scrollbar position and sizes.
Introduces unboxed (and arity-specialized) storage schemes for Atoms. It results in improvements both in memory consumption and runtime.
Memory wise: instead of using an array, we now use object fields. We also enable unboxing. This cuts a good few pointers in an unboxed object. E.g. a quadruple of integers is now 64 bytes (4x8 bytes for long fields + 16 bytes for layout and constructor pointers + 16 bytes for a class header). It used to be 168 bytes (4x24 bytes for boxed Longs + 16 bytes for array header + 32 bytes for array contents + 8 bytes for constructor ptr + 16 bytes for class header), so we're saving 104 bytes a piece. In the least impressive scenarios (all-boxed fields) we're saving 8 bytes per object (saving 16 bytes for array header, using 8 bytes for the new layout field). In the most-benchmarked case (list of longs), we save 32 bytes per cons-cell.
Time wise:
All list-summing benchmarks observe a ~2x speedup. List generation benchmarks get ~25x speedups, probably both due to less GC activity and better allocation characteristics (only allocating one object per Cons, rather than Cons + Object[] for fields). The "map-reverse" family gets a neat 10x speedup (part of the work is reading, which is 2x faster, the other is allocating, which is now 25x faster, we end up with 10x when combined).
This is a followup to https://github.com/enso-org/enso/pull/4046#pullrequestreview-1248164069.
- Compiler job cancelation is now handled - the cache entry will be cleared or the job will be resumed if there is still demand.
- The compilation awaiting process has been rewritten to not use polling. The "read cache" job is now only used to dispatch known valid reads. It is always completed within a single run cycle.
- Changed shader struct to use `ImString` for storing code, so it can be cheaply cloned. This is now common, as we are cloning it from cache.
`@` should not be legal to use as a binary operator. I accepted it in the parser because it occurred in the .enso sources, but it was actually used to create a syntax error to test error recovery.
See: https://www.pivotaltracker.com/story/show/184054024
While doing regular node manipulation in editior, noticed a number of situations when
```
java.lang.IndexOutOfBoundsException: None
at java.base/java.lang.Character.offsetByCodePoints(Character.java:8699)
at java.base/java.lang.String.offsetByCodePoints(String.java:820)
at org.enso.text.buffer.CodePointView$Ops$.drop(CodePointView.scala:98)
at org.enso.text.buffer.CodePointView$Ops$.drop(CodePointView.scala:57)
at org.enso.text.buffer.Node.drop(Tree.scala:218)
at org.enso.text.buffer.Rope.dropWith(Rope.scala:86)
at org.enso.text.buffer.CodePointView.drop(CodePointView.scala:30)
at org.enso.text.editing.RopeTextEditor$.cutOutTail(RopeTextEditor.scala:42)
...
```
would be thrown. Further text edits would simply be rejected requiring a complete restart. I doubt we should propagate
`IndexOutOfBoundsException`. Instead it is safer to just apply the edit to the end of the rope.
* Hash codes prototype
* Remove Any.hash_code
* Improve caching of hashcode in atoms
* [WIP] Add Hash_Map type
* Implement Any.hash_code builtin for primitives and vectors
* Add some values to ValuesGenerator
* Fix example docs on Time_Zone.new
* [WIP] QuickFix for HashCodeTest before PR #3956 is merged
* Fix hash code contract in HashCodeTest
* Add times and dates values to HashCodeTest
* Fix docs
* Remove hashCodeForMetaInterop specialization
* Introduce snapshoting of HashMapBuilder
* Add unit tests for EnsoHashMap
* Remove duplicate test in Map_Spec.enso
* Hash_Map.to_vector caches result
* Hash_Map_Spec is a copy of Map_Spec
* Implement some methods in Hash_Map
* Add equalsHashMaps specialization to EqualsAnyNode
* get and insert operations are able to work with polyglot values
* Implement rest of Hash_Map API
* Add test that inserts elements with keys with same hash code
* EnsoHashMap.toDisplayString use builder storage directly
* Add separate specialization for host objects in EqualsAnyNode
* Fix specialization for host objects in EqualsAnyNode
* Add polyglot hash map tests
* EconomicMap keeps reference to EqualsNode and HashCodeNode.
Rather than passing these nodes to `get` and `insert` methods.
* HashMapTest run in polyglot context
* Fix containsKey index handling in snapshots
* Remove snapshots field from EnsoHashMapBuilder
* Prepare polyglot hash map handling.
- Hash_Map builtin methods are separate nodes
* Some bug fixes
* Remove ForeignMapWrapper.
We would have to wrap foreign maps in assignments for this to be efficient.
* Improve performance of Hash_Map.get_builtin
Also, if_nothing parameter is suspended
* Remove to_flat_vector.
Interop API requires nested vector (our previous to_vector implementation). Seems that I have misunderstood the docs the first time I read it.
- to_vector does not sort the vector by keys by default
* Fix polyglot hash maps method dispatch
* Add tests that effectively test hash code implementation.
Via hash map that behaves like a hash set.
* Remove Hashcode_Spec
* Add some polyglot tests
* Add Text.== tests for NFD normalization
* Fix NFD normalization bug in Text.java
* Improve performance of EqualsAnyNode.equalsTexts specialization
* Properly compute hash code for Atom and cache it
* Fix Text specialization in HashCodeAnyNode
* Add Hash_Map_Spec as part of all tests
* Remove HashMapTest.java
Providing all the infrastructure for all the needed Truffle nodes is no longer manageable.
* Remove rest of identityHashCode message implementations
* Replace old Map with Hash_Map
* Add some docs
* Add TruffleBoundaries
* Formatting
* Fix some tests to accept unsorted vector from Map.to_vector
* Delete Map.first and Map.last methods
* Add specialization for big integer hash
* Introduce proper HashCodeTest and EqualsTest.
- Use jUnit theories.
- Call nodes directly
* Fix some specializations for primitives in HashCodeAnyNode
* Fix host object specialization
* Remove Any.hash_code
* Fix import in Map.enso
* Update changelog
* Reformat
* Add truffle boundary to BigInteger.hashCode
* Fix performance of HashCodeTest - initialize DataPoints just once
* Fix MetaIsATest
* Fix ValuesGenerator.textual - Java's char is not Text
* Fix indent in Map_Spec.enso
* Add maps to datapoints in HashCodeTest
* Add specialization for maps in HashCodeAnyNode
* Add multiLevelAtoms to ValuesGenerator
* Provide a workaround for non-linear key inserts
* Fix specializations for double and BigInteger
* Cosmetics
* Add truffle boundaries
* Add allowInlining=true to some truffle boundaries.
Increases performance a lot.
* Increase the size of vectors, and warmup time for Vector.Distinct benchmark
* Various small performance fixes.
* Fix Geo_Spec tests to accept unsorted Map.to_vector
* Implement Map.remove
* FIx Visualization tests to accept unsorted Map.to_vector
* Treat java.util.Properties as Map
* Add truffle boundaries
* Invoke polyglot methods on java.util.Properties
* Ignore python tests if python lang is missing
The fix consists of two parts:
1. All the "review-apply" and "store temporary md" actions in the searcher controller are now guarded by an ignored transaction.
2. Because some of the temporary state may reach the UR frames assigned to other actions, added a bunch of code for removing all temporary expressions from the code and use it after restoring a frame. We may consider using it after project load as well.
### Important Notes
Added a useful method "log_err" to ResultOps (so every Result will have those).
Logging: Replace tracing with an efficient logging implementation, with 0-runtime cost for disabled log levels. (https://www.pivotaltracker.com/story/show/183755412)
Profiling: Support submitting `profiler` events to the User Timing Web API, so that measurements can be viewed directly in the browser. (https://www.pivotaltracker.com/story/show/184003550)
# Important Notes
Logging interface:
- The macros (`warn!`, etc.) now take standard `format_args!` arguments (the tracing implementations accepted a broader syntax).
- Compile-time log levels can now be set through the CLI, like so:
`./run ide start --log-level=trace --uncollapsed-log-level=info`
Profiling:
- The hotkey Ctrl+Alt+Shift+P submits all `profiler` events logged since the application was loaded to the Web API, so that they can then be viewed with the browser's developer tools. Note that standard tools are not able to represent async task lifetimes or metadata; this is a convenient interface to a subset of `profiler` data.
- As an alternative interface, a runtime flag enables continuous measurement submission. In the browser it can be set through a URL parameter, like http://localhost:8080/?emit_user_timing_measurements=true. Note that this mode significantly impacts performance.
Fixes an error when the logger processes NPE:
```
[internal-logger-error] One of the printers failed to write a message: java.lang.NullPointerException
```
Fixes https://www.pivotaltracker.com/story/show/184216698
Reduced impact of node dropdown widgets on load times by deferring creation of grid views until each widget is opened. This also improves node editing time, as the dropdowns are not recreated immediately.
This approach of lazy initialization now caused a significant lag when opening the dropdown. Two major causes of the lag spike is glyph generation (msdfgen, `new_glyph`) and shader compilation (happened every time, because each dropdown has unique layer stack). To reduce the impact of that, the shader compiler now caches the shaders based on generated shader source. Glyph creation hasn't been changed and is still slow. The startup performance is now roughly where it was before introducing widgets.
[Task link](https://www.pivotaltracker.com/story/show/184012434)
This PR implements Intermediate Representation for our documentation. Later these data structures would be used to generate HTML and CSS for the documentation panel. For now, we display it in the debug scene.
https://user-images.githubusercontent.com/6566674/210674850-480a3e6e-76c3-4f34-a235-15c44dc9ec01.mp4
# Important Notes
- `suggestion-database` now lives in a separate crate
- also, two utility crates were introduced for the `notification` and `executor` modules of enso-gui
- documentation debug scene is moved to a separate crate
- All refactorings are done in the last two commits
Implements https://www.pivotaltracker.com/n/projects/2539304/stories/184023445
Added a dropdown widget to graph node for all span tree nodes that have tag values present. When an option is selected, the controller receives a partial expression update, which targets specific crumbs of the expression (similar to how edge endpoint updates work).
https://user-images.githubusercontent.com/919491/210219931-8ae418fd-3ac4-44a5-abea-9e670f15cdf9.mp4
# Important Notes
Right now the dropdown widget is recreated every time the node is edited, including a dropdown option being selected. This causes it to close every time. I wanted to get around that by diffing span trees, but I wasn't able to do it in useful way. Additionally, current implementation of node input expression view heavily relies on being reinitialized from scratch every time. This led to more necessary changes than I was comfortable with for this task. I believe it will be easier to implement it as part of more complete widget support, especially after dynamic data support, as we will have proper widget type information.
Implements https://www.pivotaltracker.com/n/projects/2539304/stories/184023380
Dropdown component. Planned to be used in nodes as a single and multiple selection widget, both for static and dynamically loaded values. Initial support is focused on static data, with limited support for dynamic sources. Notably, loading states are not supported yet. Full support for that is planned to be added later with widget lazy-loading.
- Supports single and multiple selections.
- Dedicated API for providing a static list of all entries.
- Range-based query API for dynamically loading data as it is scrolled (only basic support - will need more work for proper async lazy-loading).
- Internal entry cache and query batching to avoid querying data one by one (the batching for now is very basic, will have to be improved for proper lazy-loading).
- Automatic dropdown width adjustment based on the entry label lengths, up to a set max allowed value.
- Open and close animation.
- Keyboard support for focusing and selecting entries.

# Important Notes
Implementing the dropdown on top of grid-view have uncovered some assumptions around grid-view layers. It was assumed to always be a part of the component browser. Removing that assumption required a mechanism for propagating camera update information through layer tree. This is now implemented using a `camera_parent` layer field. Ideally each layer should simply have at most a single parent, and camera inheritance would follow that. That refactor turned out to be quite involved, so right now the simpler temporary solution is introduced in order to not delay this PR further.
Implements `getMetaObject` and related messages from Truffle interop for Enso values and types. Turns `Meta.is_a` into builtin and re-uses the same functionality.
# Important Notes
Adds `ValueGenerator` testing infrastructure to provide unified access to special Enso values and builtin types that can be reused by other tests, not just `MetaIsATest` and `MetaObjectTest`.
This PR provides a visual indication of whether the project's current state differs from the most recent snapshot saved in the VCS. The project name displayed in the IDE changes to a darker text to indicate that the VCS snapshot is outdated, and back to a lighter text when the current project state corresponds to the last saved VCS snapshot.
https://user-images.githubusercontent.com/117099775/208088438-20dfc2aa-2a7d-47bf-bc12-3d3dff7a4974.mp4
The outdated project snapshot indicator is set when:
* A node is moved.
* A node is added or removed.
* The text editor is used to edit the text.
* The project is auto-saved, and the auto-saved project state does not correspond to the last saved snapshot in the VCS.
The outdated project snapshot indicator is cleared when:
* A new project snapshot is successfully saved using `ctrl+s`.
* The project is auto-saved, and the auto-saved project state is confirmed to correspond to the last saved snapshot in the VCS. This occurs, for example, when a project change is undone and the project is reverted to the last saved snapshot state.
The auto-save events do not occur immediately after a project change but have a short delay, thus the VCS status update is affected by the same delay when triggered by an auto-save event.
This removes the special handling of polyglot exceptions and allows matching on Java exceptions in the same way as for any other types.
`Polyglot_Error`, `Panic.catch_java` and `Panic.catch_primitive` are gone
The change mostly deals with the backslash of removing `Polyglot_Error` and two `Panic` methods.
`Panic.catch` was implemented as a builtin instead of delegating to `Panic.catch_primitive` builtin that is now gone.
This fixes https://www.pivotaltracker.com/story/show/182844611
This is an enhancement of the `Slider` component implemented in #3852. It adds the following features:
* Tooltips and precision change hints
* Selectable slider limit behaviors
* Textual slider value editing
* Vertical slider layout
#### Tooltips
An information tooltip can now be added to a slider, it is shown when the mouse hovers over the component. Additionally, a pop-up indicating the slider's precision appears when the slider's precision has been adjusted.
https://user-images.githubusercontent.com/117099775/206148098-3b4dc059-18aa-4200-9ee0-5d4382363810.mp4
#### Slider limits
The previous slider implementation clamped the adjusted value to the slider's minimum/maximum limits. Now the following behaviors are available:
* Hard limits: Clamp the value to a range within the slider's limits.
* Soft limits: The value can extend beyond the slider's limits. When this occurs, an overflow indicator will be displayed on the side of the limit that is exceeded.
* Adaptive limits: The value can extend beyond the slider's limits. When this occurs, the exceeded limit will temporarily be adjusted to double the slider's range. This will be performed iteratively until the value falls within the extended limits. When a limit is extended and the value is adjusted to fit a smaller range, the extended limit will be iteratively halved until only the necessary range is covered. The slider's extended limits will never shrink to a range smaller than the original range.
These behaviors can be set to the lower and upper limits of a slider independently.
https://user-images.githubusercontent.com/117099775/206148139-6149c91d-ef49-4e2d-97f6-71084f52591c.mp4
#### Textual editing
The slider's value can now be entered through a text input field. Double-click to edit the slider's current value. To confirm the edit press `enter`, or press `escape` to cancel the edit. If an invalid value is entered on confirmation the slider will revert to its value before the edit. The slider's precision will be adjusted based on the number of decimal places of the value entered.
https://user-images.githubusercontent.com/117099775/206148170-d3fa4c82-6e73-4b1c-9be9-cb99979f7b70.mp4
#### Vertical layout
The slider component now supports a vertical layout. In this case value adjustment is performed by a vertical mouse movement, and a horizontal movement adjusts the slider's precision. The slider's track now fills the component in a vertical direction, and the slider's label is displayed near the top end of the component.
https://user-images.githubusercontent.com/117099775/206148211-0f176aaf-bc1b-45e2-afd7-0d28391aafcb.mp4
#### Scroll bar mode
The slider component supports two indicator modes:
* `Track`: The component is filled with a colored bar from the lower limit (empty) to the upper limit (full) dependent on the slider's value.
* `Thumb`: The component contains a rounded indicator that moves along the slider from one end to the other, indicating the slider's value proportionally to the slider's limits. The width of the indicator is configurable.
In addition, the value text, text entry, and precision adjustment can be turned off to provide a scroll bar appearance when used with the `Thumb` indicator.
https://user-images.githubusercontent.com/117099775/206148261-ae291073-85e9-4082-9f91-39b65fecdc0f.mp4
#### Example scene shortcuts
The example scene contains two shortcuts in order to evaluate the dynamic addition and removal of the slider components:
* `CTRL+D` drops all the slider components that are added to the scene.
* `CTRL+A` adds a new set of example slider components to the scene.
Fixes regression https://www.pivotaltracker.com/n/projects/2539304/stories/183895961
# Important Notes
The root cause of the issue was a missing deref before `flavor()` call. The autoderef doesn't work there, because the `ShapeSystemFlavorProvider` trait is implemented for all types, including `Ref`. We should reconsider if blanket default impl is a good idea, as this is a very scary footgun.
Apart from that, the cleanup of layer elements was not handling systems with same ID but different flavors correctly. That could cause text to disappear when given layer had text of multiple fonts, and all shapes of one of them got removed. Now the element is removed from layer only when all systems sharing given system ID have no more instances to render.
* Sequence literal (Vector) should preserve warnings
When Vector was created via a sequence literal, we simply dropped any
associated any warnings associated with it.
This change propagates Warnings during the creation of the Vector.
Ideally, it would be sufficient to propagate warnings from the
individual elements to the underlying storage but doesn't go well with
`Vector.fromArray`.
* update changelog
* Array-like structures preserver warnings
Added a WarningsLibrary that exposes `hasWarnings` and `getWarnings`
messages. That way we can have a single storage that defines how to
extract warnings from an Array and the others just delegate to it.
This simplifies logic added to sequence literals to handle warnings.
* Ensure polyglot method calls are warning-free
Since warnings are no longer automatically extracted from Array-like
structures, we delay the operation until an actual polyglot method call
is performed.
Discovered a bug in `Warning.detach_selected_warnings` which was missing
any usage or tests.
* nits
* Support multi-dimensional Vectors with warnings
* Propagate warnings from case branches
* nit
* Propagate all vector warnings when reading element
Previously, accessing an element of an Array-like structure would only
return warnings of that element or of the structure itself.
Now, accessing an element also returns warnings from all its elements as
well.
This PR is a draft PR while I learn EnsoGL. The eventual goal is to implement the projects list portion of the cloud dashboard in this PR. This PR will implement part of https://www.pivotaltracker.com/n/projects/2539513/stories/183557950
### Important Notes
This PR is still really rough and contains a lot of hacks & hard-coded values. The FRP usage is also likely to be suboptimal and need fixing.
Fix issues noted here: https://github.com/enso-org/enso/pull/3678#issuecomment-1273623924
- Time complexity of an operation during line-redrawing scaled quadratically with number of lines in a change; now linear.
- Time complexity of adding `n` selections to a group was `O(n^2)`. Now it is `O(n log n)`, even if the selections are added one by one.
Also fix a subtle bug I found in `Group::newest_mut`: It returned a mutable reference that allowed breaking the *sorted* invariant of the selection group. The new implementation moves the element to invalidated space before returning a reference (internally to `LazyInvariantVec`), so that if it is mutated it will be moved to its correct location.
### Important Notes
New APIs:
- `NonEmptyVec::extend_at` supports inserting a sequence of elements at a location, with asymptotically-better performance than a series of `insert`s. (This is a subset of the functionality of `Vec::splice`, a function which we can't safely offer for `NonEmptyVec`).
- `LazyInvariantVec` supports lazily-restoring an invariant on a vector. For an invariant such as *sorted* (or in this case, *sorted and merged*), this allows asymptotically-better performance than maintaining the invariant with each mutation.
This PR fixes the `code_to_insert` method of entry to insert valid code according to the newest language version. Also created a separate method for getting imports required by given entry.
Now, method entries do not add imports (except when they are extensions), and are insterted with place for this type `_.method`. Static methods and constructors are inserted with the type name, and proper import for type is added.
There are some additional work done:
* The ReferentName and NormalizedName were removed, as we are now case-sensitive.
* All QualifiedName structures were replaced with new one in `name` module, as there is no longer functional difference between type qualified name and module qualified name.
* The QualifiedName structure removes "Main" module segment where it is not necessary, thus simplifying our code base and avoiding potential issues.
* Added macro `mock_suggestion_database` which should make creating consistent mocks of SuggestionDatabase much simpler.
* Fixed bug where the visualization preview show no value for some time.
https://user-images.githubusercontent.com/3919101/202750275-0d378d5f-1482-4637-bdcd-c428a9eac0d4.mp4
# Important Notes
The tests in controller/searcher.rs file are not of the best quality, but those will be overhauled anyway when implementing my next task.
This `Slider` component allows adjusting a numeric value with the mouse. The value is increased or decreased by clicking on the component and dragging it to the left or right.
The `Slider` has a configurable default value. `Ctrl`+clicking on the component resets its value to that default. When the value is moved away from the default, the value is printed in **bold**.
The `Slider` precision is increased or decreased by clicking the component and dragging upward or downward. This precision influences how quickly the value changes when the mouse moves horizontally, the steps in which the value is incremented or decremented, and the number of digits used to display the value. There is a margin around the component within which the precision is not changed. Beyond this margin, the precision is increased or decreased in powers of 10 (e.g. `0.1` -> `0.01` -> `0.001` when moving the mouse downwards, or `0.1` -> `1.0` -> `10.0` when moving the mouse upwards). The margin and distance between consecutive steps along the vertical axis are configurable.
The value of the `Slider` is limited to a configurable range, and cannot be adjusted beyond that range. A colored bar fills the component to indicate the current value within the range.
#### Video demonstration
https://user-images.githubusercontent.com/117099775/202244982-2f6f419d-7281-41f6-8607-7e492ad25b46.mp4
#### Future additions
This is the first iteration of the `Slider` component. Additional features are planned for the future:
* Textual editing of the value.
* Improved visual feedback on precision changes.
* Additional out-of-range behaviors.
It appears that we were always adding builtin methods to the scope of the module and the builtin type that shared the same name.
This resulted in some methods being accidentally available even though they shouldn't.
This change treats differently builtins of types and modules and introduces auto-registration feature for builtins.
By default all builtin methods are registered with a type, unless explicitly defined in the annotation property.
Builtin methods that are auto-registered do not have to be explicitly defined and are registered with the underlying type.
Registration correctly infers the right type, depending whether we deal with static or instance methods.
Builtin methods that are not auto-registered have to be explicitly defined **always**. Modules' builtin methods are the prime example.
# Important Notes
Builtins now carry information whether they are static or not (inferred from the lack of `self` parameter).
They also carry a `autoRegister` property to determine if a builtin method should be automatically registered with the type.
Libraries: Revert changes that were necessitated by a new rule we have decided not to introduce.
Parser:
- Support mixed constructors/bindings in types.
- Disallow zero-length hex sequences in character escapes: `\x`, `\u`, `\u{}`, `\U`, `\U{}` are no longer legal synonyms for `\0` (matches old parser behavior).
This change adds support for Version Controlled projects in language server.
Version Control supports operations:
- `init` - initialize VCS for a project
- `save` - commit all changes to the project in VCS
- `restore` - ability to restore project to some past `save`
- `status` - show the status of the project from VCS' perspective
- `list` - show a list of requested saves
# Important Notes
Behind the scenes, Enso's VCS uses git (or rather [jGit](https://www.eclipse.org/jgit/)) but nothing stops us from using a different implementation as long as it conforms to the establish API.
Computing length of a text takes time. Let's cache it after first computation.
# Important Notes
Wrote `StringBenchmarks` that sums lengths of (the same) `Text` present many time in a `Vector`. Initially it took `383.673 ms` per operation. Then it took `0.031 ms/op`. Looks like the `length` calls are returning instantly as they get cached.
Ensure all tokens from the input are represented in trees resulting from invalid inputs--tests now cover every reachable code line that creates an `Invalid` node. (Also implemented stricter validation, mainly of `import`/`export` statements.)
See: https://www.pivotaltracker.com/story/show/183405907
Another set of improvements extracted from #3611. This time it includes a fix to the Rust part of the parser.
# Important Notes
After digging into metadata parsing I realized the positions used to query the BTree data structure are wrong. This PR tries to address that by re-arranging the order of serialized fields and passing `startCode` and `endCode` locations in.
Originally I though I need changes on the Rust side to support `in` operator. Turned out I can do that just with changes on the Java side.
Qualified names in imports were missing UUIDs. Fixed now.
Split `HasOutputTypeLabel::output_type_label` method implementation non-generic part into a separate function. This significantly reduces compile time without risking any performance regressions. That function is currently only used for debug network visualization using graphviz, but still contributed a significant compilation time.
I've made a single attempt to profile the compiler itself, and it turned out that the compiler spent a significant amount of time trying to resolve `Pattern` implementation for closures in that method. Each of those also had to separately go through codegen and optimization. That happened for each node type in the codebase, per crate. Moving that into separate non-inline function removed all those unnecessary duplicates from. I also took this opportunity to rewrite that small piece of parsing to make it a bit cleaner.
The method of measurement is explained here: https://blog.rust-lang.org/inside-rust/2020/02/25/intro-rustc-self-profile.html
In this specific case, I've used `self-profile` to generate a profile for all crates, then used `crox` and [perfetto](https://ui.perfetto.dev/) to analyze the output.
This also shows a pattern to be aware of - using closures in generic context forces the compiler to make a separate closure type per each instantiation, even if that closure doesn't close on anything and could be a static function. This in effect forces even more instantiations or unnecessary type resolutions for all code paths that touch that closure. Using static functions or separating the non-generic part away in those cases would likely continue to help with compile times and file size.
## Comparison
The measurement was done on same machine under same environment, cleaning the build artifacts inbetween runs.
| | before | after |
|-|-|-|
|total build time|5m 5.5s|3m 59.0s|
| `ide-view-graph-editor` crate build time| 85.68s | 49.73s |
| `ide-view-component-list-panel-grid` crate build time | 49.88s | 32.07s |
| `ide-view` crate build time | 29.05s | 17.5s |
| `enso_gui.wasm` file size before wasm-opt | 83.6 MB | 80.9 MB |
| `enso_gui.wasm` file size after wasm-opt | 67.3 MB | 65.3 MB |

Make sure `libenso_parser.so`, `.dll` or `.dylib` are packaged and included when `sbt buildEngineDistribution`.
# Important Notes
There was [a discussion](https://discord.com/channels/401396655599124480/1036562819644141598) about proper location of the library. It was concluded that _"there's no functional difference between a dylib and a jar."_ and as such the library is placed in `component` folder.
Currently the old parser is still used for parsing. This PR just integrates the build system changes and makes us ready for smooth flipping of the parser in the future as part of #3611.
Wrap big and commonly copied `Application` struct into `Rc` to avoid large structure sizes for all widgets.
The `Application` struct by itself takes 704 bytes, measured by `size_of::<Application>()`. This structure is very often directly copied into components and widgets. Most notably, the generic `Widget` struct contains it. There are also cases, where structs (especially various `Model`s) contain multiple other child widgets directly, and end up indirectly copying the application multiple times.
All of `Application` clones are logical references (via `CloneRef`), so wrapping it into extra `Rc` doesn't change semantics in any way, but makes all structs that clone it way smaller. This reduces the amount of `memcpy`s and overall volume of allocated memory.
Measurement of a few example structs:
Before change:
```
size_of Application: 704 B
size_of Scrollbar: 712 B
size_of Scrollbar Model: 1576 B
```
After change:
```
size_of Application: 4 B
size_of ApplicationData: 704 B
size_of Scrollbar: 12 B
size_of Scrollbar Model: 176 B
```
Ideally we would not need to clone application reference into each component, but that's out of scope of this PR since it requires a lot more effort.
Fix bugs in `TreeToIr` (rewrite) and parser. Implement more undocumented features in parser. Emulate some old parser bugs and quirks for compatibility.
Changes in libs:
- Fix some bugs.
- Clean up some odd syntaxes that the old parser translates idiosyncratically.
- Constructors are now required to precede methods.
# Important Notes
Out of 221 files:
- 215 match the old parser
- 6 contain complex types the old parser is known not to handle correctly
So, compared to the old parser, the new parser parses 103% of files correctly.
1. Changes how we do monadic state – rather than a haskelly solution, we now have an implicit env with mutable data inside. It's better for the JVM. It also opens the possibility to have state ratained on exceptions (previously not possible) – both can now be implemented.
2. Introduces permission check system for IO actions.
Fixes https://www.pivotaltracker.com/story/show/182926584
[Task link](https://www.pivotaltracker.com/story/show/183426449)
This PR fixes an IDE freeze introduced by https://github.com/enso-org/enso/pull/3732 and reimplements reverting edited nodes to their previous state.
The cause of the IDE freeze is quite interesting. A detailed investigation is available [here](https://gist.github.com/vitvakatu/785e34881368b8cfda61715d7543cbd0).
The graph editor needs to update the Presenter state only if the user is editing the node. Before this PR, the graph editor notified the Presenter with a visual representation of the node content instead of code expression. It caused inconsistency between the states of the controller and Presenter and caused severe performance issues.
https://user-images.githubusercontent.com/6566674/195831224-6d6e8258-e347-48b4-890a-d89c7300bc39.mp4
# Important Notes
- ~~There is a more complex alternative solution – it requires refactoring of the `component::node::input::area` module. The Presenter can be notified with `expression.code` changes, not `expression.viz_code`. I found a simpler solution (`.gate(&edit_mode)`), which has the same effect but does not require additional refactoring.~~ Said solution is implemented in a separate commit
We've had an old attempt at integrating a Rust parser with our Scala/Java projects. It seems to have been abandoned and is not used anywhere - it is also superseded by the new integration of the Rust parser. I think it was used as an experiment to see how to approach such an integration.
Since it is not used anymore - it make sense to remove it, because it only adds some (slight, but non-zero) maintenance effort. We can always bring it back from git history if necessary.
When hovering the mouse pointer over the Marketplace button on the left bar of the Component Browser, show a caption informing that the Marketplace will be available soon.
https://www.pivotaltracker.com/story/show/182613789
#### Visuals
The video below demonstrates the caption shown when hovering the Marketplace button on the left bar of the Component Browser. It shows the caption disappearing after a hardcoded time, or when the mouse pointer is moved away from the button.
https://user-images.githubusercontent.com/273837/196195809-45a712e1-ad86-47d8-99ff-1475a0b74c6e.mov
# Important Notes
- The "Label" visual component was fixed. Previously, the width calculation of the background was not synchronized correctly with the text width. As a result, a zero-width background was displayed when a Label was shown for the first time.
There is one place in code, where we can potentially panic on double borrow, because the drop routine is done while having data borrowed.
# Important Notes
The issue was easily reproducible on @Frizi machine.
Another part of #3611 ready for integration into `develop` branch.
# Important Notes
Test `org.enso.compiler.EnsoCompilerTest.testTestGroup` is ignored as it has problems with source offsets - identifiers don't have the appropriate names due to `Tree.codeRepr()` being _off_.
- Special precedence rules for case-of so that `:` operator works without parens or nospace-grouping.
- Support an old-lambda syntax: `x->x-> x`. According to the usual rules, the first nospace group would be parsed as an operator section. The expression now parses as a lambda that contains a lambda.
- Match old parser treatment of # in doc comments.
- Tweak precedence so (a : B = c) works.
- Documented constructors.
- Reimplement the `Duration` type to a built-in type.
- `Duration` is an interop type.
- Allow Enso method dispatch on `Duration` interop coming from different languages.
# Important Notes
- The older `Duration` type should now be split into new `Duration` builtin type and a `Period` type.
- This PR does not implement `Period` type, so all the `Period`-related functionality is currently not working, e.g., `Date - Period`.
- This PR removes `Integer.milliseconds`, `Integer.seconds`, ..., `Integer.years` extension methods.
This PR introduced an overhauled Component List Panel implementation, making use of the efficient EnsoGL grid view component. Also, it delivers a couple of new features:
* A part of the new design: there are no more section headers in grid, instead groups are "glued" together. The local scope section is under "popular" (old "favorites").
* The keyboard management inside grid works.
* there is a mouse hover highlight
* selecting the lowest entry in section when jumping with navigation bar.
* accepting input as-is with cmd/ctrl + Enter.
https://user-images.githubusercontent.com/3919101/194561890-fffb9b41-2f0d-4357-8d9a-5038a6bcb023.mp4
### Important Notes
**What is not implemented:**
* [Focus management between panels.](https://www.pivotaltracker.com/story/show/180872763) The grid is always focused. To accept the current input, use ctrl+Enter shortcut.
* [Proper handling of selection when having empty space on the right and pressing right arrow.](https://www.pivotaltracker.com/story/show/183487880)
* When entering a module, its name is not added to the input as described in the design doc. Will be a part of [this User Story](https://www.pivotaltracker.com/story/show/181058321).
**Known issues**
* [the selection, especially in the local scope section, has sometimes an undesirable offset](https://www.pivotaltracker.com/story/show/183487730). The cause is known, but not so easy to fix.
* The inserted nodes are often producing errors. The Browser's inherits the outdated understanding of the language from old Node Searcher, and it does not include new form of imports, static methods etc. Those all will be fixed as a part of [this User Story](https://www.pivotaltracker.com/story/show/181058321).
* The performance is improved, but still not ideal, due to problems in [text areas](https://www.pivotaltracker.com/story/show/183406745).
* To scroll the documentation panel, you must first click on it.
- Implement macro-contexts-lite (`from` is now only a keyword at the beginning of a line)
- Support special nospace-group handling for old lambdas (so expressions like this work: `x-> y-> x + y`)
- Fix a text-escape incompatibility
# Important Notes
- There is now an `OperatorFunction`, which is like a `Function` but has an operator for a name, and likewise an `OperatorTypeSignature`.
[ci no changelog needed]
[Task link](https://www.pivotaltracker.com/story/show/182675703)
This PR implements the actual integration of the breadcrumbs panel with the component list panel. A special breadcrumbs controller (`controller::searcher::breadcrumbs`) is tracking the currently opened module with a list of its parents. The searcher presenter uses the API of the controller to sync the displayed list of breadcrumbs with the controller state.
https://user-images.githubusercontent.com/6566674/193064122-7d3fc4d6-9148-4ded-a73e-767ac9ac83f8.mp4
# Important Notes
- There is an `All` breadcrumb displayed at all times at the beginning of the list. It will be replaced with a section name as part of [Section Title on Component Browser's Breadcrumbs Panel](https://www.pivotaltracker.com/story/show/182610561) task.
- I changed the implementation of `project::main_module_id`, `project::QualifiedName::main_module`, and `API::main_module` so that they are logically connected which each other.
- I adjusted the Breadcrumbs View to avoid "appearance" animation glitches when opening new modules. `set_entries` was replaced with the `set_entries_from` endpoint.
When running the profiling run-graph and flamegraph demo scenes, if a profile file is not found in the directory served over http, fall back to generating demo data.
This PR disables the wasm-opt optimization in the crates that can be used as WASM entry points. Unfortunately, wasm-pack does not allow for disabling wasm-opt through a command line flag, so we have to disable it by setting an appropriate flag in each Cargo.toml.
Use an `ArraySlice` to slice `Vector`.
Avoids memory copying for the slice function.
# Important Notes
| Test | Ref | New |
| --- | --- | --- |
| New Vector | 71.9 | 71.0 |
| Append Single | 26.0 | 27.7 |
| Append Large | 15.1 | 14.9 |
| Sum | 156.4 | 165.8 |
| Drop First 20 and Sum | 171.2 | 165.3 |
| Drop Last 20 and Sum | 170.7 | 163.0 |
| Filter | 76.9 | 76.9 |
| Filter With Index | 166.3 | 168.3 |
| Partition | 278.5 | 273.8 |
| Partition With Index | 392.0 | 393.7 |
| Each | 101.9 | 102.7 |
- Note: the performance of New and Append has got slower from previous tests.
This PR adds a possibility to generate native-image for engine-runner.
Note that due to on-demand loading of stdlib, programs that make use of it are currently not yet supported
(that will be resolved at a later point).
The purpose of this PR is only to make sure that we can generate a bare minimum runner because due to lack TruffleBoundaries or misconfiguration in reflection config, this can get broken very easily.
To generate a native image simply execute:
```
sbt> engine-runner-native/buildNativeImage
... (wait a few minutes)
```
The executable is called `runner` and can be tested via a simple test that is in the resources. To illustrate the benefits
see the timings difference between the non-native and native one:
```
>time built-distribution/enso-engine-0.0.0-dev-linux-amd64/enso-0.0.0-dev/bin/enso --no-ir-caches --in-project test/Tests/ --run engine/runner-native/src/test/resources/Factorial.enso 6
720
real 0m4.503s
user 0m9.248s
sys 0m1.494s
> time ./runner --run engine/runner-native/src/test/resources/Factorial.enso 6
720
real 0m0.176s
user 0m0.042s
sys 0m0.038s
```
# Important Notes
Notice that due to a [bug in GraalVM](https://github.com/oracle/graal/issues/4200), which is already fixed in 22.x, and us still being on 21.x for the time being, I had to add a workaround to our sbt build to build a different fat jar for native image. To workaround it I had to exclude sqlite jar. Hence native image task is on `engine-runner-native` and not on `engine-runner`.
Will need to add the above command to CI.
When a GridView is navigated using the keyboard, scroll it to display the newly selected entry.
https://www.pivotaltracker.com/story/show/182593635
#### Visuals
See below for a video demonstrating automatic scrolling of the GridView when arrow keys are pressed on the keyboard. The first video below shows the default scrolling behavior in a GridView without headers.
Note:
- When the Grid View is scrolled, the mouse hover highlight moves away from the mouse position. This is not a new regression, the behavior is the same in the `develop` branch (e.g. when scrolling using the mouse).
https://user-images.githubusercontent.com/273837/190183984-91f7808c-3606-43f8-bcda-ac4d5f84e00f.mov
The video below shows the behavior in a GridView with headers when the GridView is first scrolled to its top-left corner. The following guidance from the Design Doc is enabled and showcased:
> Users can change the selected component by pressing the arrow keys. The Focus does not move up if it does not have to (in most cases, the focus is located in the second row from the bottom). Instead, the component list scrolls down if there are enough entries.
https://user-images.githubusercontent.com/273837/189151546-e50aaf22-6f4d-41cb-809f-60038305745f.mov
The next video shows the behavior in the same GridView as in the previous example when the GridView is first scrolled away from any of its boundary entries. Notably, scrolling happens only when the selection is moved using the keyboard arrow keys, not when changing the selection using the mouse. This behavior is based on a discussion with @wdanilo on Discord.
https://user-images.githubusercontent.com/273837/189151974-d992be93-f61f-4e9f-9f4c-dfe260bbec5b.mov
This PR contains an entry definition for Grid View to be used inside Component List Panel View. The Example grid view with the entry definition may be seen on new_component_list_panel_view debug scene.
https://user-images.githubusercontent.com/3919101/190663278-23c35ab0-f426-4001-8128-df7147aafb9e.mp4
# Important Notes
* The styling is not detailed yet due to time constraints (I want to move to integration this grid view to Component Panel List ASAP) and the fact that I could not get new mplus1 font working with text Area.
* Implementing this required adding a "contour offset" feature to the Grid View.
[ci no changelog needed]
[Task link](https://www.pivotaltracker.com/story/show/181445628).
This PR implements a Breadcrumbs panel for the new component browser.
The Breadcrumbs is a horizontal list of text labels separated by a special icon and has an optional ellipsis icon at the end.
It is implemented using the new GridView component.
Video:
Demo of adding new breadcrumbs, scrolling behavior, and selecting breadcrumbs with the mouse.
https://user-images.githubusercontent.com/6566674/189199432-77807cef-00dc-4abe-b95c-b17a536f59f6.mp4
Demo of selecting breadcrumbs with keyboard shortcuts:
https://user-images.githubusercontent.com/6566674/189199603-53e55335-73ba-4ed7-8291-4455144c06aa.mp4
# Important Notes
- This PR implements an old interaction of the design of the component browser. The new design of the breadcrumbs can not be easily integrated into the current look of the component browser, so we would need to update styles later. It should be a relatively simple task. *The implementation uses color from the new design though. (but not fonts and sizes)*
- I found a bug in the grid view implementation that causes panics at runtime in some conditions. The reason is triggering FRP endpoints while constructing new entries. This issue is fixed in the PR.
Add support for moving the selection in a Grid View using the keyboard.
https://www.pivotaltracker.com/story/show/182585789
#### Visuals
See below for videos showcasing GridView selection keyboard navigation in the `grid_view` debug scene. In the videos, messages in the Developer Console can be observed. When a keypress would result in the selection being moved out of the GridView, the selection is not moved and a message is emitted in the Developer Console instead, showcasing an FRP output signal emitted on such event. Please note that the videos are recorded with the tracing level changed to `DEBUG`. In a default build, the tracing level is set to `WARN`, and the messages visible in the videos are not displayed in the Developer Console.
https://user-images.githubusercontent.com/273837/188483972-89d79f7b-1303-457b-869f-282e0809a755.movhttps://user-images.githubusercontent.com/273837/188484294-e9b6461c-a84f-4817-9447-d792f2ebdbb5.mov
The following video shows moving the selection between "regular" entries and header entries. It also shows a current usability limitation of the selection keyboard navigation feature, such that the Grid is not scrolled when the selection leaves the visible part of the Grid, and the selection may thus disappear from view.
https://user-images.githubusercontent.com/273837/188485238-29a82b27-de2f-4cf8-a2e7-ff8c3f41478d.mov
# Important Notes
- Keyboard navigation only works when a GridView has focus.
- Selection keyboard navigation only works if the selection was already set to some entry beforehand.
- If keyboard navigation would move selection outside of the grid, the selection movement is canceled and an FRP event is emitted.
`Vector` type is now a builtin type. This requires a bunch of additional builtin methods for its creation:
- Use `Vector.from_array` to convert any array-like structure into a `Vector` [by copy](f628b28f5f)
- Use (already existing) `Vector.from_polyglot_array` to convert any array-like structure into a `Vector` **without** copying
- Use (already existing) `Vector.fill 1 item` to create a singleton `Vector`
Additional, for pattern matching purposes, we had to implement a `VectorBranchNode`. Use following to match on `x` being an instance of `Vector` type:
```
import Standard.Base.Data.Vector
size = case x of
Vector.Vector -> x.length
_ -> 0
```
Finally, `VectorLiterals` pass that transforms `[1,2,3]` to (roughly)
```
a1 = 1
a2 = 2
a3 = 3
Vector (Array (a1,a2, a3))
```
had to be modified to generate
```
a1 = 1
a2 = 2
a3 = 3
Vector.from_array (Array (a1, a2, a3))
```
instead to accomodate to the API changes. As of 025acaa676 all the known CI checks passes. Let's start the review.
# Important Notes
Matching in `case` statement is currently done via `Vector_Data`. Use:
```
case x of
Vector.Vector_Data -> True
```
until a better alternative is found.
Parse text literals. See: https://www.pivotaltracker.com/story/show/182496940
# Important Notes
- The left-trimming algorithm (https://github.com/enso-org/design/blob/wip/wd/enso-spec/epics/enso-spec-1.0/04.%20Expressions.md#inline-and-block-text-literals) requires two passes over the sequence of text segments. This implementation performs one pass while parsing (identifying the correct amount of trim). The other pass (applying the trim) can be done when building the value of the quoted string: Trim the amount of whitespace identified by the `trim` field off of the whitespace of each `TextSection` (the value will not exceed the amount of whitespace found in the tokens' offsets, except for tokens with 0 offset, in which case no trimming is necessary/possible).
Implements:
- UUIDs: https://www.pivotaltracker.com/story/show/182931137
- Comments: https://www.pivotaltracker.com/story/show/182981779
- Type annotations and signatures: https://www.pivotaltracker.com/story/show/182497454
- Fix getter names (https://github.com/enso-org/enso/pull/3627#discussion_r940887460).
# Important Notes
- I can't fully test UUIDs; I have tested that the data obtained in Rust matches my understanding of how the format is supposed to work. What remains to be tested is that the data in Java matches the way the old parser handles the format. So @JaroslavTulach, let me know if you see any cases where I'm not returning the same values.
- This implementation of type annotations and signatures accepts any expression in type context. It would probably be nice to narrow this down at some point, but for now I have no design info on what specifically should be allowed in type expressions; this implementation should be at least an incremental improvement.
This is a step towards the new language spec. The `type` keyword now means something. So we now have
```
type Maybe a
Some (from_some : a)
None
```
as a thing one may write. Also `Some` and `None` are not standalone types now – only `Maybe` is.
This halfway to static methods – we still allow for things like `Number + Number` for backwards compatibility. It will disappear in the next PR.
The concept of a type is now used for method dispatch – with great impact on interpreter code density.
Some APIs in the STDLIB may require re-thinking. I take this is going to be up to the libraries team – some choices are not as good with a semantically different language. I've strived to update stdlib with minimal changes – to make sure it still works as it did.
It is worth mentioning the conflicting constructor name convention I've used: if `Foo` only has one constructor, previously named `Foo`, we now have:
```
type Foo
Foo_Data f1 f2 f3
```
This is now necessary, because we still don't have proper statics. When they arrive, this can be changed (quite easily, with SED) to use them, and figure out the actual convention then.
I have also reworked large parts of the builtins system, because it did not work at all with the new concepts.
It also exposes the type variants in SuggestionBuilder, that was the original tiny PR this was based on.
PS I'm so sorry for the size of this. No idea how this could have been smaller. It's a breaking language change after all.
- Added `Zone`, `Date_Time` and `Time_Of_Day` to `Standard.Base`.
- Renamed `Zone` to `Time_Zone`.
- Added `century`.
- Added `is_leap_year`.
- Added `length_of_year`.
- Added `length_of_month`.
- Added `quarter`.
- Added `day_of_year`.
- Added `Day_Of_Week` type and `day_of_week` function.
- Updated `week_of_year` to support ISO.
# Important Notes
- Had to pass locale to formatter for date/time tests to work on my PC.
- Changed default of `week_of_year` to use ISO.
* Builtin Date_Time, Time_Of_Day, Zone
Improved polyglot support for Date_Time (formerly Time), Time_Of_Day and
Zone. This follows the pattern introduced for Enso Date.
Minor caveat - in tests for Date, had to bend a lot for JS Date to pass.
This is because JS Date is not really only a Date, but also a Time and
Timezone, previously we just didn't consider the latter.
Also, JS Date does not deal well with setting timezones so the trick I
used is to first call foreign function returning a polyglot JS Date,
which is converted to ZonedDateTime and only then set the correct
timezone. That way none of the existing tests had to be changes or
special cased.
Additionally, JS deals with milliseconds rather than nanoseconds so
there is loss in precision, as noted in Time_Spec.
* Add tests for Java's LocalTime
* changelog
* Make date formatters in table happy
* PR review, add more tests for zone
* More tests and fixed a bug in column reader
Column reader didn't take into account timezone but that was a mistake
since then it wouldn't map to Enso's Date_Time.
Added tests that check it now.
* remove redundant conversion
* Update distribution/lib/Standard/Base/0.0.0-dev/src/Data/Time.enso
Co-authored-by: Radosław Waśko <radoslaw.wasko@enso.org>
* First round of addressing PR review
* don't leak java exceptions in Zone
* Move Date_Time to top-level module
* PR review
Co-authored-by: Radosław Waśko <radoslaw.wasko@enso.org>
Co-authored-by: Jaroslav Tulach <jaroslav.tulach@enso.org>
[ci no changelog needed]
[Task link](https://www.pivotaltracker.com/story/show/182955595)
This PR implements variable column widths in the new Grid View component. We need this feature to quickly implement various parts of the UI, including the breadcrumbs panel of the component browser.
There are two ways to change the width of the specific column:
1. "From the outside", using the `set_column_width` endpoint of the Grid View
2. "From the inside", using the `override_column_width` endpoint of the EntryFrp.
Both ways work similarly, but the latter is helpful for our breadcrumbs implementation, as it allows for entry to decide on the width of the column by its content.
See the screencast with three grid views. The top-left one has every even column shrunk by GridView API. Every grid view has a second column extended by EntryFrp API.
https://user-images.githubusercontent.com/6566674/185060985-7b7df076-c659-41fa-977a-22875493f8d4.mp4
[ci no changelog needed]
[Task link](https://www.pivotaltracker.com/story/show/181870555)
This PR changes the relative position of the edited node in such a way that it is left-aligned to the component browser window. This change reflects the most recent version of the [design doc](https://github.com/enso-org/design/blob/main/epics/component-browser/design.md#overview)
<img width="1157" alt="Screenshot 2022-08-08 at 19 15 47" src="https://user-images.githubusercontent.com/6566674/183454192-81960e0a-ab69-43a4-b7df-d13320a9d16d.png">
As an additional change, the FRP implementation of the `Camera2d` was extended with a new output (screen dimensions) and fixed. With the old implementation, there was a possibility of panic at runtime because of non-exclusive borrows of `RefCell`. The FRP event for camera position was emited inside the scope with a mutable `RefCell` borrow. Any attempt to borrow the camera one more time (e.g., by calling one of the getters, such as `zoom()`) caused panic at runtime.
Importing individual methods didn't work as advertised because parser
would allow them but later drop that information. This slipped by because we never had mixed atoms and methods in stdlib.
# Important Notes
Added some basic tests but we need to ensure that the new parser allows for this.
@jdunkerley will be adding some changes to stdlib that will be testing this functionality as well.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}