| Examples | ||
| PencilSketch | ||
| _config.yml | ||
| LICENSE | ||
| poster.pdf | ||
| README.md | ||
| sketchback.ipynb | ||
| sketchback.py | ||
Sketchback: Convolutional Sketch Inversion using Keras
Keras implementation of sketch inversion using deep convolution neural networks (synthesising photo-realistic images from pencil sketches) following the work of Convolutional Sketch Inversion and Scribbler.
We focused on sketches of human faces and architectural drawings of buildings. However according to Scribbler and our experimentation with their proposed framework, we believe that given a large dataset and ample training time, this network could generalize to other categories as well.
We trained the model using a dataset generated from a large database of face images, and then fine-tuned the network to fit the purpose of architectural sketches. You can find our reserach poster here.
Results
Faces
 |
 |
 |
 |
Buildings
 |
 |
 |
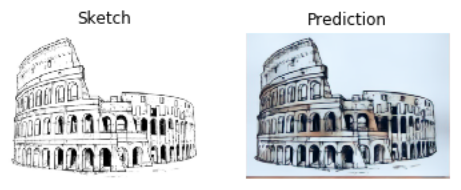 |
Datasets
We used the following datasets to train, validate and test our model:
- Large-scale CelebFaces Attributes (CelebA) dataset. CelebA dataset contains 202,599 celebrity face images of 10,177 identities. It covers large pose variation and background clutter. We used this dataset to train the network.
- ZuBuD Image Database. The ZuBuD dataset is provided by the computer vision lab of ETH Zurich. It contains 1005 images of 201 buildings in Zurich; 5 images per building from different angles.
- CUHK Face Sketch (CUFS) database. This dataset contains 188 hand-drawn face sketches and their corresponding photographs. We used the CUHK student database for testing our model.
- We finally used various building sketches from Google Images for testing
Sketching
The datasets were simulated, i.e. the sketches were generated, using the following methods (with the exception of the CUHK dataset, which contains sketches and the corresponding images)
Furthermore, due to the low number of images of buildings available, we applied various augmentations on the ZuBuD dataset to produce more images using the following image augmentation tool
Network Architecture
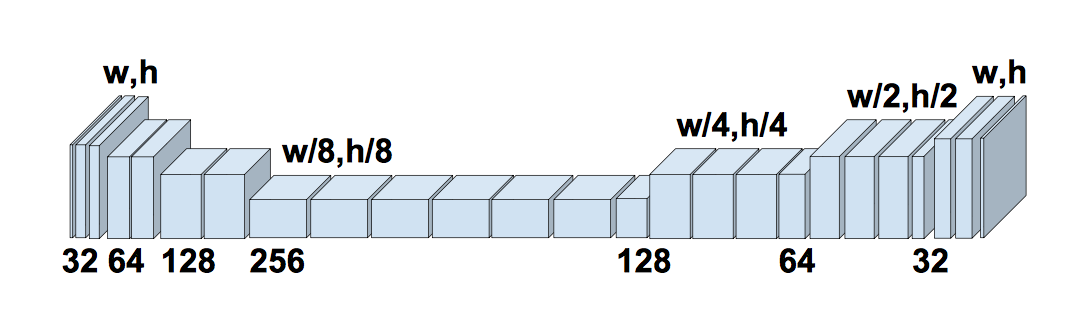
We used the network architecture used in Scribbler. The generator follows an encoder-decoder design, with down-sampling steps, followed by residual layers, followed by up-sampling steps.
Loss Functions
The Loss function was computed as the weighted average of three loss functions; namely: pixel loss, total variation loss, and feature loss.
The pixel loss was computed as:
![]()
The feature loss was computed as:

The total variation loss was used to encourage smoothness of the output, and was computed as
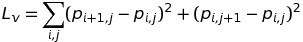
Where phi(x) is the output of the fourth layer in a pre-trained model (VGG16 relu_2_2) to feature transform the targets and predictions.
The total loss is then computed as
Lt = wpLp + wfLf + wvLv
For the present application, wf = 0.001, wp = 1, wv = 0.00001
Weights
For your convience you can find the following weights here:
- Face Weights after training the network on the CelebA dataset using the Pencil Sketchify method
- Building Weights after fine-tuning the network for the building sketches using the augmented ZuBuD dataset with the Pencil Sketchify method
Todo
- Training with a larger building dataset using a variety of sketch styles to improve the generality of the network
- Adding adversarial loss to the network.
- Using sketch anti-roughing to unify the styles of the training and input sketches.
- Passing the sketch results to a super-resolution network to improve image clarity.
- Increasing the image size of the training data.
License
MIT