16 KiB
| title | authors | image | tags | |||||
|---|---|---|---|---|---|---|---|---|
| ML code generation vs coding by hand - a hypothesis of the future |
|
/img/language-lifecycle-copilot.png |
|
import Link from '@docusaurus/Link'; import useBaseUrl from '@docusaurus/useBaseUrl'; import InBlogCta from './components/InBlogCta'; import WaspIntro from './_wasp-intro.md'; import ImgWithCaption from './components/ImgWithCaption'
We are working on a config language / DSL for building web apps that integrates with React & Node.js. A number of times we've been asked “Why are you bothering creating a new language for web app development? Isn’t Github Copilot* soon going to be generating all the code for you?”.
This is on our take on the situation and what we think things might look like in the future.
Why (ML) code generation?
In order to make development faster, we came up with IDE autocompletion - e.g. if you are using React and start typing componentDid, IDE will automatically offer to complete it to componentDidMount() or componentDidLoad(). Besides saving keystrokes, maybe even more valuable is being able to see what methods/properties are available to us within a current scope. IDE being aware of the project structure and code hierarchy also makes refactoring much easier.
Although that’s already great, how do we take it to the next level? Traditional IDE support is based on rules written by humans and if we e.g. wanted to make IDE capable of implementing common functions for us, there would be just too many of them to catalogize and maintain by hand.
If there was only a way for a computer to analyze all the code we’ve written so far and learn by itself how to autocomplete our code and what to do about humanity in general, instead of us doing all the hard work - oh, wait, ...
Delicious and moist cake aside, we actually have this working! IDEs can now do some really cool things like proposing the full implementation of a function, based on its name and the accompanying comments:
This is pretty amazing! The example above is powered by Github Copilot - it’s essentially a neural network trained on a huge amount of publicly available code. I will not get into the technical details of how it works under the hood, but there are a lot of great articles covering the science behind it.
Seeing this, questions arise - what does this mean for the future of programming? Is this just IDE autocompletion on steroids or something more? Do we need to keep bothering with manually writing code, if we can just type in the comments what we want and that’s it?
The cake is a lie** - who maintains the code once it’s generated?
**a reference to Portal, a famous video game where AI conducts experiments on humans while pretending to be well-intended and promising them a cake if they follow through. The AI eventually ends up embedded in a potato.
When thinking about how ML code generation affects the overall development process, there is one thing to consider that often doesn’t immediately spring to mind when looking at the awesome Copilot examples.
:::note For the purposes of this post, I will not delve into the questions of code quality, security, legal & privacy issues, pricing, and others of similar character that are often brought up in these early days of ML code generation. Let’s just assume all this is sorted out and see what happens next. :::
The question is - what happens with the code once it is generated? Who is responsible for it and who will maintain and refactor it in the future?
Although ML code generation helps with getting the initial code written, it cannot do much beyond that - if that code is to be maintained and changed in the future (and if anyone uses it, it is), the developer still needs to fully own and understand it.
Imagine all we had was an assembly language, but IDE completion worked really well for it, and you could say “implement a function that sorts an array, ascending” and it would produce the required code perfectly. Would that still be something you’d like to return to in the future when you need to change your sort to descending 😅 ?
In other words, it means Copilot and similar solutions do not reduce the code complexity nor the amount of knowledge required to build features, they just help write the initial code faster, and bring the knowledge/examples closer to the code (which is really helpful). If a developer accepts the generated code blindly, they are just creating tech debt and pushing it forward.
Meet the big A - Abstraction 👆
If Github Copilot and others cannot solve all our troubles of learning how to code and understanding in detail how session management via JWT works, what can?
Abstraction - that’s how programmers have been dealing with the code repetition and reducing complexity for decades - by creating libraries, frameworks, and languages. It is how we advanced from vanilla JS and direct DOM manipulation to jQuery and finally to UI libraries such as React and Vue.
Introducing abstractions inevitably means giving up on a certain amount of power and flexibility (e.g. when summing numbers in Python you don’t get to exactly specify which CPU registers are going to be used for it), but the point is that, if done right, you don’t need nor want such power in the majority of the cases.
The only way not to be responsible for a piece of code is that it doesn’t exist in the first place.
Because as soon as pixels on the screen change their color it’s something you have to worry about, and that is why the main benefit of all the frameworks, languages, etc. is less code == less decisions == less responsibility.
The only way to have less code is to make less decisions and provide fewer details to the computer on how to do a certain task - ideally, we’d just state what we want and we wouldn’t even care about how it is done, as long as it’s within the time/memory/cost boundaries we have (so we might need to state those as well).
Let’s take a look at the very common (and everyone’s favorite) feature in the world of web apps - authentication (yaay ☠️ 🔫)! The typical code for it will look something like this:
import jwt from 'jsonwebtoken'
import SecurePassword from 'secure-password'
import util from 'util'
import prisma from '../dbClient.js'
import { handleRejection } from '../utils.js'
import config from '../config.js'
const jwtSign = util.promisify(jwt.sign)
const jwtVerify = util.promisify(jwt.verify)
const JWT_SECRET = config.auth.jwtSecret
export const sign = (id, options) => jwtSign({ id }, JWT_SECRET, options)
export const verify = (token) => jwtVerify(token, JWT_SECRET)
const auth = handleRejection(async (req, res, next) => {
const authHeader = req.get('Authorization')
if (!authHeader) {
return next()
}
if (authHeader.startsWith('Bearer ')) {
const token = authHeader.substring(7, authHeader.length)
let userIdFromToken
try {
userIdFromToken = (await verify(token)).id
} catch (error) {
if (['TokenExpiredError', 'JsonWebTokenError', 'NotBeforeError'].includes(error.name)) {
return res.status(401).send()
} else {
throw error
}
}
const user = await prisma.user.findUnique({ where: { id: userIdFromToken } })
if (!user) {
return res.status(401).send()
}
const { password, ...userView } = user
req.user = userView
} else {
return res.status(401).send()
}
next()
})
const SP = new SecurePassword()
export const hashPassword = async (password) => {
const hashedPwdBuffer = await SP.hash(Buffer.from(password))
return hashedPwdBuffer.toString("base64")
}
export const verifyPassword = async (hashedPassword, password) => {
try {
return await SP.verify(Buffer.from(password), Buffer.from(hashedPassword, "base64"))
} catch (error) {
console.error(error)
return false
}
}
And this is just a portion of the backend code (and for the email & password method only)! As you can see, we have quite a lot of flexibility here and get to do/specify things like:
- choose the implementation method for auth (e.g. session or JWT-based)
- choose the exact npm packages we want to use for the token (if going with JWT) and password management
- parse the auth header and specify for each value (
Authorization,Bearer, …) how to respond - choose the return code (e.g. 401, 403) for each possible outcome
- choose how the password is decoded/encoded (base64)
On one hand, it’s really cool to have that level of control and flexibility in our code, but on the other hand, it’s quite a lot of decisions (== mistakes) to be made, especially for something as common as authentication!
If somebody later asks “so why exactly did you choose secure-password npm package, or why exactly base64 encoding?” it’s something we should probably answer with something else rather than “well, there was that SO post from 2012 that seemed pretty legit, it had almost 50 upvotes. Hmm, can’t find it now though. Plus, it has ‘secure’ in the name, that sounds good, right?”
Another thing to keep in mind is that we should also track how things change over time, and make sure that after a couple of years we’re still using the best practices and that the packages are regularly updated.
If we try to apply the principles from above (less code, less detailed instructions, stating what we want instead of how it needs to be done), the code for auth might look something like this:
auth: {
userEntity: User,
methods: [ EmailAndPassword, LinkedIn, Google ],
onAuthFailedRedirectTo: "/login",
onAuthSucceededRedirectTo: "/dashboard"
}
Based on this, the computer/compiler could take care of all the stuff mentioned above, and then depending on the level of abstraction, provide some sort of interface (e.g. form components, or functions) to “hook” in with our own e.g. React/Node.js code (btw this is how it actually works in Wasp).
We don’t need to care what exact packages or encryption methods are used beneath the hood - it is the responsibility we trust with the authors and maintainers of the abstraction layer, just like we trust that Python knows the best how to sum two numbers on the assembly level and that it is kept in sync with the latest advancements in the field. The same happens when we rely on the built-in data structures or count on the garbage collector to manage our program’s memory well.
But my beautiful generated codez 😿💻! What happens with it then?
Don’t worry, it’s all still here and you can generate all the code you wish! The main point to understand here is that ML code generation and framework/language development complement rather than replace each other and are here to stay, which is ultimately a huge win for the developer community - they will keep making our lives easier and allow us to do more fun stuff (instead of implementing auth or CRUD API for the n-th time)!
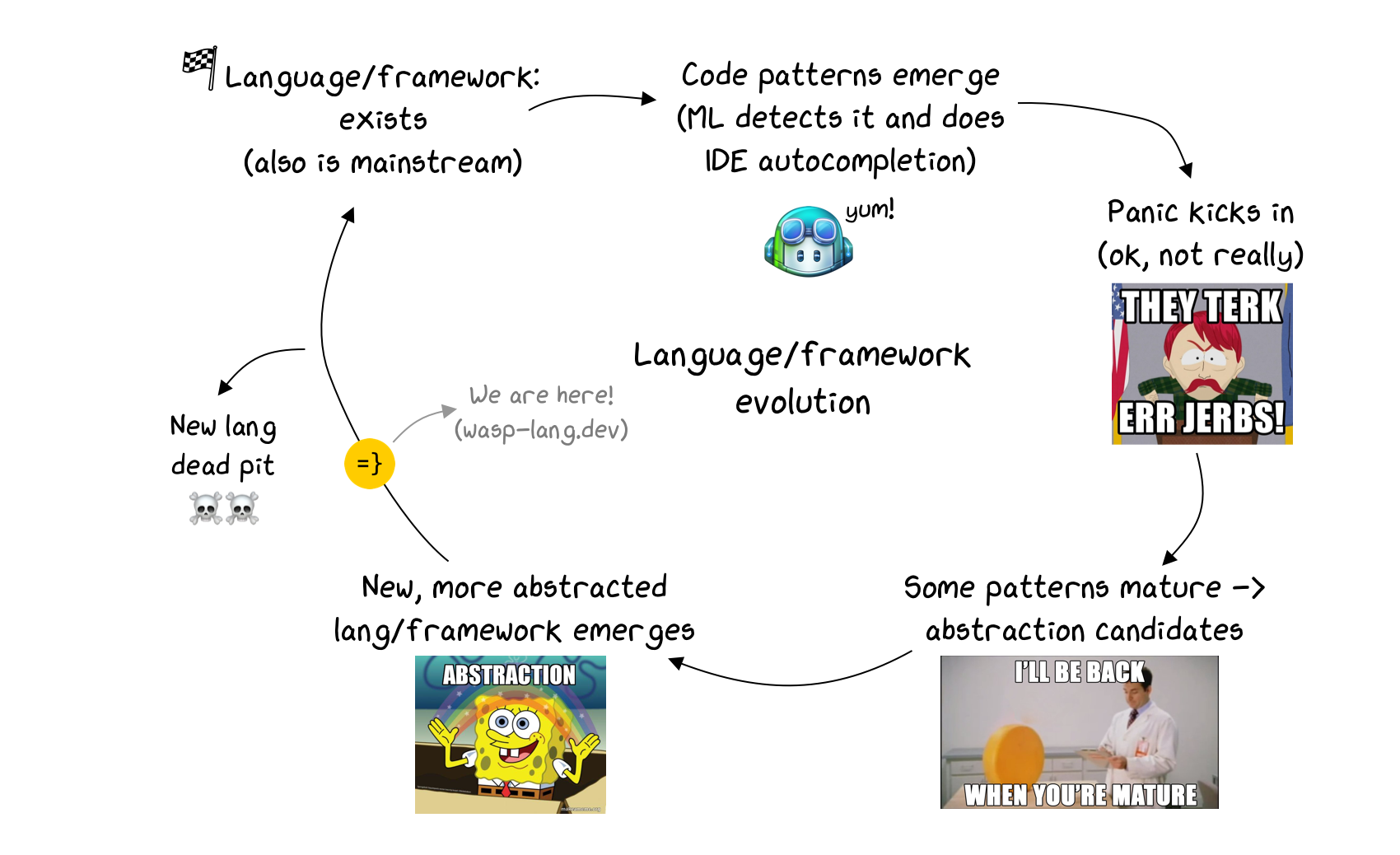
I see the evolution here as a cycle (or an upward spiral in fact, but that’s beyond my drawing capabilities):
- language/framework exists, is mainstream, and a lot of people use it
- patterns start emerging (e.g. implementing auth, or making an API call) → ML captures them, offers via autocomplete
- some of those patterns mature and become stable → candidates for abstraction
- new, more abstract, language/framework emerges
- back to step 1.
Conclusion
This means we are winning on both sides - when the language is mainstream we can benefit from ML code generation, helping us write the code faster. On the other hand, when the patterns of code we don’t want to repeat/deal with emerge and become stable we get a whole new language or framework that allows us to write even less code and care about fewer implementation details!
*Not to be biased, there are also other solutions offering similar functionality - e.g. TabNine, Webstorm has its own, Kite, GPT Code Clippy (OSS attempt) et al., but Github Copilot recently made the biggest splash.
Writing that informed this post
- Is GitHub Copilot a blessing, or a curse? (fast.ai) - an objective and extremely well-written overview of GitHub Copilot with real-world examples
- 6 Reasons Why You Should Avoid GitHub Copilot and “Fly Solo” Instead - brings up and questions the potential downsides of ML code generation and Github Copilot
- Github Copilot Wants to Play Chess Instead of Code - a fresh approach to GitHub Copilot where it is used as a conversation partner instead of writing code!
- Conversational Programming - a forward looking post that proposes a future where AI will serve as a "sparring partner" and help us reach the optimal solutions through iterations, instead of programmer doing all the work by themself.
Thanks to the reviewers
Jeremy Howard, Maxi Contieri, Mario Kostelac, Vladimir Blagojevic, Ido Nov, Krystian Safjan, Favour Kelvin, Filip Sodic, Shayne Czyzewski and Martin Sosic - thank you for your generous comments, ideas and suggestions! You made this post better and made sure I don't go overboard with memes :).