When building the dev IDE version with `./run ide build`, it creates the engine distribution with version `2023.2.1-dev`. This causes the version check to fail preventing opening the projects.
- Closes#6730
- Changes config to allow environment variables to override server host and port
- Adds port scanning to Electron app to ensure the PM is started at a free port
# Important Notes
- `SERVER_PORT=abcd enso.AppImage` does NOT work. It would not be difficult to implement, but it probably needs discussion on how exactly it should be implemented - for example, `SERVER_PORT` is quite a generic name, should the Electron app pass though something like `ENSO_PM_SERVER_PORT` to the PM as `SERVER_PORT` instead?
⚠️ Port scanning is *only* implemented in the JS frontend. It is not implemented:
- In Scala, because the JS/Rust code calling it needs to know the port as well. There shouldn't be any problems with adding port scanning though, if that's desired
- In Rust, because I'm not sure parsing the host and port from a string is a good idea.
- (This also applies to JS, but it *must* work in JS, and port scanning is already a dependency there so it's quite a bit easier)
- QA *will* need a new PM (`sbt buildProjectManagerDistribution` or `./run backend sbt` -> `buildProjectManagerDistribution`), and the path must be supplied as: `-engine.project-manager-path=path/to/new/pm/here`
Looks like that
```
[info] [2023-08-23T13:12:58.119Z] [org.enso.projectmanager.boot.ProjectManager$] Starting Enso Project Manager
Version: 0.0.0-dev
Built with: scala-2.13.11 for GraalVM 17.0.7
Built from: wip/db/fix-dev-version-check* @ 52bc6b8fcf
Built on: Linux (amd64)
```
close#7604
After moving the rename action to the dashboard, IDE is unaware of the new project name. PR implements a new `refactoring/projectRenamed` notification that is sent from the server to clients and informs them about the changed project name.
# Important Notes
https://github.com/enso-org/enso/assets/357683/7c62726d-217e-4e69-8e48-568e0b7b8c34
This was meant to be a trivial change, but actually a dirty workaround needed to be applied. Because enter is used to both open searcher and accept input/entry, both actions were fired at once. I fixed it by debouncing opening searcher event (so the searcher will be opened only once key event handling is over)
MethodProcessor generates code for builtin method invocation that is wrapped in `try-catch` and handles some predefined subset of `RuntimeException`. So far, only `com.oracle.truffle.dsl.api.UnsupportedSpecializationException`.
# Important Notes
#### The Plot
- there used to be two kinds of benchmarks: in Java and in Enso
- those in Java got quite a good treatment
- there even are results updated daily: https://enso-org.github.io/engine-benchmark-results/
- the benchmarks written in Enso used to be 2nd class citizen
#### The Revelation
This PR has the potential to fix it all!
- It designs new [Bench API](88fd6fb988) ready for non-batch execution
- It allows for _single benchmark in a dedicated JVM_ execution
- It provides a simple way to wrap such an Enso benchmark as a Java benchmark
- thus the results of Enso and Java benchmarks are [now unified](https://github.com/enso-org/enso/pull/7101#discussion_r1257504440)
Long live _single benchmarking infrastructure for Java and Enso_!
- Closes#5951
- Ensures any SQL warnings reported by the database through the JDBC driver are processed and forwarded to the user.
- These warnings show issues like the implicit name truncation that this PR is also solving. It's good to make sure they are visible as they can help avoid and understand unexpected problems. They should not show up in most standard workflows.
- Adds simple history to our REPL.
We can't really control the timing of file watcher events, which sometimes leads to failures of VCS tests. The PR disables the file watcher in the `VcsManagerTest` suite to make tests more stable.
Changelog:
- add: a `Watcher` and `WatcherFactory` interfaces
- add: a `NoopWatcher` test watcher
- update: disable the file watcher in the `VcsManagerTest` suite
close#7345#7254 introduced a delayed shutdown timeout. The `LanguageServerGateway` timeout should include the delayed shutdown time to prevent false timeouts.
Follow-up of recent GraalVM update #7176 that fixes downloading of GraalVM for Mac - instead of "darwin", the releases are now named "macos"
# Important Notes
Also re-enables the JDK/GraalVM version check as onLoad hook to the `sbt` process. We used to have that check a long time ago. Provides errors like this one if the `sbt` is run with a different JVM version:
```
[error] GraalVM version mismatch - you are running Oracle GraalVM 20.0.1+9.1 but GraalVM 17.0.7 is expected.
[error] GraalVM version check failed.
```
- Previous GraalVM update: https://github.com/enso-org/enso/pull/6750
Removed warnings:
- Remove deprecated `ConditionProfile.createCountingProfile()`.
- Add `@Shared` to some `@Cached` parameters (Truffle now emits warnings about potential `@Share` usage).
- Specialization method names should not start with execute
- Add limit attribute to some specialization methods
- Add `@NeverDefault` for some cached initializer expressions
- Add `@Idempotent` or `@NonIdempotent` where appropriate
BigInteger and potential Node inlining are tracked in follow-up issues.
# Important Notes
For `SDKMan` users:
```
sdk install java 17.0.7-graalce
sdk use java 17.0.7-graalce
```
For other users - download link can be found at https://github.com/graalvm/graalvm-ce-builds/releases/tag/jdk-17.0.7
Release notes: https://www.graalvm.org/release-notes/JDK_17/
R component was dropped from the release 23.0.0, only `python` is available to install via `gu install python`.
* Delay LS shutdown when last client disconnects
Rather than closing Language Server immediately, we delay the shutdown
until some timeout hits. This gives a chance for new clients to connect
without paying the price of the initialization again.
More importantly, during hibernation/restart, the connection between
client (IDE) and LS is severed so it appears as if client disconnect. In
fact a few moments later IDE would attempt to re-establish the
connection on the same port. Without this change, LS shutsdown and
further attempts to connect on that particular port will fail.
There are still problems on the IDE-side after waking up from
hibernation but it is not related to Language Server.
* Introduce a separate timeout for delayed shutdown
Can't/shouldn't use the same timeout value as for shutdown timeout for
delaying shutdowns initiated by lack of clients.
* Add test demonstrating the new functionality
The current instructions to _build, use and debug_ `project-manager` and its engine/ls process are complicated and require a lot of symlinks to properly point to each other. This pull requests simplifies all of that by introduction of `ENSO_ENGINE_PATH` and `ENSO_JVM_PATH` environment variables. Then it hides all the complexity behind a simple _sbt command_: `runProjectManagerDistribution --debug`.
# Important Notes
I decided to tackle this problem as I have three repositories with different branches of Enso and switching between them requires me to mangle the symlinks. I hope I will not need to do that anymore with the introduction of the `runProjectManagerDistribution` command.
This PR modifies the builtin method processor such that it forbids arrays of non-primitive and non-guest objects in builtin methods. And provides a proper implementation for the builtin methods in `EnsoFile`.
- Remove last `to_array` calls from `File.enso`
close#7194
Changelog:
- add: `/projects/{project_id}/enso_project` HTTP endpoint returning an `.enso-project` archive structure
- update: archive enso project to a `.enso-project` `.tar.gz` archive
- update: make project `path` a required field
part of #7178
Changelog:
- add: `text/fileModifiedOnDisk` notification
- update: during the auto-save, check if the file is modified on disk and send the notification. I.e. auto-save does not overwrite the file if it was changed on disk (but the save command does)
- update: IDE handles the file-modified-on-disk notification and reloads the module from disk
# Important Notes
Currently, the auto-save (and the check that the file is modified on disk) is triggered only after the file was edited. The proper check (using the file-watcher service) will be added in the next PR
https://github.com/enso-org/enso/assets/357683/ff91f3e6-2f7a-4c01-a745-98cb140e1964
As discovered in #7224, Json RPC protocol was added to the asynchronous resource initialization stage, as part of #6306, but was not in fact initialized at that point.
Instead it was initialized when the server was started to be able to serve correctly the initialization messages. A classic Catch-22. It was really hard to discover this just by looking at the code, but the profiling clearly showed where the time was spent.
This change splits Language Server's protocol into two:
- the first one accepts `heartbeat/init` and `session/initProtocolConnection`
- the second one enriches it with the full set of supported messages
This shifts the initialization from blocking for 0.5 sec to only ~30ms, and performing the second stage asynchronously.
Closes#7224.
# Important Notes
Before the change (blocking server startup):


After the change (1st stage):

After the change (2nd, asynchronous initialization, stage):

It is relatively easy to reach timeouts on weak systems for startup
operations on project manager. Once a timeout is reached, startup will
not proceed any further.
This PR is a bit of an experiment. It adds adds timeout retries to give a bit of a leeway to
under-powered machines and to log some progress on the way, so that we
know that certain actions are still in progress.
Package's config information, once loaded, never changed. While there is typically no need for it, this was problematic when the config became out-of-sync with the filesystem, like in the case of project rename action.
In rename, the config's properties would be updated in the FS, but that would never be reflected in module's package. Therefore further compilations would continue to ask for the old namespace.
Most of the changes are cosmetic (s/`.config`/`.getConfig()`) except for the new `reloadConfig` method on `Package` that is being called in `RenameProjectCmd` handler.
Closes#7062.
# Important Notes
The reported `ExecutionFailed` error should have been mostly fixed already via #7143. This change makes sure that all the related warnings are gone as well and the compiler uses the updated namespace.
The change adds logic that will attempt a few retries when executing `gu` (GraalVM updater) commands. Previously, if it failed, it failed. Retries should help with the most common case - occassional network hiccups.
Closes#6880.
# Important Notes
Note that I don't use an external library for retries on purpose. Didn't want to introduce a yet another dependency for this tiny functionality.
- Add type detection for `Mixed` columns when calling column functions.
- Excel uses column name for missing headers.
- Add aliases for parse functions on text.
- Adjust `Date`, `Time_Of_Day` and `Date_Time` parse functions to not take `Nothing` anymore and provide dropdowns.
- Removed built-in parses.
- All support Locale.
- Add support for missing day or year for parsing a Date.
- All will trim values automatically.
- Added ability to list AWS profiles.
- Added ability to list S3 buckets.
- Workaround for Table.aggregate so default item added works.
close#6936
Changelog:
- add: new suggestion type Getter that is not exposed to the api
- update: do not return suggestion of type getter when doing a global search (without specifying self types)
Private suggestions and modules mentioned in the issue will be filtered out after we finish the work on the new (refined) exports algorithm.
# Important Notes

Empty edition (null value) was parsed as NaN, which was confusing. This change correctly detects the case before trying different fallback mechanisms.
Addresses invalid warning mentioned in #6806.
Fixes#6787
# Important Notes
I can't get Project Manager compilation to work locally so I guess I'll be relying on CI to verify that it's working correctly?
Of course, QA should be able to catch any problems too - the websocket API hasn't been changed so it should work out of the box with the current dashboard.
This change fixes the rather elusive bug where shutdown hooks could not be fired when shutdown was taking too long and termination was forced.
Under the circumstances described in detail in ticket #6515 there was a small chance that we could have a shutdown race condition. Essentially the messages received when client was disconnected and language server forced the termination could lead to language server not sending the public `ProjectClosed` message which triggers shutdown hook. Now we always do.
Also made sure that multiple `ProjectClosed` messages don't lead to firing multiple shutdown hooks, which was another possibility.
No tests as one would have to be able to introduce different delays in various message handlers to simulate the problem.
Having ability to do such chaos testing would be nice but it is beyond the scope of this ticket.
I was able to reproduce the problem 100% with my specially crafted setup so I'm fairly confident about the change.
Closes#6515.
close#6611
Changelog:
- update: run compiler passes on the `ascribedType` field of the constructor arguments
- update: suggestion builder uses the type information attached to `ascribedType`
- feat: resolve qualified names in type signatures
Fixes#6609 by
- e380e647af - running whole `Vector_Spec` on `java.util.ArrayList`
- 9b1229fe20 - introducing a node to handle interop values
# Important Notes
Contains additional DSL processor fix:
- 415623dcb9 - to not crash the compiler, but to properly report compiler error
Artifically limiting the number of reported warnings to 100. Also added benchmarks with random Ints to investigate perf issues when dealing with warnings (future task).
Ideally we would have a custom set-like collection that allows us internally to specify a maximal number of elements. But `EnsoHashMap` (and potentially `EnsoSet`) are still WIP when it comes to being PE-friendly.
The change also allows for checking if the limit for the number of reported warnings has been reached. It will visualize by adding an additional "Warnings limit reached." to the visualization.
The limit is configurable via `--warnings-limit` parameter to `run`.
Closes#6283.
Remove the magical code generation of `enso_project` method from codegen phase and reimplement it as a proper builtin method.
The old behavior of `enso_project` was special, and violated the language semantics (regarding the `self` argument):
- It was implicitly declared in every module, so it could be called without a self argument.
- It can be called with explicit module as self argument, e.g. `Base.enso_project`, or `Visualizations.enso_project`.
Let's avoid implicit methods on modules and let's be explicit. Let's reimplement the `enso_project` as a builtin method. To comply with the language semantics, we will have to change the signature a bit:
- `enso_project` is a static method in the `Standard.Base.Meta.Enso_Project` module.
- It takes an optional `project` argument (instead of taking it as an explicit self argument).
Having the `enso_project` defined as a (shadowed) builtin method, we will automatically have suggestions created for it.
# Important Notes
- Truffle nodes are no longer generated in codegen phase for the `enso_project` method. It is a standard builtin now.
- The minimal import to use `enso_project` is now `from Standard.Base.Meta.Enso_Project import enso_project`.
- Tested implicitly by `org.enso.compiler.ExecCompilerTest#testInvalidEnsoProjectRef`.
Dead Letter logging is occasionally flooding our logs which is confusing to users reporting bugs. Left the possibility of a single report so that we know that something is happening.
Fixes#6416 by introducing `InlineableNode`. It runs fast even on GraalVM CE, fixes ([forever broken](https://github.com/enso-org/enso/pull/6442#discussion_r1178782635)) `Debug.eval` with `<|` and [removes discouraged subclassing](https://github.com/enso-org/enso/pull/6442#discussion_r1178778968) of `DirectCallNode`. Introduces `@BuiltinMethod.needsFrame` - something that was requested by #6293. Just in this PR the attribute is optional - its implicit value continues to be derived from `VirtualFrame` presence/absence in the builtin method argument list. A lot of methods had to be modified to pass the `VirtualFrame` parameter along to propagate it where needed.
close#6254
Changelog:
- fix: race when the actor system may be stopped before the shutdown hooks are executed
- fix: project management spec
- fix: recover from `readLine` failure during the shutdown
* Don't propagate warnings on suspended arguments
In the current implementation, application of arguments with warnings
first extracts warnings, does the application and appends the warnings
to the result.
This process was however too eager if the suspended argument was a
literal (we don't know if it will be executed after all).
The change modifies method processor to take into account the
`@Suspend` annotation and not gather warnings before the application
takes place.
* PR review
close#6232
Changelog:
- remove: `SqlVersionsRepo`
- update: `SuggestionsDatabaseModuleUpdateNotification` message removing the version
- update: cleanup versions repo usages in the language server
close#6080
Changelog
- add: implement `SuggestionsRepo.insertAll` as a batch SQL insert
- update: `search/getSuggestionsDatabase` returns empty suggestions. Currently, the method is only used at startup and returns the empty response anyway because the libs are not loaded at that point.
- update: serialize only global (defined in the module scope) suggestions during the distribution building. There's no sense in storing the local library suggestions.
- update: sqlite dependency
- remove: unused methods from `SuggestionsRepo`
- remove: Arguments table
# Important Notes
Speeds up libraries loading by ~1 second.


close#6139close#6137
When the project is renamed, the engine cleans up affected modules and initiates modules re-indexing to fill the suggestions database with new records. This way it reduces the amount of information stored in the suggestions database and helps implement #6080 optimization.
Changelog:
- remove: rename features from the suggestions database
- update: rename command to initiate modules cleanup and project re-execution
- fix: #6137
It is sometimes impossible to figure out the real reason for invalid text edit request. Added a bit of context to failures to narrow down the cause of the failure.
# Important Notes
Should help with diagnosing issues like #6099.
close#5874
Changelog:
- add: `isStatic` parameter to `search/completion` request to search by the `static` suggestion attribute
- update: search non-static suggestions when opening component browser
# Important Notes
Component browser doesn't show `Table.new` and `Table.from_rows` suggestions when a `Table` node is selected.
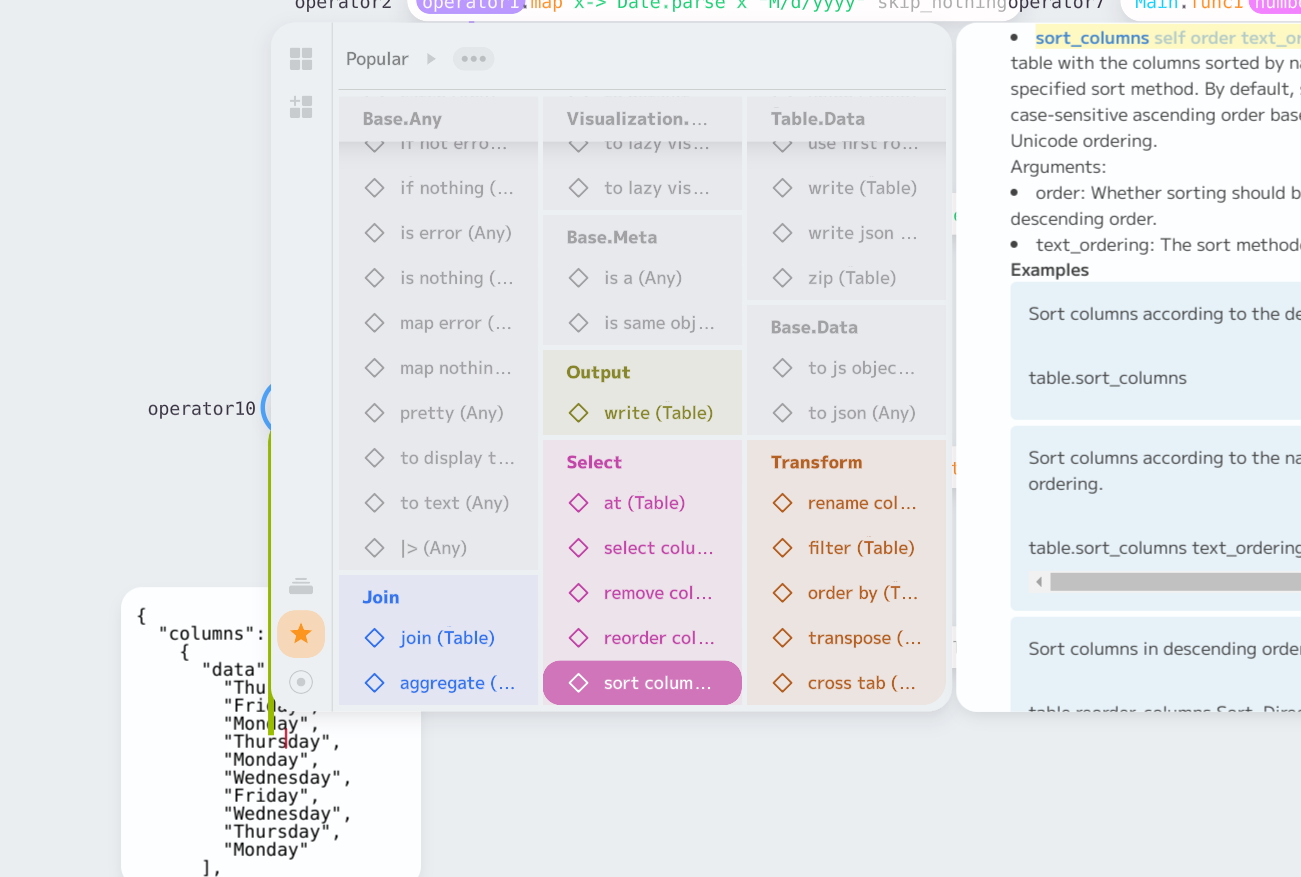
close#5881
Changelog
- add: ProtocolFactory object that initializes and returns the protocol object
- update: Add protocol initialization to the initialization component
close#5911
In interactive mode, perform writing IR caches in the background jobs queue. Background jobs execution is delayed until the first execution is complete.
The `logAvailableComponentsForDebugging` will check and install all necessary components of GraalVM for every mentioned version. While not harmful, it adds up to startup time.
Additionally added an option in language server startup to skip installation of GraalVM components. The latter is already performed by project-manager when opening the project and it is unnecessary to do it twice. Due to LS' architecture this configuration has to be passed around via multiple configs.
Finally, skipped the attempt to install Python component on Windows - this is not supported by GraalVM atm.
Closes#5749.
# Important Notes
The impact of this problem could be really felt the more versions of Enso and GraalVM one had since it would go through all of them.
Implement new Enso documentation parser; remove old Scala Enso parser.
Performance: Total time parsing documentation is now ~2ms.
# Important Notes
- Doc parsing is now done only in the frontend.
- Some engine tests had never been switched to the new parser. We should investigate tests that don't pass after the switch: #5894.
- The option to run the old searcher has been removed, as it is obsolete and was already broken before this (see #5909).
- Some interfaces used only by the old searcher have been removed.
Adds a common project that allows sharing code between the `runtime` and `std-bits`.
Due to classpath separation and the way it is compiled, the classes will be duplicated - we will have one copy for the `runtime` classpath and another copy as a small JAR for `Standard.Base` library.
This is still much better than having the code duplicated - now at least we have a single source of truth for the shared implementations.
Due to the copying we should not expand this project too much, but I encourage to put here any methods that would otherwise require us to copy the code itself.
This may be a good place to put parts of the hashing logic to then allow sharing the logic between the `runtime` and the `MultiValueKey` in the `Table` library (cc: @Akirathan).
close#5070
Changelog:
- Include the original exception to log expressions
- Enable logging of Akka Actors' lifecycle events on debug logging level
- Decrease the severity of interruption log messages because interruptions are part of the workflow. The computation can be interrupted at any time, and still be recomputed after. Warnings are just misleading in this case.
This change downgrades hashing algorithm used in caching IR and library bindings to SHA-1. It is sufficient and significantly faster for the purpose of simple checksum we use it for.
Additionally, don't calculate the digest for serialized bytes - if we get the expected object type then we are confident about the integrity.
Don't initialize Jackson's ObjectMapper for every metadata serialization/de-serialization. Initialization is very costly.
Avoid unnecessary conversions between Scala and Java. Those back-and-forth `asScala` and `asJava` are pretty expensive.
Finally fix an SBT warning when generating library cache.
Closes https://github.com/enso-org/enso/issues/5763
# Important Notes
The change cuts roughly 0.8-1s from the overall startup.
This change will certainly lead to invalidation of existing caches. It is advised to simply start with a clean slate.
This change adds serialization and deserialization of library bindings.
In order to be functional, one needs to first generate IR and
serialize bindings using `--compiled <path-to-library>` command. The bindings
will be stored under the library with `.bindings` suffix.
Bindings are being generated during `buildEngineDistribution` task, thus not
requiring any extra steps.
When resolving import/exports the compiler will first try to load
module's bindings from cache. If successful, it will not schedule its
imports/exports for immediate compilation, as we always did, but use the
bindings info to infer the dependent modules.
The current change does not make any optimizations when it comes to
compiling the modules, yet. It only delays the actual
compilation/loading IR from cache so that it can be done in bulk.
Further optimizations will come from this opportunity such as parallel
loading of caches or lazily inferring only the necessary modules.
Part of https://github.com/enso-org/enso/issues/5568 work.
In cloud we want to allow users to create new project from the template. List of templates is a bit outdated and doesn't contain all from the https://github.com/enso-org/project-templates. This PR simply adds missing ones
A combination of commands triggered separate compilation that only recompiled part of builtins. A mechanism that workaround annotation processor's problems with separate compilation was updated to include changes from https://github.com/enso-org/enso/pull/4111. This was pretty tough to find given the rather unusual circumstances in CI.
# Important Notes
This eliminates the _random_ failures in CI related to separate compilation.
To reproduce a specific set of steps has to be executed:
```
sbt> all buildEngineDistribution engine-runner/assembly runtime/Benchmark/compile language-server/Benchmark/compile searcher/Benchmark/compile
(exit sbt)
sbt> test
```
Expressions returning polyglot values were not reporting the type of the result because we have to do additional magic that infers the correct Enso type. Since this is exactly what `TypeOfNode` does, I re-used the logic.
Straightforward solution failed in tests because of assertions:
```
[enso] WARNING: Execution of function main failed (Invalid library usage. Cached library must be adopted by a RootNode before it is executed.).
java.lang.AssertionError: Invalid library usage. Cached library must be adopted by a RootNode before it is executed.
```
That is why this PR replaces `ExecutionEventListener` with `ExecutionEventNodeFactory`.
# Important Notes
Usage of `TypeOfNode` for programs that **do not** import stdlib means that we report types that do not involve stdlib e.g.
`Standard.Builtins.Main.Integer` instead of `Standard.Base.Data.Numbers.Integer`. While surprising, this is correct and I would say desirable. While reviewing the code, notice the difference in expectations in our runtime tests.
In order to investigate `engine/language-server` project, I need to be able to open its sources in IGV and NetBeans.
# Important Notes
By adding same Java source (this time `package-info.java`) and compiling with our Frgaal compiler the necessary `.enso-sources*` files are generated for `engine/language-server` and then the `enso4igv` plugin can open them and properly understand their compile settings.

In addition to that this PR enhances the _"logical view"_ presentation of the project by including all source roots found under `src/*/*`.
https://github.com/enso-org/enso/pull/3764 introduced static wrappers for instance methods. Except it had a limitation to only be allowed for types with at least a single constructor.
That excluded builtin types as well which, by default, don't have them. This limitation is problematic for Array/Vector consolidation and makes builtin types somehow second-citizens.
This change lifts the limitation for builtin types only. Note that we do want to share the implementation of the generated builtin methods. At the same time due to the additional argument we have to adjust the starting index of the arguments.
This change avoids messing with the existing dispatch logic, to avoid unnecessary complexity.
As a result it is now possible to call builtin types' instance methods, statically:
```
arr = Array.new_1 42
Array.length arr
```
That would previously lead to missing method exception in runtime.
# Important Notes
The only exception is `Nothing`. Primarily because it requires `Nothing` to have a proper eigentype (`Nothing.type`) which would messed up a lot of existing logic for no obvious benefit (no more calling of `foo=Nothing` in parameters being one example).
Introduces unboxed (and arity-specialized) storage schemes for Atoms. It results in improvements both in memory consumption and runtime.
Memory wise: instead of using an array, we now use object fields. We also enable unboxing. This cuts a good few pointers in an unboxed object. E.g. a quadruple of integers is now 64 bytes (4x8 bytes for long fields + 16 bytes for layout and constructor pointers + 16 bytes for a class header). It used to be 168 bytes (4x24 bytes for boxed Longs + 16 bytes for array header + 32 bytes for array contents + 8 bytes for constructor ptr + 16 bytes for class header), so we're saving 104 bytes a piece. In the least impressive scenarios (all-boxed fields) we're saving 8 bytes per object (saving 16 bytes for array header, using 8 bytes for the new layout field). In the most-benchmarked case (list of longs), we save 32 bytes per cons-cell.
Time wise:
All list-summing benchmarks observe a ~2x speedup. List generation benchmarks get ~25x speedups, probably both due to less GC activity and better allocation characteristics (only allocating one object per Cons, rather than Cons + Object[] for fields). The "map-reverse" family gets a neat 10x speedup (part of the work is reading, which is 2x faster, the other is allocating, which is now 25x faster, we end up with 10x when combined).
While doing regular node manipulation in editior, noticed a number of situations when
```
java.lang.IndexOutOfBoundsException: None
at java.base/java.lang.Character.offsetByCodePoints(Character.java:8699)
at java.base/java.lang.String.offsetByCodePoints(String.java:820)
at org.enso.text.buffer.CodePointView$Ops$.drop(CodePointView.scala:98)
at org.enso.text.buffer.CodePointView$Ops$.drop(CodePointView.scala:57)
at org.enso.text.buffer.Node.drop(Tree.scala:218)
at org.enso.text.buffer.Rope.dropWith(Rope.scala:86)
at org.enso.text.buffer.CodePointView.drop(CodePointView.scala:30)
at org.enso.text.editing.RopeTextEditor$.cutOutTail(RopeTextEditor.scala:42)
...
```
would be thrown. Further text edits would simply be rejected requiring a complete restart. I doubt we should propagate
`IndexOutOfBoundsException`. Instead it is safer to just apply the edit to the end of the rope.
* Hash codes prototype
* Remove Any.hash_code
* Improve caching of hashcode in atoms
* [WIP] Add Hash_Map type
* Implement Any.hash_code builtin for primitives and vectors
* Add some values to ValuesGenerator
* Fix example docs on Time_Zone.new
* [WIP] QuickFix for HashCodeTest before PR #3956 is merged
* Fix hash code contract in HashCodeTest
* Add times and dates values to HashCodeTest
* Fix docs
* Remove hashCodeForMetaInterop specialization
* Introduce snapshoting of HashMapBuilder
* Add unit tests for EnsoHashMap
* Remove duplicate test in Map_Spec.enso
* Hash_Map.to_vector caches result
* Hash_Map_Spec is a copy of Map_Spec
* Implement some methods in Hash_Map
* Add equalsHashMaps specialization to EqualsAnyNode
* get and insert operations are able to work with polyglot values
* Implement rest of Hash_Map API
* Add test that inserts elements with keys with same hash code
* EnsoHashMap.toDisplayString use builder storage directly
* Add separate specialization for host objects in EqualsAnyNode
* Fix specialization for host objects in EqualsAnyNode
* Add polyglot hash map tests
* EconomicMap keeps reference to EqualsNode and HashCodeNode.
Rather than passing these nodes to `get` and `insert` methods.
* HashMapTest run in polyglot context
* Fix containsKey index handling in snapshots
* Remove snapshots field from EnsoHashMapBuilder
* Prepare polyglot hash map handling.
- Hash_Map builtin methods are separate nodes
* Some bug fixes
* Remove ForeignMapWrapper.
We would have to wrap foreign maps in assignments for this to be efficient.
* Improve performance of Hash_Map.get_builtin
Also, if_nothing parameter is suspended
* Remove to_flat_vector.
Interop API requires nested vector (our previous to_vector implementation). Seems that I have misunderstood the docs the first time I read it.
- to_vector does not sort the vector by keys by default
* Fix polyglot hash maps method dispatch
* Add tests that effectively test hash code implementation.
Via hash map that behaves like a hash set.
* Remove Hashcode_Spec
* Add some polyglot tests
* Add Text.== tests for NFD normalization
* Fix NFD normalization bug in Text.java
* Improve performance of EqualsAnyNode.equalsTexts specialization
* Properly compute hash code for Atom and cache it
* Fix Text specialization in HashCodeAnyNode
* Add Hash_Map_Spec as part of all tests
* Remove HashMapTest.java
Providing all the infrastructure for all the needed Truffle nodes is no longer manageable.
* Remove rest of identityHashCode message implementations
* Replace old Map with Hash_Map
* Add some docs
* Add TruffleBoundaries
* Formatting
* Fix some tests to accept unsorted vector from Map.to_vector
* Delete Map.first and Map.last methods
* Add specialization for big integer hash
* Introduce proper HashCodeTest and EqualsTest.
- Use jUnit theories.
- Call nodes directly
* Fix some specializations for primitives in HashCodeAnyNode
* Fix host object specialization
* Remove Any.hash_code
* Fix import in Map.enso
* Update changelog
* Reformat
* Add truffle boundary to BigInteger.hashCode
* Fix performance of HashCodeTest - initialize DataPoints just once
* Fix MetaIsATest
* Fix ValuesGenerator.textual - Java's char is not Text
* Fix indent in Map_Spec.enso
* Add maps to datapoints in HashCodeTest
* Add specialization for maps in HashCodeAnyNode
* Add multiLevelAtoms to ValuesGenerator
* Provide a workaround for non-linear key inserts
* Fix specializations for double and BigInteger
* Cosmetics
* Add truffle boundaries
* Add allowInlining=true to some truffle boundaries.
Increases performance a lot.
* Increase the size of vectors, and warmup time for Vector.Distinct benchmark
* Various small performance fixes.
* Fix Geo_Spec tests to accept unsorted Map.to_vector
* Implement Map.remove
* FIx Visualization tests to accept unsorted Map.to_vector
* Treat java.util.Properties as Map
* Add truffle boundaries
* Invoke polyglot methods on java.util.Properties
* Ignore python tests if python lang is missing
Fixes an error when the logger processes NPE:
```
[internal-logger-error] One of the printers failed to write a message: java.lang.NullPointerException
```
Implements `getMetaObject` and related messages from Truffle interop for Enso values and types. Turns `Meta.is_a` into builtin and re-uses the same functionality.
# Important Notes
Adds `ValueGenerator` testing infrastructure to provide unified access to special Enso values and builtin types that can be reused by other tests, not just `MetaIsATest` and `MetaObjectTest`.
This removes the special handling of polyglot exceptions and allows matching on Java exceptions in the same way as for any other types.
`Polyglot_Error`, `Panic.catch_java` and `Panic.catch_primitive` are gone
The change mostly deals with the backslash of removing `Polyglot_Error` and two `Panic` methods.
`Panic.catch` was implemented as a builtin instead of delegating to `Panic.catch_primitive` builtin that is now gone.
This fixes https://www.pivotaltracker.com/story/show/182844611
* Sequence literal (Vector) should preserve warnings
When Vector was created via a sequence literal, we simply dropped any
associated any warnings associated with it.
This change propagates Warnings during the creation of the Vector.
Ideally, it would be sufficient to propagate warnings from the
individual elements to the underlying storage but doesn't go well with
`Vector.fromArray`.
* update changelog
* Array-like structures preserver warnings
Added a WarningsLibrary that exposes `hasWarnings` and `getWarnings`
messages. That way we can have a single storage that defines how to
extract warnings from an Array and the others just delegate to it.
This simplifies logic added to sequence literals to handle warnings.
* Ensure polyglot method calls are warning-free
Since warnings are no longer automatically extracted from Array-like
structures, we delay the operation until an actual polyglot method call
is performed.
Discovered a bug in `Warning.detach_selected_warnings` which was missing
any usage or tests.
* nits
* Support multi-dimensional Vectors with warnings
* Propagate warnings from case branches
* nit
* Propagate all vector warnings when reading element
Previously, accessing an element of an Array-like structure would only
return warnings of that element or of the structure itself.
Now, accessing an element also returns warnings from all its elements as
well.
It appears that we were always adding builtin methods to the scope of the module and the builtin type that shared the same name.
This resulted in some methods being accidentally available even though they shouldn't.
This change treats differently builtins of types and modules and introduces auto-registration feature for builtins.
By default all builtin methods are registered with a type, unless explicitly defined in the annotation property.
Builtin methods that are auto-registered do not have to be explicitly defined and are registered with the underlying type.
Registration correctly infers the right type, depending whether we deal with static or instance methods.
Builtin methods that are not auto-registered have to be explicitly defined **always**. Modules' builtin methods are the prime example.
# Important Notes
Builtins now carry information whether they are static or not (inferred from the lack of `self` parameter).
They also carry a `autoRegister` property to determine if a builtin method should be automatically registered with the type.
This change adds support for Version Controlled projects in language server.
Version Control supports operations:
- `init` - initialize VCS for a project
- `save` - commit all changes to the project in VCS
- `restore` - ability to restore project to some past `save`
- `status` - show the status of the project from VCS' perspective
- `list` - show a list of requested saves
# Important Notes
Behind the scenes, Enso's VCS uses git (or rather [jGit](https://www.eclipse.org/jgit/)) but nothing stops us from using a different implementation as long as it conforms to the establish API.
Computing length of a text takes time. Let's cache it after first computation.
# Important Notes
Wrote `StringBenchmarks` that sums lengths of (the same) `Text` present many time in a `Vector`. Initially it took `383.673 ms` per operation. Then it took `0.031 ms/op`. Looks like the `length` calls are returning instantly as they get cached.
1. Changes how we do monadic state – rather than a haskelly solution, we now have an implicit env with mutable data inside. It's better for the JVM. It also opens the possibility to have state ratained on exceptions (previously not possible) – both can now be implemented.
2. Introduces permission check system for IO actions.
We've had an old attempt at integrating a Rust parser with our Scala/Java projects. It seems to have been abandoned and is not used anywhere - it is also superseded by the new integration of the Rust parser. I think it was used as an experiment to see how to approach such an integration.
Since it is not used anymore - it make sense to remove it, because it only adds some (slight, but non-zero) maintenance effort. We can always bring it back from git history if necessary.
- Reimplement the `Duration` type to a built-in type.
- `Duration` is an interop type.
- Allow Enso method dispatch on `Duration` interop coming from different languages.
# Important Notes
- The older `Duration` type should now be split into new `Duration` builtin type and a `Period` type.
- This PR does not implement `Period` type, so all the `Period`-related functionality is currently not working, e.g., `Date - Period`.
- This PR removes `Integer.milliseconds`, `Integer.seconds`, ..., `Integer.years` extension methods.
Use an `ArraySlice` to slice `Vector`.
Avoids memory copying for the slice function.
# Important Notes
| Test | Ref | New |
| --- | --- | --- |
| New Vector | 71.9 | 71.0 |
| Append Single | 26.0 | 27.7 |
| Append Large | 15.1 | 14.9 |
| Sum | 156.4 | 165.8 |
| Drop First 20 and Sum | 171.2 | 165.3 |
| Drop Last 20 and Sum | 170.7 | 163.0 |
| Filter | 76.9 | 76.9 |
| Filter With Index | 166.3 | 168.3 |
| Partition | 278.5 | 273.8 |
| Partition With Index | 392.0 | 393.7 |
| Each | 101.9 | 102.7 |
- Note: the performance of New and Append has got slower from previous tests.
This PR adds a possibility to generate native-image for engine-runner.
Note that due to on-demand loading of stdlib, programs that make use of it are currently not yet supported
(that will be resolved at a later point).
The purpose of this PR is only to make sure that we can generate a bare minimum runner because due to lack TruffleBoundaries or misconfiguration in reflection config, this can get broken very easily.
To generate a native image simply execute:
```
sbt> engine-runner-native/buildNativeImage
... (wait a few minutes)
```
The executable is called `runner` and can be tested via a simple test that is in the resources. To illustrate the benefits
see the timings difference between the non-native and native one:
```
>time built-distribution/enso-engine-0.0.0-dev-linux-amd64/enso-0.0.0-dev/bin/enso --no-ir-caches --in-project test/Tests/ --run engine/runner-native/src/test/resources/Factorial.enso 6
720
real 0m4.503s
user 0m9.248s
sys 0m1.494s
> time ./runner --run engine/runner-native/src/test/resources/Factorial.enso 6
720
real 0m0.176s
user 0m0.042s
sys 0m0.038s
```
# Important Notes
Notice that due to a [bug in GraalVM](https://github.com/oracle/graal/issues/4200), which is already fixed in 22.x, and us still being on 21.x for the time being, I had to add a workaround to our sbt build to build a different fat jar for native image. To workaround it I had to exclude sqlite jar. Hence native image task is on `engine-runner-native` and not on `engine-runner`.
Will need to add the above command to CI.
`Vector` type is now a builtin type. This requires a bunch of additional builtin methods for its creation:
- Use `Vector.from_array` to convert any array-like structure into a `Vector` [by copy](f628b28f5f)
- Use (already existing) `Vector.from_polyglot_array` to convert any array-like structure into a `Vector` **without** copying
- Use (already existing) `Vector.fill 1 item` to create a singleton `Vector`
Additional, for pattern matching purposes, we had to implement a `VectorBranchNode`. Use following to match on `x` being an instance of `Vector` type:
```
import Standard.Base.Data.Vector
size = case x of
Vector.Vector -> x.length
_ -> 0
```
Finally, `VectorLiterals` pass that transforms `[1,2,3]` to (roughly)
```
a1 = 1
a2 = 2
a3 = 3
Vector (Array (a1,a2, a3))
```
had to be modified to generate
```
a1 = 1
a2 = 2
a3 = 3
Vector.from_array (Array (a1, a2, a3))
```
instead to accomodate to the API changes. As of 025acaa676 all the known CI checks passes. Let's start the review.
# Important Notes
Matching in `case` statement is currently done via `Vector_Data`. Use:
```
case x of
Vector.Vector_Data -> True
```
until a better alternative is found.
This is a step towards the new language spec. The `type` keyword now means something. So we now have
```
type Maybe a
Some (from_some : a)
None
```
as a thing one may write. Also `Some` and `None` are not standalone types now – only `Maybe` is.
This halfway to static methods – we still allow for things like `Number + Number` for backwards compatibility. It will disappear in the next PR.
The concept of a type is now used for method dispatch – with great impact on interpreter code density.
Some APIs in the STDLIB may require re-thinking. I take this is going to be up to the libraries team – some choices are not as good with a semantically different language. I've strived to update stdlib with minimal changes – to make sure it still works as it did.
It is worth mentioning the conflicting constructor name convention I've used: if `Foo` only has one constructor, previously named `Foo`, we now have:
```
type Foo
Foo_Data f1 f2 f3
```
This is now necessary, because we still don't have proper statics. When they arrive, this can be changed (quite easily, with SED) to use them, and figure out the actual convention then.
I have also reworked large parts of the builtins system, because it did not work at all with the new concepts.
It also exposes the type variants in SuggestionBuilder, that was the original tiny PR this was based on.
PS I'm so sorry for the size of this. No idea how this could have been smaller. It's a breaking language change after all.
- Added `Zone`, `Date_Time` and `Time_Of_Day` to `Standard.Base`.
- Renamed `Zone` to `Time_Zone`.
- Added `century`.
- Added `is_leap_year`.
- Added `length_of_year`.
- Added `length_of_month`.
- Added `quarter`.
- Added `day_of_year`.
- Added `Day_Of_Week` type and `day_of_week` function.
- Updated `week_of_year` to support ISO.
# Important Notes
- Had to pass locale to formatter for date/time tests to work on my PC.
- Changed default of `week_of_year` to use ISO.
* Builtin Date_Time, Time_Of_Day, Zone
Improved polyglot support for Date_Time (formerly Time), Time_Of_Day and
Zone. This follows the pattern introduced for Enso Date.
Minor caveat - in tests for Date, had to bend a lot for JS Date to pass.
This is because JS Date is not really only a Date, but also a Time and
Timezone, previously we just didn't consider the latter.
Also, JS Date does not deal well with setting timezones so the trick I
used is to first call foreign function returning a polyglot JS Date,
which is converted to ZonedDateTime and only then set the correct
timezone. That way none of the existing tests had to be changes or
special cased.
Additionally, JS deals with milliseconds rather than nanoseconds so
there is loss in precision, as noted in Time_Spec.
* Add tests for Java's LocalTime
* changelog
* Make date formatters in table happy
* PR review, add more tests for zone
* More tests and fixed a bug in column reader
Column reader didn't take into account timezone but that was a mistake
since then it wouldn't map to Enso's Date_Time.
Added tests that check it now.
* remove redundant conversion
* Update distribution/lib/Standard/Base/0.0.0-dev/src/Data/Time.enso
Co-authored-by: Radosław Waśko <radoslaw.wasko@enso.org>
* First round of addressing PR review
* don't leak java exceptions in Zone
* Move Date_Time to top-level module
* PR review
Co-authored-by: Radosław Waśko <radoslaw.wasko@enso.org>
Co-authored-by: Jaroslav Tulach <jaroslav.tulach@enso.org>
Importing individual methods didn't work as advertised because parser
would allow them but later drop that information. This slipped by because we never had mixed atoms and methods in stdlib.
# Important Notes
Added some basic tests but we need to ensure that the new parser allows for this.
@jdunkerley will be adding some changes to stdlib that will be testing this functionality as well.
This change allows for importing modules using a qualified name and deals with any conflicts on the way.
Given a module C defined at `A/B/C.enso` with
```
type C
type C a
```
it is now possible to import it as
```
import project.A
...
val x = A.B.C 10
```
Given a module located at `A/B/C/D.enso`, we will generate
intermediate, synthetic, modules that only import and export the successor module along the path.
For example, the contents of a synthetic module B will look like
```
import <namespace>.<pkg-name>.A.B.C
export <namespace>.<pkg-name>.A.B.C
```
If module B is defined already by the developer, the compiler will _inject_ the above statements to the IR.
Also removed the last elements of some lowercase name resolution that managed to survive recent
changes (`Meta.Enso_Project` would now be ambiguous with `enso_project` method).
Finally, added a pass that detects shadowing of the synthetic module by the type defined along the path.
We print a warning in such a situation.
Related to https://www.pivotaltracker.com/n/projects/2539304
# Important Notes
There was an additional request to fix the annoying problem with `from` imports that would always bring
the module into the scope. The changes in stdlib demonstrate how it is now possible to avoid the workaround of
```
from X.Y.Z as Z_Module import A, B
```
(i.e. `as Z_Module` part is almost always unnecessary).
Fixes random timeout failures on CI.
```
INFO ide_ci::program::command: sbtℹ️ up to date, audited 98 packages in 3s
```
`npm install` takes 3s of test time doing unnecessary package auditing. On CI the command is executed once before running the tests and redundant `npm install` calls can be omitted.
This change modifies the current language by requiring explicit `self` parameter declaration
for methods. Methods without `self` parameter in the first position should be treated as statics
although that is not yet part of this PR. We add an implicit self to all methods
This obviously required updating the whole stdlib and its components, tests etc but the change
is pretty straightforward in the diff.
Notice that this change **does not** change method dispatch, which was removed in the last changes.
This was done on purpose to simplify the implementation for now. We will likely still remove all
those implicit selfs to bring true statics.
Minor caveat - since `main` doesn't actually need self, already removed that which simplified
a lot of code.
Significantly improves the polyglot Date support (as introduced by #3374). It enhances the `Date_Spec` to run it in four flavors:
- with Enso Date (as of now)
- with JavaScript Date
- with JavaScript Date wrapped in (JavaScript) array
- with Java LocalDate allocated directly
The code is then improved by necessary modifications to make the `Date_Spec` pass.
# Important Notes
James has requested in [#181755990](https://www.pivotaltracker.com/n/projects/2539304/stories/181755990) - e.g. _Review and improve InMemory Table support for Dates, Times, DateTimes, BigIntegers_ the following program to work:
```
foreign js dateArr = """
return [1, new Date(), 7]
main =
IO.println <| (dateArr.at 1).week_of_year
```
the program works with here in provided changes and prints `27` as of today.
@jdunkerley has provided tests for proper behavior of date in `Table` and `Column`. Those tests are working as of [f16d07e](f16d07e640). One just needs to accept `List<Value>` and then query `Value` for `isDate()` when needed.
Last round of changes is related to **exception handling**. 8b686b12bd makes sure `makePolyglotError` accepts only polyglot values. Then it wraps plain Java exceptions into `WrapPlainException` with `has_type` method - 60da5e70ed - the remaining changes in the PR are only trying to get all tests working in the new setup.
The support for `Time` isn't part of this PR yet.
Modified UppercaseNames to now resolve methods without an explicit `here` to point to the current module.
`here` was also often used instead of `self` which was allowed by the compiler.
Therefore UppercaseNames pass is now GlobalNames and does some extra work -
it translated method calls without an explicit target into proper applications.
# Important Notes
There was a long-standing bug in scopes usage when compiling standalone expressions.
This resulted in AliasAnalysis generating incorrect graphs and manifested itself only in unit tests
and when running `eval`, thus being a bit hard to locate.
See `runExpression` for details.
Additionally, method name resolution is now case-sensitive.
Obsolete passes like UndefinedVariables and ModuleThisToHere were removed. All tests have been adapted.
A semi-manual s/this/self appied to the whole standard library.
Related to https://www.pivotaltracker.com/story/show/182328601
In the compiler promoted to use constants instead of hardcoded
`this`/`self` whenever possible.
# Important Notes
The PR **does not** require explicit `self` parameter declaration for methods as this part
of the design is still under consideration.
Auto-generate all builtin methods for builtin `File` type from method signatures.
Similarly, for `ManagedResource` and `Warning`.
Additionally, support for specializations for overloaded and non-overloaded methods is added.
Coverage can be tracked by the number of hard-coded builtin classes that are now deleted.
## Important notes
Notice how `type File` now lacks `prim_file` field and we were able to get rid off all of those
propagating method calls without writing a single builtin node class.
Similarly `ManagedResource` and `Warning` are now builtins and `Prim_Warnings` stub is now gone.
Drop `Core` implementation (replacement for IR) as it (sadly) looks increasingly
unlikely this effort will be continued. Also, it heavily relies
on implicits which increases some compilation time (~1sec from `clean`)
Related to https://www.pivotaltracker.com/story/show/182359029
This change introduces a custom LogManager for console that allows for
excluding certain log messages. The primarily reason for introducing
such LogManager/Appender is to stop issuing hundreds of pointless
warnings coming from the analyzing compiler (wrapper around javac) for
classes that are being generated by annotation processors.
The output looks like this:
```
[info] Cannot install GraalVM MBean due to Failed to load org.graalvm.nativebridge.jni.JNIExceptionWrapperEntryPoints
[info] compiling 129 Scala sources and 395 Java sources to /home/hubert/work/repos/enso/enso/engine/runtime/target/scala-2.13/classes ...
[warn] Unexpected javac output: warning: File for type 'org.enso.interpreter.runtime.type.ConstantsGen' created in the last round will not be subject to annotation processing.
[warn] 1 warning.
[info] [Use -Dgraal.LogFile=<path> to redirect Graal log output to a file.]
[info] Cannot install GraalVM MBean due to Failed to load org.graalvm.nativebridge.jni.JNIExceptionWrapperEntryPoints
[info] foojavac Filer
[warn] Could not determine source for class org.enso.interpreter.node.expression.builtin.number.decimal.CeilMethodGen
[warn] Could not determine source for class org.enso.interpreter.node.expression.builtin.resource.TakeNodeGen
[warn] Could not determine source for class org.enso.interpreter.node.expression.builtin.error.ThrowErrorMethodGen
[warn] Could not determine source for class org.enso.interpreter.node.expression.builtin.number.smallInteger.MultiplyMethodGen
[warn] Could not determine source for class org.enso.interpreter.node.expression.builtin.warning.GetWarningsNodeGen
[warn] Could not determine source for class org.enso.interpreter.node.expression.builtin.number.smallInteger.BitAndMethodGen
[warn] Could not determine source for class org.enso.interpreter.node.expression.builtin.error.ErrorToTextNodeGen
[warn] Could not determine source for class org.enso.interpreter.node.expression.builtin.warning.GetValueMethodGen
[warn] Could not determine source for class org.enso.interpreter.runtime.callable.atom.AtomGen$MethodDispatchLibraryExports$Cached
....
```
The output now has over 500 of those and there will be more. Much more
(generated by our and Truffle processors).
There is no way to tell SBT that those are OK. One could potentially
think of splitting compilation into 3 stages (Java processors, Java and
Scala) but that will already complicate the non-trivial build definition
and we may still end up with the initial problem.
This is a fix to make it possible to get reasonable feedback from
compilation without scrolling mutliple screens *every single time*.
Also fixed a spurious warning in javac processor complaining about
creating files in the last round.
Related to https://www.pivotaltracker.com/story/show/182138198
@radeusgd discovered that no formatting was being applied to std-bits projects.
This was caused by the fact that `enso` project didn't aggregate them. Compilation and
packaging still worked because one relied on the output of some tasks but
```
sbt> javafmtAll
```
didn't apply it to `std-bits`.
# Important Notes
Apart from `build.sbt` no manual changes were made.
This is the 2nd part of DSL improvements that allow us to generate a lot of
builtins-related boilerplate code.
- [x] generate multiple method nodes for methods/constructors with varargs
- [x] expanded processing to allow for @Builtin to be added to classes and
and generate @BuiltinType classes
- [x] generate code that wraps exceptions to panic via `wrapException`
annotation element (see @Builtin.WrapException`
Also rewrote @Builtin annotations to be more structured and introduced some nesting, such as
@Builtin.Method or @Builtin.WrapException.
This is part of incremental work and a follow up on https://github.com/enso-org/enso/pull/3444.
# Important Notes
Notice the number of boilerplate classes removed to see the impact.
For now only applied to `Array` but should be applicable to other types.
A low-hanging fruit where we can automate the generation of many
@BuiltinMethod nodes simply from the runtime's methods signatures.
This change introduces another annotation, @Builtin, to distinguish from
@BuiltinType and @BuiltinMethod processing. @Builtin processing will
always be the first stage of processing and its output will be fed to
the latter.
Note that the return type of Array.length() is changed from `int` to
`long` because we probably don't want to add a ton of specializations
for the former (see comparator nodes for details) and it is fine to cast
it in a small number of places.
Progress is visible in the number of deleted hardcoded classes.
This is an incremental step towards #181499077.
# Important Notes
This process does not attempt to cover all cases. Not yet, at least.
We only handle simple methods and constructors (see removed `Array` boilerplate methods).
In order to analyse why the `runner.jar` is slow to start, let's _"self sample"_ it using the [sampler library](https://bits.netbeans.org/dev/javadoc/org-netbeans-modules-sampler/org/netbeans/modules/sampler/Sampler.html). As soon as the `Main.main` is launched, the sampling starts and once the server is up, it writes its data into `/tmp/language-server.npss`.
Open the `/tmp/language-server.npss` with [VisualVM](https://visualvm.github.io) - you should have one copy in your
GraalVM `bin/jvisualvm` directory and there has to be a GraalVM to run Enso.
#### Changelog
- add: the `MethodsSampler` that gathers information in `.npss` format
- add: `--profiling` flag that enables the sampler
- add: language server processes the updates in batches
This PR replaces hard-coded `@Builtin_Method` and `@Builtin_Type` nodes in Builtins with an automated solution
that a) collects metadata from such annotations b) generates `BuiltinTypes` c) registers builtin methods with corresponding
constructors.
The main differences are:
1) The owner of the builtin method does not necessarily have to be a builtin type
2) You can now mix regular methods and builtin ones in stdlib
3) No need to keep track of builtin methods and types in various places and register them by hand (a source of many typos or omissions as it found during the process of this PR)
Related to #181497846
Benchmarks also execute within the margin of error.
### Important Notes
The PR got a bit large over time as I was moving various builtin types and finding various corner cases.
Most of the changes however are rather simple c&p from Builtins.enso to the corresponding stdlib module.
Here is the list of the most crucial updates:
- `engine/runtime/src/main/java/org/enso/interpreter/runtime/builtin/Builtins.java` - the core of the changes. We no longer register individual builtin constructors and their methods by hand. Instead, the information about those is read from 2 metadata files generated by annotation processors. When the builtin method is encountered in stdlib, we do not ignore the method. Instead we lookup it up in the list of registered functions (see `getBuiltinFunction` and `IrToTruffle`)
- `engine/runtime/src/main/java/org/enso/interpreter/runtime/callable/atom/AtomConstructor.java` has now information whether it corresponds to the builtin type or not.
- `engine/runtime/src/main/scala/org/enso/compiler/codegen/RuntimeStubsGenerator.scala` - when runtime stubs generator encounters a builtin type, based on the @Builtin_Type annotation, it looks up an existing constructor for it and registers it in the provided scope, rather than creating a new one. The scope of the constructor is also changed to the one coming from stdlib, while ensuring that synthetic methods (for fields) also get assigned correctly
- `engine/runtime/src/main/scala/org/enso/compiler/codegen/IrToTruffle.scala` - when a builtin method is encountered in stdlib we don't generate a new function node for it, instead we look it up in the list of registered builtin methods. Note that Integer and Number present a bit of a challenge because they list a whole bunch of methods that don't have a corresponding method (instead delegating to small/big integer implementations).
During the translation new atom constructors get initialized but we don't want to do it for builtins which have gone through the process earlier, hence the exception
- `lib/scala/interpreter-dsl/src/main/java/org/enso/interpreter/dsl/MethodProcessor.java` - @Builtin_Method processor not only generates the actual code fpr nodes but also collects and writes the info about them (name, class, params) to a metadata file that is read during builtins initialization
- `lib/scala/interpreter-dsl/src/main/java/org/enso/interpreter/dsl/MethodProcessor.java` - @Builtin_Method processor no longer generates only (root) nodes but also collects and writes the info about them (name, class, params) to a metadata file that is read during builtins initialization
- `lib/scala/interpreter-dsl/src/main/java/org/enso/interpreter/dsl/TypeProcessor.java` - Similar to MethodProcessor but handles @Builtin_Type annotations. It doesn't, **yet**, generate any builtin objects. It also collects the names, as present in stdlib, if any, so that we can generate the names automatically (see generated `types/ConstantsGen.java`)
- `engine/runtime/src/main/java/org/enso/interpreter/node/expression/builtin` - various classes annotated with @BuiltinType to ensure that the atom constructor is always properly registered for the builitn. Note that in order to support types fields in those, annotation takes optional `params` parameter (comma separated).
- `engine/runtime/src/bench/scala/org/enso/interpreter/bench/fixtures/semantic/AtomFixtures.scala` - drop manual creation of test list which seemed to be a relict of the old design
* Initial integration with Frgaal in sbt
Half-working since it chokes on generated classes from annotation
processor.
* Replace AutoService with ServiceProvider
For reasons unknown AutoService would fail to initialize and fail to
generate required builtin method classes.
Hidden error message is not particularly revealing on the reason for
that:
```
[error] error: Bad service configuration file, or exception thrown while constructing Processor object: javax.annotation.processing.Processor: Provider com.google.auto.service.processor.AutoServiceProcessor could not be instantiated
```
The sample records is only to demonstrate that we can now use newer Java
features.
* Cleanup + fix benchmark compilation
Bench requires jmh classes which are not available because we obviously
had to limit `java.base` modules to get Frgaal to work nicely.
For now, we default to good ol' javac for Benchmarks.
Limiting Frgaal to runtime for now, if it plays nicely, we can expand it
to other projects.
* Update CHANGELOG
* Remove dummy record class
* Update licenses
* New line
* PR review
* Update legal review
Co-authored-by: Radosław Waśko <radoslaw.wasko@enso.org>
Changelog:
- fix: `search/completion` request with the position parameter.
- fix: `refactoring/renameProject` request. Previously it did not take into account the library namespace (e.g. `local.`)
Result of automatic formatting with `scalafmtAll` and `javafmtAll`.
Prerequisite for https://github.com/enso-org/enso/pull/3394
### Important Notes
This touches a lot of files and might conflict with existing PRs that are in progress. If that's the case, just run
`scalafmtAll` and `javafmtAll` after merge and everything should be in order since formatters should be deterministic.
Changelog:
- add: component groups to package descriptions
- add: `executionContext/getComponentGroups` method that returns component groups of libraries that are currently loaded
- doc: cleanup unimplemented undo/redo commands
- refactor: internal component groups datatype
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}