| figures | ||
| LR | ||
| models | ||
| results | ||
| .gitignore | ||
| LICENSE | ||
| net_interp.py | ||
| QA.md | ||
| README.md | ||
| RRDBNet_arch.py | ||
| test.py | ||
| transer_RRDB_models.py | ||
ESRGAN (Enhanced SRGAN) [🚀 BasicSR] [Real-ESRGAN]
✨ New Updates.
We have extended ESRGAN to Real-ESRGAN, which is a more practical algorithm for real-world image restoration. For example, it can also remove annoying JPEG compression artifacts.
You are recommended to have a try 😃
In the Real-ESRGAN repo,
- You can still use the original ESRGAN model or your re-trained ESRGAN model. The model zoo in Real-ESRGAN.
- We provide a more handy inference script, which supports 1) tile inference; 2) images with alpha channel; 3) gray images; 4) 16-bit images.
- We also provide a Windows executable file
RealESRGAN-ncnn-vulkanfor easier use without installing the environment. This executable file also includes the original ESRGAN model. - The full training codes are also released in the Real-ESRGAN repo.
Welcome to open issues or open discussions in the Real-ESRGAN repo.
- If you have any question, you can open an issue in the Real-ESRGAN repo.
- If you have any good ideas or demands, please open an issue/discussion in the Real-ESRGAN repo to let me know.
- If you have some images that Real-ESRGAN could not well restored, please also open an issue/discussion in the Real-ESRGAN repo. I will record it (but I cannot guarantee to resolve it😛).
Here are some examples for Real-ESRGAN:

[Paper]
Xintao Wang, Liangbin Xie, Chao Dong, Ying Shan
Applied Research Center (ARC), Tencent PCG
Shenzhen Institutes of Advanced Technology, Chinese Academy of Sciences
As there may be some repos have dependency on this ESRGAN repo, we will not modify this ESRGAN repo (especially the codes).
The following is the original README:
The training codes are in 🚀 BasicSR. This repo only provides simple testing codes, pretrained models and the network interpolation demo.
BasicSR is an open source image and video super-resolution toolbox based on PyTorch (will extend to more restoration tasks in the future).
It includes methods such as EDSR, RCAN, SRResNet, SRGAN, ESRGAN, EDVR, etc. It now also supports StyleGAN2.
Enhanced Super-Resolution Generative Adversarial Networks
By Xintao Wang, Ke Yu, Shixiang Wu, Jinjin Gu, Yihao Liu, Chao Dong, Yu Qiao, Chen Change Loy
We won the first place in PIRM2018-SR competition (region 3) and got the best perceptual index. The paper is accepted to ECCV2018 PIRM Workshop.
🚩 Add Frequently Asked Questions.
For instance,
- How to reproduce your results in the PIRM18-SR Challenge (with low perceptual index)?
- How do you get the perceptual index in your ESRGAN paper?
BibTeX
@InProceedings{wang2018esrgan,
author = {Wang, Xintao and Yu, Ke and Wu, Shixiang and Gu, Jinjin and Liu, Yihao and Dong, Chao and Qiao, Yu and Loy, Chen Change},
title = {ESRGAN: Enhanced super-resolution generative adversarial networks},
booktitle = {The European Conference on Computer Vision Workshops (ECCVW)},
month = {September},
year = {2018}
}

The RRDB_PSNR PSNR_oriented model trained with DF2K dataset (a merged dataset with DIV2K and Flickr2K (proposed in EDSR)) is also able to achive high PSNR performance.
| Method | Training dataset | Set5 | Set14 | BSD100 | Urban100 | Manga109 |
|---|---|---|---|---|---|---|
| SRCNN | 291 | 30.48/0.8628 | 27.50/0.7513 | 26.90/0.7101 | 24.52/0.7221 | 27.58/0.8555 |
| EDSR | DIV2K | 32.46/0.8968 | 28.80/0.7876 | 27.71/0.7420 | 26.64/0.8033 | 31.02/0.9148 |
| RCAN | DIV2K | 32.63/0.9002 | 28.87/0.7889 | 27.77/0.7436 | 26.82/ 0.8087 | 31.22/ 0.9173 |
| RRDB(ours) | DF2K | 32.73/0.9011 | 28.99/0.7917 | 27.85/0.7455 | 27.03/0.8153 | 31.66/0.9196 |
Quick Test
Dependencies
- Python 3
- PyTorch >= 1.0 (CUDA version >= 7.5 if installing with CUDA. More details)
- Python packages:
pip install numpy opencv-python
Test models
- Clone this github repo.
git clone https://github.com/xinntao/ESRGAN
cd ESRGAN
- Place your own low-resolution images in
./LRfolder. (There are two sample images - baboon and comic). - Download pretrained models from Google Drive or Baidu Drive. Place the models in
./models. We provide two models with high perceptual quality and high PSNR performance (see model list). - Run test. We provide ESRGAN model and RRDB_PSNR model and you can config in the
test.py.
python test.py
- The results are in
./resultsfolder.
Network interpolation demo
You can interpolate the RRDB_ESRGAN and RRDB_PSNR models with alpha in [0, 1].
- Run
python net_interp.py 0.8, where 0.8 is the interpolation parameter and you can change it to any value in [0,1]. - Run
python test.py models/interp_08.pth, where models/interp_08.pth is the model path.

Perceptual-driven SR Results
You can download all the resutls from Google Drive. (✔️ included; ➖ not included; ⭕ TODO)
HR images can be downloaed from BasicSR-Datasets.
| Datasets | LR | ESRGAN | SRGAN | EnhanceNet | CX |
|---|---|---|---|---|---|
| Set5 | ✔️ | ✔️ | ✔️ | ✔️ | ⭕ |
| Set14 | ✔️ | ✔️ | ✔️ | ✔️ | ⭕ |
| BSDS100 | ✔️ | ✔️ | ✔️ | ✔️ | ⭕ |
| PIRM (val, test) |
✔️ | ✔️ | ➖ | ✔️ | ✔️ |
| OST300 | ✔️ | ✔️ | ➖ | ✔️ | ⭕ |
| urban100 | ✔️ | ✔️ | ➖ | ✔️ | ⭕ |
| DIV2K (val, test) |
✔️ | ✔️ | ➖ | ✔️ | ⭕ |
ESRGAN
We improve the SRGAN from three aspects:
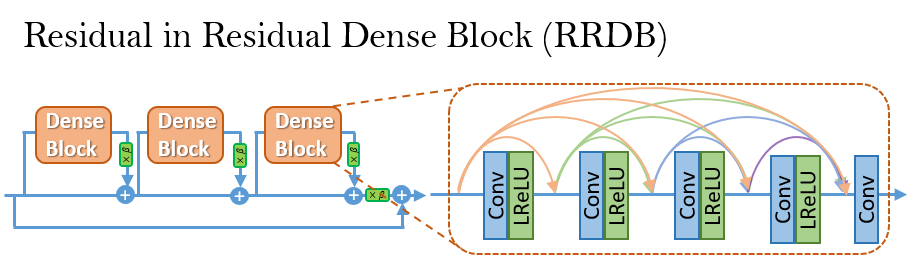
- adopt a deeper model using Residual-in-Residual Dense Block (RRDB) without batch normalization layers.
- employ Relativistic average GAN instead of the vanilla GAN.
- improve the perceptual loss by using the features before activation.
In contrast to SRGAN, which claimed that deeper models are increasingly difficult to train, our deeper ESRGAN model shows its superior performance with easy training.

Network Interpolation
We propose the network interpolation strategy to balance the visual quality and PSNR.

We show the smooth animation with the interpolation parameters changing from 0 to 1. Interestingly, it is observed that the network interpolation strategy provides a smooth control of the RRDB_PSNR model and the fine-tuned ESRGAN model.


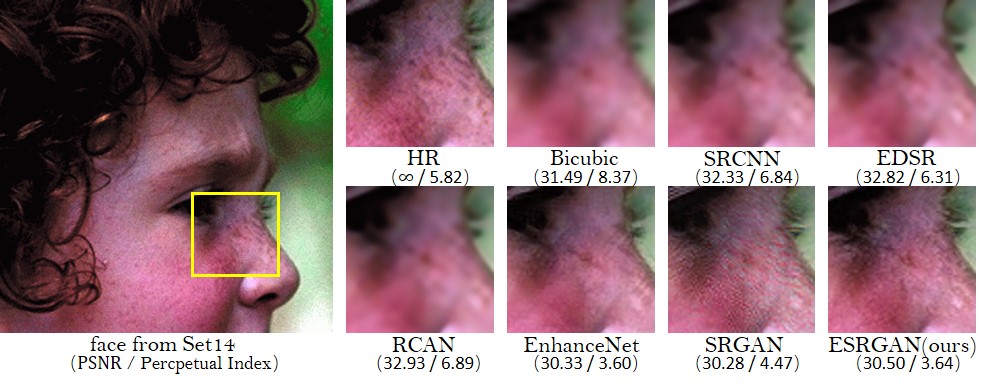
Qualitative Results
PSNR (evaluated on the Y channel) and the perceptual index used in the PIRM-SR challenge are also provided for reference.



Ablation Study
Overall visual comparisons for showing the effects of each component in ESRGAN. Each column represents a model with its configurations in the top. The red sign indicates the main improvement compared with the previous model.

BN artifacts
We empirically observe that BN layers tend to bring artifacts. These artifacts, namely BN artifacts, occasionally appear among iterations and different settings, violating the needs for a stable performance over training. We find that the network depth, BN position, training dataset and training loss have impact on the occurrence of BN artifacts.

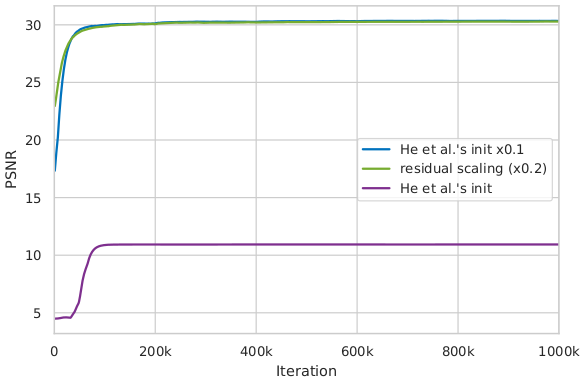
Useful techniques to train a very deep network
We find that residual scaling and smaller initialization can help to train a very deep network. More details are in the Supplementary File attached in our paper.
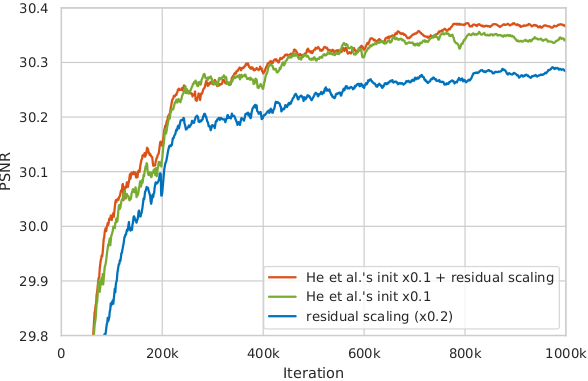
The influence of training patch size
We observe that training a deeper network benefits from a larger patch size. Moreover, the deeper model achieves more improvement (∼0.12dB) than the shallower one (∼0.04dB) since larger model capacity is capable of taking full advantage of larger training patch size. (Evaluated on Set5 dataset with RGB channels.)

