387 KiB
![]()
Данный репозиторий представляет собой наглядную шпаргалку по основным темам в области Backend-разработки. Весь материал разбит на главы, которые включают в себя разные темы. В каждой теме можно выделить три основные части:
- Визуальная часть - различные изображения/таблицы/шпаргалки для лучшего понимания (может отсутствовать). Все рисунки и таблицы сделаны с нуля, специально для этого репозитория.
- Краткое описание - очень краткая выжимка информации с перечнем основных терминов и понятий. На термины навешиваются гиперссылки ведущие на соответствующий раздел в Википедии или подобном справочном ресурсе.
- Ссылки на источники - ресурсы, где можно найти полную информацию по конкретному вопросу (они скрыты под спойлером, который раскрывается при нажатии). По возможности, указываются максимально авторитетные источники, либо же те, которые предоставляют информацию максимально простым и понятным языком.
🛠 Репозиторий находится в стадии активной разработки, поэтому постоянно обновляется и дополняется (см. roadmap).
🤝 Если у Вас есть идеи как сделать проект лучше, не стесняйтесь присылать issues и pull requests.
🌙 Для лучшего восприятия включите темную тему.
Содержание
Сеть и интернет
Интернет - это всемирная система объединяющая компьютерные сети со всего мира в единую сеть для хранения/передачи информации. Изначально Интернет разрабатывался для военных. Но вскоре он стал внедряться в учреждения образования (университеты), а затем его смогли использовать частные компании, которые начали организовывать сети провайдеров, предоставляющие услуги доступа в Интернет обычным гражданам. К началу 2020 года количество пользователей в сети Интернет перевалило за 4.5 млрд человек.
-
Как устроен Интернет
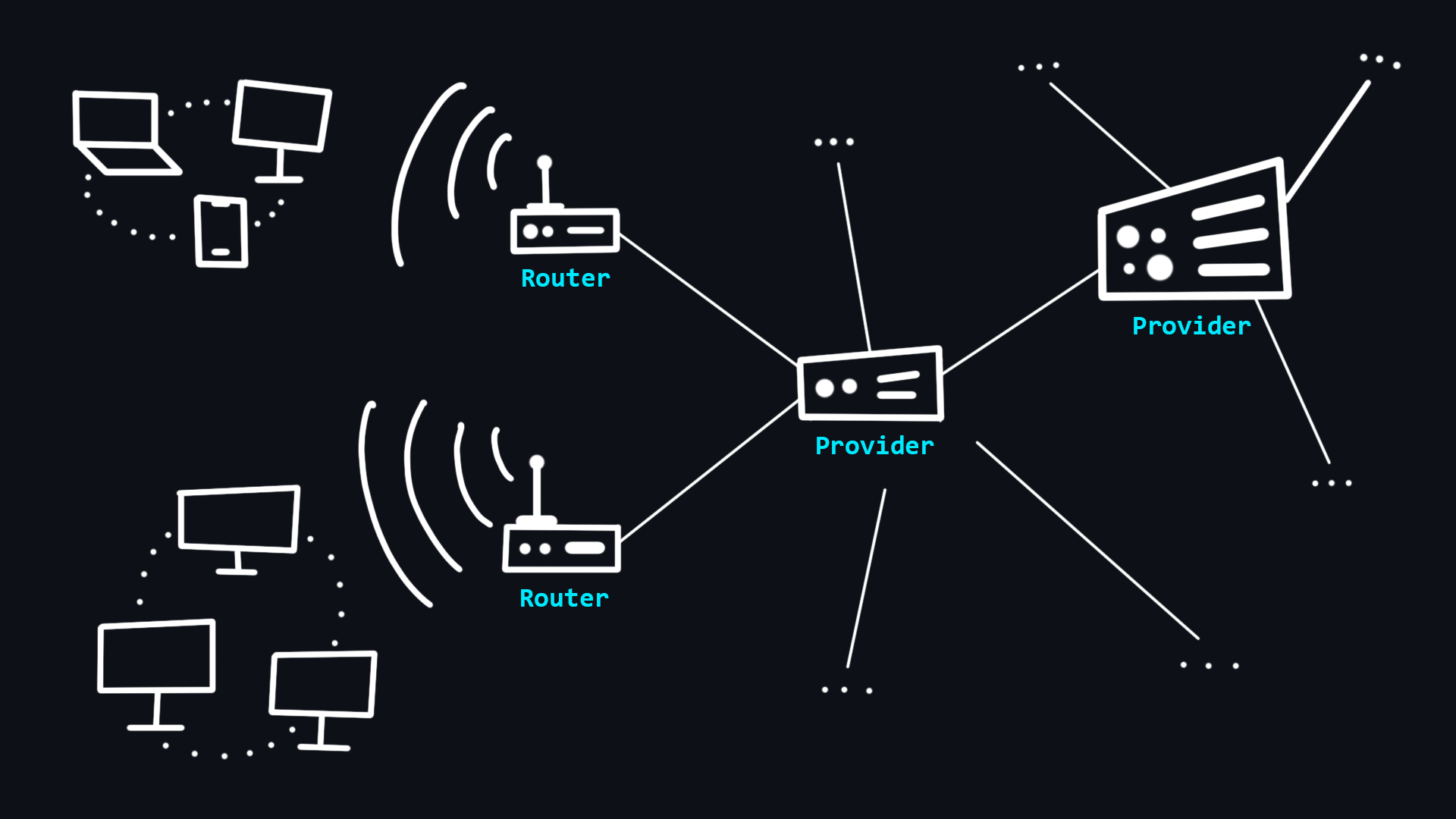
Ваш компьютер не имеет прямого доступа в Интернет. Вместо этого он имеет доступ к вашей локальной сети, к которой подключены другие устройства через проводное (Ethernet) или беспроводное (Wi-Fi) соединение. Организатором такой сети является специальный мини-компьютер – маршрутизатор. Это устройство связывает Вас с интернет-провайдером, который в свою очередь связан с другими провайдерами более высокого уровня. Таким образом, все эти взаимодействия образуют Интернет, и ваши сообщения всегда проходят транзитом через разные сети, прежде чем достигнут конечного получателя.
- Хост
(Host - принимающий) так называют любое устройство, которое находится в какой-либо сети.
- Сервер
(Serve - обслуживать) специальный компьютер в сети, который обслуживает запросы поступающие от других участников.

- Сетевые топологии
Существует несколько топологий (способов организации сети): Point to point (Точка-точка), Daisy chain (Цепочка/гирлянда), Bus (Шина), Ring (Кольцо), Star (Звезда) и Mesh (Сетка). Сам Интернет нельзя отнести к какой-то одной топологии, поскольку это невероятно сложная система смешанная разными топологиями.
- Хост
🔗 Ссылки на материалы
-
Что такое доменное имя

Доменные имена - это человеко-читаемые адреса веб-серверов, доступных в Интернете. Они состоят из частей (уровней) разделенных между собой точкой. Каждая из этих частей предоставляет специфическую информацию о доменном имени. Например страну, название сервиса, локализацию и т.д.
- Кто владеем доменными именами
Корпорация ICANN является основателем распределённой системы регистрации доменов. Она выдаёт аккредитации компаниям, которые хотят заниматься продажей доменов. Таким образом формируется конкурентный доменный рынок.
- Как купить доменное имя
Доменное имя нельзя купить навсегда. Оно выдается в аренду на определенный срок. Покупать домены лучше у аккредитованных регистраторов (найти их можно почти в любой стране).
- Кто владеем доменными именами
🔗 Ссылки на материалы
-
IP-адрес
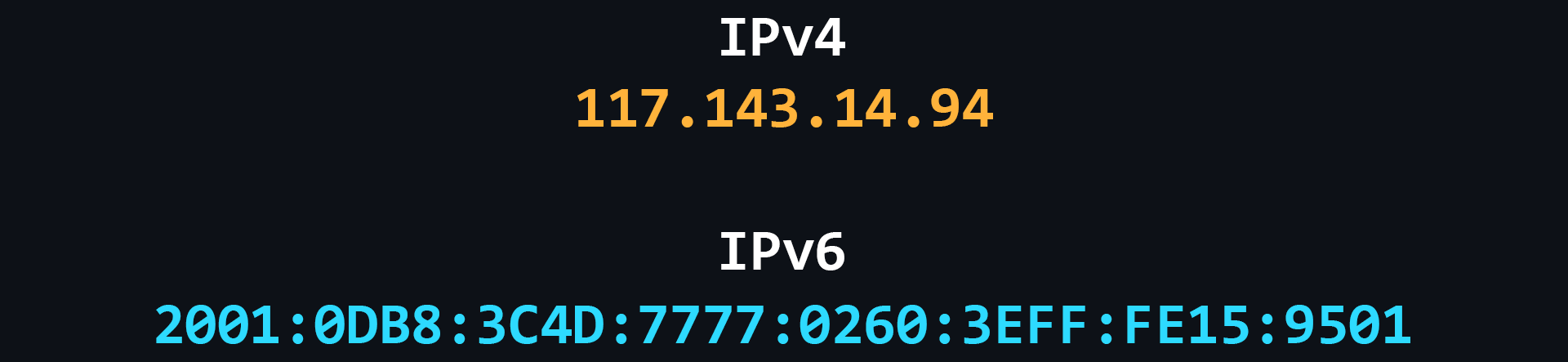
IP-адрес – уникальный числовой адрес, который используется для распознавания того или иного устройства в сети.
- Уровни видимости
- Внешний и доступный всем IP-адрес, который принадлежит Вашему провайдеру и используется для выхода в интернет сотен других пользователей.
- IP-адрес вашего роутера в локальной сети провайдера, той самой, с IP-адресом которой вы выходите в интернет.
- IP-адрес вашего компьютера в локальной (домашней) сети, созданной роутером, к которой вы можете подключать свои устройства. Как правило, имеет вид 192.168.XXX.XXX.
- Внутренний IP-адрес компьютера, недоступный извне и используемый только для общения между запущенными процессами. У всех он одинаковый – 127.0.0.1 или просто localhost.
- Порт
На одном устройстве (компьютере) может работать множество приложений, которые используют сеть. Для того, чтобы правильно распознать, куда и какие данные, пришедшие по сети, нужно доставить (в какое из приложений), используется специальный числовой номер – порт.
- IPv4
4 версия IP-протокола. Разработана в 1981 году и ограничивает адресное пространство около 4.3 млрд (2^32) возможными уникальными адресами.
- IPv6
Со временем распределение адресного пространства стало происходить значительно более быстрыми темпами, что вынудило создание новой версии IP-протокола для хранения большего количества адресов. IPv6 способен выдать 2^128 уникальных адресов.
- Уровни видимости
🔗 Ссылки на материалы
- 📄 IP адрес
- 📄 Всё об IP адресах и о том, как с ними работать – habr.com
- 📄 Как узнать IP-адрес в Linux
- 📺 Порты и перенаправление\открытие портов. Инструкция и объяснения на пальцах – YouTube
- 📄 Список зарезервированных портов TCP и UDP – Википедия
- 📄 Протоколы IPv4 и IPv6. В чем разница и что лучше?
- 📺 Адреса IPv6 | Компьютерные сети. Продвинутые темы – YouTube
- 📄 IPv6: как организовать миграцию и в чем преимущества перехода
- 📺 IPv6 - от слов к делу – YouTube
-
Что такое DNS
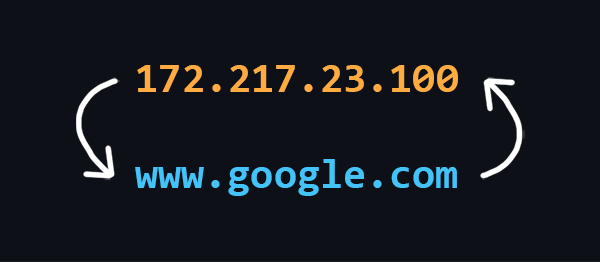
DNS (Domain Name System) - это децентрализованная система именования адресов в Интернете, которая позволяет создавать удобные для человека буквеные наименования (доменные имена) соответствующие числовым IP-адресам, которые используются компьютерами.
- Структура DNS
DNS состоит из множества независимых узлов, каждый из которых хранит только те данные, которые входят в его зону ответственности.
- DNS Resolver
Сервер, который расположен в непосредственной близости от вашего провайдера. Именно он выполняет поиск адресов по доменным именам, а также занимается их кэшированием (временным хранением для быстрой выдачи при последующих обращениях).
- DNS записи
- Запись A – связывает доменное имя с адресом IPv4.
- Запись AAAA – связывает доменное имя с адресом IPv6.
- Запись CNAME – перенаправляет на другое доменное имя.
- и другие – запись MX, запись NS, запись PTR, запись SOA.
- Структура DNS
🔗 Ссылки на материалы
-
Устройство веб-приложений
Современные веб-приложения состоят из двух частей: клиентской (frontend) и серверной (backend). Тем самым реализуя клиент-серверную архитектуру.
Задачами клиентской части являются:
- Реализация пользовательского интерфейса (внешний вид приложения)
- Для создания веб-страниц используется специальный язык разметки – HTML.
- Для стилизации шрифтов, расположения содержимого и т.д. используется язык стилей – CSS.
- Для добавления динамики и интерактивности – язык программирования JavaScript.
Как правило в чистом виде эти инструменты используются редко, поскольку для более удобной и быстрой разработки существуют так называемые фреймворки и препроцессоры.
- Cоздание функционала для формирования запросов к серверу
Как правило это различного вида формы ввода, с которыми можно удобно взаимодействовать.
- Приём данных от сервера и их последующая обработка для вывода на клиент
Задачи серверной части:
- Обработка клиентских запросов
Проверка на наличие прав и доступа, разного рода валидации и т.д.
- Выполнение бизнес логики
Здесь может подразумевается широкий спектр задач: работа с базами данных, обработка информации, вычисления и т.д. Это, так сказать, самое сердце мира Backend. Здесь и происходит все самое важное и интересное.
- Формирование ответа и отправка его на клиент
- Реализация пользовательского интерфейса (внешний вид приложения)
🔗 Ссылки на материалы
- 📄 Как работают веб-приложения – habr.com
- 📺 Как устроены веб-приложения? (Frontend/Backend) – YouTube
- 📺 Архитектура современных WEB приложений. Эволюция от А до Я – YouTube
- 📄 Что такое HTML за 7 минут
- 📄 Базовый курс по фронтенду – (MDN) mozilla.org
- 📄 Frontend Developer roadmap
- 📄 Нативные, гибридные и web-приложения в сравнении – medium.com
-
Браузеры и как они работают
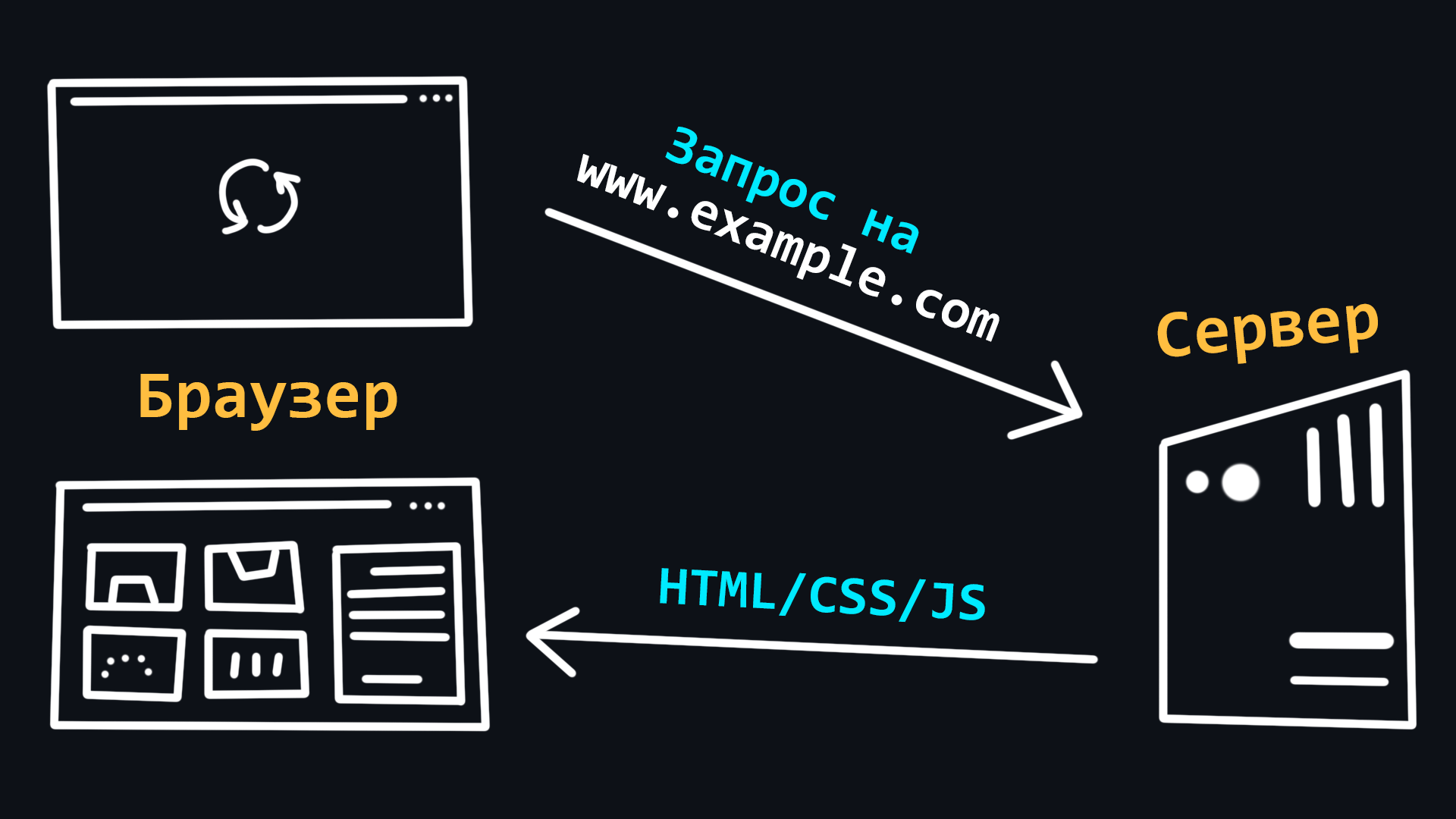
Браузер – клиент, с помощью которого можно отправлять запросы на сервер для получения файлов, которые впоследствии используются для отрисовки web-страниц. Если совсем упрощенно, то браузер можно воспринимать как программу для просмотра HTML-файлов, которая так же может искать и скачивать их из интернета.
- Принцип работы
Работа с запросами, отрисовка страниц, особенность работы вкладок (для каждой вкладки создается отдельный процесс, чтобы не допустить ситуации, при которой содержимое одной вкладки имеет возможность влиять на содержимое другой).
- Расширения (WebExtensions)
Позволяют менять пользовательский интерфейс браузера, модифицировать содержимое вебстраниц, изменять сетевые запросы браузера.
- Инструменты разработчика (DevTools)
Незаменимый инструмент любого веб-разработчика. Позволяет анализировать всю возможную информацию связанную с веб-страницами, мониторить их производительность, логи и, что для нас самое важное, отслеживать информацию о сетевых запросах.
- Принцип работы
🔗 Ссылки на материалы
- 📄 Как работают браузеры — MDN (mozilla.org)
- 📄 Как работают браузеры — введение в безопасность веб-приложений – habr.com
- 📄 Как браузер рисует страницы
- 📄 Важные аспекты работы браузера для разработчиков – habr.com
- 📄 Обзор всех инструментов разработчика Chrome DevTools – habr.com
- 📄 Что на самом деле происходит, когда пользователь вбивает в браузер адрес google.com – habr.com
- 📄 Принципы работы современных веб-браузеров
- 📄 Подробное объяснение того, как работает браузер (под капотом)
- 📺 Архитектура браузера. Движки и рендер. Самое подробное видео – YouTube
-
VPN и Proxy
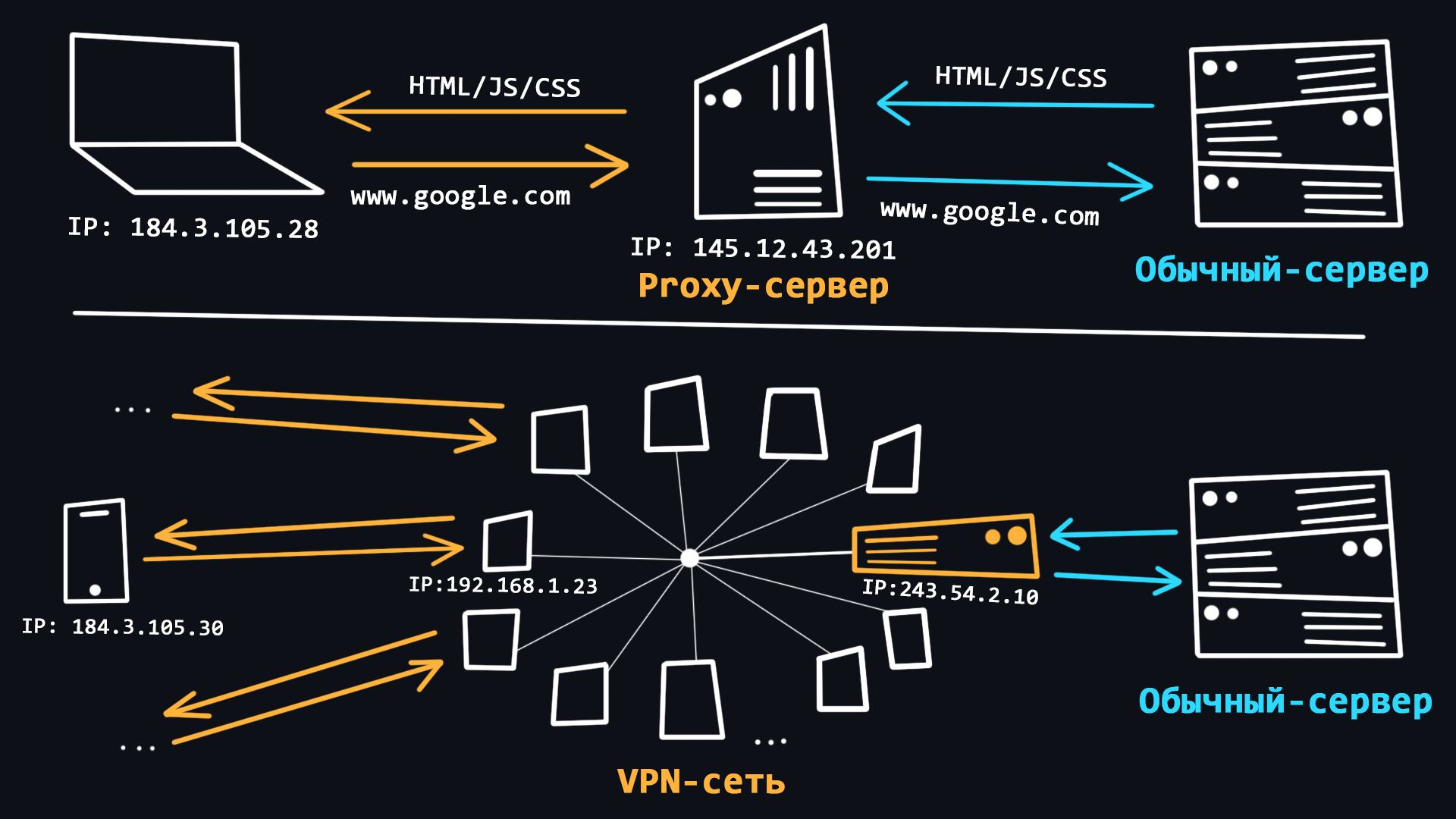
Использование VPN и Proxy довольно распространённое явление в последние годы. С помощью этих технологий пользователи могут получить базовую анонимность при серфинге в сети, а также обходить различные региональные блокировки.
- VPN (Virtual Private Network)
Технология позволяющая стать участником приватной сети (подобной вашей локальной), где запросы всех участников проходят через единый публичный IP-адрес. Это позволяет Вам смешаться в общей массе запросов от других участников.
- Простая процедура подключения и использования.
- Надежное шифрование трафика.
- Нет гарантии 100% анонимности, поскольку владелец сети знает IP-адреса всех участников.
- VPN бесполезны для работы с мультиаккаунтами и некоторыми программами, поскольку все аккаунты, работающие с одного VPN легко обнаруживаются и блокируются.
- Бесплатные VPN, как правило, имеют большую нагруженность, что приводит к нестабильной работе и снижению скорости загрузки данных.
- Простая процедура подключения и использования.
- Proxy (прокси-сервер)
Прокси это специальный сервер в сети, который выполняет роль посредника между Вами и конечным сервером к которому Вы намереваетесь обратиться. Когда Вы подключены к прокси-серверу все Ваши запросы будут выполняться от имени этого сервера, то есть IP-адрес и местоположение будут подменены.
- Возможность использовать индивидуальный IP-адрес, что позволяет работать с мультиаккаунтами.
- Стабильность соединения из-за отсутствия высоких нагрузок.
- Подключение через прокси предусмотрено в самой ОС и браузере, поэтому доп. ПО не требуется.
- Существуют разновидности прокси, которые обеспечивают высокий уровень анонимности.
- Ненадежность бесплатных решений, поскольку прокси-сервер может видеть и контролировать всё, что вы делаете в интернете.
- Возможность использовать индивидуальный IP-адрес, что позволяет работать с мультиаккаунтами.
- VPN (Virtual Private Network)
🔗 Ссылки на материалы
-
Хостинг
Хостинг (hosting) - специальная услуга, предоставляемая хостинг-провайдерами, которая позволяет арендовать пространство на сервере (который круглосуточно подключён к сети Интернет), где могут храниться ваши данные и файлы. Существуют различные варианты хостинга, где вы можете использовать не только дисковое пространство сервера, но и так же процессорную мощность для работы ваших сетевых приложений.
- Виртуальный хостинг
Один физический сервер, который распределяет свои ресурсы на нескольких арендаторов.
- VPS/VDS
Виртуальные серверы, эмулирующие работу отдельного физического сервера и предоставляемые в аренду клиенту с максимальными привилегиями.
- Выделенный сервер
Аренда полноценного физического сервера с полным доступом ко всем ресурсам. Как правило, это самая дорогая услуга.
- Облачный хостинг
Услуга которая использует ресурсы нескольких серверов. При аренде пользователь платит только за используемые по факту ресурсы.
- Колокация
Услуга предоставляющая клиенту возможность установить свое оборудование на территории провайдера.
- Виртуальный хостинг
🔗 Ссылки на материалы
- 📺 Что такое хостинг, домен и как устроен интернет на понятном языке – YouTube
- 📄 Что такое хостинг и домен сайта простыми словами
- 📄 Хостинг: что это, зачем и как выбрать
- 📄 Хостинг: варианты, сравнения, пользовательская статистика — habr.com
- 📄 VPS-хостинг и облачный хостинг: что выбрать и в чем разница? – habr.com
- 📄 Колокейшн: как, зачем и почему – habr.com
-
Сетевая модель OSI
№ Уровень Используемые протоколы 7 Прикладной уровень HTTP, DNS, FTP, POP3 6 Уровень представления SSL, SSH, IMAP, JPEG 5 Сеансовый уровень APIs Sockets 4 Транспортный уровень TCP, UDP 3 Сетевой уровень IP, ICMP, IGMP 2 Канальный уровень Ethernet, MAC, HDLC 1 Физический уровень RS-232, RJ45, DSL OSI (The Open Systems Interconnection model) – это набор правил, который описывает то, как должны взаимодействовать друг с другом различные сетевые устройства. Модель разделяется на 7 уровней, каждый из которых отвечает за выполнение определенной функции. Все это нужно для того, чтобы процесс обмена информацией в сети происходил по единому шаблону и все устройства, будь-то умный холодильник и смартфон, могли без проблем понять друг друга.
- Физический уровень
На этом уровне происходит кодирование битов (единиц/нулей) в физические сигналы (ток, свет, радиоволны) и их дальнейшая передача проводным (Ethernet) или беспроводным (Wi-Fi) способом.
- Канальный уровень
Физические сигналы с первого уровня раскодируются обратно в единицы и нули, исправляются ошибки и дефекты, извлекаются MAC-адреса отправителя и получателя.
- Сетевой уровень
Происходит маршрутизация трафика, запросы к DNS и формирование IP-пакетов.
- Транспортный уровень
Уровень ответственный за передачу данных. Здесь существуют 2 важнейших протокола:
- TCP - обеспечивающий надежную передачу данных. TCP гарантирует доставку данных и сохранение порядка следования сообщений. Это сказывается на скорости передачи. Данный протокол используется там, где потеря информации недопустима, например при отправки почты или загрузке веб-страниц.
- UDP – простой протокол с быстрой передачей данных. Он не использует механизмов для гарантирования доставки и порядка следования данных. Используется, например в онлайн-играх, где частичная потеря пакетов не критична, но скорость передачи данных имеет гораздо более важное значение. Так же, запросы к DNS-серверам происходят через UDP протокол.
- TCP - обеспечивающий надежную передачу данных. TCP гарантирует доставку данных и сохранение порядка следования сообщений. Это сказывается на скорости передачи. Данный протокол используется там, где потеря информации недопустима, например при отправки почты или загрузке веб-страниц.
- Сеансовый уровень
Отвечает за открытие и закрытие связи (сеансов) между двумя устройствами. Гарантирует, что сеанс будет оставаться открытым достаточно долго для передачи всех необходимых данных, а затем быстро закроется, чтобы избежать траты ресурсов.
- Уровень представления
Трансляция, шифрование/расшифровка и сжатие данных. Именно здесь данные, которые приходят в виде нулей и единиц преобразуются в нужные форматы (PNG, MP3, PDF и т.д.)
- Прикладной уровень
Уровень работы с приложениями. Разрешает приложениям пользователя иметь доступ к сетевым службам, таким как обработчик запросов к базам данных, доступ к файлам, пересылке электронной почты.
- Физический уровень
🔗 Ссылки на материалы
- 📺 Модель OSI | 7 уровней за 7 минут – YouTube
- 📺 Модель OSI | Курс "Компьютерные сети" – YouTube
- 📄 Простое пособие по сетевой модели OSI для начинающих – selectel.ru
- 📄 Физика Ethernet для самых маленьких – habr.com
- 📄 Как работает Wi-fi. История беспроводных сетей – habr.com
- 📄 Wi-Fi или витая пара — что лучше? – habr.com
- 📄 Всё, что вы хотели знать о МАС адресе — habr.com
- 📺 Протокол IP: маршрутизация | Курс "Компьютерные сети" — YouTube
- 📺 Протокол TCP — YouTube
- 📺 Протокол UDP — YouTube
- 📺 Прикладной уровень | Курс "Компьютерные сети" — YouTube
-
Протокол HTTP
HTTP (HyperText Transport Protocol) - cамый важный протокол интернета. Используется для передачи данных любого формата. Сам по себе протокол работает по простому принципу: запрос –> ответ.
- Структура HTTP-сообщений
HTTP-сообщения состоят из заголовка, содержащего метаданные о сообщении, за которым следует необязательное тело сообщения, содержащее отправляемые данные.

- Заголовки
Дополнительная служебная информация которая отправляется вместе с запросом/ответом.
Основные: Host, User-Agent, If-Modified-Since, Cookie, Referer, Authorization, Cache-Control, Content-Type, Content-Length, Last-Modified, Set-Cookie, Content-Encoding. - Методы запросов
Основные: GET, POST, PUT, DELETE.
Дополнительные: HEAD, CONNECT, OPTIONS, TRACE, PATCH. - Коды состояния
Каждый ответ от сервера имеет специальный числовой код, который характеризует состояние отправленного запроса. Эти коды делятся на 5 основных классов:
- 1хх - Служебная информация
- 2хх - Успешный запрос
- 3хх - Перенаправление на другой адрес
- 4хх - Ошибка на стороне клиента
- 5хх - Ошибка на стороне сервера
- HTTPS
Тот же HTTP, но с поддержкой шифрования. Ваши приложения должны использовать HTTPS, чтобы быть безопасными.
- Cookie
Протокол HTTP не предоставляет возможности сохранять информацию о состояниях предыдущих запросов и ответов. Для решения этой проблемы используются куки. Куки позволяют серверу хранить информацию на стороне клиента, которую клиент может передавать обратно на сервер. Например, куки могут использоваться для авторизации пользователей или для сохранения различных параметров и настроек.
- CORS (Cross origin resource sharing)
Технология, которая позволяет одному домену получать данные от другого.
- CSP (Content Security Policy)
Специальный заголовок позволяющий распознавать и устранять определённые типы уязвимостей веб-приложения.
- Эволюция HTTP
- HTTP 1.0: Использует отдельные соединения для каждого запроса/ответа, не поддерживает кэширование, передача сообщений в виде plain текста.
- HTTP 1.1: Возможность переиспользовать одно соеднинение, конвейеризация, заголовок Host и кодирование передачи данных в виде чанков (кусков).
- HTTP 2: Поддерживает мультиплексирование, сжатие заголовков, пуш-уведомления и работу с двоичными данными.
- HTTP 3: Построен поверх протокола QUIC, предлагает улучшенное мультиплексирование, стабильность и лучшую производительность в ненадежных сетях.
- Структура HTTP-сообщений
🔗 Ссылки на материалы
- 📄 Протокол HTTP – MDN (mozilla.org)
- 📺 Протокол HTTP | Курс компьютерные сети – YouTube
- 📄 Простым языком об HTTP – habr.com
- 📄 HTTP-запросы: структура, методы, строка статуса и коды состояния – selectel.ru
- 📄 Что такое протокол HTTPS, и как он защищает вас в интернете
- 📄 В чем разница протоколов HTTP и HTTPS – selectel.ru
- 📺 Как работает HTTPS? – YouTube
- 📺 Что такое cookies браузера – YouTube
- 📄 Что такое cookie в браузере и почему на многих сайтах предупреждают об их использовании?
- 📄 CORS для чайников: история возникновения, как устроен и оптимальные методы работы – habr.com
- 📄 Улучшение сетевой безопасности с помощью Content Security Policy – habr.com
- 📄 Путь к HTTP/2 – habr.com
- 📄 Evolution of HTTP – MDN (mozilla.org)
-
Cтек протоколов TCP/IP

По сравнению с моделью OSI стек TCP/IP имеет более простую архитектуру. В целом, модель TCP/IP является более широко используемой и практичной, а модель OSI - более теоретической и детальной. Обе модели описывают одни и те же принципы, но отличаются подходом и протоколами, которые они включают на своих уровнях.
- Канальный уровень
Определяет, как данные передаются по физической среде, такой как кабели или беспроводные сигналы.
Протоколы: Ethernet, Wi-Fi, Bluetooth, оптоволокно. - Сетевой (межсетевой) уровень
Маршрутизация данных между различными сетями. Он использует IP-адреса для идентификации устройств и направляет пакеты данных к месту назначения.
Протоколы: IP, ARP, ICMP, IGMP - Транспортный уровень
Передача данных между двумя устройствами. При этом используются такие протоколы, как TCP - надежный, но медленный и UDP - быстрый, но ненадежный.
- Прикладной уровень
Предоставляет услуги конечному пользователю, такие как просмотр веб-страниц, электронная почта и передача файлов.
Протоколы: HTTP, FTP, SMTP, DNS, SNMP.
- Канальный уровень
🔗 Ссылки на материалы
-
Проблемы сети

Качество работы сетей, включая Интернет, далеко от идеального. Это связано со сложной структурой сетей и их зависимости от огромного количества факторов. Например, от стабильности соединения между клиентским устройством и его роутером, от качества услуг провайдера, от мощности и производительности сервера, от физического расстояния между клиентом и сервером и т.д.
- Latency (задержка)
Время которое требуется, чтобы пакет данных дошёл от отправителя к получателю. В большей степени зависит от физического расстояния.
- Packet loss (потеря пакетов)
Не все пакеты, путешествуя по сети, могут добраться до места назначения. Чаще всего такое происходит при использовании беспроводных сетей или из-за перегрузок сети.
- Round Trip Time (RTT)
Время, за которое пакет данных доходит до пункта назначения + время на ответ о том, что пакет был получен успешно.
- Jitter
Колебания задержки (нестабильный ping, например, то 50ms, то 120ms, то 35ms...).
- Packet reordering
Протокол IP не гарантирует, что пакеты будут доставляются в том порядке, в котором они были отправлены.
- Latency (задержка)
🔗 Ссылки на материалы
-
Диагностика сети

- Трассировка сетевого маршрута
Процедура, позволяющая отследить по каким узлам, с какими IP адресами, передаётся отправленный вами пакет прежде чем он достигнет точки назначения. Трассировка может применяться для выявления связанных с работой компьютерной сети проблем, а также для исследования/анализа сети.
- Ping-сканирование
Самый простой способ проверить сервер на работоспособность.
- Проверка на потерю пакетов
- Wireshark
Мощная программа с графическим интерфейсом для анализа всего трафика, проходящего по сети, в режиме реального времени.
- Трассировка сетевого маршрута
🔗 Ссылки на материалы
- 📄 Как находить проблемы с интернетом и кто виноват: часть 1 – habr.com
- 📄 Как находить проблемы с интернетом и кто виноват: часть 2 – habr.com
- 📄 Прочитай и сделай: проводим сканирование сети самостоятельно – habr.com
- 📺 Основы компьютерных сетей. Диагностика и устранение основных проблем – YouTube
- 📄 Трассировка сетевого маршрута — hackware.ru
- 📄 Wireshark — приручение акулы – habr.com
- 📺 Протокол HTTPS в WireShark – YouTube
Устройство ПК
-
Основные компоненты (железо)
- Материнская плата
Самый важный компонент ПК к которому подключаются все остальные элементы.
- Чипсет - набор микросхем, который отвечает за коммуникацию всех элементов материнской платы.
- Сокет - разъем для установки процессора.
- VRM (Voltage Regulator Module) - модуль который преобразовывает поступающие напряжение (как правило 12 В) в более низкое для работы процессора, встроенной графики и оперативной памяти.
- Слоты для оперативной памяти.
- Слоты расширения PCI-Express - предназначены для подключения видеокарт, внешних сетевых/звуковых карт.
- Слоты М.2 / SATA - предназначены для подключения жёстких дисков и SSD.
- Процессор (ЦП / CPU)
Важнейшее устройство, которое исполняет инструкции (код программы). Процессоры работают только с 1 и 0, поэтому все программы в конечном виде представляют из себя набор двоичного кода.
- Регистры - самая быстрая память в ПК, имеет крайне малый объем, встроена в процессор и предназначена для временного хранения обрабатываемых данных.
- Кэш (Cache) - чуть менее быстрая память, которая так же встроена в процессор и используемая для хранения копии данных из часто используемых ячеек основной памяти.
- Процессоры могут иметь разные архитектуры. В настоящее время наиболее распространена архитектура х86 (настольные ПК и ноутбуки) и ARM (мобильные девайсы, а также компьютеры фирмы Apple).
- Оперативная память (ОЗУ / RAM)
Быстрая память небольшого объема (4-16GB), предназначенная для временного хранения кода программы, а также входных, выходных и промежуточных данных, обрабатываемых процессором.
- Постоянная память
Память большого объема (256GB-1TB), предназначенная для долговременного хранения файлов и установленных программ.
- Видеокарта (GPU)
Отдельная плата, занимающаяся переводом и обработкой данных в изображения для вывода их на экран монитора. Такое устройство ещё называют дискретной видеокартой. Обычно нужны для тех, кто занимается 3D моделированием или играет в игры. Встроенная видеокарта – это видеокарта встроенная в процессор. Подходит для повседневной работы.
- Сетевая карта
Устройство, которое обеспечивает приём и передачу данных от других устройств подключённых к одной сети.
- Звуковая карта
Устройство позволяющее обрабатывать звук, выводить его на другие устройства, записывать с помощью микрофона и т.д.
- Блок питания
Устройство, предназначенное для преобразования напряжения переменного тока от сети в напряжение постоянного тока.
- Материнская плата
🔗 Ссылки на материалы
- 📺 Устройство Компьютера для чайников – YouTube
- 📺 Материнская плата. Из чего она состоит? – YouTube
- 📄 Внутри материнской платы: анализ технологий, лежащих в основе компонентов ПК – habr.com
- 📺 Как работает процессор – YouTube
- 📄 Как работает CPU: интерактивный урок – habr.com
- 📺 Как работает кэш процессора – YouTube
- 📺 Различия компьютерных архитектур – YouTube
- 📺 ПРОЦЕССОРЫ ARM vs x86: ОБЪЯСНЯЕМ – YouTube
- 📺 Как работает память компьютера – YouTube
- 📄 Анатомия оперативной памяти – habr.com
- 📺 Сетевая карта – YouTube
- 📄 О работе ПК на примере Windows 10 и клавиатуры – habr.com
-
Устройство операционной системы
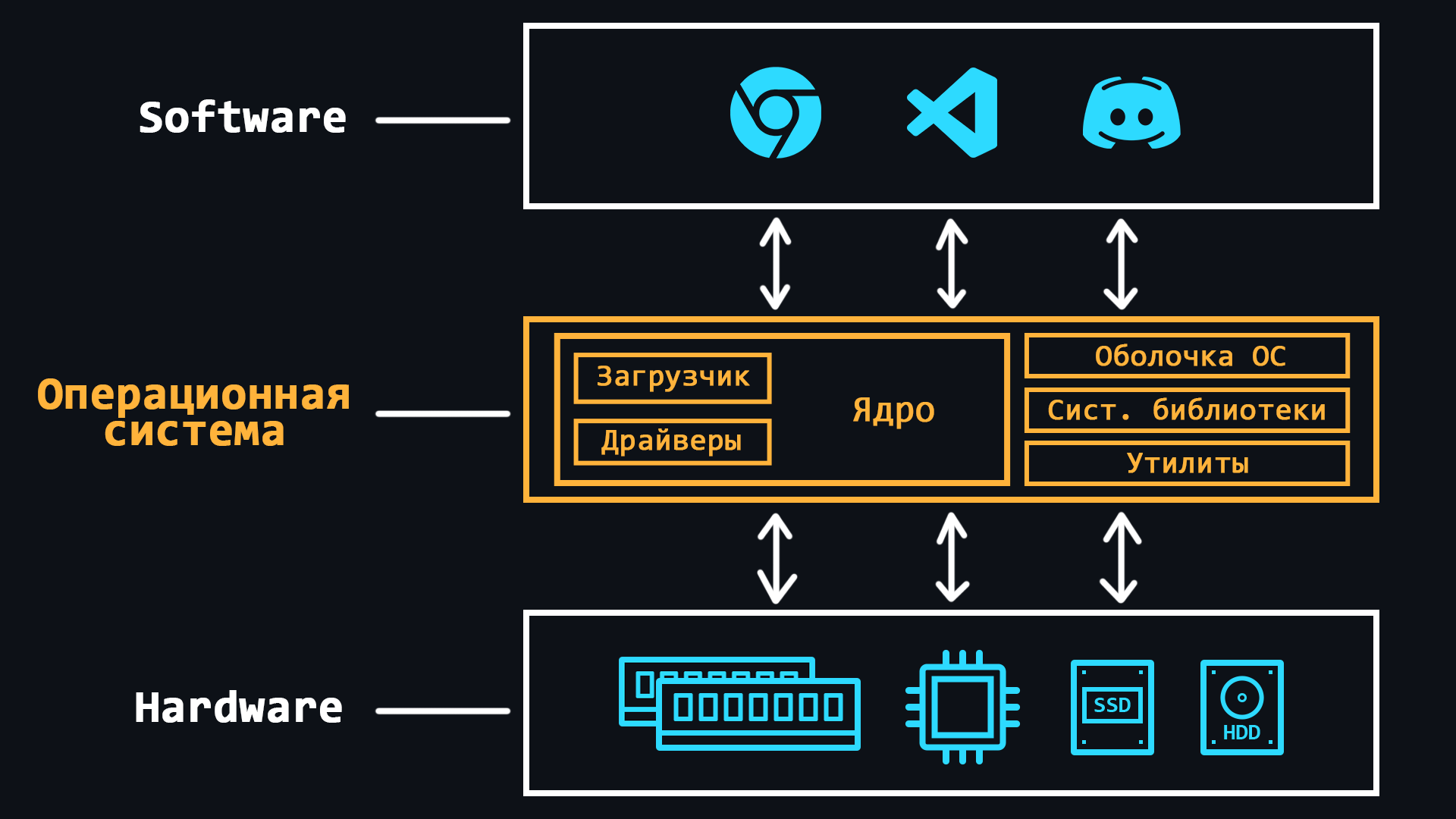
Операционная система (ОС) – это комплексная программная система, которая предназначена для управления ресурсами компьютера. Благодаря операционным системам людям не приходится иметь дело непосредственно с процессором, оперативной памятью или другими составляющими ПК.
То есть, ОС можно представить как слой абстракции, который управляет железом (hardware) компьютера, тем самым предоставляя простую и удобную среду для работы пользовательского софта (software).
- Основные функции
- Управление оперативной памятью (выделение пространства для отдельных программ)
- Загрузка программ в оперативную память и их выполнение
- Выполнение запросов поступающих от пользовательских программ (ввод и вывод данных, запуск и остановка других программ, высвобождение памяти или выделение дополнительной...)
- Взаимодействие с устройствами ввода и вывода (мышь, клавиатура, монитор...)
- Взаимодействие с носителями информации (жесткие диски, SSD...)
- Предоставление пользовательского интерфейса (консольная оболочка или графичеcкий интерфейс)
- Ведение журнала об программных ошибках (сохранение логов)
- Управление оперативной памятью (выделение пространства для отдельных программ)
- Дополнительные функции (могут быть не во всех ОС)
- Организация многозадачности (одновременное выполнение нескольких программ)
- Разграничивание доступа к ресурсам для каждого процесса
- Взаимодействие между процессами (обмен данными, синхронизация)
- Организация защиты самой ОС от других программ и действий самого пользователя
- Предоставление многопользовательского режима и разграничение прав между разными пользователями ОС (админ, гость...)
- Организация многозадачности (одновременное выполнение нескольких программ)
- Ядро ОС
Центральная часть ОС, которая используется наиболее интенсивно. Ядро постоянно находится в памяти, в то время как другие части ОС загружаются в память и выгружаются из неё по мере надобности.
- Загрузчик ОС
Системный софт, который обеспечивает подготовку окружения для запуска ОС (приводит аппаратуру в нужное состояние, подготавливает память, загружает туда ядро ОС и передает ему (ядру) управление).
- Драйверы
Специальное ПО, которое позволяет ОС работать с тем или иным оборудованием.
- Основные функции
🔗 Ссылки на материалы
-
Процессы и потоки

- Процесс
Cвоего рода контейнер, в котором находятся все необходимые ресурсы для работы той или иной программы. Как правило в состав процесса входят:
- Исполняемый код программы
- Входные и выходные данные
- Стек вызовов (порядок инструкций для выполнения)
- Куча (структура для хранения промежуточных данных, создаваемых во время работы процесса)
- Дескриптор сегмента
- Файловые дескрипторы
- Информация о наборе допустимых полномочий
- Информация о состоянии процессора
- Исполняемый код программы
- Поток
Cущность, в которой выполняются последовательности действий (процедуры) программы. Потоки находятся внутри процесса и используют то же адресное пространство. В одном процессе может быть несколько потоков, что обеспечивает возможность выполнения нескольких задач. Эти задачи, благодаря потокам, могут обмениваться данными, использовать общие данные или результаты других задач.
- Процесс
🔗 Ссылки на материалы
-
Конкурентность и параллелизм

- Параллелизм (Parallelism)
Способность выполнять несколько задач одновременно используя несколько ядер процессора, где на каждом отдельном ядре выполняется отдельно взятая задача.
- Конкурентность (Concurrency)
Способность выполнять несколько задач, но используя одно ядро процессора. Это достигается путем разделения задач на отдельные блоки команд, которые выполняются по очереди, но переключение между этими блоками происходит настолько быстро, что для пользователей создается впечатление, будто эти процессы выполняются одновременно.
- Параллелизм (Parallelism)
🔗 Ссылки на материалы
-
Межпроцессорное взаимодействие
Механизм позволяющий организовать обмен данными между потоками одного или разных процессов. Причем, процессы могут быть запущены как на одном и том же компьютере, так и на разных, соединенных сетью. Межпроцессорные взаимодействия бывают разных типов.
- Файл
Самый простой способ организовать обмен данными. Один процесс записывает данные в определенный файл, другой процесс читает этот же файл и тем самым получает данные от первого процесса.
- Сигнал
Асинхронное уведомление одного процесса о событии произошедшем в другом процессе.
- Сокет
В частности для взаимодействия между компьютерами с помощью стека протоколов TCP/IP используются IP-адреса и порты. Эта пара определяет сокет («гнездо», соответствующее адресу и порту).
- Семафор
Счетчик над которым можно проводить только 2 операции: увеличение и уменьшение (причем для 0 операция уменьшения блокируется).
- Сообщения и очереди сообщений
- Каналы (akа конвейеры, pipes)
Перенаправление выходных данных одного процесса на вход другого процесса (подобие трубы).
- Файл
🔗 Ссылки на материалы
- 📺 Архитектура ЭВМ. Межпроцессное взаимодействие – YouTube
- 📺 Основы программирования. Межпроцессное взаимодействие – YouTube
- 📄 IPC: основы межпроцессного взаимодействия
- 📺 Интерфейс сокетов | Курс "Компьютерные сети" – YouTube
- 📺 Порты, сокеты, статика (для самых маленьких программистов) – YouTube
- 📺 Разделяемая память. Семафоры – YouTube
Основы Linux
Операционные системы на базе ядра Linux это стандарт в мире серверной разработки, поскольку большинство серверов работают именно на таких ОС. Использовать Linux на серверах выгодно, ведь он распространяется бесплатно, имеет открытый исходный код, имеет достаточно высокий уровень безопасности и работает быстро, даже на слабом железе.
Существует огромное количество дистрибутивов (сборок с набором предустановленного ПО) Linux на любой вкус и цвет. Одним из самых популярных является Ubuntu. Именно с него можно начать своё погружение в серверную разработку.
Установить Ubuntu можно на отдельный ПК или ноутбук. Если такой возможности нет, можно воспользоваться специальной программой Virtual Box, в которой можно запускать другие ОС поверх основной. Так же можно запустить Docker контейнер с образом Ubuntu (Docker - это отдельная тема, которая рассматривается в этом репозитории).
После этого можно быстро пройти вводный курс по Linux и Bash.
-
Работа с командной оболочкой
Командная оболочка (или, как ещё говорят - консоль, терминал) - программа, в которой для управления компьютером используются специальные текстовые команды. Как правило, на серверах отсутствуют графические оболочки, поэтому вам обязательно понадобятся навыки работы с терминалом. Существуют разные UNIX-подобные командные оболочки, но большинство дистрибутивов Linux поставляются с оболочкой Bash по умолчанию.
- Основные команды для навигации по файловой системе
ls # просмотр содержимого директории cd [ПУТЬ] # переход в указанный каталог cd .. # переход на уровень выше (в родительский каталог) touch [ФАЙЛ] # создание файла cat > [ФАЙЛ] # ввод текста в файл из консоли (перезапись) cat >> [ФАЙЛ] # ввод текста в конец файла (добавление) cat/more/less [ФАЙЛ] # просмотр содержимого файла head/tail [ФАЙЛ] # просмотр первых/последних строк файла pwd # вывести абсолютный путь к текущей директории mkdir [ИМЯ] # создать директорию rmdir [ИМЯ] # удалить директорию cp [ФАЙЛ] [ПУТЬ] # копировать файл или директорию mv [ФАЙЛ] [ПУТЬ] # перемещение или переименование rm [ФАЙЛ] # удаление файла или директории find [СТРОКА] # поиск в файловой системе du [ФАЙЛ] # вывод размера файла или каталога grep [ПАТТЕРН] [ФАЙЛ] # вывести строки соответствующие паттерну - Команды для получения справочной информации
man [КОМАНДА] # позволяет посмотреть руководство по любой команде apropos [СТРОКА] # поиск команды с описанием имеющим указанную строку man -k [СТРОКА] # аналогично команде выше whatis [КОМАНДА] # краткое описание команды - Права суперпользователя
Аналог запуска от имени администратора в Windows
sudo [КОМАНДА] # выполняет команду с правами суперпользователя - Текстовый редактор
Изучите любой для того чтобы свободно читать и редактировать файлы через терминал. Самый простой – nano. Что-то среднее – micro. Самый продвинутый – Vim.
- Основные команды для навигации по файловой системе
🔗 Ссылки на материалы
- 📺 Linux для Начинающих (Плейлист) – YouTube
- 📄 Основные linux-команды для новичка – habr.com
- 📄 44 команды Linux которые вы должны знать – losst.ru
- 📄 Основные команды Linux: (почти) полное руководство с примерами – selectel.ru
- 📄 Шпаргалка для редактора Nano
- 📄 Документация для редактора Micro на русском
- 📄 Основы редактора Vim (Плейлист) – YouTube
- 📄 Изучение терминала через прохождение челленджей
-
Менеджер пакетов
Менеджер пакетов – это утилита позволяющая устанавливать/обновлять программные пакеты с помощью терминала.
Linux дистрибутивы можно разделить на несколько групп, в зависимости от того, какой в них используется менеджер пакетов: apt (в дистрибутивах на основе Debian), RPM (система управления пакетами Red Hat) и Pacman (менеджер пакетов в Arch-подобных дистрибутивах)
Ubuntu основан на Debian, поэтому там используется менеджер пакетов apt (advanced packaging tool).
- Базовые команды
apt install [имя_пакета] # установить пакет apt remove [имя_пакета] # удалить пакет, но оставить конфигурацию apt purge [имя_пакета] # удалить пакет вместе с конфигурацией apt update # обновление информации о новых версиях пакетов apt upgrade # обновление пакетов, установленных в системе apt list --installed # список установленных в системе пакетов apt list --upgradable # список пакетов, которые требуют обновления apt search [имя] # поиск пакетов по имени в сети apt show [имя_пакета] # информация о пакете - Управление репозиториями пакетов
Менеджеры пакетов обычно работают с удаленными репозиториями. Эти репозитории содержат коллекцию программных пакетов, которые поддерживаются и предоставляются сообществом дистрибутива или официальными источниками.
add-apt-repository [ССЫЛКА] # подключить новый репозиторий add-apt-repository --remove [ССЫЛКА] # отключить репозиторий # не забывайте обновлять информацию о пакетах - apt update/etc/apt/sources.list # файл содержащий ссылки на репозитории /etc/apt/sources.list.d # каталог содержащий файлы со сторонними репозиториями
- Базовые команды
🔗 Ссылки на материалы
-
Скрипты Bash
С помощью скриптов (сценариев) можно автоматизировать последовательный ввод любого количества команд. В Bash можно создавать различные условия (разветвления), циклы, таймеры и т.д. для выполнения всевозможных действий связанных с вводом в терминал.
- Основы Bash скриптов
Самые базовые и часто используемые возможности такие как: переменные, ввод/вывод, циклы, условия и т.д.
- Практика
Решайте задания на таких сайтах как HackerRank и Codewars.
Начните использовать Bash для автоматизации рутинных действий на своем компьютере. Если вы уже занимаетесь программированием, создавайте скрипты для удобной сборки вашего проекта, для установки настроек и так далее. - ShellCheck инструмент для анализа скриптов
Укажет Вам на возможные ошибки и научит лучшим практикам написания действительно качественных скриптов.
- Дополнительные ресурсы
В таких репозиториях, как awesome bash и awesome shell собраны целые коллекции полезных ресурсов и инструментов, которые помогут развить ещё больше навыков работы с Bash и терминалом в общем.
- Основы Bash скриптов
🔗 Ссылки на материалы
- 📺 Основы работы с Bash – YouTube
- 📄 Интерактивный онлайн-тренажёр по основам Bash
- 📄 Bash-скрипты: начало – habr.com
- 📄 Шпаргалка по Bash – Learn X in Y minutes
- 📄 Шпаргалка оп Bash – quickref.me
- 📄 Страница Bash на Reddit – reddit.com
- 📄 Лучшие практики Bash скриптов – habr.com
- 📄 Как работает bash: разбираемся в деталях – VK Cloud
-
Пользователи, группы и права доступа
ОС на базе Linux являются многопользовательскими. Это означает, что несколько людей могут запускать множество различных приложений одновременно на одном и том же компьютере. Чтобы система Linux смогла «узнать» пользователя, он должен войти в систему, соответственно каждый пользователь должен иметь уникальное имя и секретный пароль.
- Работа с пользователями
useradd [имя] [ключи] # создать нового пользователя passwd [имя] # установить пароль пользователю usermod [имя] [ключи] # редактировать пользователя usermod -L [имя] # заблокировать пользователя usermod -U [имя] # разблокировать пользователя userdel [имя] [ключи] # удалить пользователя su [имя] # переключиться на другого пользователя - Работа с группами
groupadd [группа] [ключи] # создать группу groupmod [группа] [опции] # редактировать группу groupdel [группа] [опции] # удалить группу usermod -a -G [группы] [пользователь] # добавить пользователя в группы gpasswd --delete [пользователь] [группы] # удалить пользователя из групп - Системные файлы
/etc/passwd # файл содержащий основную информацию о пользователях /etc/shadow # файл содержащий зашифрованные пароли /etc/group # файл содержащий основную информацию о группах /etc/gshadow # файл содержащий шифрованные пароли групп
В Linux можно разделять привилегии между пользователями, ограничить доступ к нежелательным файлам или возможностям, контролировать доступные действия для сервисов и многое другое. В Linux существует всего три вида прав - право на чтение, запись и выполнение, а также три категории пользователей, к которым они могут применяться - владелец файла, группа файла и все остальные.
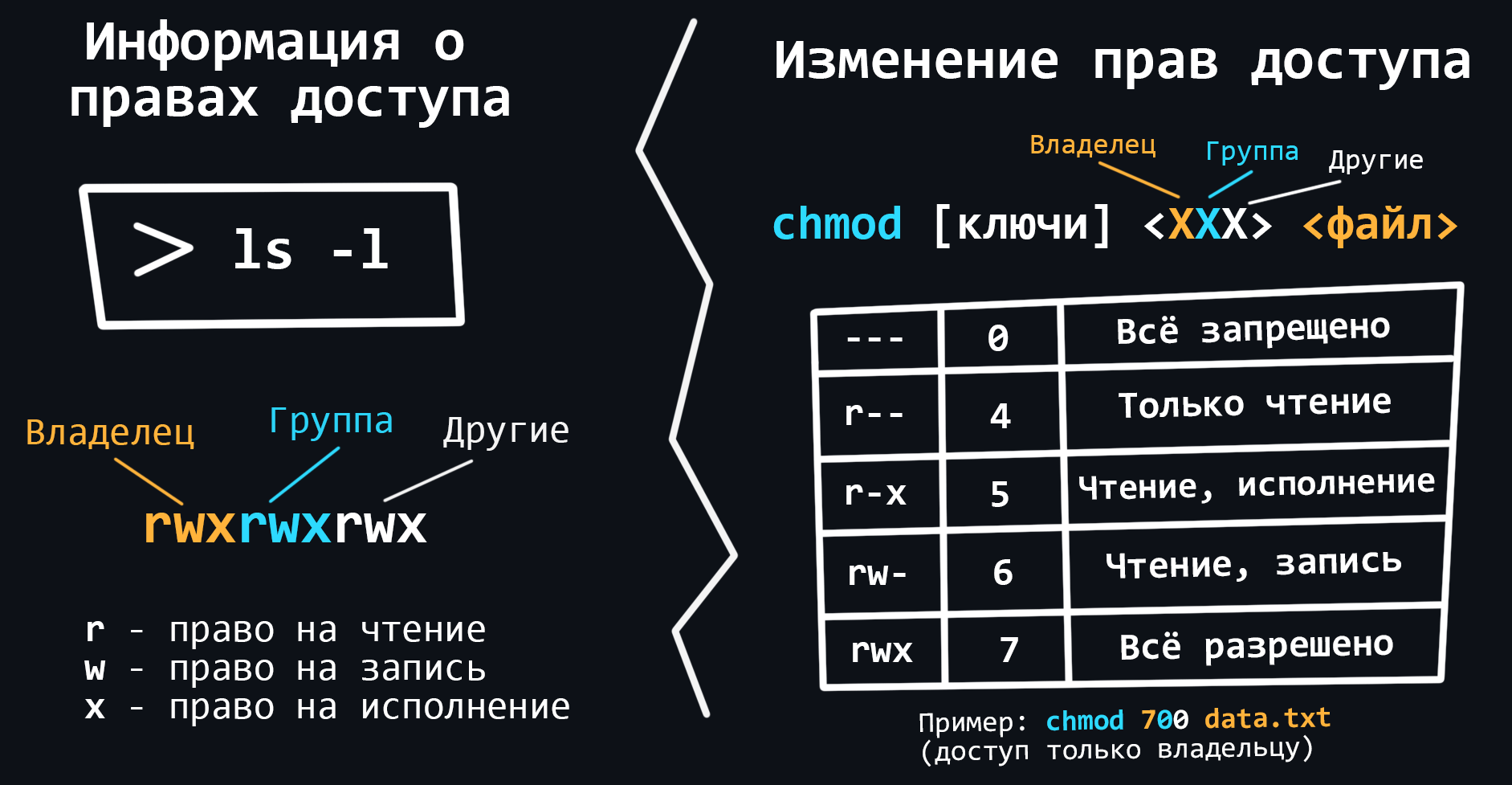
- Основные команды для работы с правами
chown <пользователь> [файл] # изменяет владельца и/или группу для указанных файлов chmod <права> [файл] # изменяет права доступа к файлам и каталогам chgrp <группа> [файл] # позволяет пользователям изменять группы - Расширенные права SUID, GUID и sticky bit
- ACL (Access control list)
Продвинутая подсистема для управления правами доступа.
- Работа с пользователями
🔗 Ссылки на материалы
- 📄 Пользователи в Linux: добавление, изменение, удаление
- 📄 Группы и пользователи в Linux
- 📄 Права доступа в Linux – younglinux.info
- 📄 Управление доступом в Linux
- 📄 Команда chmod – изменение прав доступа – younglinux.info
- 📄 Права в Linux (chown, chmod, SUID, GUID, sticky bit, ACL, umask) – habr.com
- 📄 Быть или не быть ACL в администрировании Linux – habr.com
-
Работа с процессами
Процессы в Linux можно описать как контейнеры, в которых хранится вся информация о состоянии выполняемой программы. Если программа зависла и нужно восстановить её работу, тогда Вам понадобиться навыки работы по управлению процессами.
- Базовые команды
ps # вывести 'снимок' процессов всех пользователей top # диспетчер задач в реальном времени [команда] & # запуск процесса в фоновом режиме, (не блокируя ввод в терминал) jobs # список запущенных в фоновом режиме процессов fg [номер/PID] # вернуть процесс обратно в активный режим по его номеру bg [номер/PID] # запуск остановленного процесса в фоновый режим kill [id процесса] # завершить процесс по id killall [программа] # завершить все процессы связанные с одной программой
- Базовые команды
🔗 Ссылки на материалы
-
Работа с SSH
Служба SSH позволяет получить удаленный доступ к терминалу другого компьютера. В случае с персональным компьютером, это может понадобиться для срочного решения какой-либо проблемы, а в случае работы с сервером это вообще является основным методом подключения.
- Базовые команды
apt install openssh-server # установка SSH (хотя он почти везде стоит из коробки) service ssh start # запуск SSH service ssh stop # остановка SSH ssh -p [порт] [user]@[remotehost] # подключение к удаленному ПК через SSH - Подключение без пароля
ssh-keygen -t rsa # генерация RSA-ключа для беспарольного входа ssh-copy-id -i ~/.ssh/id_rsa [user]@[remotehost] # копирование ключа на удаленную машину - Файлы конфигураций
/etc/ssh/sshd_config # глобальные настройки ssh сервера ~/.ssh/config # локальные настройки ssh сервера ~/.ssh/authorized_keys # файл с сохраненными публичными ключами
- Базовые команды
🔗 Ссылки на материалы
-
Сетевые утилиты
Для Linux существует множество, как встроенных, так и сторонних утилит, которые помогут настроить сеть, проанализировать её или устранить возможные проблемы.
- Базовые утилиты
ip address # показать информацию об IPv4 и IPv6 адресах ваших устройств ip monitor # мониторинг состояния устройств в режиме реального времени ifconfig # параметры сетевого адаптера и IP-протокола traceroute <host> # показать маршрут, пройденный пакетами для достижения хоста tracepath <host> # отслеживает значения MTU до указанного хоста ping <host> # проверка соединения с хостом ss -at # показать список всех прослушиваемых TCP-соединений dig <host> # показать информацию о сервере имен DNS host <host | ip-address> # показать IP-адрес указанного домена mtr <host | ip-address> # комбинация утилит ping и traceroute nslookup # интерактивный запрос к серверам DNS whois <host> # показать информацию о регистрации домена ifplugstatus # определение состояния локальных устройств iftop # информация о пропускной способности ethtool <device name> # показать подробную информацию о устройстве nmap # инструмент для изучения и аудита безопасности сети bmon # монитор пропускной способности и скорости сети firewalld # добавление, настройка и удаление правил брандмауэра ipref # измерение и настройка производительности сети speedtest-cli # информация о скорости сети wget <link> # скачать файл из Интернета tcpdumpКонсольная утилита, позволяющая перехватывать и анализировать весь сетевой трафик, проходящий через ваш компьютер.
netcatУтилита позволяющая устанавливать соединения по TCP и UDP, принимать оттуда данные и передавать их. Может выполнять сканирование портов, передачу файлов и прослушивание портов: как и любой сервер, она может быть использована как Бэкдор.
iptablesПользовательская утилита, позволяющая настраивать правила фильтрации IP-пакетов брандмауэра ядра Linux. Фильтры организованы в виде таблиц, которые содержат цепочки правил обработки пакетов сетевого трафика.
nftablesЯвляется современной заменой для
iptables, а также объединяет в себе ряд других пакетов.curlИнструмент командной строки для передачи данных с использованием различных сетевых протоколов.
- Базовые утилиты
🔗 Ссылки на материалы
- 📺 Linux для Начинающих - Сетевые комманды – YouTube
- 📄 Шпаргалка по сетевым инструментам Linux – habr.com
- 📄 7 важных сетевых Linux-команд – habr.com
- 📄 Используем tcpdump для анализа и перехвата сетевого трафика – habr.com
- 📄 Что такое Netcat? Bind Shell и Reverse Shell в действии – habr.com
- 📄 Переход с iptables на nftables. Краткий справочник – habr.com
- 📄 Что такое curl? Как работает эта команда? – habr.com
- 📄 Шпаргалка по метрикам производительности cURL – habr.com
-
Планировщик задач

Благодаря планировщикам можно гибко управлять отложенным запуском команд и скриптов. В Linux есть встроенный планировщик cron, с помощью которого можно легко выполнять необходимые действия через определенные интервалы времени.
- Основные команды
crontab -e # редактирование файла cron текущего пользователя crontab -l # вывод содержимого текущего файла расписания crontab -r # удаление текущего файла расписания - Конфигурационные файлы
/etc/crontab # основной конфиг /etc/cron.d/ # дополнительная директория для хранения файлов cron # каталоги, в которых можно хранить скрипты запускаемые: /etc/cron.daily/ # ежедневно /etc/cron.weekly/ # еженедельно /etc/cron.monthly/ # ежемесячно
- Основные команды
🔗 Ссылки на материалы
-
Системные логи
Файлы журнала (логи) - cпециальные текстовые файлы, в которые заносится вся информация о работе компьютера, программы или пользователя. Они особенно полезны при возникновении багов и ошибок в работе программы или сервера. Рекомендуется периодически просматривать логи, даже если ничего подозрительного не происходит.
- Основные лог файлы
/var/log/syslog или /var/log/messages # информация о ядре, различных службах, обнаруженных # устройствах, сетевых интерфейсах и т.д. /var/log/auth.log или /var/log/secure # информация об авторизации пользователей /var/log/faillog # неудачные попытки входа в систему /var/log/dmesg # информация о драйверах устройств /var/log/boot.log # информация о загрузке операционной системы /var/log/cron # отчёт о работе планировщика задач cron - Утилита lnav
Предназначена для удобного просмотра лог файлов (подсветка, чтение разных форматов, поиск и т.д.)
- Ротация логов с помощью logrotate
Позволяет настроить автоматическое удаление (чистку) лог-файлов, чтобы не забивать память.
- Демон journald
Cобирает данные из всех доступных источников и сохраняет их в двоичном формате для удобного и динамичного управления
- Основные лог файлы
🔗 Ссылки на материалы
- 📄 Что такое логирование
- 📄 Как посмотреть логи в Linux – losst.ru
- 📄 Лог файлы Linux по порядку – habr.com
- 📄 Что такое «управление конфигурацией»
- 📄 Туториал по системным логам Linux
- 📄 Документация по lnav на русском
- 📄 Ротация логов в Linux с помощью logrotate
- 📄 Использование journalctl для просмотра и анализа логов: подробный гайд – habr.com
-
Основные проблемы в Linux
- Проблемы с установкой/обновлением пакетов
- Проблемы с драйверами
Все свободные драйвера Linux встроены прямо в его ядро. Поэтому после установки системы все должно работать "прямо из коробки" (проблемы могут быть с совсем новым оборудованием). Драйвера, исходный код, которых закрыт, считаются проприетарными и не включаются в ядро, а доустанавливаются вручную (например, драйвера для видеокарт Nvidia).
- Проблемы с файловой системой
- Проверьте доступность дискового пространства с помощью команды
dfи убедитесь, что критические разделы не заполнены. - Используйте команду
fsckдля проверки и устранения несоответствий в файловой системе. - В случае потери или случайного удаления данных используйте такие инструменты восстановления данных, как
extundeleteилиtestdisk.
- Проверьте доступность дискового пространства с помощью команды
- Производительность и использование ресурсов
- Проверяйте использование системных ресурсов, включая процессор, память и дисковое пространство, с помощью команд
free,dfилиdu. - Определите ресурсоемкие процессы с помощью команд
top,htopилиsystemd-cgtop. - Отключайте ненужные службы запуска и фоновые процессы при старте системы.
- Проверяйте использование системных ресурсов, включая процессор, память и дисковое пространство, с помощью команд
- Проблемы с подключением к сети
- Используйте команду
pingдля проверки сетевого подключения к определенному узлу или IP-адресу. - Проверяйте сетевые настройки, такие как конфигурация IP, настройки DNS и правила фаервола.
- Используйте команду
- Проблемы с ядром
Kernel panic может возникать из-за ошибки при монтировании корневой файловой системы.
Тут лучше всего поможет навык чтения логов для выявления проблем (командаdmesg).
- Проблемы с установкой/обновлением пакетов
🔗 Ссылки на материалы
Общие знания
-
Системы счисления
Система счисления (СС) представляет собой совокупность символов и правил для обозначения чисел. В информатике принято выделять четыре основных системы счисления: двоичная, восьмеричная, десятичная, шестнадцатеричная. Связано это, в первую очередь, с их использованием в различных отраслях программирования.
- Двоичная СС
Самая важная СС для вычислительной техники. Её использование обосновано тем, что логика работы процессора построена на основе всего двух состояний (включено/выключено, открыто/закрыто, высокий/низкий, истина/ложь, да/нет, больше/меньше).
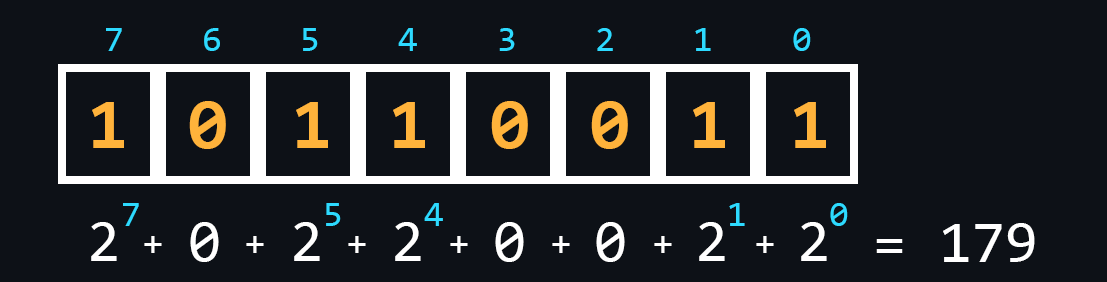
- Восьмеричная СС
Используется, например, в Linux-системах для выдачи прав доступа.

- Десятичная СС
СС которая удобная для восприятия большинству людей.
- Шестнадцатеричная СС
Для записи используются дополнительно буквы: A, B, C, D, E, F. Широко используется в низкоуровневом программировании и компьютерной документации из-за, того что минимальной адресуемой единицей памяти является 8-битный байт, значения которого удобно записывать двумя шестнадцатеричными цифрами.

- Перевод из одной СС в другую
Для лучшего понимания можно попробовать онлайн конвертер
- Двоичная СС
🔗 Ссылки на материалы
-
Логические операции
Логические операции широко используются в программировании для работы с булевыми типами (true/false или 1/0). Результатом логического выражения также является значение булевого типа.
И (AND)
a b a AND b 0 0 0 0 1 0 1 0 0 1 1 1 ИЛИ (OR)
a b a OR b 0 0 0 0 1 1 1 0 1 1 1 1 Исключающее ИЛИ (XOR)
a b a XOR b 0 0 0 0 1 1 1 0 1 1 1 0 - Простейшие логические операции
Лежат в основе других всевозможных операций.
Всего их 3: Операция И (AND, &&, Конъюнкция), операция ИЛИ (OR, ||, Дизъюнкция), операция НЕ (NOT, !). - Операция
Исключающее ИЛИ (XOR, Сложение по модулю 2)Важная операция, которая является фундаментальной в области шифрования информации.
- Таблицы истинности
Для логических операций существуют специальные таблицы, которые описывают входные данные и возвращаемый результат.
- Приоритет операций
Наибольший приоритет имеет оператор
НЕ, за ним следует операторИ, а затем операторИЛИ. С помощью скобок это поведение можно изменить.
- Простейшие логические операции
🔗 Ссылки на материалы
-
Структуры данных
Структуры данных (СД) – это контейнеры в которых данные хранятся по определенным правилам. В зависимости от этих правил структура данных будет эффективна в одних задачах и неэффективна в других. Поэтому необходимо понимать, когда и где использовать ту или иную структуру.
- Массив
СД, которая позволяет хранить данные одинакового типа, где каждому элементу присваивается свой порядковый номер.

- Связный список
СД где все элементы, помимо данных, содержат ссылки на последующий и/или предыдущий элемент. Существуют 3 разновидности:
- Односвязный список – СД, где каждый элемент хранит ссылку только на следующий (одно направление).
- Двусвязный список – СД, где элементы содержат ссылки, как на следующий элемент, так и на предыдущий (два направления).
- Кольцевой список – разновидность двусвязного списка, где последний элемент кольцевого списка содержит указатель на первый, а первый — на последний.

- Стек
СД где хранение данных работает по принципу "последним пришел – первым вышел".

- Очередь
СД где хранение данных происходит по принципу "первым пришел – первым вышел".

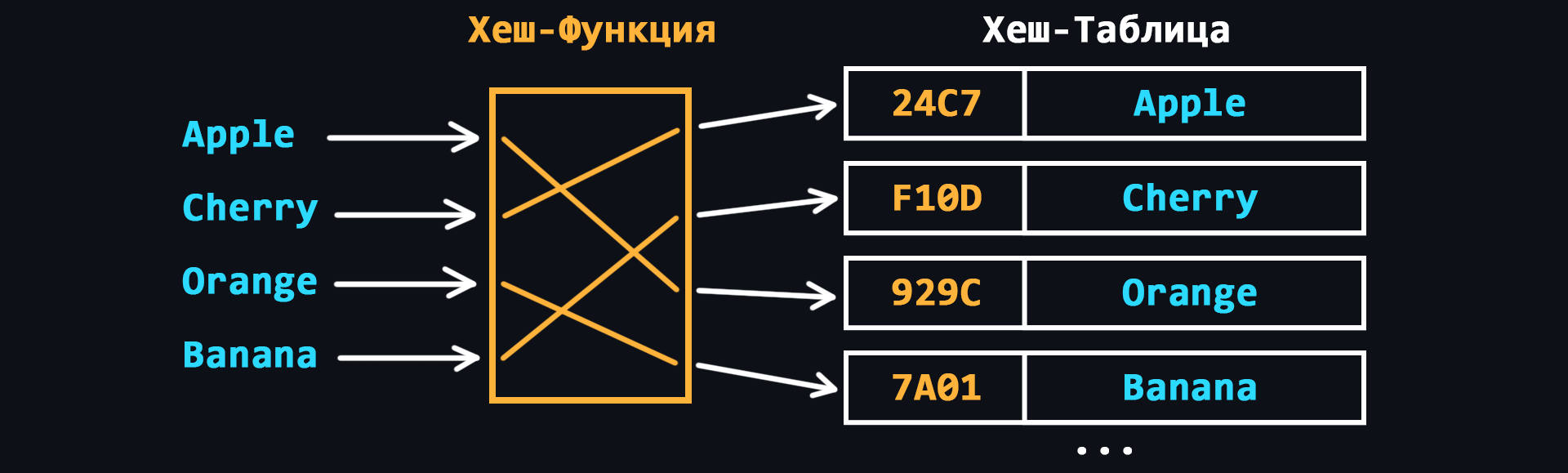
- Хеш-таблица
По другому ассоциативный массив. Здесь для обращения к каждому из элементов используется соответствующее ключевое значение, которое вычисляется с помощью хеш-функции по определенному алгоритму.
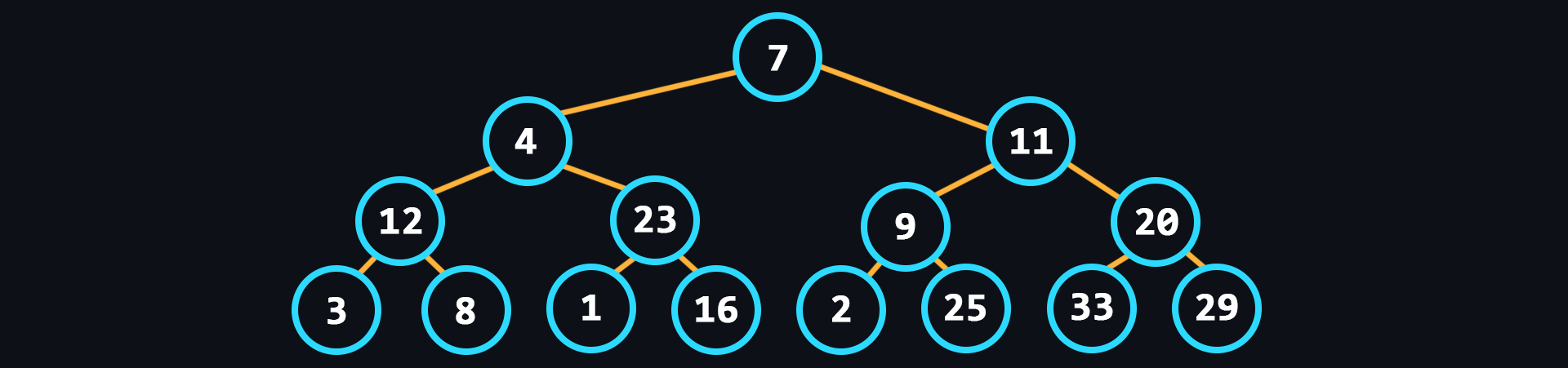
- Дерево
СД с иерархической моделью, в виде набора связанных между собой элементов, как правило, никак не упорядоченных.
- Куча
Аналогична дереву, но в куче, элементы с наибольшим ключом, является корневым узлом (max-куча). Но может быть и наоборот, тогда это min-кучи.

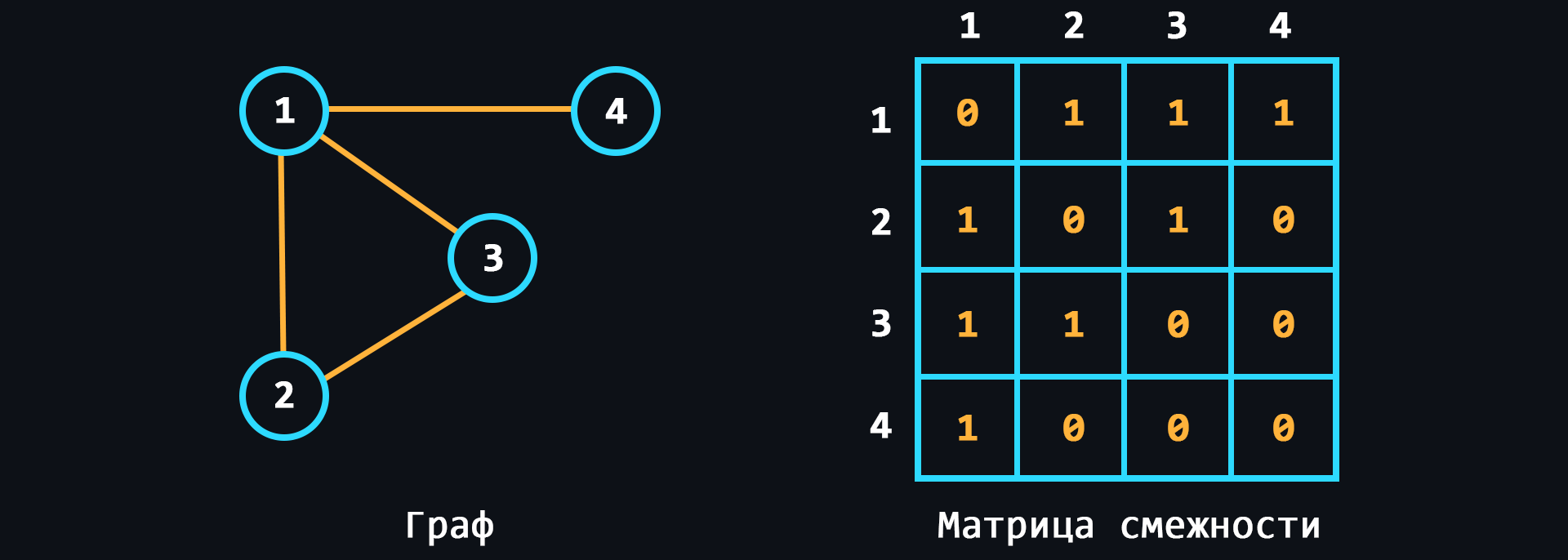
- Граф
Структура, которая предназначена для работы с большим количеством связей.
- Массив
🔗 Ссылки на материалы
- 📄 Структуры данных для самых маленьких – habr.com
- 📄 Обзор наиболее часто используемых структур данных – habr.com
- 📺 Вся правда о массивах – YouTube
- 📺 Как работает стек – YouTube
- 📺 Как работают деревья – YouTube
- 📺 Хэш-таблицы за 10 минут – YouTube
- 📺 Как работают хэш-таблицы – YouTube
- 📺 Как работают графы – YouTube
-
Базовые алгоритмы
Алгоритмы подразумевают под собой наборы последовательных инструкций (шагов), которые приводят к решению поставленной задачи. За всю человеческую историю было придумано огромное количество алгоритмов, которые позволяют решать определенные задачи максимально эффективным способом. Соответственно правильный выбор алгоритмов в программировании позволит создавать максимально быстрые и ресурсоемкие решения.
Существует очень хорошая книжка по алгоритмам – Грокаем алгоритмы. С ней можно параллельно начать изучение языка программирования.
- Двоичный поиск
Максимально эффективный алгоритм поиска для отсортированных списков.
- Сортировка выбором
На каждом шаге алгоритма происходит поиск минимального элемента и затем он меняется местами с текущим элементом итерации.
- Рекурсия
Когда функция может вызывать сама себя и так до бесконечности. С одной стороны решения на основе рекурсии выглядят очень элегантно, а с другой стороны такой подход очень быстро приводит к переполнению стека и его рекомендуют избегать.
- Сортировка пузырьком
На каждой итерации последовательно сравниваются соседние элементы, и, если порядок в паре неверный, то элементы меняют местами.
- Быстрая сортировка
Усовершенствованный метод пузырьковой сортировки.
- Поиск в ширину
Позволяет находить все кратчайшие пути от заданной вершины графа.
- Алгоритм Дейкстры
Находит кратчайшие пути между всеми вершинами графа и их длину.
- Жадный алгоритм
Алгоритм, который на каждом шагу делает локально наилучший выбор в надежде, что итоговое решение будет оптимальным.
- Двоичный поиск
🔗 Ссылки на материалы
- 📺 Алгоритмы и структуры данных. Подготовительный курс (плейлист) – YouTube
- 📺 Алгоритмы и структуры данных на JavaScript – YouTube
- 📺 Как работают сортировки – YouTube
- 📄 Сортировки выбором – habr.com
- 📺 Сортировка выбором – YouTube
- 📄 Рекурсия. Занимательные задачки – habr.com
- 📄 Пузырьковая сортировка и все-все-все – habr.com
- 📄 Алгоритм Дейкстры – habr.com
- 📄 Жадные алгоритмы – habr.com
- 📄 Визуализация алгоритмов сортировки
- 📄 Сайт с алгоритмами и структурами данных
- 📄 Крупнейшая библиотека алгоритмов на разных языках
- 📄 Большая коллекция алгоритмов – GitHub
- 📘 Алгоритмы. Руководство по разработке – Скиена Стивен С., 2011
-
Оценка сложности алгоритмов

В мире программирования существует специальная единица измерения Большое О (Big O, О-нотация). Оно описывает то, как сложность алгоритма растёт с увеличением количества входных данных. Большое О оценивает то, сколько действий (шагов/итераций) необходимо совершить для выполнения алгоритма, при этом всегда показывая худший вариант развития событий.
- Основные разновидности сложности алгоритмов
- Константная - O(1)
- Линейная - O(n)
- Логарифмическая - O(log n)
- Линеарифметическая - O(n * log n)
- Квадратичная - O(n^2)
- Степенная - О(2^n)
- Факториальная - O(!n)
- Константная - O(1)
- Временная сложность
Когда вы заранее знаете, на какой машине будет выполняться алгоритм, вы можете измерить время выполнения алгоритма. Опять же, на очень хорошем железе время выполнения алгоритма может быть вполне приемлемым, но тот же алгоритм на более слабой машине может выполняться сотни миллисекунд или даже несколько секунд. Такие задержки будут очень чувствительны, если ваше приложение обрабатывает запросы пользователей по сети.
- Пространственная сложность
Помимо времени, необходимо учитывать, сколько памяти тратится на работу алгоритма. Это важно, поскольку вы всегда работаете с ограниченными ресурсами.
- Основные разновидности сложности алгоритмов
🔗 Ссылки на материалы
-
Форматы хранения данных
Для хранения и передачи данных по сети используются различные форматы файлов. Текстовые файлы представляют удобочитаемый формат для человека и обычно применяются, например, для файлов конфигурации. Однако, передача данных в текстовом формате по сети не всегда является оптимальным выбором, так как такие файлы занимают больше места по сравнению с соответствующими файлами в двоичном формате.
-
Текстовые форматы
- JSON (JavaScript Object Notation)
Представляет из себя объект, в котом данные хранятся в виде пар ключ-значение.
- YAML (Yet Another Markup Language)
Формат близкий к языкам разметки по типу HTML. Минималистичный, поскольку не имеет открывающих и закрывающих тегов. Удобный для редактирования.
- XML (eXtensible Markup Language)
Формат более близкий к HTML. Здесь данные оборачиваются в открывающие и закрывающие теги.
- JSON (JavaScript Object Notation)
-
Двоичные форматы
- Message Pack
Бинарный аналог JSON. Позволяет упаковывать данные на 15-20% эффективнее.
- BSON (Binary JavaScript Object Notation)
Является надмножеством JSON, включая дополнительно регулярные выражения, двоичные данные и даты.
- ProtoBuf (Protocol Buffers)
Бинарная альтернатива текстовому формату XML. Проще, компактнее и быстрее.
- Message Pack
-
Форматы изображений
- JPEG (Joint Photographic Experts Group)
Подходит для фотографий и сложных изображений с широкой палитрой цветов. Формат обеспечивает высокие коэффициенты сжатия, при этом сохраняя хорошее качество изображения. Однако, повторное редактирование и сохранение JPEG-изображений может привести к деградации качества.
- PNG (Portable Network Graphics)
Используется для изображений с четкими краями, логотипов, иконок и изображений, требующих прозрачности. Размер файлов в формате PNG может быть больше по сравнению с JPEG, но они сохраняют отличное качество без деградации при повторном сохранении.
- GIF (Graphics Interchange Format)
Используется для простых анимаций, изображений с низким разрешением и ограниченной палитрой цветов. Формат поддерживает прозрачность и может воспроизводить анимации путем отображения последовательности кадров.
- SVG (Scalable Vector Graphics)
Формат векторных изображений на основе XML, определенных с помощью математических уравнений, а не пикселей. Изображения SVG могут масштабироваться до любого размера без потери качества и хорошо подходят для логотипов, иконок и графических элементов.
- WebP
Современный формат изображений, разработанный компанией Google. Он поддерживает сжатие с потерями и без, обеспечивая хорошее качество изображения при более низком размере файла по сравнению с форматами JPEG и PNG. Изображения WebP оптимизированы для использования на веб-сайтах и могут включать прозрачность и анимацию.
- JPEG (Joint Photographic Experts Group)
-
Видеоформаты
- MP4 (MPEG-4 Part 14)
Широко используемый формат, который поддерживает высокий уровень сжатия, что делает его подходящим для потоковой передачи и хранения видео. Файлы MP4 могут содержать как видео, так и аудио.
- AVI (Audio Video Interleave)
Мультимедийный контейнерный формат, разработанный компанией Microsoft. Он может хранить аудио- и видеоданные в одном файле. Однако такие файлы обычно имеют больший размер по сравнению с более современными форматами.
- MOV (QuickTime Movie)
Формат разработанный компанией Apple для использования с их медиаплеером QuickTime. Он широко используется с устройствами Mac и iOS. Файлы MOV могут содержать как видео, так и аудио, и они обеспечивают хорошее сжатие и качество.
- WEBM
Лучший форамт для встраивания видео на вашем личном или деловом веб-сайте. Оптимизирован и создан специально для веб-страниц.
- MP4 (MPEG-4 Part 14)
-
Аудиоформаты
- MP3 (MPEG-1 Audio Layer 3)
Самый популярный аудиоформат, известный высоким уровнем сжатия и небольшими размерами файлов. Это достигается путем удаления некоторых аудиоданных, которые могут быть менее заметны для человеческого слуха.
- WAV (Waveform Audio File Format)
Хранит аудиоданные без потерь, обеспечивая высокое качество звукового воспроизведения. Файлы WAV широко используются в профессиональном аудио-производстве и редактировании благодаря своей точности. Однако, они имеют больший размер.
- AAC (Advanced Audio Coding)
Aудиоформат, известный своим эффективным сжатием и хорошим качеством звука. Он предлагает лучшее воспроизведение звука при более низких битрейтах по сравнению с форматом MP3.
- MP3 (MPEG-1 Audio Layer 3)
-
🔗 Ссылки на материалы
- 📄 Форматы сериализации данных – habr.com
- 📄 Введение в JSON – medium.org
- 📄 Работа с JSON – (MDN) mozilla.org
- 📄 Шпаргалка по JSON – Learn X in Y Minutes
- 📄 Шпаргалка по YAML – Learn X in Y Minutes
- 📄 Шпаргалка по XML – Learn X in Y Minutes
- 📄 Краткое руководство по XML
- 📄 YAML за 5 минут: синтаксис и основные возможности – tproger.ru
- 📄 Universal Binary JSON — ещё один бинарный JSON – habr.com
-
Кодировки текста
Компьютеры работают только с числами, а если точнее только с 0 и 1. Как преобразовывать числа из разных систем счисления в двоичную, уже понятно. Но с текстом производить такие преобразования не получится. Именно поэтому были придуманы специальные таблицы, называемые кодировками, в которых текстовым символам присваиваются числовые эквиваленты.
- ASCII (American standard code for information interchange)
Самая простая кодировка, созданная специально для американского алфавита. Состоит из 128 символов.
- Unicode
Это международная таблица символов, которая помимо английского алфавита, содержит алфавиты почти всех стран. Способна вместить в себя более миллиона различных символов (на данный момент таблица заполнена не полностью).
- UTF-8 (Unicode Transformation Format)
Unicode-кодировка переменной длинны, с помощью которой можно представить любой символ unicode.
- UTF-16
Главное ее отличие от UTF-8 состоит в том что структурной единицей в ней является не один а два байта.
- ASCII (American standard code for information interchange)
🔗 Ссылки на материалы
Язык программирования
На этом этапе Вам предстоит выбрать для изучения один из языков программирования. В открытом доступе полно информации по различным языкам, (книги, курсы, тематические сайты и т.д.) поэтому у Вас не должно возникнуть проблем.
Ниже приведен список конкретных языков, которые лично по моему мнению хорошо подходят для backend-разработки (⚠️ может не совпадать с мнением других людей, в том числе более компетентных в этом вопросе).
- Python
Очень популярный язык с широким спектром применений. Лёгкий в изучении, благодаря простому синтаксису.
- JavaScript
Не менее популярный и практический единственный язык для полноценной Web-разработки. Благодаря платформе Node.js последнее несколько лет набирает популярность и в области backend-разработки.
- Go
Язык созданный внутри компании Google. Создавался специально для высоконагруженной серверной разработки. Минималистичный синтаксис, высокая производительность и богатая стандартная библиотека.
- Kotlin
Этакая современная версия Java. Более простой и лаконичный синтаксис, лучшая типобезопасность, наличие встроенных инструментов для многопоточности. Один из лучших выборов для разработки под Android.
Найти хорошую книгу или онлайн-учебник на русском можно в этом репозитории. Там собрана большая коллекция под разные ЯП и фреймворки.
Поищите специальный awesome-репозиторий – ресурс в котором собрано огромное количество полезных ссылок на материалы под Ваш ЯП (библиотеки, шпаргалки, блоги и другие различные ресурсы).
В будущем планируется создание шпаргалки по одному из вышеупомянутых языков.
-
Классификация языков программирования
Языков программирования много. Все они созданы не просто так. Некоторые языки могут быть совсем специфическими и использоваться только для определенных целей. Также, разные языки могут использовать разные подходы к написанию программ. А могут вообще по разному исполняться на компьютере. В общем существует множество различных классификаций, в которых было бы полезно разобраться.
- В зависимости от уровня языка
- Языки низкого уровня
Близкие к машинному коду, сложные в написании, но максимально производительные. Как правило предоставляют доступ ко всем ресурсам компьютера.
- Языки высокого уровня
Имеют достаточно большой уровень абстракции, за счет чего достигается простота и удобство написания. Как правило безопаснее, поскольку не предоставляют доступ ко всем ресурсам компьютера.
- Языки низкого уровня
- В зависимости от способа выполнения кода
- Компиляция
Позволяет преобразовать исходный код программы в исполняемый файл.
- Интерпретация
Исходный код программы транслируется и сразу выполняется (интерпретируется) с помощью специальной программы-интерпретатора.
- Виртуальная машина
При таком подходе программа компилируется не в машинный язык, а в машинно-независимый код низкого уровня, байт-код. Далее этот байт-код выполняется уже самой виртуальной машиной.
- Компиляция
- В зависимости от парадигмы программирования
- Императивная парадигма
Базируется на описании конкретных шагов для решения проблемы с помощью последовательности утверждений или команд.
- Декларативная парадигма
Базируется на описании того, что должна делать программа, а не на том, как она должна это делать. Примерами декларативных языков являются SQL и HTML.
- Функциональная парадигма
Основана на идее рассматривать вычисления в виде математических функций. Она подразумевает иммутабельность данных, избежание побочных эффектов и использование функций высшего порядка. Примерами функциональных языков являются Haskell, Lisp и Clojure.
- Объектно-ориентированная парадигма
Базируется вокруг создания объектов, которые содержат как данные, так и поведение, с целью моделирования вещей реального мира. Примерами объектно-ориентированных языков являются Java, Python и C++.
- Параллельные вычисления
Ориентированы на одновременную обработку нескольких задач или потоков. Используются в системах, требующих высокой производительности и быстроты реакции. Примерами параллельных языков являются Go и Erlang.
- Императивная парадигма
- В зависимости от уровня языка
🔗 Ссылки на материалы
- 📺 Языки программирования: что нужно знать – YouTube
- 📺 Языки программирования: критерии выбора – YouTube
- 📺 Компиляция и интерпретация за 10 минут – YouTube
- 📺 Почему языков программирования так много? – YouTube
- 📄 Что такое компилятор
- 📄 Что такое интерпретатор
- 📄 Методы программирования – GitHub
- 📄 Парадигмы программирования
-
Основы языка
Под основами подразумеваются некоторые фундаментальные идеи, присутствующие в каждом ЯП.
- Переменные и константы
Имена, присваиваемые участку памяти в программе для хранения некоторых данных.
- Типы данных
Определяют какого рода значения могут храниться в переменной. Основными типами данных являются целые числа, числа с плавающей запятой, символы, строки и логические типы (boolean).
- Операторы
Используются для выполнения операций над переменными. К общим операторам относятся арифметические операторы, операторы сравнения, логические операторы и операторы присваивания.
- Управление потоком
Циклы, условия
if elseиswitch case. - Функции
Это блоки кода, которые могут многократно переиспользоваться в программе. Функции являются важной концепцией для понимания области видимости переменных.
- Структуры данных
Специальные контейнеры, в которых данные хранятся по определенным правилам. Основные структуры данных: массивы, карты (словари), деревья, графы.
- Стандартная библиотека
Встроенные в язык возможности для манипуляции над структурами данных, работы с файловой системой, сетью, криптографией и т.д.
- Обработка ошибок
Важный концепт для обработки непредвиденных событий, которые могут произойти во время выполнения программы.
- Регулярные выражения
Мощный инструмент для работы со строками. Обязательно ознакомьтесь с этим в своем ЯП, хотя бы на базовом уровне.
- Модули
Писать код всей программы в одном файле совсем не удобно. Гораздо читабельнее будет если разбить его на небольшие модули и импортировать их в нужные места.
- Пакетный менеджер
Рано или поздно, возникнет желание воспользоваться сторонними библиотеками.
После освоения минимальной базы для написания простейших программ нет особого смысла продолжать изучение без наличия конкретных целей (без практики все забудется). Вам необходимо придумать/найти что-то, что вы хотели бы создать самостоятельно (игра, чат-бот, сайт, мобильное/десктопное приложение, что угодно). Для вдохновения посмотрите эти репозитории: Build your own x и Project based learning.
На этом моменте начинается самая продуктивная часть обучения: Вы просто ищите всевозможную информацию для реализации вашего проекта. Вашими лучшими друзьями становиться Google, YouTube и Stack Overflow.
- Переменные и константы
🔗 Ссылки на материалы
- 📄 Metanit – русскоязычный учебный ресурс по основам разных ЯП
- 📄 Руководство по языку Python на русском – pydocs.ru
- 📄 Шпаргалка по основам Python – Learn X in Y minutes
- 📄 Шпаргалка по основам Python – quickref.me
- 📄 Современный учебник JavaScript на русском – learn.javascript.ru
- 📄 Шпаргалка по основам JavaScript – Learn X in Y minutes
- 📄 Шпаргалка по основам JavaScript – quickref.me
- 📄 Руководство по Go на русском – golangify.com
- 📄 Шпаргалка по основам Go – Learn X in Y minutes
- 📄 Шпаргалка по основам Go – quickref.me
- 📄 Изучение Go на примерах
- 📄 Руководство по языку Kotlin на русском – kotlinlang.ru
- 📄 Шпаргалка по основам Kotlin – Learn X in Y minutes
- 📄 Шпаргалка по основам Kotlin – devhints.io
- 📄 Интерактивный курс по регулярным выражениям
- 📄 Список книг для программиста (70+ на разные темы)
-
Объектно ориентированное программирование
ООП – это один из наиболее удачных и удобных подходов для моделирования предметов реального мира. Этот подход сочетает в себе несколько очень важных принципов, которые позволяют писать модульный, расширяемый и слабо-связанный код.
- Понятие класса
Класс можно понимать как кастомный тип данных (своего рода шаблон), в котором Вы описываете структуру будущих объектов, которые будут реализовывать данный класс. Классы могут содержать
свойства(это конкретные поля, в которых могут храниться данные определенного типа данных) иметоды(это функции, которые имеют доступ к свойствам и возможность ими манипулировать, изменять). - Понятие объекта
Объект – это конкретная реализация класса. Если в классе, например, описано свойство name с типом string, то объект будет иметь конкретное значение для этого поля, например "Alex".
- Принцип наследования
Возможность создавать новые классы, которые наследуют свойства и методы своих родителей. Это позволяет повторно использовать код и создавать иерархию классов.
- Принцип инкапсуляции
Возможность скрывать определенные свойства/методы от доступа из вне, оставляя только упрощенный интерфейс для взаимодействия с объектом.
- Принцип полиморфизма
Возможность реализовывать один и тот же метод по разному в классах наследниках.
- Композиция вместо наследования
Часто принцип
наследованияможет усложнить и запутать Вашу программу, если хорошенько не поразмыслить над тем, как выстраивать будущую иерархию. Поэтому существует альтернативный (более гибкий) подход, который называют композицией. В частности, в языке Go отсутствуют классы и многие ООП принципы, но широко используется композиция.
- Понятие класса
🔗 Ссылки на материалы
-
Разработка серверов
- Понимание сокетов
Сокет – это специальный интерфейс обеспечивающий возможность обмена данными между разными процессами. Вам необходимо знать, как создавать, подключаться, отправлять и получать данные через сокеты.
- Создание и запуск локальных TCP, UDP и HTTP серверов
Эти протоколы являются самыми важными, необходимо понимать тонкости работы с каждым из них.
- Раздача статических файлов
Необходимо уметь поднимать HTML-страницы, хостить картинки, PDF-документы, аудио/видео файлы и т.д.
- Маршрутизация
Создание эндпоинтов (URL-адресов) при обращении к которым на сервере будет вызывается соответствующий обработчик.
- Обработка запросов
Как правило в HTTP-обработчиках имеется специальный объект в который приходит вся информация о запросе пользователя (заголовки, метод, тело-запроса, полный url с параметрами и т.д.)
- Обработка ответов
Отправка соответствующего сообщения на поступивший запрос (HTTP-статус и код, тело-ответа, заголовки и т.д.)
- Обработка ошибок
Всегда нужно быть готовым к тому, что что-то пойдет не так: пользователь отправит некорректные данные, база данных не выполнит операцию или просто в приложении произойдёт непредвиденная ошибка. Необходимо, чтобы сервер не падал, а отсылал ответ с информацией об ошибке.
- Middleware (промежуточное ПО)
Промежуточный компонент между приложением и сервером. Он может использоваться для аутентификации пользователей, валидации параметров, кэширования данных, логирования запросов и так далее.
- Отправка запросов
Часто внутри одного приложения вам придется обращаться по сети к другому. Поэтому важно уметь отправлять HTTP-запросы используя встроенные возможности ЯП.
- Шаблонизатор
Представляет собой специальный модуль, использующий более удобный синтаксис для формирования HTML на основе динамических данных.
- Понимание сокетов
🔗 Ссылки на материалы
- 📄 Руководство по веб-фреймворку Django (Python) – metanit.com
- 📺 Node JS фундаментальный курс от А до Я – YouTube
- 📄 Руководство по Node.js (JavaScript) – metanit.com
- 📄 Документация Node.js на русском
- 📄 Руководство по веб-фреймворку Express (JavaScript)
- 📄 Создание веб-приложения на Go – golangify.com
- 📄 Разработка веб-серверов на Golang — от простого к сложному – habr.com
- 📄 Разработка серверных приложений на Kotlin – kotlinlang.ru
-
Асинхронное программирование
Асинхронное программирование позволяет писать эффективные программы с большим количеством операций ввода/вывода. Такие операции могут подразумевать чтение файлов, обращение к базе данных или удаленному серверу, чтение пользовательского ввода и так далее. В этих случаях программа тратит много времени на ожидание ответа от внешних источников, а асинхронное программирование позволяет программе выполнять другие задачи в моменты этих ожидании.
- Функция обратного вызова (callback)
Это функция, которая передается в качестве аргумента другой функции и предназначена для вызова этой функцией в более позднее время. Цель обратного вызова - позволить вызывающей функции продолжать выполнение, пока вызываемая функция выполняет трудоемкую или асинхронную задачу. Как только задача будет выполнена, вызываемая функция вызовет функцию обратного вызова, передав ей в качестве аргументов все необходимые данные.
- Событийно-ориентированная архитектура (event-driven architecture, EDA)
Популярный подход к написанию асинхронных программ. Основной принцип заключается в ожидании определенных событий и их обработке по мере поступления. Это может быть полезно в веб-приложениях, которым необходимо обрабатывать большое количество одновременных соединений, например, в чат-приложениях.
- Асинхронность в конкретных языках
- В JavaScript асинхронное программирование обычно достигается за счет использования promises, callbacks, async/await syntax и event loop.
- В Python асинхронные программы можно писать с помощью модуля asyncio, который предоставляет цикл событий и API на основе корутин для параллелизма. Существуют и сторонние библиотеки, такие как Twisted и Tornado, которые предоставляют асинхронные возможности.
- Go имеет встроенную поддержку параллелизма через goroutines и channels, которые позволяют писать асинхронный код, который может взаимодействовать и синхронизироваться в нескольких потоках.
- Kotlin предоставляет coroutines, похожие на async/await в JavaScript и asyncio в Python, и могут использоваться с различными библиотеками и фреймворками.
- Функция обратного вызова (callback)
🔗 Ссылки на материалы
- 📄 Асинхронность в программировании – habr.com
- 📺 Python - Асинхронное программирование – YouTube
- 📺 Асинхронность в Python (playlist) – YouTube
- 📄 Коллбэк в JavaScript… Что за зверь? – habr.com
- 📄 Промисы в JavaScript на примере бургер-вечеринки – habr.com
- 📄 У нас проблемы с промисами в JavaScript – habr.com
- 📺 Асинхронное программирование с примерами на JavaScript (playlist) – YouTube
- 📺 Android - Потоки и асинхронность – YouTube
-
Многозадачность
Сегодня компьютеры оснащены процессорами с несколькими физическими и виртуальными ядрами, а если учесть серверные машины, то их количество может достигать сотен. Все эти доступные ресурсы хорошо бы использовать по максимуму, для достижения максимальной производительности приложений. Именно поэтому современная разработка серверов не обходоится без внедрения многозадачности и распараллеливания.
- Как это работает
Многозадачность означает одновременное выполнение нескольких потоков управления в рамках одной программы. Поток - это легкий процесс, который выполняется в контексте полноценного процесса и имеет свой собственный стек, программный счетчик и набор регистров. Несколько потоков могут совместно использовать ресурсы одного процесса, такие как память, файлы и устройства ввода-вывода. Каждый поток работает независимо и может выполнять отдельную задачу или часть задачи.
- Типы многозадачности
- Кооперативная многозадачность: каждая программа или задача отвечает за передачу контроля другим программам или задачам в соответствующее время. Этот подход требует, чтобы программы или задачи были организованы таким образом, чтобы не занимать все ресурсы процессора. Если программа или задача не уступает управление добровольно, это может привести к тому, что вся система перестанет функционировать. Кооперативная многозадачность широко использовалась в ранних операционных системах и до сих пор используется в некоторых встроенных системах или операционных системах реального времени.
- Вытесняющая многозадачность: операционная система принудительно прерывает выполнение программ или задач через регулярные промежутки времени, чтобы дать возможность выполнить другие программы или задачи. ОС отвечает за управление процессором и обеспечение того, чтобы каждая программа или задача получила справедливую долю процессорного времени. Этот подход более надежен, чем кооперативная многозадачность, и может справиться с плохо ведущими себя программами или задачами, которые могут не уступать управление другим. Вытесняющая многозадачность используется в современных операционных системах, таких как Windows, macOS, Linux и Android.
- Основные проблемы и трудности
- Состояния гонки (race conditions): когда несколько потоков одновременно обращаются к общим данным и изменяют их, могут возникнуть условия гонки, что приведет к непредсказуемому поведению или неправильным результатам.
- Взаимные блокировки (deadlocks): возникают, когда два или более потока блокируются в ожидании ресурсов, которые находятся у других потоков, что приводит к тупиковой ситуации.
- Отладка: поиск ошибок в многозадачных программах может быть затруднен из-за их сложности и недетерминированного поведения. Для диагностики и устранения проблем необходимо использовать продвинутые инструменты и методы отладки, такие как дампы потоков, профилировщики и протоколирование.
- Примитивы синхронизации
Необходимы для безопасного обмена данными между различными потоками.
- Семафор (semaphore): по сути, это счетчик, который отслеживает количество доступных ресурсов и может блокировать потоки или процессы, которые пытаются получить больше ресурсов, чем можно.
- Мьютекс (mutex): (взаимное исключение) позволяет только одному потоку или процессу одновременно обращаться к ресурсу, гарантируя отсутствие конфликтов или условий гонки.
- Атомарные операции (atomic operations): операции, которые выполняются как единое, неделимое целое, без возможности прерывания или вмешательства со стороны других потоков или процессов.
- Переменные условий (condition variables): позволяют потокам ждать, пока определенное условие станет истинным, прежде чем продолжить выполнение. Они часто используется в сочетании с мьютексами, чтобы избежать долгих ожиданий и повысить эффективность.
- Работа с конкретным языком программирования
- В Python вы можете использовать threading и multiprocessing модули.
- В Node.js вы можете работать с worker threads, cluster модулем и shared array buffers.
- Go имеет невероятные горутины и каналы.
- Kotlin предоставляет корутины.
- Как это работает
🔗 Ссылки на материалы
- 📄 Race condition в веб-приложениях – habr.com
- 📄 Знакомство с уровнями распараллеливания –
- 📄 Атомарные и неатомарные операции – habr.com
- 📄 Многопоточность, общие данные и мьютексы – habr.com
- 📺 Многопроцессность, многопоточность, асинхронность в Python и не только – YouTube
- 📺 Worker threads. Многопоточность в Node.js – YouTube
- 📺 Всё про конкурентность в Go – YouTube
-
Продвинутые темы
- Сборщик мусора (garbage collector)
Процесс благодаря которому сильно популяризировались языки высокого уровня – позволяет программисту не заботится о выделении и очистке памяти. Обязательно ознакомьтесь с тонкостями его работы в своем ЯП.
- Отладчик кода (debuger)
Удобный инструмент для анализа работы кода программы и выявления ошибок.
- Компиляторы, интерпретаторы и виртуальные машины
В зависимости от того, какой язык вы используете, вы можете подробно изучить процесс преобразования написанного вами кода в машинный код (набор нулей и единиц). Как правило, процессы компиляции/интерпретации/виртуализации состоят из нескольких этапов. Понимая их, вы сможете оптимизировать свои программы для более быстрой сборки и эффективного выполнения.
- Сборщик мусора (garbage collector)
🔗 Ссылки на материалы
- 📺 Python Memory Management на пальцах – YouTube
- 📺 Управление памятью в python – YouTube
- 📺 Утечки памяти в Node.js и JavaScript, сборка мусора и профилирование – YouTube
- 📺 Примеры утечек памяти в JavaScript – YouTube
- 📺 Как устроена сборка мусора в Go – YouTube
- 📺 Потребление оперативной памяти в языке Go: проблемы и пути решения – YouTube
-
Качество кода
За эти долгие годы, что существует программирование было написано огромное количество кода, программ и целых систем. Ну и как следствие, при разработке всего этого возникали разного рода проблемы. В первую очередь они были связаны с масштабированием, поддержкой, а также порогом входа для новых разработчиков. Умные люди, естественно, не сидели на месте и начали решать эти проблемы, тем самым создавая так называемые паттерны/принципы/подходы для написания качественного кода.
Изучив лучшие практики программирования, вы не только сделаете лучше для себя, но и для других, поскольку с вашим кодом будут работать другие разработчики.
- DRY (Don't Repeat Yourself)
- KISS (Keep It Simple, Stupid)
- YAGNI (You Aren't Gonna Need It)
- SOLID принципы
- GRASP (General Responsibility Assignment Software Patterns)
Для многих языков существуют специальные руководства по стилю и соглашения по написанию кода. В них обычно сравнивается правильный и неправильный способ написания кода и объясняется, почему это так.
🔗 Ссылки на материалы
- 📄 Практика хорошего кода – habr.com
- 📄 Принципы для разработки: KISS, DRY, YAGNI... – habr.com
- 📺 SOLID принципы простым языком (много примеров) – YouTube
- 📄 Простое объяснение принципов SOLID – habr.com
- 📄 Принципы SOLID, о которых должен знать каждый разработчик – medium.com
- 📄 GRASP паттерны проектирования – habr.com
- 📄 Google style guides – GitHub
Базы данных
База данных (БД) – набор данных, которые организованы по определённым правилам. Например, библиотека является базой данных для книг.
Система управления базой данных (СУБД) – программное обеспечение, которое позволяет создать БД и удобно ей манипулировать (выполнять различные операции над данными). Примером СУБД может являться библиотекарь. Он может легко и эффективно работать с книгами в библиотеке: выдавать запрашиваемые книги, принимать их обратно, добавлять новые и т.д.
-
Классификация баз данных
БД могут существенно отличаться друг от друга и соответственно иметь разные области применения. Для понимания какая БД подойдёт для той или иной задачи, необходимо разобраться с классификацией.
- Реляционные БД (relation – отношение, связь)
Представляют из себя хранилища, где данные организованны в виде набора таблиц (со строками и столбцами). Взаимодействия между данными организуются на основе связей между этими таблицами. БД такого типа обеспечивает быстрый и эффективный доступ к структурированной информации.
- Объектно-ориентированные БД
Здесь данные представляются в виде объектов с набором атрибутов и методов. Подходят для тех случаев, когда требуется высокопроизводительная обработка данных, имеющих сложную структуру.
- Распределенные
Состоят из нескольких частей, расположенных на разных компьютерах (серверах). Такие БД могут полностью исключать дублирование информации, либо полностью её дублировать в каждой распределенной копии (например, как блокчейн)
- Не реляционные (NoSQL)
Хранят и обрабатывают неструктурированные или слабоструктурированные данные. Этот тип БД подразделяется на подтипы:
- Модель ключ-значение
- Семейство столбцов (строки и столбцы используются как ключи)
- Документо-ориентированные (хранят данные в виде иерархии документов)
- Графовые (применяются для данных с большим количеством связей)
- Модель ключ-значение
- Реляционные БД (relation – отношение, связь)
🔗 Ссылки на материалы
-
Реляционная база данных
Наиболее популярные реляционные БД: MySQL, PostgreSQL, MariaDB, Oracle. Для работы с ними используется специальный язык – SQL (Structured Query Language). Он довольно простой и интуитивно понятный.
- Основы SQL
Изучите основной цикл операций по созданию/получению/обновлению/удалению данных. Всё остальное по мере надобности.
- Объединение таблиц
- Запрос данных из нескольких таблиц
Оператор
JOIN; Комбинации с другими операторами; типыJOIN: (внешние/внутренние, левое/правое, перекрёстные, полные) - Связи между таблицами
Ссылки из одной таблицы на другую; внешние ключи (FOREIGN KEY)
- Запрос данных из нескольких таблиц
- Подзапросы
Запрос внутри другого запроса SQL
- Индексы
Структура данных, позволяющая быстро определить положение интересующих данных в базе.
- Транзакции
Последовательности команд, которые должны быть выполнены полностью, либо не выполнены вообще.
- Команда
START TRANSACTION - Команды
COMMITиROLLBACK
- Команда
- Работа с языком программирования
Для этого необходимо установить драйвер (адаптер) базы данных под ваш ЯП.
Например psycopg2 для Python, node-postgres для Node.js, pgx для Go. - ORM (Object-Relational Mapping) библиотеки
Писать SQL-запросы в коде трудно. В них легко допускать ошибки и опечатки, поскольку это просто строки которые никак не валидируются. Для решения этой проблемы существуют так называемые ORM-библиотеки, которые позволяют выполнять SQL-запросы, как если бы вы просто вызывали методы у объекта. К сожалению и с ними не все так гладко, поскольку "под капотом" запросы, которые генерируются этими библиотеками далеко не самые оптимальные в плане производительности (поэтому будьте готовы работать как с ORM, так и с чистым SQL).
Популярныме ORM: SQLAlchemy для Python, Prisma для Node.js, GORM для Go. - Оптимизация и производительность
- Основы SQL
🔗 Ссылки на материалы
- 📺 Базы данных SQL уроки для начинающих – YouTube
- 📺 Что такое SQL и реляционные базы данных – YouTube
- 📺 Базы данных (плейлист) – YouTube
- 📺 Основы SQL (плейлист) – YouTube
- 📘 Изучаем SQL – Алан Бьюли, 2017
- 📺 Практика SQL (плейлист) – YouTube
- 📄 Онлайн-тренажёр по SQL
- 📘 SQL Сборник рецептов – Энтони Молинаро, 2009
- 📺 Расширенные возможности SQL (плейлист) – YouTube
- 📄 8 книг по PostgreSQL для новичков и профессионалов – selectel.ru
- 📺 Что такое SQL ИНДЕКСЫ за 10 минут: Объяснение с примерами – YouTube
- 📄 Индексы в PostgreSQL – habr.com
- 📺 PostgreSQL. Индексы: то, что вы всегда хотели узнать, но боялись спросить – YouTube
- 📺 Вся правда об индексах в PostgreSQL – YouTube
- 📺 Лекция - Что такое ORM? Почему стоит использовать ORM? – YouTube
-
MongoDB
MongoDB - это популярная NoSQL база данных, которая хранит данные в гибких, JSON-подобных документах, что позволяет создавать динамические и масштабируемые структуры данных. Она обеспечивает высокую производительность, горизонтальную масштабируемость и мощный язык запросов.
- Основные команды
Изучите основной цикл операций по созданию/получению/обновлению/удалению данных. Всё остальное по мере надобности.
- Агрегации
MongoDB предоставляет конвейеры агрегации для выполнения сложных запросов и вычислений.
- Работа с индексами
Индексирование является важной концепцией в MongoDB для повышения производительности.
- Работа с языком программирования
Для этого необходимо установить драйвер MongoDB под ваш ЯП.
- Изучите лучшие практики
Узнайте о лучших практиках проектирования схем, индексирования и оптимизации запросов. Ознакомьтесь с ними, чтобы обеспечить производительность и масштабируемость ваших приложений.
- Масштабирование
Узнайте о масштабировании для работы с большими массивами данных и высоким трафиком. MongoDB предоставляет шардинг и наборы реплик для горизонтального и вертикального масштабирования.
- Основные команды
🔗 Ссылки на материалы
-
Redis
Redis – быстрое хранилище данных работающее со структурами типа ключ-значение. Может использоваться в качестве базы данных, кэша, брокера сообщений или очереди.
- Типы данных
Строки / Списки / Множества (sets) / Хэш-таблицы (hashes) / Упорядоченные множества (sorted sets)
- Базовые операции
SET key "value" # установка ключа key со значение "value" GET key # получить значение по указанному ключу SETNX key "data" # установка значения / создания ключа MSET key1 "1" key2 "2" key3 "3" # установка нескольких ключей MGET key1 key2 key3 # получение значений сразу по нескольким ключам DEL key # удалить пару ключ-значение INCR someNumber # увеличение числового значения по ключу на 1 DECR someNumber # уменьшение числового значения по ключу на 1 EXPIRE key 1000 # установить таймер жизни ключа 1000 секунд TTL key # получить информацию о времени жизни пары ключ-значение # -1 ключ существует, но не имеет срока действия # -2 ключ не существует # <другое число> время жизни ключа в секундах SETEX key 1000 "value" # объединение команды SET и EXPIRE - Транзакции
MULTI— начать запись команд для транзакции.
EXEC— выполнить записанные команды.
DISCARD— удалить все записанные команды.
WATCH— команда, обеспечивающая выполнение только в случае, если другие клиенты не изменили значение переменной. Иначе EXEC не выполнит записанные команды.
- Типы данных
🔗 Ссылки на материалы
-
Требования ACID
ACID – это аббревиатура состоящая из названий четырёх основных свойств, которые гарантируют надежность транзакций в БД.
- Atomicity (атомарность)
Гарантирует, что транзакция будет выполнена полностью, либо не выполнена вообще.
- Consistency (согласованность)
Гарантирует, что каждая успешная транзакция фиксирует только допустимые результаты (какие-либо несоответствия исключены).
- Isolation (изолированность)
Гарантирует, что одна транзакция никак не может повлиять на другую.
- Durability (стойкость)
Гарантирует сохранение изменений внесённые транзакцией.
- Atomicity (атомарность)
🔗 Ссылки на материалы
-
Проектирование баз данных
Проектирование баз данных очень важная тема, которая часто упускается из виду. Грамотно спроектированная БД обеспечит долговременную масштабируемость и простоту обслуживания данных. Можно выделить несколько основных этапов при проектировании:
- Определение сущностей
Сущность - это объект, понятие или событие, имеющее свой собственный набор атрибутов. Например, если вы разрабатываете базу данных для библиотеки, сущностями могут в ней могут быть книги, авторы, издатели и т.д.
- Определение атрибутов для каждой сущности
Каждая сущность должна иметь как минимум один атрибут. Например, атрибуты книги могут включать ее название, автора, ISBN и дату публикации. Каждый атрибут имеет определенный тип данных, будь то строка, целое число, логический тип и т.д.
- Определение ограничений
Значения атрибутов могут иметь определенные ограничения. Например, строки должны быть только уникальными или иметь ограничение на максимальное количество символов.
- Определите отношения
Сущности могут быть связаны друг с другом одним из типов отношений: один к одному, один ко многим или многие ко многим. Например, у книги может быть один или несколько авторов, а автор может написать одну или несколько книг. Вы можете представить эти отношения, создав внешний ключ в одной таблице, который ссылается на первичный ключ в другой таблице.
- Нормализация
Это процесс разделения данных по отдельным связанным таблицам. Нормализация устраняет избыточность данных (data redundancy) и тем самым позволяет избежать нарушения целостности данных при их изменении.
- Оптимизация производительности
Создайте индексы для часто запрашиваемых столбцов, настройте конфигурацию базы данных под ваше приложение и оптимизируйте запросы, которые используются для доступа к данным.
- Определение сущностей
🔗 Ссылки на материалы
- 📄 Основы проектирования баз данных. – GitHub
- 📄 Руководство по проектированию реляционных баз данных – metanit.com
- 📺 Базы данных. Проектирование – YouTube
- 📺 Лекция по проектированию схем базы данных – YouTube
- 📺 Проектирование баз данных за 40 минут. Практика – YouTube
- 📄 Руководство по проектированию реляционных баз данных – habr.com
- 📄 Основы современных баз данных
Разработка API
API (Application Programming Interface) – программный интерфейс, который описывает определенный набор правил, по которым различные программы (приложения, боты, сайты...) могут взаимодействовать друг с другом. С помощью вызовов API можно выполнить определённые функции программы не зная, как она работает.
При разработке серверных приложений могут использоваться разные форматы API, в зависимости от поставленных задач и требований.
-
REST API
REST (Representational State Transfer) – архитектурный подход, который описывает набор правил того, как программисту организовать написание кода серверного приложения, чтобы все системы легко обменивались данными и приложение можно было легко масштабировать. При построении REST API широко используются методы HTTP-протокола.
Основные правила написания хорошего REST API:
- Использование HTTP-методов
Как правило, для работы над определенной моделью данных используется единый URL-маршрут (например для пользователей –
/api/user). Для выполнения разных операций (получение/создание/изменение/удаление) этот маршрут должен реализовывать обработчики на соответствующие HTTP-методы (GET/POST/PUT/DELETE). - Использование множественных названий
Например, URL-маршрут на получение одного пользователя по id выглядит так:
/user/42, а на получение всех пользователей так:/users. - Отправка соответствующих HTTP-кодов ответа
Самые часто используемые: 200, 201, 204, 304, 400, 401, 403, 404, 405, 410, 415, 422, 429.
- Использование версионности
Со временем у Вас может возникнуть желание или необходимость кардинально изменить принцип работы вашего REST API сервиса. Чтобы не ломать приложения использующие текущую версию, можно оставить её на прежнем месте, а новую версию реализовать поверх другого URL-маршрута, например
/api/v2.
- Использование HTTP-методов
🔗 Ссылки на материалы
- 📄 Что такое API
- 📄 Что такое REST API
- 📺 Что такое REST API – YouTube
- 📺 Что такое CRUD за 6 минут – YouTube
- 📄 Введение в REST API
- 📄 Используем API как разработчики
- 📄 Основы REST: теория и практика – tproger.ru
- 📄 Глоссарий API и источники
- 📄 REST API Best Practices – habr.com
- 📄 Версионирование API или единая кодовая база для всех версий – habr.com
- 📄 JSON API – работаем по спецификации – habr.com
-
GraphQL
GraphQL это язык запросов и серверная среда выполнения API, которая позволяет получать и изменять данные с сервера с помощью единого URL-маршрута. Он обеспечивает ряд преимуществ, включая возможность получения только необходимых данных (снижения потребления трафика), агрегирование данных из нескольких источников и строгую систему типов для описания данных.
- Схема и типы данных
Изучите, как описывать данные с помощью схемы GraphQL и базовых типов.
- Queries (запросы) и Mutations (мутации)
Запросы используются для получения данных с сервера, тогда как мутации используются для изменения (создания, обновления или удаления) данных на сервере.
- Resolvers (резолверы)
Это функции, которые определяют, как получить данные для определенного поля в схеме GraphQL.
- Data sources
Это места, откуда вы получаете данные, например, базы данных или стороннего API. Источники данных подключаются к серверу GraphQL через резолверы.
- Оптимизация производительности
- Лучшие практики
- Схема и типы данных
🔗 Ссылки на материалы
-
WebSockets
Веб-сокеты это продвинутая технология, позволяющая открыть постоянное двунаправленное сетевое соединение между клиентом и сервером. С помощью его API вы можете отправить сообщение на сервер и получить ответ без выполнения HTTP-запроса, тем самым реализуя real-time взаимодействие.
Основная идея в том, что вам ненужно посылать запросы на сервер для получения новой информации. Когда соединение установлено, сервер сам будет отправлять новую порцию данных подключенным клиентам, как только эти данные появятся. Веб-сокеты широко используются для создания чатов, онлайн-игр, трейдерских приложений и т.д.
- Открытие веб-сокета
Отправка HTTP-запроса с определенным набором заголовков:
Connection: Upgrade,Upgrade: websocket,Sec-WebSocket-Key,Sec-WebSocket-Version. - Состояния соединения
CONNECTING,OPEN,CLOSING,CLOSED. - События
Open,Message,Error,Close. - Коды закрытия соединения
1000,1001,1006,1009,1011и т.д.
- Открытие веб-сокета
🔗 Ссылки на материалы
- 📺 Что такое веб-сокеты за 4 минуты – YouTube
- 📺 Что такое Websocket? Websockets простыми словами – YouTube
- 📺 Web сокеты | Компьютерные сети. Продвинутые темы – YouTube
- 📄 Использование WebSockets в браузере – learn.javascript.ru
- 📺 Пример использования WebSocket на Python – YouTube
- 📺 [ENG] Все об WebSocket на Node.js за 30 минут – YouTube
- 📺 [ENG] Приложение с WebSocket на Go – YouTube
- 📄 WebSocket и HTTP/2+SSE. Что выбрать? – habr.com
-
RPC (Remote Procedure Call)
RPC – технология удаленного вызова процедур. Фактически, это просто вызов функции на сервере с набором определенных аргументов, который ответом отдает результат вызова этой функции. Существует несколько протоколов, которые реализуют RPC.
- Протоколы на основе XML
Существует два основных: XML-RPC и SOAP (Simple Object Access Protocol)
Они считаются устаревшими и не рекомендуются для новых проектов, поскольку потребляют много трафика и сложнее в реализации по сравнению с более новыми альтернативами, такими как REST, GraphQL и другими RPC-протоколами. - JSON-RPC
Протокол с очень простой спецификацией. Все запросы и ответы сериализуются в формате JSON.
- Запрос к серверу включает в себя:
method- имя вызываемого метода;params- объект или массив значений, передаваемых в качестве параметров определенному методу;id- идентификатор, используемый для сопоставления ответа с запросом. - Ответ включает в себя:
result- данные, возвращенные вызванным методом;error- объект с ошибкой или null при успехе;id- тот же, что и в запросе.
- Запрос к серверу включает в себя:
- gRPC
RPC-фреймворк, разработанный компанией Google. Работает на основе Protocol Buffers, языкового формата двоичной сериализации, который генерируется в код клиента и сервера для различных языков программирования.
- Протоколы на основе XML
🔗 Ссылки на материалы
-
WebRTC
WebRTC – open-source проект для организации передачи потоковых данных (видео, звука) в браузере. Работа WebRTC основана на peer to peer соединении, однако существуют реализации позволяющие организовывать сложные групповые сеансы. Например, сервис видео-звонков Google Meet широко использует WebRTC.
🔗 Ссылки на материалы
Программное обеспечение
-
Система контроля версий Git
Git - специальная система для управления историей изменения исходного кода. Любые изменения которые вносятся в Git могут быть сохранены, что позволяет откатываться (возвращаться) на ранее сохраненную копию проекта. На данный момент Git является стандартом для разработки.
- Основные команды
git init # инициализация Git в текущей папке git add [файл] # добавить файл в Git git add . # добавить все файлы в папке в Git git reset [файл] # отменить добавление указанного файла git reset # отменить добавление всех файлов git commit -m "ваш текст" # создать коммит (сохранение) git status # показывает статус добавленных файлов git push # отправить текущие коммиты в удаленный репозиторий git pull # загрузить изменения с удаленного репозитория git clone [ссылка] # склонировать указанный репозиторий к себе на ПК - Работа с ветками
Ветвление позволяет отклонятся от основной линии разработки и продолжать работу независимо.
git branch # показать список текущих веток git branch [имя] # создать новую ветку от текущего коммита git checkout [имя] # переключиться на указанную ветку git merge [имя] # слияние указанной ветки в текущую ветку git branch -d [имя] # удалить указанную ветку - Отмена коммитов
git revert HEAD --no-edit # создать новый коммит который отменяет изменения предыдущего git revert [хэш_коммита] --no-edit # то же действие, но с указанным коммитом - История изменений
git log [ветка] # показать коммиты указанной ветки git log -3 # показать 3 последних коммита текущей ветки git log [файл] # показать историю коммитов указанного файла
- Основные команды
🔗 Ссылки на материалы
-
Docker
Docker - специальная программа, которая позволяет запускать изолированные песочницы (контейнеры) с различным предустановленным окружением (будь то определенная операционная система, база данных и т.д.). Технология контейнеризации, которую предоставляет Docker, схожа с виртуальными машинами, но в отличие от виртуальных машин, контейнеры используют ядро хостовой ОС, что требует гораздо меньших ресурсов.
- Образ (image)
Специальный фиксированный шаблон, в котором содержится описание среды для запуска приложения (ОС, исходный код, библиотеки, переменные окружения, файлы конфигурации и т.д.). Образы можно скачивать с официального сайта и на их основе создавать свои.
- Контейнер (container)
Изолированная среда, созданная на основе какого-либо образа. По сути это является запущенным процессом на компьютере, который внутри содержит то окружение, которое описано в образе.
- Основные команды
docker pull [имя_образа] # Загрузить образ из сети docker images # Список доступных образов docker run [id_образа] # Запуск контейнера на основе выбранного образа # Некоторые флаги для команды run: -d # Запуск с возвратом в консоль --name [имя] # Задать имя контейнеру --rm # Удалить контейнер после остановки -p [локальный_порт][порт_внутри_контейнера] # Проброс портов docker build [путь_к_Dockerfile] # Создание образа на основе Dockerfile docker ps # Список запущенных контейнеров docker ps -a # Список всех контейнеров docker stop [id/имя_контейнера] # Остановить контейнер docker start [id/имя_контейнера] # Запустить существующий контейнер docker attach [id/имя_контейнера] # Подключится к консоли контейнера docker logs [id/имя_контейнера] # Вывести логи контейнера docker rm [id/имя_контейнера] # Удалить контейнер docker container prune # Удалить все контейнеры docker rmi [id_образа] # Удалить образ - Инструкции Dockerfile
Dockerfile представляет собой файл с набором инструкций и аргументов для создания образов.
FROM [имя_образа] # Задание базового образа WORKDIR [путь] # Задание корневой директории внутри контейнера COPY [путь_относительно_Dockefile] [путь_в_контейнере] # Копирование файлов ADD [путь] [путь] # Аналогично команде выше RUN [команда] # Команда которая запускается только при инициализации образа CMD ["команда"] # Команда которая отрабатывает каждый раз при запуске контейнера ENV КЛЮЧ="ЗНАЧЕНИЕ" # Установка переменных окружения ARG ИМЯ=ЗНАЧЕНИЕ # Задание переменных для передачи Docker во время сборки образа ENTRYPOINT ["команда"] # Команда которая запускается во время работы контейнера EXPOSE порт/протокол # Указывает на необходимость открыть порт VOLUME ["путь"] # Создаёт точку монтирования для работы с постоянным хранилищем - Docker-compose
Специальный инструмент позволяющий одновременно запускать несколько контейнеров с разной инфраструктурой. В каком-то смысле это Dockerfile на максималках.
- Образ (image)
🔗 Ссылки на материалы
- 📄 Что такое виртуализация и для чего она нужна
- 📄 Что такое Docker: для чего он нужен и где используется – selectel.ru
- 📄 Как и для чего использовать Docker
- 📺 Docker. Полный курс Docker для начинающих за 3 часа – YouTube
- 📺 Docker для Начинающих. Полный Курс – YouTube
- 📄 Полное практическое руководство по Docker – habr.com
- 📄 Изучаем Docker: файлы Dockerfile – habr.com
- 📄 Руководство по Docker Compose для начинающих – habr.com
- 📄 Установка и настройка PostgreSQL в Docker – selectel.ru
-
Postman/Insomnia
При создании серверной части приложения, возникает необходимость в тестировании его работоспособности. Это можно сделать разными способами. Один из самых простых – это воспользоваться консольной утилитой curl. Но такой способ годится для совсем простых приложений. Намного эффективнее использовать специальное ПО для тестирования, которое имеют удобный интерфейс и весь необходимый функционал для создания коллекций запросов.
- Postman
Очень популярная и многофункциональная программа. Здесь точно есть всё, что Вам может пригодиться и даже больше: начиная от банального создания коллекций до поднятия mock-серверов. Основной функционал приложения предоставляется бесплатно.
- Insomnia
Не такой популярный, но очень приятный инструмент. Интерфейс в Insomnia, минималистичный и понятный. Здесь поменьше функционала, но все самое необходимое есть: коллекции, переменные, работа с GraphQL, gRPC, WebSocket и т.д. Имеется возможность установки сторонних плагинов.
- Postman
🔗 Ссылки на материалы
-
Веб-сервера

Веб-сервер – это программа предназначенная для обработки входящих запросов по протоколу HTTP. Также он может вести журналы ошибок (логи), производить аунтефикацию и авторизацию, хранить правила на обработку файлов и т.д.
- Зачем нужен?
- Не все языки могут иметь встроенный веб-сервер (например PHP). Поэтому для запуска веб-приложений, написанных на таких языках, необходим сторонний.
- На одном сервере (виртуальном или выделенном) может быть запущенно несколько приложений, но внешний IP-адрес только один. Сконфигурированный веб-сервер способен перенаправлять поступающие запросы в нужные приложения.
- Популярные веб-серверы
- Зачем нужен?
🔗 Ссылки на материалы
- 📺 Что такое веб сервер и для чего он нужен? – YouTube
- 📄 Веб-сервер: краткий обзор
- 📄 Что такое Nginx
- 📄 Веб-сервер Nginx: краткий обзор
- 📺 Основы Nginx (плейлист) – YouTube
- 📄 NGINX изнутри: рожден для производительности и масштабирования – habr.com
- 📄 Что такое Apache
- 📄 Веб-сервер Apache: краткий обзор
- 📄 Apache vs Nginx: практический взгляд – habr.com
- 📺 Установка web-сервера Apache на Linux Ubuntu и публикация web-сайта – YouTube
- 📺 Web-технологии. Web сервера | Технострим – YouTube
- 📺 Веб-сервер на Ubuntu 18 с нуля: nginx, HTTP/2, Brotli и HTTPS – YouTube
-
Брокеры сообщений

При создании масштабной backend-системы может возникать проблема коммуникации между большим количеством микросервисов. Чтобы не усложнять уже имеющиеся сервисы (налаживать надёжную систему коммуникации, распределять нагрузку, предусматривать различные ошибки и т.д.) можно использовать отдельный сервис, который называется брокером сообщений (очередью сообщений).
Брокер берет на себя ответственность создания надежной и отказоустойчивой системы коммуникации между сервисами (выполняет балансировку, гарантирует доставки, мониторит получателей, ведёт логи, буферизацию и т.д.)
Под сообщением понимается обычный HTTP запрос/ответ с данными определенного формата.
🔗 Ссылки на материалы
- 📺 Системы доставки сообщений, для чего они нужны? – YouTube
- 📄 Что такое очередь сообщений? – Amazon)
- 📄 Понимание брокеров сообщений. Изучение механики обмена сообщениями – habr.com
- 📺 Микросервисы: Коммуникации через очередь сообщений – YouTube
- 📺 RabbitMQ Tutorial на русском (плейлист) – YouTube
- 📄 Что такое Apache Kafka за 5 минут – YouTube
- 📄 Apache Kafka: основы технологии – habr.com
- 📺 Про Kafka (основы) – YouTube
- 📺 Брокер сообщений Kafka в условиях повышенной нагрузки – YouTube
- 📄 Выбор MQ для высоконагруженного проекта – habr.com
-
Ngrok
Ngrok - это инструмент для создания общедоступных туннелей в интернет, который позволяет локальным сетевым приложениям (веб-серверам, веб-сервисам и т.д.) стать доступными извне.
- Как это работает?
Ngrok создает временный публичный URL-адрес, который может быть использован для доступа к вашему локальному серверу из Интернета. После запуска Ngrok вы получаете доступ к консоли, где можно наблюдать за запросами, обработкой и ответами на эти запросы, а также настраивать дополнительные функции, такие как аутентификация и шифрование.
- Для чего это использовать?
Например, для тестирования веб-сайтов и API-интерфейсов, демонстрации работающих приложений на локальном сервере, доступа к локальным сетевым приложениям через Интернет без необходимости настройки маршрутизатора, прокси-сервера и т.д.
- Как это работает?
🔗 Ссылки на материалы
-
Инструменты ИИ
Системы искусственного интеллекта (ИИ) в последнее время совершили невероятный скачок. С каждым днем появляется все больше инструментов, которые могут писать за вас код, генерировать документацию, проводить код-ревью, помогать изучать новые технологии и так далее. Многие люди все еще скептически относятся к возможностям и качеству контента, который создает ИИ. Но, по крайней мере, уже сейчас можно сэкономить много времени и ресурсов для повышения производительности любого разработчика.
- ChatGPT
Самая качественная языковая модель на данный момент. Работает как обычный чат-бот и без проблем понимает человеческую речь на нескольких языках.
- Bard
Разработан компанией Goolge в качестве альтернативы и прямого конкурента ChatGPT.
- GitHub Copilot
Инструмент для авто-заполнения кода на основе искусственного интеллекта, разработанный в GitHub в сотрудничестве с разработчиками ChatGPT. Он интегрируется с популярными текстовыми редакторами и предоставляет предложения и дополнения к коду в режиме реального времени по мере его написания.
- Tabnine
Альтернатива GitHub Copilot, которая предоставляет контекстно-зависимые предложения по коду на основе шаблонов, полученных из миллионов общедоступных репозиториев.
- ChatGPT
🔗 Ссылки на материалы
Безопасность
-
Уязвимости веб-приложений
- Межсайтовый скриптинг (XSS)
Атака, которая позволяют злоумышленнику внедрять вредоносный код через веб-сайт в браузеры других пользователей.
- SQL-инъекций
Атака может быть возможна если, пользовательский ввод, который передаётся в SQL-запрос, способен изменить смысл оператора или добавить туда другой запрос.
- Подделка межсайтовых запросов (CSRF)
Когда на сайте для выполнения какой-либо операции используется POST-запрос, злоумышленник может подделать форму, например в электронном письме и отправить его жертве. Затем жертва, являющаяся авторизованным пользователем, взаимодействую с этим письмом, не зная того, может отправить запрос на сайт с данными, которые задал злоумышленник.
- Кликджекинг (Clickjacking)
Принцип основан на том, что поверх видимой веб-страницы располагается невидимый слой, в который и загружается нужная злоумышленнику страница, при этом элемент управления (кнопка, ссылка), необходимый для осуществления требуемого действия, совмещается с видимой ссылкой или кнопкой, нажатие на которую ожидается от пользователя.
- DoS-атака (Denial of Service)
Хакерская атака, которая приводит к перегрузке сервера, на котором работает веб-приложение, за счет отправки огромного количества запросов.
- Man-in-the-Middle (человек посередине)
Тип атаки при которой злоумышленник попадает в цепь между двумя (или более) общающимися сторонами, чтобы перехватить разговор или передачу данных.
- Неверная конфигурация безопасности
Использование параметров конфигурации по умолчанию может быть опасным, поскольку это общеизвестная информация. К примеру, частой уязвимостью является то, что сетевые администраторы оставляют стандартные логины и пароли admin:admin.
- Межсайтовый скриптинг (XSS)
🔗 Ссылки на материалы
- 📄 Веб-безопасность – (MDN) mozilla.org
- 📄 Безопасность веб-приложений: от уязвимостей до мониторинга – habr.com
- 📺 Безопасность: уязвимости вашего приложения – YouTube
- 📺 Самые популярные уязвимости Web-приложений в контексте Golang – YouTube
- 📄 Как защитить веб-приложение: основные советы, инструменты, полезные ссылки – tproger.ru
- 📄 Что такое XSS-уязвимость и как тестировщику не пропустить ее – habr.com
- 📄 DDoS-атаки: что это, происхождение, виды и способы защиты – selectel.ru
- 📄 DDoS-атаки: нападение и защита – habr.com
- 📄 Man-in-the-Middle: советы по обнаружению и предотвращению
- 📺 Безопасность Web-приложений (плейлист) – YouTube
- 📺 Безопасность интернет-приложений (плейлист) – YouTube
- 📄 Аналитика уязвимостей и угроз веб-приложений за 2019 год
-
Переменные окружения
Часто в ваших приложениях могут использоваться различные токены (например для доступа к стороннему платному API), логины и пароли (для подключения к базе данных), различные секретные ключи для подписей и так далее. Все эти данные не должны быть известны и доступны посторонним людям, соответственно оставлять их в коде программы ни в коем случае нельзя. Для решения этой проблемы существуют переменные окружения.
- Файл
.envСпециальный файл в котором можно хранить все переменные окружения.
- Парсинг
.envфайлаПеременные передаются в программу с помощью аргументов командной строки. Чтобы сделать подобное с
.envфайлом необходимо воспользоваться специальной библиотекой под ваш ЯП. - Хранение и передача
Изучите как загружать
.envфайлы на хостинг сервисы, а так же помните, что такие файлы нельзя коммитить в удаленные репозитории, поэтому не забывайте добавлять их в исключения через файл.gitignore.
- Файл
🔗 Ссылки на материалы
-
Хеширование

Для обеспечения безопасности в сети широко используется криптографические алгоритмы на основе хеш-функций.
Основные понятия:
- Хеширование
Процесс преобразования массива информации (от одной буквы и хоть до целого литературного произведения) в некую уникальную короткую строку символов (называемую хэшем), которая присуща только этому массиву информации. Причем если в этом массиве информации изменить хоть один символ, то новый хэш будет отличатся кардинально.
Хеширование является необратимым процессом, то есть по полученному хэшу невозможно восстановить изначальные данные. - Контрольные суммы
Хэши могут использоваться как контрольные суммы, которые служат доказательством целостности данных.
- Коллизии
Cлучаи когда хеширование разного набора информации приводит к одинаковым хэшам.
- Соль (в криптографии)
Случайная строка данных, которая добавляется к входным данным перед хешированием, для вычисления хэша. Это необходимо для усложнения взлома методом перебора.
Основные алгоритмы хеширования:
- Семейство SHA (Secure Hash Algorithm)
SHA-256 наиболее популярный алгоритм шифрования. Используется, например, в Bitcoin.
- Семейство MD (Message Digest)
Наиболее популярный алгоритм семейства – MD5. Сейчас считается очень уязвимым к коллизиям (существуют даже генераторы коллизий для MD5).
- CRC (Cyclic redundancy check)
Алгоритм нахождения контрольной суммы, предназначенный для проверки целостности данных.
- Хеширование
🔗 Ссылки на материалы
- 📄 Хеш-функция, что это такое? – habr.com
- 📺 Что такое ХЭШ функция? | Хеширование – YouTube
- 📺 Как работает хэширование – YouTube
- 📺 Hash/Хеш - просто о сложном – YouTube
- 📺 Как работает SHA256 – YouTube
- 📄 «Привет, мир»: разбираем каждый шаг хэш-алгоритма SHA-256 – habr.com
- 📄 Все методы взлома MD5
- 📄 CRC: как защитить программу
- 📄 Простой расчет контрольной суммы – habr.com
-
Аутентификация и авторизация
Важно понимать отличие между двумя этими понятиями.
Аутентификация – процедура проверки подлинности пользователя. Как правило выполняется путем сравнения введенного пользователем пароля с паролем, сохраненным в базе данных. Так же, в это понятие часто включают и идентификацию – процедуру выявления пользователя по его уникальному идентификатору (как правило это обычный логин или email). Это нужно, чтобы точно знать для какого пользователя выполняется проверка подлинности.
Авторизация – процедура выдачи прав доступа определенному пользователю на выполнение определенных операций. Например обычные пользователи интернет-магазина могут просматривать товары, добавлять их в корзину. А вот добавлять новые товары или удалять уже имеющиеся могут только администраторы.
- Basic Authentication
Наиболее простая схема аутентификации, при которой username и password пользователя передаются в заголовке Authorization в незашифрованном виде (base64-encoded). При использовании HTTPS является относительно безопасным.
- SSO (Single Sign-On)
Технология реализующая возможность перехода из одного сервиса в другой (не связанный с первым), без повторной аутентификации.
- OAuth / OAuth 2.0
Протокол авторизации благодаря которому можно зарегистрироваться в различных приложениях с помощью популярных сервисов (Google, Facebook, GitHub и т.д.)
- OpenID
Открытый стандарт, позволяющий создавать единую учётную запись для аутентификации на множестве не связанных друг с другом сервисов.
- JWT (Json Web Token)
Стандарт аутентификации работающий на основе токенов доступа. Токены создаются сервером, подписываются секретным ключом и передаются клиенту, который в дальнейшем использует данный токен для подтверждения своей личности.
- Basic Authentication
🔗 Ссылки на материалы
- 📄 Аутентификация и авторизация в микросервисных приложениях – habr.com
- 📄 Обзор способов и протоколов аутентификации в веб-приложениях – habr.com
- 📄 Как работает single sign-on (технология единого входа)? – habr.com
- 📄 OAuth 2: введение в протокол авторизации – selectel.ru
- 📺 Как работает OAuth 2 - введение (просто и понятно) – YouTube
- 📄 OAuth 2.0 простым и понятным языком – habr.com
- 📺 OpenID Connect. Теория – YouTube
- 📄 OpenID Connect простыми словами – habr.com
- 📄 Пять простых шагов для понимания JSON Web Tokens (JWT) – habr.com
- 📺 Виды авторизации: сессии, JWT-токены. Для чего нужны сессии? Как работает JWT? – YouTube
- 📺 JWT. Часть 1. Теория – YouTube
-
SSL/TLS
SSL (Secure Socket Layer) и TLS (Transport Layer Security) – это криптографические протоколы, которые обеспечивают защищённую передачу данных между двумя компьютерами в сети. По сути эти протоколы работают одинаково и отличий у них нет. SSL считается устаревшим, хотя все еще используется для поддержки старых устройств.
- Центр сертификации
TLS/SSL использует цифровые сертификаты, выдаваемые центром сертификации. Одним из самых популярных является Let’s Encrypt.
- Конфигурация и установка сертификатов
Необходимо уметь генерировать сертификаты и правильно их устанавливать, чтобы Ваш сервер работал по HTTPS.
- Процесс рукопожатия (handshake)
Чтобы установить безопасное соединение между клиентом и сервером, должен произойти специальный процесс, который включает в себя обмен ключами и информацией об алгоритмах шифрования.
- Центр сертификации
🔗 Ссылки на материалы
- 📺 Протоколы TLS/SSL | Защищенные сетевые протоколы – YouTube
- 📄 Как это работает: знакомство с SSL/TLS – habr.com
- 📄 Что такое TLS – habr.com
- 📺 TLS/SSL сертификаты и с чем их едят – YouTube
- 📄 Как HTTPS обеспечивает безопасность соединения – habr.com
- 📺 Шифрование в TLS/SSL | Защищенные сетевые протоколы – YouTube
- 📺 Как получить и настроить LetsEncrypt SSL сертификат для сайта? – YouTube
- 📺 Криптография с нуля – YouTube
Тестирование
Тестирование — это процесс оценки того, что все части программы ведут себя так, как от них это ожидается. Покрытие продукта должным количеством тестов, позволяет в дальнейшем проводить быстрые проверки на то, не сломалось ли что-нибудь в приложении, после добавления нового или изменения старого функционала.
-
Unit-тесты
Самый простой вид тестов. Как правило, около 70-80% от всех тестов занимают именно unit-тесты. «Unit» означает, что тестируется не вся система в целом, а небольшие и отдельные её части (функции, методы, компоненты и т.д.) в изоляции от других. Всё зависимое внешнее окружение, как правило, покрывается моками (mocks).
- Какая польза от Unit-тестов?
Для примера представим автомобиль. Его «юниты» — это двигатель, тормоза, приборная панель и т.д. Их можно проверить по отдельности перед сборкой и, в случае чего заменить или починить. А можно собрать автомобиль, не протестировав юниты, — и он не поедет. Придётся всё разбирать и проверять каждую деталь.
- Что нужно чтобы начать писать Unit-тесты?
Как правило, средств стандартной библиотеки языка достаточно, чтобы писать качественные тесты. Но для более удобного и быстрого написания тестов, лучше использовать сторонние инструменты. Например:
- Для Python используется pytest, хотя для начала хватит и стандартного unittest.
- Для JavaScript/TypeScript лучший выбор – это Jest.
- Для Go – testify.
- И так далее...
- Какая польза от Unit-тестов?
🔗 Ссылки на материалы
- 📄 Юнит-тестирование для чайников – habr.com
- 📺 Unit tests - модульное тестирование – YouTube
- 📺 Python – юнит-тестирование. Использование unittest и coverage – YouTube
- 📺 Jest. Unit Тестирование в JavaScript – YouTube
- 📺 Тестирование в Go: от плохого к хорошему – YouTube
- 📄 Когда использовать mocks в юнит-тестировании – habr.com
-
Интеграционные тесты
Интеграционное тестирование подразумевает тестирование отдельных модулей (компонентов) в связке с другими (то есть, в интеграции). То, что при Unit-тестировании закрывалось заглушкой – теперь является реальным компонентом или целым модулем.
- Зачем это нужно?
Интеграционные тесты это следующий этап после юнитов. Протестировав каждый компонент по отдельности мы еще не можем сказать, что основной функционал программы работает без ошибок. Потенциально, еще может существовать множество проблем, которые всплывут только после взаимодействия различных частей программы между собой.
- Стратегии написания интеграционных тестов
- Большой Взрыв: большинство разработанных модулей соединяются вместе, образуя либо всю необходимую систему либо её большую часть. Если всё работает, то таким спобом можно сэкономить много времени.
- Инкрементальный подход: выполняется путем соединения двух или более логически связанных модулей и затем постепенно подключаются всё новые модули, пока не будет протестирована вся система.
- Подход снизу вверх: каждый модуль на более низких уровнях тестируется с помощью модулей следующего более высокого уровня , пока не будут протестированы все модули.
- Зачем это нужно?
🔗 Ссылки на материалы
-
E2E тесты

End-to-end (E2E, сквозные) тесты подразумевают тестирование работы всей системы в целом. При этом виде тестирования, реализуется среда максимально близкая к реальным условиям. Можно провести аналогию, что за компьютером сидит робот и нажимает кнопки в указанном порядке, как это делал бы реальный пользователь.
- Когда использовать?
E2E это самый сложный вид тестов. Они требуют много времени, как для написания, так и для выполнения, поскольку задействуют всё приложение. Поэтому, если ваше приложение небольшое (например, его разрабатываете только Вы), то скорее всего будет достаточно написания Unit и некоторого кол-ва интеграционных тестов.
- Когда использовать?
🔗 Ссылки на материалы
-
Нагрузочное тестирование
Когда вы создаете большое приложение, которое должно обслуживать большое количество запросов, возникает необходимость в тестировании этой самой возможности выдерживать большие нагрузки. Для создания искусственной нагруженности существует множество утилит.
- JMeter
Удобный интерфейс, кроссплатформенность, поддержка многопоточности, расширяемость, отличные возможности по созданию отчётов, поддержка многих протоколов для запросов.
- LoadRunner
Имеет интересную функцию виртуальных пользователей, которые параллельно что-то делают с тестируемым приложением. Это позволяет понять как влияет работа одних пользователей, активно что-то делающих с сервисом, на работу других.
- Gatling
Очень мощный инструмент ориентированный уже не более опытных пользователей. Для описания сценариев используется Scala.
- Taurus
Целый фреймворк для более удобной работы над JMeter, Gatling и так далее. Для описания тестов используется JSON или YAML.
- JMeter
🔗 Ссылки на материалы
- 📄 Поговорим о нагрузочном тестировании – habr.com
- 📺 Использование непрерывного нагрузочного тестирования для оценки ёмкости и ресурсов – YouTube
- 📄 Обзор инструментария для нагрузочного и перформанс-тестирования – habr.com
- 📄 Приручаем JMeter – habr.com
- 📄 Нагрузочное тестирование на Gatling — Полное руководство – habr.com
-
Регрессионное тестирование
Регрессионное тестирование (regression - движение назад) – вид тестирования, направленный на обнаружение ошибок в уже протестированных участках исходного кода.
- Зачем нужно?
По статистике, повторное появление одних и тех же ошибок в коде - довольно частое явление. И, что самое интересное, выпускаемые для них патчи/фиксы со временем также перестают работать. Поэтому считается хорошей практикой при исправлении ошибки создать тест на неё и регулярно прогонять его при последующих изменениях.
- Зачем нужно?
🔗 Ссылки на материалы
Развертывание (CI/CD)
-
Облачные сервисы
Прежде чем запустить приложение в сети, необходимо решить, где вы хотите его разместить. Вы можете арендовать собственный сервер или воспользоваться услугами облачных провайдеров, которые обладают большими функционалом для автоматизации процессов, мониторинга, балансировки нагрузки, хранения данных и так далее.
- AWS (Amazon Web Services)
Предоставляет широкий спектр услуг: хранение данных, управление базами данных, создание сетей, обеспечение безопасности и т.д. AWS - один из старейших и наиболее авторитетных поставщиков облачных услуг.
- Google Cloud
Ориентирован на машинное обучение и искусственный интеллект, имеет интеграции с другими сервисами Google, такими как Google Analytics и Google Maps.
- Microsoft Azure
Azure известен своей интеграцией с другими сервисами Microsoft, такими как Office 365 и Dynamics 365, а также поддержкой широкого спектра языков программирования и фреймворков.
- Digital Ocean
Предоставляет виртуальные частные серверы (VPS) для разработчиков и малого бизнеса. Известен своей простотой и удобством использования, а также низкими ценами.
- Heroku
Одна из первых PaaS-платформ. Поддерживает большой спектр языков программирования. До недавнего времени Heroku являлся наиболее популярным сервисом для размещения open-source проектов, поскольку имел бесплатный тарифный план (сейчас его убрали).
Как правило, все эти сервисы имеют интуитивно понятный простой интерфейс, подробную документацию, а также множество видеоуроков на YouTube.
- AWS (Amazon Web Services)
🔗 Ссылки на материалы
-
Управление контейнерами
Оркестровка контейнеров (container orchestration) - это процесс управления, автоматизации развертывания, масштабирования и обслуживания контейнерных приложений и зависимостей в кластере серверов.
- Docker в рабочей среде
Самый простой способ управления контейнерами - использовать непосредственно Docker, следуя списку правил для обеспечения стабильности и безопасности приложений.
- Храните свои образы Docker в частном реестре для предотвращения несанкционированного доступа.
- Используйте надежные механизмы аутентификации для доступа к реестру Docker и применяйте меры безопасности, такие как правила брандмауэра.
- Ужимайте размер контейнеров до минимума, убирая ненужные пакеты и зависимости.
- Используйте отдельные контейнеры для различных служб (например для сервера приложения, базы данных, хранилища кэша, метрики и т.д.).
- Используйте Docker Volumes для хранения постоянных данных, таких как файлы баз данных, журналы и файлы конфигурации.
- Docker swarm
Это собственный инструмент оркестровки Docker для управления, масштабирования и автоматизации таких задач, как обновление контейнеров, восстановление, балансировка трафика, service discovery и так далее.
- Kubernetes (K8s)
Это очень популярная платформа оркестровки, которая может работать с различными контейнерными рантаймами, включая Docker. Kubernetes предлагает более обширный набор функций (чем Docker swarm), включая расширенное планирование, оркестровку хранилищ и возможности продвинутого самовосстановления.
- Docker в рабочей среде
🔗 Ссылки на материалы
-
Инструменты автоматизации
Процесс развертывания ПО включает в себя множество этапов: тестирование, минимизация, сборка, установка зависимостей, интеграции с другими инструментами (репозитории, мониторинг и т.д.), установка переменных окружения, контейнеризация и так далее. Чтобы упростить этот трудоемкий пайплайн, можно прибегнуть к инструментам автоматизации.
- Github Actions
Инструмент CI/CD, встроенный в платформу Github, который позволяет разработчикам автоматизировать рабочие процессы для своих репозиториев. Отличный выбор, если вы уже используете GitHub. Имеется большое количество предварительно созданных прессетов для разных языков и платформ. Одна из самых полезных функций - возможность запускать рабочие процессы на основе различных событий, например на отправку пулл реквестов.
- Jenkins
Мощный инструмент с открытым исходным кодом с большой экосистемой плагинов, доступных для настройки его функциональности. Jenkins может использоваться в различных средах, включая локальные, облачные и гибридные системы.
- Circle CI
Это облачная платформа CI/CD, разработанная для быстрой и простой настройки с упором на экономию времени разработчиков. Circle CI интегрируется с различными облачными сервисами, такими как AWS, Google Cloud и Microsoft Azure. Вы также можете разместить ее локально в своей сети.
- Travis CI
Это также облачная платформа CI/CD. Ее можно легко интегрировать с GitHub или Bitbucket. Travis CI поддерживает множество языков программирования и фреймворков. Она также может быть развернута в качестве вашей локальной платформы.
- Github Actions
🔗 Ссылки на материалы
-
Мониторинг и логи
Логи фиксируют подробную информацию о событиях, ошибках и действиях в ваших приложениях, облегчая процесс устранения неисправностей и отладки. Они обеспечивают ведение истории поведения системы, позволяя вам находить проблемы, понимать их причины, чтобы повысить общую надежность и стабильность системы.
- Библиотеки для вашего языка
Самый простой способ логирования - использовать инструменты стандартной библиотеки языка или пакеты сторонних разработчиков. Например, в Python вы можете использовать модуль logging или Loguru. В Node.js – Winston, Pino. В языке Go – пакет log, Logrus.
- Loki
Предназначен для сбора данных логов из различных источников и обеспечивает возможности быстрого поиска и фильтрации.
- Graylog
Комплексная платформа управления логами, которая также централизует данные журналов из различных источников. Graylog предлагает такие функции, как прием, индексирование, поиск и анализ журналов.
- Стэк ELK (Elasticsearch, Logstash, Kibana)
Это сочетание трех инструментов с открытым исходным кодом, используемых для управления и анализа журналов. Elasticsearch - это распределенный поисковый и аналитический механизм, который хранит и индексирует журналы. Logstash - это конвейер ввода и обработки журналов, который собирает, фильтрует и преобразует данные журналов. Kibana - это веб-интерфейс, который позволяет искать, визуализировать и анализировать журналы, хранящиеся в Elasticsearch.
Метрики помогают отслеживать ключевые показатели производительности, использование ресурсов и поведение системы, позволяя выявлять узкие места, оптимизировать и обеспечивать эффективное распределение ресурсов.
- Prometheus
Система мониторинга с открытым исходным кодом, которая может собирать метрические данные из различных источников. В ней используется модель, основанная на принципе "вытягивания", при которой периодически производится "соскабливание" целей для сбора метрик. Собранные данные хранятся в специальной базе данных, что позволяет выполнять мощные запросы и анализ. Prometheus предоставляет гибкий язык запросов и удобный интерфейс для визуализации и мониторинга метрик. Он также включает систему оповещения на основе заданных правил и пороговых значений.
- Grafana
Инструмент для визуализации и мониторинга. Он позволяет создавать визуально красивые панели и диаграммы для анализа и мониторинга метрических данных из различных источников, включая базы данных и системы мониторинга, такие как Prometheus и InfluxDB.
- InfluxDB
База данных, разработанная специально для хранения метрик и событий. Предлагает простой и гибкий язык запросов для извлечения ценной информации из хранящихся данных. InfluxDB позволяет легко агрегировать, сокращать выборку и применять различные политики хранения.
- Библиотеки для вашего языка
🔗 Ссылки на материалы
- 📄 Loki — сбор логов, используя подход Prometheus – habr.com
- 📄 Изучаем ELK. Часть I — Установка Elasticsearch – habr.com
- 📄 Основы мониторинга (обзор Prometheus и Grafana) – habr.com
- 📄 Долгосрочное хранение метрик Prometheus – habr.com
- 📄 Grafana как еще один инструмент для технического мониторинга – habr.com
Оптимизация
-
Профилирование
Профилирование – это анализ производительности программы, который позволяет обнаружить узкие места в которых происходит наибольшая нагрузка на процессор и/или память.
- Для чего это нужно?
Информация полученая после профилирования может оказаться очень полезной для оптимизации производительности. Также, профилирование может быть полезно при отладке программы для поиска багов и ошибок.
- Когда этим нужно заниматься?
По мере потребности – когда есть явные проблемы или подозрения.
- Какие конкретные инструменты для этого есть?
Для Python используется: cProfile, line_profiler.
Для Node.js: встроенный Profiler, Clinic.js, модуль Trace events.
Для Go: пакет runtime/pprof, утилита trace.
- Для чего это нужно?
🔗 Ссылки на материалы
- 📄 Профилирование кода к Python
- 📄 Профилировщики Python
- 📺 Утечки памяти в Node.js и JavaScript, сборка мусора и профилирование – YouTube
- 📺 Профилирование JS: увидеть самое важное и не утонуть в море чисел – YouTube
- 📄 Простое профилирование Node.js приложений
- 📄 Профилирование и оптимизация программ на Go
- 📄 Профилирование в Go
- 📄 Kotlin performance on Android
-
Бенчмарки
Бенчмарк (в контексте программирования) – это инструмент, который используется для измерения времени выполнения программного кода. Обычно, для измерения производительности, один и тот же код (или его определенная часть) запускается многократно, и затем вычисляется среднее время выполнения. Кроме того, этот инструмент может также предоставлять информацию о количестве выполненных операций и объеме используемой памяти.
- Для чего это нужно?
Бенчмарки полезны, как для оценки производительности, так и для выбора наиболее эффективного решения поставленной задачи.
- Какие конкретные инструменты для этого есть?
Для Python: timeit, pytest-benchmark.
Для Node.js: console.time, Artillery.
Для Go: testing.B, Benchstat.
Существуют бенчмарки для измерения производительности сетевых приложений, где можно получить подробную информацию о среднем времени обработки запросов, максимальном количестве поддерживаемых подключений, скорости передачи данных и так далее (см. список HTTP бенчмарков).
- Для чего это нужно?
🔗 Ссылки на материалы
-
Кэширование
Кэширование является одним из самых действенных решений по оптимизации работы веб-приложений. Благодаря кэшированию можно повторно использовать ранее полученные ресурсы (статические файлы), тем самым сокращая задержку, снижая сетевой трафик и уменьшая время, необходимое для полной загрузки контента.

- CDN (Content Delivery Network)
Система серверов расположенная по всему миру. Такие сервера позволяют хранить дубликаты статического контента и доставлять его намного быстрее тем пользователям, которые находятся в непосредственной географической близости. Так же при использовании CDN снижается нагрузка на главный сервер.
- Браузерное (клиентское) кэширование
Основано на загрузке страниц и других статических данных из локального кэша. Для этого браузеру (клиенту) отдается специальные заголовки: 304 Not Modified, Expires, Strict-Transport-Security.
- Memcached
Программа-демон которая реализует высокопроизводительное кэширование в оперативной памяти на основе пар ключ-значение. В отличие от Redis не может являться надёжным и долговременным хранилищем, поэтому подходит только для кэша.
- CDN (Content Delivery Network)
🔗 Ссылки на материалы
- 📄 Что такое CDN и как это работает? – habr.com
- 📄 CDN: что такое и как это работает – selectel.ru
- 📄 Что такое CDN и как работает данная технология
- 📺 CDN своими руками – YouTube
- 📄 Учебное пособие по кэшированию – habr.com
- 📄 Кэширование и производительность веб-приложений – habr.com
- 📄 Основы кеширования веб-приложений
- 📄 HTTP-кеширование – (MDN) mozilla.org
- 📄 Четыре уровня кэширования в сети: клиентский, сетевой, серверный и уровень приложения – tproger.ru
- 📄 «HTTP Strict-Transport-Security» или как обезопасить себя от атак «man-in-the-middle» и заставить браузер всегда использовать HTTPS – habr.com
- 📄 Что такое Memcached? – Amazon
- 📺 Сравниваем Redis и Memcached, плюсы и минусы этих решений – YouTube
-
Балансировка нагрузки

Когда весь код приложения максимально оптимизирован и наращивание мощности сервера подходит к пределу, а нагрузка всё растёт и растёт – приходится прибегать к механизмам кластеризации и балансировки. Суть заключается в объединении групп серверов в кластера, где нагрузка между ними распределяется при помощи специальных методов и алгоритмов, называемых балансировкой.
- Балансировка на сетевом уровне
- DNS-балансировка. На одно доменное имя выделяется несколько IP-адресов и сервер на который будет перенаправлен запрос определяется по алгоритму Round Robin.
- Построение NLB-кластера. Используется для управления двумя или более серверами в качестве одного виртуального кластера.
- Балансировка по территориальному признаку. Примером может служить метод рассылки Anycast.
- Балансировка на транспортном уровне
Общение с клиентом замыкается на балансировщике, который работает как прокси. Он взаимодействует с серверами от своего имени, передавая информацию о клиенте в дополнительных данных и заголовках. Пример – HAProxy.
- Балансировка на прикладном уровне
Балансировщик анализирует клиентские запросы и перенаправляет их на разные серверы в зависимости от характера запрашиваемого контента. Примером может служить модуль Upstream в Nginx (который отвечает за балансировку) и pgpool из базы данных PostgreSQL (например, c его помощью можно распределять запросы на чтение на один сервер, а запросы на запись — на другой).
- Алгоритмы балансировки
- Round Robin. Каждый запрос направляется поочередно на каждый сервер (сначала на первый, потом на второй и так по кругу).
- Weighted Round Robin. Улучшенный алгоритм Round Robin, который учитывает еще и производительность сервера.
- Least Connections. Каждый последующий запрос направляется на сервер с наименьшим количеством поддерживаемых подключений.
- Destination Hash Scheduling. Сервер, обрабатывающий запрос, выбирается из статической таблицы по IP-адресу получателя.
- Source Hash Scheduling. Сервер, который будет обрабатывать запрос, выбирается из таблицы по IP-адресу отправителя.
- Sticky Sessions. Запросы распределяются в зависимости от IP-адреса пользователя. Sticky Sessions предполагает, что обращения от одного клиента будут направляться на один и тот же сервер, а не скакать в пуле.
- Балансировка на сетевом уровне
🔗 Ссылки на материалы
- 📄 Как устроен балансировщик нагрузки: алгоритмы, методы и задачи – selectel.ru
- 📄 Балансировка нагрузки: основные алгоритмы и методы – habr.com
- 📄 Введение в современную балансировку сетевой нагрузки и проксирование – medium.com
- 📄 Балансировка и распределение нагрузки
- 📺 Балансировка нагрузки при помощи NGINX – YouTube
- 📺 HAProxy - бесплатный LoadBalancer. Установка и конфигурация – YouTube
Документирование
-
Markdown
Стандарт в мире разработки. Невероятно простой, но в тоже время мощный язык разметки для описания Ваших проектов. Собственно говоря, ресурс, который Вы сейчас читаете, написан с помощью Markdown.
- Markdown cheatsheet
Шпаргалка по всем синтаксически возможностям языка.
- Awesome Markdown
Сборник различных ресурсов для работы с Markdown.
- Awesome README
Сборник красивых README.md файлов (это главный файл любого репозитория на GitHub, использующий Markdown).
- Конспекты и заметки
Markdown используются не только для написания документации. Этот невероятный инструмент отлично подходит для обучения – создания электронных конспектов и различных заметок. Лично я использую редактор Obsidian для конспектирования нового материала.
- Markdown cheatsheet
🔗 Ссылки на материалы
-
Документация внутри кода
Для каждого современного языка программирования существуют специальные инструменты которые позволяют писать документацию прямо в коде программы. Благодаря этому Вы можете читать описание методов, функций, структур и так далее прямо внутри вашей IDE. Как правило, такого рода документация выполняется в виде обычных комментариев с учётом некоторых синтаксических особенностей.
- Зачем нужно?
Чтобы сделать свою работу и работу других разработчиков проще. В долгосрочной перспективе это сэкономит больше времени, чем путешествия по коду с целью понять как все работает, какие параметры передать функции или узнать какие вообще методы есть у того или иного класса. Со временем вы неизбежно будете забывать свой же код, поэтому уже написанная документация будет полезна и Вам лично.
- Что нужно чтобы начать?
Для каждого языка все индивидуально. Во многих есть свои устоявшиеся подходы:
- Docstring для Python.
- JSDoc для JavaScript.
- Godoc для Go.
- KDoc и Dokka для Kotlin.
- Javadoc для Java.
- И другие ищите по запросу:
documentation engine for <ваш язык>.
- Зачем нужно?
🔗 Ссылки на материалы
-
Документирование API
Удобная и понятная документация позволит другим пользователям быстрее разобраться и начать использовать ваш продукт. Писать документацию с нуля – это утомительный процесс. Для решения этой проблемы существуют общепринятые спецификации и инструменты автогенерации.
- OpenAPI
Спецификация, которая описывает, то как необходимо документировать API, чтобы он был читаем как для людей, так и для машин.
- Swagger
Набор инструментов который позволяет создавать удобную документацию API на основе той самой спецификации OpenAPI.
- Swagger UI
Инструмент позволяющий автоматически генерировать интерактивную документацию, которую можно не только читать, но и активно с ней взаимодействовать (отправлять HTTP-запросы).
- Swagger editor
Этакий playground в котором можно писать документацию и сразу видеть результат сгенерированной странички. Для этого используется файл YAML или JSON формата.
- Swagger codegen
Позволяет автоматически создавать клиентские библиотеки API, заглушки сервера и документацию.
- OpenAPI
🔗 Ссылки на материалы
- 📄 Документирование конечных точек
- 📺 Что такое Swagger и OpenAPI за 3 минуты – YouTube
- 📄 Swagger – умная документация вашего RESTful web-API – habr.com
- 📄 В чем польза формальных спецификаций вроде OpenAPI? – habr.com
- 📄 Спецификация OpenAPI и Swagger
- 📺 API + Swagger. Доклад Яндекса – YouTube
- 📄 Итак, вам нужно документировать API...
- 📄📺 Специфицируй это. Доклад Яндекса – habr.com
- 📄 Тестирование документации
-
Генераторы статики
Со временем, когда Ваш проект разрастается и у него появляется множество модулей, одной странички README на GitHub может быть не достаточно. Уместно будет создать отдельный сайт для документации вашего проекта. Для этого совсем не обязательно учиться верстать, поскольку существует множество сайтов-генераторов для создания красивой и удобной документации.
- GitBook
Наверное самый популярный генератор документации с использованием GitHub/Git и Markdown.
- Docusaurus
Open-source генератор от компании Facebook (Meta).
- MkDocs
Простой и широко кастомизируемый генератор документации в формате Markdown.
- Slate
Минималистичный генератор документации для REST API.
- Docsify
Ещё один простой, легкий и минималистичный генератор статики.
- Astro
Генератор с современным и продвинутым дизайном.
- mdBook
Статический генератор от разработчиков языка Rust.
- И другие...
- GitBook
🔗 Ссылки на материалы
Построение архитектуры
-
Архитектурные шаблоны
- Layered (многоуровневый)
Используется для структурирования программ, которые могут быть разложены на группы подзадач, каждая из которых находится на определенном уровне абстракции. Каждый уровень предоставляет услуги следующему более высокому уровню.
- Client-server
Классический шаблон, где клиенты обращаются за данными и услугами к серверу, а сервер эффективно обрабатывает эти запросы.
- Master-slave (ведущий-ведомый)
Ведущий компонент распределяет работу между идентичными ведомыми компонентами и вычисляет конечный результат из результатов, которые возвращают ведомые компоненты.
- Pipe-filter (канал-фильтр)
Каждый этап обработки заключен в компонент фильтра. Данные, подлежащие обработке, передаются по каналам. Эти каналы могут использоваться для буферизации или для синхронизации.
- Broker pattern (посредник)
Компонент посредника отвечает за координацию связи между всеми компонентами.
- Peer-to-peer (одноранговый)
Компоненты могут функционировать как в качестве клиента, запрашивая услуги у других компонентов, так и в качестве сервера, предоставляя услуги другим компонентам. Компонент может действовать как клиент, как сервер или как оба, а также может динамически менять свою роль со временем.
- Event-bus (шина событий)
Имеет 4 основных компонента: источник событий, слушатель событий, канал и шина событий. Источники публикуют сообщения в определенные каналы на шине событий.
- Blackboard (доска)
Применяется для решения задач, для которых не известны детерминированные стратегии решения.
- Interpreter (интерпретатор)
Используется для разработки компонента, который интерпретирует программы, написанные на специальном языке.
- Model-view-controller
- MVP (Modev-View-Presenter)
- MVVM (Model-View-ViewModel)
- DDD (Domain-Driven Design)
- Event-Driven Architecture
- Layered (многоуровневый)
🔗 Ссылки на материалы
- 📺 Архитектура ПО. Что это и зачем? – YouTube
- 📄 Краткий обзор 10 популярных архитектурных шаблонов приложений – medium
- 📺 Что такое MVC за 4 минуты – YouTube
- 📺 MVC, MVVM Архитектура. Наглядная теория и примеры – YouTube
- 📄 Самые важные архитектурные шаблоны, которые нужно знать – habr.com
- 📄 Архитектурные шаблоны – github.com
- 📄 Чистая архитектура – habr.com
- 📄 Что можно узнать о Domain Driven Design за 10 минут? – habr.com
- 📺 Доклад про Domain Driven Design – YouTube
-
Паттерны проектирования
- Порождающие паттерны
Отвечают за удобное и безопасное создание новых объектов или даже целых семейств объектов
- Структурные паттерны
Отвечают за построение удобных в поддержке иерархий классов
- Поведенческие паттерны
Решают задачи эффективного и безопасного взаимодействия между объектами программы
- Порождающие паттерны
🔗 Ссылки на материалы
- 📄 Паттерны ООП в метафорах – habr.com
- 📄 Шпаргалка по шаблонам проектирования – habr.com
- 📺 Паттерны проектирования на языке Python (playlist) – YouTube
- 📺 JavaScript Паттерны. Шаблоны проектирования. 17 Примеров – YouTube
- 📺 Паттерны проектирования на языке Go (playlist) – YouTube
- 📄 Паттерны проектирования – metanit.com
-
Монолитная и микросервисная архитектура
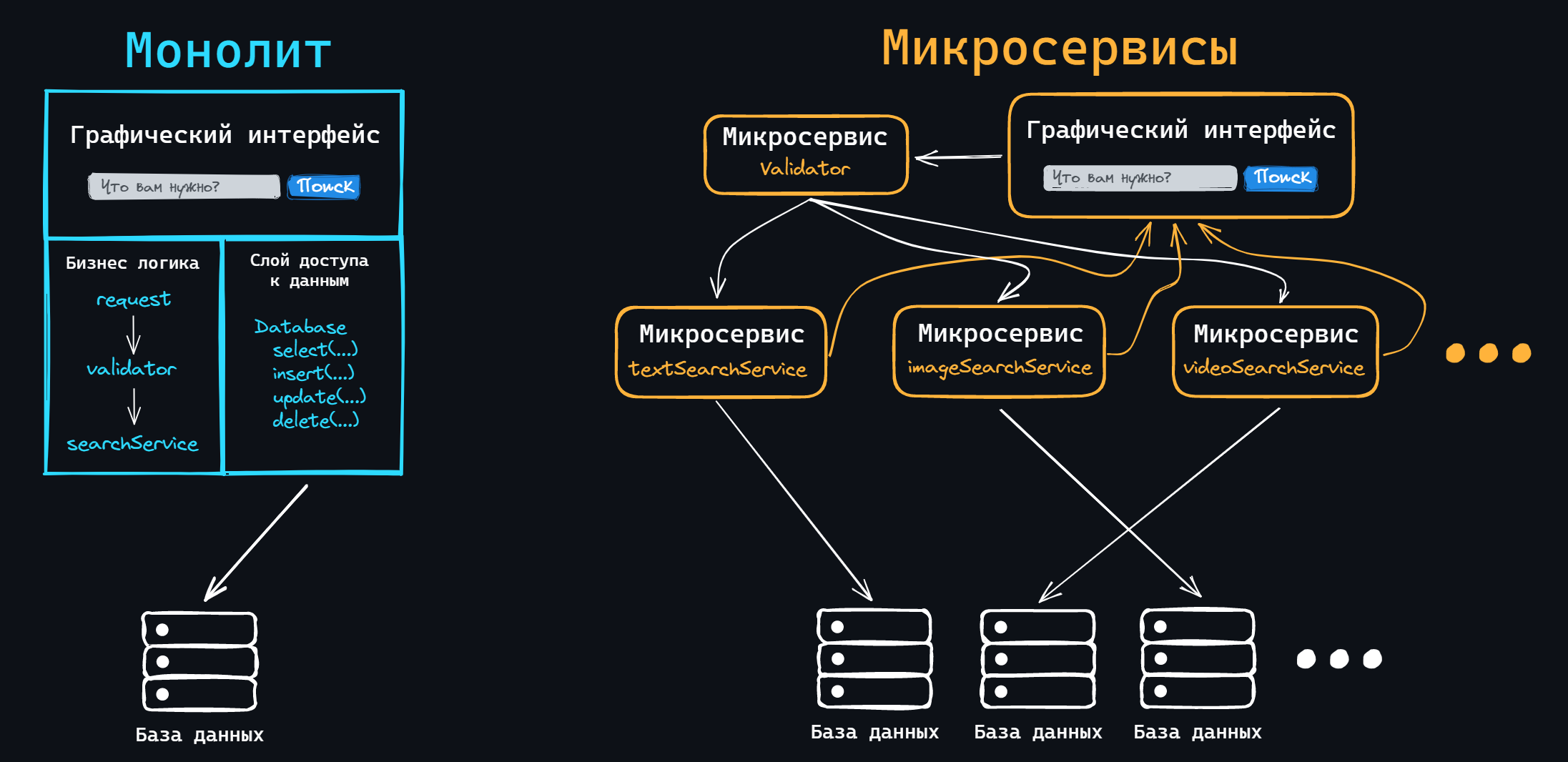
Монолит – это полноценное приложение, которое содержит единую кодовую базу (написана на одном стеке технологий и хранится в одном репозитории) и имеет единую точку входа для запуска всего приложения. Это самый распространенный подход для создания приложений в одиночку или небольшой командой.
- Достоинства
- Простота разработки (все в одном стиле и в одном месте).
- Простота развертывания.
- Легко масштабируется на начальном этапе.
- Простота разработки (все в одном стиле и в одном месте).
- Недостатки
- Нарастающая сложность (с ростом проекта увеличивается порог входа для новых разработчиков).
- Растет время на сборку и запуск.
- Усложняется добавление нового функционала, который затрагивает старый.
- Сложно (или невозможно) применение новых технологий.
- Нарастающая сложность (с ростом проекта увеличивается порог входа для новых разработчиков).
Микросервис – это полноценное приложение с единой кодовой базой. Но, в отличие от монолита, такое приложение отвечает лишь за одну функциональную единицу. То есть это маленький сервис, который решает только одну задачу, но хорошо.
- Достоинства
- Каждый отдельный микросервис может иметь свой стек технологий и разрабатываться не зависимо.
- Легко добавлять новый функционал (просто создайте новый микросервис).
- Меньше порог входа для новых разработчиков.
- Малые затраты времени на сборку и запуск.
- Каждый отдельный микросервис может иметь свой стек технологий и разрабатываться не зависимо.
- Недостатки
- Сложность реализации взаимодействия между всеми микросервисами.
- Сложнее в эксплуатации, чем несколько экземпляров монолита.
- Сложность выполнения транзакций.
- Изменения, затрагивающие несколько микросервисов, должны координироваться.
- Сложность реализации взаимодействия между всеми микросервисами.
- Достоинства
🔗 Ссылки на материалы
-
Горизонтальное и вертикальное масштабирование
Со временем, когда нагрузка на Ваше приложение начинает расти (приходит больше пользователей, появляется новый функционал и, как следствие, задействуется больше процессорного времени), становится необходимым увеличивать мощность сервера. Для этого есть 2 основных подхода:
- Вертикальное масштабирование
Подразумевает увеличение мощности уже существующего сервера. К примеру, сюда можно отнести увеличение размера оперативной памяти, установка более быстрого накопителя или увеличение его объема, а также покупка нового процессора с большой тактовой частотой и/или большим количеством ядер и потоков. Вертикальное масштабирование имеет свой предел, поскольку мы не можем долго наращивать мощности одного сервера.
- Горизонтальное масштабирование
Процесс развертывания новых серверов. Данный подход требует построения надёжной и масштабируемой архитектуры, которая позволит разнести логику работы всего приложения (или уже правильнее сказать сервиса) на несколько физических машин.
- Вертикальное масштабирование
🔗 Ссылки на материалы
Дополнительные и похожие ресурсы
- Backend Developer Roadmap: Learn to become a modern backend developer
- Профессия: бэкенд-разработчик
- Backend Roadmap (from Junior to Senior)
- A curated and opinionated list of resources (English & Russian) for Backend developers
- Timur Shemsedinov – открытые лекции, конференции, митапы по программной инженерии
- Hussein Nasser – один из лучших англоязычных каналов на YouTube по серверной разработке
- Курс по компьютерным сетям начального уровня
- Как освоить бэкенд-разработку в 2022 году: дорожная карта
- Backend Roadmap для самоучек
- Max-Starling/Notes - Заметки Full Stack разработчика
- Что должен знать Junior Backend разработчик? Подробный план
- Сети для самых маленьких – серия статей о сетях, их настройке и администрировании