15 KiB
Scaling to 1 million active GraphQL subscriptions (live queries)
Hasura is a GraphQL engine on Postgres that provides instant GraphQL APIs with authorization. Read more at hasura.io and on github.com/hasura/graphql-engine.
Hasura allows 'live queries' for clients (over GraphQL subscriptions). For example, a food ordering app can use a live query to show the live-status of an order for a particular user.
This document describes Hasura's architecture which lets you scale to handle a million active live queries.
Table of Contents
TL;DR:
The setup: Each client (a web/mobile app) subscribes to data or a live-result with an auth token. The data is in Postgres. 1 million rows are updated in Postgres every second (ensuring a new result pushed per client). Hasura is the GraphQL API provider (with authorization).
The test: How many concurrent live subscriptions (clients) can Hasura handle? Does Hasura scale vertically and/or horizontally?


| Single instance configuration | No. of active live queries | CPU load average |
|---|---|---|
| 1xCPU, 2GB RAM | 5000 | 60% |
| 2xCPU, 4GB RAM | 10000 | 73% |
| 4xCPU, 8GB RAM | 20000 | 90% |
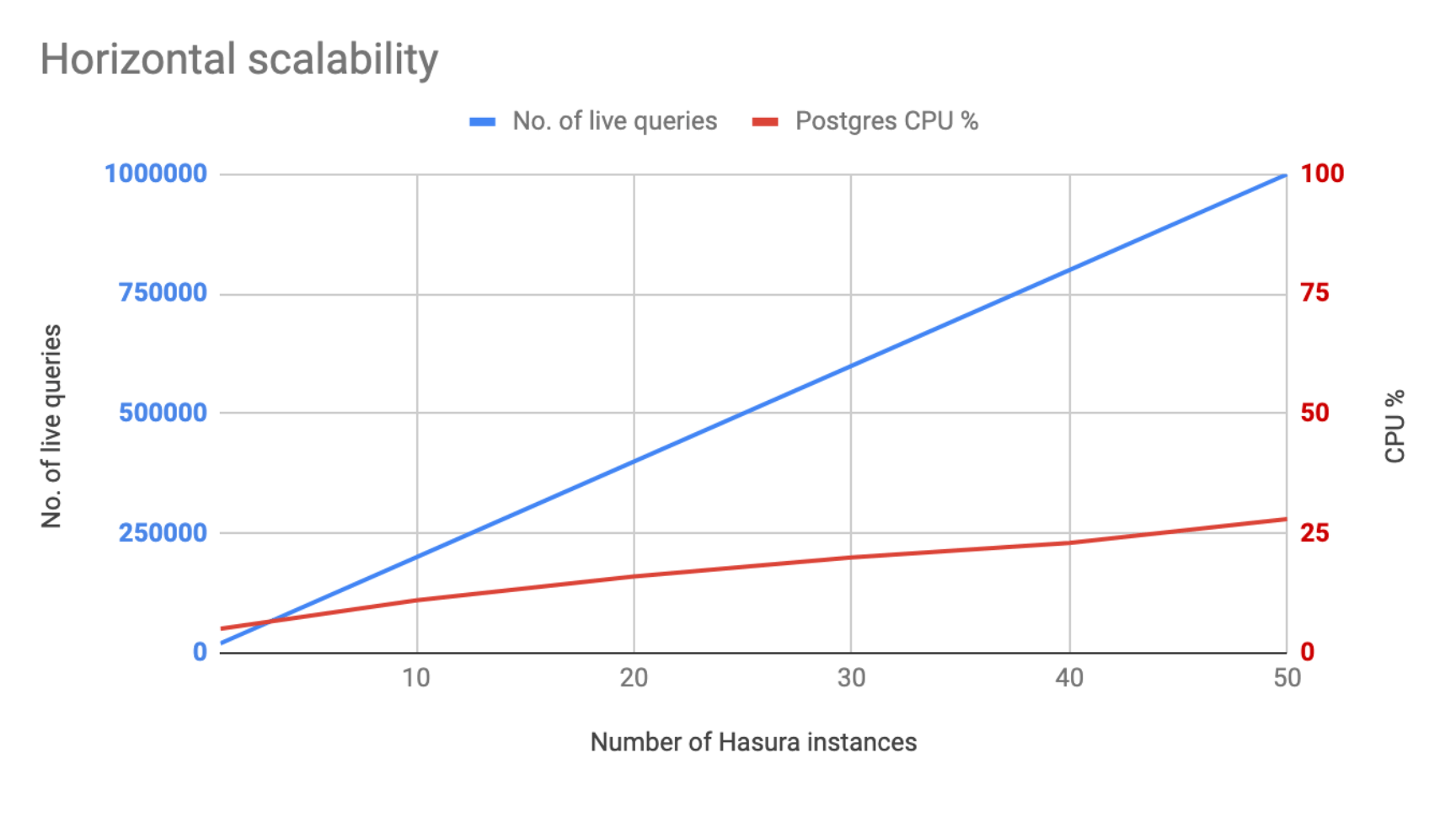
At 1 million live queries, Postgres is under about 28% load with peak number of connections being around 850.
Notes on configuration:
- AWS RDS postgres, Fargate, ELB were used with their default configurations and without any tuning.
- RDS Postgres: 16xCPU, 64GB RAM, Postgres 11
- Hasura running on Fargate (4xCPU, 8GB RAM per instance) with default configurations
GraphQL and subscriptions
GraphQL makes it easy for app developers to query for precisely the data they want from their API.
For example, let’s say we’re building a food delivery app. Here’s what the schema might look like on Postgres:
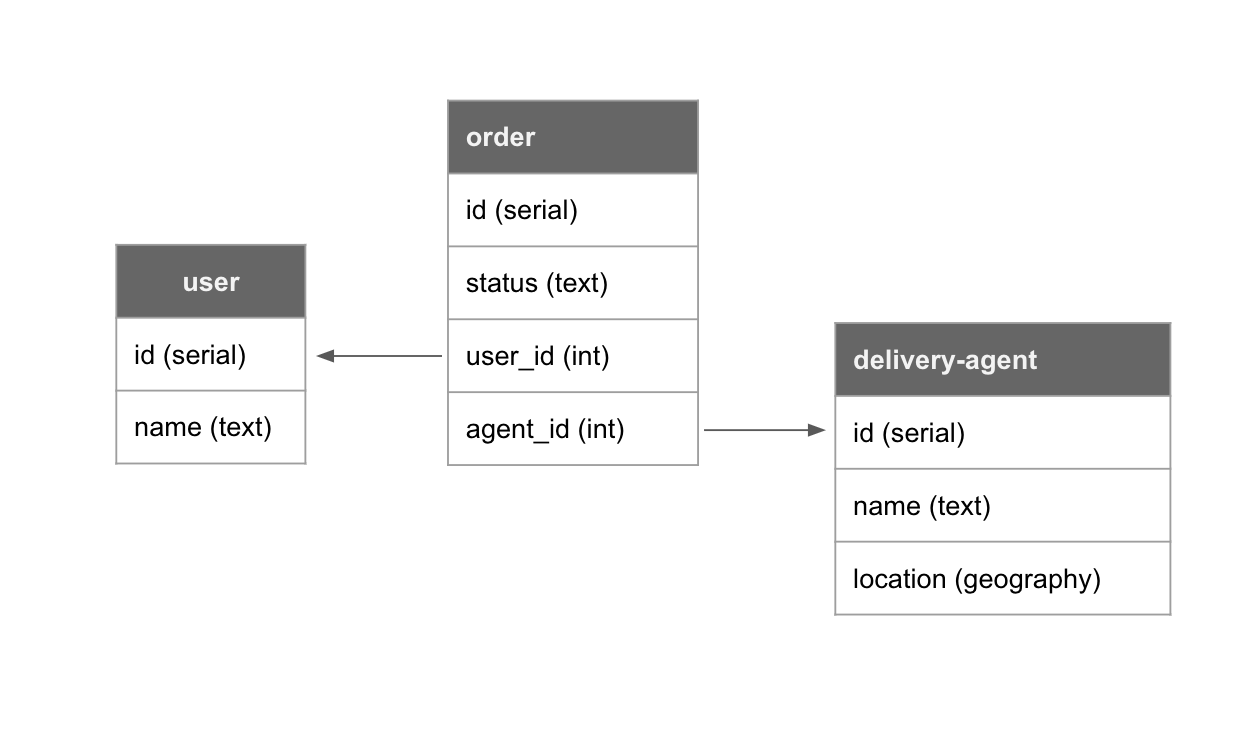
For an app screen showing a “order status” for the current user for their order, a GraphQL query would fetch the latest order status and the location of the agent delivering the order.
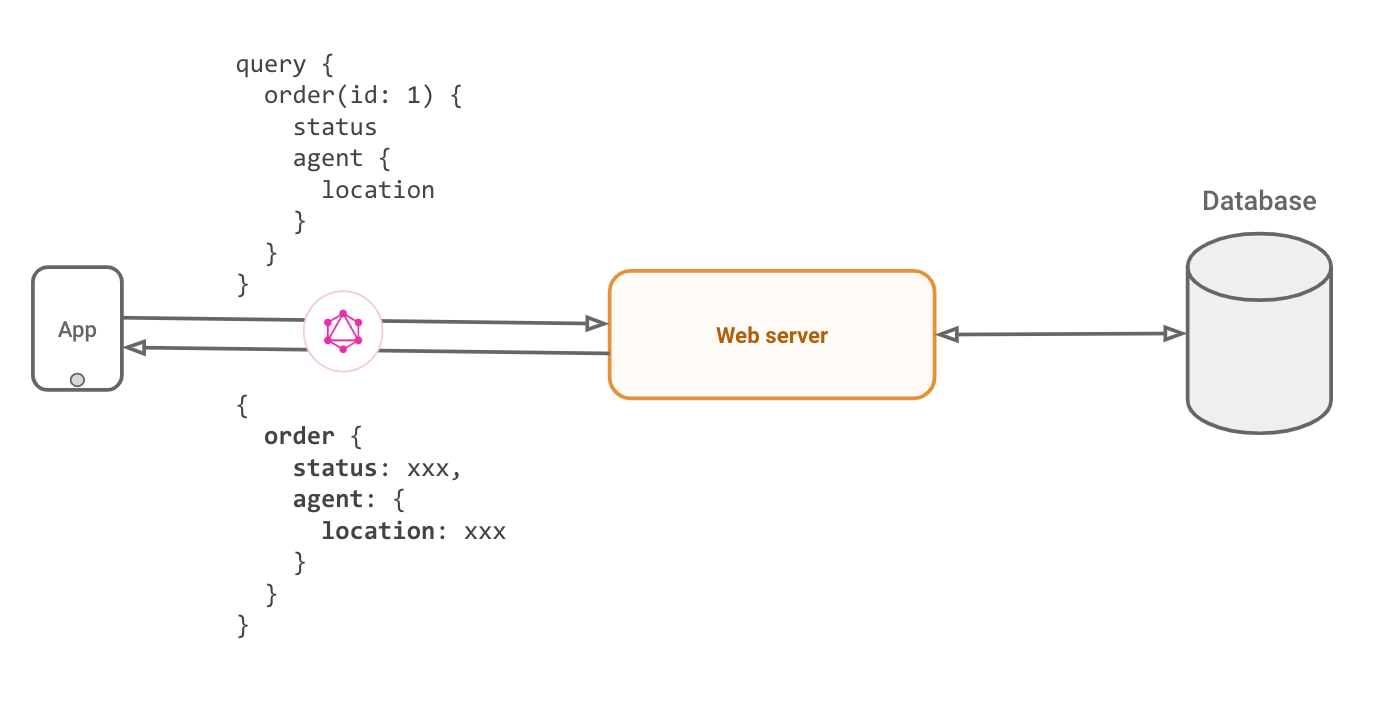
Underneath it, this query is sent as a string to a webserver that parses it, applies authorization rules and makes appropriate calls to things like databases to fetch the data for the app. It sends this data, in the exact shape that was requested, as a JSON.
Enter live-queries: Live queries is the idea of being able to subscribe to the latest result of a particular query. As the underlying data changes, the server should push the latest result to the client.
On the surface this is a perfect fit with GraphQL because GraphQL clients support subscriptions that take care of dealing with messy websocket connections. Converting a query to a live query might look as simple as replacing the word query with subscription for the client. That is, if the GraphQL server can implement it.
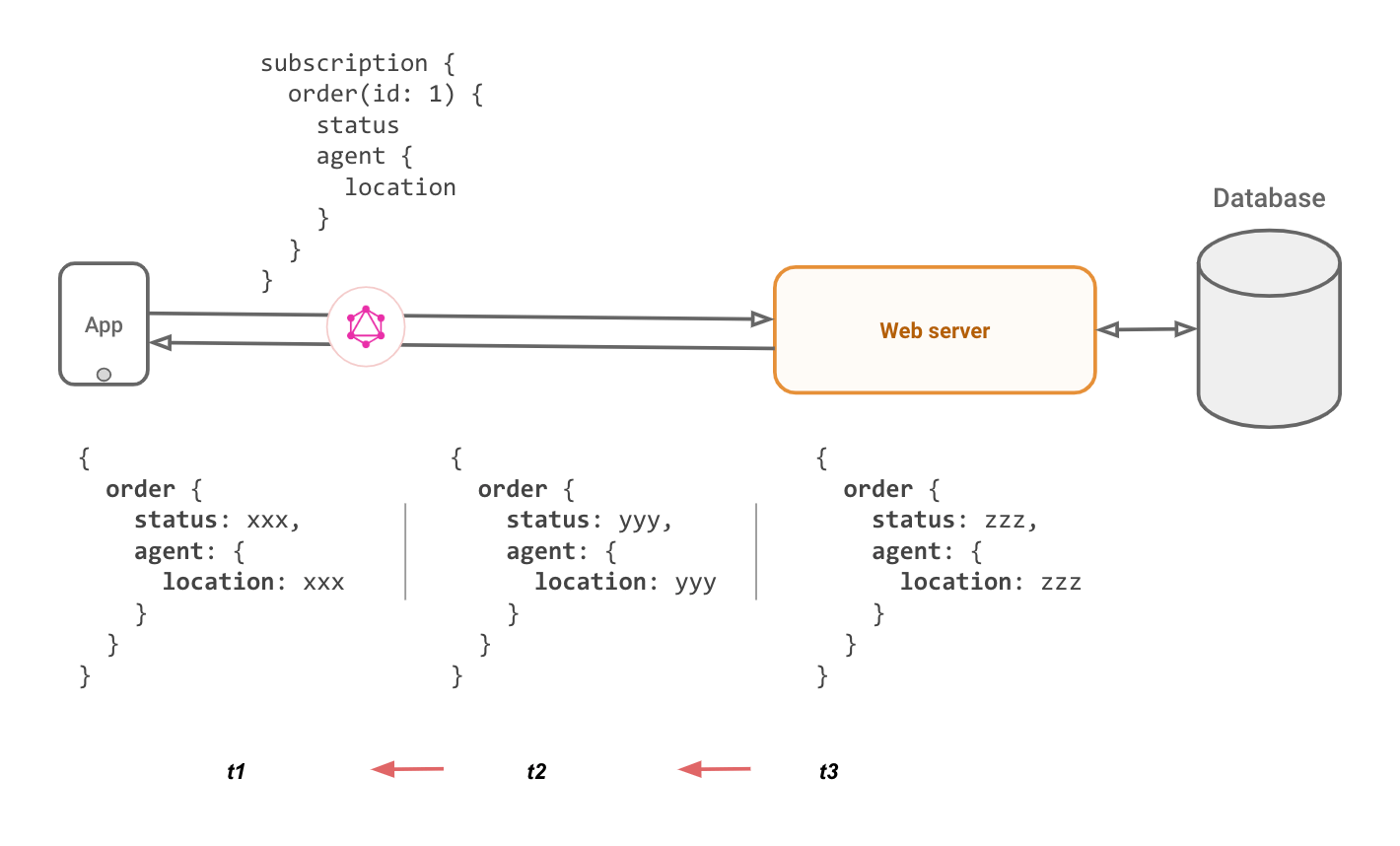
Implementing GraphQL live-queries
Implementing live-queries is painful. Once you have a database query that has all the authorization rules, it might be possible to incrementally compute the result of the query as events happen. But this is practically challenging to do at the web-service layer. For databases like Postgres, it is equivalent to the hard problem of keeping a materialized view up to date as underlying tables change. An alternative approach is to refetch all the data for a particular query (with the appropriate authorization rules for the specific client). This is the approach we currently take.
Secondly, building a webserver to handle websockets in a scalable way is also sometimes a little hairy, but certain frameworks and languages do make the concurrent programming required a little more tractable.
Refetching results for a GraphQL query
To understand why refetching a GraphQL query is hard, let’s look at how a GraphQL query is typically processed:
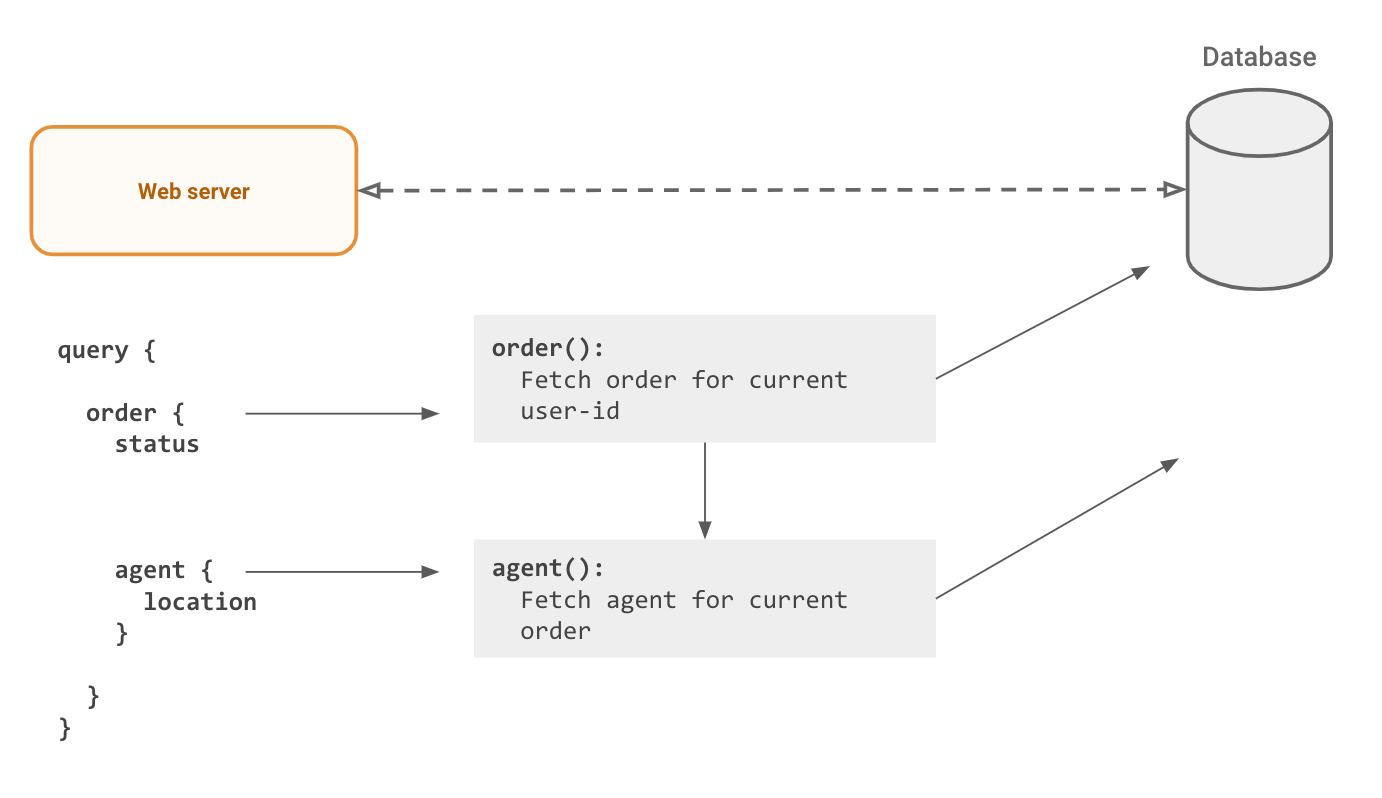
The authorization + data fetching logic has to run for each “node” in the GraphQL query. This is scary, because even a slightly large query fetching a collection could bring down the database quite easily. The N+1 query problem, also common with badly implemented ORMs, is bad for your database and makes it hard to optimally query Postgres. Data loader type patterns can alleviate the problem, but will still query the underlying Postgres database multiple times (reduces to as many nodes in the GraphQL query from as many items in the response).
For live queries, this problem becomes worse, because each client’s query will translate into an independent refetch. Even though the queries are the “same”, since the authorization rules create different session variables, independent fetches are required for each client.
Hasura approach
Is it possible to do better? What if declarative mapping from the data models to the GraphQL schema could be used to create a single SQL query to the database? This would avoid multiple hits to the database, whether there are a large number of items in the response or the number of nodes in the GraphQL query are large.
Idea #1: “Compile” a GraphQL query to a single SQL query
Part of Hasura is a transpiler that uses the metadata of mapping information for the data models to the GraphQL schema to “compile” GraphQL queries to the SQL queries to fetch data from the database.
GraphQL query → GraphQL AST → SQL AST → SQL
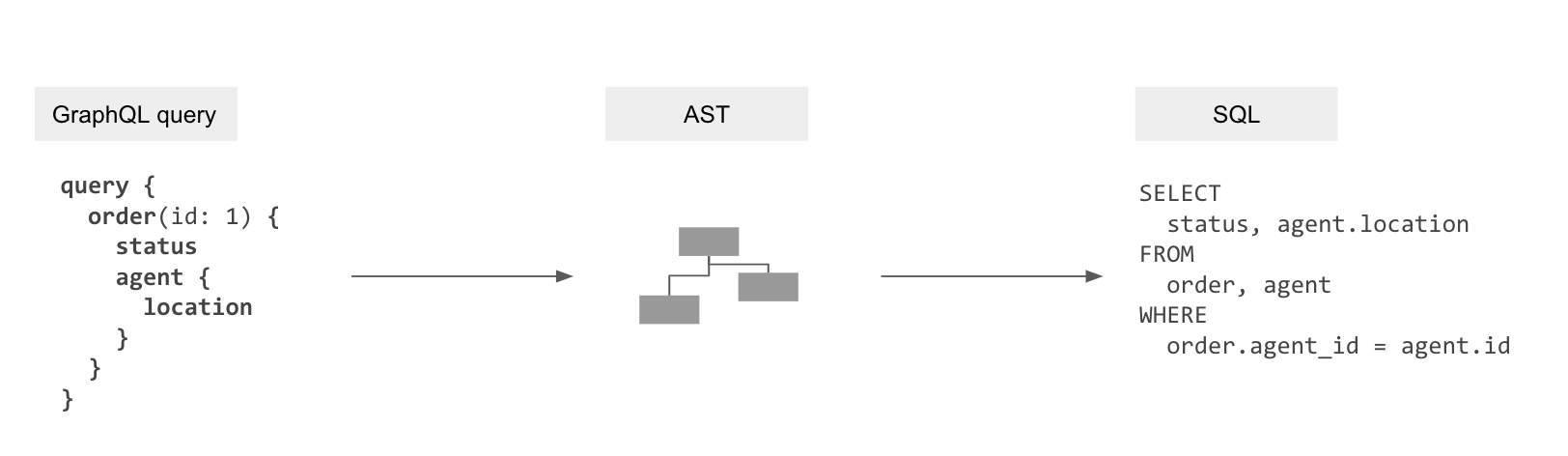
This gets rid of the N+1 query problem and allows the database to optimise data-fetching now that it can see the entire query.
But this in itself isn't enough as resolvers also enforce authorization rules by only fetching the data that is allowed. We will therefore need to embed these authorization rules into the generated SQL.
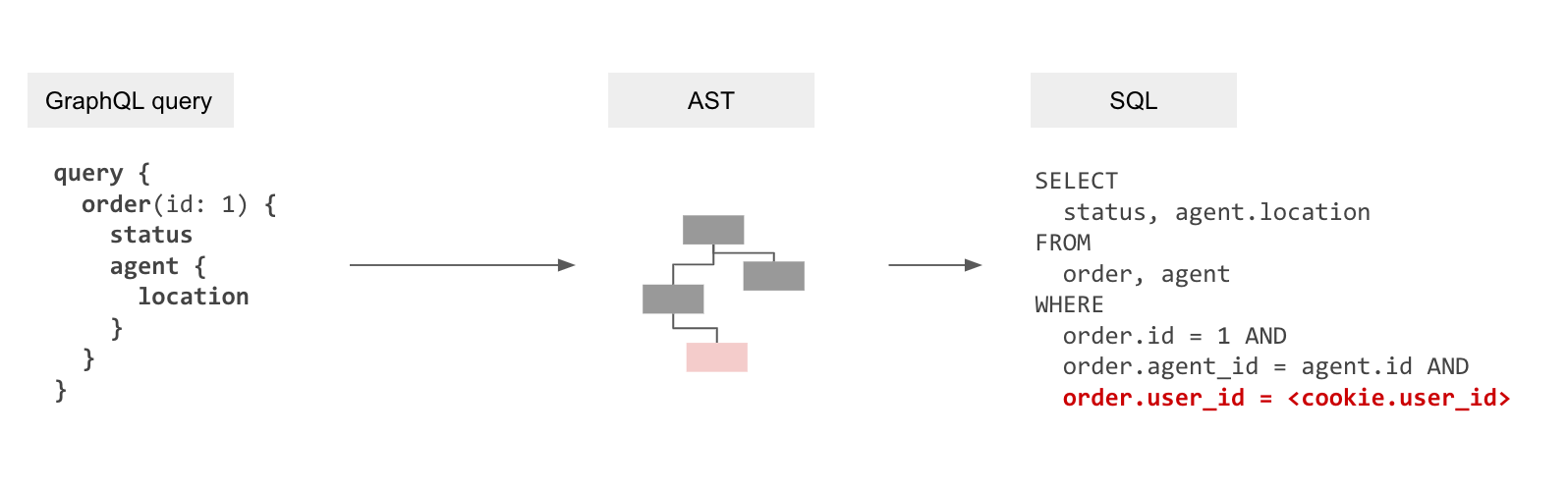
Idea #2: Make authorization declarative
Authorization when it comes to accessing data is essentially a constraint that depends on the values of data (or rows) being fetched combined with application-user specific “session variables” that are provided dynamically. For example, in the most trivial case, a row might container a user_id that denotes the data ownership. Or documents that are viewable by a user might be represented in a related table, document_viewers. In other scenarios the session variable itself might contain the data ownership information pertinent to a row, for eg, an account manager has access to any account [1,2,3…] where that information is not present in the current database but present in the session variable (probably provided by some other data system).
To model this, we implemented an authorization layer similar to Postgres RLS at the API layer to provide a declarative framework to configure access control. If you’re familiar with RLS, the analogy is that the “current session” variables in a SQL query are now HTTP “session-variables” coming from cookies or JWTs or HTTP headers.
Incidentally, because we had started the engineering work behind Hasura many years ago, we ended up implementing Postgres RLS features at the application layer before it landed in Postgres. We even had the same bug in our equivalent of the insert returning clause that Postgres RLS fixed 🤓 https://www.postgresql.org/about/news/1614/.
Because of implementing authorization at the application layer in Hasura (instead of using RLS and passing user-details via current session settings in the postgres connection) had significant benefits, which we’ll soon see.
To summarise, now that authorization is declarative and available at a table, view or even a function (if the function returns SETOF) it is possible to create a single SQL query that has the authorization rules.
GraphQL query → GraphQL AST → Internal AST with authorization rules → SQL AST → SQL
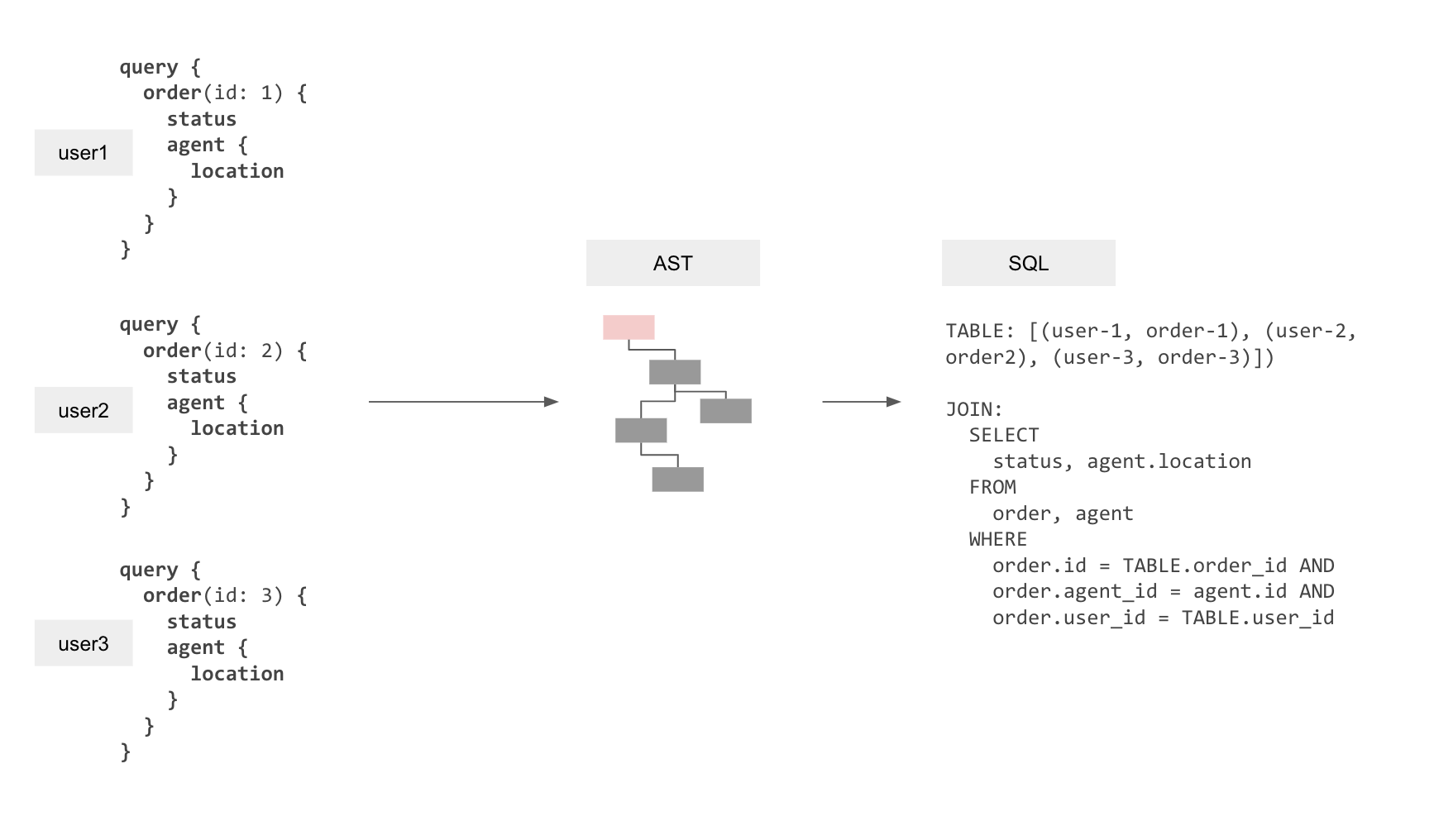
Idea #3: Batch multiple live-queries into one SQL query
With only ideas #1, #2 implemented we would still result in the situation where a 100k connected clients could result in a proportional load of 100k postgres queries to fetch the latest data (let’s say if 100k updates happen, 1 update relevant to each client).
However, considering that we have all the application-user level session variables available at the API layer, we can actually create a single SQL query to re-fetch data for a number of clients all at once!
Let’s say that we have clients running a subscription to get the latest order status and the delivery agent location. We can create a “relation” in-query that contains all the query-variables (the order IDs) and the session variables (the user IDs) as different rows. We can then “join” the query to fetch the actual data with this relation to ensure that we get the latest data for multiple clients in a single response. Each row in this response contains the final result for each user. This will allow fetching the latest result for multiple users at the same time, even though the parameters and the session variables that they provide are completely dynamic and available only at query-time.
When do we refetch?
We experimented with several methods of capturing events from the underlying Postgres database to decide when to refetch queries.
- Listen/Notify: Requires instrumenting all tables with triggers, events consumed by consumer (the web-server) might be dropped in case of the consumer restarting or a network disruption.
- WAL: Reliable stream, but LR slots are expensive which makes horizontal scaling hard, and are often not available on managed database vendors. Heavy write loads can pollute the WAL and will need throttling at the application layer.
After these experiments, we’ve currently fallen back to interval based polling to refetch queries. So instead of refetching when there is an appropriate event, we refetch the query based on a time interval. There were two major reasons for doing this:
- Mapping database events to a live query for a particular client is possible to some extent when the declarative permissions and the conditions used in the live queries are trivial (like
order_id= 1 anduser_id= cookie.session_id) but becomes intractable for anything complicated (say the query uses'status' ILIKE 'failed_%'). The declarative permissions can also sometimes span across tables. We made significant investment in investigating this approach coupled with basic incremental updating and have a few small projects in production that takes an approach similar to this talk. - For any application unless the write throughput is very small, you’ll end up throttling/debouncing events over an interval anyway.
The tradeoff with this approach is latency when write-loads are small. Refetching can be done immediately, instead after X ms. This can be alleviated quite easily, by tuning the refetch interval and the batch size appropriately. So far we have focussed on removing the most expensive bottleneck first, the query refetching. That said, we will continue to look at improvements in the months to come, especially to use event dependency (in cases where it is applicable) to potentially reduce the number of live queries that are refetched every interval.
Please do note that we have drivers internally for other event based methods and would love to work with you if you have a use-case where the current approach does not suffice. Hit us up on our discord, and we’ll help you run benchmarks and figure out the best way to proceed!
Testing
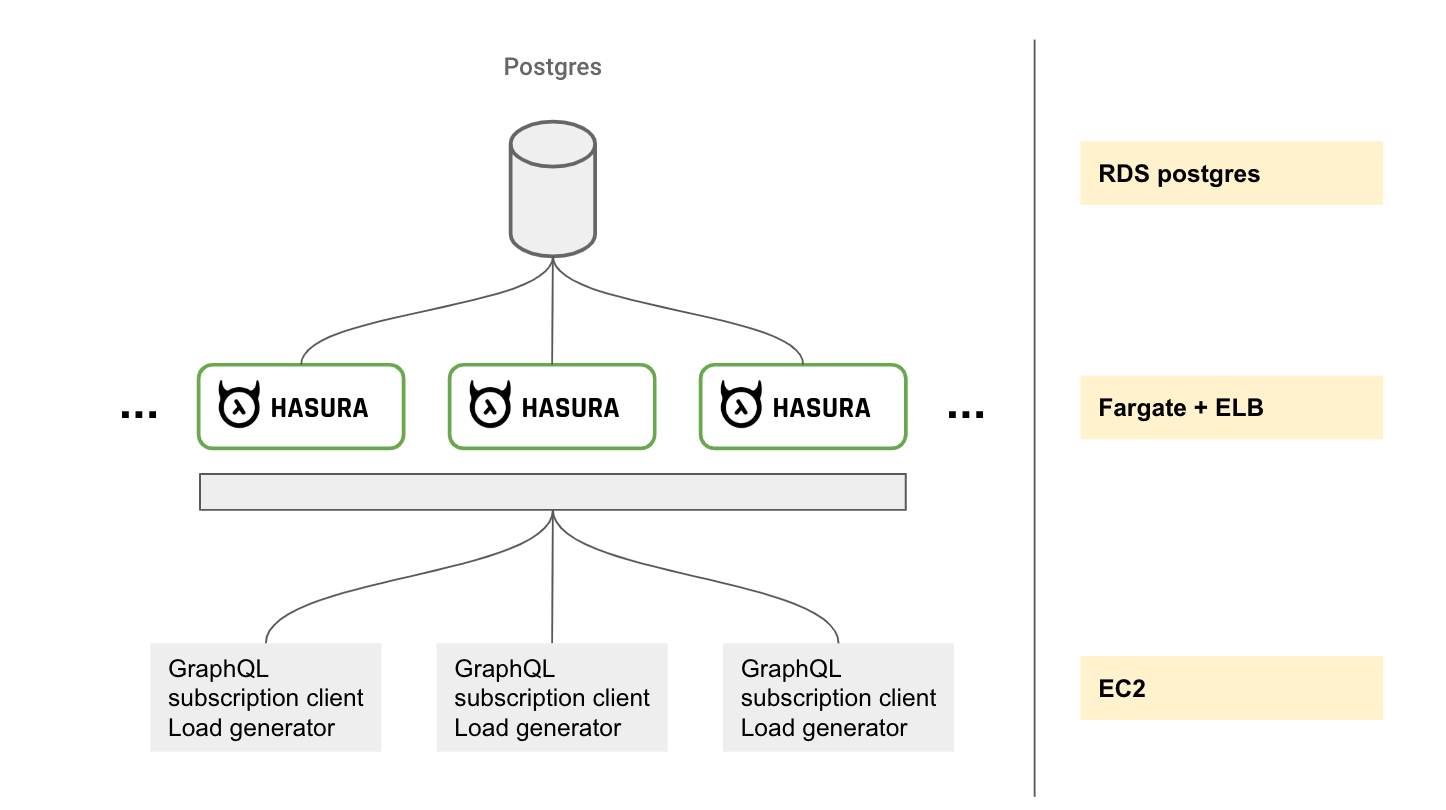
Testing scalability & reliability for live-queries with websockets has been a challenge. It took us a few weeks to build the testing suite and the infra automation tooling. This is what the setup looks like:
-
A nodejs script that runs a large number of GraphQL live-query clients and logs events in memory which are later ingested into a database. [github]
-
A script that creates a write load on the database that causes changes across all clients running their live queries (1 million rows are updated every second).
-
Once the test suites finish running, a verification script runs on the database where the logs/events were ingested to verify that there were no errors and all events were received.
-
Tests are considered valid only if:
- There are 0 errors in the payload received
- Avg latency from time of creation of event to receipt on the client is less than 1000ms
Benefits of this approach
Hasura makes live-queries easy and accessible. The notion of queries is easily extended to live-queries without any extra effort on the part of the developer using GraphQL queries. This is the most important thing for us.
- Expressive/featureful live queries with full support for Postgres operators/aggregations/views/functions etc
- Predictable performance
- Vertical & Horizontal scaling
- Works on all cloud/database vendors
Future work:
Reduce load on Postgres by:
- Mapping events to active live queries
- Incremental computation of result set